 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Training end-to-end speech-to-text models on mobile phones
Dec 07, 2021
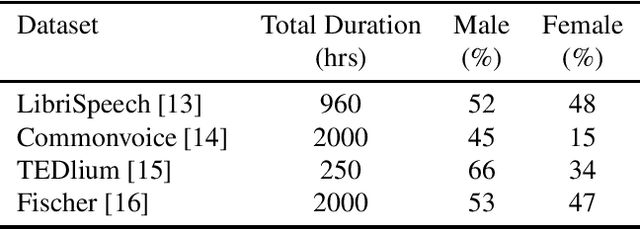
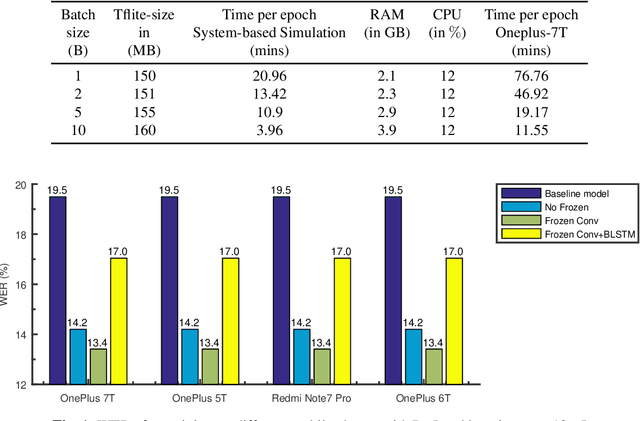
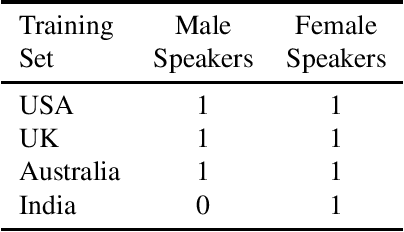
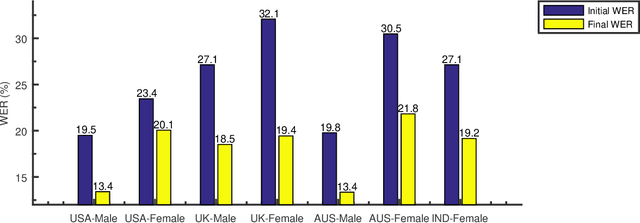
Training the state-of-the-art speech-to-text (STT) models in mobile devices is challenging due to its limited resources relative to a server environment. In addition, these models are trained on generic datasets that are not exhaustive in capturing user-specific characteristics. Recently, on-device personalization techniques have been making strides in mitigating the problem. Although many current works have already explored the effectiveness of on-device personalization, the majority of their findings are limited to simulation settings or a specific smartphone. In this paper, we develop and provide a detailed explanation of our framework to train end-to-end models in mobile phones. To make it simple, we considered a model based on connectionist temporal classification (CTC) loss. We evaluated the framework on various mobile phones from different brands and reported the results. We provide enough evidence that fine-tuning the models and choosing the right hyperparameter values is a trade-off between the lowest WER achievable, training time on-device, and memory consumption. Hence, this is vital for a successful deployment of on-device training onto a resource-limited environment like mobile phones. We use training sets from speakers with different accents and record a 7.6% decrease in average word error rate (WER). We also report the associated computational cost measurements with respect to time, memory usage, and cpu utilization in mobile phones in real-time.
Bayes Optimal Algorithm is Suboptimal in Frequentist Best Arm Identification
Feb 10, 2022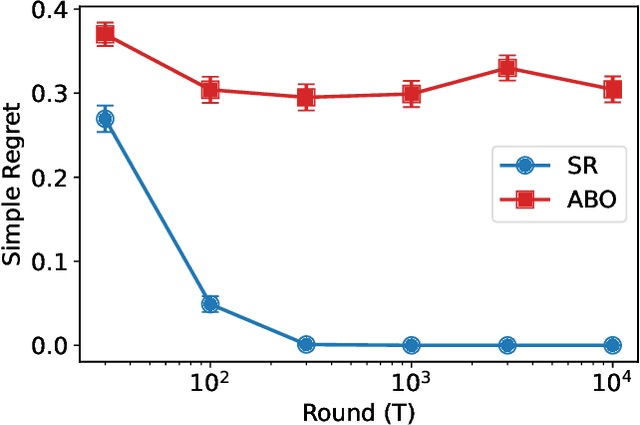
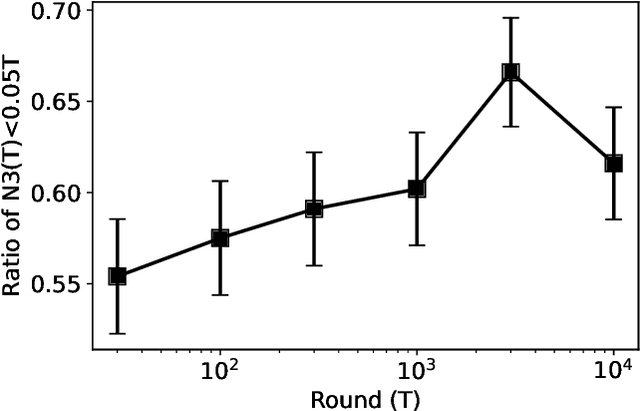
We consider the fixed-budget best arm identification problem with Normal rewards. In this problem, the forecaster is given $K$ arms (treatments) and $T$ time steps. The forecaster attempts to find the best arm in terms of the largest mean via an adaptive experiment conducted with an algorithm. The performance of the algorithm is measured by the simple regret, or the quality of the estimated best arm. It is known that the frequentist simple regret can be exponentially small to $T$ for any fixed parameters, whereas the Bayesian simple regret is $\Theta(T^{-1})$ over a continuous prior distribution. This paper shows that Bayes optimal algorithm, which minimizes the Bayesian simple regret, does not have an exponential simple regret for some parameters. This finding contrasts with the many results indicating the asymptotic equivalence of Bayesian and frequentist algorithms in fixed sampling regimes. While the Bayes optimal algorithm is described in terms of a recursive equation that is virtually impossible to compute exactly, we pave the way to an analysis by introducing a key quantity that we call the expected Bellman improvement.
TEE-based decentralized recommender systems: The raw data sharing redemption
Feb 23, 2022

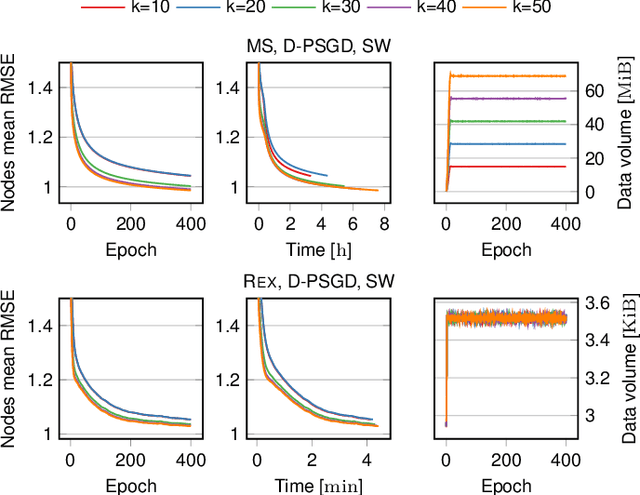
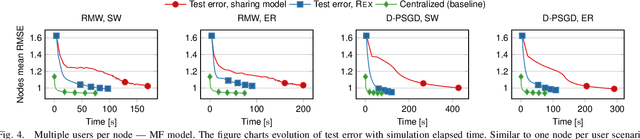
Recommenders are central in many applications today. The most effective recommendation schemes, such as those based on collaborative filtering (CF), exploit similarities between user profiles to make recommendations, but potentially expose private data. Federated learning and decentralized learning systems address this by letting the data stay on user's machines to preserve privacy: each user performs the training on local data and only the model parameters are shared. However, sharing the model parameters across the network may still yield privacy breaches. In this paper, we present REX, the first enclave-based decentralized CF recommender. REX exploits Trusted execution environments (TEE), such as Intel software guard extensions (SGX), that provide shielded environments within the processor to improve convergence while preserving privacy. Firstly, REX enables raw data sharing, which ultimately speeds up convergence and reduces the network load. Secondly, REX fully preserves privacy. We analyze the impact of raw data sharing in both deep neural network (DNN) and matrix factorization (MF) recommenders and showcase the benefits of trusted environments in a full-fledged implementation of REX. Our experimental results demonstrate that through raw data sharing, REX significantly decreases the training time by 18.3x and the network load by 2 orders of magnitude over standard decentralized approaches that share only parameters, while fully protecting privacy by leveraging trustworthy hardware enclaves with very little overhead.
A learning-based approach to feature recognition of Engineering shapes
Dec 15, 2021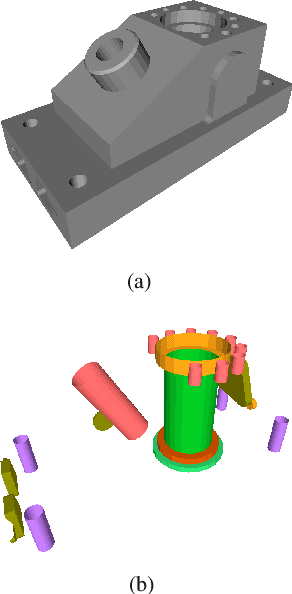
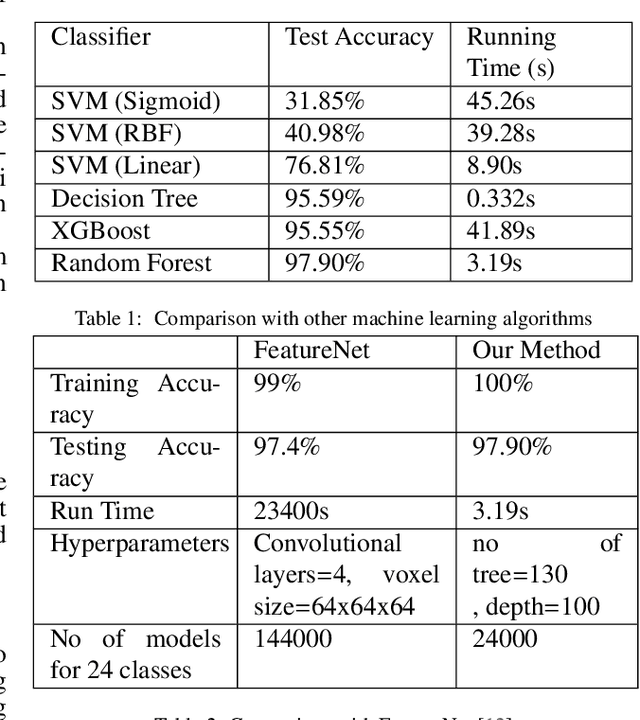


In this paper, we propose a machine learning approach to recognise engineering shape features such as holes, slots, etc. in a CAD mesh model. With the advent of digital archiving, newer manufacturing techniques such as 3D printing, scanning of components and reverse engineering, CAD data is proliferated in the form of mesh model representation. As the number of nodes and edges become larger in a mesh model as well as the possibility of presence of noise, direct application of graph-based approaches would not only be expensive but also difficult to be tuned for noisy data. Hence, this calls for newer approaches to be devised for feature recognition for CAD models represented in the form of mesh. Here, we show that a discrete version of Gauss map can be used as a signature for a feature learning. We show that this approach not only requires fewer memory requirements but also the training time is quite less. As no network architecture is involved, the number of hyperparameters are much lesser and can be tuned in a much faster time. The recognition accuracy is also very similar to that of the one obtained using 3D convolutional neural networks (CNN) but in much lesser running time and storage requirements. A comparison has been done with other non-network based machine learning approaches to show that our approach has the highest accuracy. We also show the recognition results for CAD models having multiple features as well as complex/interacting features obtained from public benchmarks. The ability to handle noisy data has also been demonstrated.
Improvements to short-term weather prediction with recurrent-convolutional networks
Nov 24, 2021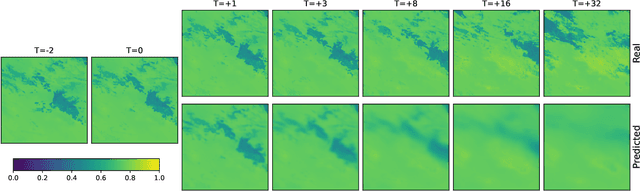

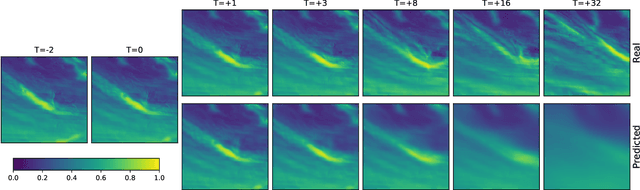
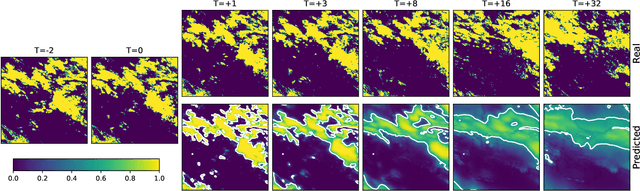
The Weather4cast 2021 competition gave the participants a task of predicting the time evolution of two-dimensional fields of satellite-based meteorological data. This paper describes the author's efforts, after initial success in the first stage of the competition, to improve the model further in the second stage. The improvements consisted of a shallower model variant that is competitive against the deeper version, adoption of the AdaBelief optimizer, improved handling of one of the predicted variables where the training set was found not to represent the validation set well, and ensembling multiple models to improve the results further. The largest quantitative improvements to the competition metrics can be attributed to the increased amount of training data available in the second stage of the competition, followed by the effects of model ensembling. Qualitative results show that the model can predict the time evolution of the fields, including the motion of the fields over time, starting with sharp predictions for the immediate future and blurring of the outputs in later frames to account for the increased uncertainty.
COIN++: Data Agnostic Neural Compression
Jan 30, 2022
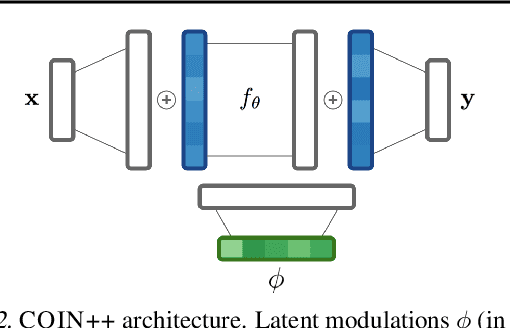
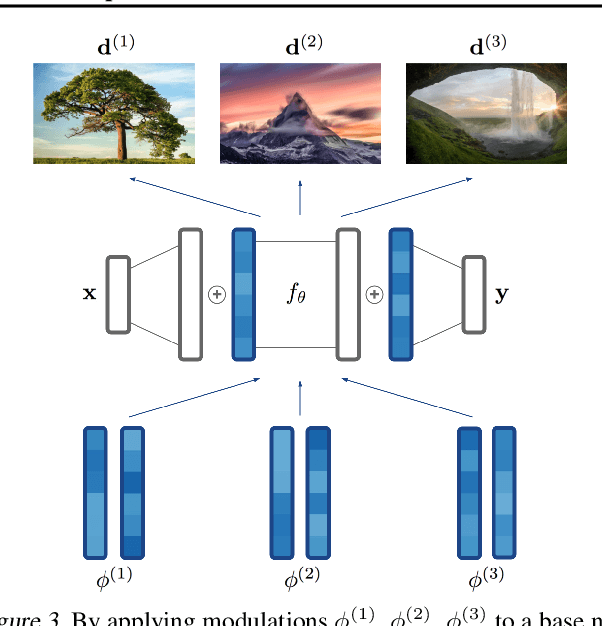
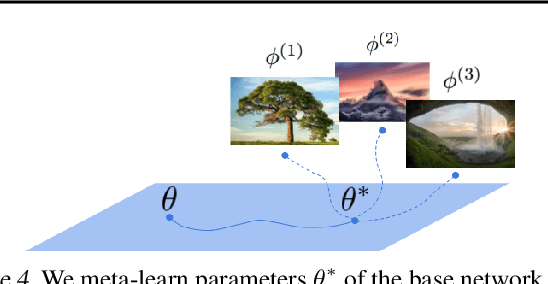
Neural compression algorithms are typically based on autoencoders that require specialized encoder and decoder architectures for different data modalities. In this paper, we propose COIN++, a neural compression framework that seamlessly handles a wide range of data modalities. Our approach is based on converting data to implicit neural representations, i.e. neural functions that map coordinates (such as pixel locations) to features (such as RGB values). Then, instead of storing the weights of the implicit neural representation directly, we store modulations applied to a meta-learned base network as a compressed code for the data. We further quantize and entropy code these modulations, leading to large compression gains while reducing encoding time by two orders of magnitude compared to baselines. We empirically demonstrate the effectiveness of our method by compressing various data modalities, from images to medical and climate data.
Current Time Series Anomaly Detection Benchmarks are Flawed and are Creating the Illusion of Progress
Oct 08, 2020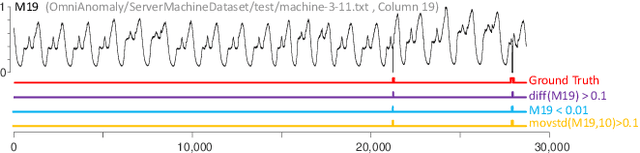
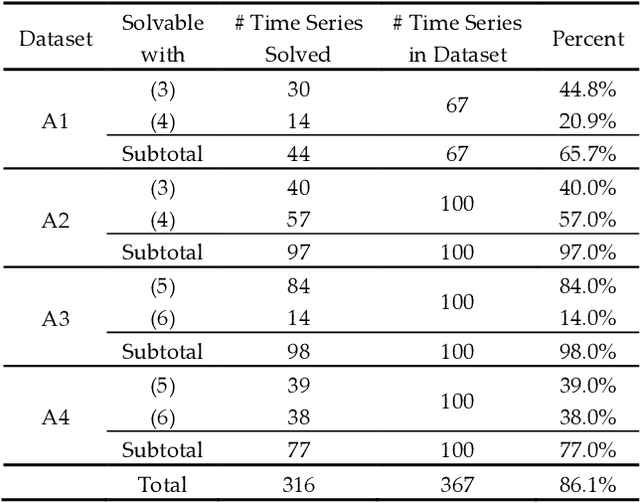
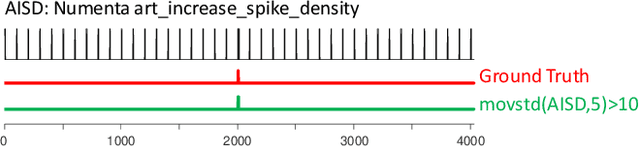
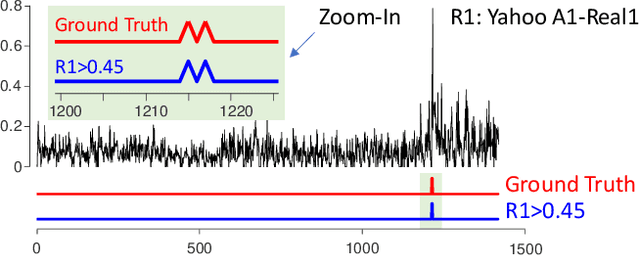
Time series anomaly detection has been a perennially important topic in data science, with papers dating back to the 1950s. However, in recent years there has been an explosion of interest in this topic, much of it driven by the success of deep learning in other domains and for other time series tasks. Most of these papers test on one or more of a handful of popular benchmark datasets, created by Yahoo, Numenta, NASA, etc. In this work we make a surprising claim. The majority of the individual exemplars in these datasets suffer from one or more of four flaws. Because of these four flaws, we believe that many published comparisons of anomaly detection algorithms may be unreliable, and more importantly, much of the apparent progress in recent years may be illusionary. In addition to demonstrating these claims, with this paper we introduce the UCR Time Series Anomaly Datasets. We believe that this resource will perform a similar role as the UCR Time Series Classification Archive, by providing the community with a benchmark that allows meaningful comparisons between approaches and a meaningful gauge of overall progress.
Faking feature importance: A cautionary tale on the use of differentially-private synthetic data
Mar 02, 2022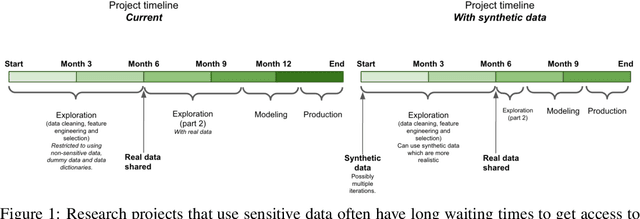
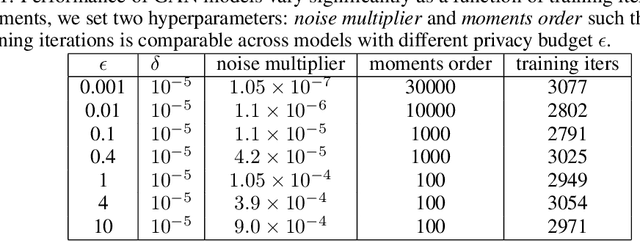
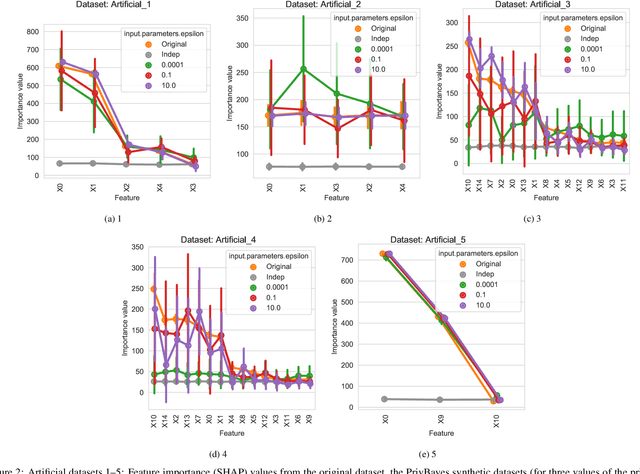
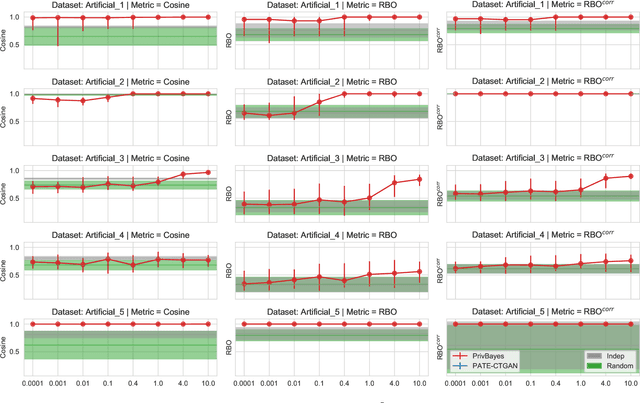
Synthetic datasets are often presented as a silver-bullet solution to the problem of privacy-preserving data publishing. However, for many applications, synthetic data has been shown to have limited utility when used to train predictive models. One promising potential application of these data is in the exploratory phase of the machine learning workflow, which involves understanding, engineering and selecting features. This phase often involves considerable time, and depends on the availability of data. There would be substantial value in synthetic data that permitted these steps to be carried out while, for example, data access was being negotiated, or with fewer information governance restrictions. This paper presents an empirical analysis of the agreement between the feature importance obtained from raw and from synthetic data, on a range of artificially generated and real-world datasets (where feature importance represents how useful each feature is when predicting a the outcome). We employ two differentially-private methods to produce synthetic data, and apply various utility measures to quantify the agreement in feature importance as this varies with the level of privacy. Our results indicate that synthetic data can sometimes preserve several representations of the ranking of feature importance in simple settings but their performance is not consistent and depends upon a number of factors. Particular caution should be exercised in more nuanced real-world settings, where synthetic data can lead to differences in ranked feature importance that could alter key modelling decisions. This work has important implications for developing synthetic versions of highly sensitive data sets in fields such as finance and healthcare.
No Cost Likelihood Manipulation at Test Time for Making Better Mistakes in Deep Networks
Apr 01, 2021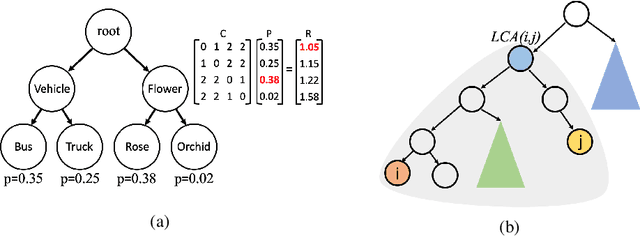
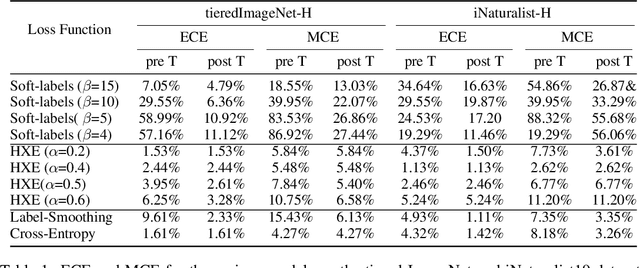


There has been increasing interest in building deep hierarchy-aware classifiers that aim to quantify and reduce the severity of mistakes, and not just reduce the number of errors. The idea is to exploit the label hierarchy (e.g., the WordNet ontology) and consider graph distances as a proxy for mistake severity. Surprisingly, on examining mistake-severity distributions of the top-1 prediction, we find that current state-of-the-art hierarchy-aware deep classifiers do not always show practical improvement over the standard cross-entropy baseline in making better mistakes. The reason for the reduction in average mistake-severity can be attributed to the increase in low-severity mistakes, which may also explain the noticeable drop in their accuracy. To this end, we use the classical Conditional Risk Minimization (CRM) framework for hierarchy-aware classification. Given a cost matrix and a reliable estimate of likelihoods (obtained from a trained network), CRM simply amends mistakes at inference time; it needs no extra hyperparameters and requires adding just a few lines of code to the standard cross-entropy baseline. It significantly outperforms the state-of-the-art and consistently obtains large reductions in the average hierarchical distance of top-$k$ predictions across datasets, with very little loss in accuracy. CRM, because of its simplicity, can be used with any off-the-shelf trained model that provides reliable likelihood estimates.
A Strong Baseline for Weekly Time Series Forecasting
Oct 16, 2020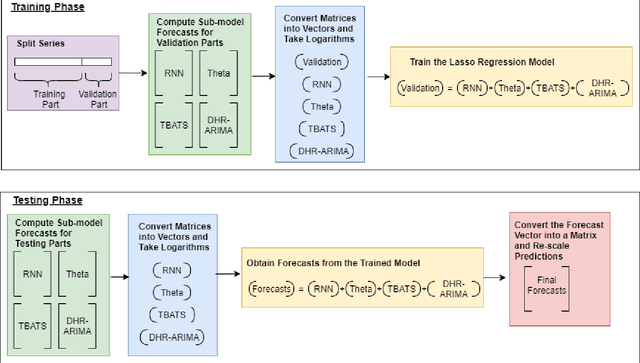

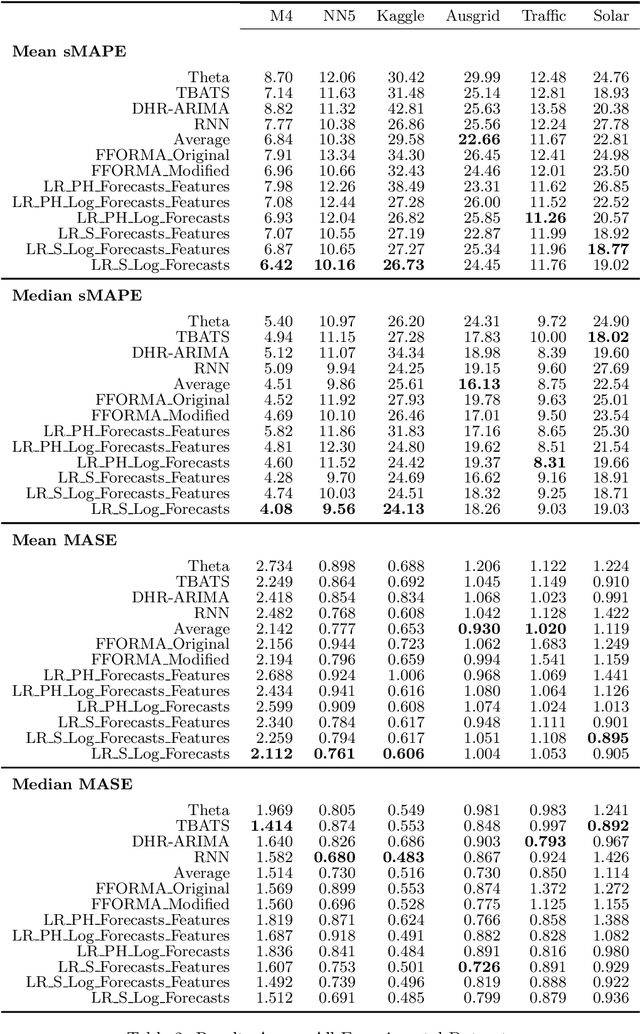
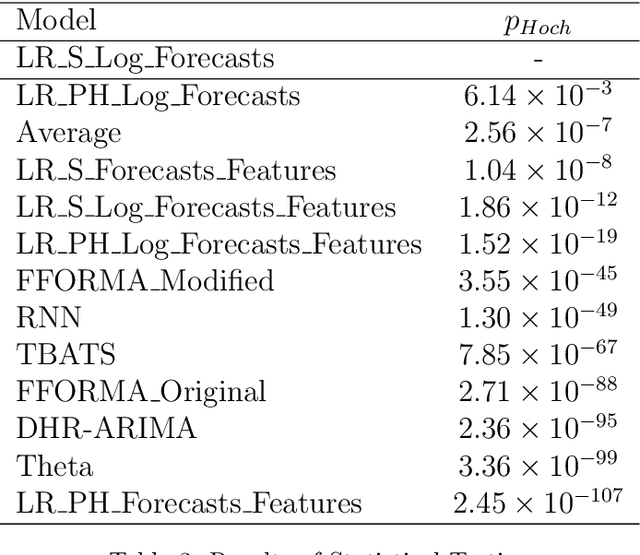
Many businesses and industries require accurate forecasts for weekly time series nowadays. The forecasting literature however does not currently provide easy-to-use, automatic, reproducible and accurate approaches dedicated to this task. We propose a forecasting method that can be used as a strong baseline in this domain, leveraging state-of-the-art forecasting techniques, forecast combination, and global modelling. Our approach uses four base forecasting models specifically suitable for forecasting weekly data: a global Recurrent Neural Network model, Theta, Trigonometric Box-Cox ARMA Trend Seasonal (TBATS), and Dynamic Harmonic Regression ARIMA (DHR-ARIMA). Those are then optimally combined using a lasso regression stacking approach. We evaluate the performance of our method against a set of state-of-the-art weekly forecasting models on six datasets. Across four evaluation metrics, we show that our method consistently outperforms the benchmark methods by a considerable margin with statistical significance. In particular, our model can produce the most accurate forecasts, in terms of mean sMAPE, for the M4 weekly dataset.