 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDependable Distributed Training of Compressed Machine Learning Models
Feb 22, 2024



The existing work on the distributed training of machine learning (ML) models has consistently overlooked the distribution of the achieved learning quality, focusing instead on its average value. This leads to a poor dependability}of the resulting ML models, whose performance may be much worse than expected. We fill this gap by proposing DepL, a framework for dependable learning orchestration, able to make high-quality, efficient decisions on (i) the data to leverage for learning, (ii) the models to use and when to switch among them, and (iii) the clusters of nodes, and the resources thereof, to exploit. For concreteness, we consider as possible available models a full DNN and its compressed versions. Unlike previous studies, DepL guarantees that a target learning quality is reached with a target probability, while keeping the training cost at a minimum. We prove that DepL has constant competitive ratio and polynomial complexity, and show that it outperforms the state-of-the-art by over 27% and closely matches the optimum.
Matching DNN Compression and Cooperative Training with Resources and Data Availability
Dec 02, 2022To make machine learning (ML) sustainable and apt to run on the diverse devices where relevant data is, it is essential to compress ML models as needed, while still meeting the required learning quality and time performance. However, how much and when an ML model should be compressed, and {\em where} its training should be executed, are hard decisions to make, as they depend on the model itself, the resources of the available nodes, and the data such nodes own. Existing studies focus on each of those aspects individually, however, they do not account for how such decisions can be made jointly and adapted to one another. In this work, we model the network system focusing on the training of DNNs, formalize the above multi-dimensional problem, and, given its NP-hardness, formulate an approximate dynamic programming problem that we solve through the PACT algorithmic framework. Importantly, PACT leverages a time-expanded graph representing the learning process, and a data-driven and theoretical approach for the prediction of the loss evolution to be expected as a consequence of training decisions. We prove that PACT's solutions can get as close to the optimum as desired, at the cost of an increased time complexity, and that, in any case, such complexity is polynomial. Numerical results also show that, even under the most disadvantageous settings, PACT outperforms state-of-the-art alternatives and closely matches the optimal energy cost.
Energy-efficient Training of Distributed DNNs in the Mobile-edge-cloud Continuum
Feb 23, 2022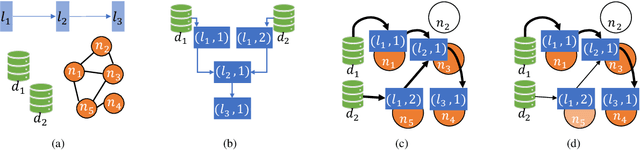
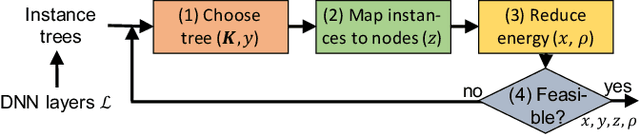
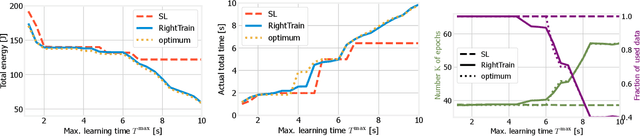
We address distributed machine learning in multi-tier (e.g., mobile-edge-cloud) networks where a heterogeneous set of nodes cooperate to perform a learning task. Due to the presence of multiple data sources and computation-capable nodes, a learning controller (e.g., located in the edge) has to make decisions about (i) which distributed ML model structure to select, (ii) which data should be used for the ML model training, and (iii) which resources should be allocated to it. Since these decisions deeply influence one another, they should be made jointly. In this paper, we envision a new approach to distributed learning in multi-tier networks, which aims at maximizing ML efficiency. To this end, we propose a solution concept, called RightTrain, that achieves energy-efficient ML model training, while fulfilling learning time and quality requirements. RightTrain makes high-quality decisions in polynomial time. Further, our performance evaluation shows that RightTrain closely matches the optimum and outperforms the state of the art by over 50%.
Vessel-CAPTCHA: an efficient learning framework for vessel annotation and segmentation
Jan 29, 2021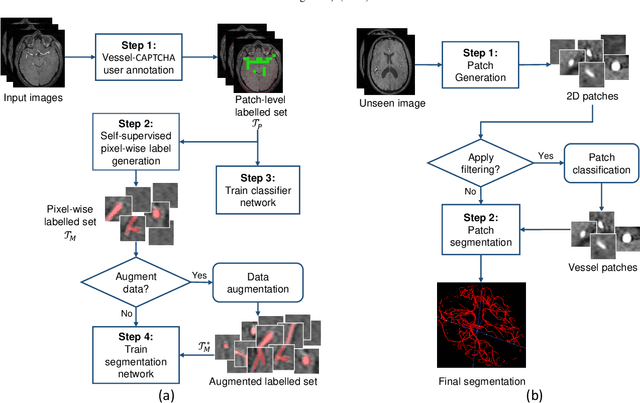
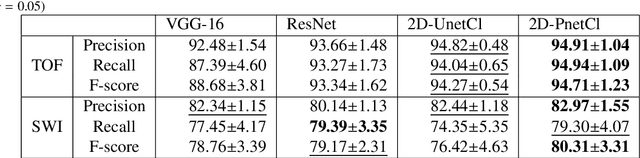
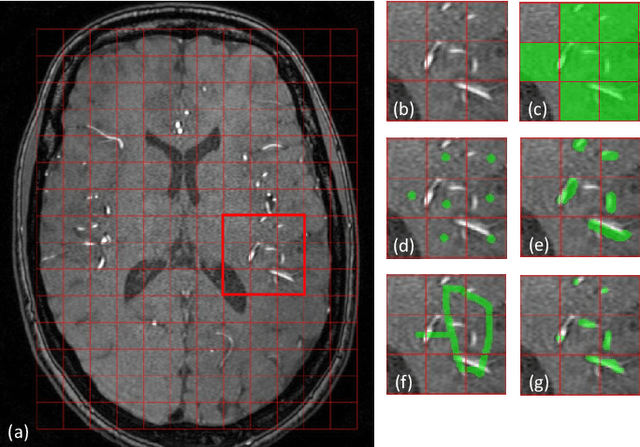

The use of deep learning techniques for 3D brain vessel image segmentation has not been as widespread as for the segmentation of other organs and tissues. This can be explained by two factors. First, deep learning techniques tend to show poor performances at the segmentation of relatively small objects compared to the size of the full image. Second, due to the complexity of vascular trees and the small size of vessels, it is challenging to obtain the amount of annotated training data typically needed by deep learning methods. To address these problems, we propose a novel annotation-efficient deep learning vessel segmentation framework. The framework avoids pixel-wise annotations, only requiring patch-level labels to discriminate between vessel and non-vessel 2D patches in the training set, in a setup similar to the CAPTCHAs used to differentiate humans from bots in web applications. The user-provided annotations are used for two tasks: 1) to automatically generate pixel-wise labels for vessels and background in each patch, which are used to train a segmentation network, and 2) to train a classifier network. The classifier network allows to generate additional weak patch labels, further reducing the annotation burden, and it acts as a noise filter for poor quality images. We use this framework for the segmentation of the cerebrovascular tree in Time-of-Flight angiography (TOF) and Susceptibility-Weighted Images (SWI). The results show that the framework achieves state-of-the-art accuracy, while reducing the annotation time by up to 80% with respect to learning-based segmentation methods using pixel-wise labels for training