 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Optimizing Data Shapley Interaction Calculation from O(2^n) to O(t n^2) for KNN models
Apr 02, 2023
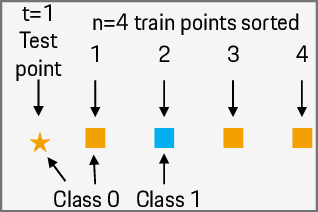
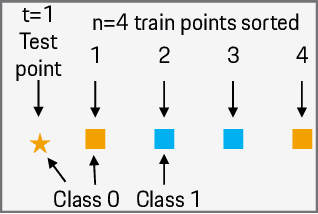
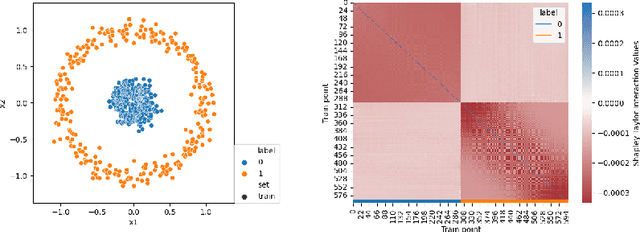
With the rapid growth of data availability and usage, quantifying the added value of each training data point has become a crucial process in the field of artificial intelligence. The Shapley values have been recognized as an effective method for data valuation, enabling efficient training set summarization, acquisition, and outlier removal. In this paper, we introduce "STI-KNN", an innovative algorithm that calculates the exact pair-interaction Shapley values for KNN models in O(t n^2) time, which is a significant improvement over the O(2^n)$ time complexity of baseline methods. By using STI-KNN, we can efficiently and accurately evaluate the value of individual data points, leading to improved training outcomes and ultimately enhancing the effectiveness of artificial intelligence applications.
Ensemble weather forecast post-processing with a flexible probabilistic neural network approach
Apr 07, 2023
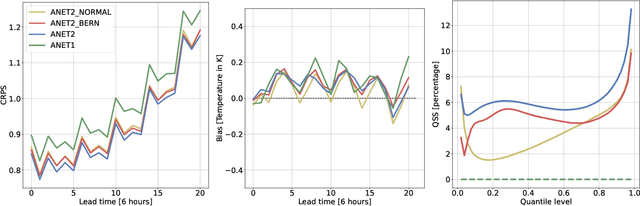
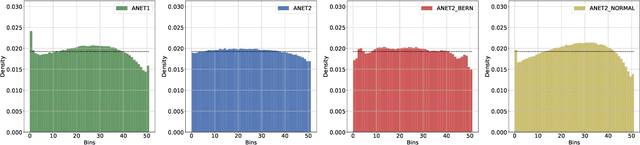
Ensemble forecast post-processing is a necessary step in producing accurate probabilistic forecasts. Conventional post-processing methods operate by estimating the parameters of a parametric distribution, frequently on a per-location or per-lead-time basis. We propose a novel, neural network-based method, which produces forecasts for all locations and lead times, jointly. To relax the distributional assumption of many post-processing methods, our approach incorporates normalizing flows as flexible parametric distribution estimators. This enables us to model varying forecast distributions in a mathematically exact way. We demonstrate the effectiveness of our method in the context of the EUPPBench benchmark, where we conduct temperature forecast post-processing for stations in a sub-region of western Europe. We show that our novel method exhibits state-of-the-art performance on the benchmark, outclassing our previous, well-performing entry. Additionally, by providing a detailed comparison of three variants of our novel post-processing method, we elucidate the reasons why our method outperforms per-lead-time-based approaches and approaches with distributional assumptions.
Fairness in AI and Its Long-Term Implications on Society
Apr 16, 2023
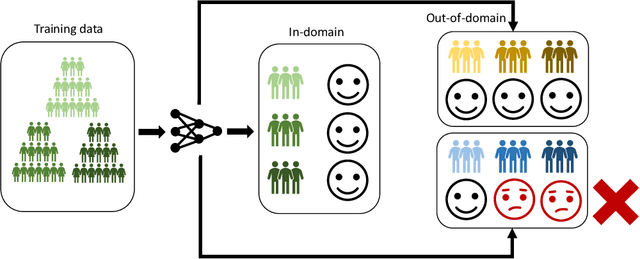

Successful deployment of artificial intelligence (AI) in various settings has led to numerous positive outcomes for individuals and society. However, AI systems have also been shown to harm parts of the population due to biased predictions. We take a closer look at AI fairness and analyse how lack of AI fairness can lead to deepening of biases over time and act as a social stressor. If the issues persist, it could have undesirable long-term implications on society, reinforced by interactions with other risks. We examine current strategies for improving AI fairness, assess their limitations in terms of real-world deployment, and explore potential paths forward to ensure we reap AI's benefits without harming significant parts of the society.
IC-FPS: Instance-Centroid Faster Point Sampling Module for 3D Point-base Object Detection
Mar 31, 2023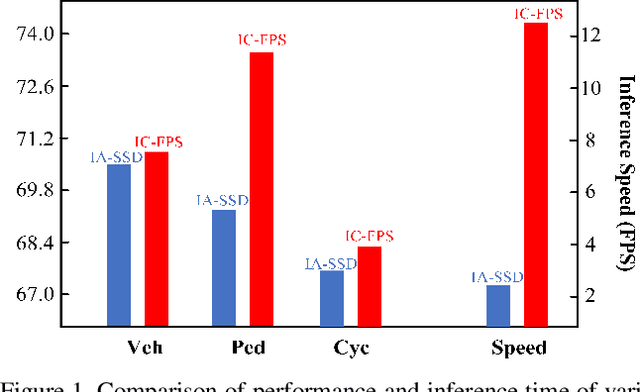
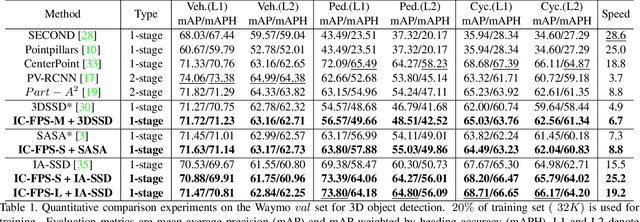
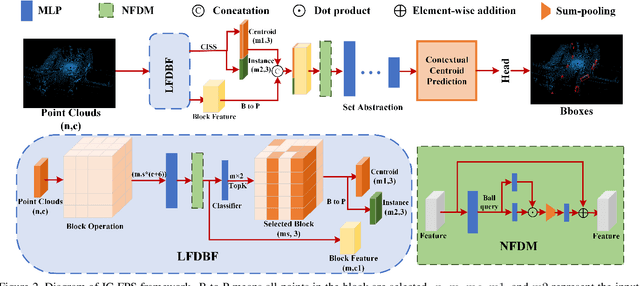
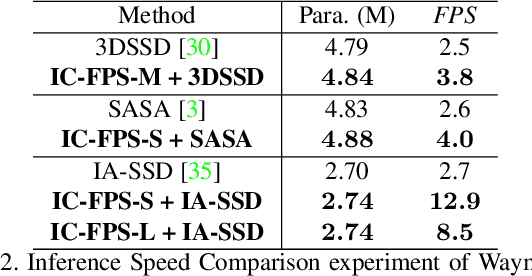
3D object detection is one of the most important tasks in autonomous driving and robotics. Our research focuses on tackling low efficiency issue of point-based methods on large-scale point clouds. Existing point-based methods adopt farthest point sampling (FPS) strategy for downsampling, which is computationally expensive in terms of inference time and memory consumption when the number of point cloud increases. In order to improve efficiency, we propose a novel Instance-Centroid Faster Point Sampling Module (IC-FPS) , which effectively replaces the first Set Abstraction (SA) layer that is extremely tedious. IC-FPS module is comprised of two methods, local feature diffusion based background point filter (LFDBF) and Centroid-Instance Sampling Strategy (CISS). LFDBF is constructed to exclude most invalid background points, while CISS substitutes FPS strategy by fast sampling centroids and instance points. IC-FPS module can be inserted to almost every point-based models. Extensive experiments on multiple public benchmarks have demonstrated the superiority of IC-FPS. On Waymo dataset, the proposed module significantly improves performance of baseline model and accelerates inference speed by 3.8 times. For the first time, real-time detection of point-based models in large-scale point cloud scenario is realized.
AIRCADE: an Anechoic and IR Convolution-based Auralization Data-compilation Ensemble
Apr 18, 2023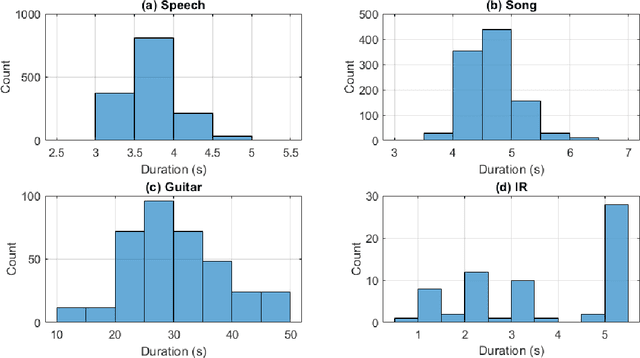
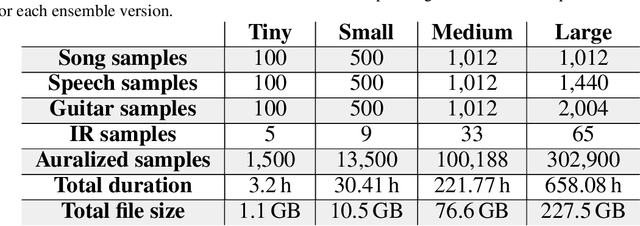
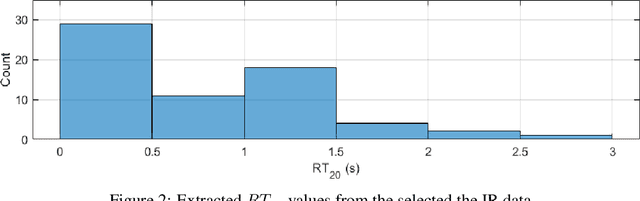
In this paper, we introduce a data-compilation ensemble, primarily intended to serve as a resource for researchers in the field of dereverberation, particularly for data-driven approaches. It comprises speech and song samples, together with acoustic guitar sounds, with original annotations pertinent to emotion recognition and Music Information Retrieval (MIR). Moreover, it includes a selection of impulse response (IR) samples with varying Reverberation Time (RT) values, providing a wide range of conditions for evaluation. This data-compilation can be used together with provided Python scripts, for generating auralized data ensembles in different sizes: tiny, small, medium and large. Additionally, the provided metadata annotations also allow for further analysis and investigation of the performance of dereverberation algorithms under different conditions. All data is licensed under Creative Commons Attribution 4.0 International License.
Early Detection of Parkinson's Disease using Motor Symptoms and Machine Learning
Apr 18, 2023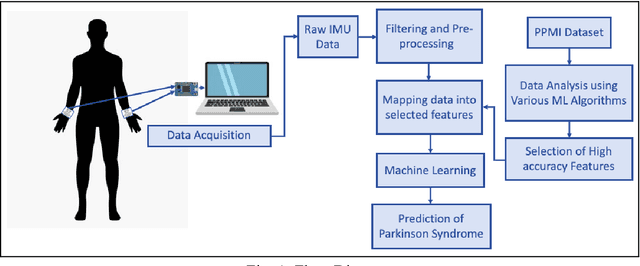
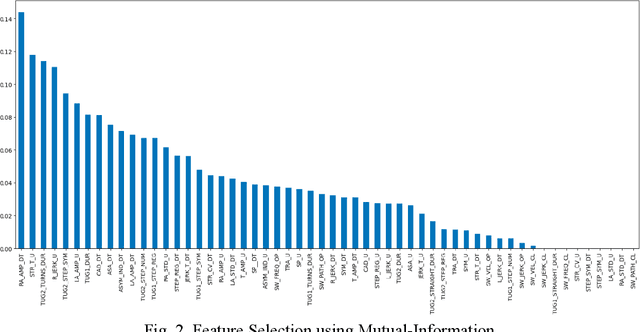
Parkinson's disease (PD) has been found to affect 1 out of every 1000 people, being more inclined towards the population above 60 years. Leveraging wearable-systems to find accurate biomarkers for diagnosis has become the need of the hour, especially for a neurodegenerative condition like Parkinson's. This work aims at focusing on early-occurring, common symptoms, such as motor and gait related parameters to arrive at a quantitative analysis on the feasibility of an economical and a robust wearable device. A subset of the Parkinson's Progression Markers Initiative (PPMI), PPMI Gait dataset has been utilised for feature-selection after a thorough analysis with various Machine Learning algorithms. Identified influential features has then been used to test real-time data for early detection of Parkinson Syndrome, with a model accuracy of 91.9%
Cardiac Arrhythmia Detection using Artificial Neural Network
Apr 17, 2023The prime purpose of this project is to develop a portable cardiac abnormality monitoring device which can drastically improvise the quality of the monitoring and the overall safety of the device. While a generic, low cost, wearable battery powered device for such applications may not yield sufficient performance, such devices combined with the capabilities of Artificial Neural Network algorithms can however, prove to be as competent as high end flexible and wearable monitoring devices fabricated using advanced manufacturing technologies. This paper evaluates the feasibility of the Levenberg-Marquardt ANN algorithm for use in any generic low power wearable devices implemented either as a pure real-time embedded system or as an IoT device capable of uploading the monitored readings to the cloud.
Snacks: a fast large-scale kernel SVM solver
Apr 17, 2023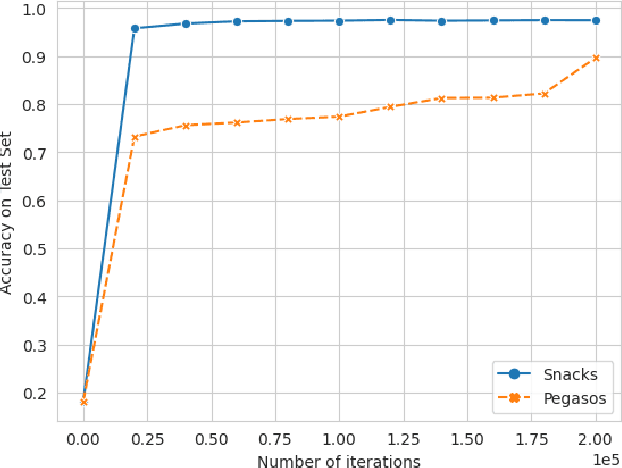
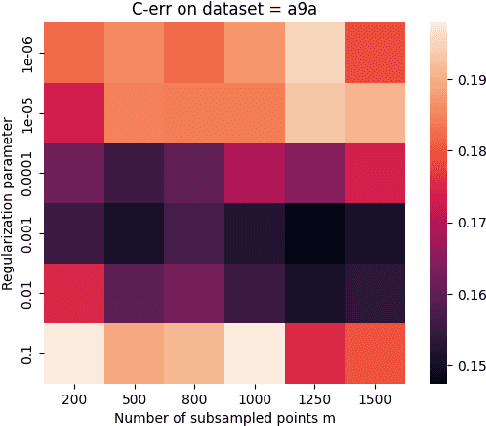

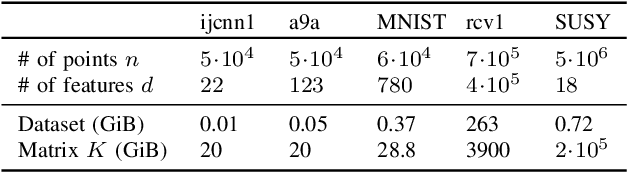
Kernel methods provide a powerful framework for non parametric learning. They are based on kernel functions and allow learning in a rich functional space while applying linear statistical learning tools, such as Ridge Regression or Support Vector Machines. However, standard kernel methods suffer from a quadratic time and memory complexity in the number of data points and thus have limited applications in large-scale learning. In this paper, we propose Snacks, a new large-scale solver for Kernel Support Vector Machines. Specifically, Snacks relies on a Nystr\"om approximation of the kernel matrix and an accelerated variant of the stochastic subgradient method. We demonstrate formally through a detailed empirical evaluation, that it competes with other SVM solvers on a variety of benchmark datasets.
Safe Control Transitions: Machine Vision Based Observable Readiness Index and Data-Driven Takeover Time Prediction
Jan 18, 2023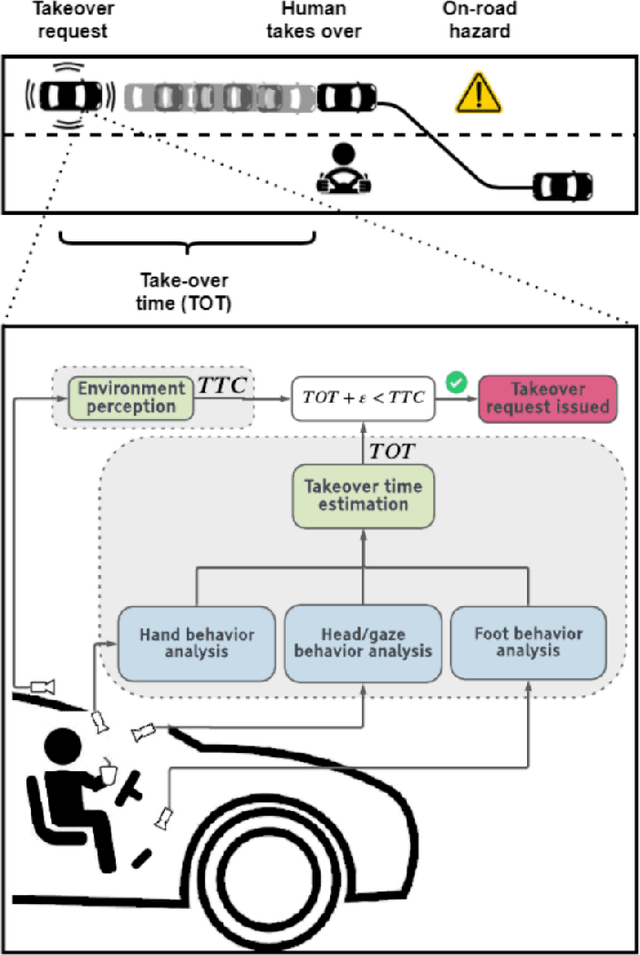
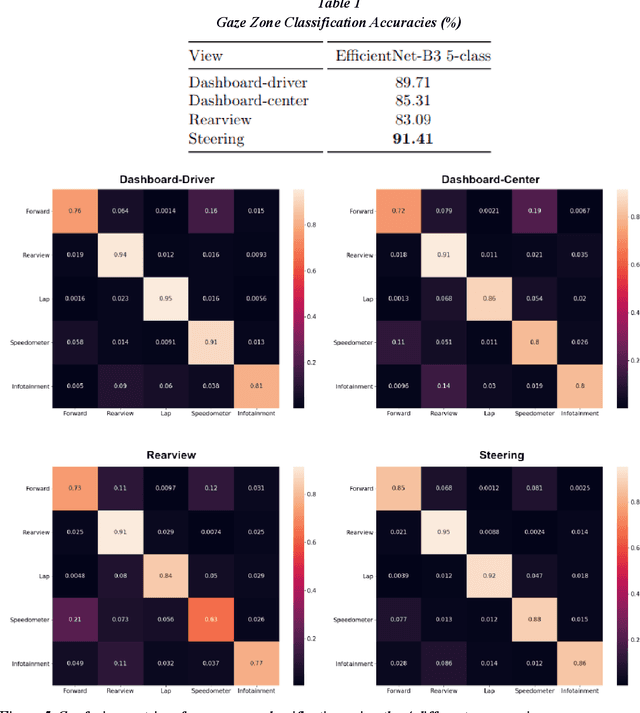
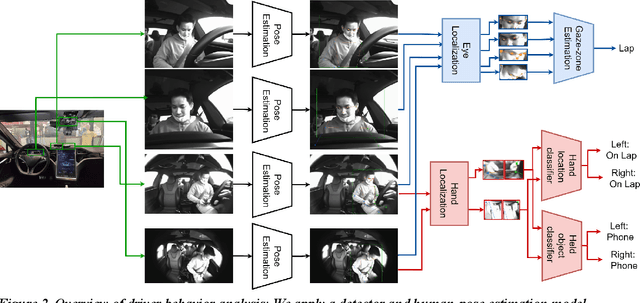
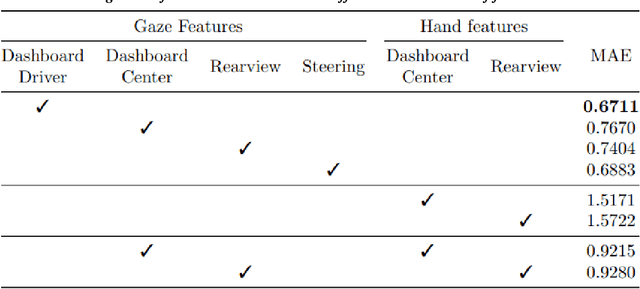
To make safe transitions from autonomous to manual control, a vehicle must have a representation of the awareness of driver state; two metrics which quantify this state are the Observable Readiness Index and Takeover Time. In this work, we show that machine learning models which predict these two metrics are robust to multiple camera views, expanding from the limited view angles in prior research. Importantly, these models take as input feature vectors corresponding to hand location and activity as well as gaze location, and we explore the tradeoffs of different views in generating these feature vectors. Further, we introduce two metrics to evaluate the quality of control transitions following the takeover event (the maximal lateral deviation and velocity deviation) and compute correlations of these post-takeover metrics to the pre-takeover predictive metrics.
HyMo: Vulnerability Detection in Smart Contracts using a Novel Multi-Modal Hybrid Model
Apr 25, 2023

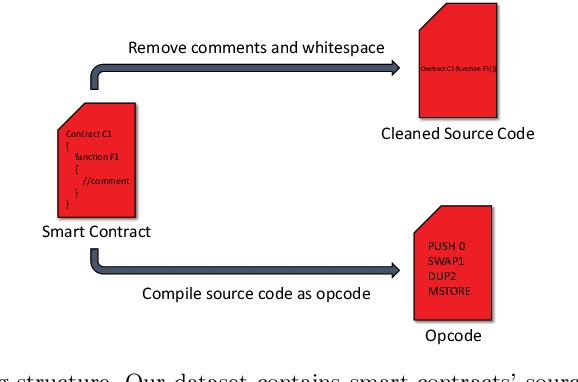
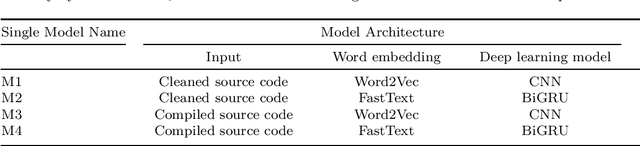
With blockchain technology rapidly progress, the smart contracts have become a common tool in a number of industries including finance, healthcare, insurance and gaming. The number of smart contracts has multiplied, and at the same time, the security of smart contracts has drawn considerable attention due to the monetary losses brought on by smart contract vulnerabilities. Existing analysis techniques are capable of identifying a large number of smart contract security flaws, but they rely too much on rigid criteria established by specialists, where the detection process takes much longer as the complexity of the smart contract rises. In this paper, we propose HyMo as a multi-modal hybrid deep learning model, which intelligently considers various input representations to consider multimodality and FastText word embedding technique, which represents each word as an n-gram of characters with BiGRU deep learning technique, as a sequence processing model that consists of two GRUs to achieve higher accuracy in smart contract vulnerability detection. The model gathers features using various deep learning models to identify the smart contract vulnerabilities. Through a series of studies on the currently publicly accessible dataset such as ScrawlD, we show that our hybrid HyMo model has excellent smart contract vulnerability detection performance. Therefore, HyMo performs better detection of smart contract vulnerabilities against other approaches.