 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep Learning Techniques for Visual Counting
Jun 08, 2022

In this dissertation, we investigated and enhanced Deep Learning (DL) techniques for counting objects, like pedestrians, cells or vehicles, in still images or video frames. In particular, we tackled the challenge related to the lack of data needed for training current DL-based solutions. Given that the budget for labeling is limited, data scarcity still represents an open problem that prevents the scalability of existing solutions based on the supervised learning of neural networks and that is responsible for a significant drop in performance at inference time when new scenarios are presented to these algorithms. We introduced solutions addressing this issue from several complementary sides, collecting datasets gathered from virtual environments automatically labeled, proposing Domain Adaptation strategies aiming at mitigating the domain gap existing between the training and test data distributions, and presenting a counting strategy in a weakly labeled data scenario, i.e., in the presence of non-negligible disagreement between multiple annotators. Moreover, we tackled the non-trivial engineering challenges coming out of the adoption of Convolutional Neural Network-based techniques in environments with limited power resources, introducing solutions for counting vehicles and pedestrians directly onboard embedded vision systems, i.e., devices equipped with constrained computational capabilities that can capture images and elaborate them.
SDF-based RGB-D Camera Tracking in Neural Scene Representations
May 04, 2022

We consider the problem of tracking the 6D pose of a moving RGB-D camera in a neural scene representation. Different such representations have recently emerged, and we investigate the suitability of them for the task of camera tracking. In particular, we propose to track an RGB-D camera using a signed distance field-based representation and show that compared to density-based representations, tracking can be sped up, which enables more robust and accurate pose estimates when computation time is limited.
A Fingerprint Detection Method by Fingerprint Ridge Orientation Check
May 06, 2022

Fingerprints are popular among the biometric based systems due to ease of acquisition, uniqueness and availability. Nowadays it is used in smart phone security, digital payment and digital locker. Fingerprint recognition technology has been studied for a long time, and its recognition rate has recently risen to a high level. In particular, with the introduction of Deep Neural Network technologies, the recognition rate that could not be reached before was reached. In this paper, we propose a fingerprint detection algorithm used in a fingerprint recognition system.
Deep Learning Neural Networks for Emotion Classification from Text: Enhanced Leaky Rectified Linear Unit Activation and Weighted Loss
Mar 04, 2022
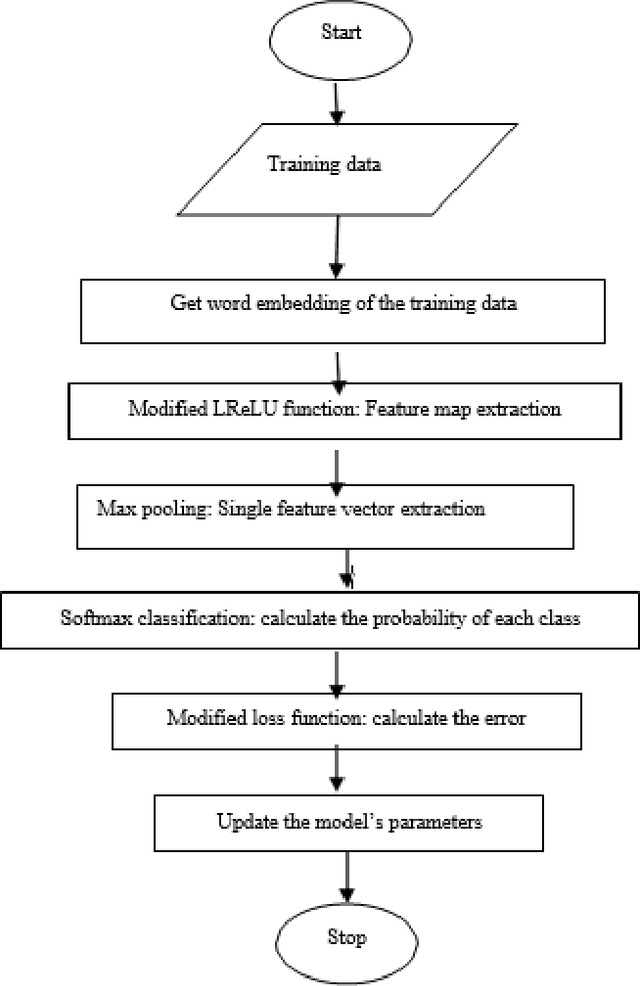
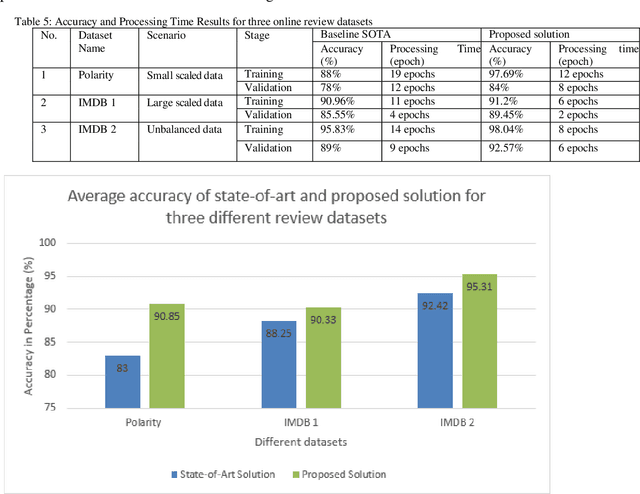
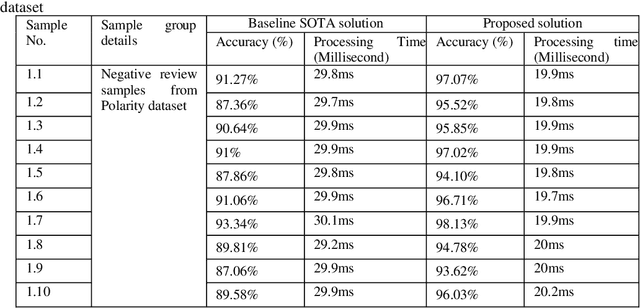
Accurate emotion classification for online reviews is vital for business organizations to gain deeper insights into markets. Although deep learning has been successfully implemented in this area, accuracy and processing time are still major problems preventing it from reaching its full potential. This paper proposes an Enhanced Leaky Rectified Linear Unit activation and Weighted Loss (ELReLUWL) algorithm for enhanced text emotion classification and faster parameter convergence speed. This algorithm includes the definition of the inflection point and the slope for inputs on the left side of the inflection point to avoid gradient saturation. It also considers the weight of samples belonging to each class to compensate for the influence of data imbalance. Convolutional Neural Network (CNN) combined with the proposed algorithm to increase the classification accuracy and decrease the processing time by eliminating the gradient saturation problem and minimizing the negative effect of data imbalance, demonstrated on a binary sentiment problem. The results show that the proposed solution achieves better classification performance in different data scenarios and different review types. The proposed model takes less convergence time to achieve model optimization with seven epochs against the current convergence time of 11.5 epochs on average. The proposed solution improves accuracy and reduces the processing time of text emotion classification. The solution provides an average class accuracy of 96.63% against a current average accuracy of 91.56%. It also provides a processing time of 23.3 milliseconds compared to the current average processing time of 33.2 milliseconds. Finally, this study solves the issues of gradient saturation and data imbalance. It enhances overall average class accuracy and decreases processing time.
* 28 pages
Graph Signal Sampling Under Stochastic Priors
Jun 01, 2022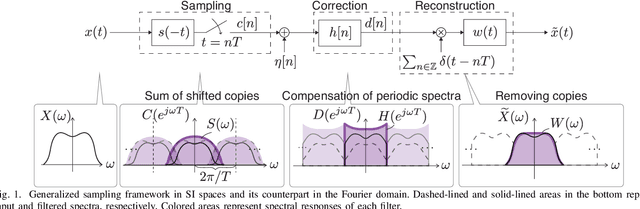
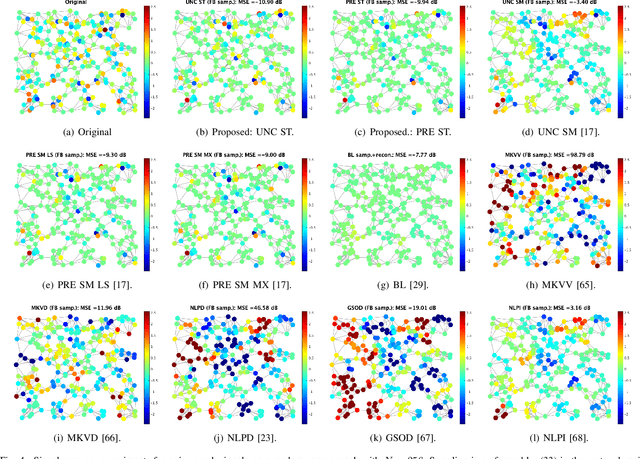
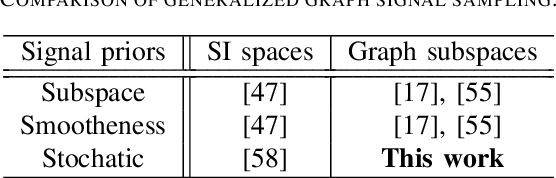
We propose a generalized sampling framework for stochastic graph signals. Stochastic graph signals are characterized by graph wide sense stationarity (GWSS) which is an extension of wide sense stationarity (WSS) for standard time-domain signals. In this paper, graph signals are assumed to satisfy the GWSS conditions and we study their sampling as well as recovery procedures. In generalized sampling, a correction filter is inserted between sampling and reconstruction operators to compensate for non-ideal measurements. We propose a design method for the correction filters to reduce the mean-squared error (MSE) between original and reconstructed graph signals. We derive the correction filters for two cases: The reconstruction filter is arbitrarily chosen or predefined. The proposed framework allows for arbitrary sampling methods, i.e., sampling in the vertex or graph frequency domain. We also show that the graph spectral response of the resulting correction filter parallels that for generalized sampling for WSS signals if sampling is performed in the graph frequency domain. The effectiveness of our approach is validated via experiments by comparing its MSE with existing approaches.
Spiking-GAN: A Spiking Generative Adversarial Network Using Time-To-First-Spike Coding
Jun 29, 2021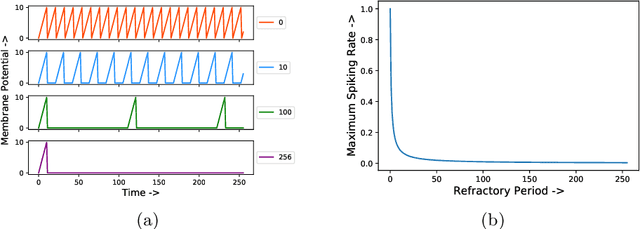
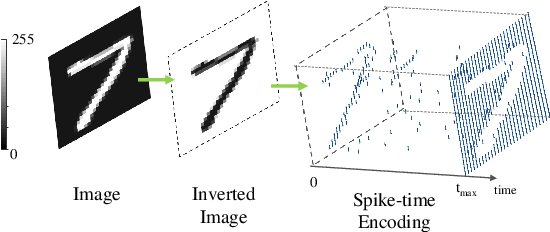
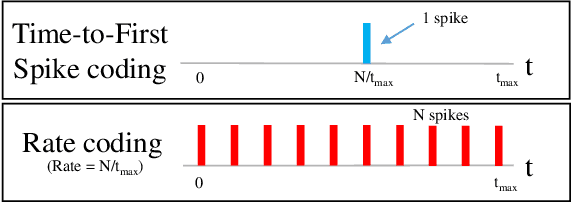
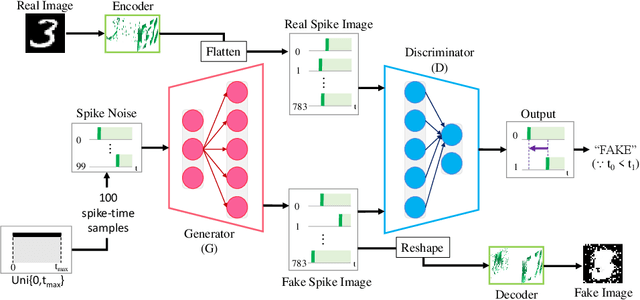
Spiking Neural Networks (SNNs) have shown great potential in solving deep learning problems in an energy-efficient manner. However, they are still limited to simple classification tasks. In this paper, we propose Spiking-GAN, the first spike-based Generative Adversarial Network (GAN). It employs a kind of temporal coding scheme called time-to-first-spike coding. We train it using approximate backpropagation in the temporal domain. We use simple integrate-and-fire (IF) neurons with very high refractory period for our network which ensures a maximum of one spike per neuron. This makes the model much sparser than a spike rate-based system. Our modified temporal loss function called 'Aggressive TTFS' improves the inference time of the network by over 33% and reduces the number of spikes in the network by more than 11% compared to previous works. Our experiments show that on training the network on the MNIST dataset using this approach, we can generate high quality samples. Thereby demonstrating the potential of this framework for solving such problems in the spiking domain.
Towards Understanding the Impact of Real-Time AI-Powered Educational Dashboards (RAED) on Providing Guidance to Instructors
Jul 30, 2021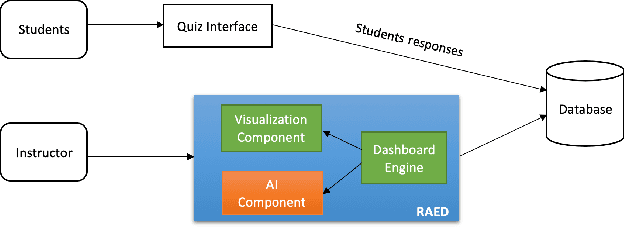
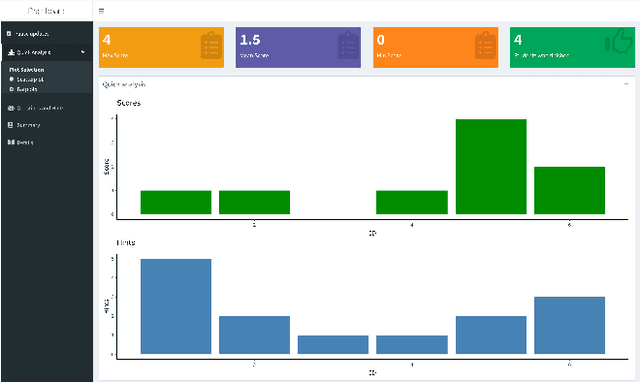
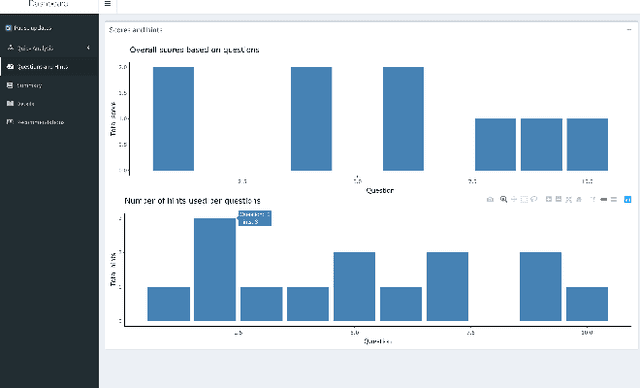
The objectives of this ongoing research are to build Real-Time AI-Powered Educational Dashboard (RAED) as a decision support tool for instructors, and to measure its impact on them while making decisions. Current developments in AI can be combined with the educational dashboards to make them AI-Powered. Thus, AI can help in providing recommendations based on the students' performances. AI-Powered educational dashboards can also assist instructors in tracking real-time student activities. In this ongoing research, our aim is to develop the AI component as well as improve the existing design component of the RAED. Further, we will conduct experiments to study its impact on instructors, and understand how much they trust RAED to guide them while making decisions. This paper elaborates on the ongoing research and future direction.
DeeptDCS: Deep Learning-Based Estimation of Currents Induced During Transcranial Direct Current Stimulation
May 04, 2022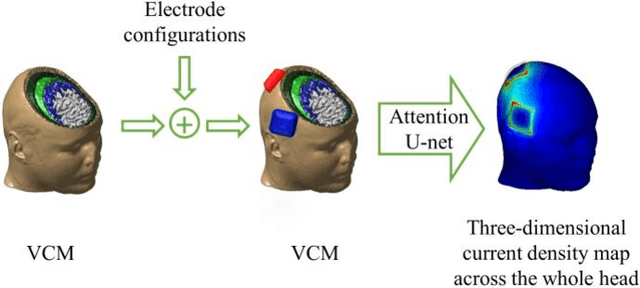
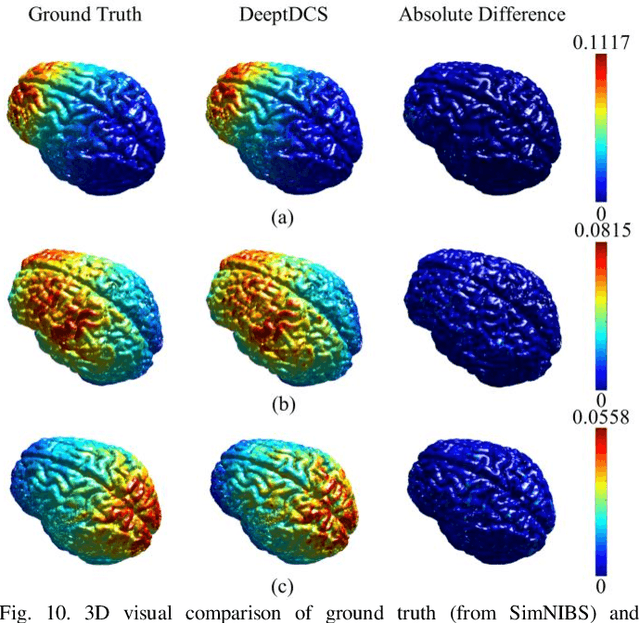
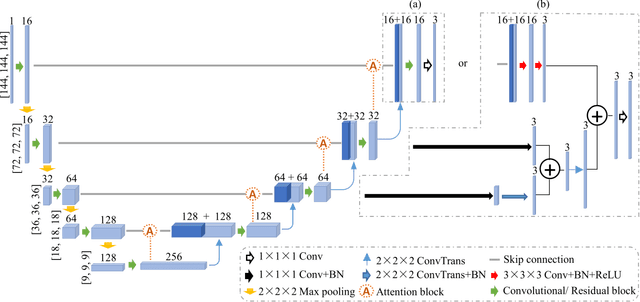
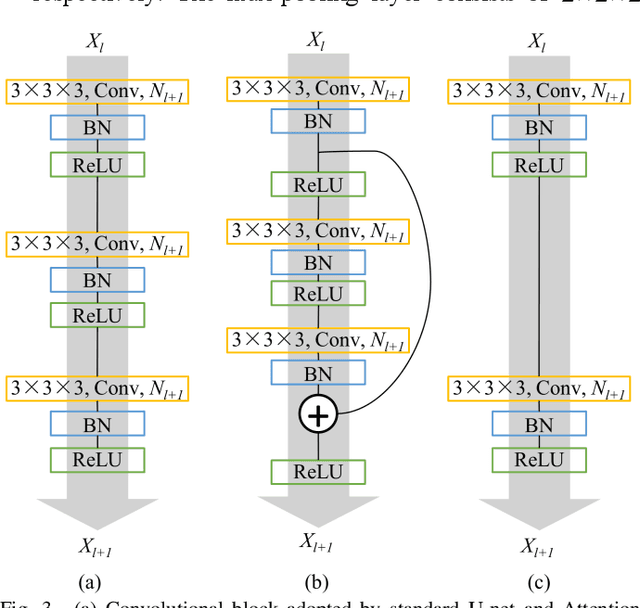
Objective: Transcranial direct current stimulation (tDCS) is a non-invasive brain stimulation technique used to generate conduction currents in the head and disrupt brain functions. To rapidly evaluate the tDCS-induced current density in near real-time, this paper proposes a deep learning-based emulator, named DeeptDCS. Methods: The emulator leverages Attention U-net taking the volume conductor models (VCMs) of head tissues as inputs and outputting the three-dimensional current density distribution across the entire head. The electrode configurations are also incorporated into VCMs without increasing the number of input channels; this enables the straightforward incorporation of the non-parametric features of electrodes (e.g., thickness, shape, size, and position) in the training and testing of the proposed emulator. Results: Attention U-net outperforms standard U-net and its other three variants (Residual U-net, Attention Residual U-net, and Multi-scale Residual U-net) in terms of accuracy. The generalization ability of DeeptDCS to non-trained electrode positions can be greatly enhanced through fine-tuning the model. The computational time required by one emulation via DeeptDCS is a fraction of a second. Conclusion: DeeptDCS is at least two orders of magnitudes faster than a physics-based open-source simulator, while providing satisfactorily accurate results. Significance: The high computational efficiency permits the use of DeeptDCS in applications requiring its repetitive execution, such as uncertainty quantification and optimization studies of tDCS.
Representation Learning in Continuous-Time Score-Based Generative Models
May 29, 2021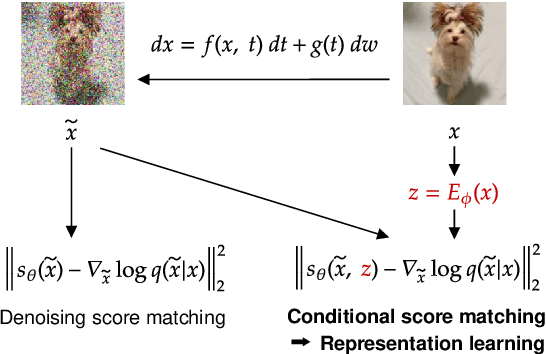
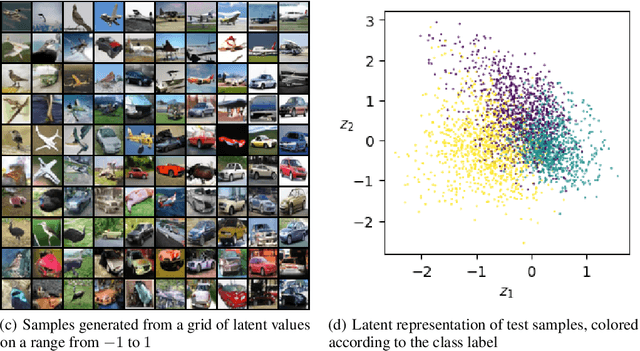
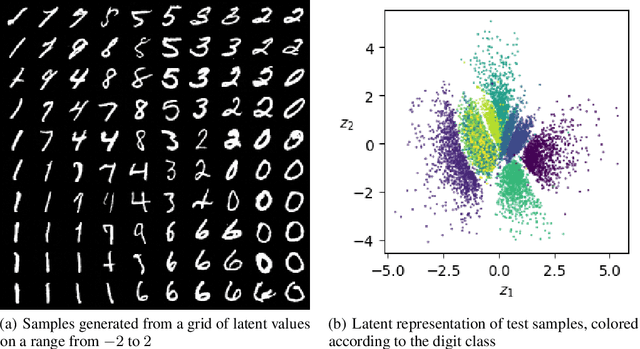
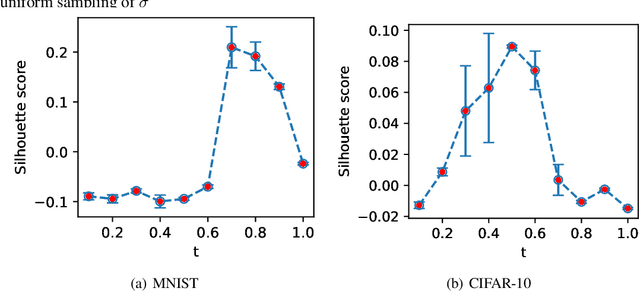
Score-based methods represented as stochastic differential equations on a continuous time domain have recently proven successful as a non-adversarial generative model. Training such models relies on denoising score matching, which can be seen as multi-scale denoising autoencoders. Here, we augment the denoising score-matching framework to enable representation learning without any supervised signal. GANs and VAEs learn representations by directly transforming latent codes to data samples. In contrast, score-based representation learning relies on a new formulation of the denoising score-matching objective and thus encodes information needed for denoising. We show how this difference allows for manual control of the level of detail encoded in the representation.
Towards a Defense against Backdoor Attacks in Continual Federated Learning
May 28, 2022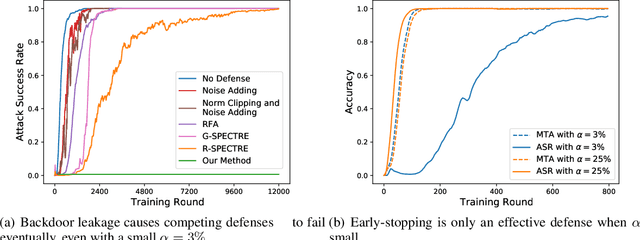

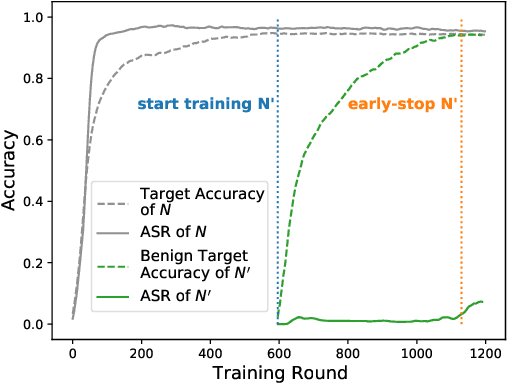

Backdoor attacks are a major concern in federated learning (FL) pipelines where training data is sourced from untrusted clients over long periods of time (i.e., continual learning). Preventing such attacks is difficult because defenders in FL do not have access to raw training data. Moreover, in a phenomenon we call backdoor leakage, models trained continuously eventually suffer from backdoors due to cumulative errors in backdoor defense mechanisms. We propose a novel framework for defending against backdoor attacks in the federated continual learning setting. Our framework trains two models in parallel: a backbone model and a shadow model. The backbone is trained without any defense mechanism to obtain good performance on the main task. The shadow model combines recent ideas from robust covariance estimation-based filters with early-stopping to control the attack success rate even as the data distribution changes. We provide theoretical motivation for this design and show experimentally that our framework significantly improves upon existing defenses against backdoor attacks.