 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Real-time Critical-scenario-generation Framework for Testing Autonomous Driving System
Jun 02, 2022
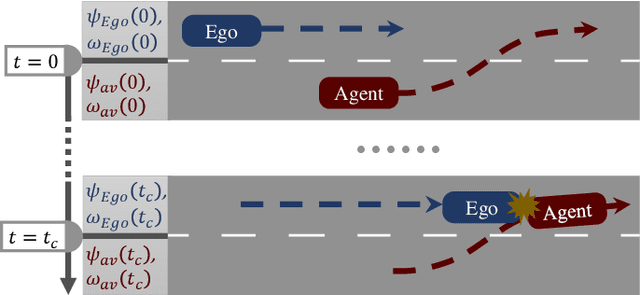
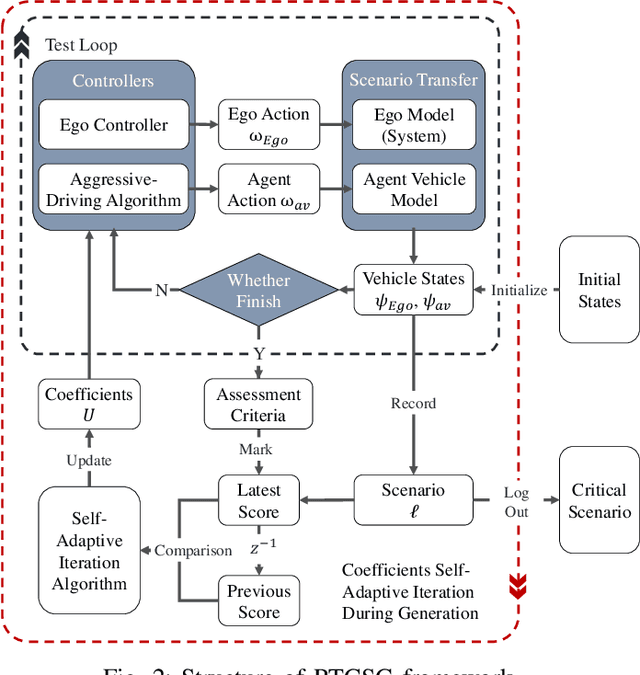
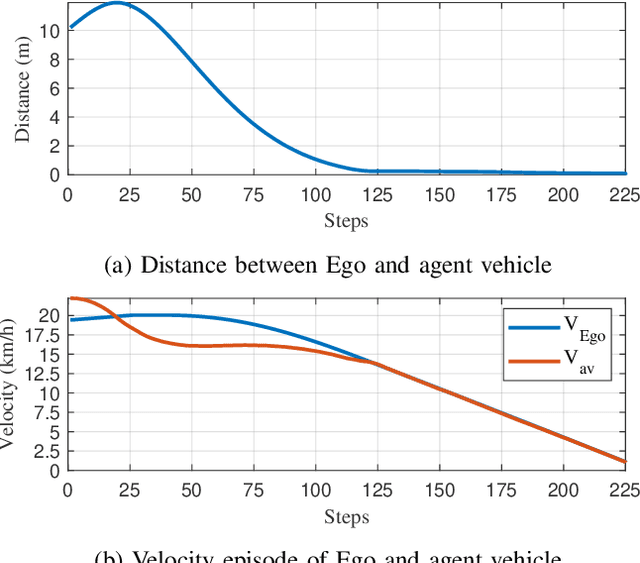
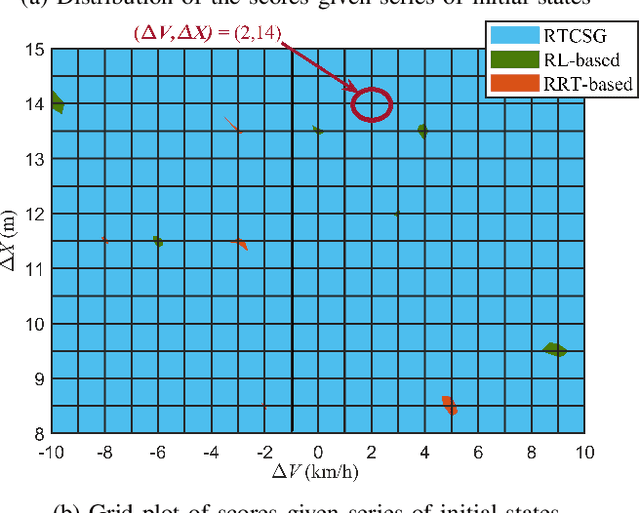
In order to find the most likely failure scenarios which may occur under certain given operation domain, critical-scenario-based test is supposed as an effective and widely used method, which gives suggestions for designers to improve the developing algorithm. However, for the state of art, critical-scenario generation approaches commonly utilize random-search or reinforcement learning methods to generate series of scenarios for a specific algorithm, which takes amounts of computing resource for testing a developing target that is always changing, and inapplicable for testing a real-time system. In this paper, we proposed a real-time critical-scenario-generation (RTCSG) framework to address the above challenges. In our framework, an aggressive-driving algorithm is proposed in controlling the virtual agent vehicles, a specially designed cost function is presented to guide scenarios to evolve towards critical conditions, and a self-adaptive coefficient iteration is designed that enable the approach to operate successfully in different conditions. With our proposed method, the critical-scenarios can be directly generated for the target under test which is a black-box system, and the real-time critical-scenario test can be brought into reality. The simulation results show that our approach is able to obtain more critical scenarios in most conditions than current methods, with a higher stability of success. For a real-time testing, our approach improves the efficiency around 16 times.
GraphAD: A Graph Neural Network for Entity-Wise Multivariate Time-Series Anomaly Detection
May 23, 2022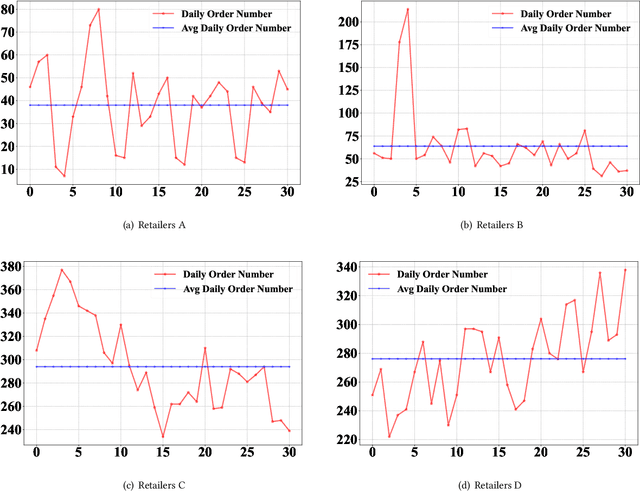
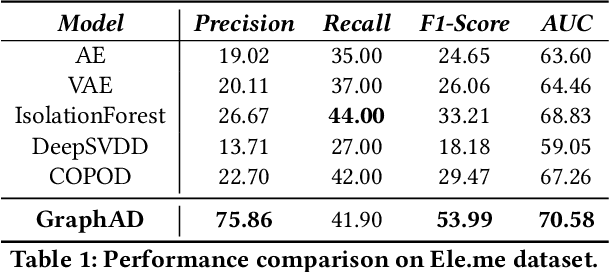
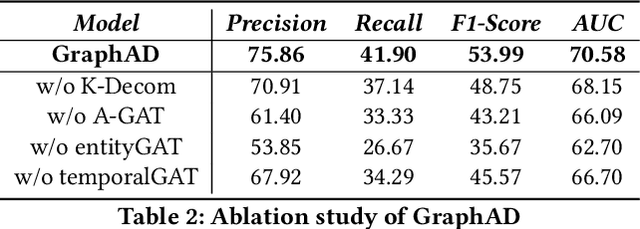
In recent years, the emergence and development of third-party platforms have greatly facilitated the growth of the Online to Offline (O2O) business. However, the large amount of transaction data raises new challenges for retailers, especially anomaly detection in operating conditions. Thus, platforms begin to develop intelligent business assistants with embedded anomaly detection methods to reduce the management burden on retailers. Traditional time-series anomaly detection methods capture underlying patterns from the perspectives of time and attributes, ignoring the difference between retailers in this scenario. Besides, similar transaction patterns extracted by the platforms can also provide guidance to individual retailers and enrich their available information without privacy issues. In this paper, we pose an entity-wise multivariate time-series anomaly detection problem that considers the time-series of each unique entity. To address this challenge, we propose GraphAD, a novel multivariate time-series anomaly detection model based on the graph neural network. GraphAD decomposes the Key Performance Indicator (KPI) into stable and volatility components and extracts their patterns in terms of attributes, entities and temporal perspectives via graph neural networks. We also construct a real-world entity-wise multivariate time-series dataset from the business data of Ele.me. The experimental results on this dataset show that GraphAD significantly outperforms existing anomaly detection methods.
A Search and Detection Autonomous Drone System: from Design to Implementation
Nov 29, 2022
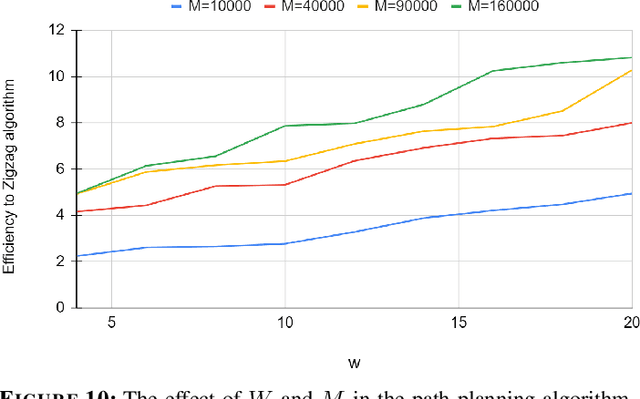
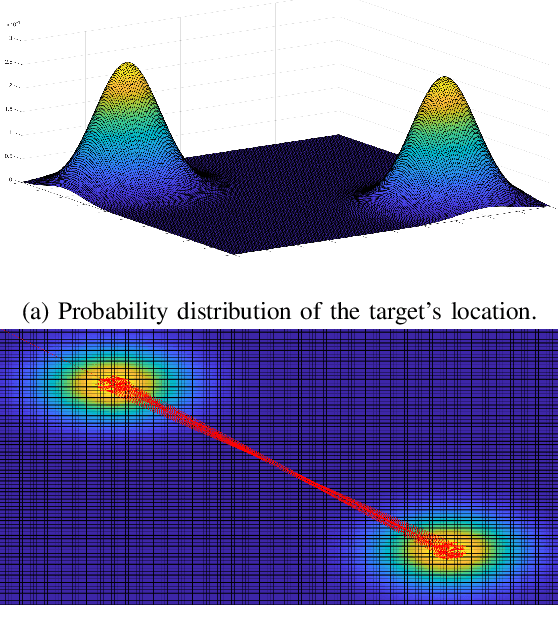

Utilizing autonomous drones or unmanned aerial vehicles (UAVs) has shown great advantages over preceding methods in support of urgent scenarios such as search and rescue (SAR) and wildfire detection. In these operations, search efficiency in terms of the amount of time spent to find the target is crucial since with the passing of time the survivability of the missing person decreases or wildfire management becomes more difficult with disastrous consequences. In this work, it is considered a scenario where a drone is intended to search and detect a missing person (e.g., a hiker or a mountaineer) or a potential fire spot in a given area. In order to obtain the shortest path to the target, a general framework is provided to model the problem of target detection when the target's location is probabilistically known. To this end, two algorithms are proposed: Path planning and target detection. The path planning algorithm is based on Bayesian inference and the target detection is accomplished by means of a residual neural network (ResNet) trained on the image dataset captured by the drone as well as existing pictures and datasets on the web. Through simulation and experiment, the proposed path planning algorithm is compared with two benchmark algorithms. It is shown that the proposed algorithm significantly decreases the average time of the mission.
Regret Analysis of Certainty Equivalence Policies in Continuous-Time Linear-Quadratic Systems
Jun 09, 2022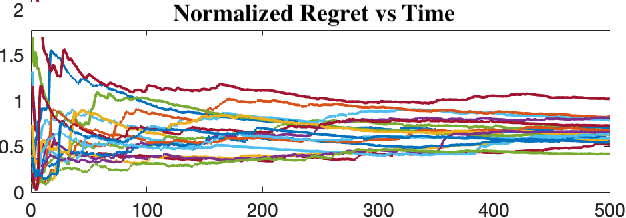
This work studies theoretical performance guarantees of a ubiquitous reinforcement learning policy for controlling the canonical model of stochastic linear-quadratic system. We show that randomized certainty equivalent policy addresses the exploration-exploitation dilemma for minimizing quadratic costs in linear dynamical systems that evolve according to stochastic differential equations. More precisely, we establish square-root of time regret bounds, indicating that randomized certainty equivalent policy learns optimal control actions fast from a single state trajectory. Further, linear scaling of the regret with the number of parameters is shown. The presented analysis introduces novel and useful technical approaches, and sheds light on fundamental challenges of continuous-time reinforcement learning.
Voice Analysis for Stress Detection and Application in Virtual Reality to Improve Public Speaking in Real-time: A Review
Aug 01, 2022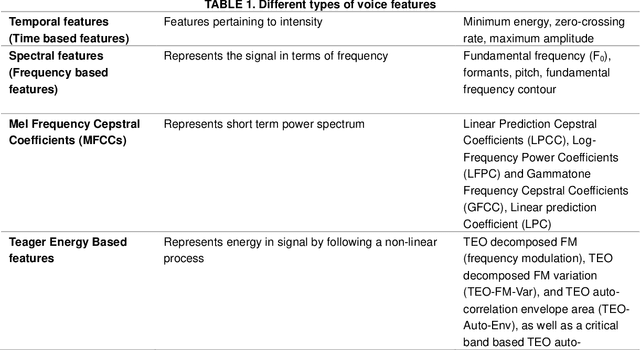
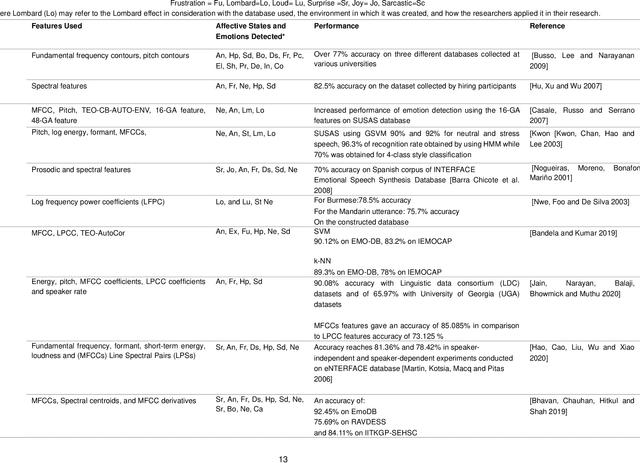
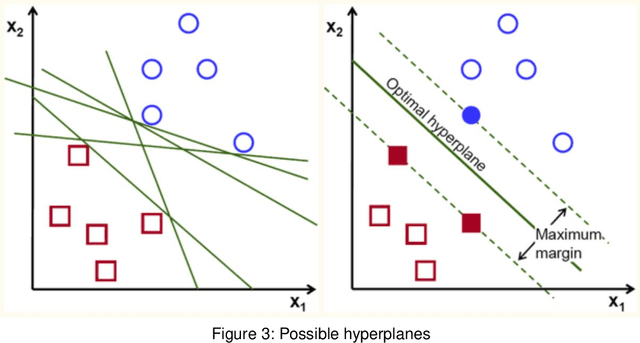
Stress during public speaking is common and adversely affects performance and self-confidence. Extensive research has been carried out to develop various models to recognize emotional states. However, minimal research has been conducted to detect stress during public speaking in real time using voice analysis. In this context, the current review showed that the application of algorithms was not properly explored and helped identify the main obstacles in creating a suitable testing environment while accounting for current complexities and limitations. In this paper, we present our main idea and propose a stress detection computational algorithmic model that could be integrated into a Virtual Reality (VR) application to create an intelligent virtual audience for improving public speaking skills. The developed model, when integrated with VR, will be able to detect excessive stress in real time by analysing voice features correlated to physiological parameters indicative of stress and help users gradually control excessive stress and improve public speaking performance
AdaNeRF: Adaptive Sampling for Real-time Rendering of Neural Radiance Fields
Jul 28, 2022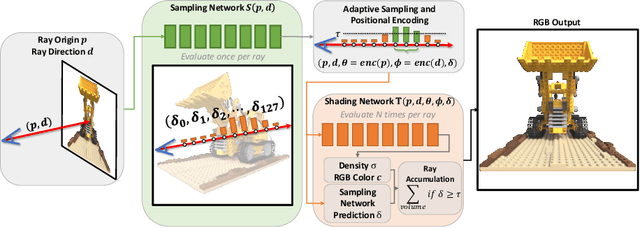
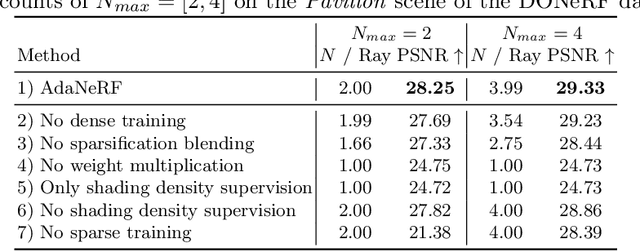
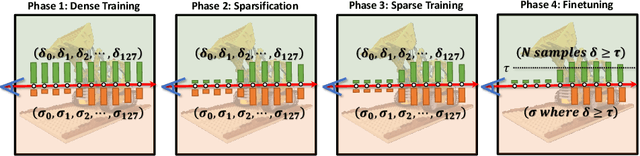
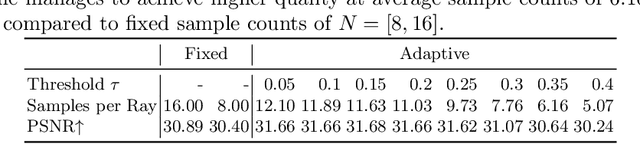
Novel view synthesis has recently been revolutionized by learning neural radiance fields directly from sparse observations. However, rendering images with this new paradigm is slow due to the fact that an accurate quadrature of the volume rendering equation requires a large number of samples for each ray. Previous work has mainly focused on speeding up the network evaluations that are associated with each sample point, e.g., via caching of radiance values into explicit spatial data structures, but this comes at the expense of model compactness. In this paper, we propose a novel dual-network architecture that takes an orthogonal direction by learning how to best reduce the number of required sample points. To this end, we split our network into a sampling and shading network that are jointly trained. Our training scheme employs fixed sample positions along each ray, and incrementally introduces sparsity throughout training to achieve high quality even at low sample counts. After fine-tuning with the target number of samples, the resulting compact neural representation can be rendered in real-time. Our experiments demonstrate that our approach outperforms concurrent compact neural representations in terms of quality and frame rate and performs on par with highly efficient hybrid representations. Code and supplementary material is available at https://thomasneff.github.io/adanerf.
Effective and Efficient Training for Sequential Recommendation Using Cumulative Cross-Entropy Loss
Jan 03, 2023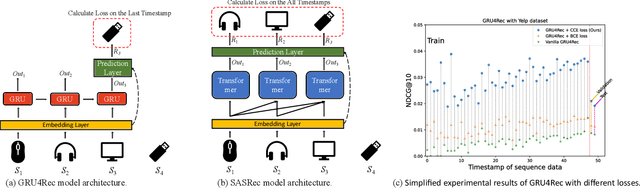
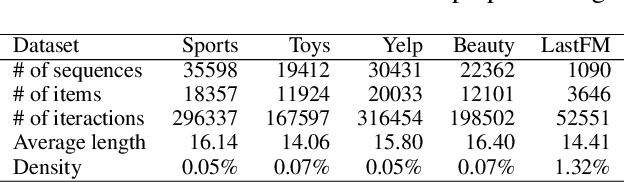
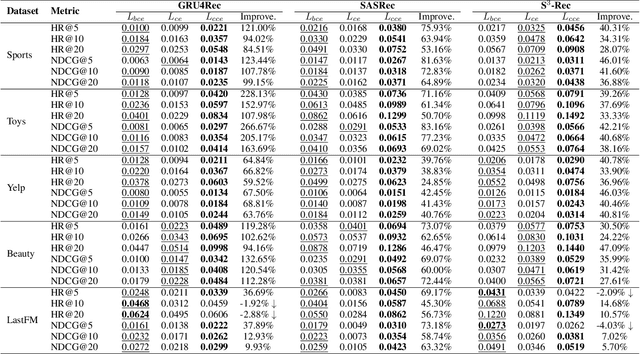
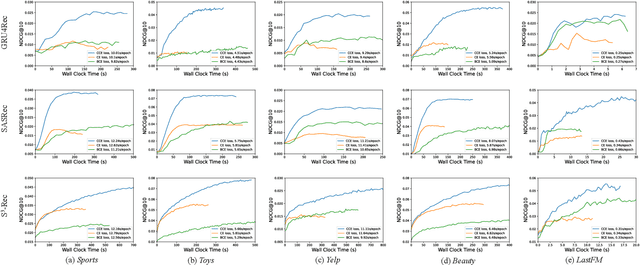
Increasing research interests focus on sequential recommender systems, aiming to model dynamic sequence representation precisely. However, the most commonly used loss function in state-of-the-art sequential recommendation models has essential limitations. To name a few, Bayesian Personalized Ranking (BPR) loss suffers the vanishing gradient problem from numerous negative sampling and predictionbiases; Binary Cross-Entropy (BCE) loss subjects to negative sampling numbers, thereby it is likely to ignore valuable negative examples and reduce the training efficiency; Cross-Entropy (CE) loss only focuses on the last timestamp of the training sequence, which causes low utilization of sequence information and results in inferior user sequence representation. To avoid these limitations, in this paper, we propose to calculate Cumulative Cross-Entropy (CCE) loss over the sequence. CCE is simple and direct, which enjoys the virtues of painless deployment, no negative sampling, and effective and efficient training. We conduct extensive experiments on five benchmark datasets to demonstrate the effectiveness and efficiency of CCE. The results show that employing CCE loss on three state-of-the-art models GRU4Rec, SASRec, and S3-Rec can reach 125.63%, 69.90%, and 33.24% average improvement of full ranking NDCG@5, respectively. Using CCE, the performance curve of the models on the test data increases rapidly with the wall clock time, and is superior to that of other loss functions in almost the whole process of model training.
Graphical House Allocation
Jan 03, 2023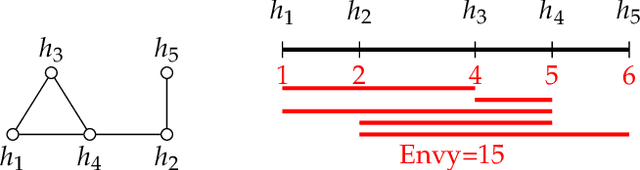
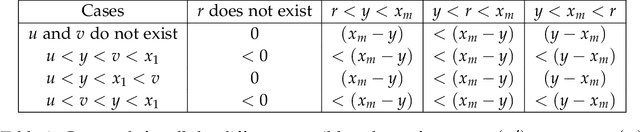

The classical house allocation problem involves assigning $n$ houses (or items) to $n$ agents according to their preferences. A key criterion in such problems is satisfying some fairness constraints such as envy-freeness. We consider a generalization of this problem wherein the agents are placed along the vertices of a graph (corresponding to a social network), and each agent can only experience envy towards its neighbors. Our goal is to minimize the aggregate envy among the agents as a natural fairness objective, i.e., the sum of all pairwise envy values over all edges in a social graph. When agents have identical and evenly-spaced valuations, our problem reduces to the well-studied problem of linear arrangements. For identical valuations with possibly uneven spacing, we show a number of deep and surprising ways in which our setting is a departure from this classical problem. More broadly, we contribute several structural and computational results for various classes of graphs, including NP-hardness results for disjoint unions of paths, cycles, stars, or cliques, and fixed-parameter tractable (and, in some cases, polynomial-time) algorithms for paths, cycles, stars, cliques, and their disjoint unions. Additionally, a conceptual contribution of our work is the formulation of a structural property for disconnected graphs that we call separability which results in efficient parameterized algorithms for finding optimal allocations.
Improving a sequence-to-sequence nlp model using a reinforcement learning policy algorithm
Dec 28, 2022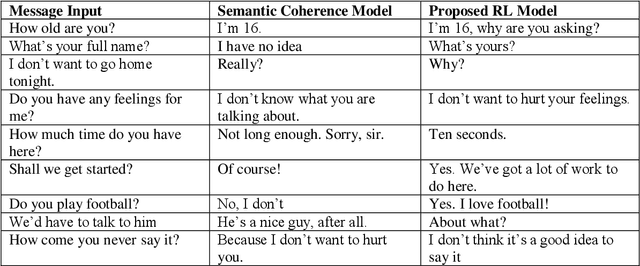


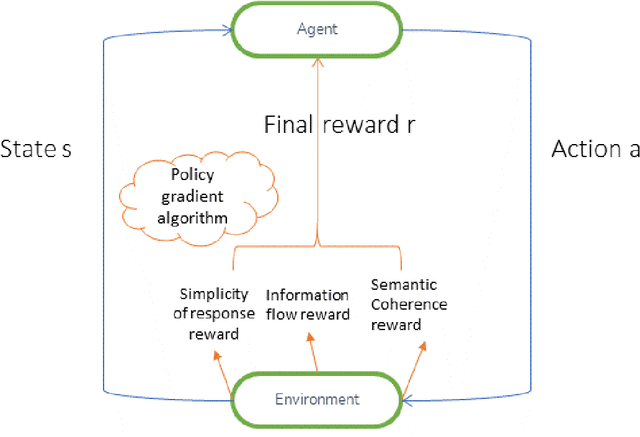
Nowadays, the current neural network models of dialogue generation(chatbots) show great promise for generating answers for chatty agents. But they are short-sighted in that they predict utterances one at a time while disregarding their impact on future outcomes. Modelling a dialogue's future direction is critical for generating coherent, interesting dialogues, a need that has led traditional NLP dialogue models that rely on reinforcement learning. In this article, we explain how to combine these objectives by using deep reinforcement learning to predict future rewards in chatbot dialogue. The model simulates conversations between two virtual agents, with policy gradient methods used to reward sequences that exhibit three useful conversational characteristics: the flow of informality, coherence, and simplicity of response (related to forward-looking function). We assess our model based on its diversity, length, and complexity with regard to humans. In dialogue simulation, evaluations demonstrated that the proposed model generates more interactive responses and encourages a more sustained successful conversation. This work commemorates a preliminary step toward developing a neural conversational model based on the long-term success of dialogues.
* Published in Proceedings of Artificial Intelligence, Soft Computing and Applications 12th International Conference on Artificial Intelligence, Soft Computing and Applications (AIAA 2022) December 22 ~ 24, 2022, Sydney, Australia Volume Editors : David C. Wyld, Dhinaharan Nagamalai (Eds) ISBN : 978-1-925953-83-1
Robustifying Markowitz
Dec 28, 2022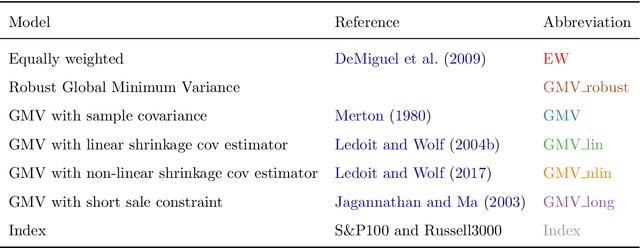
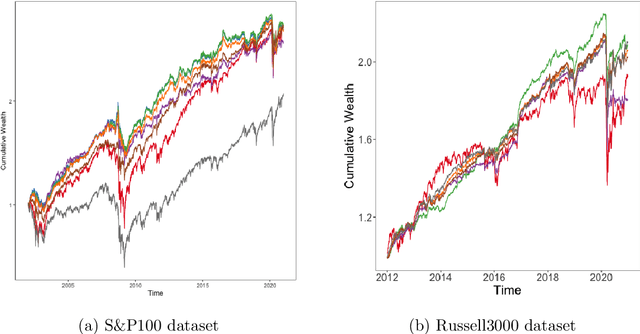
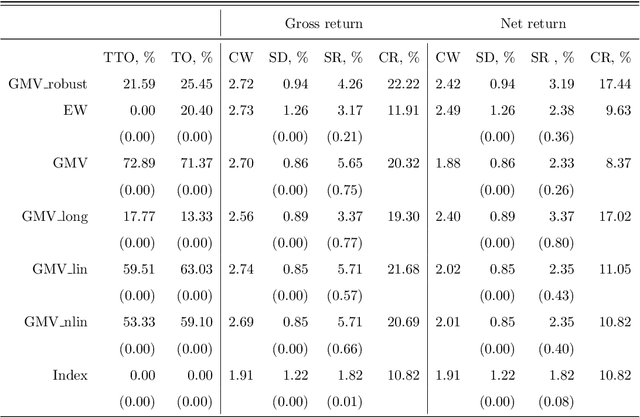
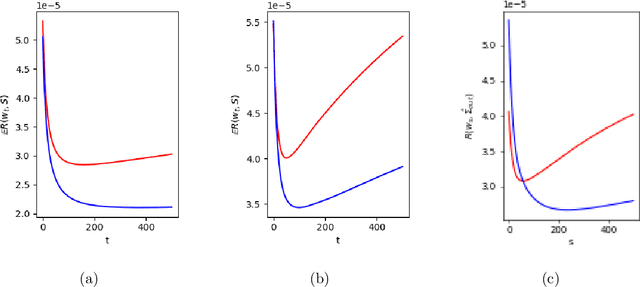
Markowitz mean-variance portfolios with sample mean and covariance as input parameters feature numerous issues in practice. They perform poorly out of sample due to estimation error, they experience extreme weights together with high sensitivity to change in input parameters. The heavy-tail characteristics of financial time series are in fact the cause for these erratic fluctuations of weights that consequently create substantial transaction costs. In robustifying the weights we present a toolbox for stabilizing costs and weights for global minimum Markowitz portfolios. Utilizing a projected gradient descent (PGD) technique, we avoid the estimation and inversion of the covariance operator as a whole and concentrate on robust estimation of the gradient descent increment. Using modern tools of robust statistics we construct a computationally efficient estimator with almost Gaussian properties based on median-of-means uniformly over weights. This robustified Markowitz approach is confirmed by empirical studies on equity markets. We demonstrate that robustified portfolios reach the lowest turnover compared to shrinkage-based and constrained portfolios while preserving or slightly improving out-of-sample performance.