 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Trial-Based Dominance Enables Non-Parametric Tests to Compare both the Speed and Accuracy of Stochastic Optimizers
Dec 19, 2022


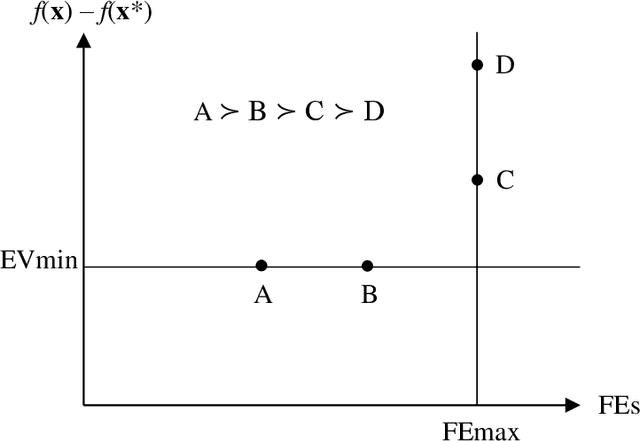
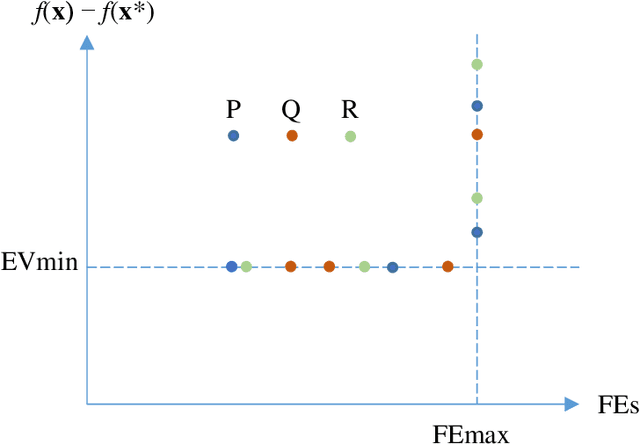
Non-parametric tests can determine the better of two stochastic optimization algorithms when benchmarking results are ordinal, like the final fitness values of multiple trials. For many benchmarks, however, a trial can also terminate once it reaches a pre-specified target value. When only some trials reach the target value, two variables characterize a trial's outcome: the time it takes to reach the target value (or not) and its final fitness value. This paper describes a simple way to impose linear order on this two-variable trial data set so that traditional non-parametric methods can determine the better algorithm when neither dominates. We illustrate the method with the Mann-Whitney U-test. A simulation demonstrates that U-scores are much more effective than dominance when tasked with identifying the better of two algorithms. We test U-scores by having them determine the winners of the CEC 2022 Special Session and Competition on Real-Parameter Numerical Optimization.
Time Shifts to Reduce the Size of Reservoir Computers
May 03, 2022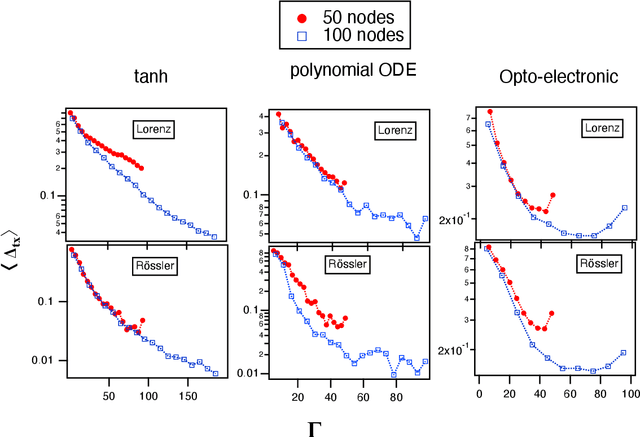
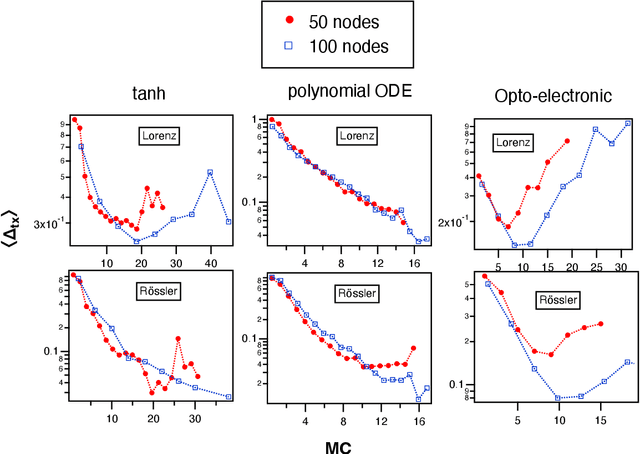
A reservoir computer is a type of dynamical system arranged to do computation. Typically, a reservoir computer is constructed by connecting a large number of nonlinear nodes in a network that includes recurrent connections. In order to achieve accurate results, the reservoir usually contains hundreds to thousands of nodes. This high dimensionality makes it difficult to analyze the reservoir computer using tools from dynamical systems theory. Additionally, the need to create and connect large numbers of nonlinear nodes makes it difficult to design and build analog reservoir computers that can be faster and consume less power than digital reservoir computers. We demonstrate here that a reservoir computer may be divided into two parts; a small set of nonlinear nodes (the reservoir), and a separate set of time-shifted reservoir output signals. The time-shifted output signals serve to increase the rank and memory of the reservoir computer, and the set of nonlinear nodes may create an embedding of the input dynamical system. We use this time-shifting technique to obtain excellent performance from an opto-electronic delay-based reservoir computer with only a small number of virtual nodes. Because only a few nonlinear nodes are required, construction of a reservoir computer becomes much easier, and delay-based reservoir computers can operate at much higher speeds.
Graph Federated Learning for CIoT Devices in Smart Home Applications
Dec 29, 2022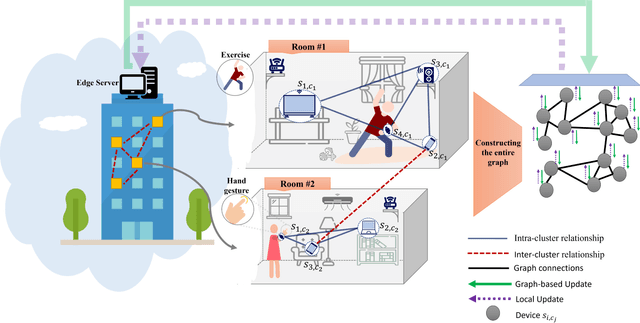
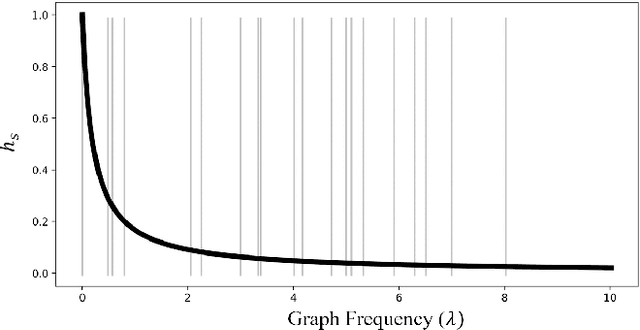
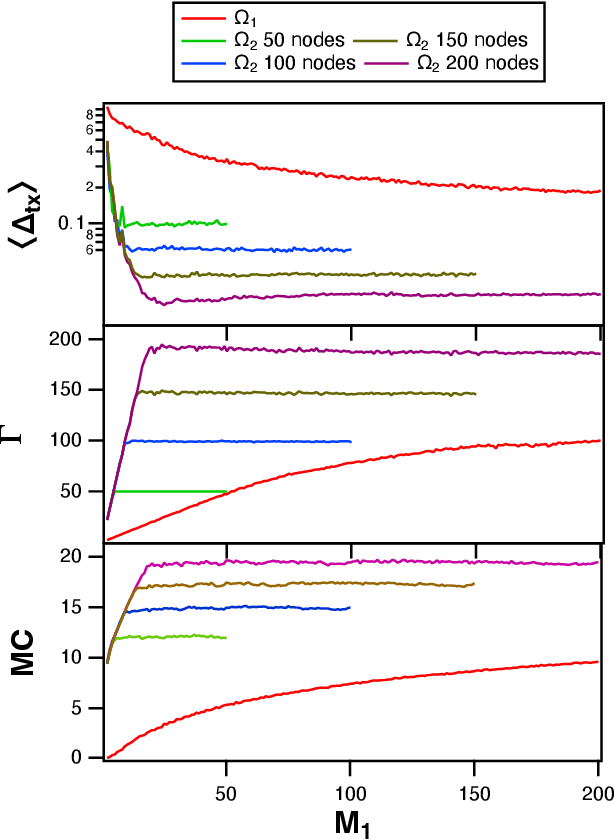
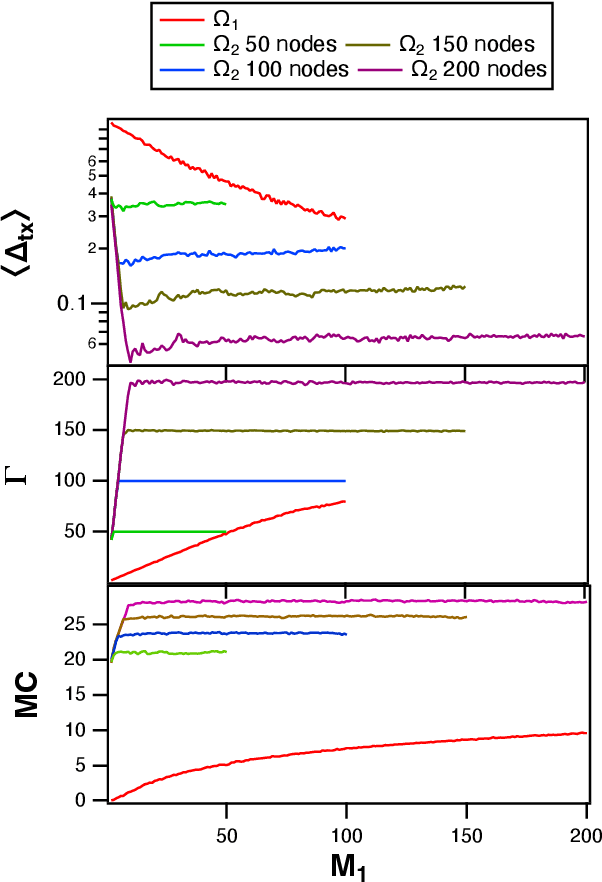
This paper deals with the problem of statistical and system heterogeneity in a cross-silo Federated Learning (FL) framework where there exist a limited number of Consumer Internet of Things (CIoT) devices in a smart building. We propose a novel Graph Signal Processing (GSP)-inspired aggregation rule based on graph filtering dubbed ``G-Fedfilt''. The proposed aggregator enables a structured flow of information based on the graph's topology. This behavior allows capturing the interconnection of CIoT devices and training domain-specific models. The embedded graph filter is equipped with a tunable parameter which enables a continuous trade-off between domain-agnostic and domain-specific FL. In the case of domain-agnostic, it forces G-Fedfilt to act similar to the conventional Federated Averaging (FedAvg) aggregation rule. The proposed G-Fedfilt also enables an intrinsic smooth clustering based on the graph connectivity without explicitly specified which further boosts the personalization of the models in the framework. In addition, the proposed scheme enjoys a communication-efficient time-scheduling to alleviate the system heterogeneity. This is accomplished by adaptively adjusting the amount of training data samples and sparsity of the models' gradients to reduce communication desynchronization and latency. Simulation results show that the proposed G-Fedfilt achieves up to $3.99\% $ better classification accuracy than the conventional FedAvg when concerning model personalization on the statistically heterogeneous local datasets, while it is capable of yielding up to $2.41\%$ higher accuracy than FedAvg in the case of testing the generalization of the models.
Near-Optimal Non-Parametric Sequential Tests and Confidence Sequences with Possibly Dependent Observations
Dec 29, 2022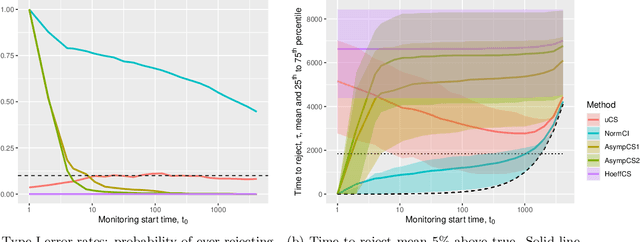
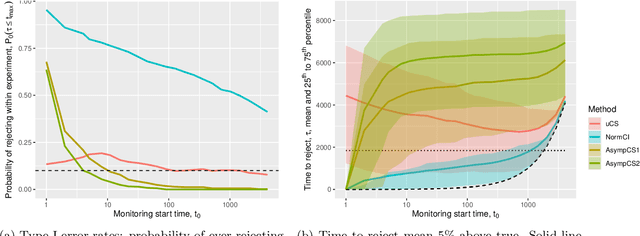
Sequential testing, always-valid $p$-values, and confidence sequences promise flexible statistical inference and on-the-fly decision making. However, unlike fixed-$n$ inference based on asymptotic normality, existing sequential tests either make parametric assumptions and end up under-covering/over-rejecting when these fail or use non-parametric but conservative concentration inequalities and end up over-covering/under-rejecting. To circumvent these issues, we sidestep exact at-least-$\alpha$ coverage and focus on asymptotically exact coverage and asymptotic optimality. That is, we seek sequential tests whose probability of ever rejecting a true hypothesis asymptotically approaches $\alpha$ and whose expected time to reject a false hypothesis approaches a lower bound on all tests with asymptotic coverage at least $\alpha$, both under an appropriate asymptotic regime. We permit observations to be both non-parametric and dependent and focus on testing whether the observations form a martingale difference sequence. We propose the universal sequential probability ratio test (uSPRT), a slight modification to the normal-mixture sequential probability ratio test, where we add a burn-in period and adjust thresholds accordingly. We show that even in this very general setting, the uSPRT is asymptotically optimal under mild generic conditions. We apply the results to stabilized estimating equations to test means, treatment effects, etc. Our results also provide corresponding guarantees for the implied confidence sequences. Numerical simulations verify our guarantees and the benefits of the uSPRT over alternatives.
Biologically Plausible Learning on Neuromorphic Hardware Architectures
Dec 29, 2022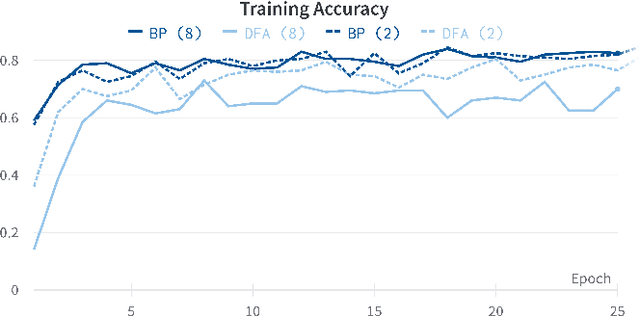
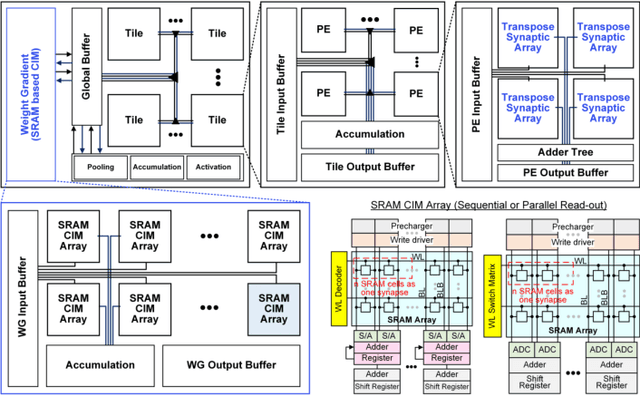
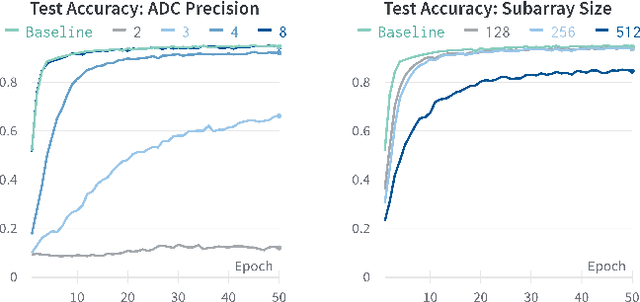
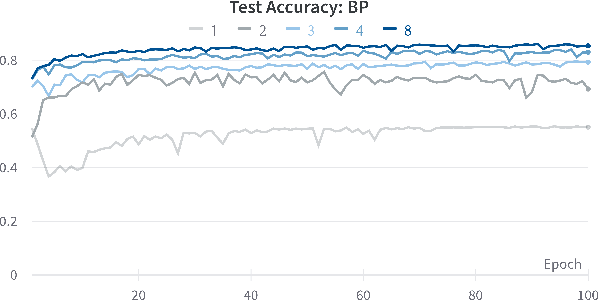
With an ever-growing number of parameters defining increasingly complex networks, Deep Learning has led to several breakthroughs surpassing human performance. As a result, data movement for these millions of model parameters causes a growing imbalance known as the memory wall. Neuromorphic computing is an emerging paradigm that confronts this imbalance by performing computations directly in analog memories. On the software side, the sequential Backpropagation algorithm prevents efficient parallelization and thus fast convergence. A novel method, Direct Feedback Alignment, resolves inherent layer dependencies by directly passing the error from the output to each layer. At the intersection of hardware/software co-design, there is a demand for developing algorithms that are tolerable to hardware nonidealities. Therefore, this work explores the interrelationship of implementing bio-plausible learning in-situ on neuromorphic hardware, emphasizing energy, area, and latency constraints. Using the benchmarking framework DNN+NeuroSim, we investigate the impact of hardware nonidealities and quantization on algorithm performance, as well as how network topologies and algorithm-level design choices can scale latency, energy and area consumption of a chip. To the best of our knowledge, this work is the first to compare the impact of different learning algorithms on Compute-In-Memory-based hardware and vice versa. The best results achieved for accuracy remain Backpropagation-based, notably when facing hardware imperfections. Direct Feedback Alignment, on the other hand, allows for significant speedup due to parallelization, reducing training time by a factor approaching N for N-layered networks.
Optimized Sparse Matrix Operations for Reverse Mode Automatic Differentiation
Dec 10, 2022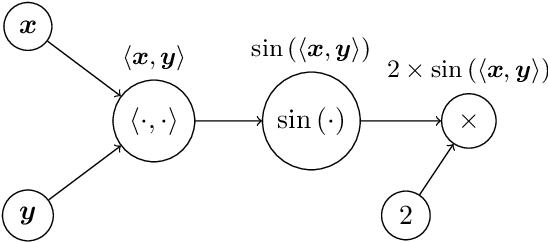
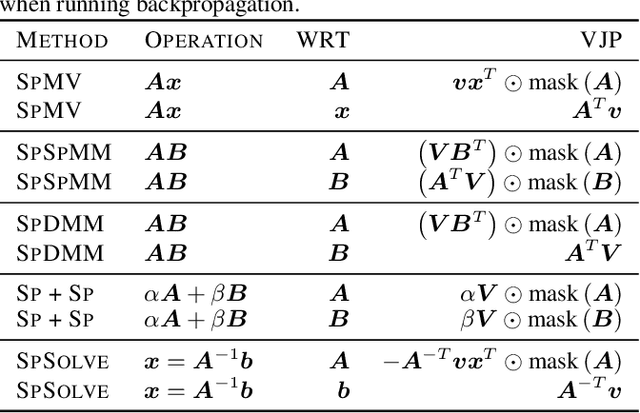

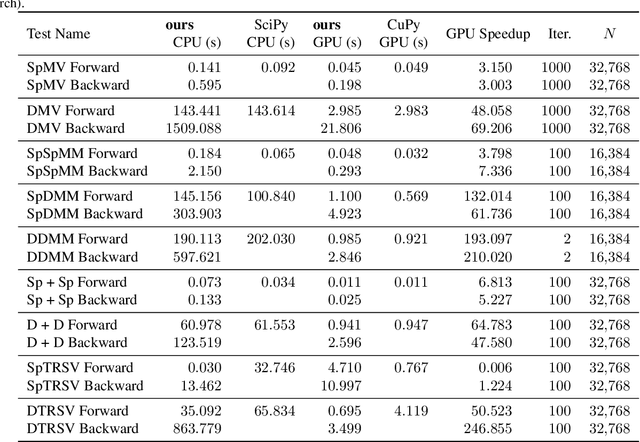
Sparse matrix representations are ubiquitous in computational science and machine learning, leading to significant reductions in compute time, in comparison to dense representation, for problems that have local connectivity. The adoption of sparse representation in leading ML frameworks such as PyTorch is incomplete, however, with support for both automatic differentiation and GPU acceleration missing. In this work, we present an implementation of a CSR-based sparse matrix wrapper for PyTorch with CUDA acceleration for basic matrix operations, as well as automatic differentiability. We also present several applications of the resulting sparse kernels to optimization problems, demonstrating ease of implementation and performance measurements versus their dense counterparts.
Robust Recurrent Neural Network to Identify Ship Motion in Open Water with Performance Guarantees -- Technical Report
Dec 16, 2022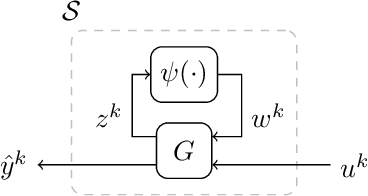
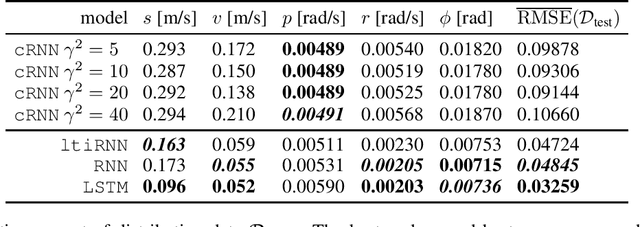
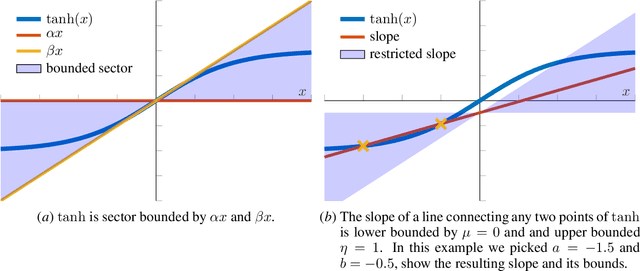
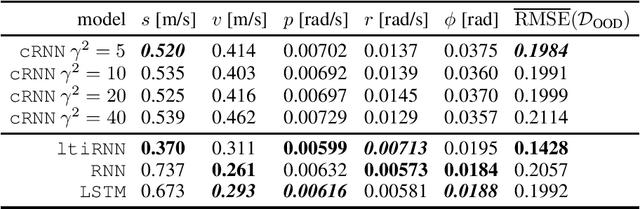
Recurrent neural networks are capable of learning the dynamics of an unknown nonlinear system purely from input-output measurements. However, the resulting models do not provide any stability guarantees on the input-output mapping. In this work, we represent a recurrent neural network as a linear time-invariant system with nonlinear disturbances. By introducing constraints on the parameters, we can guarantee finite gain stability and incremental finite gain stability. We apply this identification method to learn the motion of a four-degrees-of-freedom ship that is moving in open water and compare it against other purely learning-based approaches with unconstrained parameters. Our analysis shows that the constrained recurrent neural network has a lower prediction accuracy on the test set, but it achieves comparable results on an out-of-distribution set and respects stability conditions.
On Safe and Usable Chatbots for Promoting Voter Participation
Dec 16, 2022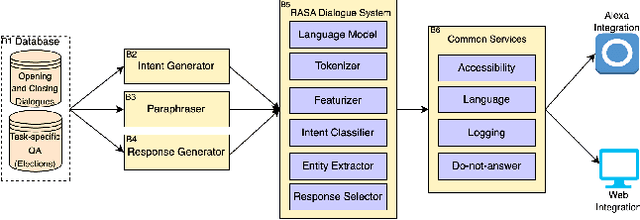
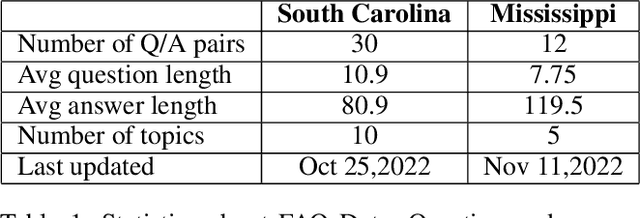
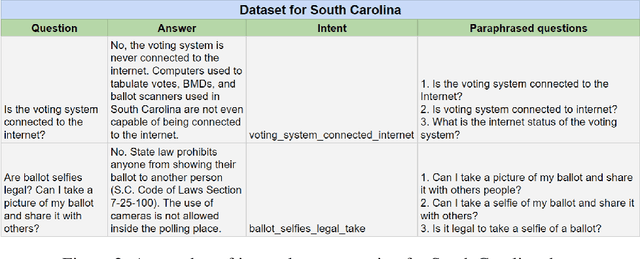
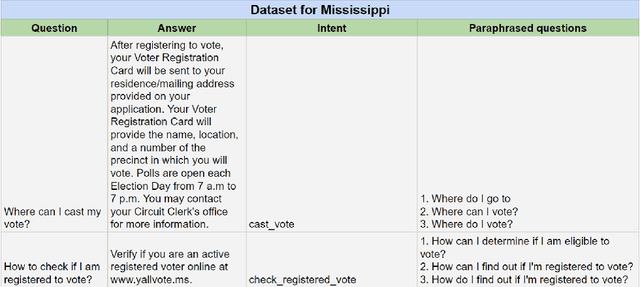
Chatbots, or bots for short, are multi-modal collaborative assistants that can help people complete useful tasks. Usually, when chatbots are referenced in connection with elections, they often draw negative reactions due to the fear of mis-information and hacking. Instead, in this paper, we explore how chatbots may be used to promote voter participation in vulnerable segments of society like senior citizens and first-time voters. In particular, we build a system that amplifies official information while personalizing it to users' unique needs transparently. We discuss its design, build prototypes with frequently asked questions (FAQ) election information for two US states that are low on an ease-of-voting scale, and report on its initial evaluation in a focus group. Our approach can be a win-win for voters, election agencies trying to fulfill their mandate and democracy at large.
Imitation Learning based Auto-Correction of Extrinsic Parameters for A Mixed-Reality Setup
Dec 16, 2022
In this paper, we discuss an imitation learning based method for reducing the calibration error for a mixed reality system consisting of a vision sensor and a projector. Unlike a head mounted display, in this setup, augmented information is available to a human subject via the projection of a scene into the real world. Inherently, the camera and projector need to be calibrated as a stereo setup to project accurate information in 3D space. Previous calibration processes require multiple recording and parameter tuning steps to achieve the desired calibration, which is usually time consuming process. In order to avoid such tedious calibration, we train a CNN model to iteratively correct the extrinsic offset given a QR code and a projected pattern. We discuss the overall system setup, data collection for training, and results of the auto-correction model.
Resolving Indirect Referring Expressions for Entity Selection
Dec 21, 2022
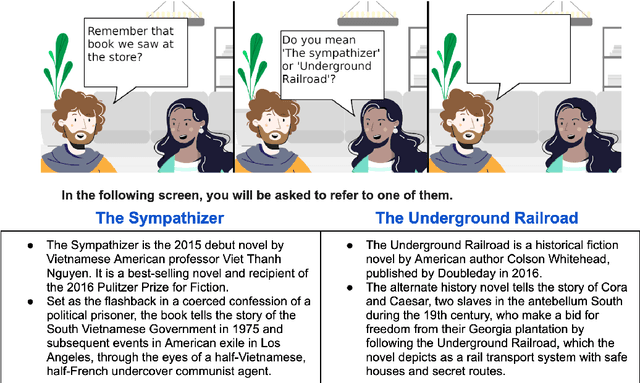

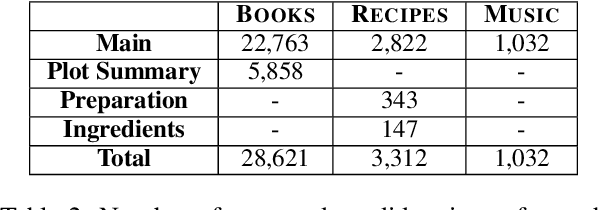
Recent advances in language modeling have enabled new conversational systems. In particular, it is often desirable for people to make choices among specified options when using such systems. We address the problem of reference resolution, when people use natural expressions to choose between real world entities. For example, given the choice `Should we make a Simnel cake or a Pandan cake?' a natural response from a non-expert may be indirect: `let's make the green one'. Reference resolution has been little studied with natural expressions, thus robustly understanding such language has large potential for improving naturalness in dialog, recommendation, and search systems. We create AltEntities (Alternative Entities), a new public dataset of entity pairs and utterances, and develop models for the disambiguation problem. Consisting of 42K indirect referring expressions across three domains, it enables for the first time the study of how large language models can be adapted to this task. We find they achieve 82%-87% accuracy in realistic settings, which while reasonable also invites further advances.