 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Novel techniques for improvement the NNetEn entropy calculation for short and noisy time series
Feb 25, 2022
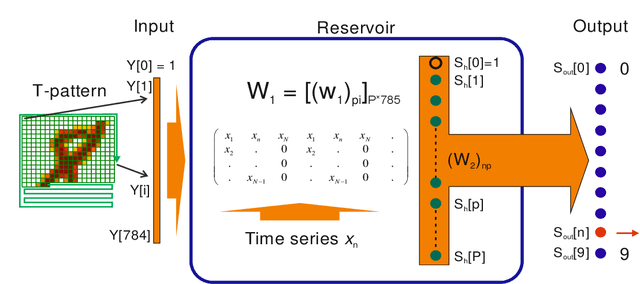
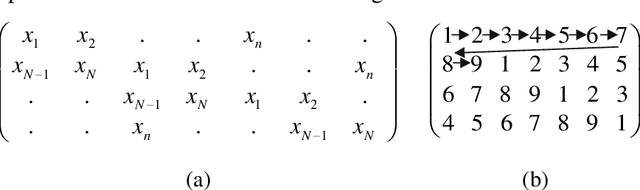

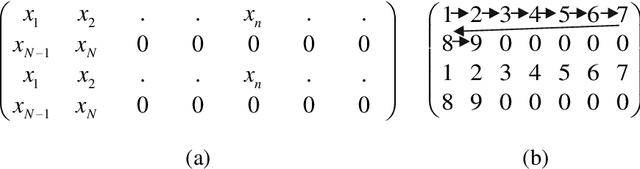
Entropy is a fundamental concept of information theory. It is widely used in the analysis of analog and digital signals. Conventional entropy measures have drawbacks, such as sensitivity to the length and amplitude of time series and low robustness to external noise. Recently, the NNetEn entropy measure has been introduced to overcome these problems. The NNetEn entropy uses a modified version of the LogNNet neural network classification model. The algorithm contains a reservoir matrix with N = 19625 elements, which the given time series should fill. Many practical time series have less than 19625 elements. Against this background, this paper investigates different duplicating and stretching techniques for filling to overcome this difficulty. The most successful technique is identified for practical applications. The presence of external noise and bias are other important issues affecting the efficiency of entropy measures. In order to perform meaningful analysis, three time series with different dynamics (chaotic, periodic, and binary), with a variation of signal-to-noise ratio (SNR) and offsets, are considered. It is shown that the error in the calculation of the NNetEn entropy does not exceed 10% when the SNR exceeds 30 dB. This opens the possibility of measuring the NNetEn of experimental signals in the presence of noise of various nature, white noise, or 1/f noise, without the need for noise filtering.
Imputing Missing Observations with Time Sliced Synthetic Minority Oversampling Technique
Jan 14, 2022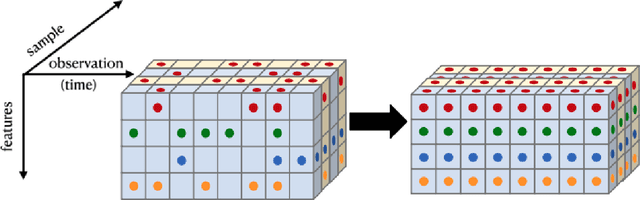
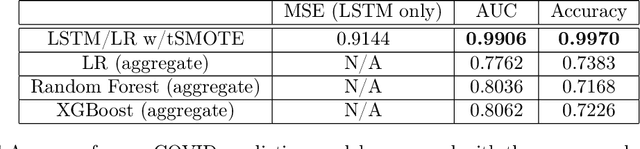
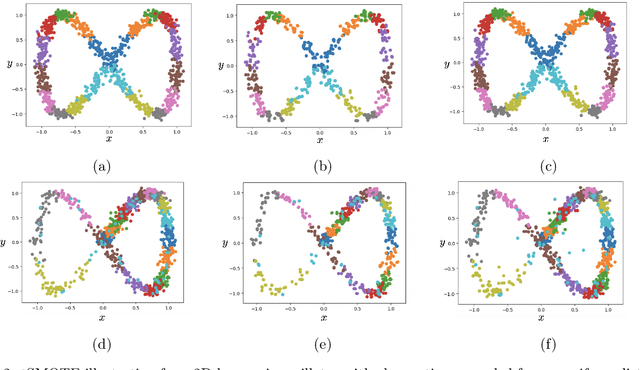
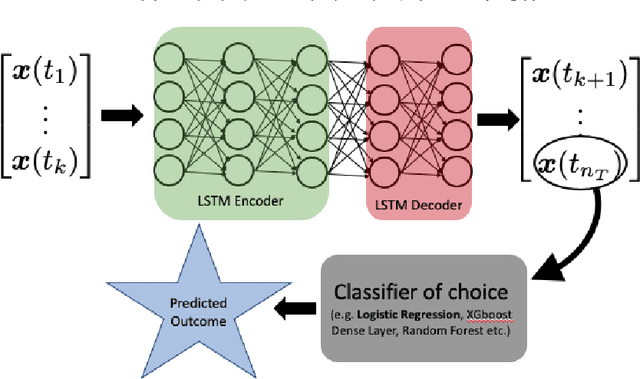
We present a simple yet novel time series imputation technique with the goal of constructing an irregular time series that is uniform across every sample in a data set. Specifically, we fix a grid defined by the midpoints of non-overlapping bins (dubbed "slices") of observation times and ensure that each sample has values for all of the features at that given time. This allows one to both impute fully missing observations to allow uniform time series classification across the entire data and, in special cases, to impute individually missing features. To do so, we slightly generalize the well-known class imbalance algorithm SMOTE \cite{smote} to allow component wise nearest neighbor interpolation that preserves correlations when there are no missing features. We visualize the method in the simplified setting of 2-dimensional uncoupled harmonic oscillators. Next, we use tSMOTE to train an Encoder/Decoder long-short term memory (LSTM) model with Logistic Regression for predicting and classifying distinct trajectories of different 2D oscillators. After illustrating the the utility of tSMOTE in this context, we use the same architecture to train a clinical model for COVID-19 disease severity on an imputed data set. Our experiments show an improvement over standard mean and median imputation techniques by allowing a wider class of patient trajectories to be recognized by the model, as well as improvement over aggregated classification models.
MEET: Mobility-Enhanced Edge inTelligence for Smart and Green 6G Networks
Oct 27, 2022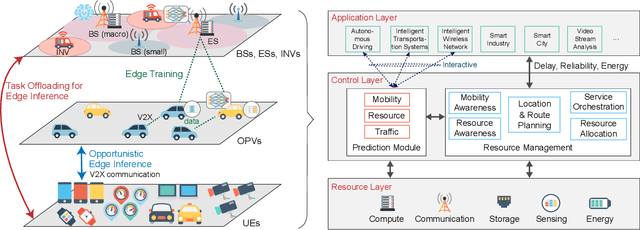
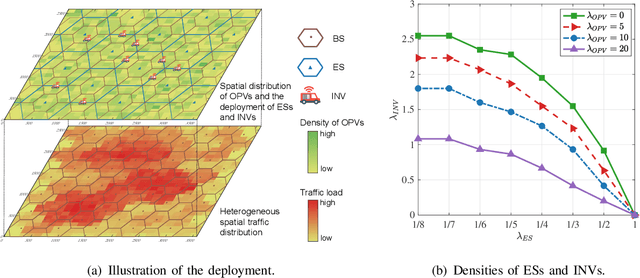
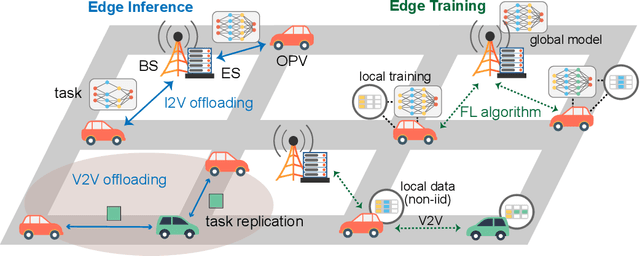
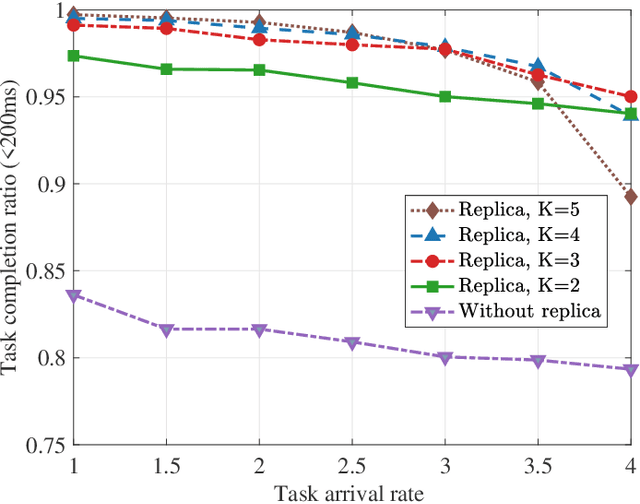
Edge intelligence is an emerging paradigm for real-time training and inference at the wireless edge, thus enabling mission-critical applications. Accordingly, base stations (BSs) and edge servers (ESs) need to be densely deployed, leading to huge deployment and operation costs, in particular the energy costs. In this article, we propose a new framework called Mobility-Enhanced Edge inTelligence (MEET), which exploits the sensing, communication, computing, and self-powering capabilities of intelligent connected vehicles for the smart and green 6G networks. Specifically, the operators can incorporate infrastructural vehicles as movable BSs or ESs, and schedule them in a more flexible way to align with the communication and computation traffic fluctuations. Meanwhile, the remaining compute resources of opportunistic vehicles are exploited for edge training and inference, where mobility can further enhance edge intelligence by bringing more compute resources, communication opportunities, and diverse data. In this way, the deployment and operation costs are spread over the vastly available vehicles, so that the edge intelligence is realized cost-effectively and sustainably. Furthermore, these vehicles can be either powered by renewable energy to reduce carbon emissions, or charged more flexibly during off-peak hours to cut electricity bills.
BERT-Flow-VAE: A Weakly-supervised Model for Multi-Label Text Classification
Oct 27, 2022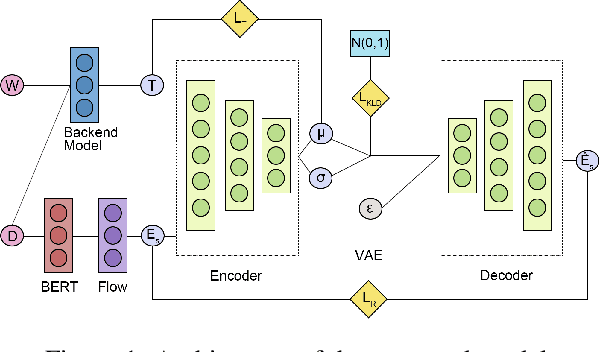
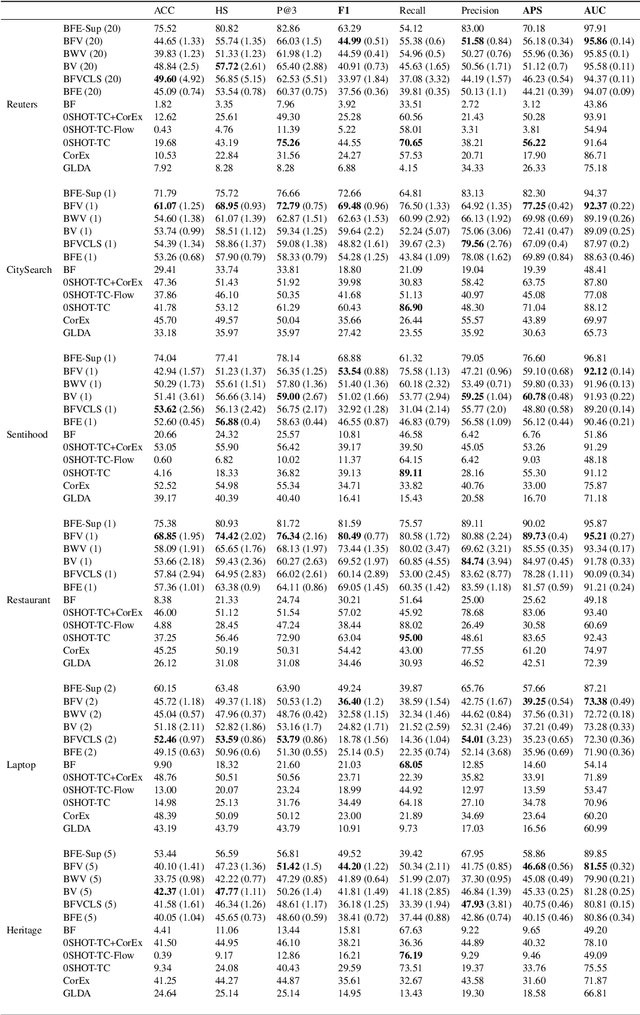
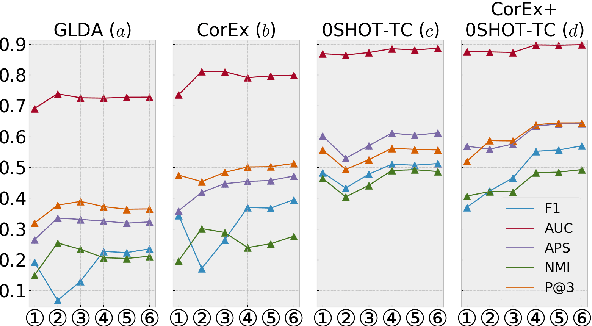
Multi-label Text Classification (MLTC) is the task of categorizing documents into one or more topics. Considering the large volumes of data and varying domains of such tasks, fully supervised learning requires manually fully annotated datasets which is costly and time-consuming. In this paper, we propose BERT-Flow-VAE (BFV), a Weakly-Supervised Multi-Label Text Classification (WSMLTC) model that reduces the need for full supervision. This new model (1) produces BERT sentence embeddings and calibrates them using a flow model, (2) generates an initial topic-document matrix by averaging results of a seeded sparse topic model and a textual entailment model which only require surface name of topics and 4-6 seed words per topic, and (3) adopts a VAE framework to reconstruct the embeddings under the guidance of the topic-document matrix. Finally, (4) it uses the means produced by the encoder model in the VAE architecture as predictions for MLTC. Experimental results on 6 multi-label datasets show that BFV can substantially outperform other baseline WSMLTC models in key metrics and achieve approximately 84% performance of a fully-supervised model.
* 8 pages, 4 figures
ObSynth: An Interactive Synthesis System for Generating Object Models from Natural Language Specifications
Oct 20, 2022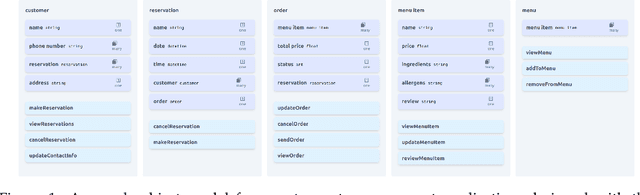

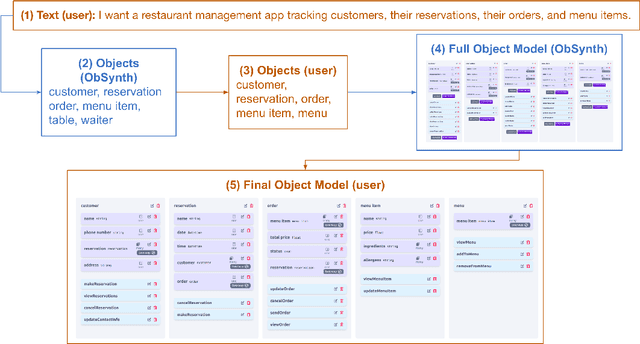
We introduce ObSynth, an interactive system leveraging the domain knowledge embedded in large language models (LLMs) to help users design object models from high level natural language prompts. This is an example of specification reification, the process of taking a high-level, potentially vague specification and reifying it into a more concrete form. We evaluate ObSynth via a user study, leading to three key findings: first, object models designed using ObSynth are more detailed, showing that it often synthesizes fields users might have otherwise omitted. Second, a majority of objects, methods, and fields generated by ObSynth are kept by the user in the final object model, highlighting the quality of generated components. Third, ObSynth altered the workflow of participants: they focus on checking that synthesized components were correct rather than generating them from scratch, though ObSynth did not reduce the time participants took to generate object models.
Scientific Impact of Graph-Based Approaches in Deep Learning Studies -- A Bibliometric Comparison
Oct 13, 2022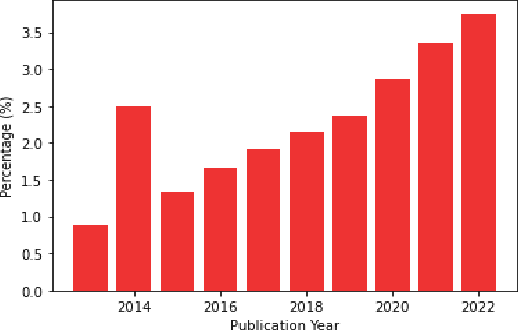
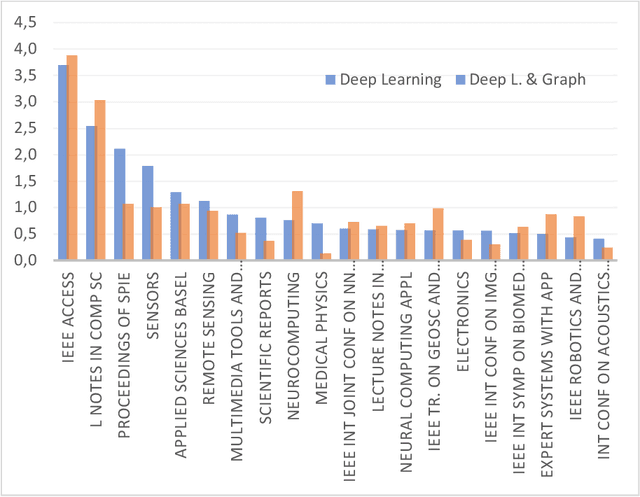
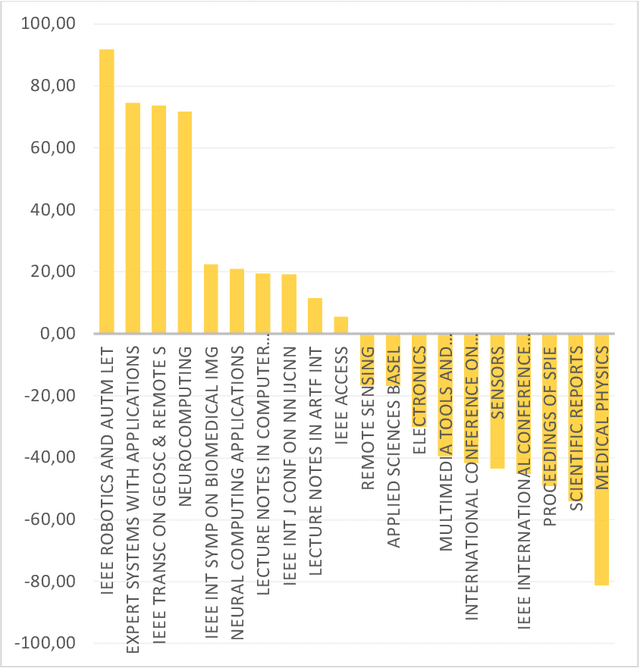
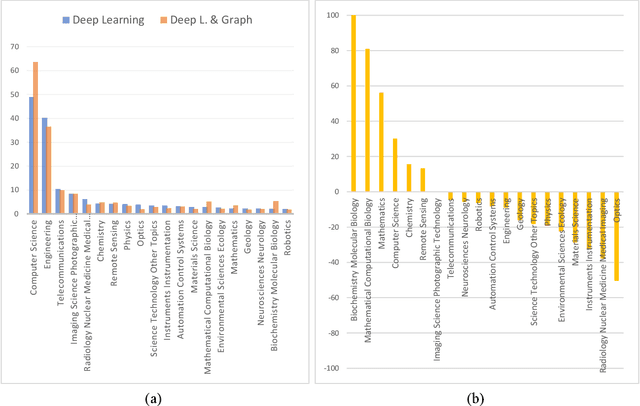
Applying graph-based approaches in deep learning receives more attention over time. This study presents statistical analysis on the use of graph-based approaches in deep learning and examines the scientific impact of the related articles. Processing the data obtained from the Web of Science database, metrics such as the type of the articles, funding availability, indexing type, annual average number of citations and the number of access were analyzed to quantitatively reveal the effects on the scientific audience. It's outlined that deep learning-based studies gained momentum after year 2013, and the rate of graph-based approaches in all deep learning studies increased linearly from 1% to 4% within the following 10 years. Conference publications scanned in the Conference Proceeding Citation Index (CPCI) on the graph-based approaches receive significantly more citations. The citation counts of the SCI-Expanded and Emerging SCI indexed publications of the two streams are close to each other. While the citation performances of the supported and unsupported publications of the two sides were similar, pure deep learning studies received more citations on the journal publication side and graph-based approaches received more citations on the conference side. Despite their similar performance in recent years, graph-based studies show twice more citation performance as they get older, compared to traditional approaches. Annual average citation performance per article for all deep learning studies is 11.051 in 2014, while it is 22.483 for graph-based studies. Also, despite receiving 16% more access, graph-based papers get almost the same overall citation over time with the pure counterpart. This is an indication that graph-based approaches need a greater bunch of attention to follow, while pure deep learning counterpart is relatively simpler to get inside.
Age of Information in Federated Learning over Wireless Networks
Sep 14, 2022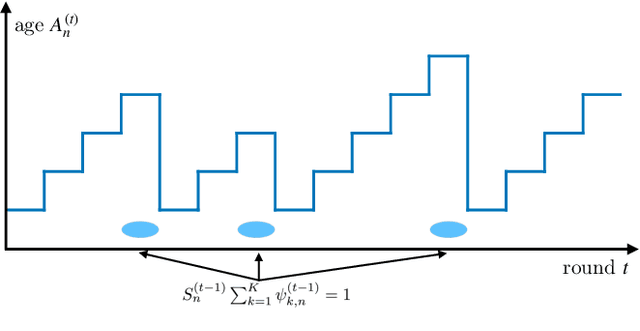
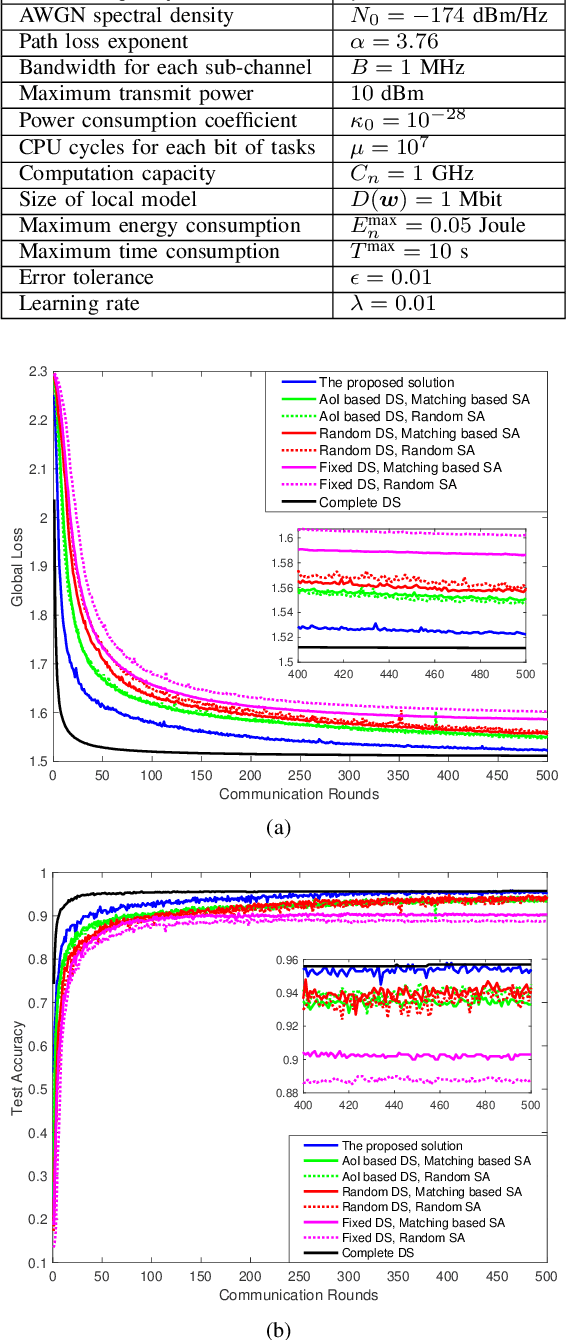
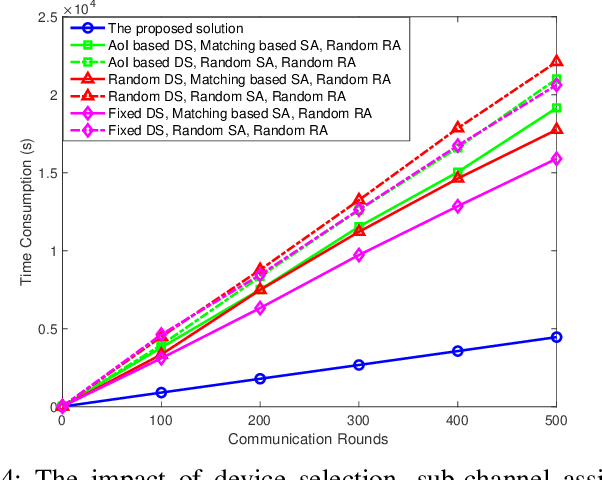
In this paper, federated learning (FL) over wireless networks is investigated. In each communication round, a subset of devices is selected to participate in the aggregation with limited time and energy. In order to minimize the convergence time, global loss and latency are jointly considered in a Stackelberg game based framework. Specifically, age of information (AoI) based device selection is considered at leader-level as a global loss minimization problem, while sub-channel assignment, computational resource allocation, and power allocation are considered at follower-level as a latency minimization problem. By dividing the follower-level problem into two sub-problems, the best response of the follower is obtained by a monotonic optimization based resource allocation algorithm and a matching based sub-channel assignment algorithm. By deriving the upper bound of convergence rate, the leader-level problem is reformulated, and then a list based device selection algorithm is proposed to achieve Stackelberg equilibrium. Simulation results indicate that the proposed device selection scheme outperforms other schemes in terms of the global loss, and the developed algorithms can significantly decrease the time consumption of computation and communication.
Parameter-Conditioned Reachable Sets for Updating Safety Assurances Online
Sep 29, 2022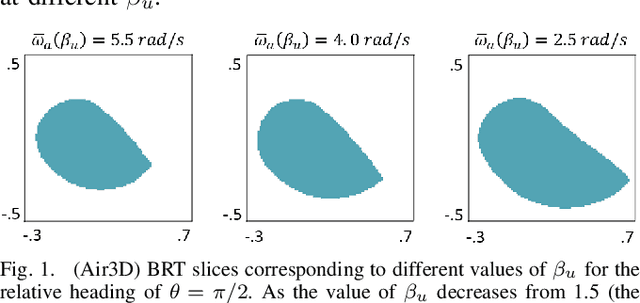
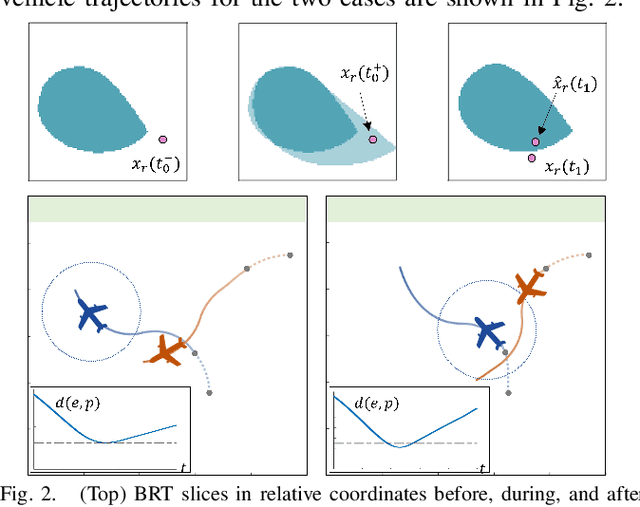
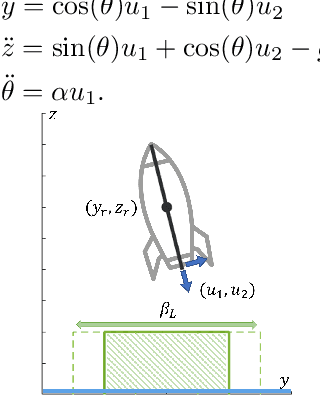
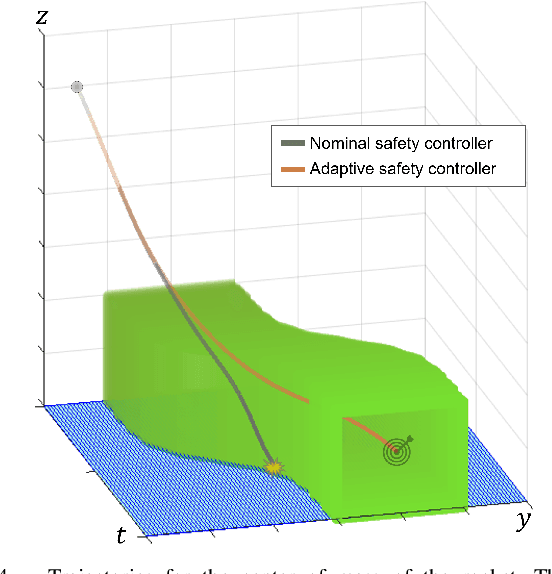
Hamilton-Jacobi (HJ) reachability analysis is a powerful tool for analyzing the safety of autonomous systems. However, the provided safety assurances are often predicated on the assumption that once deployed, the system or its environment does not evolve. Online, however, an autonomous system might experience changes in system dynamics, control authority, external disturbances, and/or the surrounding environment, requiring updated safety assurances. Rather than restarting the safety analysis from scratch, which can be time-consuming and often intractable to perform online, we propose to compute \textit{parameter-conditioned} reachable sets. Assuming expected system and environment changes can be parameterized, we treat these parameters as virtual states in the system and leverage recent advances in high-dimensional reachability analysis to solve the corresponding reachability problem offline. This results in a family of reachable sets that is parameterized by the environment and system factors. Online, as these factors change, the system can simply query the corresponding safety function from this family to ensure system safety, enabling a real-time update of the safety assurances. Through various simulation studies, we demonstrate the capability of our approach in maintaining system safety despite the system and environment evolution.
Joint PMD Tracking and Nonlinearity Compensation with Deep Neural Networks
Sep 21, 2022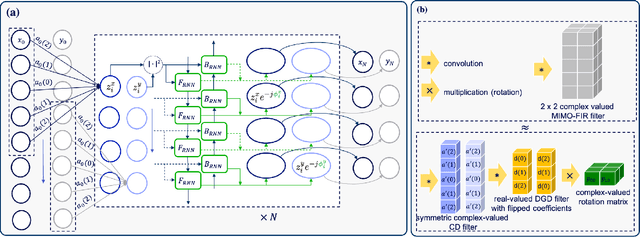

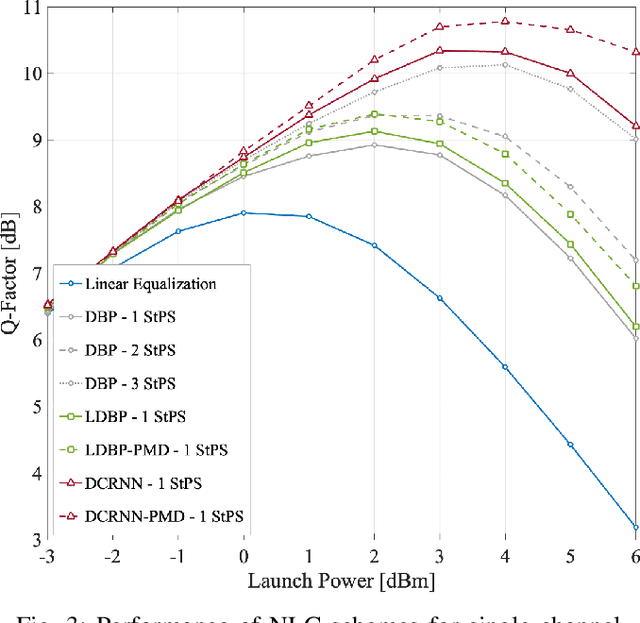
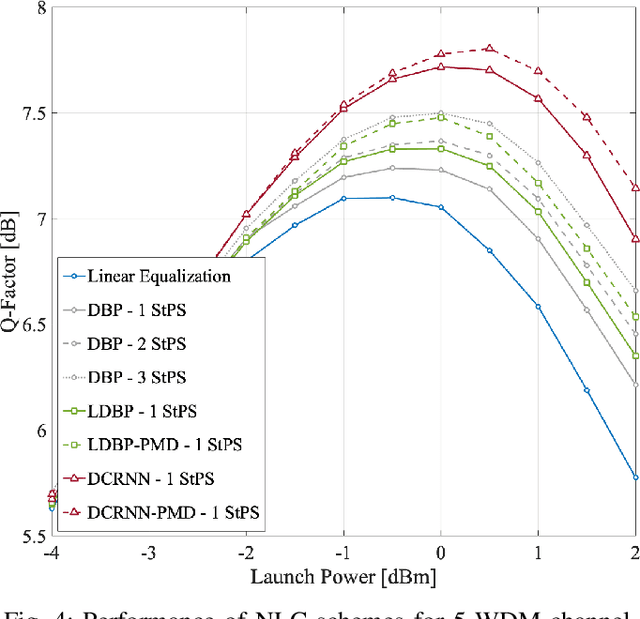
Overcoming fiber nonlinearity is one of the core challenges limiting the capacity of optical fiber communication systems. Machine learning based solutions such as learned digital backpropagation (LDBP) and the recently proposed deep convolutional recurrent neural network (DCRNN) have been shown to be effective for fiber nonlinearity compensation (NLC). Incorporating distributed compensation of polarization mode dispersion (PMD) within the learned models can improve their performance even further but at the same time, it also couples the compensation of nonlinearity and PMD. Consequently, it is important to consider the time variation of PMD for such a joint compensation scheme. In this paper, we investigate the impact of PMD drift on the DCRNN model with distributed compensation of PMD. We propose a transfer learning based selective training scheme to adapt the learned neural network model to changes in PMD. We demonstrate that fine-tuning only a small subset of weights as per the proposed method is sufficient for adapting the model to PMD drift. Using decision directed feedback for online learning, we track continuous PMD drift resulting from a time-varying rotation of the state of polarization (SOP). We show that transferring knowledge from a pre-trained base model using the proposed scheme significantly reduces the re-training efforts for different PMD realizations. Applying the hinge model for SOP rotation, our simulation results show that the learned models maintain their performance gains while tracking the PMD.
On the Efficient Implementation of High Accuracy Optimality of Profile Maximum Likelihood
Oct 13, 2022
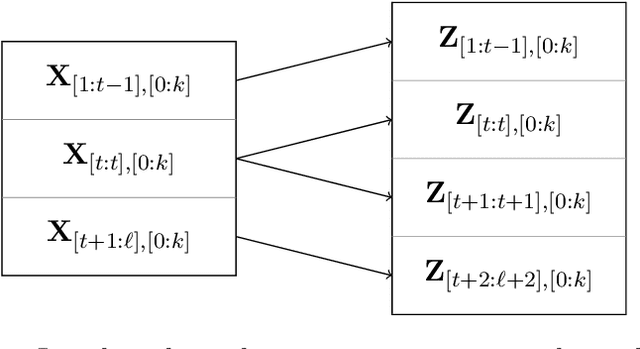
We provide an efficient unified plug-in approach for estimating symmetric properties of distributions given $n$ independent samples. Our estimator is based on profile-maximum-likelihood (PML) and is sample optimal for estimating various symmetric properties when the estimation error $\epsilon \gg n^{-1/3}$. This result improves upon the previous best accuracy threshold of $\epsilon \gg n^{-1/4}$ achievable by polynomial time computable PML-based universal estimators [ACSS21, ACSS20]. Our estimator reaches a theoretical limit for universal symmetric property estimation as [Han21] shows that a broad class of universal estimators (containing many well known approaches including ours) cannot be sample optimal for every $1$-Lipschitz property when $\epsilon \ll n^{-1/3}$.