 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoice conversion with limited data and limitless data augmentations
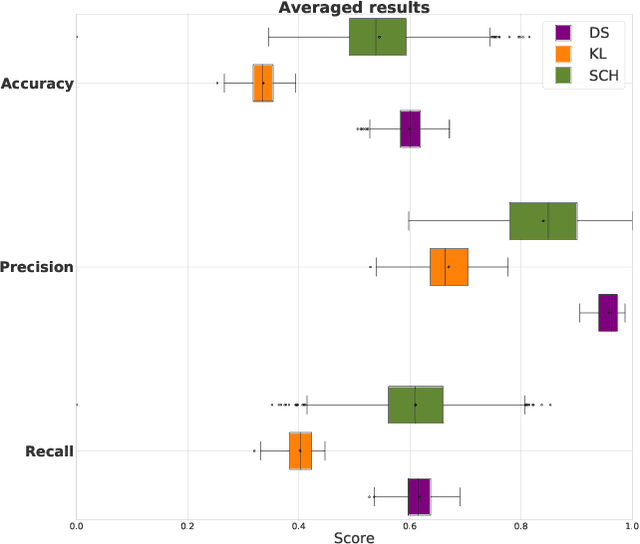
Dec 27, 2022Applying changes to an input speech signal to change the perceived speaker of speech to a target while maintaining the content of the input is a challenging but interesting task known as Voice conversion (VC). Over the last few years, this task has gained significant interest where most systems use data-driven machine learning models. Doing the conversion in a low-latency real-world scenario is even more challenging constrained by the availability of high-quality data. Data augmentations such as pitch shifting and noise addition are often used to increase the amount of data used for training machine learning based models for this task. In this paper we explore the efficacy of common data augmentation techniques for real-time voice conversion and introduce novel techniques for data augmentation based on audio and voice transformation effects as well. We evaluate the conversions for both male and female target speakers using objective and subjective evaluation methodologies.
LoopNet: Musical Loop Synthesis Conditioned On Intuitive Musical Parameters
May 21, 2021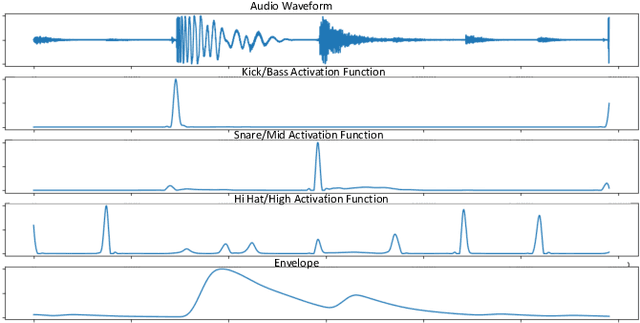

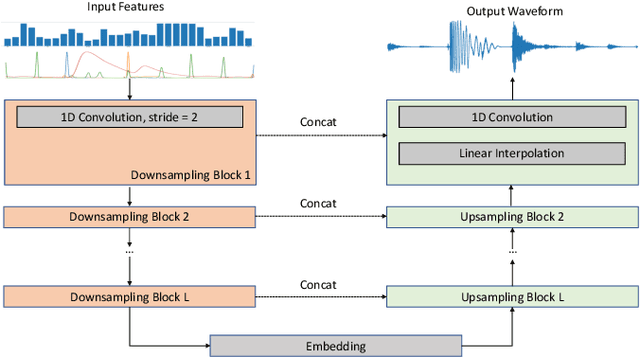
Loops, seamlessly repeatable musical segments, are a cornerstone of modern music production. Contemporary artists often mix and match various sampled or pre-recorded loops based on musical criteria such as rhythm, harmony and timbral texture to create compositions. Taking such criteria into account, we present LoopNet, a feed-forward generative model for creating loops conditioned on intuitive parameters. We leverage Music Information Retrieval (MIR) models as well as a large collection of public loop samples in our study and use the Wave-U-Net architecture to map control parameters to audio. We also evaluate the quality of the generated audio and propose intuitive controls for composers to map the ideas in their minds to an audio loop.
A Deep Learning Based Analysis-Synthesis Framework For Unison Singing
Sep 21, 2020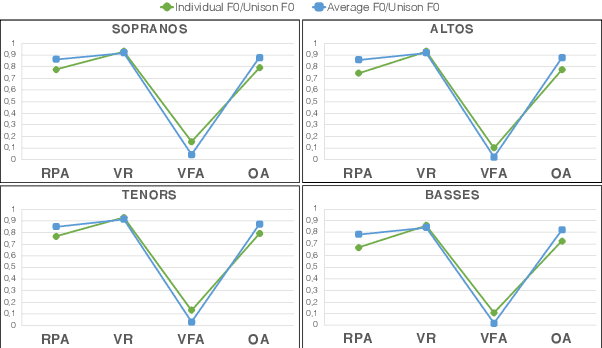
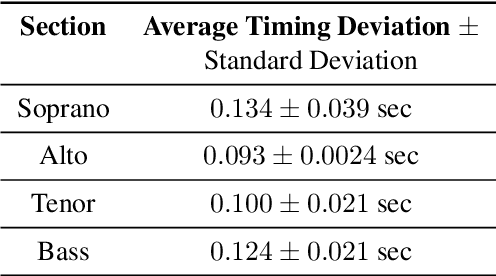
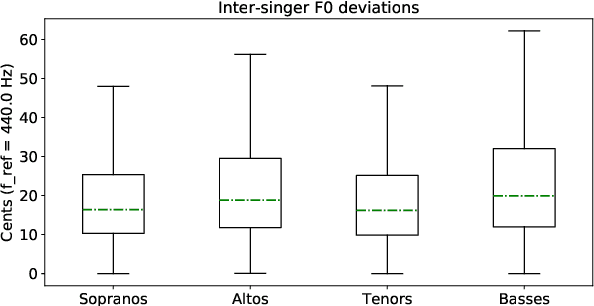
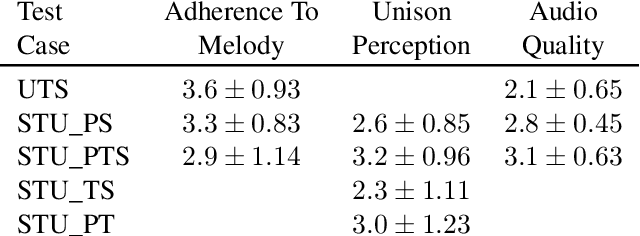
Unison singing is the name given to an ensemble of singers simultaneously singing the same melody and lyrics. While each individual singer in a unison sings the same principle melody, there are slight timing and pitch deviations between the singers, which, along with the ensemble of timbres, give the listener a perceived sense of "unison". In this paper, we present a study of unison singing in the context of choirs; utilising some recently proposed deep-learning based methodologies, we analyse the fundamental frequency (F0) distribution of the individual singers in recordings of unison mixtures. Based on the analysis, we propose a system for synthesising a unison signal from an a cappella input and a single voice prototype representative of a unison mixture. We use subjective listening tests to evaluate perceptual factors of our proposed system for synthesis, including quality, adherence to the melody as well the degree of perceived unison.
Deep Learning Based Source Separation Applied To Choir Ensembles
Aug 17, 2020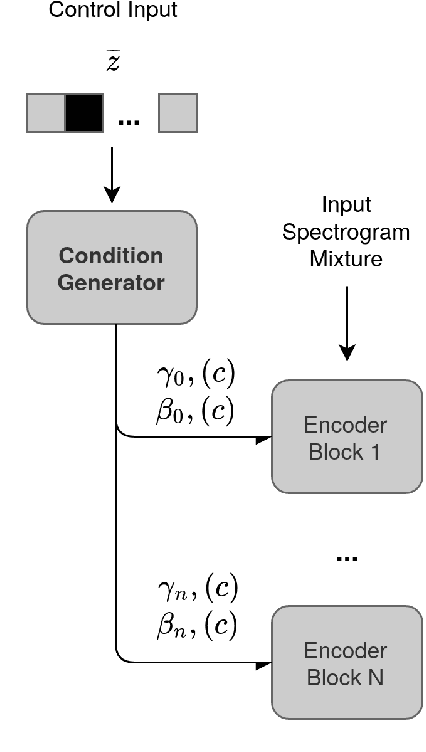
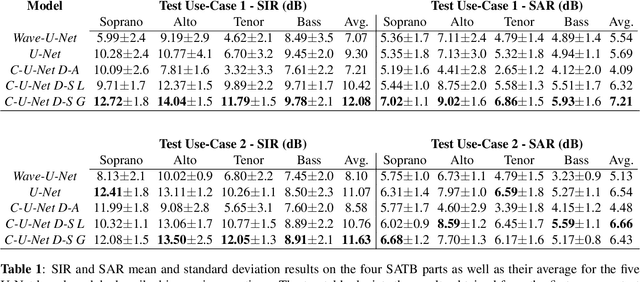
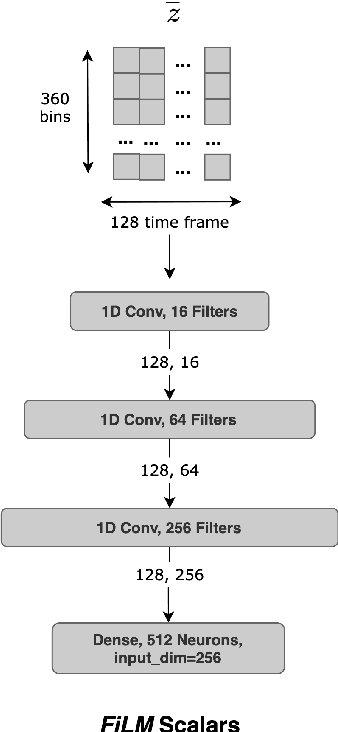
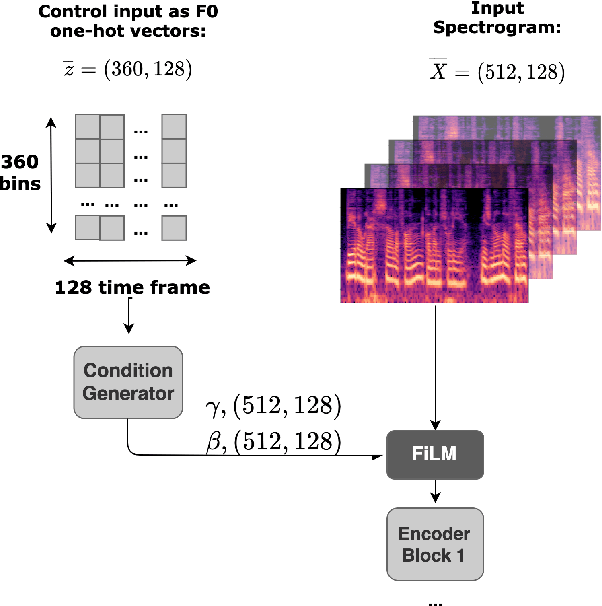
Choral singing is a widely practiced form of ensemble singing wherein a group of people sing simultaneously in polyphonic harmony. The most commonly practiced setting for choir ensembles consists of four parts; Soprano, Alto, Tenor and Bass (SATB), each with its own range of fundamental frequencies (F$0$s). The task of source separation for this choral setting entails separating the SATB mixture into the constituent parts. Source separation for musical mixtures is well studied and many deep learning based methodologies have been proposed for the same. However, most of the research has been focused on a typical case which consists in separating vocal, percussion and bass sources from a mixture, each of which has a distinct spectral structure. In contrast, the simultaneous and harmonic nature of ensemble singing leads to high structural similarity and overlap between the spectral components of the sources in a choral mixture, making source separation for choirs a harder task than the typical case. This, along with the lack of an appropriate consolidated dataset has led to a dearth of research in the field so far. In this paper we first assess how well some of the recently developed methodologies for musical source separation perform for the case of SATB choirs. We then propose a novel domain-specific adaptation for conditioning the recently proposed U-Net architecture for musical source separation using the fundamental frequency contour of each of the singing groups and demonstrate that our proposed approach surpasses results from domain-agnostic architectures.
Content Based Singing Voice Extraction From a Musical Mixture
Feb 17, 2020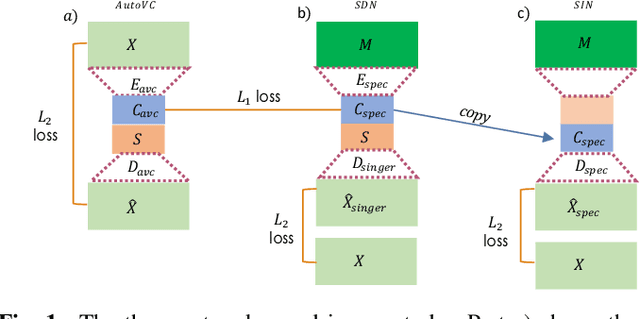
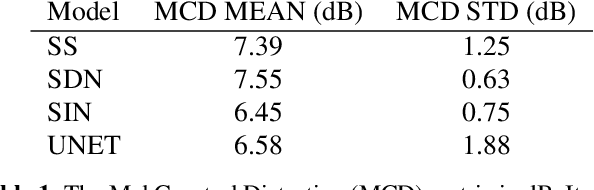
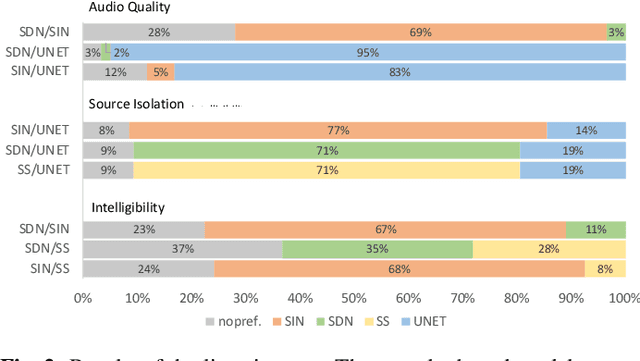
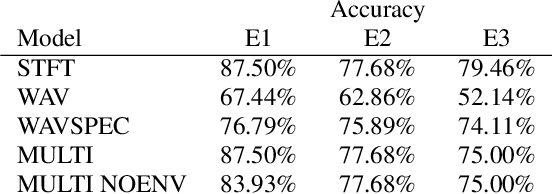
We present a deep learning based methodology for extracting the singing voice signal from a musical mixture based on the underlying linguistic content. Our model follows an encoder decoder architecture and takes as input the magnitude component of the spectrogram of a musical mixture with vocals. The encoder part of the model is trained via knowledge distillation using a teacher network to learn a content embedding, which is decoded to generate the corresponding vocoder features. Using this methodology, we are able to extract the unprocessed raw vocal signal from the mixture even for a processed mixture dataset with singers not seen during training. While the nature of our system makes it incongruous with traditional objective evaluation metrics, we use subjective evaluation via listening tests to compare the methodology to state-of-the-art deep learning based source separation algorithms. We also provide sound examples and source code for reproducibility.
* To be published in ICASSP 2020
Neural Percussive Synthesis Parameterised by High-Level Timbral Features
Nov 25, 2019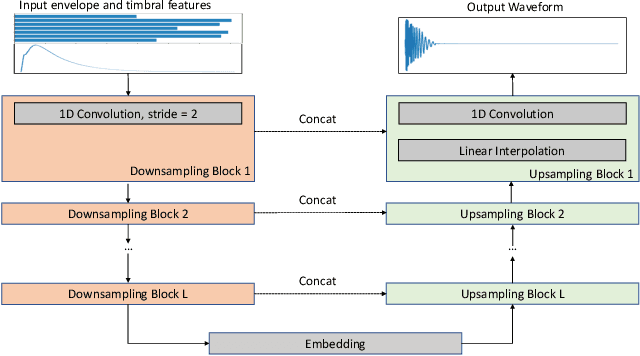
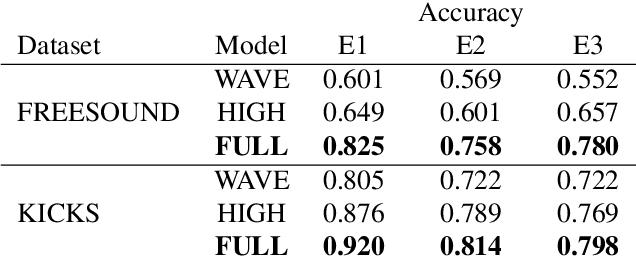
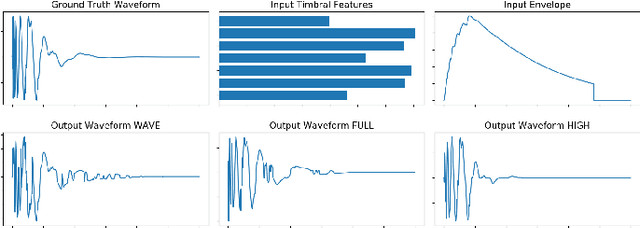
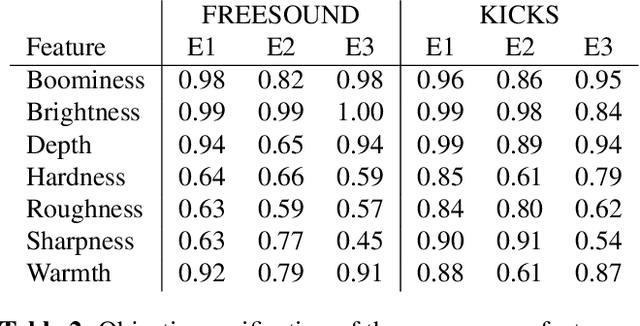
We present a deep neural network-based methodology for synthesising percussive sounds with control over high-level timbral characteristics of the sounds. This approach allows for intuitive control of a synthesizer, enabling the user to shape sounds without extensive knowledge of signal processing. We use a feedforward convolutional neural network-based architecture, which is able to map input parameters to the corresponding waveform. We propose two datasets to evaluate our approach on both a restrictive context, and in one covering a broader spectrum of sounds. The timbral features used as parameters are taken from recent literature in signal processing. We also use these features for evaluation and validation of the presented model, to ensure that changing the input parameters produces a congruent waveform with the desired characteristics. Finally, we evaluate the quality of the output sound using a subjective listening test. We provide sound examples and the system's source code for reproducibility.
A Framework for Multi-f0 Modeling in SATB Choir Recordings
Apr 10, 2019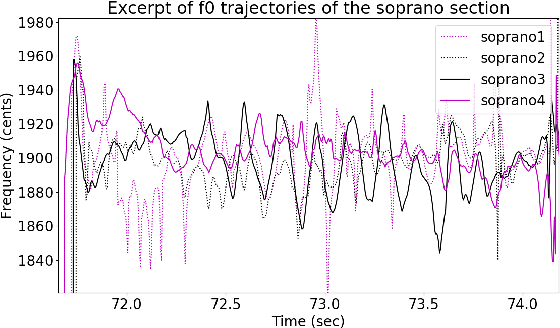
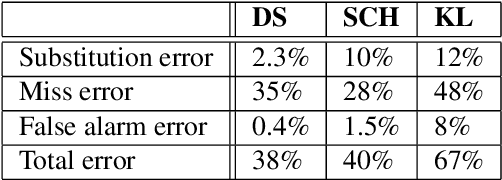
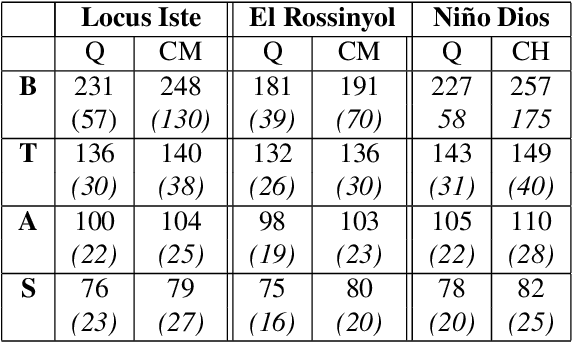
Fundamental frequency (f0) modeling is an important but relatively unexplored aspect of choir singing. Performance evaluation as well as auditory analysis of singing, whether individually or in a choir, often depend on extracting f0 contours for the singing voice. However, due to the large number of singers, singing at a similar frequency range, extracting the exact individual pitch contours from choir recordings is a challenging task. In this paper, we address this task and develop a methodology for modeling pitch contours of SATB choir recordings. A typical SATB choir consists of four parts, each covering a distinct range of pitches and often with multiple singers each. We first evaluate some state-of-the-art multi-f0 estimation systems for the particular case of choirs with a single singer per part, and observe that the pitch of individual singers can be estimated to a relatively high degree of accuracy. We observe, however, that the scenario of multiple singers for each choir part (i.e. unison singing) is far more challenging. In this work we propose a methodology based on combining a multi-f0 estimation methodology based on deep learning followed by a set of traditional DSP techniques to model f0 and its dispersion instead of a single f0 trajectory for each choir part. We present and discuss our observations and test our framework with different singer configurations.
Deep Learning for Singing Processing: Achievements, Challenges and Impact on Singers and Listeners
Jul 09, 2018
This paper summarizes some recent advances on a set of tasks related to the processing of singing using state-of-the-art deep learning techniques. We discuss their achievements in terms of accuracy and sound quality, and the current challenges, such as availability of data and computing resources. We also discuss the impact that these advances do and will have on listeners and singers when they are integrated in commercial applications.