 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Contribution to the initialization of linear non-commensurate fractional-order systems for the joint estimation of parameters and fractional differentiation orders
Oct 18, 2022
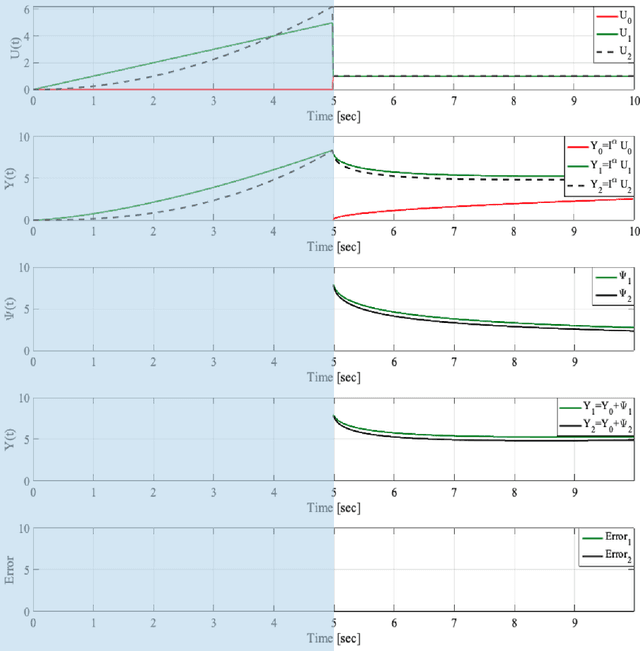
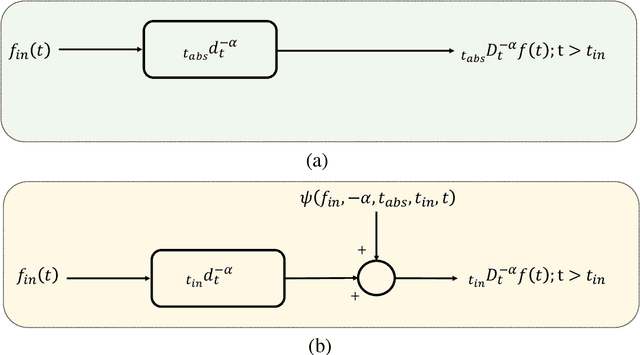
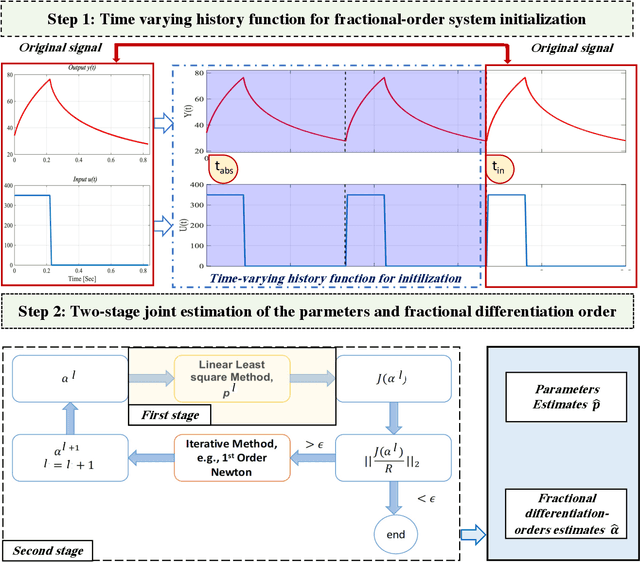
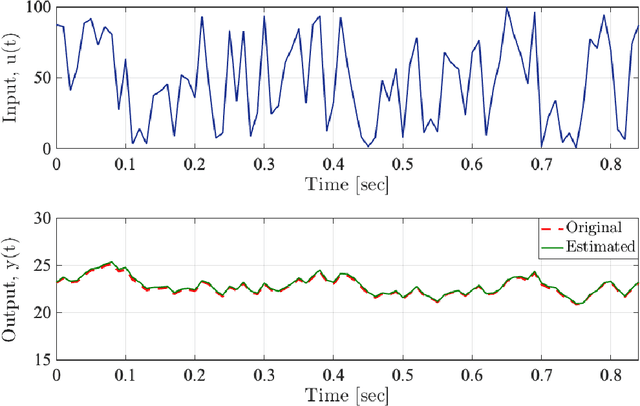
It has been recognized that using time-varying initialization functions to solve the initial value problem of fractional-order systems (FOS) is both complex and essential in defining the dynamical behavior of the states of FOSs. In this paper, we investigate the use of the initialization functions for the purpose of estimating unknown parameters of linear non-commensurate FOSs. In particular, we propose a novel "pre-initial" process that describes the dynamic characteristic of FOSs before the initial state and consists of designing an appropriate time-varying initialization function that ensures accurate convergence of the estimates of the unknown parameters. To do so, we propose an estimation technique that consists of two steps: (i) to design of practical initialization function that is output-dependent and which is employed; (ii) to solve the joint estimation problem of both parameters and fractional differentiation orders (FDOs). A convergence proof has been presented. The performance of the proposed method is illustrated through different numerical examples. Potential applications of the algorithm to joint estimation of parameters and FDOs of the fractional arterial Windkessel and neurovascular models are also presented using both synthetic and real data. The added value of the proposed "pre-initial" process to solve the studied estimation problem is shown through different simulation tests that investigate the sensitivity of estimation results using different time-varying initialization functions.
Branch-and-Bound with Barrier: Dominance and Suboptimality Detection for DD-Based Branch-and-Bound
Nov 22, 2022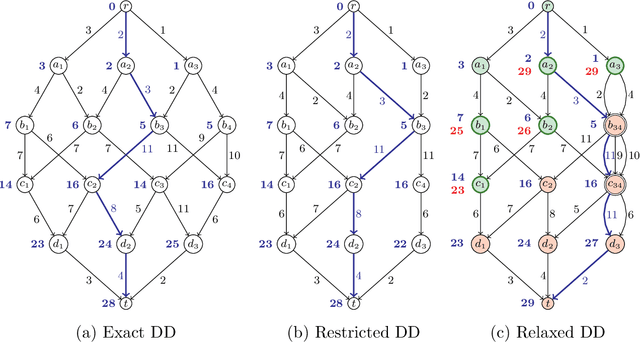
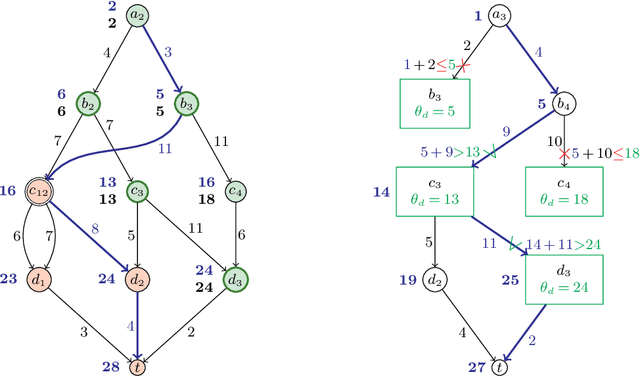
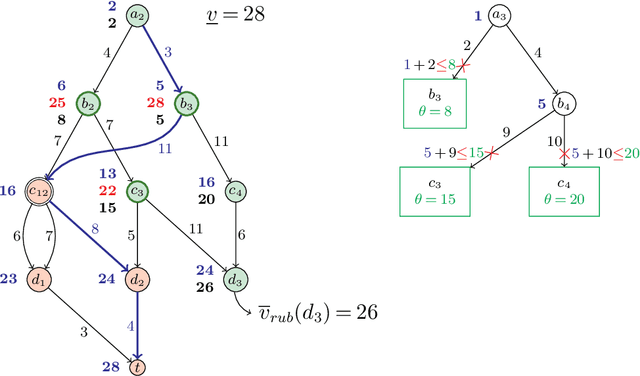
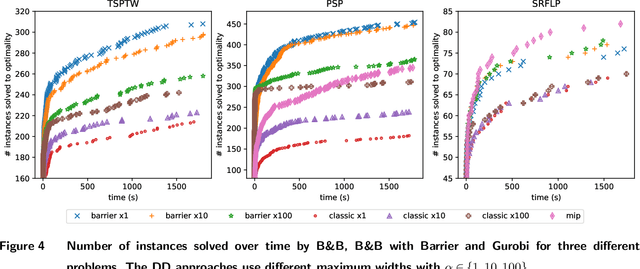
The branch-and-bound algorithm based on decision diagrams introduced by Bergman et al. in 2016 is a framework for solving discrete optimization problems with a dynamic programming formulation. It works by compiling a series of bounded-width decision diagrams that can provide lower and upper bounds for any given subproblem. Eventually, every part of the search space will be either explored or pruned by the algorithm, thus proving optimality. This paper presents new ingredients to speed up the search by exploiting the structure of dynamic programming models. The key idea is to prevent the repeated exploration of nodes corresponding to the same dynamic programming states by storing and querying thresholds in a data structure called the Barrier. These thresholds are based on dominance relations between partial solutions previously found. They can be further strengthened by integrating the filtering techniques introduced by Gillard et al. in 2021. Computational experiments show that the pruning brought by the Barrier allows to significantly reduce the number of nodes expanded by the algorithm. This results in more benchmark instances of difficult optimization problems being solved in less time while using narrower decision diagrams.
Leveraging Memory Effects and Gradient Information in Consensus-Based Optimization: On Global Convergence in Mean-Field Law
Nov 22, 2022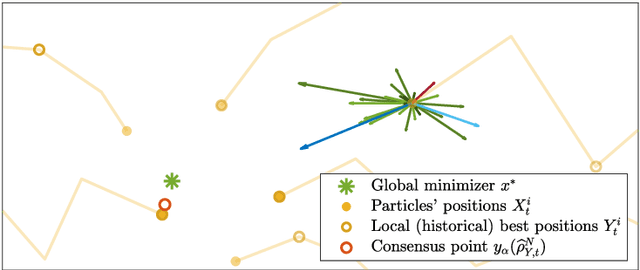
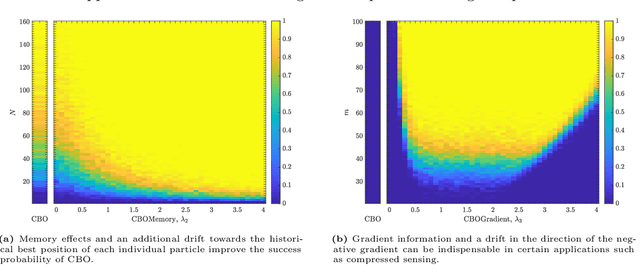
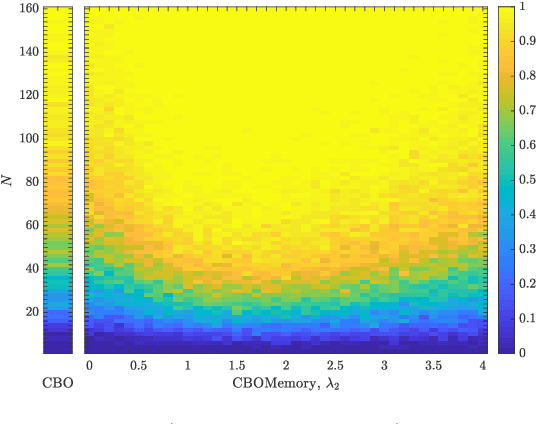

In this paper we study consensus-based optimization (CBO), a versatile, flexibel and customizable optimization method suitable for performing nonconvex and nonsmooth global optimizations in high dimensions. CBO is a multi-particle metaheuristic, which is effective in various applications and at the same time amenable to theoretical analysis thanks to its minimalistic design. The underlying dynamics, however, is flexible enough to incorporate different mechanisms widely used in evolutionary computation and machine learning, as we show by analyzing a variant of CBO which makes use of memory effects and gradient information. We rigorously prove that this dynamics converges to a global minimizer of the objective function in mean-field law for a vast class of functions under minimal assumptions on the initialization of the method. The proof in particular reveals how to leverage further, in some applications advantageous, forces in the dynamics without loosing provable global convergence. To demonstrate the benefit of the herein investigated memory effects and gradient information in certain applications, we present numerical evidence for the superiority of this CBO variant in applications such as machine learning and compressed sensing, which en passant widen the scope of applications of CBO.
Cosmology from Galaxy Redshift Surveys with PointNet
Nov 22, 2022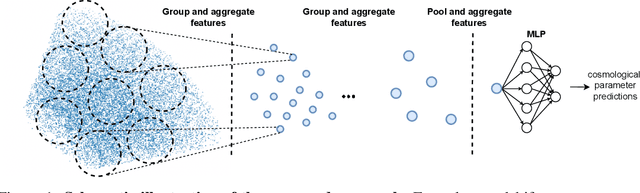
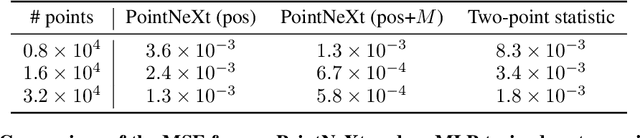
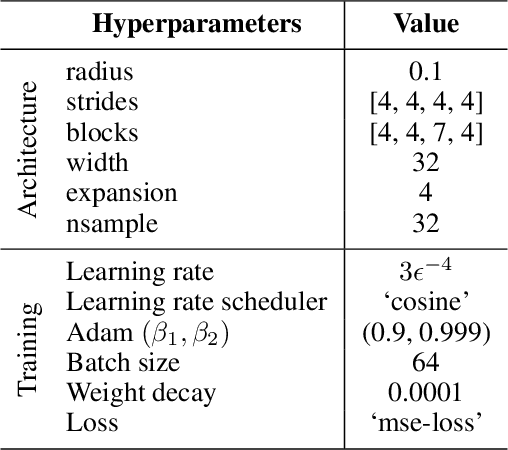
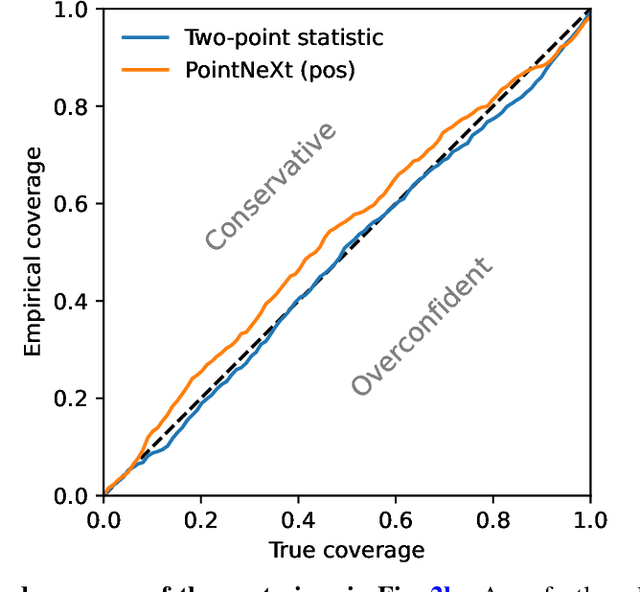
In recent years, deep learning approaches have achieved state-of-the-art results in the analysis of point cloud data. In cosmology, galaxy redshift surveys resemble such a permutation invariant collection of positions in space. These surveys have so far mostly been analysed with two-point statistics, such as power spectra and correlation functions. The usage of these summary statistics is best justified on large scales, where the density field is linear and Gaussian. However, in light of the increased precision expected from upcoming surveys, the analysis of -- intrinsically non-Gaussian -- small angular separations represents an appealing avenue to better constrain cosmological parameters. In this work, we aim to improve upon two-point statistics by employing a \textit{PointNet}-like neural network to regress the values of the cosmological parameters directly from point cloud data. Our implementation of PointNets can analyse inputs of $\mathcal{O}(10^4) - \mathcal{O}(10^5)$ galaxies at a time, which improves upon earlier work for this application by roughly two orders of magnitude. Additionally, we demonstrate the ability to analyse galaxy redshift survey data on the lightcone, as opposed to previously static simulation boxes at a given fixed redshift.
Design and Performance Analysis of Hardware Realization of 3GPP Physical Layer for 5G Cell Search
Nov 22, 2022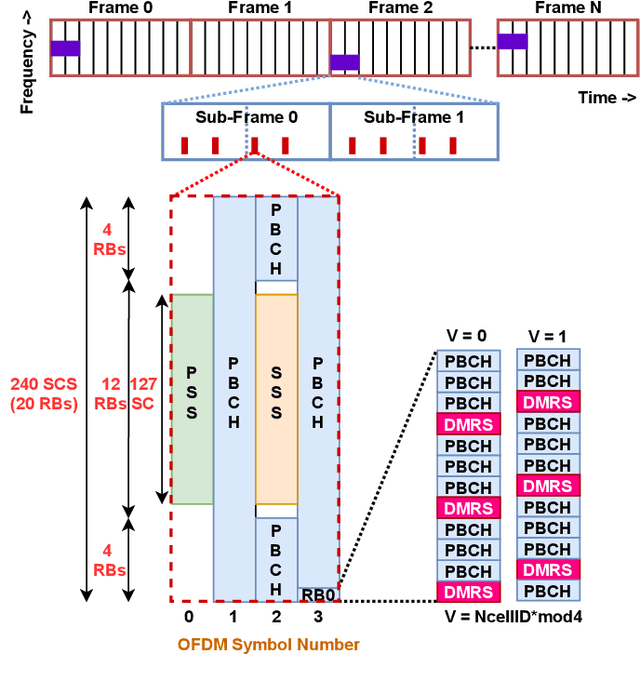
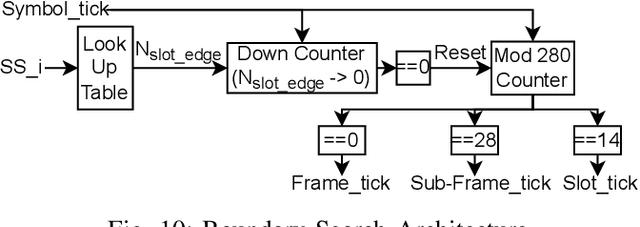
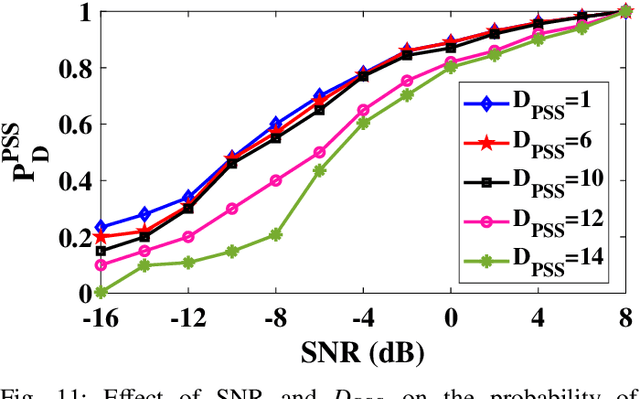
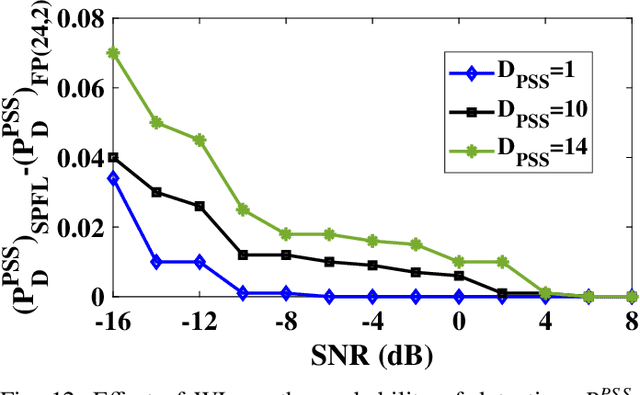
5G Cell Search (CS) is the first step for user equipment (UE) to initiate the communication with the 5G node B (gNB) every time it is powered ON. In cellular networks, CS is accomplished via synchronization signals (SS) broadcasted by gNB. 5G 3rd generation partnership project (3GPP) specifications offer a detailed discussion on the SS generation at gNB but a limited understanding of their blind search, and detection is available. Unlike 4G, 5G SS may not be transmitted at the center of carrier frequency and their frequency location is unknown to UE. In this work, we demonstrate the 5G CS by designing 3GPP compatible hardware realization of the physical layer (PHY) of the gNB transmitter and UE receiver. The proposed SS detection explores a novel down-sampling approach resulting in a significant reduction in complexity and latency. Via detailed performance analysis, we analyze the functional correctness, computational complexity, and latency of the proposed approach for different word lengths, signal-to-noise ratio (SNR), and down-sampling factors. We demonstrate the complete CS functionality on GNU Radio-based RFNoC framework and USRP-FPGA platform. The 3GPP compatibility and demonstration on hardware strengthen the commercial significance of the proposed work.
A Differential Attention Fusion Model Based on Transformer for Time Series Forecasting
Feb 23, 2022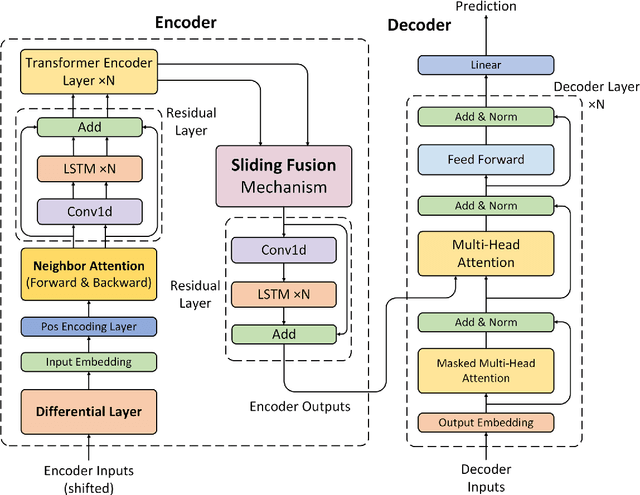
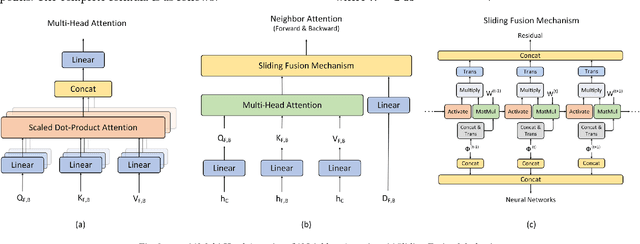
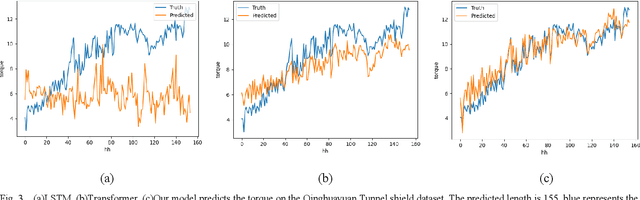
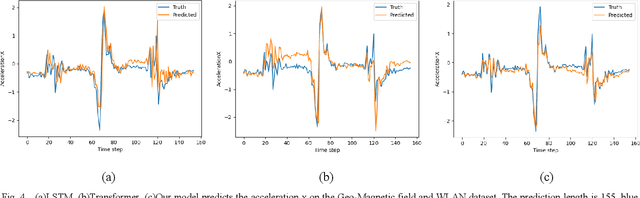
Time series forecasting is widely used in the fields of equipment life cycle forecasting, weather forecasting, traffic flow forecasting, and other fields. Recently, some scholars have tried to apply Transformer to time series forecasting because of its powerful parallel training ability. However, the existing Transformer methods do not pay enough attention to the small time segments that play a decisive role in prediction, making it insensitive to small changes that affect the trend of time series, and it is difficult to effectively learn continuous time-dependent features. To solve this problem, we propose a differential attention fusion model based on Transformer, which designs the differential layer, neighbor attention, sliding fusion mechanism, and residual layer on the basis of classical Transformer architecture. Specifically, the differences of adjacent time points are extracted and focused by difference and neighbor attention. The sliding fusion mechanism fuses various features of each time point so that the data can participate in encoding and decoding without losing important information. The residual layer including convolution and LSTM further learns the dependence between time points and enables our model to carry out deeper training. A large number of experiments on three datasets show that the prediction results produced by our method are favorably comparable to the state-of-the-art.
Efficient block contrastive learning via parameter-free meta-node approximation
Sep 28, 2022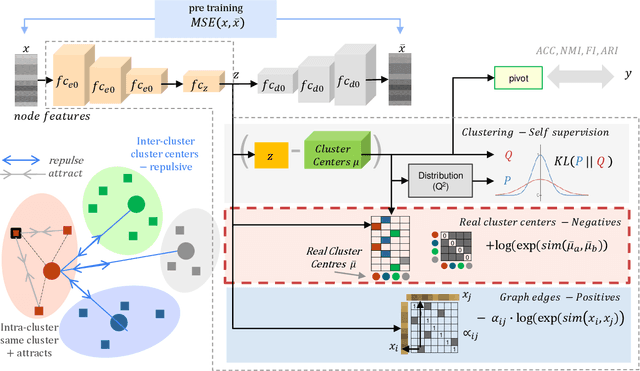
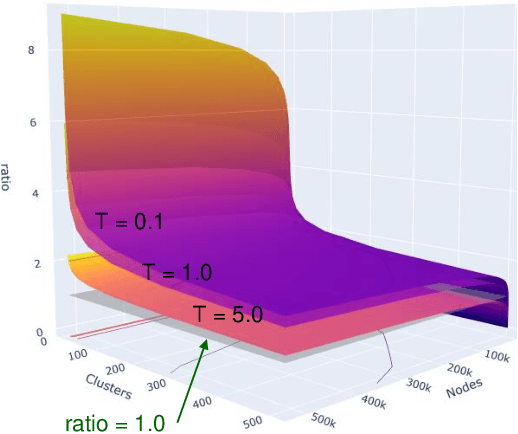
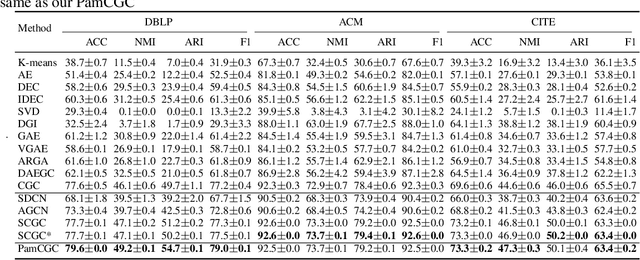
Contrastive learning has recently achieved remarkable success in many domains including graphs. However contrastive loss, especially for graphs, requires a large number of negative samples which is unscalable and computationally prohibitive with a quadratic time complexity. Sub-sampling is not optimal and incorrect negative sampling leads to sampling bias. In this work, we propose a meta-node based approximation technique that can (a) proxy all negative combinations (b) in quadratic cluster size time complexity, (c) at graph level, not node level, and (d) exploit graph sparsity. By replacing node-pairs with additive cluster-pairs, we compute the negatives in cluster-time at graph level. The resulting Proxy approximated meta-node Contrastive (PamC) loss, based on simple optimized GPU operations, captures the full set of negatives, yet is efficient with a linear time complexity. By avoiding sampling, we effectively eliminate sample bias. We meet the criterion for larger number of samples, thus achieving block-contrastiveness, which is proven to outperform pair-wise losses. We use learnt soft cluster assignments for the meta-node constriction, and avoid possible heterophily and noise added during edge creation. Theoretically, we show that real world graphs easily satisfy conditions necessary for our approximation. Empirically, we show promising accuracy gains over state-of-the-art graph clustering on 6 benchmarks. Importantly, we gain substantially in efficiency; up to 3x in training time, 1.8x in inference time and over 5x in GPU memory reduction.
Deep conditional transformation models for survival analysis
Oct 20, 2022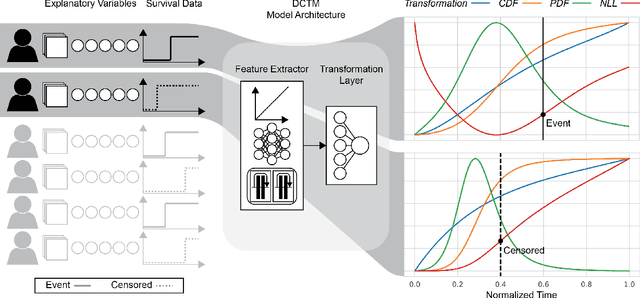
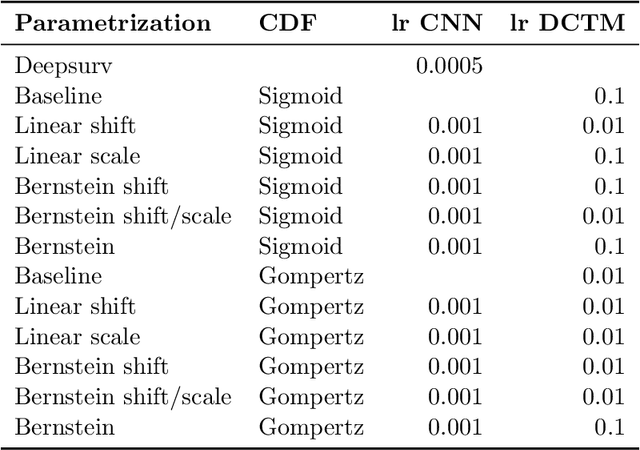
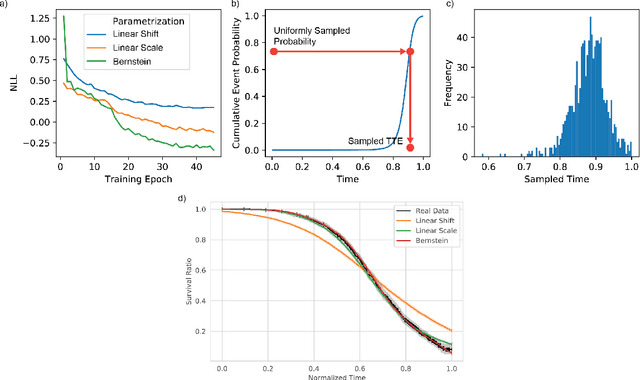
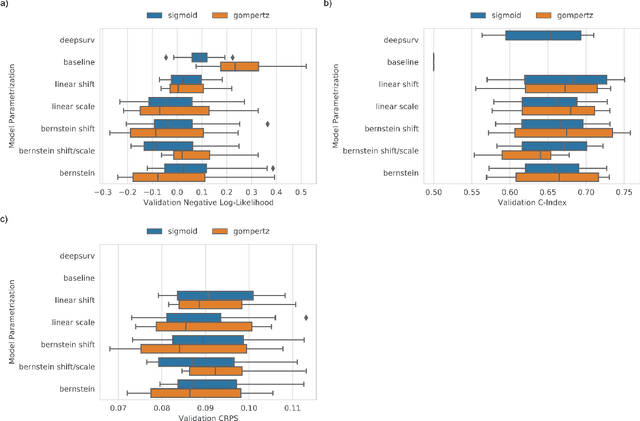
An every increasing number of clinical trials features a time-to-event outcome and records non-tabular patient data, such as magnetic resonance imaging or text data in the form of electronic health records. Recently, several neural-network based solutions have been proposed, some of which are binary classifiers. Parametric, distribution-free approaches which make full use of survival time and censoring status have not received much attention. We present deep conditional transformation models (DCTMs) for survival outcomes as a unifying approach to parametric and semiparametric survival analysis. DCTMs allow the specification of non-linear and non-proportional hazards for both tabular and non-tabular data and extend to all types of censoring and truncation. On real and semi-synthetic data, we show that DCTMs compete with state-of-the-art DL approaches to survival analysis.
Stabilizing Machine Learning Prediction of Dynamics: Noise and Noise-inspired Regularization
Nov 09, 2022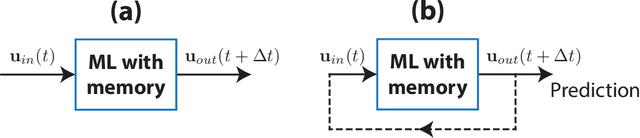
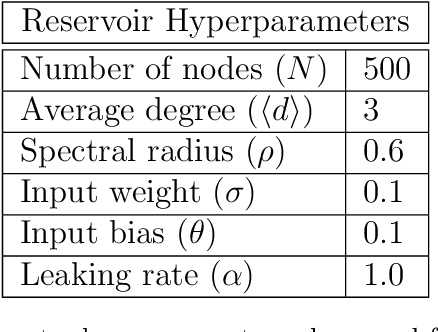
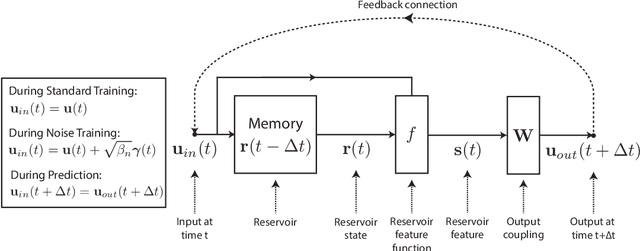
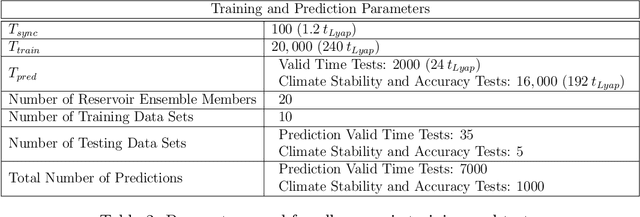
Recent work has shown that machine learning (ML) models can be trained to accurately forecast the dynamics of unknown chaotic dynamical systems. Such ML models can be used to produce both short-term predictions of the state evolution and long-term predictions of the statistical patterns of the dynamics (``climate''). Both of these tasks can be accomplished by employing a feedback loop, whereby the model is trained to predict forward one time step, then the trained model is iterated for multiple time steps with its output used as the input. In the absence of mitigating techniques, however, this technique can result in artificially rapid error growth, leading to inaccurate predictions and/or climate instability. In this article, we systematically examine the technique of adding noise to the ML model input during training as a means to promote stability and improve prediction accuracy. Furthermore, we introduce Linearized Multi-Noise Training (LMNT), a regularization technique that deterministically approximates the effect of many small, independent noise realizations added to the model input during training. Our case study uses reservoir computing, a machine-learning method using recurrent neural networks, to predict the spatiotemporal chaotic Kuramoto-Sivashinsky equation. We find that reservoir computers trained with noise or with LMNT produce climate predictions that appear to be indefinitely stable and have a climate very similar to the true system, while reservoir computers trained without regularization are unstable. Compared with other types of regularization that yield stability in some cases, we find that both short-term and climate predictions from reservoir computers trained with noise or with LMNT are substantially more accurate. Finally, we show that the deterministic aspect of our LMNT regularization facilitates fast hyperparameter tuning when compared to training with noise.
A Critical Analysis of Classifier Selection in Learned Bloom Filters
Nov 28, 2022

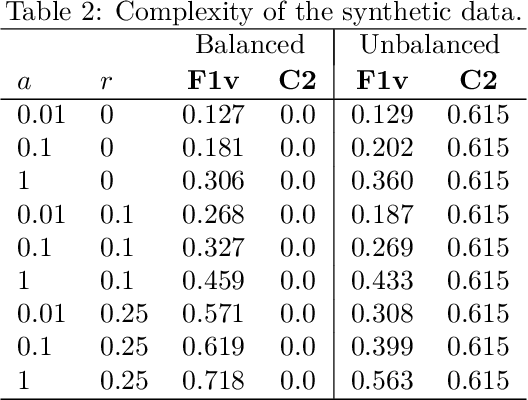
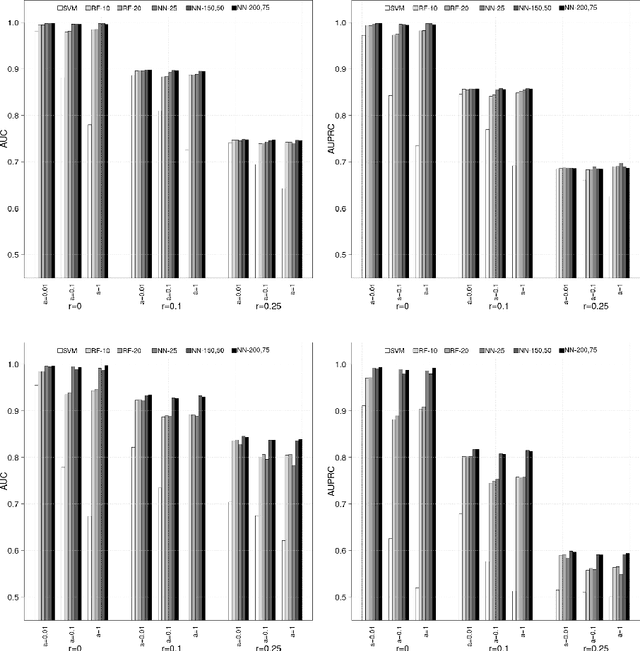
Learned Bloom Filters, i.e., models induced from data via machine learning techniques and solving the approximate set membership problem, have recently been introduced with the aim of enhancing the performance of standard Bloom Filters, with special focus on space occupancy. Unlike in the classical case, the "complexity" of the data used to build the filter might heavily impact on its performance. Therefore, here we propose the first in-depth analysis, to the best of our knowledge, for the performance assessment of a given Learned Bloom Filter, in conjunction with a given classifier, on a dataset of a given classification complexity. Indeed, we propose a novel methodology, supported by software, for designing, analyzing and implementing Learned Bloom Filters in function of specific constraints on their multi-criteria nature (that is, constraints involving space efficiency, false positive rate, and reject time). Our experiments show that the proposed methodology and the supporting software are valid and useful: we find out that only two classifiers have desirable properties in relation to problems with different data complexity, and, interestingly, none of them has been considered so far in the literature. We also experimentally show that the Sandwiched variant of Learned Bloom filters is the most robust to data complexity and classifier performance variability, as well as those usually having smaller reject times. The software can be readily used to test new Learned Bloom Filter proposals, which can be compared with the best ones identified here.