 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
BLINC: Lightweight Bimodal Learning for Low-Complexity VVC Intra Coding
Jan 19, 2022
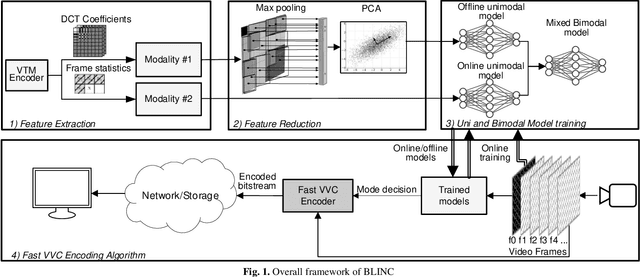

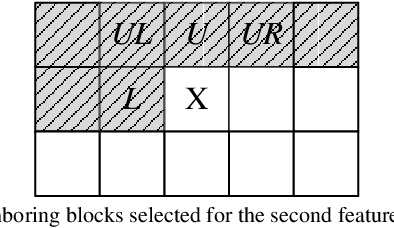
The latest video coding standard, Versatile Video Coding (VVC), achieves almost twice coding efficiency compared to its predecessor, the High Efficiency Video Coding (HEVC). However, achieving this efficiency (for intra coding) requires 31x computational complexity compared to HEVC, making it challenging for low power and real-time applications. This paper, proposes a novel machine learning approach that jointly and separately employs two modalities of features, to simplify the intra coding decision. First a set of features are extracted that use the existing DCT core of VVC, to assess the texture characteristics, and forms the first modality of data. This produces high quality features with almost no overhead. The distribution of intra modes at the neighboring blocks is also used to form the second modality of data, which provides statistical information about the frame. Second, a two-step feature reduction method is designed that reduces the size of feature set, such that a lightweight model with a limited number of parameters can be used to learn the intra mode decision task. Third, three separate training strategies are proposed (1) an offline training strategy using the first (single) modality of data, (2) an online training strategy that uses the second (single) modality, and (3) a mixed online-offline strategy that uses bimodal learning. Finally, a low-complexity encoding algorithms is proposed based on the proposed learning strategies. Extensive experimental results show that the proposed methods can reduce up to 24% of encoding time, with a negligible loss of coding efficiency. Moreover, it is demonstrated how a bimodal learning strategy can boost the performance of learning. Lastly, the proposed method has a very low computational overhead (0.2%), and uses existing components of a VVC encoder, which makes it much more practical compared to competing solutions.
YONO: Modeling Multiple Heterogeneous Neural Networks on Microcontrollers
Mar 08, 2022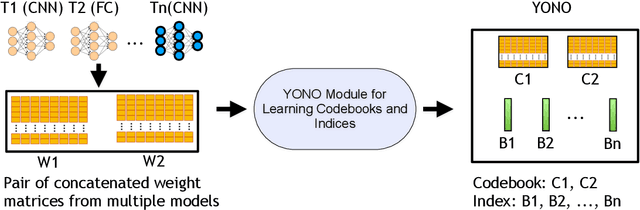
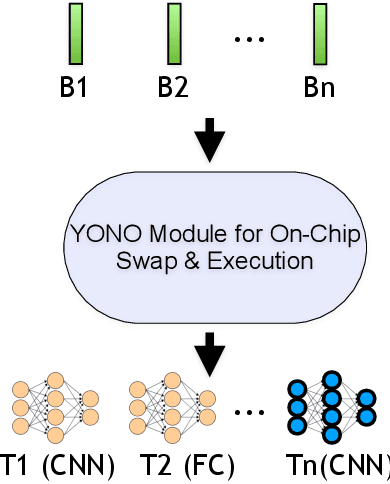

With the advancement of Deep Neural Networks (DNN) and large amounts of sensor data from Internet of Things (IoT) systems, the research community has worked to reduce the computational and resource demands of DNN to compute on low-resourced microcontrollers (MCUs). However, most of the current work in embedded deep learning focuses on solving a single task efficiently, while the multi-tasking nature and applications of IoT devices demand systems that can handle a diverse range of tasks (activity, voice, and context recognition) with input from a variety of sensors, simultaneously. In this paper, we propose YONO, a product quantization (PQ) based approach that compresses multiple heterogeneous models and enables in-memory model execution and switching for dissimilar multi-task learning on MCUs. We first adopt PQ to learn codebooks that store weights of different models. Also, we propose a novel network optimization and heuristics to maximize the compression rate and minimize the accuracy loss. Then, we develop an online component of YONO for efficient model execution and switching between multiple tasks on an MCU at run time without relying on an external storage device. YONO shows remarkable performance as it can compress multiple heterogeneous models with negligible or no loss of accuracy up to 12.37$\times$. Besides, YONO's online component enables an efficient execution (latency of 16-159 ms per operation) and reduces model loading/switching latency and energy consumption by 93.3-94.5% and 93.9-95.0%, respectively, compared to external storage access. Interestingly, YONO can compress various architectures trained with datasets that were not shown during YONO's offline codebook learning phase showing the generalizability of our method. To summarize, YONO shows great potential and opens further doors to enable multi-task learning systems on extremely resource-constrained devices.
An analysis of deep neural networks for predicting trends in time series data
Sep 22, 2020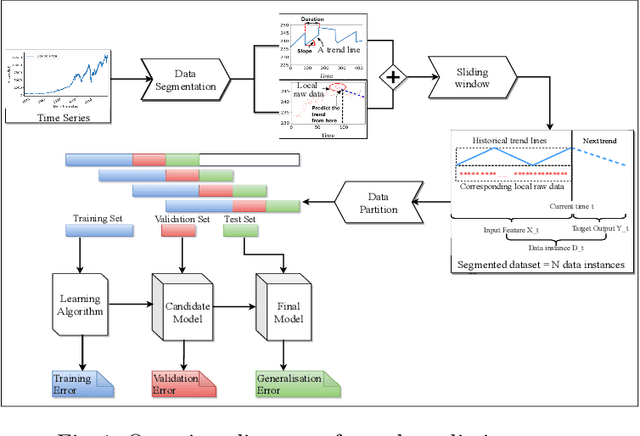

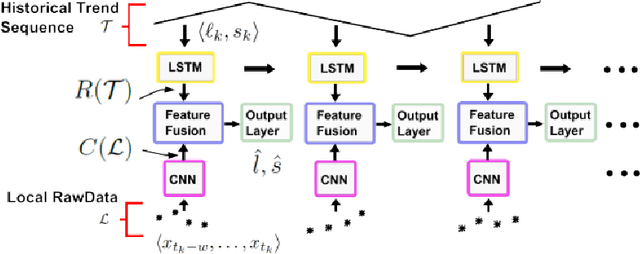
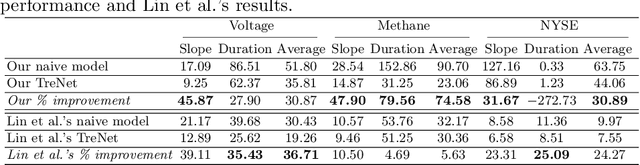
Recently, a hybrid Deep Neural Network (DNN) algorithm, TreNet was proposed for predicting trends in time series data. While TreNet was shown to have superior performance for trend prediction to other DNN and traditional ML approaches, the validation method used did not take into account the sequential nature of time series data sets and did not deal with model update. In this research we replicated the TreNet experiments on the same data sets using a walk-forward validation method and tested our optimal model over multiple independent runs to evaluate model stability. We compared the performance of the hybrid TreNet algorithm, on four data sets to vanilla DNN algorithms that take in point data, and also to traditional ML algorithms. We found that in general TreNet still performs better than the vanilla DNN models, but not on all data sets as reported in the original TreNet study. This study highlights the importance of using an appropriate validation method and evaluating model stability for evaluating and developing machine learning models for trend prediction in time series data.
Accelerating Deep Reinforcement Learning for Digital Twin Network Optimization with Evolutionary Strategies
Feb 01, 2022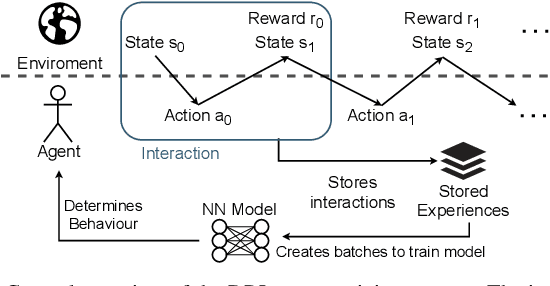
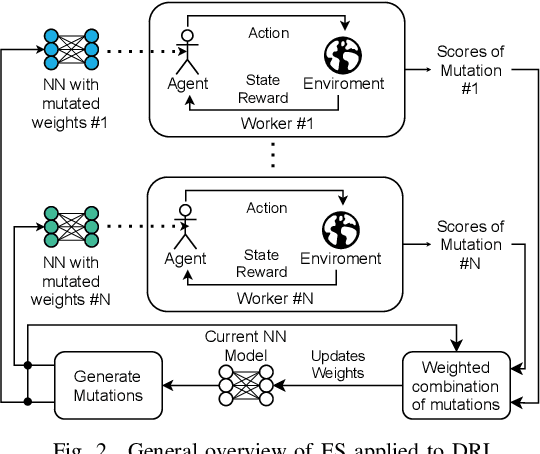
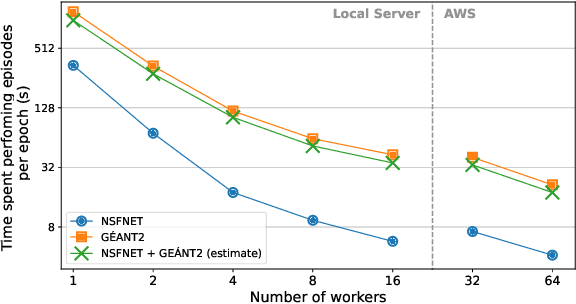
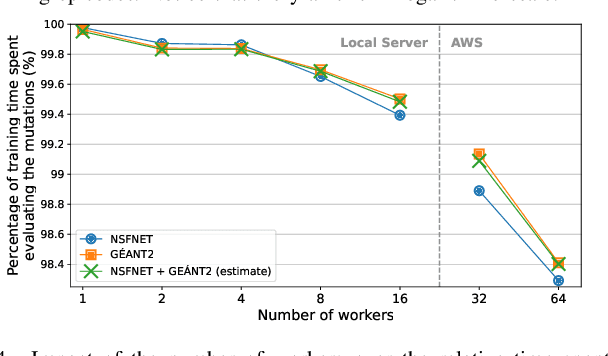
The recent growth of emergent network applications (e.g., satellite networks, vehicular networks) is increasing the complexity of managing modern communication networks. As a result, the community proposed the Digital Twin Networks (DTN) as a key enabler of efficient network management. Network operators can leverage the DTN to perform different optimization tasks (e.g., Traffic Engineering, Network Planning). Deep Reinforcement Learning (DRL) showed a high performance when applied to solve network optimization problems. In the context of DTN, DRL can be leveraged to solve optimization problems without directly impacting the real-world network behavior. However, DRL scales poorly with the problem size and complexity. In this paper, we explore the use of Evolutionary Strategies (ES) to train DRL agents for solving a routing optimization problem. The experimental results show that ES achieved a training time speed-up of 128 and 6 for the NSFNET and GEANT2 topologies respectively.
Optimal reservoir computers for forecasting systems of nonlinear dynamics
Feb 09, 2022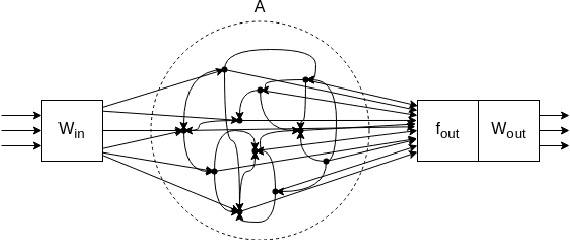
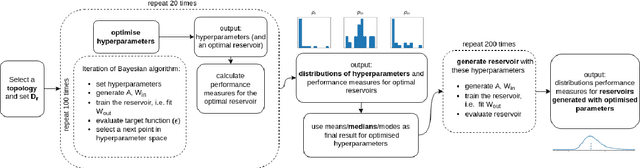
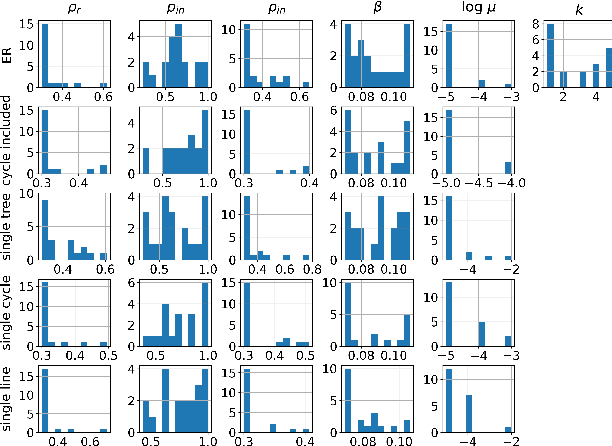
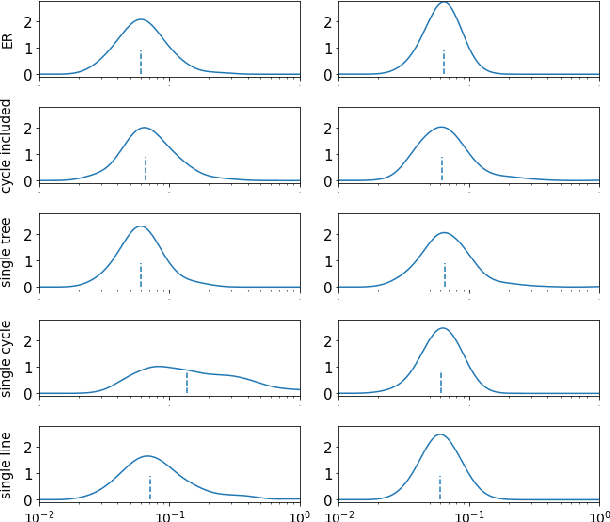
Prediction and analysis of systems of nonlinear dynamics is crucial in many applications. Here, we study characteristics and optimization of reservoir computing, a machine learning technique that has gained attention as a suitable method for this task. By systematically applying Bayesian optimization on reservoirs we show that reservoirs of low connectivity perform better than or as well as those of high connectivity in forecasting noiseless Lorenz and coupled Wilson-Cowan systems. We also show that, unexpectedly, computationally effective reservoirs of unconnected nodes (RUN) outperform reservoirs of linked network topologies in predicting these systems. In the presence of noise, reservoirs of linked nodes perform only slightly better than RUNs. In contrast to previously reported results, we find that the topology of linked reservoirs has no significance in the performance of system prediction. Based on our findings, we give a procedure for designing optimal reservoir computers (RC) for forecasting dynamical systems. This work paves way for computationally effective RCs applicable to real-time prediction of signals measured on systems of nonlinear dynamics such as EEG or MEG signals measured on a brain.
Multi-modal unsupervised brain image registration using edge maps
Feb 22, 2022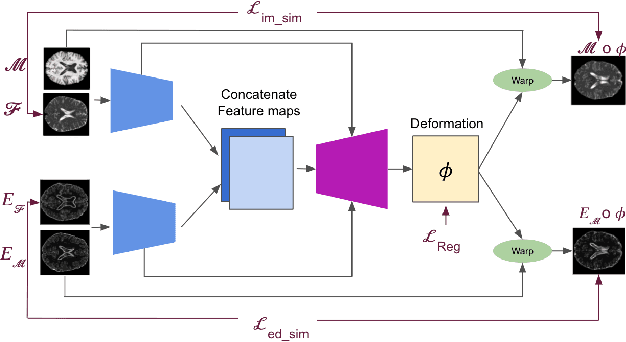
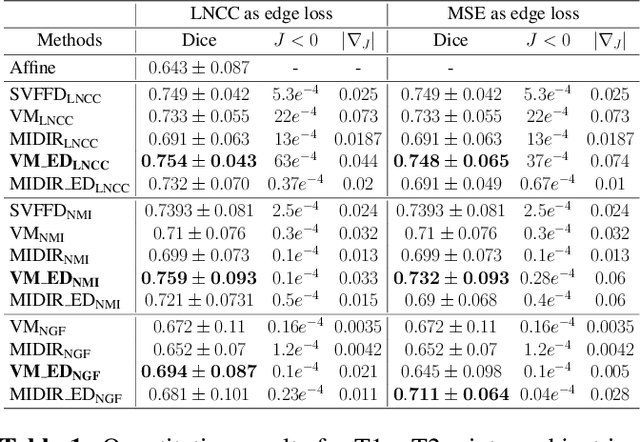


Diffeomorphic deformable multi-modal image registration is a challenging task which aims to bring images acquired by different modalities to the same coordinate space and at the same time to preserve the topology and the invertibility of the transformation. Recent research has focused on leveraging deep learning approaches for this task as these have been shown to achieve competitive registration accuracy while being computationally more efficient than traditional iterative registration methods. In this work, we propose a simple yet effective unsupervised deep learning-based {\em multi-modal} image registration approach that benefits from auxiliary information coming from the gradient magnitude of the image, i.e. the image edges, during the training. The intuition behind this is that image locations with a strong gradient are assumed to denote a transition of tissues, which are locations of high information value able to act as a geometry constraint. The task is similar to using segmentation maps to drive the training, but the edge maps are easier and faster to acquire and do not require annotations. We evaluate our approach in the context of registering multi-modal (T1w to T2w) magnetic resonance (MR) brain images of different subjects using three different loss functions that are said to assist multi-modal registration, showing that in all cases the auxiliary information leads to better results without compromising the runtime.
How to Manage Tiny Machine Learning at Scale: An Industrial Perspective
Feb 18, 2022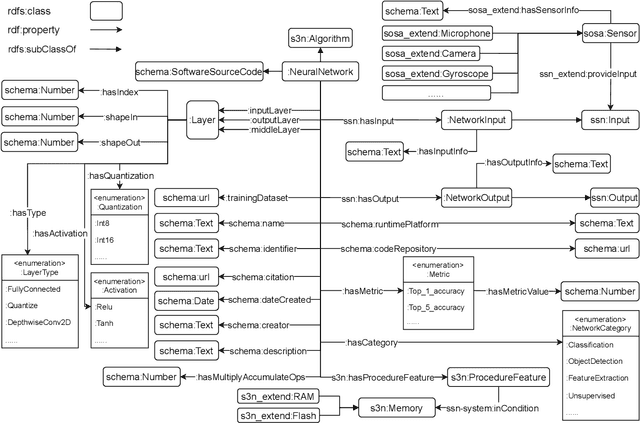
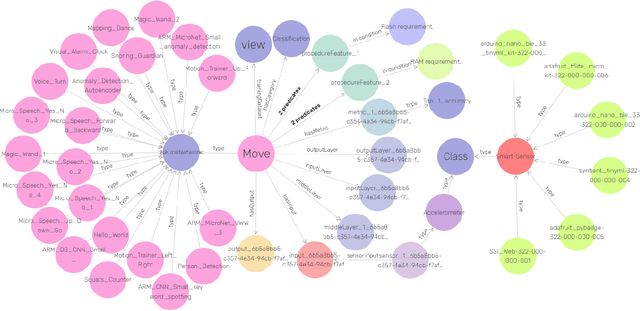
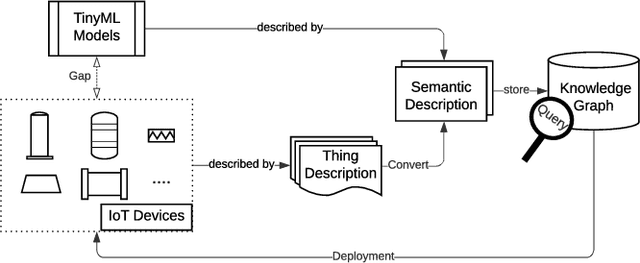
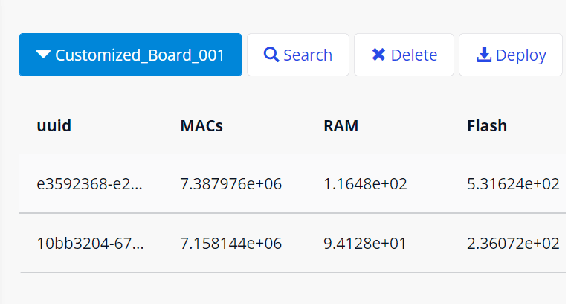
Tiny machine learning (TinyML) has gained widespread popularity where machine learning (ML) is democratized on ubiquitous microcontrollers, processing sensor data everywhere in real-time. To manage TinyML in the industry, where mass deployment happens, we consider the hardware and software constraints, ranging from available onboard sensors and memory size to ML-model architectures and runtime platforms. However, Internet of Things (IoT) devices are typically tailored to specific tasks and are subject to heterogeneity and limited resources. Moreover, TinyML models have been developed with different structures and are often distributed without a clear understanding of their working principles, leading to a fragmented ecosystem. Considering these challenges, we propose a framework using Semantic Web technologies to enable the joint management of TinyML models and IoT devices at scale, from modeling information to discovering possible combinations and benchmarking, and eventually facilitate TinyML component exchange and reuse. We present an ontology (semantic schema) for neural network models aligned with the World Wide Web Consortium (W3C) Thing Description, which semantically describes IoT devices. Furthermore, a Knowledge Graph of 23 publicly available ML models and six IoT devices were used to demonstrate our concept in three case studies, and we shared the code and examples to enhance reproducibility: https://github.com/Haoyu-R/How-to-Manage-TinyML-at-Scale
Shape and Time Distortion Loss for Training Deep Time Series Forecasting Models
Oct 21, 2019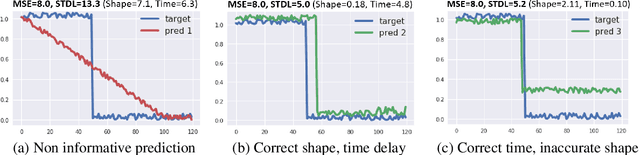
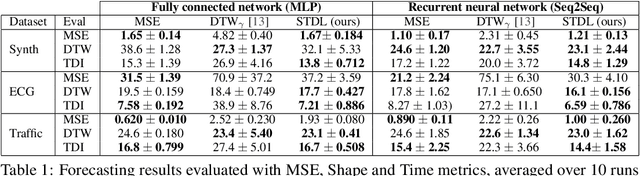
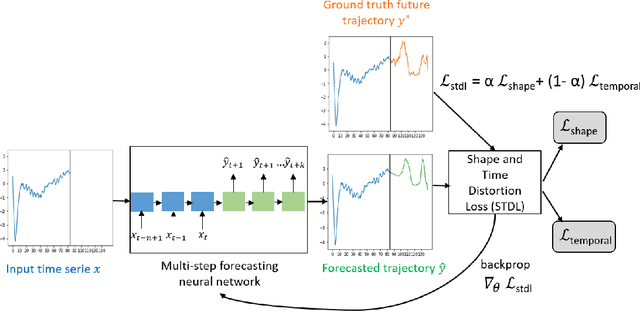
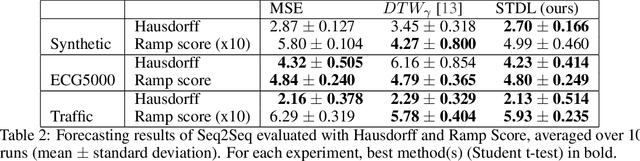
This paper addresses the problem of time series forecasting for non-stationary signals and multiple future steps prediction. To handle this challenging task, we introduce DILATE (DIstortion Loss including shApe and TimE), a new objective function for training deep neural networks. DILATE aims at accurately predicting sudden changes, and explicitly incorporates two terms supporting precise shape and temporal change detection. We introduce a differentiable loss function suitable for training deep neural nets, and provide a custom back-prop implementation for speeding up optimization. We also introduce a variant of DILATE, which provides a smooth generalization of temporally-constrained Dynamic Time Warping (DTW). Experiments carried out on various non-stationary datasets reveal the very good behaviour of DILATE compared to models trained with the standard Mean Squared Error (MSE) loss function, and also to DTW and variants. DILATE is also agnostic to the choice of the model, and we highlight its benefit for training fully connected networks as well as specialized recurrent architectures, showing its capacity to improve over state-of-the-art trajectory forecasting approaches.
Strategies for modelling open-loop saccade control of a cable-driven biomimetic robot eye
Mar 01, 2022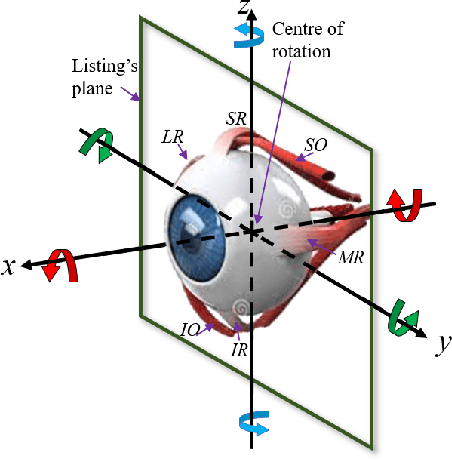
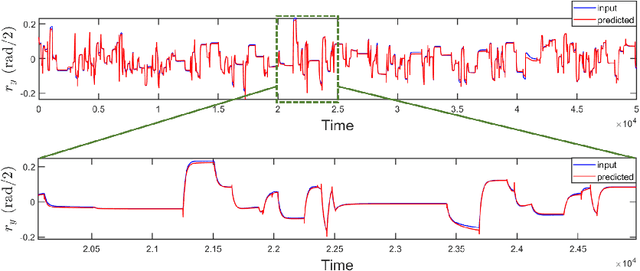

In human-robot interactions, eye movements play an important role in non-verbal communication. However, controlling the motions of a robotic eye that display similar performance as the human oculomotor system is still a major challenge. In this paper, we study how to control a realistic model of the human eye, with a cable-driven actuation system that mimicks the 6 extra-ocular muscles. We have built a robotic prototype and developed a non-linear simulation model, for which we compared different techniques to control its gaze behavior to match the main characteristics of saccade eye movements. In the first approach, we linearized the six degrees of freedom nonlinear model, using a local derivative technique, and designed linear-quadratic optimal controllers to optimize a cost function that accounts for accuracy, energy and duration. The second method learns a dynamic neural-network that matches the system dynamics, trained from sample trajectories of the system, and a non-linear trajectory optimization solver optimized a similar cost function. We focused on the generation of rapid saccadic eye movements with fully unconstrained kinematics, and the generation of control signals for the six cables that simultaneously satisfied several dynamic optimization criteria. The model faithfully mimicked the three-dimensional rotational kinematics and dynamics observed for human saccades. Our experimental results indicate that while the linear model provides a more accurate eye movement, the nonlinear model simulate eye dynamic properties in a better way faithful approximation to the properties of the human saccadic system than the linearized model, at the cost of larger training and optimization time.
A Fair and Efficient Hybrid Federated Learning Framework based on XGBoost for Distributed Power Prediction
Jan 08, 2022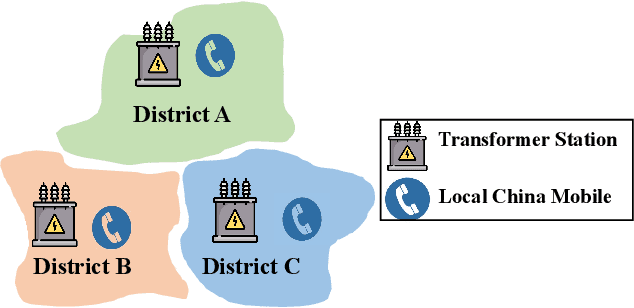
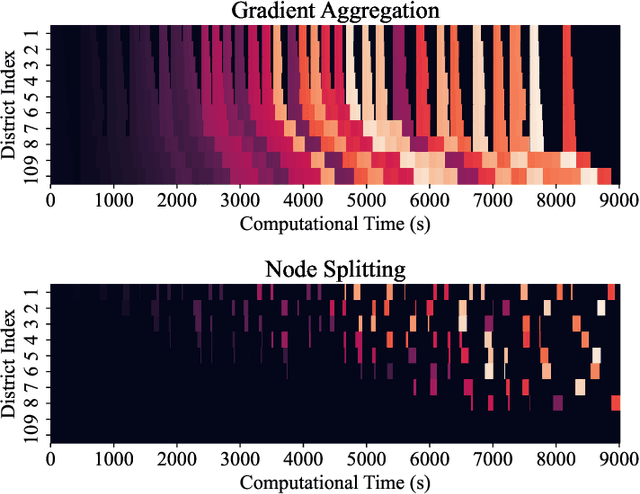
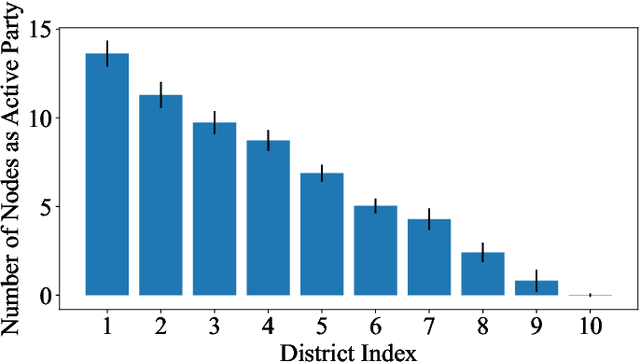
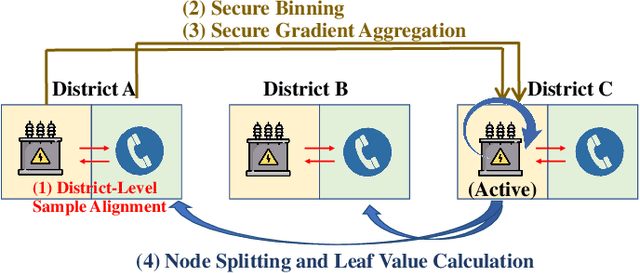
In a modern power system, real-time data on power generation/consumption and its relevant features are stored in various distributed parties, including household meters, transformer stations and external organizations. To fully exploit the underlying patterns of these distributed data for accurate power prediction, federated learning is needed as a collaborative but privacy-preserving training scheme. However, current federated learning frameworks are polarized towards addressing either the horizontal or vertical separation of data, and tend to overlook the case where both are present. Furthermore, in mainstream horizontal federated learning frameworks, only artificial neural networks are employed to learn the data patterns, which are considered less accurate and interpretable compared to tree-based models on tabular datasets. To this end, we propose a hybrid federated learning framework based on XGBoost, for distributed power prediction from real-time external features. In addition to introducing boosted trees to improve accuracy and interpretability, we combine horizontal and vertical federated learning, to address the scenario where features are scattered in local heterogeneous parties and samples are scattered in various local districts. Moreover, we design a dynamic task allocation scheme such that each party gets a fair share of information, and the computing power of each party can be fully leveraged to boost training efficiency. A follow-up case study is presented to justify the necessity of adopting the proposed framework. The advantages of the proposed framework in fairness, efficiency and accuracy performance are also confirmed.