 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Practical Frequency-Hopping MIMO Joint Radar Communications: Design and Experiment
Jan 27, 2023
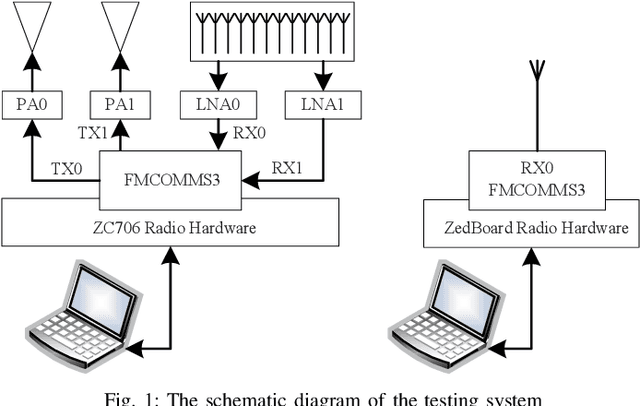
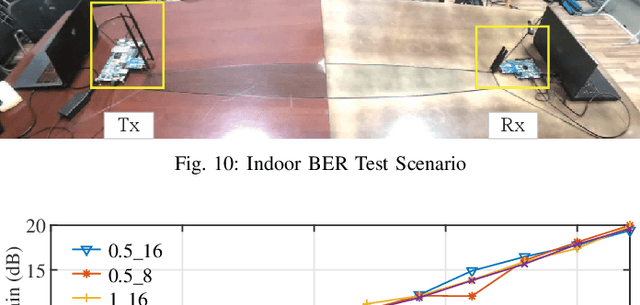
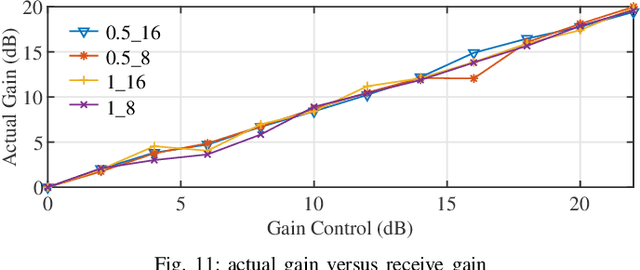
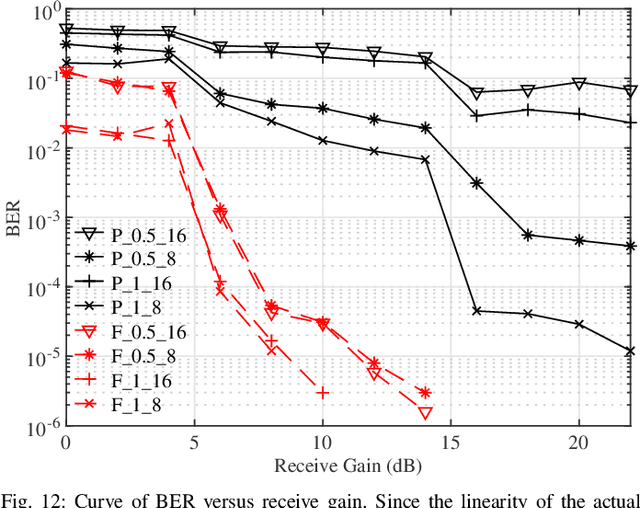
Joint radar and communications (JRC) can realize two radio frequency (RF) functions using one set of resources, greatly saving hardware, energy and spectrum for wireless systems needing both functions. Frequency-hopping (FH) MIMO radar is a popular candidate for JRC, as the achieved communication symbol rate can greatly exceed radar pulse repetition frequency. However, practical transceiver imperfections can fail many existing theoretical designs. In this work, we unveil for the first time the non-trivial impact of hardware imperfections on FH-MIMO JRC and analytically model the impact. We also design new waveforms and, accordingly, develop a low-complexity algorithm to jointly estimate the hardware imperfections of unsynchronized receiver. Moreover, employing low-cost software-defined radios and commercial off-the-shelf (COTS) products, we build the first FH-MIMO JRC experiment platform with radar and communications simultaneously validated over the air. Corroborated by simulation and experiment results, the proposed designs achieves high performances for both radar and communications.
Transfer Learning and Class Decomposition for Detecting the Cognitive Decline of Alzheimer Disease
Jan 31, 2023

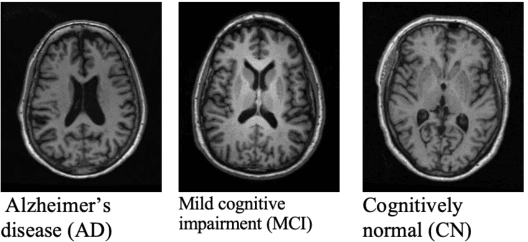
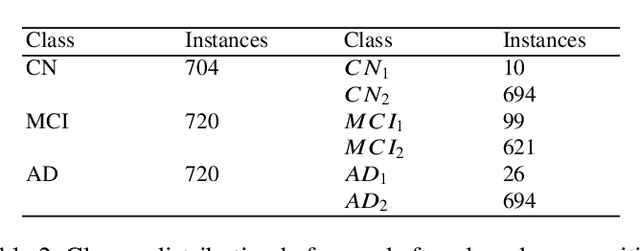
Early diagnosis of Alzheimer's disease (AD) is essential in preventing the disease's progression. Therefore, detecting AD from neuroimaging data such as structural magnetic resonance imaging (sMRI) has been a topic of intense investigation in recent years. Deep learning has gained considerable attention in Alzheimer's detection. However, training a convolutional neural network from scratch is challenging since it demands more computational time and a significant amount of annotated data. By transferring knowledge learned from other image recognition tasks to medical image classification, transfer learning can provide a promising and effective solution. Irregularities in the dataset distribution present another difficulty. Class decomposition can tackle this issue by simplifying learning a dataset's class boundaries. Motivated by these approaches, this paper proposes a transfer learning method using class decomposition to detect Alzheimer's disease from sMRI images. We use two ImageNet-trained architectures: VGG19 and ResNet50, and an entropy-based technique to determine the most informative images. The proposed model achieved state-of-the-art performance in the Alzheimer's disease (AD) vs mild cognitive impairment (MCI) vs cognitively normal (CN) classification task with a 3\% increase in accuracy from what is reported in the literature.
Improved Algorithms for Multi-period Multi-class Packing Problems with~Bandit~Feedback
Jan 31, 2023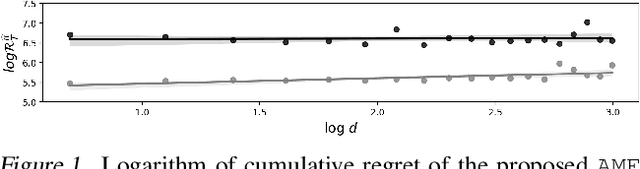
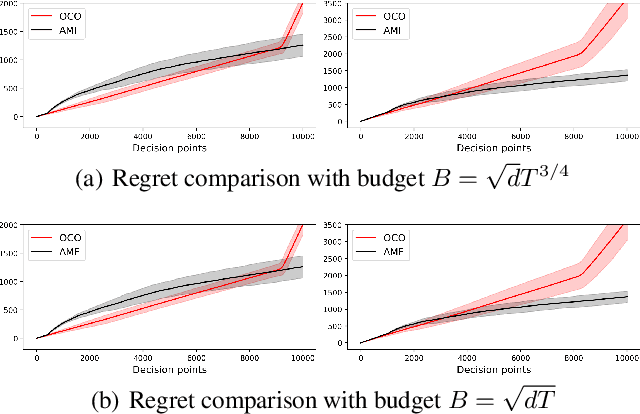
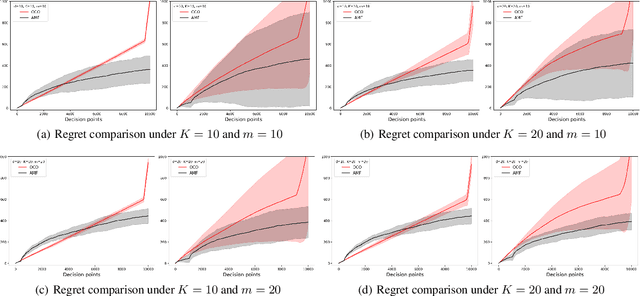
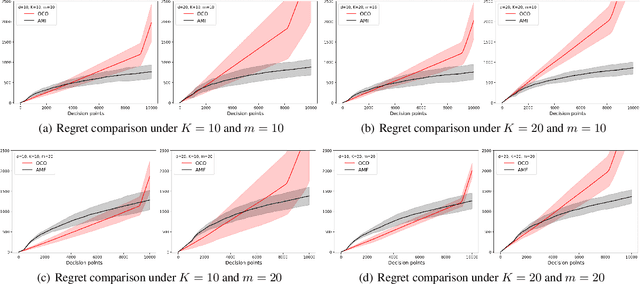
We consider the linear contextual multi-class multi-period packing problem~(LMMP) where the goal is to pack items such that the total vector of consumption is below a given budget vector and the total value is as large as possible. We consider the setting where the reward and the consumption vector associated with each action is a class-dependent linear function of the context, and the decision-maker receives bandit feedback. LMMP includes linear contextual bandits with knapsacks and online revenue management as special cases. We establish a new more efficient estimator which guarantees a faster convergence rate, and consequently, a lower regret in such problems. We propose a bandit policy that is a closed-form function of said estimated parameters. When the contexts are non-degenerate, the regret of the proposed policy is sublinear in the context dimension, the number of classes, and the time horizon~$T$ when the budget grows at least as $\sqrt{T}$. We also resolve an open problem posed in Agrawal & Devanur (2016), and extend the result to a multi-class setting. Our numerical experiments clearly demonstrate that the performance of our policy is superior to other benchmarks in the literature.
Dynamic Scheduled Sampling with Imitation Loss for Neural Text Generation
Jan 31, 2023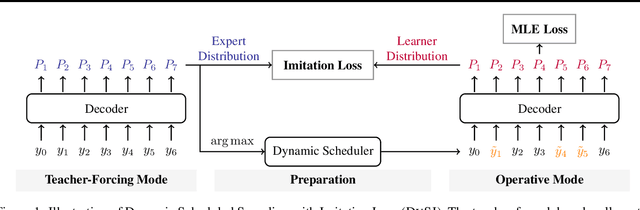
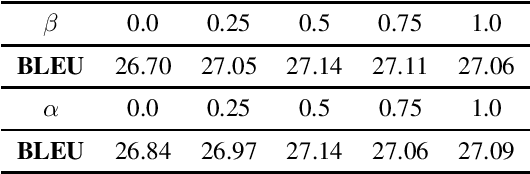
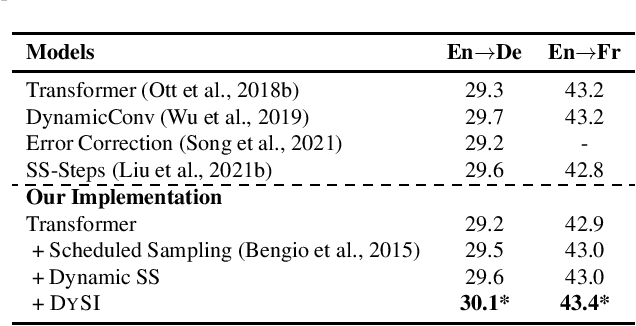
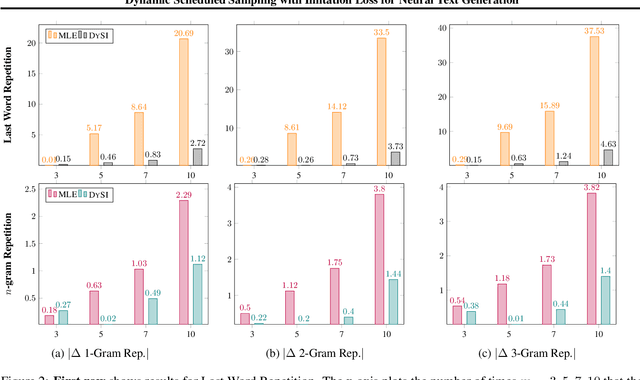
State-of-the-art neural text generation models are typically trained to maximize the likelihood of each token in the ground-truth sequence conditioned on the previous target tokens. However, during inference, the model needs to make a prediction conditioned on the tokens generated by itself. This train-test discrepancy is referred to as exposure bias. Scheduled sampling is a curriculum learning strategy that gradually exposes the model to its own predictions during training to mitigate this bias. Most of the proposed approaches design a scheduler based on training steps, which generally requires careful tuning depending on the training setup. In this work, we introduce Dynamic Scheduled Sampling with Imitation Loss (DySI), which maintains the schedule based solely on the training time accuracy, while enhancing the curriculum learning by introducing an imitation loss, which attempts to make the behavior of the decoder indistinguishable from the behavior of a teacher-forced decoder. DySI is universally applicable across training setups with minimal tuning. Extensive experiments and analysis show that DySI not only achieves notable improvements on standard machine translation benchmarks, but also significantly improves the robustness of other text generation models.
Learning, Fast and Slow: A Goal-Directed Memory-Based Approach for Dynamic Environments
Jan 31, 2023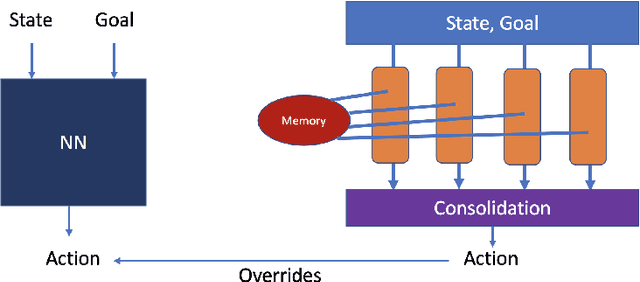
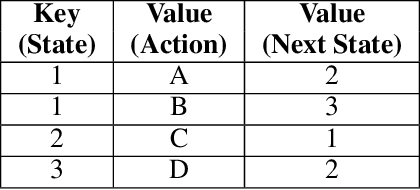
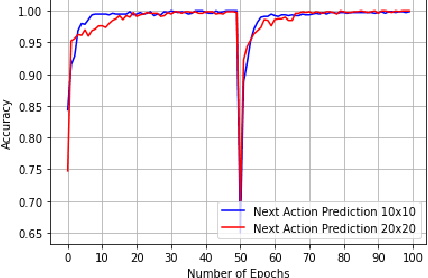
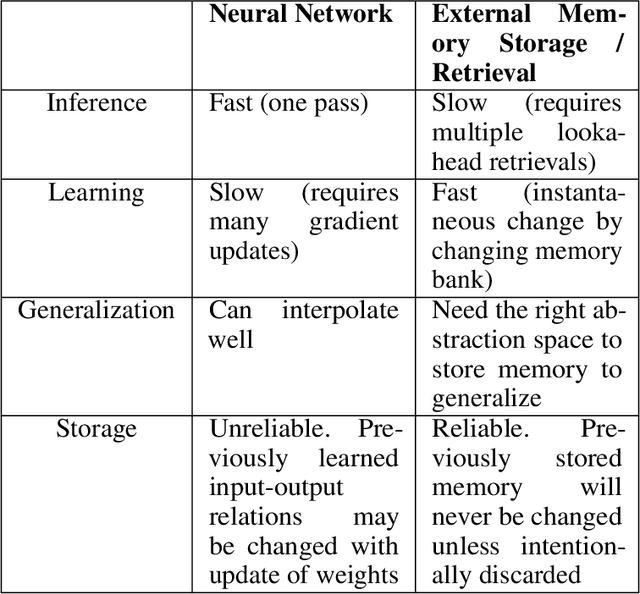
Model-based next state prediction and state value prediction are slow to converge. To address these challenges, we do the following: i) Instead of a neural network, we do model-based planning using a parallel memory retrieval system (which we term the slow mechanism); ii) Instead of learning state values, we guide the agent's actions using goal-directed exploration, by using a neural network to choose the next action given the current state and the goal state (which we term the fast mechanism). The goal-directed exploration is trained online using hippocampal replay of visited states and future imagined states every single time step, leading to fast and efficient training. Empirical studies show that our proposed method has a 92% solve rate across 100 episodes in a dynamically changing grid world, significantly outperforming state-of-the-art actor critic mechanisms such as PPO (54%), TRPO (50%) and A2C (24%). Ablation studies demonstrate that both mechanisms are crucial. We posit that the future of Reinforcement Learning (RL) will be to model goals and sub-goals for various tasks, and plan it out in a goal-directed memory-based approach.
Gas Leak detection using airborne US Sensors
Jan 31, 2023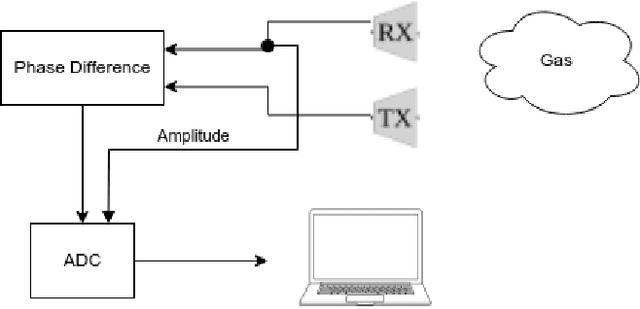
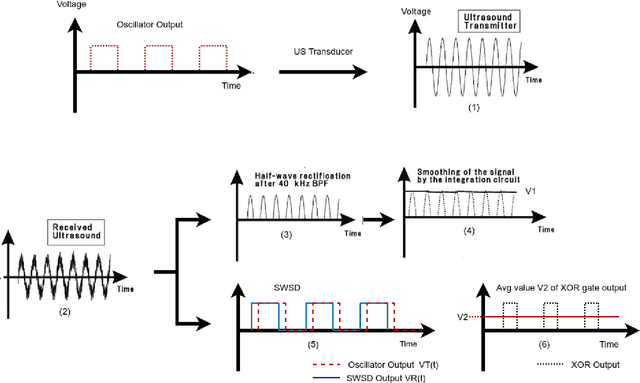
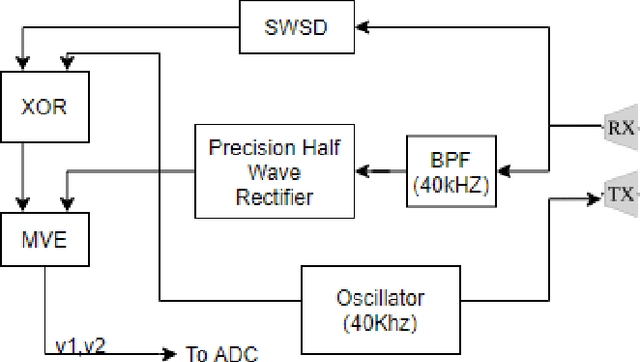

Gas leakage is a critical problem in the industrial sector, residential structures, and gas-powered vehicles; installing gas leakage detection systems is one of the preventative strategies for reducing hazards caused by gas leakage. Conventional gas sensors, such as electrochemical, infrared point, and MOS sensors, have traditionally been used to detect leaks. The challenge with these sensors is their versatility in settings involving many gases, as well as their exorbitant cost and scalability. As a result, several gas detection approaches were explored. Our approach utilizes 40 KHz ultrasound signal for gas detection. Here, the reflected signal has been analyzed to detect gas leaks and identify gas in real-time, providing a quick, reliable solution for gas leak detection in industrial environments. The electronics and sensors used are both low-cost and easily scalable. The system incorporates commonly accessible materials and off-the-shelf components, making it suitable for use in a variety of contexts. They are also more effective at detecting numerous gas leaks and has a longer lifetime. Butane was used to test our system. The breaches were identified in 0.01 seconds after permitting gas to flow from a broken pipe, whereas identifying the gas took 0.8 seconds
Image Shortcut Squeezing: Countering Perturbative Availability Poisons with Compression
Jan 31, 2023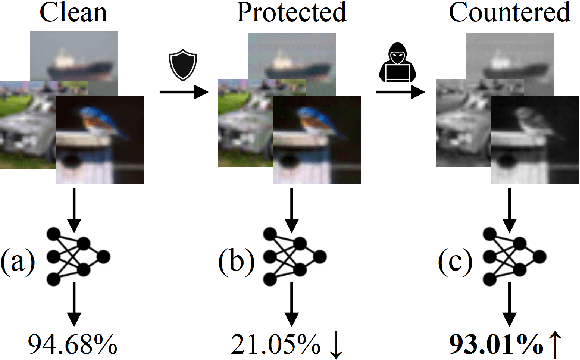
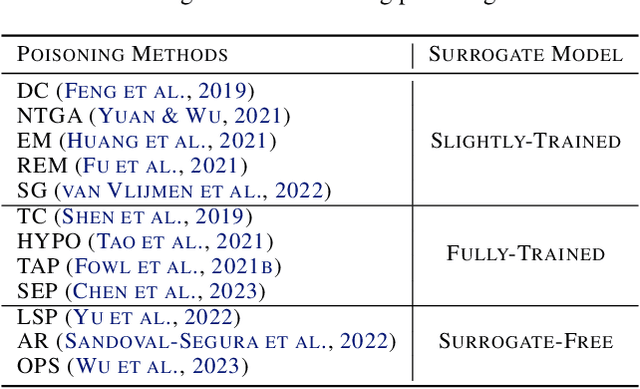
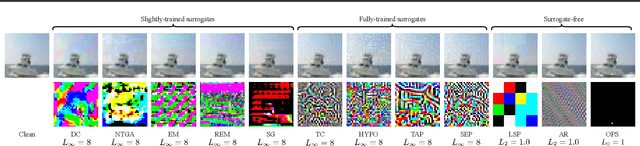
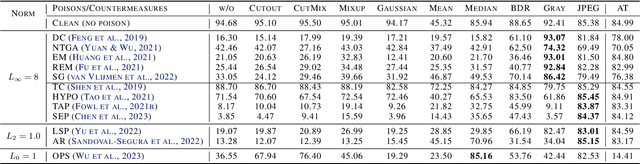
Perturbative availability poisoning (PAP) adds small changes to images to prevent their use for model training. Current research adopts the belief that practical and effective approaches to countering such poisons do not exist. In this paper, we argue that it is time to abandon this belief. We present extensive experiments showing that 12 state-of-the-art PAP methods are vulnerable to Image Shortcut Squeezing (ISS), which is based on simple compression. For example, on average, ISS restores the CIFAR-10 model accuracy to $81.73\%$, surpassing the previous best preprocessing-based countermeasures by $37.97\%$ absolute. ISS also (slightly) outperforms adversarial training and has higher generalizability to unseen perturbation norms and also higher efficiency. Our investigation reveals that the property of PAP perturbations depends on the type of surrogate model used for poison generation, and it explains why a specific ISS compression yields the best performance for a specific type of PAP perturbation. We further test stronger, adaptive poisoning, and show it falls short of being an ideal defense against ISS. Overall, our results demonstrate the importance of considering various (simple) countermeasures to ensure the meaningfulness of analysis carried out during the development of availability poisons.
Efficient Graph-Friendly COCO Metric Computation for Train-Time Model Evaluation
Jul 21, 2022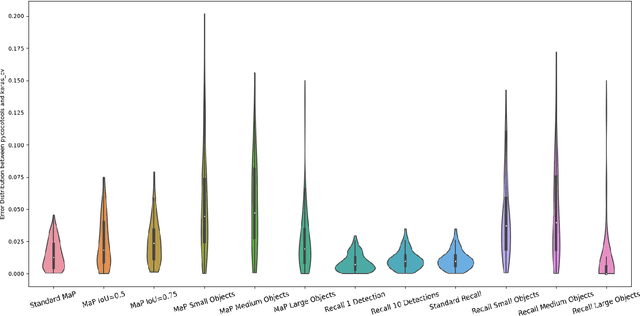
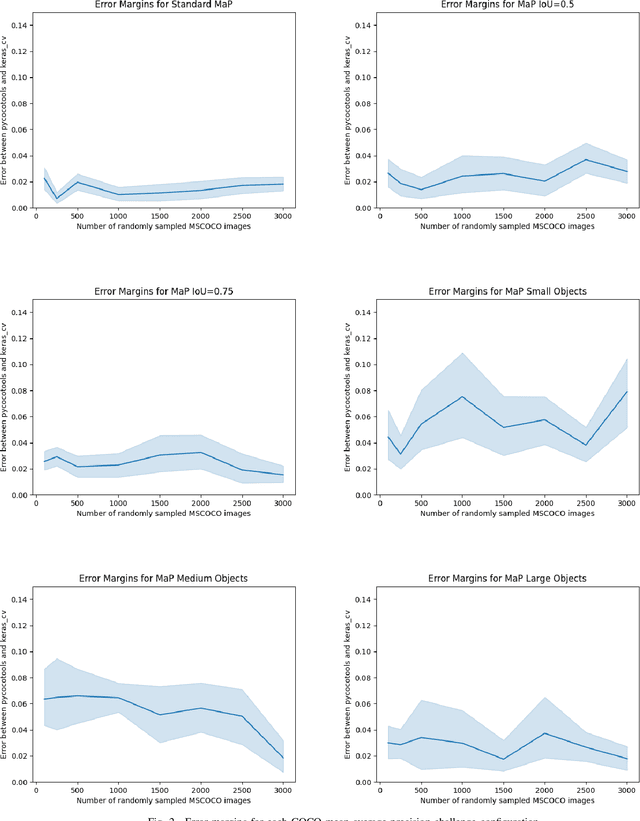
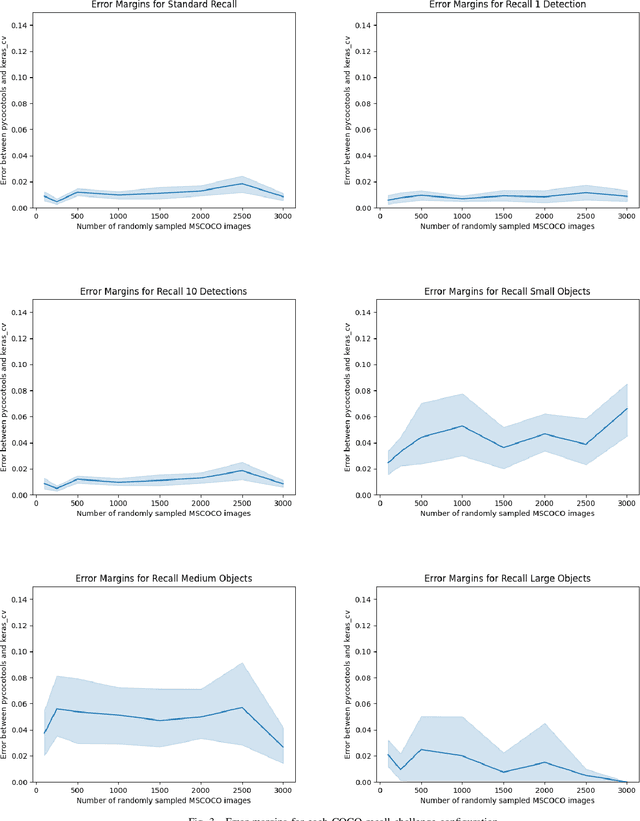
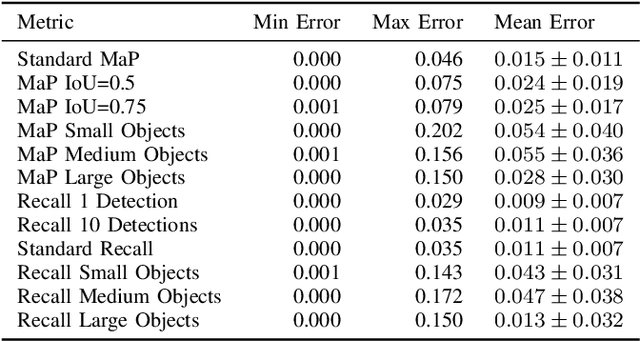
Evaluating the COCO mean average precision (MaP) and COCO recall metrics as part of the static computation graph of modern deep learning frameworks poses a unique set of challenges. These challenges include the need for maintaining a dynamic-sized state to compute mean average precision, reliance on global dataset-level statistics to compute the metrics, and managing differing numbers of bounding boxes between images in a batch. As a consequence, it is common practice for researchers and practitioners to evaluate COCO metrics as a post training evaluation step. With a graph-friendly algorithm to compute COCO Mean Average Precision and recall, these metrics could be evaluated at training time, improving visibility into the evolution of the metrics through training curve plots, and decreasing iteration time when prototyping new model versions. Our contributions include an accurate approximation algorithm for Mean Average Precision, an open source implementation of both COCO mean average precision and COCO recall, extensive numerical benchmarks to verify the accuracy of our implementations, and an open-source training loop that include train-time evaluation of mean average precision and recall.
PROFHIT: Probabilistic Robust Forecasting for Hierarchical Time-series
Jun 20, 2022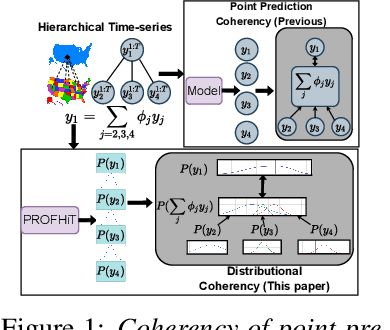
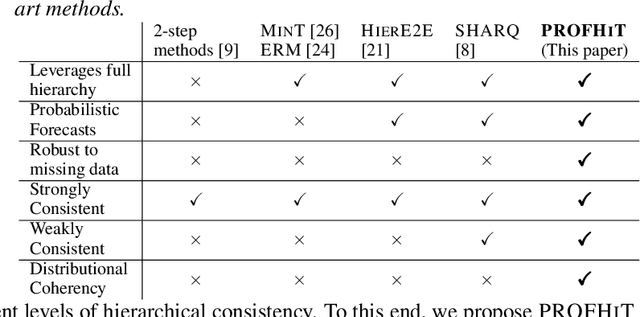
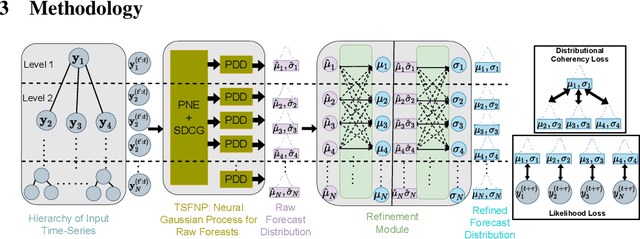
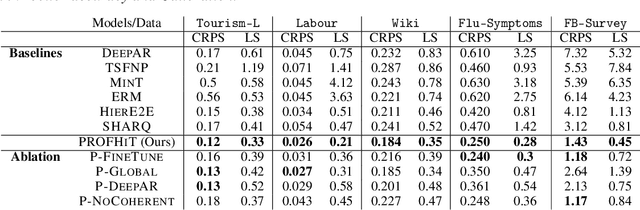
Probabilistic hierarchical time-series forecasting is an important variant of time-series forecasting, where the goal is to model and forecast multivariate time-series that have underlying hierarchical relations. Most methods focus on point predictions and do not provide well-calibrated probabilistic forecasts distributions. Recent state-of-art probabilistic forecasting methods also impose hierarchical relations on point predictions and samples of distribution which does not account for coherency of forecast distributions. Previous works also silently assume that datasets are always consistent with given hierarchical relations and do not adapt to real-world datasets that show deviation from this assumption. We close both these gaps and propose PROFHIT, which is a fully probabilistic hierarchical forecasting model that jointly models forecast distribution of entire hierarchy. PROFHIT uses a flexible probabilistic Bayesian approach and introduces a novel Distributional Coherency regularization to learn from hierarchical relations for entire forecast distribution that enables robust and calibrated forecasts as well as adapt to datasets of varying hierarchical consistency. On evaluating PROFHIT over wide range of datasets, we observed 41-88% better performance in accuracy and calibration. Due to modeling the coherency over full distribution, we observed that PROFHIT can robustly provide reliable forecasts even if up to 10% of input time-series data is missing where other methods' performance severely degrade by over 70%.
Inversion of Time-Lapse Surface Gravity Data for Detection of 3D CO$_2$ Plumes via Deep Learning
Sep 06, 2022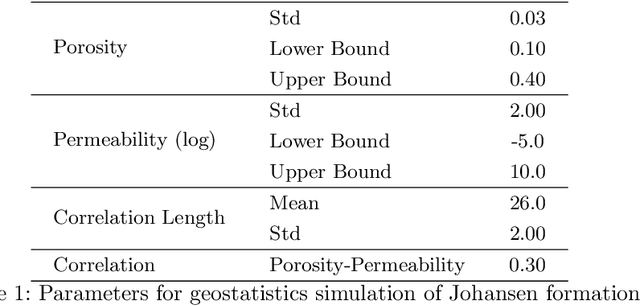
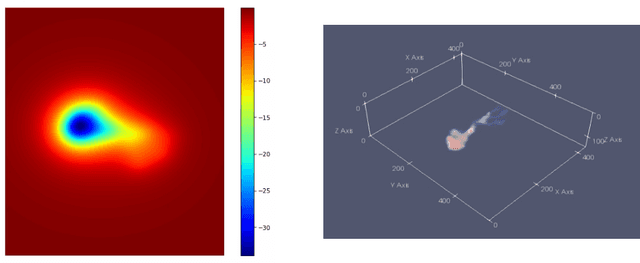
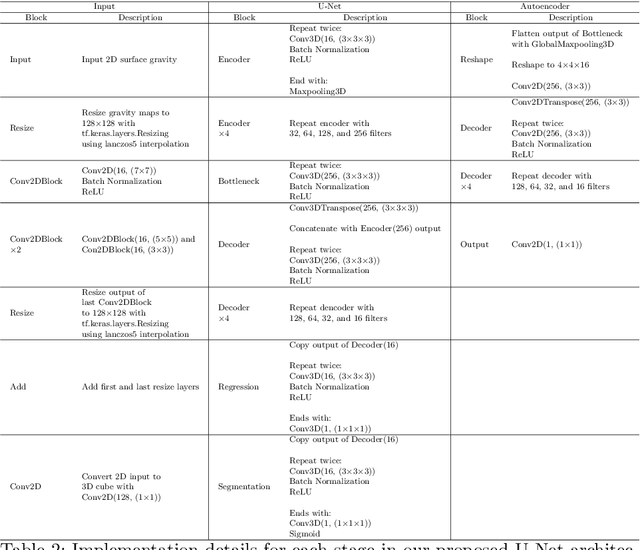
We introduce three algorithms that invert simulated gravity data to 3D subsurface rock/flow properties. The first algorithm is a data-driven, deep learning-based approach, the second mixes a deep learning approach with physical modeling into a single workflow, and the third considers the time dependence of surface gravity monitoring. The target application of these proposed algorithms is the prediction of subsurface CO$_2$ plumes as a complementary tool for monitoring CO$_2$ sequestration deployments. Each proposed algorithm outperforms traditional inversion methods and produces high-resolution, 3D subsurface reconstructions in near real-time. Our proposed methods achieve Dice scores of up to 0.8 for predicted plume geometry and near perfect data misfit in terms of $\mu$Gals. These results indicate that combining 4D surface gravity monitoring with deep learning techniques represents a low-cost, rapid, and non-intrusive method for monitoring CO$_2$ storage sites.