 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Human Activity Recognition from Wi-Fi CSI Data Using Principal Component-Based Wavelet CNN
Dec 26, 2022
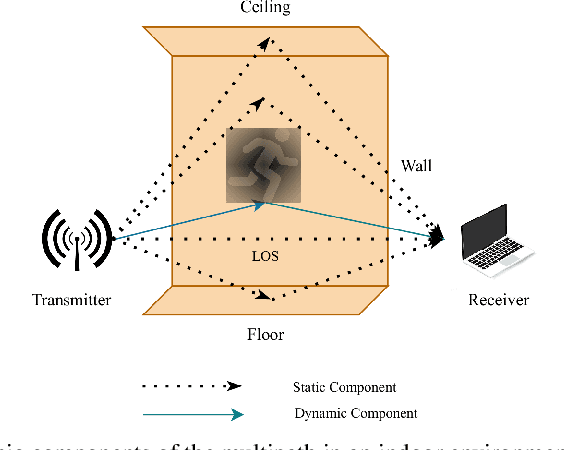
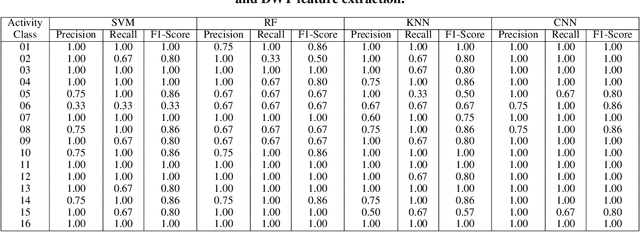

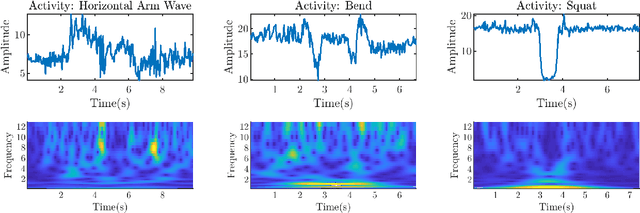
Human Activity Recognition (HAR) is an emerging technology with several applications in surveillance, security, and healthcare sectors. Noninvasive HAR systems based on Wi-Fi Channel State Information (CSI) signals can be developed leveraging the quick growth of ubiquitous Wi-Fi technologies, and the correlation between CSI dynamics and body motions. In this paper, we propose Principal Component-based Wavelet Convolutional Neural Network (or PCWCNN) -- a novel approach that offers robustness and efficiency for practical real-time applications. Our proposed method incorporates two efficient preprocessing algorithms -- the Principal Component Analysis (PCA) and the Discrete Wavelet Transform (DWT). We employ an adaptive activity segmentation algorithm that is accurate and computationally light. Additionally, we used the Wavelet CNN for classification, which is a deep convolutional network analogous to the well-studied ResNet and DenseNet networks. We empirically show that our proposed PCWCNN model performs very well on a real dataset, outperforming existing approaches.
GaitVibe+: Enhancing Structural Vibration-based Footstep Localization Using Temporary Cameras for In-home Gait Analysis
Dec 07, 2022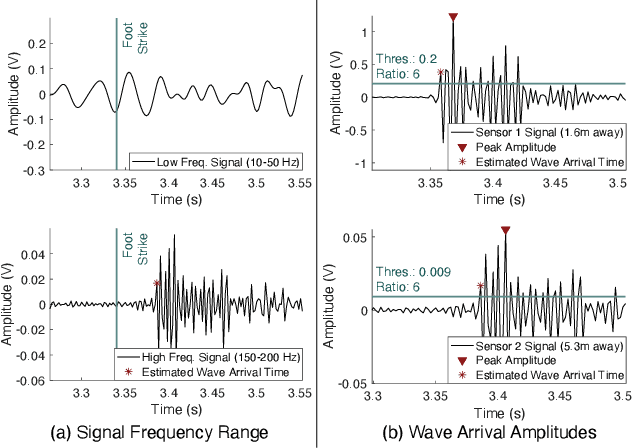
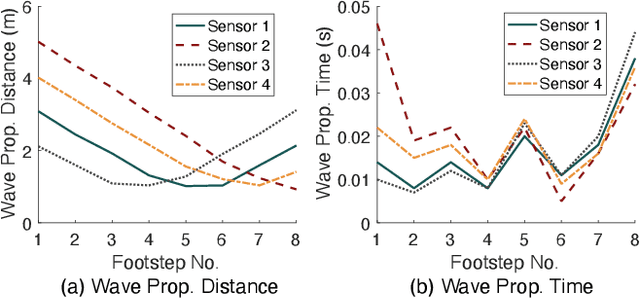
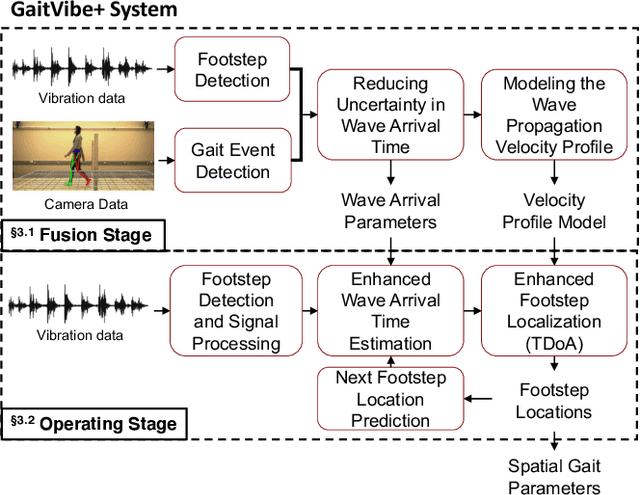
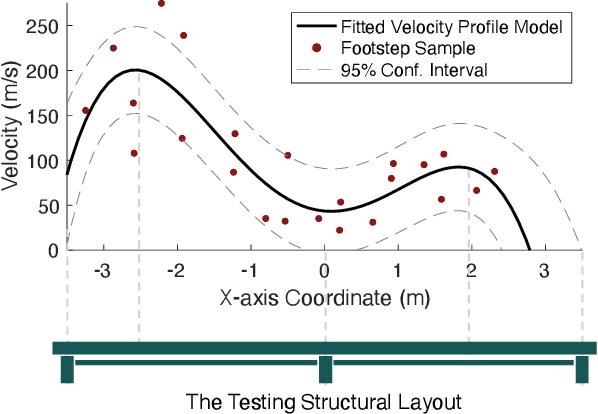
In-home gait analysis is important for providing early diagnosis and adaptive treatments for individuals with gait disorders. Existing systems include wearables and pressure mats, but they have limited scalability. Recent studies have developed vision-based systems to enable scalable, accurate in-home gait analysis, but it faces privacy concerns due to the exposure of people's appearances. Our prior work developed footstep-induced structural vibration sensing for gait monitoring, which is device-free, wide-ranged, and perceived as more privacy-friendly. Although it has succeeded in temporal gait event extraction, it shows limited performance for spatial gait parameter estimation due to imprecise footstep localization. In particular, the localization error mainly comes from the estimation error of the wave arrival time at the vibration sensors and its error propagation to wave velocity estimations. Therefore, we present GaitVibe+, a vibration-based footstep localization method fused with temporarily installed cameras for in-home gait analysis. Our method has two stages: fusion and operating. In the fusion stage, both cameras and vibration sensors are installed to record only a few trials of the subject's footstep data, through which we characterize the uncertainty in wave arrival time and model the wave velocity profiles for the given structure. In the operating stage, we remove the camera to preserve privacy at home. The footstep localization is conducted by estimating the time difference of arrival (TDoA) over multiple vibration sensors, whose accuracy is improved through the reduced uncertainty and velocity modeling during the fusion stage. We evaluate GaitVibe+ through a real-world experiment with 50 walking trials. With only 3 trials of multi-modal fusion, our approach has an average localization error of 0.22 meters, which reduces the spatial gait parameter error from 111% to 27%.
Decentralized Online Regularized Learning Over Random Time-Varying Graphs
Jun 07, 2022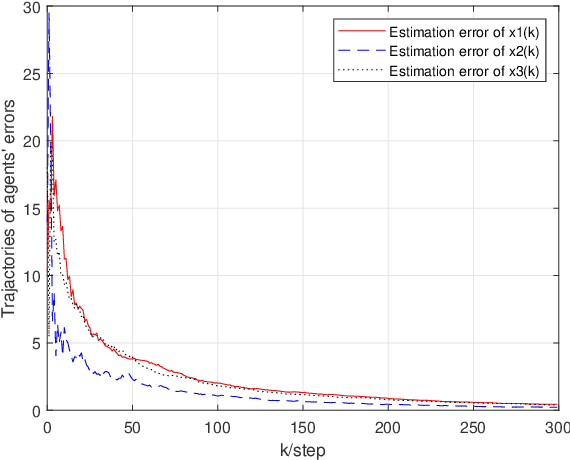
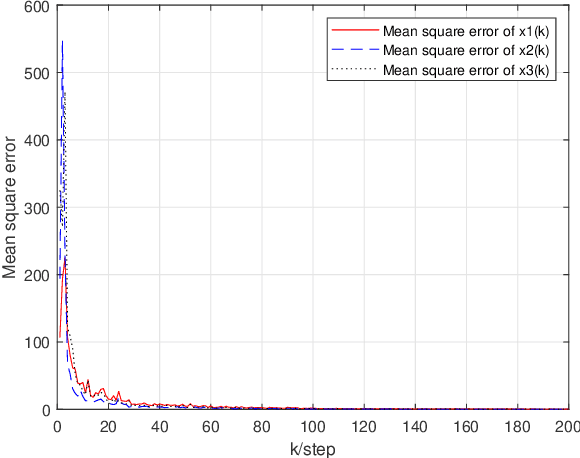
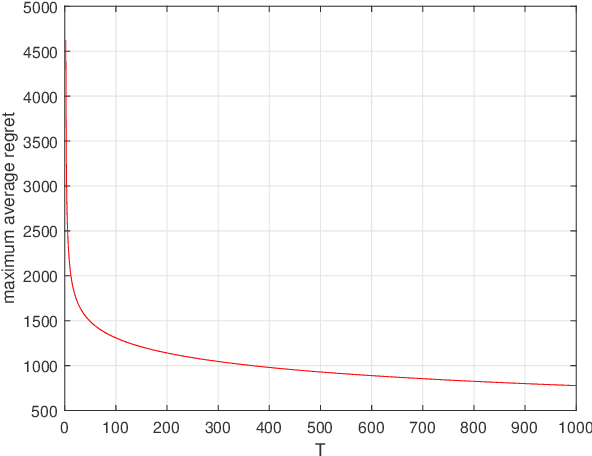
We study the decentralized online regularized linear regression algorithm over random time-varying graphs. At each time step, every node runs an online estimation algorithm consisting of an innovation term processing its own new measurement, a consensus term taking a weighted sum of estimations of its own and its neighbors with additive and multiplicative communication noises and a regularization term preventing over-fitting. It is not required that the regression matrices and graphs satisfy special statistical assumptions such as mutual independence, spatio-temporal independence or stationarity. We develop the nonnegative supermartingale inequality of the estimation error, and prove that the estimations of all nodes converge to the unknown true parameter vector almost surely if the algorithm gains, graphs and regression matrices jointly satisfy the sample path spatio-temporal persistence of excitation condition. Especially, this condition holds by choosing appropriate algorithm gains if the graphs are uniformly conditionally jointly connected and conditionally balanced, and the regression models of all nodes are uniformly conditionally spatio-temporally jointly observable, under which the algorithm converges in mean square and almost surely. In addition, we prove that the regret upper bound $\mathcal O(T^{1-\tau}\ln T)$, where $\tau\in (0.5,1)$ is a constant depending on the algorithm gains.
Voice conversion with limited data and limitless data augmentations
Dec 27, 2022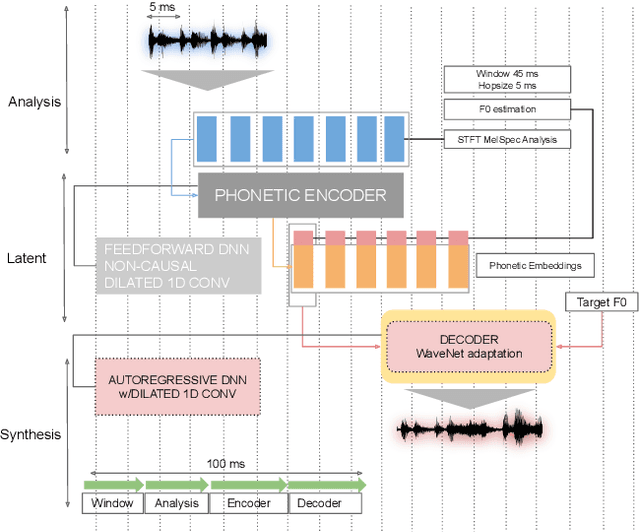
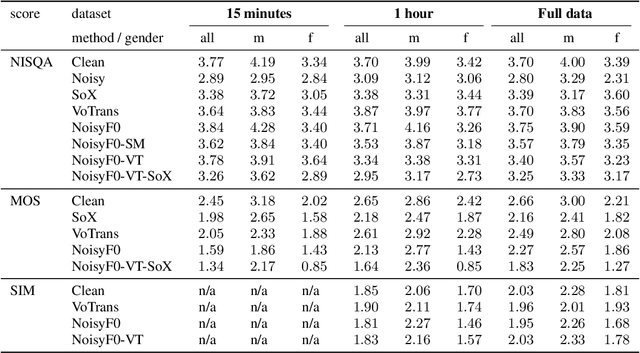
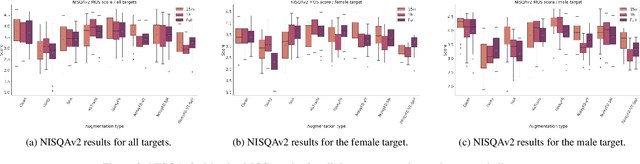
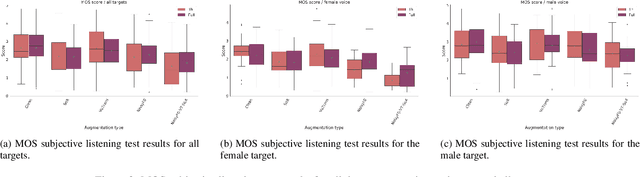
Applying changes to an input speech signal to change the perceived speaker of speech to a target while maintaining the content of the input is a challenging but interesting task known as Voice conversion (VC). Over the last few years, this task has gained significant interest where most systems use data-driven machine learning models. Doing the conversion in a low-latency real-world scenario is even more challenging constrained by the availability of high-quality data. Data augmentations such as pitch shifting and noise addition are often used to increase the amount of data used for training machine learning based models for this task. In this paper we explore the efficacy of common data augmentation techniques for real-time voice conversion and introduce novel techniques for data augmentation based on audio and voice transformation effects as well. We evaluate the conversions for both male and female target speakers using objective and subjective evaluation methodologies.
High-Speed High-Accuracy Spatial Curve Tracking Using Motion Primitives in Industrial Robots
Jan 06, 2023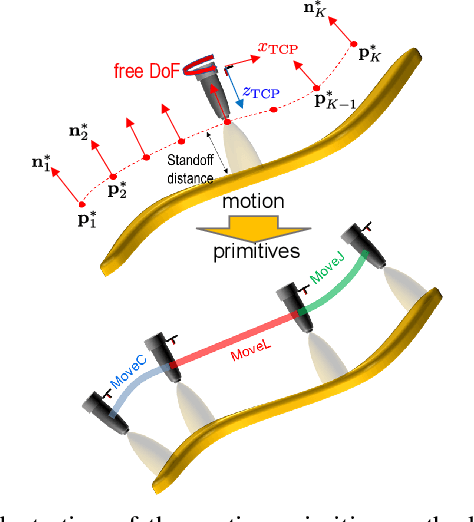
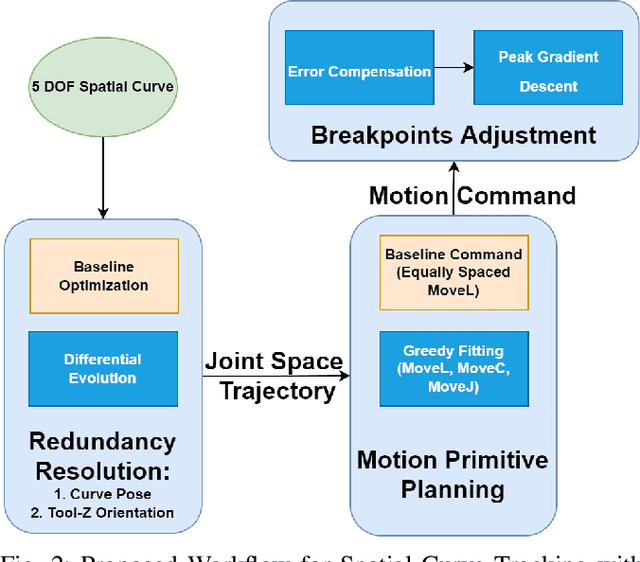
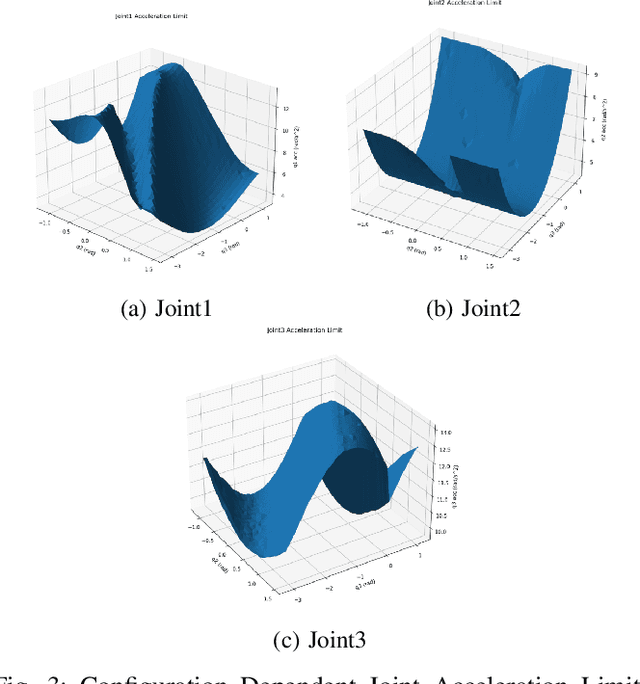
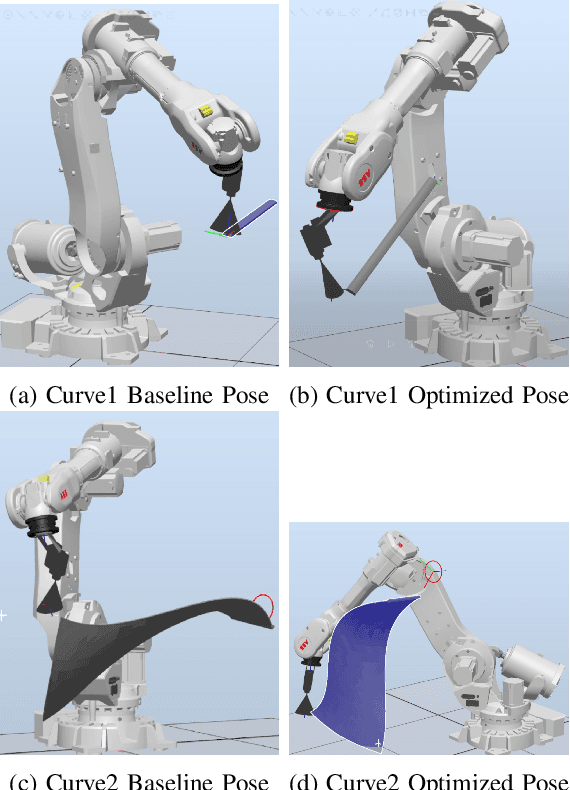
Industrial robots are increasingly deployed in applications requiring an end effector tool to closely track a specified path, such as in spraying and welding. Performance and productivity present possibly conflicting objectives: tracking accuracy, path speed, and motion uniformity. Industrial robots are programmed through motion primitives consisting of waypoints connected by pre-defined motion segments, with specified parameters such as path speed and blending zone. The actual executed robot motion depends on the robot joint servo controller and joint motion constraints (velocity, acceleration, etc.) which are largely unknown to the users. Programming a robot to achieve the desired performance today is time-consuming and mostly manual, requiring tuning a large number of coupled parameters in the motion primitives. The performance also depends on the choice of additional parameters: possible redundant degrees of freedom, location of the target curve, and the robot configuration. This paper presents a systematic approach to optimize the robot motion primitives for performance. The approach first selects the static parameters, then the motion primitives, and finally iteratively update the waypoints to minimize the tracking error. The ultimate performance objective is to maximize the path speed subject to the tracking accuracy and speed uniformity constraints over the entire path. We have demonstrated the effectiveness of this approach in simulation for ABB and FANUC robots for two challenging example curves, and experimentally for an ABB robot. Comparing with the baseline using the current industry practice, the optimized performance shows over 200% performance improvement.
Matching DNN Compression and Cooperative Training with Resources and Data Availability
Dec 02, 2022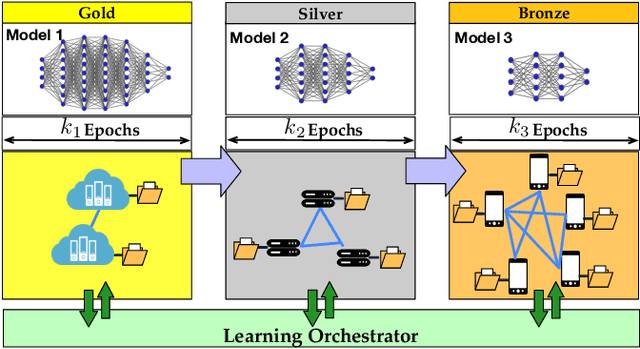
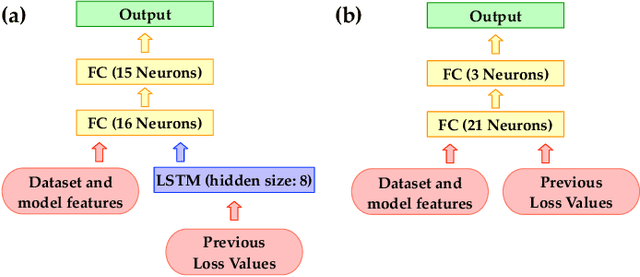
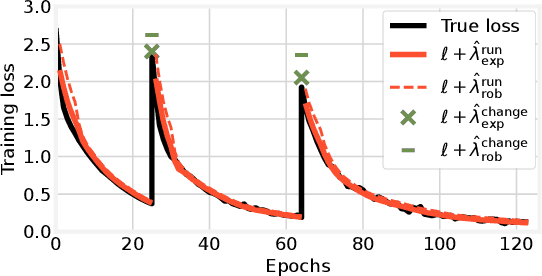
To make machine learning (ML) sustainable and apt to run on the diverse devices where relevant data is, it is essential to compress ML models as needed, while still meeting the required learning quality and time performance. However, how much and when an ML model should be compressed, and {\em where} its training should be executed, are hard decisions to make, as they depend on the model itself, the resources of the available nodes, and the data such nodes own. Existing studies focus on each of those aspects individually, however, they do not account for how such decisions can be made jointly and adapted to one another. In this work, we model the network system focusing on the training of DNNs, formalize the above multi-dimensional problem, and, given its NP-hardness, formulate an approximate dynamic programming problem that we solve through the PACT algorithmic framework. Importantly, PACT leverages a time-expanded graph representing the learning process, and a data-driven and theoretical approach for the prediction of the loss evolution to be expected as a consequence of training decisions. We prove that PACT's solutions can get as close to the optimum as desired, at the cost of an increased time complexity, and that, in any case, such complexity is polynomial. Numerical results also show that, even under the most disadvantageous settings, PACT outperforms state-of-the-art alternatives and closely matches the optimal energy cost.
A Novel SOC Estimation for Hybrid Energy Pack using Deep Learning
Dec 23, 2022
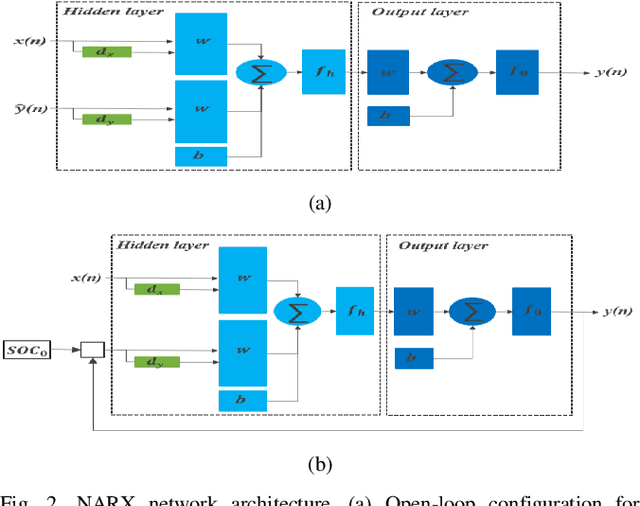
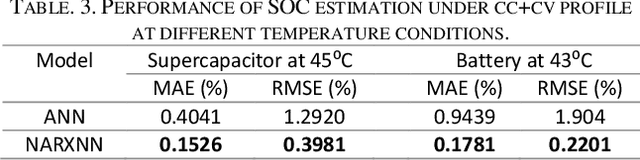
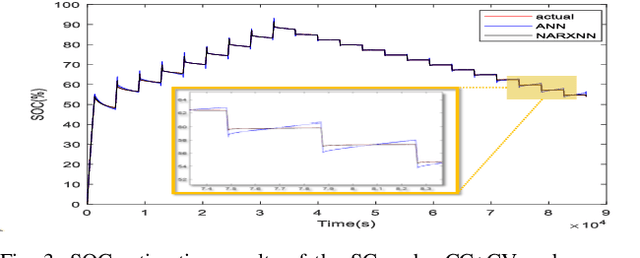
Estimating the state of charge (SOC) of compound energy storage devices in the hybrid energy storage system (HESS) of electric vehicles (EVs) is vital in improving the performance of the EV. The complex and variable charging and discharging current of EVs makes an accurate SOC estimation a challenge. This paper proposes a novel deep learning-based SOC estimation method for lithium-ion battery-supercapacitor HESS EV based on the nonlinear autoregressive with exogenous inputs neural network (NARXNN). The NARXNN is utilized to capture and overcome the complex nonlinear behaviors of lithium-ion batteries and supercapacitors in EVs. The results show that the proposed method improved the SOC estimation accuracy by 91.5% on average with error values below 0.1% and reduced consumption time by 11.4%. Hence validating both the effectiveness and robustness of the proposed method.
Post hoc Explanations may be Ineffective for Detecting Unknown Spurious Correlation
Dec 09, 2022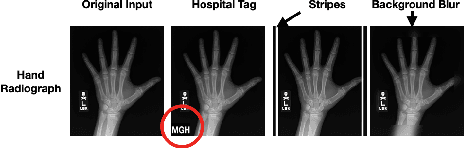
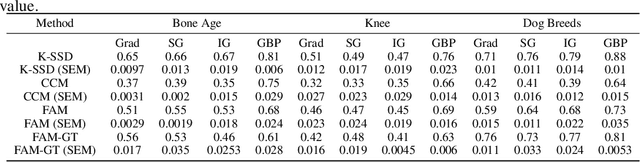
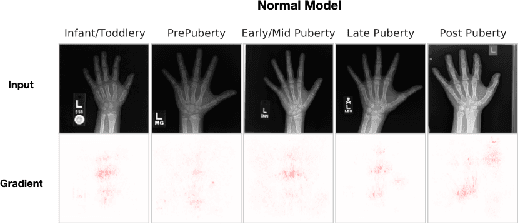
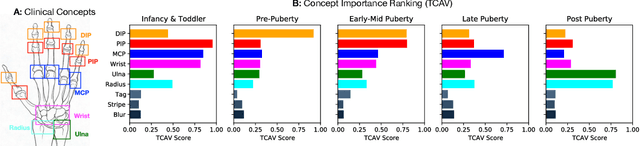
We investigate whether three types of post hoc model explanations--feature attribution, concept activation, and training point ranking--are effective for detecting a model's reliance on spurious signals in the training data. Specifically, we consider the scenario where the spurious signal to be detected is unknown, at test-time, to the user of the explanation method. We design an empirical methodology that uses semi-synthetic datasets along with pre-specified spurious artifacts to obtain models that verifiably rely on these spurious training signals. We then provide a suite of metrics that assess an explanation method's reliability for spurious signal detection under various conditions. We find that the post hoc explanation methods tested are ineffective when the spurious artifact is unknown at test-time especially for non-visible artifacts like a background blur. Further, we find that feature attribution methods are susceptible to erroneously indicating dependence on spurious signals even when the model being explained does not rely on spurious artifacts. This finding casts doubt on the utility of these approaches, in the hands of a practitioner, for detecting a model's reliance on spurious signals.
Gradient flow in the gaussian covariate model: exact solution of learning curves and multiple descent structures
Dec 13, 2022
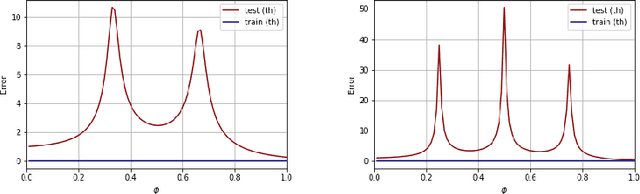
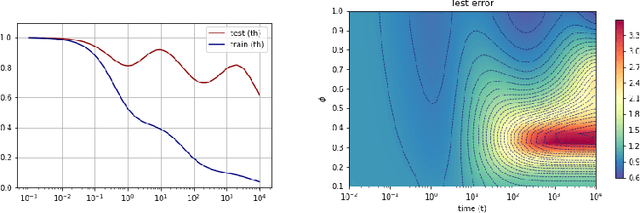
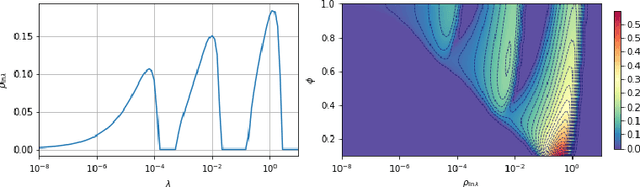
A recent line of work has shown remarkable behaviors of the generalization error curves in simple learning models. Even the least-squares regression has shown atypical features such as the model-wise double descent, and further works have observed triple or multiple descents. Another important characteristic are the epoch-wise descent structures which emerge during training. The observations of model-wise and epoch-wise descents have been analytically derived in limited theoretical settings (such as the random feature model) and are otherwise experimental. In this work, we provide a full and unified analysis of the whole time-evolution of the generalization curve, in the asymptotic large-dimensional regime and under gradient-flow, within a wider theoretical setting stemming from a gaussian covariate model. In particular, we cover most cases already disparately observed in the literature, and also provide examples of the existence of multiple descent structures as a function of a model parameter or time. Furthermore, we show that our theoretical predictions adequately match the learning curves obtained by gradient descent over realistic datasets. Technically we compute averages of rational expressions involving random matrices using recent developments in random matrix theory based on "linear pencils". Another contribution, which is also of independent interest in random matrix theory, is a new derivation of related fixed point equations (and an extension there-off) using Dyson brownian motions.
Real Time Object Detection System with YOLO and CNN Models: A Review
Jul 23, 2022The field of artificial intelligence is built on object detection techniques. YOU ONLY LOOK ONCE (YOLO) algorithm and it's more evolved versions are briefly described in this research survey. This survey is all about YOLO and convolution neural networks (CNN)in the direction of real time object detection.YOLO does generalized object representation more effectively without precision losses than other object detection models.CNN architecture models have the ability to eliminate highlights and identify objects in any given image. When implemented appropriately, CNN models can address issues like deformity diagnosis, creating educational or instructive application, etc. This article reached atnumber of observations and perspective findings through the analysis.Also it provides support for the focused visual information and feature extraction in the financial and other industries, highlights the method of target detection and feature selection, and briefly describe the development process of YOLO algorithm.