 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTree of Thoughts as a Classical Heuristic Search Problem: Formal Foundations and Design Patterns
May 27, 2026Large Language Models (LLMs) have demonstrated remarkable reasoning capabilities, yet their standard generation process -- auto-regressive token prediction -- is inherently myopic and prone to cascading errors. To address this, the Tree-of-Thoughts (ToT) framework creates a search space over intermediate reasoning steps, allowing search models to explore, look ahead, and backtrack. However, current ToT research remains fragmented across Natural Language Processing and Automated Planning communities, often using inconsistent terminology and ad-hoc implementations. Consequently, we synthesize the ToT landscape through a unified taxonomy based on classical heuristic search terminology. We map LLM-based reasoning to classical search components: state representation (granularity of thoughts), successor generation (prompting operators), and heuristic evaluation (self-assessment of progress). We analyze existing work within the context of our taxonomy and identify emerging design patterns: systematic search (Best-First Search) for shallow, deterministic tasks and lookahead-heavy strategies (DFS, MCTS) for deep multi-step reasoning. We conclude by identifying open algorithmic challenges at the intersection of heuristic search and LLM reasoning, and call on the heuristic search community to engage with this emerging domain.
* Extended version of the SoCS 2026 paper. Includes appendices omitted from the proceedings version
Policy-Guided Search on Tree-of-Thoughts for Efficient Problem Solving with Bounded Language Model Queries
Jan 07, 2026Recent studies explored integrating state-space search algorithms with Language Models (LM) to perform look-ahead on the token generation process, the ''Tree-of-Thoughts'' (ToT), generated by LMs, thereby improving performance on problem-solving tasks. However, the affiliated search algorithms often overlook the significant computational costs associated with LM inference, particularly in scenarios with constrained computational budgets. Consequently, we address the problem of improving LM performance on problem-solving tasks under limited computational budgets. We demonstrate how the probabilities assigned to thoughts by LMs can serve as a heuristic to guide search within the ToT framework, thereby reducing the number of thought evaluations. Building on this insight, we adapt a heuristic search algorithm, Levin Tree Search (LTS), to the ToT framework, which leverages LMs as policies to guide the tree exploration efficiently. We extend the theoretical results of LTS by showing that, for ToT (a pruned tree), LTS guarantees a bound on the number of states expanded, and consequently, on the number of thoughts generated. Additionally, we analyze the sensitivity of this bound to the temperature values commonly used in the final softmax layer of the LM. Empirical evaluation under a fixed LM query budget demonstrates that LTS consistently achieves comparable or higher accuracy than baseline search algorithms within the ToT framework, across three domains (Blocksworld, PrOntoQA, Array Sorting) and four distinct LMs. These findings highlight the efficacy of LTS on ToT, particularly in enabling cost-effective and time-efficient problem-solving, making it well-suited for latency-critical and resource-constrained applications.
* Published in Transactions on Machine Learning Research (TMLR), 2025. Available at https://openreview.net/forum?id=Rlk1bWe2ii
A Joint Imitation-Reinforcement Learning Framework for Reduced Baseline Regret
Sep 20, 2022
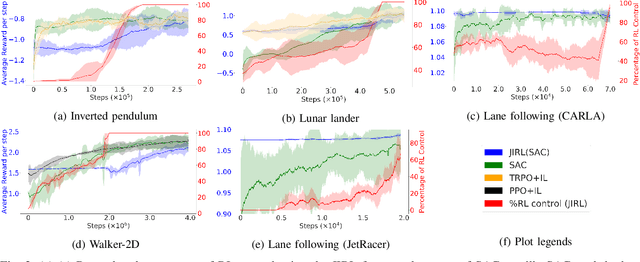
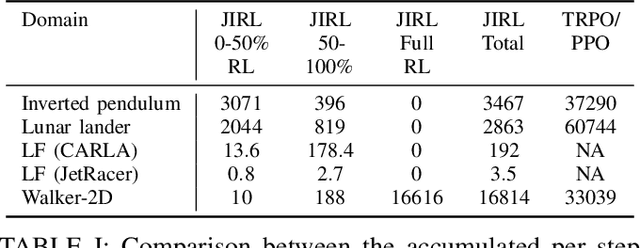
In various control task domains, existing controllers provide a baseline level of performance that -- though possibly suboptimal -- should be maintained. Reinforcement learning (RL) algorithms that rely on extensive exploration of the state and action space can be used to optimize a control policy. However, fully exploratory RL algorithms may decrease performance below a baseline level during training. In this paper, we address the issue of online optimization of a control policy while minimizing regret w.r.t a baseline policy performance. We present a joint imitation-reinforcement learning framework, denoted JIRL. The learning process in JIRL assumes the availability of a baseline policy and is designed with two objectives in mind \textbf{(a)} leveraging the baseline's online demonstrations to minimize the regret w.r.t the baseline policy during training, and \textbf{(b)} eventually surpassing the baseline performance. JIRL addresses these objectives by initially learning to imitate the baseline policy and gradually shifting control from the baseline to an RL agent. Experimental results show that JIRL effectively accomplishes the aforementioned objectives in several, continuous action-space domains. The results demonstrate that JIRL is comparable to a state-of-the-art algorithm in its final performance while incurring significantly lower baseline regret during training in all of the presented domains. Moreover, the results show a reduction factor of up to $21$ in baseline regret over a state-of-the-art baseline regret minimization approach.
The (Un)Scalability of Heuristic Approximators for NP-Hard Search Problems
Sep 11, 2022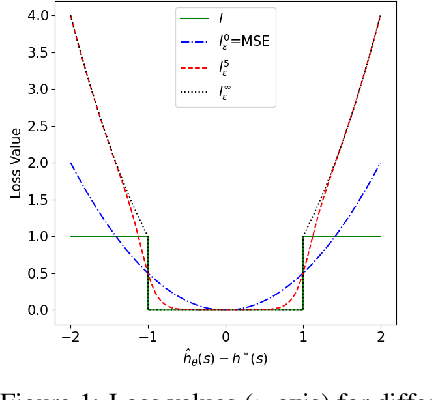
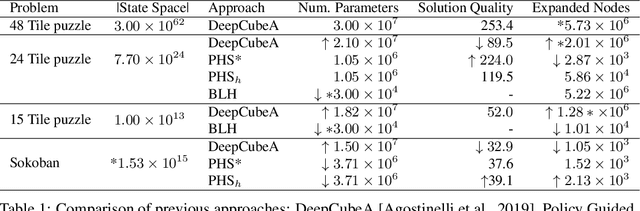
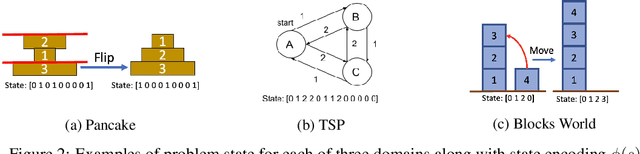
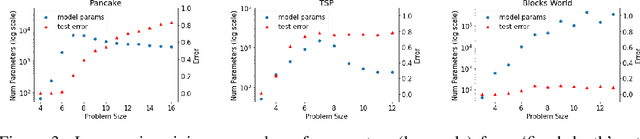
The A* algorithm is commonly used to solve NP-hard combinatorial optimization problems. When provided with an accurate heuristic function, A* can solve such problems in time complexity that is polynomial in the solution depth. This fact implies that accurate heuristic approximation for many such problems is also NP-hard. In this context, we examine a line of recent publications that propose the use of deep neural networks for heuristic approximation. We assert that these works suffer from inherent scalability limitations since -- under the assumption that P$\ne$NP -- such approaches result in either (a) network sizes that scale exponentially in the instance sizes or (b) heuristic approximation accuracy that scales inversely with the instance sizes. Our claim is supported by experimental results for three representative NP-hard search problems that show that fitting deep neural networks accurately to heuristic functions necessitates network sizes that scale exponentially with the instance size.
Learning an Interpretable Traffic Signal Control Policy
Dec 23, 2019
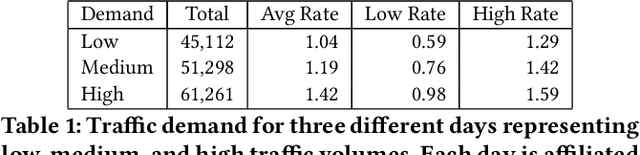
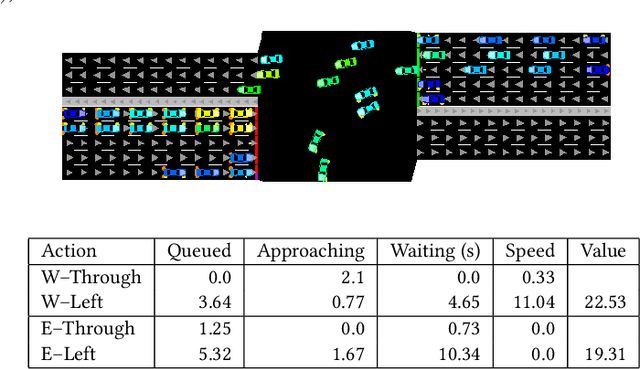

Signalized intersections are managed by controllers that assign right of way (green, yellow, and red lights) to non-conflicting directions. Optimizing the actuation policy of such controllers is expected to alleviate traffic congestion and its adverse impact. Given such a safety-critical domain, the affiliated actuation policy is required to be interpretable in a way that can be understood and regulated by a human. This paper presents and analyzes several on-line optimization techniques for tuning interpretable control functions. Although these techniques are defined in a general way, this paper assumes a specific class of interpretable control functions (polynomial functions) for analysis purposes. We show that such an interpretable policy function can be as effective as a deep neural network for approximating an optimized signal actuation policy. We present empirical evidence that supports the use of value-based reinforcement learning for on-line training of the control function. Specifically, we present and study three variants of the Deep Q-learning algorithm that allow the training of an interpretable policy function. Our Deep Regulatable Hardmax Q-learning variant is shown to be particularly effective in optimizing our interpretable actuation policy, resulting in up to 19.4% reduced vehicles delay compared to commonly deployed actuated signal controllers.
Traffic Optimization For a Mixture of Self-interested and Compliant Agents
Sep 27, 2017

This paper focuses on two commonly used path assignment policies for agents traversing a congested network: self-interested routing, and system-optimum routing. In the self-interested routing policy each agent selects a path that optimizes its own utility, while the system-optimum routing agents are assigned paths with the goal of maximizing system performance. This paper considers a scenario where a centralized network manager wishes to optimize utilities over all agents, i.e., implement a system-optimum routing policy. In many real-life scenarios, however, the system manager is unable to influence the route assignment of all agents due to limited influence on route choice decisions. Motivated by such scenarios, a computationally tractable method is presented that computes the minimal amount of agents that the system manager needs to influence (compliant agents) in order to achieve system optimal performance. Moreover, this methodology can also determine whether a given set of compliant agents is sufficient to achieve system optimum and compute the optimal route assignment for the compliant agents to do so. Experimental results are presented showing that in several large-scale, realistic traffic networks optimal flow can be achieved with as low as 13% of the agent being compliant and up to 54%.
Overview: Generalizations of Multi-Agent Path Finding to Real-World Scenarios
Feb 17, 2017
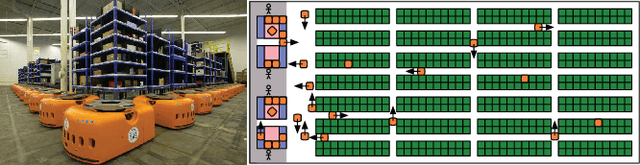
Multi-agent path finding (MAPF) is well-studied in artificial intelligence, robotics, theoretical computer science and operations research. We discuss issues that arise when generalizing MAPF methods to real-world scenarios and four research directions that address them. We emphasize the importance of addressing these issues as opposed to developing faster methods for the standard formulation of the MAPF problem.