 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Adaptive Learning on Time Series: Method and Financial Applications
Nov 17, 2021
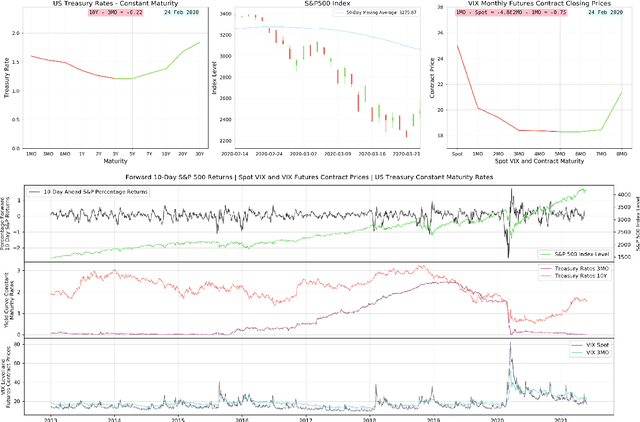
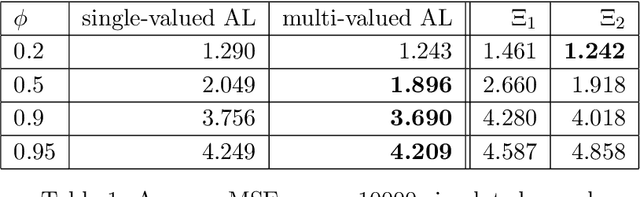
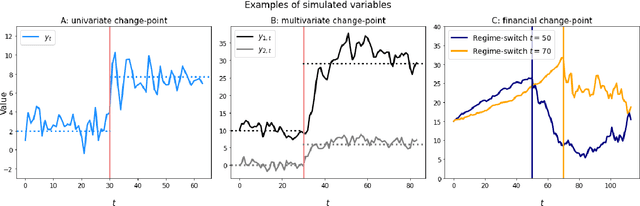
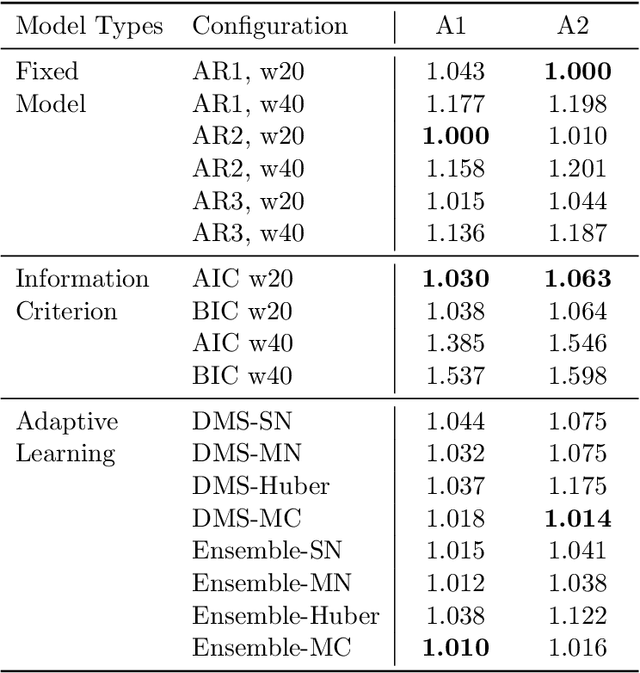
We formally introduce a time series statistical learning method, called Adaptive Learning, capable of handling model selection, out-of-sample forecasting and interpretation in a noisy environment. Through simulation studies we demonstrate that the method can outperform traditional model selection techniques such as AIC and BIC in the presence of regime-switching, as well as facilitating window size determination when the Data Generating Process is time-varying. Empirically, we use the method to forecast S&P 500 returns across multiple forecast horizons, employing information from the VIX Curve and the Yield Curve. We find that Adaptive Learning models are generally on par with, if not better than, the best of the parametric models a posteriori, evaluated in terms of MSE, while also outperforming under cross validation. We present a financial application of the learning results and an interpretation of the learning regime during the 2020 market crash. These studies can be extended in both a statistical direction and in terms of financial applications.
It's About Time: Analog Clock Reading in the Wild
Nov 17, 2021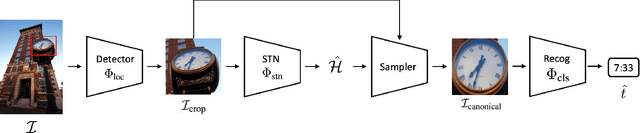
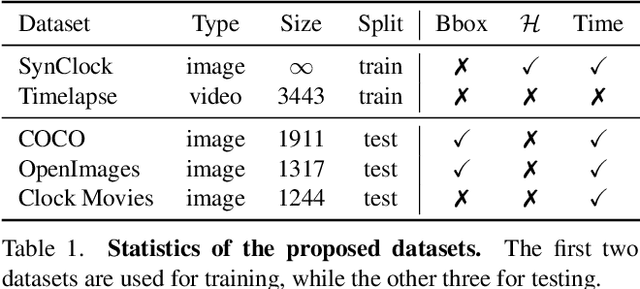

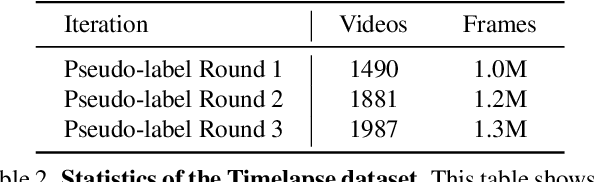
In this paper, we present a framework for reading analog clocks in natural images or videos. Specifically, we make the following contributions: First, we create a scalable pipeline for generating synthetic clocks, significantly reducing the requirements for the labour-intensive annotations; Second, we introduce a clock recognition architecture based on spatial transformer networks (STN), which is trained end-to-end for clock alignment and recognition. We show that the model trained on the proposed synthetic dataset generalises towards real clocks with good accuracy, advocating a Sim2Real training regime; Third, to further reduce the gap between simulation and real data, we leverage the special property of time, i.e. uniformity, to generate reliable pseudo-labels on real unlabelled clock videos, and show that training on these videos offers further improvements while still requiring zero manual annotations. Lastly, we introduce three benchmark datasets based on COCO, Open Images, and The Clock movie, totalling 4,472 images with clocks, with full annotations for time, accurate to the minute.
Gemino: Practical and Robust Neural Compression for Video Conferencing
Sep 22, 2022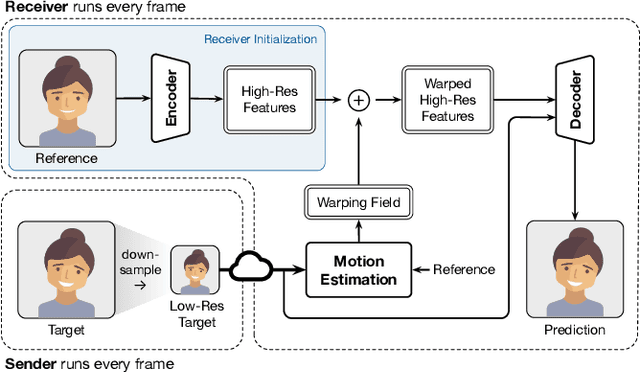
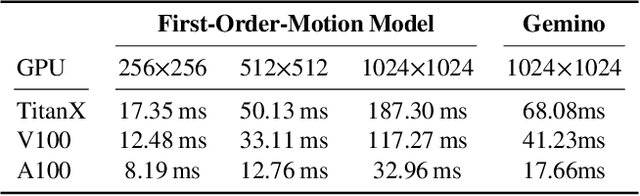


Video conferencing systems suffer from poor user experience when network conditions deteriorate because current video codecs simply cannot operate at extremely low bitrates. Recently, several neural alternatives have been proposed that reconstruct talking head videos at very low bitrates using sparse representations of each frame such as facial landmark information. However, these approaches produce poor reconstructions in scenarios with major movement or occlusions over the course of a call, and do not scale to higher resolutions. We design Gemino, a new neural compression system for video conferencing based on a novel high-frequency-conditional super-resolution pipeline. Gemino upsamples a very low-resolution version of each target frame while enhancing high-frequency details (e.g., skin texture, hair, etc.) based on information extracted from a single high-resolution reference image. We use a multi-scale architecture that runs different components of the model at different resolutions, allowing it to scale to resolutions comparable to 720p, and we personalize the model to learn specific details of each person, achieving much better fidelity at low bitrates. We implement Gemino atop aiortc, an open-source Python implementation of WebRTC, and show that it operates on 1024x1024 videos in real-time on a A100 GPU, and achieves 2.9x lower bitrate than traditional video codecs for the same perceptual quality.
The (Un)Scalability of Heuristic Approximators for NP-Hard Search Problems
Sep 11, 2022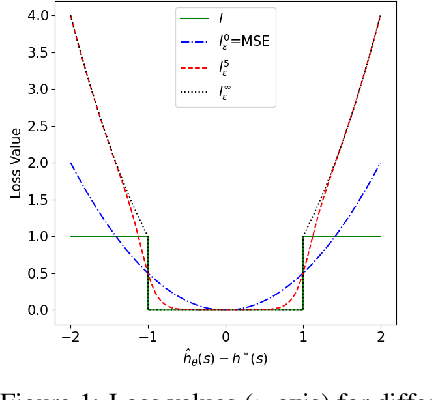
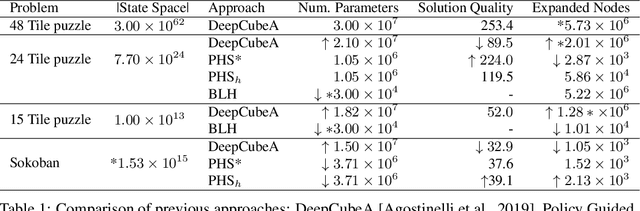
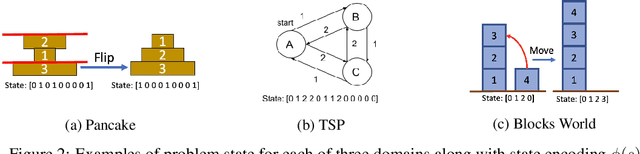
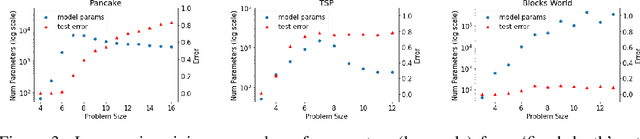
The A* algorithm is commonly used to solve NP-hard combinatorial optimization problems. When provided with an accurate heuristic function, A* can solve such problems in time complexity that is polynomial in the solution depth. This fact implies that accurate heuristic approximation for many such problems is also NP-hard. In this context, we examine a line of recent publications that propose the use of deep neural networks for heuristic approximation. We assert that these works suffer from inherent scalability limitations since -- under the assumption that P$\ne$NP -- such approaches result in either (a) network sizes that scale exponentially in the instance sizes or (b) heuristic approximation accuracy that scales inversely with the instance sizes. Our claim is supported by experimental results for three representative NP-hard search problems that show that fitting deep neural networks accurately to heuristic functions necessitates network sizes that scale exponentially with the instance size.
Towards self-attention based visual navigation in the real world
Sep 19, 2022
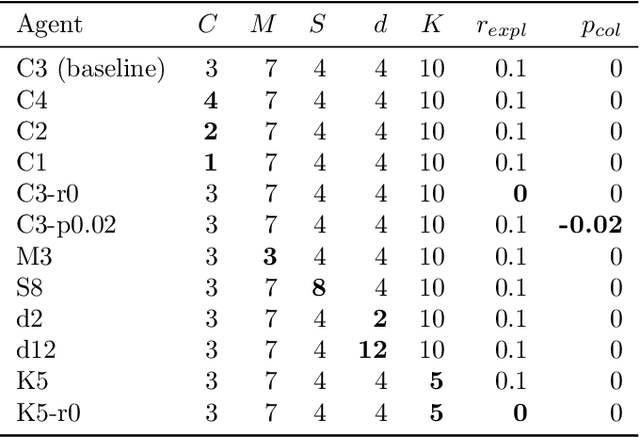
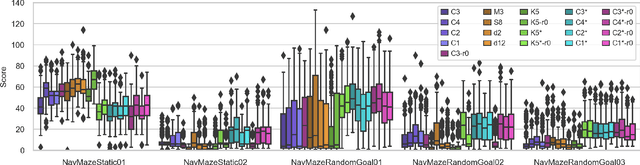
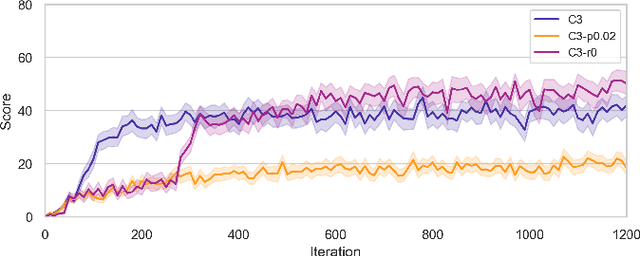
Vision guided navigation requires processing complex visual information to inform task-orientated decisions. Applications include autonomous robots, self-driving cars, and assistive vision for humans. A key element is the extraction and selection of relevant features in pixel space upon which to base action choices, for which Machine Learning techniques are well suited. However, Deep Reinforcement Learning agents trained in simulation often exhibit unsatisfactory results when deployed in the real-world due to perceptual differences known as the $\textit{reality gap}$. An approach that is yet to be explored to bridge this gap is self-attention. In this paper we (1) perform a systematic exploration of the hyperparameter space for self-attention based navigation of 3D environments and qualitatively appraise behaviour observed from different hyperparameter sets, including their ability to generalise; (2) present strategies to improve the agents' generalisation abilities and navigation behaviour; and (3) show how models trained in simulation are capable of processing real world images meaningfully in real time. To our knowledge, this is the first demonstration of a self-attention based agent successfully trained in navigating a 3D action space, using less than 4000 parameters.
Embedding-Assisted Attentional Deep Learning for Real-World RF Fingerprinting of Bluetooth
Sep 22, 2022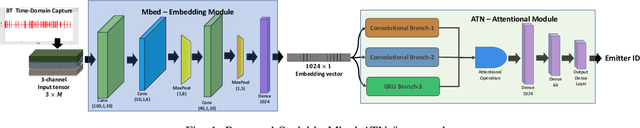
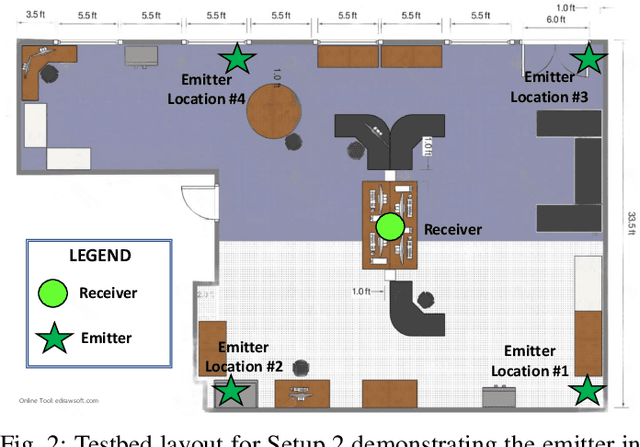
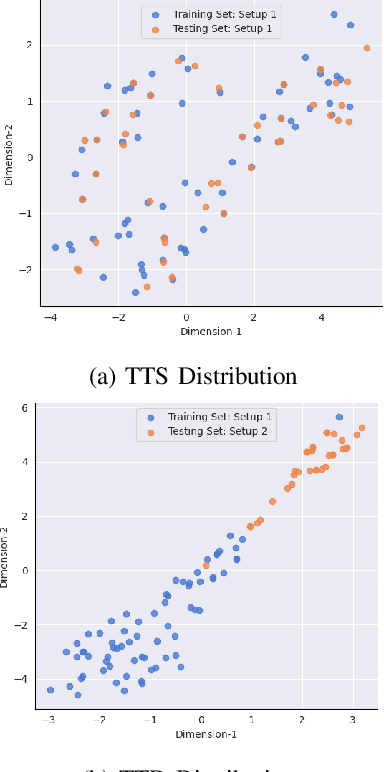
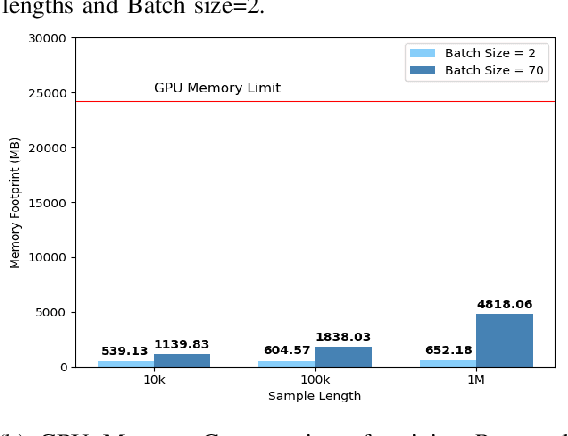
A scalable and computationally efficient framework is designed to fingerprint real-world Bluetooth devices. We propose an embedding-assisted attentional framework (Mbed-ATN) suitable for fingerprinting actual Bluetooth devices. Its generalization capability is analyzed in different settings and the effect of sample length and anti-aliasing decimation is demonstrated. The embedding module serves as a dimensionality reduction unit that maps the high dimensional 3D input tensor to a 1D feature vector for further processing by the ATN module. Furthermore, unlike the prior research in this field, we closely evaluate the complexity of the model and test its fingerprinting capability with real-world Bluetooth dataset collected under a different time frame and experimental setting while being trained on another. Our study reveals 7.3x and 65.2x lesser memory usage with Mbed-ATN architecture in contrast to Oracle at input sample lengths of M=10 kS and M=100 kS respectively. Further, the proposed Mbed-ATN showcases 16.9X fewer FLOPs and 7.5x lesser trainable parameters when compared to Oracle. Finally, we show that when subject to anti-aliasing decimation and at greater input sample lengths of 1 MS, the proposed Mbed-ATN framework results in a 5.32x higher TPR, 37.9% fewer false alarms, and 6.74x higher accuracy under the challenging real-world setting.
WOC: A Handy Webcam-based 3D Online Chatroom
Sep 02, 2022
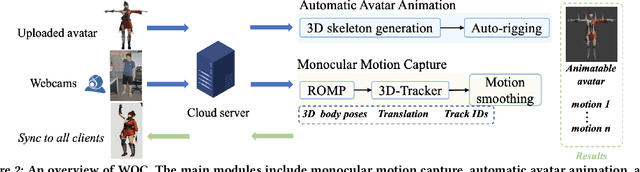
We develop WOC, a webcam-based 3D virtual online chatroom for multi-person interaction, which captures the 3D motion of users and drives their individual 3D virtual avatars in real-time. Compared to the existing wearable equipment-based solution, WOC offers convenient and low-cost 3D motion capture with a single camera. To promote the immersive chat experience, WOC provides high-fidelity virtual avatar manipulation, which also supports the user-defined characters. With the distributed data flow service, the system delivers highly synchronized motion and voice for all users. Deployed on the website and no installation required, users can freely experience the virtual online chat at https://yanch.cloud.
Deep Learning-Based Discrete Calibrated Survival Prediction
Aug 17, 2022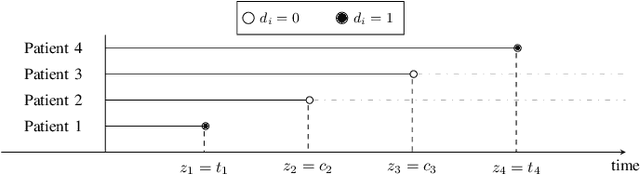
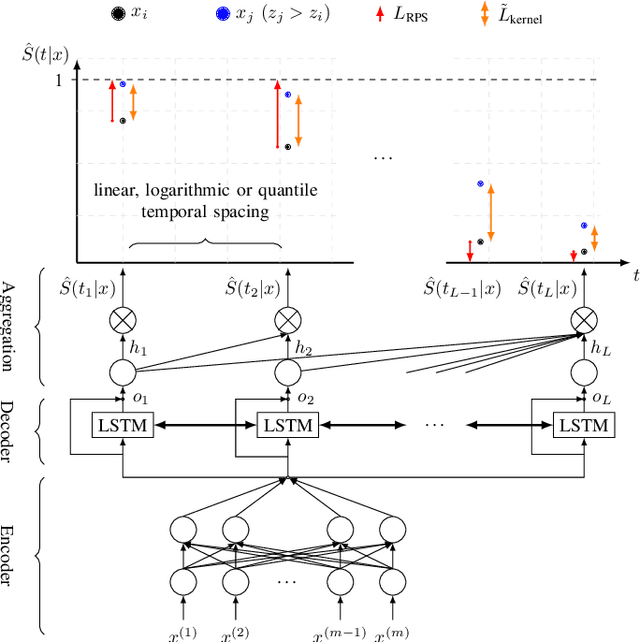

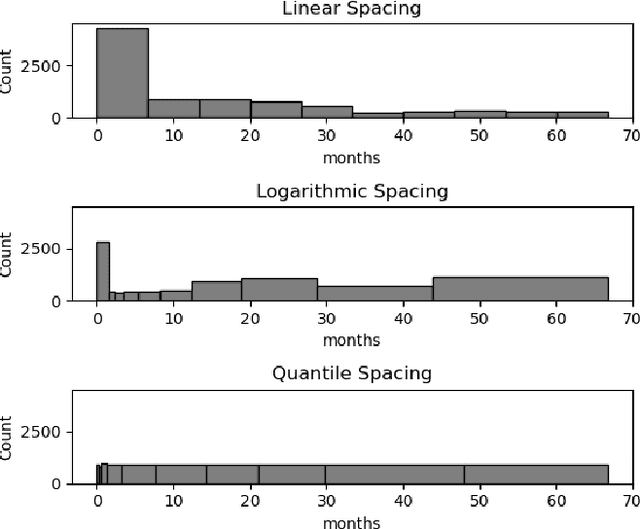
Deep neural networks for survival prediction outper-form classical approaches in discrimination, which is the ordering of patients according to their time-of-event. Conversely, classical approaches like the Cox Proportional Hazards model display much better calibration, the correct temporal prediction of events of the underlying distribution. Especially in the medical domain, where it is critical to predict the survival of a single patient, both discrimination and calibration are important performance metrics. Here we present Discrete Calibrated Survival (DCS), a novel deep neural network for discriminated and calibrated survival prediction that outperforms competing survival models in discrimination on three medical datasets, while achieving best calibration among all discrete time models. The enhanced performance of DCS can be attributed to two novel features, the variable temporal output node spacing and the novel loss term that optimizes the use of uncensored and censored patient data. We believe that DCS is an important step towards clinical application of deep-learning-based survival prediction with state-of-the-art discrimination and good calibration.
Image denoising in acoustic field microscopy
Aug 07, 2022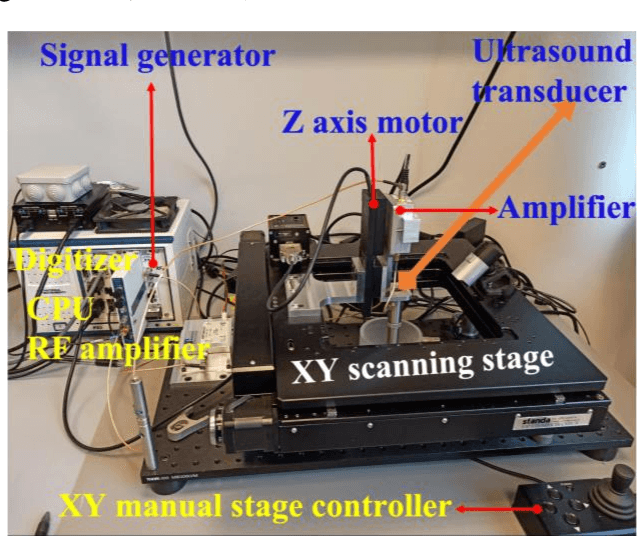
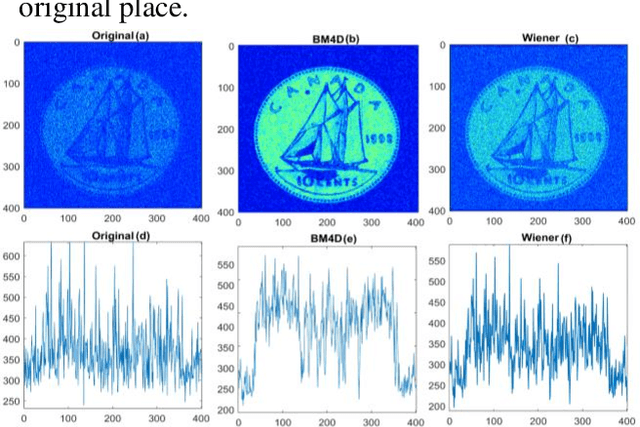
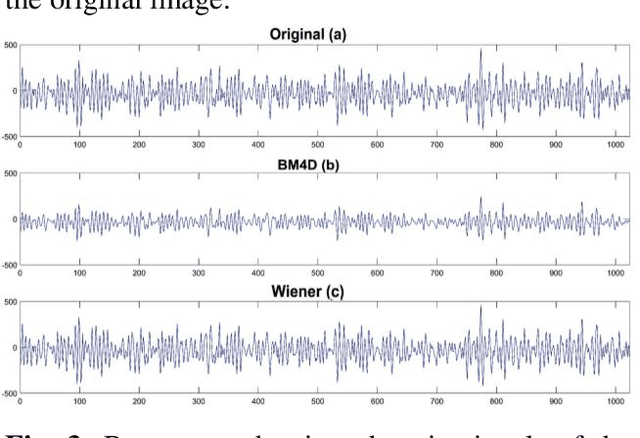
Scanning acoustic microscopy (SAM) has been employed since microscopic images are widely used for biomedical or materials research. Acoustic imaging is an important and well-established method used in nondestructive testing (NDT), bio-medical imaging, and structural health monitoring.The imaging is frequently carried out with signals of low amplitude, which might result in leading that are noisy and lacking in details of image information. In this work, we attempted to analyze SAM images acquired from low amplitude signals and employed a block matching filter over time domain signals to obtain a denoised image. We have compared the images with conventional filters applied over time domain signals, such as the gaussian filter, median filter, wiener filter, and total variation filter. The noted outcomes are shown in this article.
Collision-Free 6-DoF Trajectory Generation for Omnidirectional Multi-rotor Aerial Vehicle
Sep 16, 2022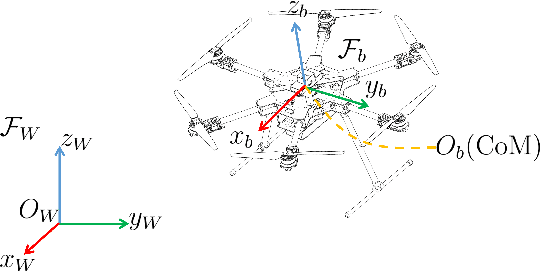
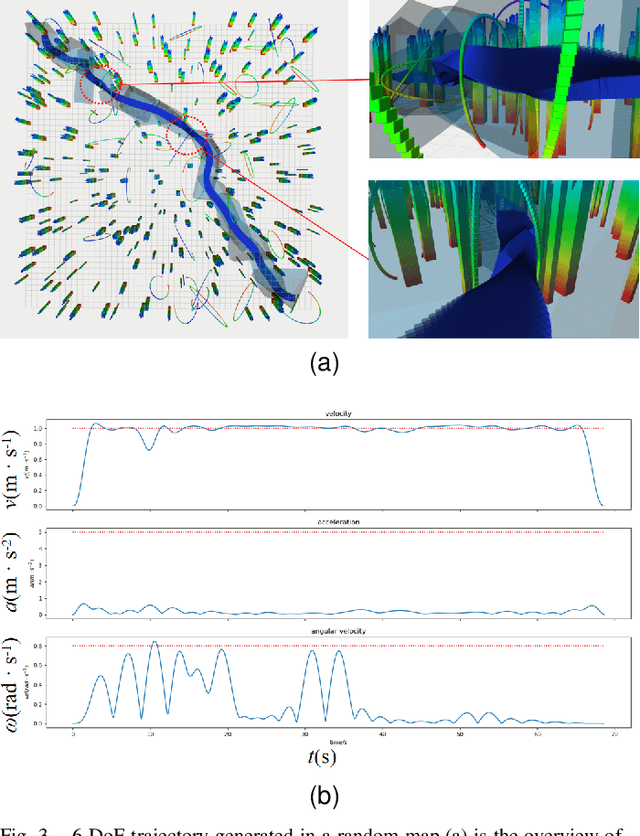

As a kind of fully actuated system, omnidirectional multirotor aerial vehicles (OMAVs) has more flexible maneuverability than traditional underactuated multirotor aircraft, and it also has more significant advantages in obstacle avoidance flight in complex environments.However, there is almost no way to generate the full degrees of freedom trajectory that can play the OMAVs' potential.Due to the high dimensionality of configuration space, it is challenging to make the designed trajectory generation algorithm efficient and scalable.This paper aims to achieve obstacle avoidance planning of OMAV in complex environments. A 6-DoF trajectory generation framework for OMAVs was designed for the first time based on the geometrically constrained Minimum Control Effort (MINCO) trajectory generation framework.According to the safe regions represented by a series of convex polyhedra, combined with the aircraft's overall shape and dynamic constraints, the framework finally generates a collision-free optimal 6-DoF trajectory.The vehicle's attitude is parameterized into a 3D vector by stereographic projection.Simulation experiments based on Gazebo and PX4 Autopilot are conducted to verify the performance of the proposed framework.