 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Visual Comparison of Language Model Adaptation
Aug 17, 2022
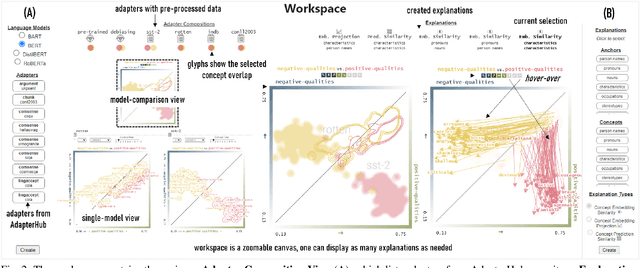
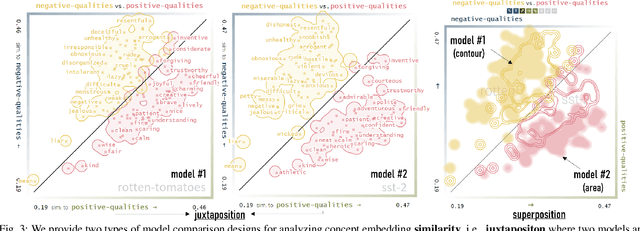
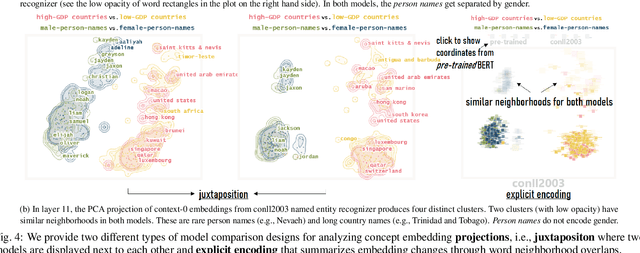
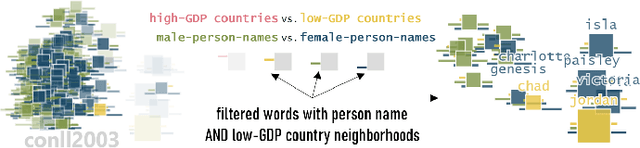
Neural language models are widely used; however, their model parameters often need to be adapted to the specific domains and tasks of an application, which is time- and resource-consuming. Thus, adapters have recently been introduced as a lightweight alternative for model adaptation. They consist of a small set of task-specific parameters with a reduced training time and simple parameter composition. The simplicity of adapter training and composition comes along with new challenges, such as maintaining an overview of adapter properties and effectively comparing their produced embedding spaces. To help developers overcome these challenges, we provide a twofold contribution. First, in close collaboration with NLP researchers, we conducted a requirement analysis for an approach supporting adapter evaluation and detected, among others, the need for both intrinsic (i.e., embedding similarity-based) and extrinsic (i.e., prediction-based) explanation methods. Second, motivated by the gathered requirements, we designed a flexible visual analytics workspace that enables the comparison of adapter properties. In this paper, we discuss several design iterations and alternatives for interactive, comparative visual explanation methods. Our comparative visualizations show the differences in the adapted embedding vectors and prediction outcomes for diverse human-interpretable concepts (e.g., person names, human qualities). We evaluate our workspace through case studies and show that, for instance, an adapter trained on the language debiasing task according to context-0 (decontextualized) embeddings introduces a new type of bias where words (even gender-independent words such as countries) become more similar to female than male pronouns. We demonstrate that these are artifacts of context-0 embeddings.
Automatic Identification of Coal and Rock/Gangue Based on DenseNet and Gaussian Process
Aug 31, 2022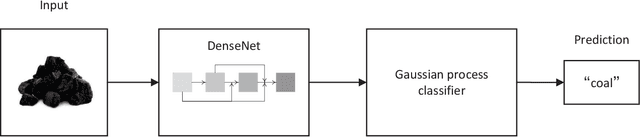
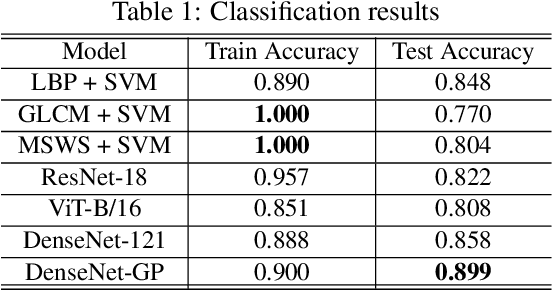

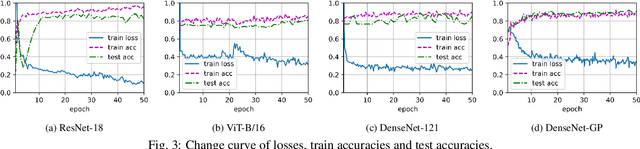
To improve the purity of coal and prevent damage to the coal mining machine, it is necessary to identify coal and rock in underground coal mines. At the same time, the mined coal needs to be purified to remove rock and gangue. These two procedures are manually operated by workers in most coal mines. The realization of automatic identification and purification is not only conducive to the automation of coal mines, but also ensures the safety of workers. We discuss the possibility of using image-based methods to distinguish them. In order to find a solution that can be used in both scenarios, a model that forwards image feature extracted by DenseNet to Gaussian process is proposed, which is trained on images taken on surface and achieves high accuracy on images taken underground. This indicates our method is powerful in few-shot learning such as identification of coal and rock/gangue and might be beneficial for realizing automation in coal mines.
Fuse: In-Situ Sensemaking Support in the Browser
Aug 31, 2022

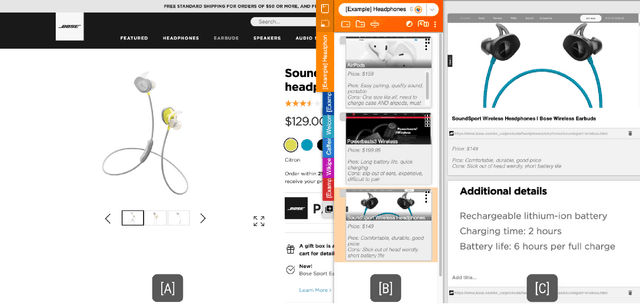
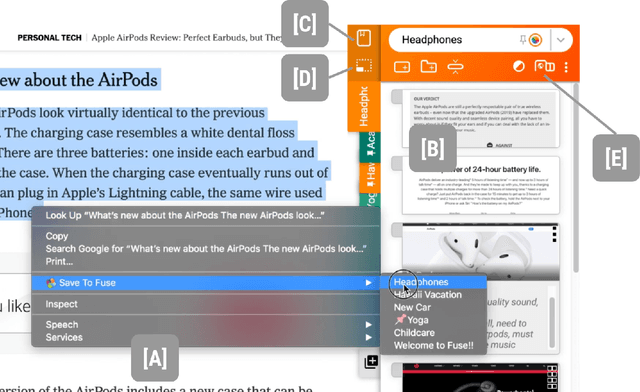
People spend a significant amount of time trying to make sense of the internet, collecting content from a variety of sources and organizing it to make decisions and achieve their goals. While humans are able to fluidly iterate on collecting and organizing information in their minds, existing tools and approaches introduce significant friction into the process. We introduce Fuse, a browser extension that externalizes users' working memory by combining low-cost collection with lightweight organization of content in a compact card-based sidebar that is always available. Fuse helps users simultaneously extract key web content and structure it in a lightweight and visual way. We discuss how these affordances help users externalize more of their mental model into the system (e.g., saving, annotating, and structuring items) and support fast reviewing and resumption of task contexts. Our 22-month public deployment and follow-up interviews provide longitudinal insights into the structuring behaviors of real-world users conducting information foraging tasks.
Deep Probabilistic Models for Forward and Inverse Problems in Parametric PDEs
Aug 09, 2022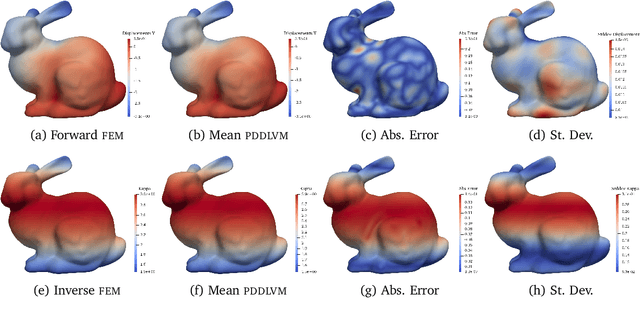
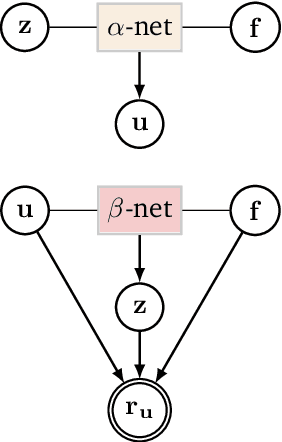


We formulate a class of physics-driven deep latent variable models (PDDLVM) to learn parameter-to-solution (forward) and solution-to-parameter (inverse) maps of parametric partial differential equations (PDEs). Our formulation leverages the finite element method (FEM), deep neural networks, and probabilistic modeling to assemble a deep probabilistic framework in which the forward and inverse maps are approximated with coherent uncertainty quantification. Our probabilistic model explicitly incorporates a parametric PDE-based density and a trainable solution-to-parameter network while the introduced amortized variational family postulates a parameter-to-solution network, all of which are jointly trained. Furthermore, the proposed methodology does not require any expensive PDE solves and is physics-informed only at training time, which allows real-time emulation of PDEs and generation of inverse problem solutions after training, bypassing the need for FEM solve operations with comparable accuracy to FEM solutions. The proposed framework further allows for a seamless integration of observed data for solving inverse problems and building generative models. We demonstrate the effectiveness of our method on a nonlinear Poisson problem, elastic shells with complex 3D geometries, and integrating generic physics-informed neural networks (PINN) architectures. We achieve up to three orders of magnitude speed-ups after training compared to traditional FEM solvers, while outputting coherent uncertainty estimates.
WATCH: Wasserstein Change Point Detection for High-Dimensional Time Series Data
Jan 18, 2022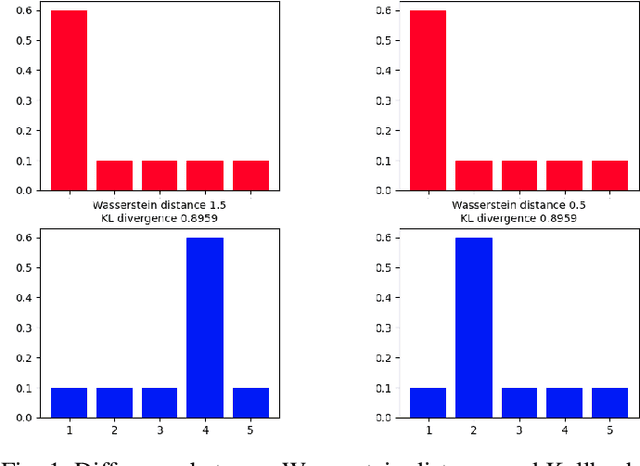
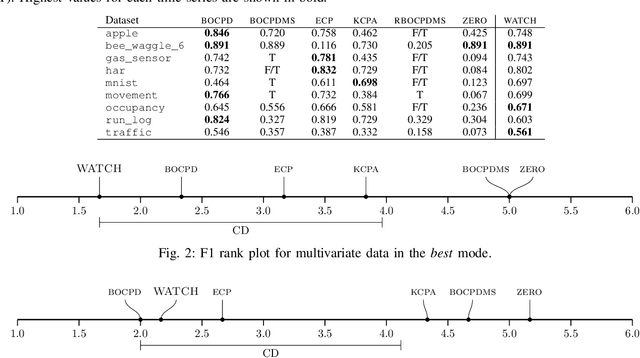


Detecting relevant changes in dynamic time series data in a timely manner is crucially important for many data analysis tasks in real-world settings. Change point detection methods have the ability to discover changes in an unsupervised fashion, which represents a desirable property in the analysis of unbounded and unlabeled data streams. However, one limitation of most of the existing approaches is represented by their limited ability to handle multivariate and high-dimensional data, which is frequently observed in modern applications such as traffic flow prediction, human activity recognition, and smart grids monitoring. In this paper, we attempt to fill this gap by proposing WATCH, a novel Wasserstein distance-based change point detection approach that models an initial distribution and monitors its behavior while processing new data points, providing accurate and robust detection of change points in dynamic high-dimensional data. An extensive experimental evaluation involving a large number of benchmark datasets shows that WATCH is capable of accurately identifying change points and outperforming state-of-the-art methods.
Generalisability of deep learning models in low-resource imaging settings: A fetal ultrasound study in 5 African countries
Sep 20, 2022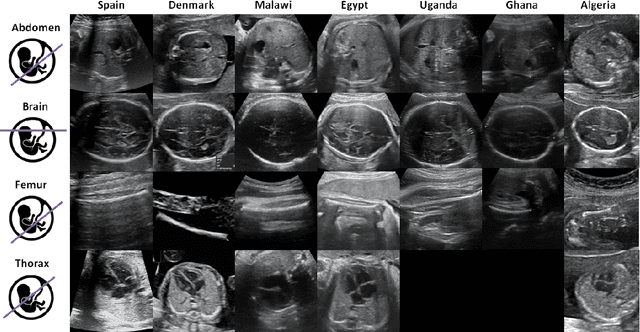
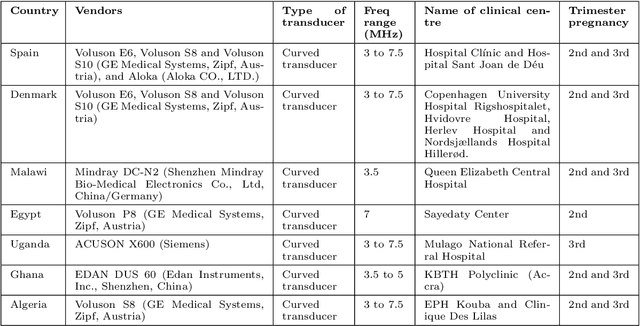
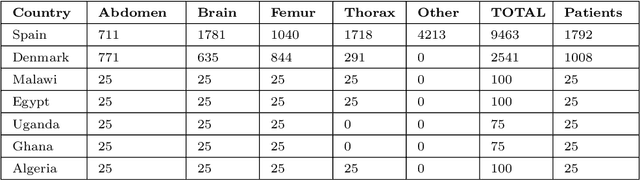
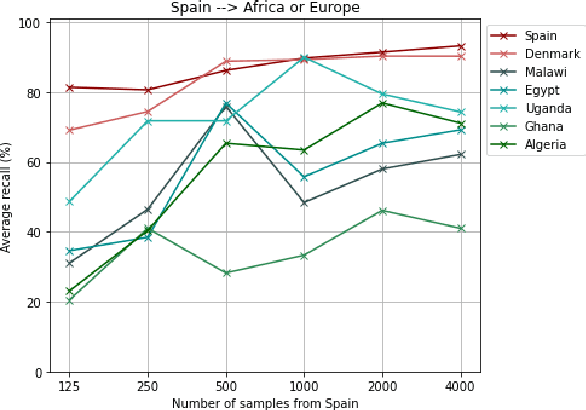
Most artificial intelligence (AI) research have concentrated in high-income countries, where imaging data, IT infrastructures and clinical expertise are plentiful. However, slower progress has been made in limited-resource environments where medical imaging is needed. For example, in Sub-Saharan Africa the rate of perinatal mortality is very high due to limited access to antenatal screening. In these countries, AI models could be implemented to help clinicians acquire fetal ultrasound planes for diagnosis of fetal abnormalities. So far, deep learning models have been proposed to identify standard fetal planes, but there is no evidence of their ability to generalise in centres with limited access to high-end ultrasound equipment and data. This work investigates different strategies to reduce the domain-shift effect for a fetal plane classification model trained on a high-resource clinical centre and transferred to a new low-resource centre. To that end, a classifier trained with 1,792 patients from Spain is first evaluated on a new centre in Denmark in optimal conditions with 1,008 patients and is later optimised to reach the same performance in five African centres (Egypt, Algeria, Uganda, Ghana and Malawi) with 25 patients each. The results show that a transfer learning approach can be a solution to integrate small-size African samples with existing large-scale databases in developed countries. In particular, the model can be re-aligned and optimised to boost the performance on African populations by increasing the recall to $0.92 \pm 0.04$ and at the same time maintaining a high precision across centres. This framework shows promise for building new AI models generalisable across clinical centres with limited data acquired in challenging and heterogeneous conditions and calls for further research to develop new solutions for usability of AI in countries with less resources.
Hardware Software Co-design of Statistical and Deep Learning Frameworks for Wideband Sensing on Zynq System on Chip
Sep 06, 2022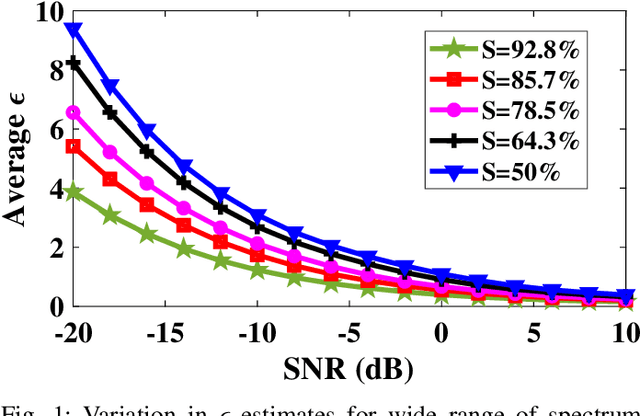
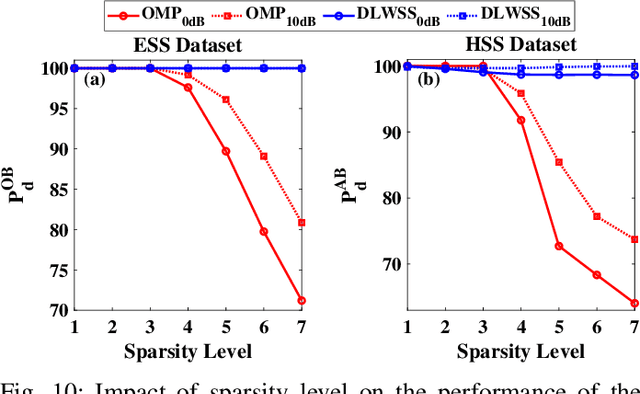
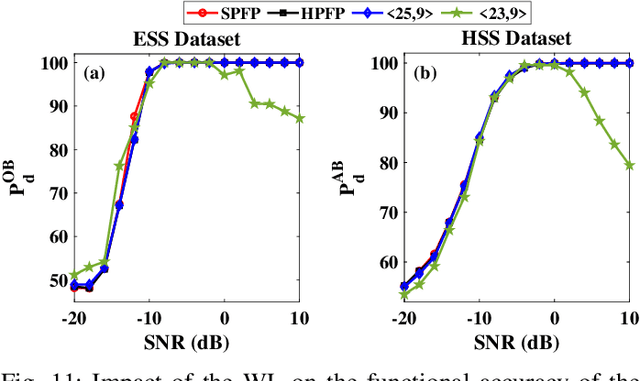
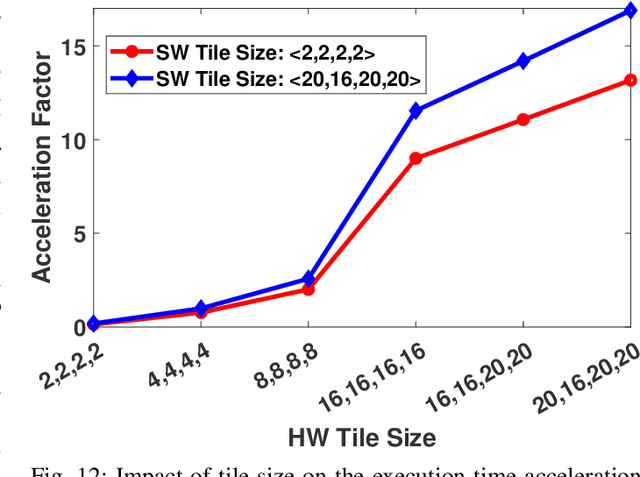
With the introduction of spectrum sharing and heterogeneous services in next-generation networks, the base stations need to sense the wideband spectrum and identify the spectrum resources to meet the quality-of-service, bandwidth, and latency constraints. Sub-Nyquist sampling (SNS) enables digitization for sparse wideband spectrum without needing Nyquist speed analog-to-digital converters. However, SNS demands additional signal processing algorithms for spectrum reconstruction, such as the well-known orthogonal matching pursuit (OMP) algorithm. OMP is also widely used in other compressed sensing applications. The first contribution of this work is efficiently mapping the OMP algorithm on the Zynq system-on-chip (ZSoC) consisting of an ARM processor and FPGA. Experimental analysis shows a significant degradation in OMP performance for sparse spectrum. Also, OMP needs prior knowledge of spectrum sparsity. We address these challenges via deep-learning-based architectures and efficiently map them on the ZSoC platform as second contribution. Via hardware-software co-design, different versions of the proposed architecture obtained by partitioning between software (ARM processor) and hardware (FPGA) are considered. The resource, power, and execution time comparisons for given memory constraints and a wide range of word lengths are presented for these architectures.
Learning Mean-Field Control for Delayed Information Load Balancing in Large Queuing Systems
Aug 09, 2022
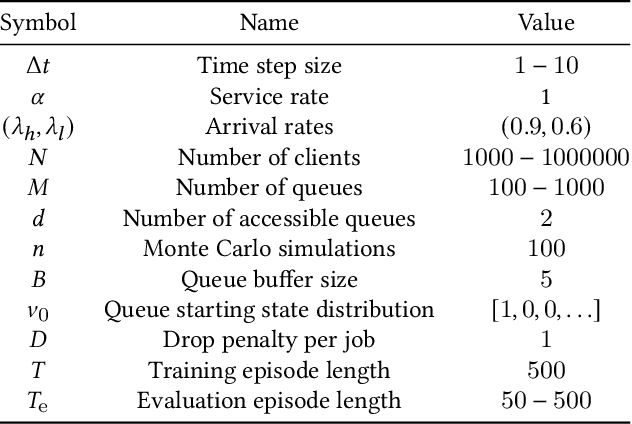
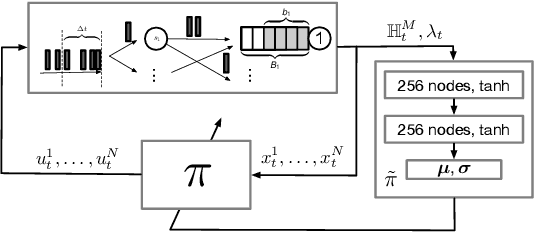
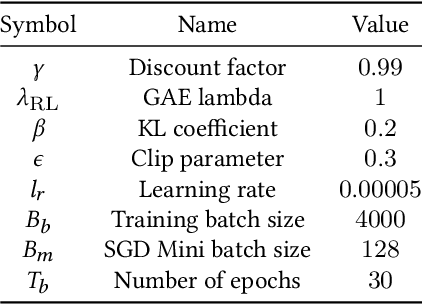
Recent years have seen a great increase in the capacity and parallel processing power of data centers and cloud services. To fully utilize the said distributed systems, optimal load balancing for parallel queuing architectures must be realized. Existing state-of-the-art solutions fail to consider the effect of communication delays on the behaviour of very large systems with many clients. In this work, we consider a multi-agent load balancing system, with delayed information, consisting of many clients (load balancers) and many parallel queues. In order to obtain a tractable solution, we model this system as a mean-field control problem with enlarged state-action space in discrete time through exact discretization. Subsequently, we apply policy gradient reinforcement learning algorithms to find an optimal load balancing solution. Here, the discrete-time system model incorporates a synchronization delay under which the queue state information is synchronously broadcasted and updated at all clients. We then provide theoretical performance guarantees for our methodology in large systems. Finally, using experiments, we prove that our approach is not only scalable but also shows good performance when compared to the state-of-the-art power-of-d variant of the Join-the-Shortest-Queue (JSQ) and other policies in the presence of synchronization delays.
FLInt: Exploiting Floating Point Enabled Integer Arithmetic for Efficient Random Forest Inference
Sep 09, 2022
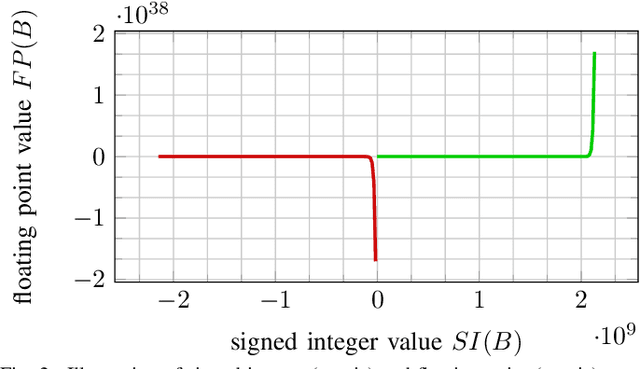
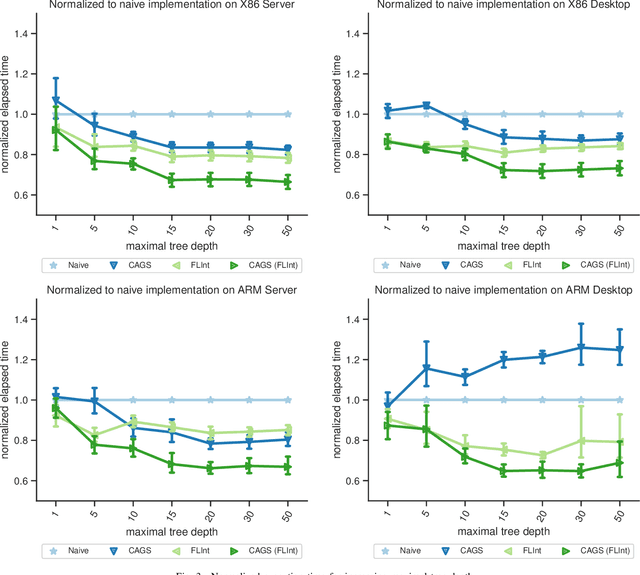
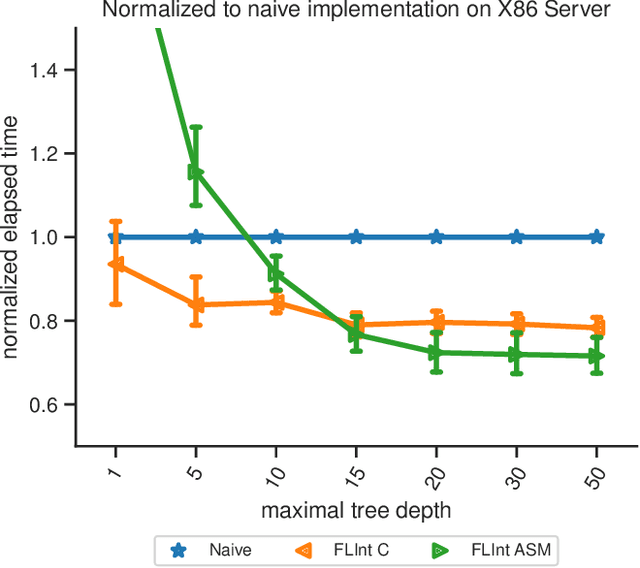
In many machine learning applications, e.g., tree-based ensembles, floating point numbers are extensively utilized due to their expressiveness. Nowadays performing data analysis on embedded devices from dynamic data masses becomes available, but such systems often lack hardware capabilities to process floating point numbers, introducing large overheads for their processing. Even if such hardware is present in general computing systems, using integer operations instead of floating point operations promises to reduce operation overheads and improve the performance. In this paper, we provide \mdname, a full precision floating point comparison for random forests, by only using integer and logic operations. To ensure the same functionality preserves, we formally prove the correctness of this comparison. Since random forests only require comparison of floating point numbers during inference, we implement \mdname~in low level realizations and therefore eliminate the need for floating point hardware entirely, by keeping the model accuracy unchanged. The usage of \mdname~basically boils down to a one-by-one replacement of conditions: For instance, a comparison statement in C: if(pX[3]<=(float)10.074347) becomes if((*(((int*)(pX))+3))<=((int)(0x41213087))). Experimental evaluation on X86 and ARMv8 desktop and server class systems shows that the execution time can be reduced by up to $\approx 30\%$ with our novel approach.
HRF-Net: Holistic Radiance Fields from Sparse Inputs
Aug 09, 2022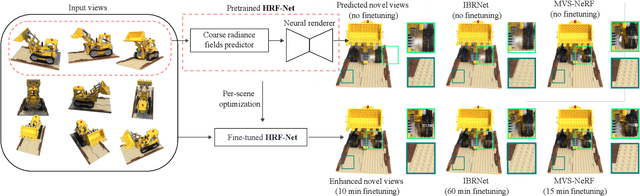
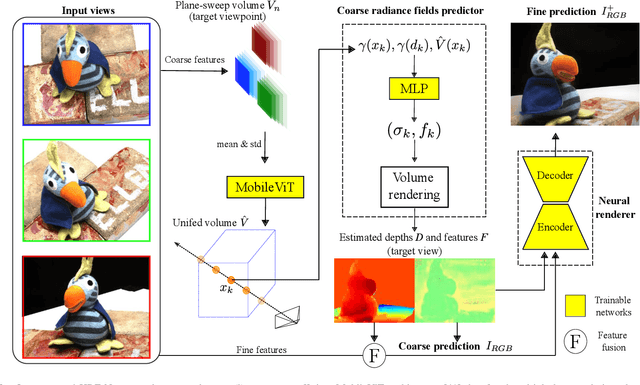
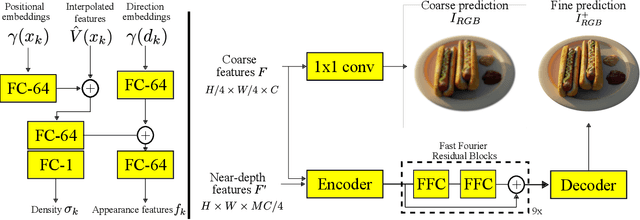
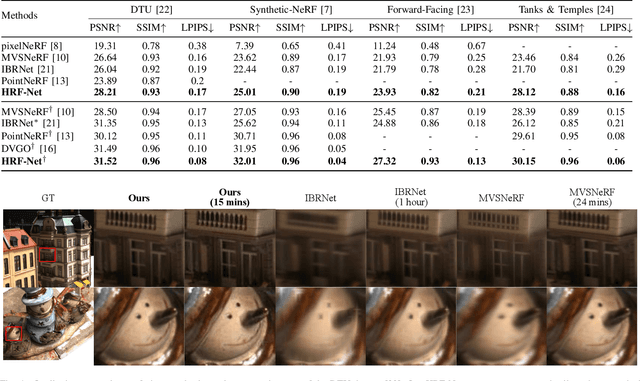
We present HRF-Net, a novel view synthesis method based on holistic radiance fields that renders novel views using a set of sparse inputs. Recent generalizing view synthesis methods also leverage the radiance fields but the rendering speed is not real-time. There are existing methods that can train and render novel views efficiently but they can not generalize to unseen scenes. Our approach addresses the problem of real-time rendering for generalizing view synthesis and consists of two main stages: a holistic radiance fields predictor and a convolutional-based neural renderer. This architecture infers not only consistent scene geometry based on the implicit neural fields but also renders new views efficiently using a single GPU. We first train HRF-Net on multiple 3D scenes of the DTU dataset and the network can produce plausible novel views on unseen real and synthetics data using only photometric losses. Moreover, our method can leverage a denser set of reference images of a single scene to produce accurate novel views without relying on additional explicit representations and still maintains the high-speed rendering of the pre-trained model. Experimental results show that HRF-Net outperforms state-of-the-art generalizable neural rendering methods on various synthetic and real datasets.