 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Online Continual Learning for Embedded Devices
Mar 21, 2022
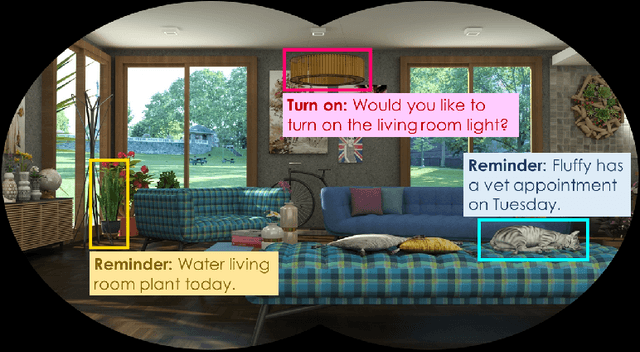
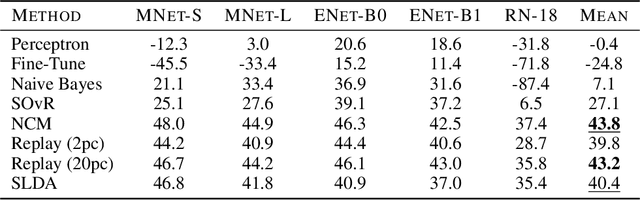

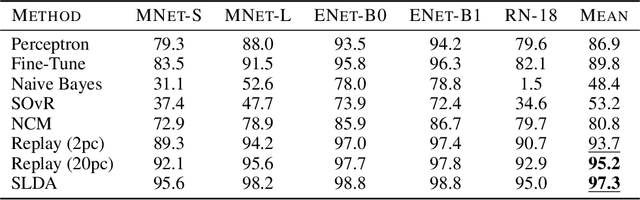
Real-time on-device continual learning is needed for new applications such as home robots, user personalization on smartphones, and augmented/virtual reality headsets. However, this setting poses unique challenges: embedded devices have limited memory and compute capacity and conventional machine learning models suffer from catastrophic forgetting when updated on non-stationary data streams. While several online continual learning models have been developed, their effectiveness for embedded applications has not been rigorously studied. In this paper, we first identify criteria that online continual learners must meet to effectively perform real-time, on-device learning. We then study the efficacy of several online continual learning methods when used with mobile neural networks. We measure their performance, memory usage, compute requirements, and ability to generalize to out-of-domain inputs.
Machining Cycle Time Prediction: Data-driven Modelling of Machine Tool Feedrate Behavior with Neural Networks
Jun 18, 2021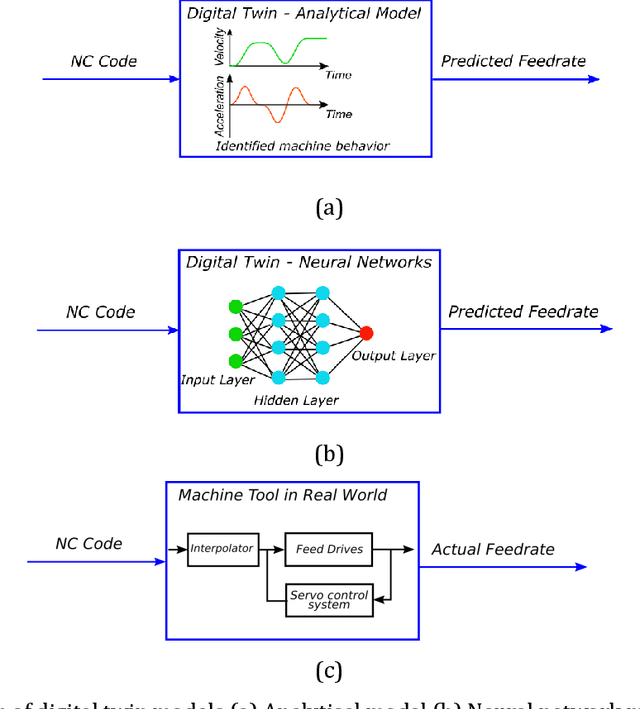

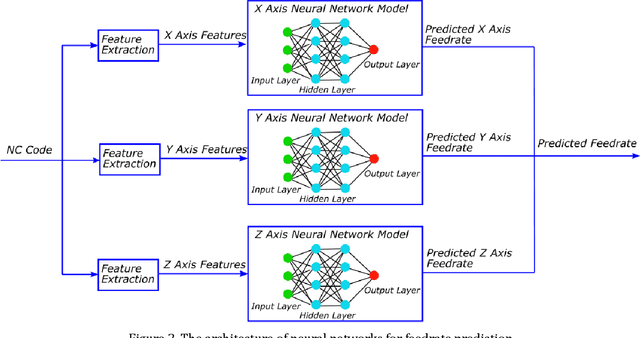
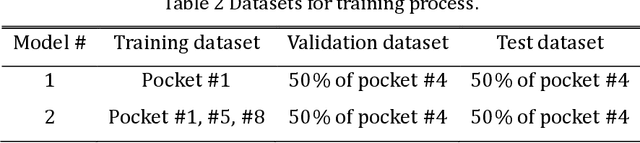
Accurate prediction of machining cycle times is important in the manufacturing industry. Usually, Computer Aided Manufacturing (CAM) software estimates the machining times using the commanded feedrate from the toolpath file using basic kinematic settings. Typically, the methods do not account for toolpath geometry or toolpath tolerance and therefore under estimate the machining cycle times considerably. Removing the need for machine specific knowledge, this paper presents a data-driven feedrate and machining cycle time prediction method by building a neural network model for each machine tool axis. In this study, datasets composed of the commanded feedrate, nominal acceleration, toolpath geometry and the measured feedrate were used to train a neural network model. Validation trials using a representative industrial thin wall structure component on a commercial machining centre showed that this method estimated the machining time with more than 90% accuracy. This method showed that neural network models have the capability to learn the behavior of a complex machine tool system and predict cycle times. Further integration of the methods will be critical in the implantation of digital twins in Industry 4.0.
Phase Shift Design in RIS Empowered Wireless Networks: From Optimization to AI-Based Methods
Apr 28, 2022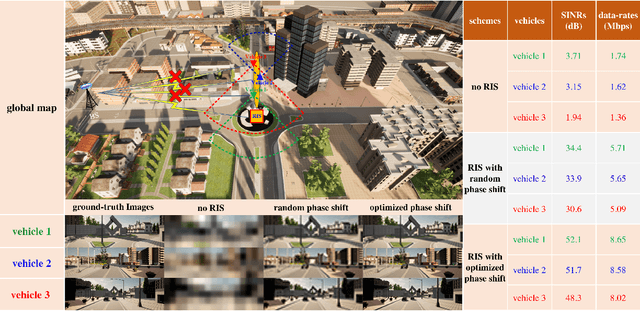
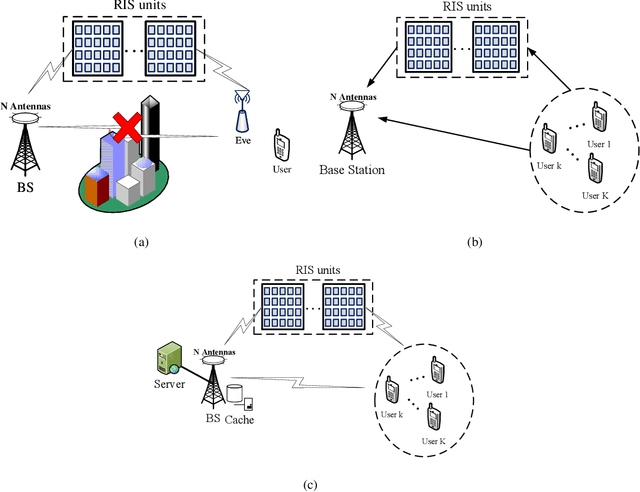
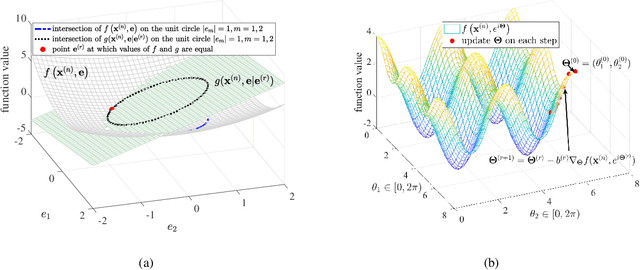
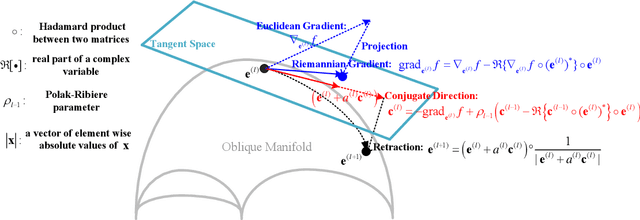
Reconfigurable intelligent surfaces (RISs) have a revolutionary capability to customize the radio propagation environment for wireless networks. To fully exploit the advantages of RISs in wireless systems, the phases of the reflecting elements must be jointly designed with conventional communication resources, such as beamformers, transmit power, and computation time. However, due to the unique constraints on the phase shift, and massive numbers of reflecting units and users in large-scale networks, the resulting optimization problems are challenging to solve. This paper provides a review of current optimization methods and artificial intelligence-based methods for handling the constraints imposed by RIS and compares them in terms of solution quality and computational complexity. Future challenges in phase shift optimization involving RISs are also described and potential solutions are discussed.
Extremely Lightweight Quantization Robust Real-Time Single-Image Super Resolution for Mobile Devices
May 21, 2021
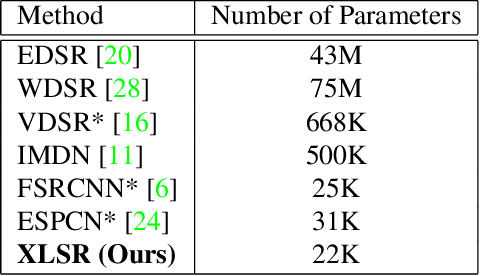
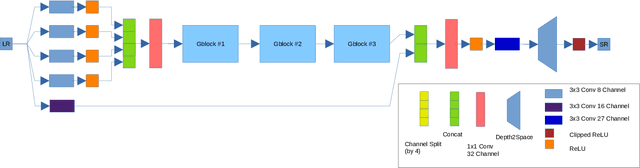

Single-Image Super Resolution (SISR) is a classical computer vision problem and it has been studied for over decades. With the recent success of deep learning methods, recent work on SISR focuses solutions with deep learning methodologies and achieves state-of-the-art results. However most of the state-of-the-art SISR methods contain millions of parameters and layers, which limits their practical applications. In this paper, we propose a hardware (Synaptics Dolphin NPU) limitation aware, extremely lightweight quantization robust real-time super resolution network (XLSR). The proposed model's building block is inspired from root modules for Image classification. We successfully applied root modules to SISR problem, further more to make the model uint8 quantization robust we used Clipped ReLU at the last layer of the network and achieved great balance between reconstruction quality and runtime. Furthermore, although the proposed network contains 30x fewer parameters than VDSR its performance surpasses it on Div2K validation set. The network proved itself by winning Mobile AI 2021 Real-Time Single Image Super Resolution Challenge.
On the Performance of Machine Learning Methods for Breakthrough Curve Prediction
Apr 25, 2022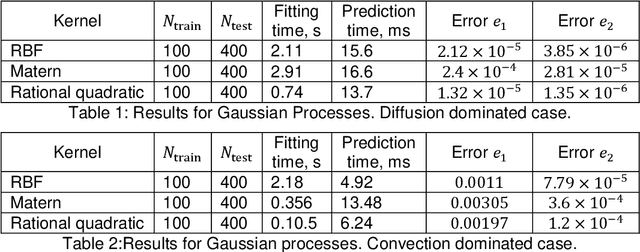
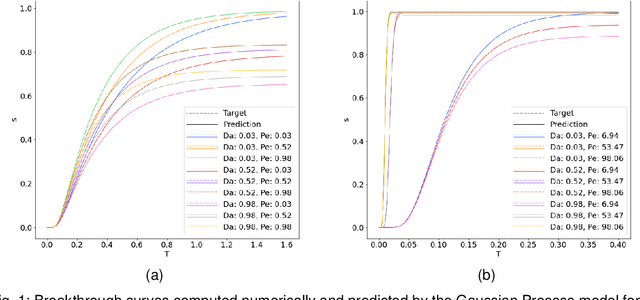
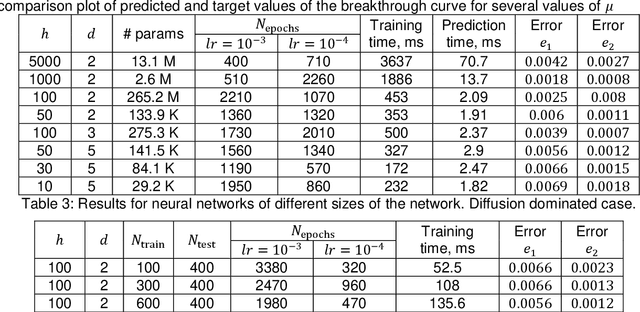
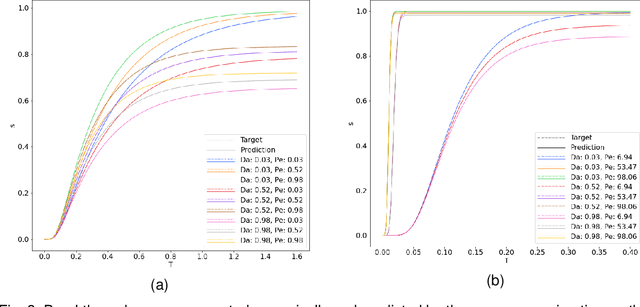
Reactive flows are important part of numerous technical and environmental processes. Often monitoring the flow and species concentrations within the domain is not possible or is expensive, in contrast, outlet concentration is straightforward to measure. In connection with reactive flows in porous media, the term breakthrough curve is used to denote the time dependency of the outlet concentration with prescribed conditions at the inlet. In this work we apply several machine learning methods to predict breakthrough curves from the given set of parameters. In our case the parameters are the Damk\"ohler and Peclet numbers. We perform a thorough analysis for the one-dimensional case and also provide the results for the three-dimensional case.
On Learning Mixture of Linear Regressions in the Non-Realizable Setting
May 26, 2022
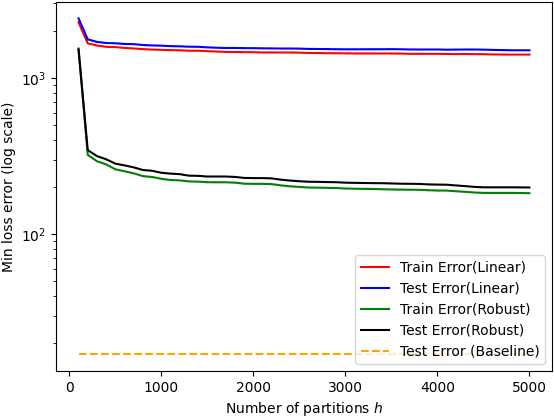


While mixture of linear regressions (MLR) is a well-studied topic, prior works usually do not analyze such models for prediction error. In fact, {\em prediction} and {\em loss} are not well-defined in the context of mixtures. In this paper, first we show that MLR can be used for prediction where instead of predicting a label, the model predicts a list of values (also known as {\em list-decoding}). The list size is equal to the number of components in the mixture, and the loss function is defined to be minimum among the losses resulted by all the component models. We show that with this definition, a solution of the empirical risk minimization (ERM) achieves small probability of prediction error. This begs for an algorithm to minimize the empirical risk for MLR, which is known to be computationally hard. Prior algorithmic works in MLR focus on the {\em realizable} setting, i.e., recovery of parameters when data is probabilistically generated by a mixed linear (noisy) model. In this paper we show that a version of the popular alternating minimization (AM) algorithm finds the best fit lines in a dataset even when a realizable model is not assumed, under some regularity conditions on the dataset and the initial points, and thereby provides a solution for the ERM. We further provide an algorithm that runs in polynomial time in the number of datapoints, and recovers a good approximation of the best fit lines. The two algorithms are experimentally compared.
Data-Driven Approximations of Chance Constrained Programs in Nonstationary Environments
May 08, 2022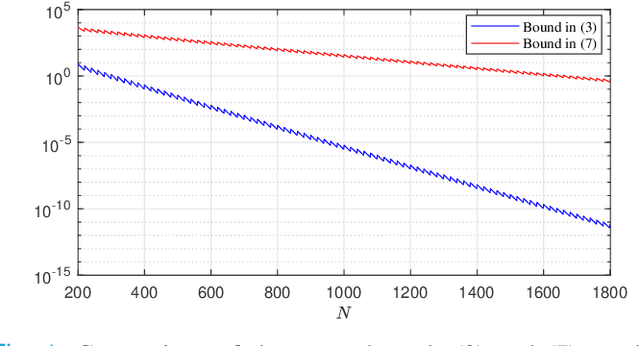
We study sample average approximations (SAA) of chance constrained programs. SAA methods typically approximate the actual distribution in the chance constraint using an empirical distribution constructed from random samples assumed to be independent and identically distributed according to the actual distribution. In this paper, we consider a nonstationary variant of this problem, where the random samples are assumed to be independently drawn in a sequential fashion from an unknown and possibly time-varying distribution. This nonstationarity may be driven by changing environmental conditions present in many real-world applications. To account for the potential nonstationarity in the data generation process, we propose a novel robust SAA method exploiting information about the Wasserstein distance between the sequence of data-generating distributions and the actual chance constraint distribution. As a key result, we obtain distribution-free estimates of the sample size required to ensure that the robust SAA method will yield solutions that are feasible for the chance constraint under the actual distribution with high confidence.
An End-to-End Integrated Computation and Communication Architecture for Goal-oriented Networking: A Perspective on Live Surveillance Video
Apr 05, 2022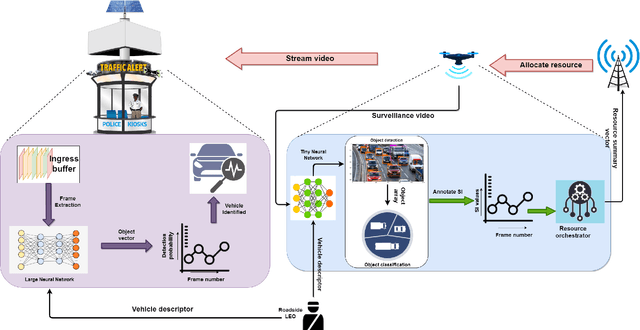
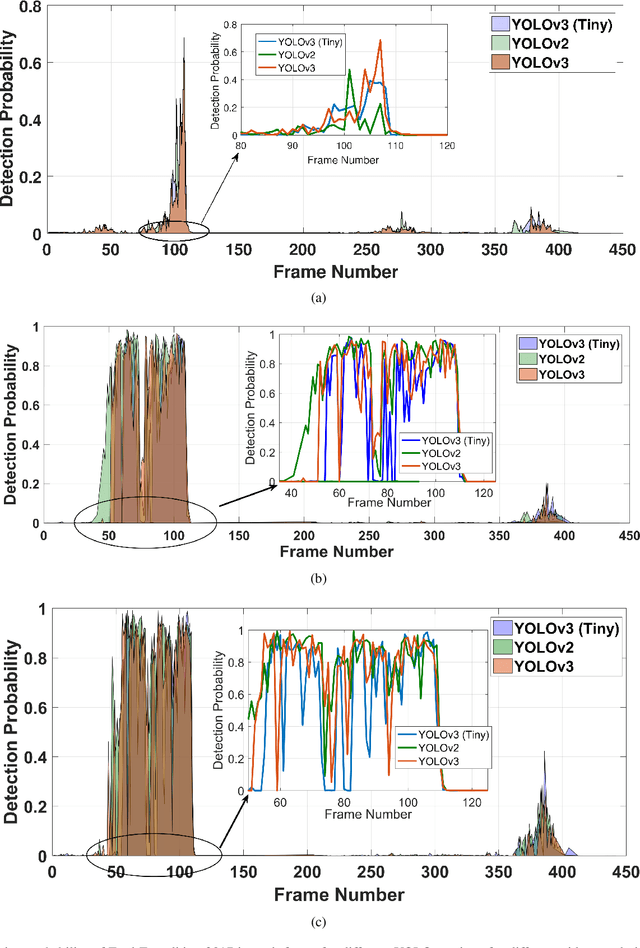
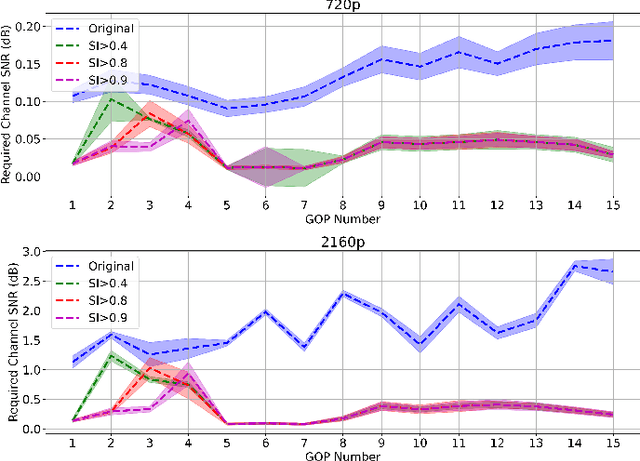
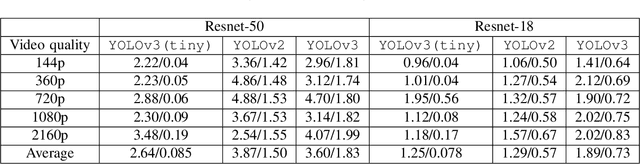
Real-time video surveillance has become a crucial technology for smart cities, made possible through the large-scale deployment of mobile and fixed video cameras. In this paper, we propose situation-aware streaming, for real-time identification of important events from live-feeds at the source rather than a cloud based analysis. For this, we first identify the frames containing a specific situation and assign them a high scale-of-importance (SI). The identification is made at the source using a tiny neural network (having a small number of hidden layers), which incurs a small computational resource, albeit at the cost of accuracy. The frames with a high SI value are then streamed with a certain required Signal-to-Noise-Ratio (SNR) to retain the frame quality, while the remaining ones are transmitted with a small SNR. The received frames are then analyzed using a deep neural network (with many hidden layers) to extract the situation accurately. We show that the proposed scheme is able to reduce the required power consumption of the transmitter by 38.5% for 2160p (UHD) video, while achieving a classification accuracy of 97.5%, for the given situation.
Hippocluster: an efficient, hippocampus-inspired algorithm for graph clustering
May 19, 2022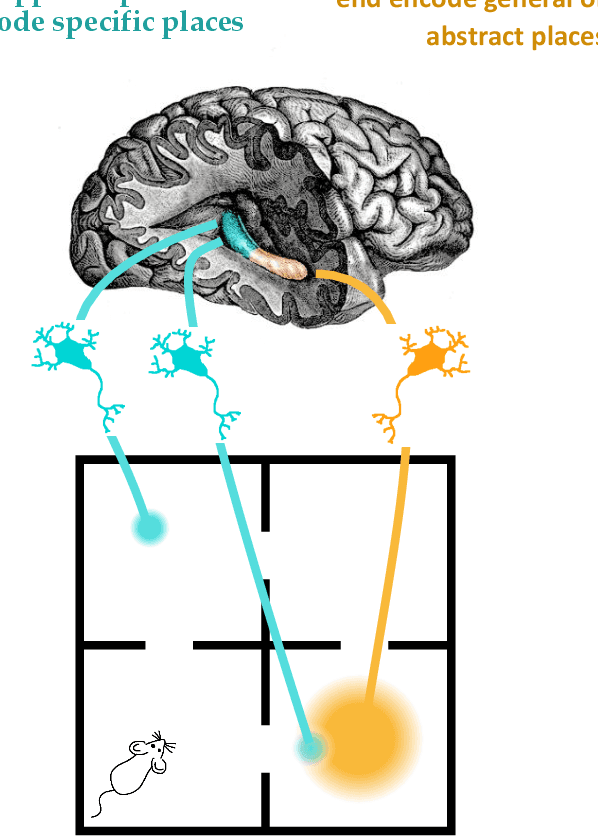
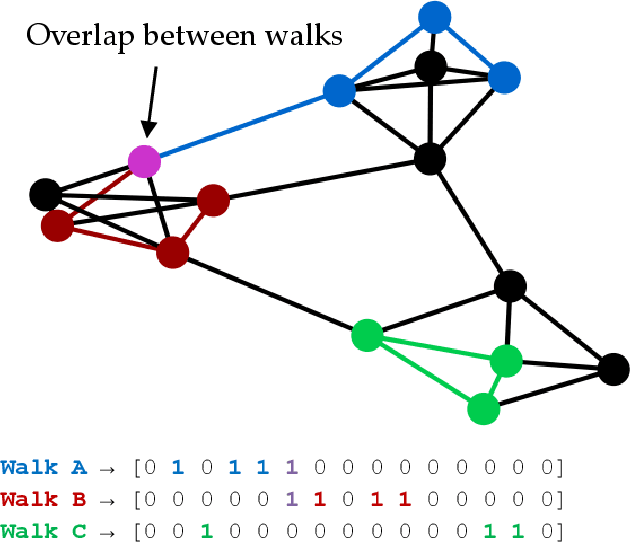
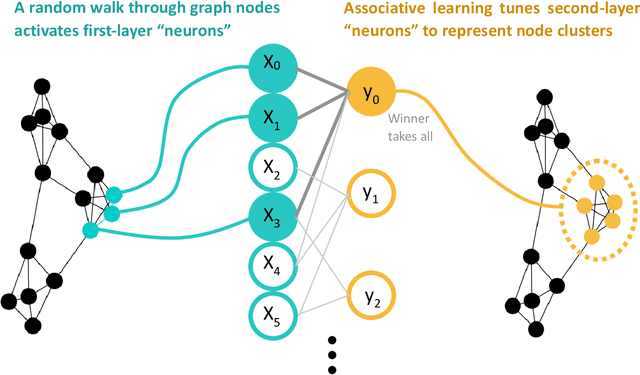
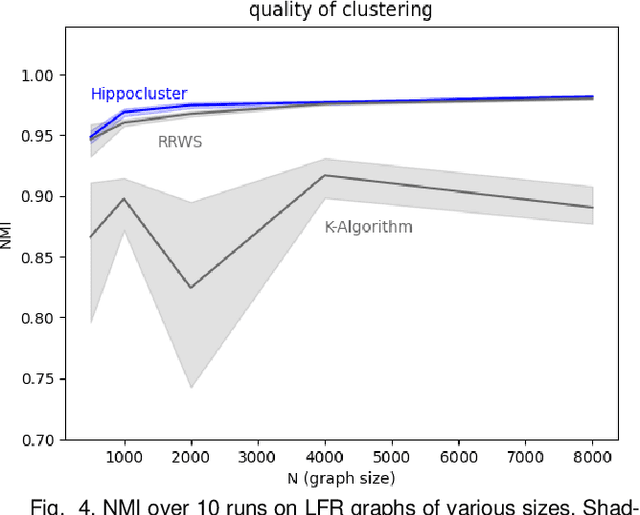
Random walks can reveal communities or clusters in networks, because they are more likely to stay within a cluster than leave it. Thus, one family of community detection algorithms uses random walks to measure distance between pairs of nodes in various ways, and then applies K-Means or other generic clustering methods to these distances. Interestingly, information processing in the brain may suggest a simpler method of learning clusters directly from random walks. Drawing inspiration from the hippocampus, we describe a simple two-layer neural learning framework. Neurons in one layer are associated with graph nodes and simulate random walks. These simulations cause neurons in the second layer to become tuned to graph clusters through simple associative learning. We show that if these neuronal interactions are modelled a particular way, the system is essentially a variant of K-Means clustering applied directly in the walk-space, bypassing the usual step of computing node distances/similarities. The result is an efficient graph clustering method. Biological information processing systems are known for high efficiency and adaptability. In tests on benchmark graphs, our framework demonstrates this high data-efficiency, low memory use, low complexity, and real-time adaptation to graph changes, while still achieving clustering quality comparable to other algorithms.
Inferring 3D change detection from bitemporal optical images
May 31, 2022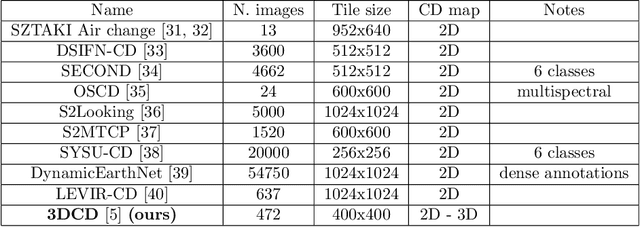
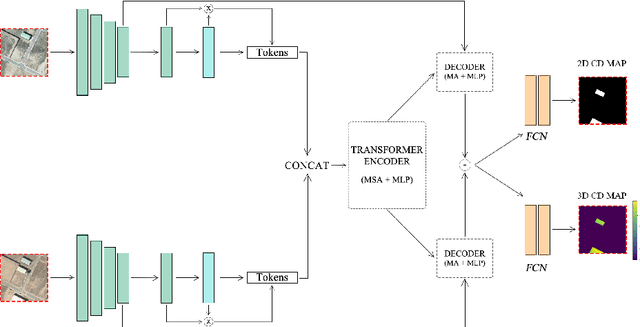
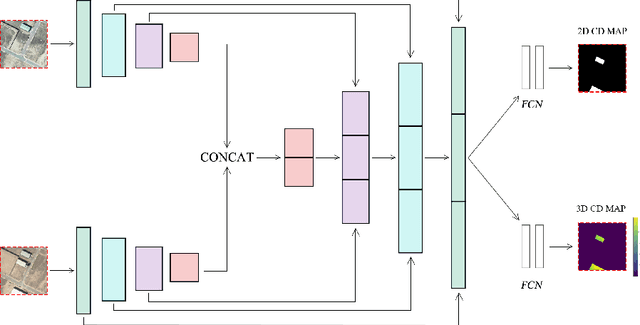
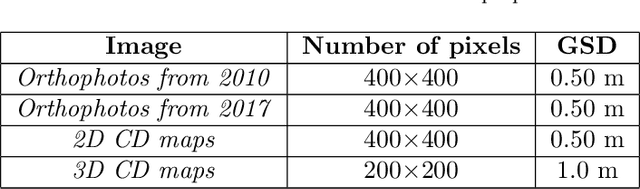
Change detection is one of the most active research areas in Remote Sensing (RS). Most of the recently developed change detection methods are based on deep learning (DL) algorithms. This kind of algorithms is generally focused on generating two-dimensional (2D) change maps, thus only identifying planimetric changes in land use/land cover (LULC) and not considering nor returning any information on the corresponding elevation changes. Our work goes one step further, proposing two novel networks, able to solve simultaneously the 2D and 3D CD tasks, and the 3DCD dataset, a novel and freely available dataset precisely designed for this multitask. Particularly, the aim of this work is to lay the foundations for the development of DL algorithms able to automatically infer an elevation (3D) CD map -- together with a standard 2D CD map --, starting only from a pair of bitemporal optical images. The proposed architectures, to perform the task described before, consist of a transformer-based network, the MultiTask Bitemporal Images Transformer (MTBIT), and a deep convolutional network, the Siamese ResUNet (SUNet). Particularly, MTBIT is a transformer-based architecture, based on a semantic tokenizer. SUNet instead combines, in a siamese encoder, skip connections and residual layers to learn rich features, capable to solve efficiently the proposed task. These models are, thus, able to obtain 3D CD maps from two optical images taken at different time instants, without the need to rely directly on elevation data during the inference step. Encouraging results, obtained on the novel 3DCD dataset, are shown. The code and the 3DCD dataset are available at \url{https://sites.google.com/uniroma1.it/3dchangedetection/home-page}.