 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Scaling Pareto-Efficient Decision Making Via Offline Multi-Objective RL
Apr 30, 2023
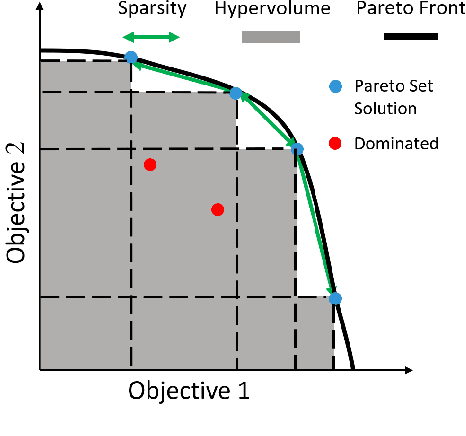

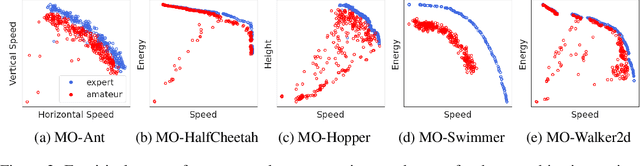
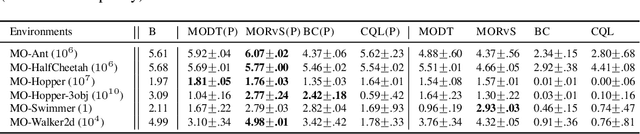
The goal of multi-objective reinforcement learning (MORL) is to learn policies that simultaneously optimize multiple competing objectives. In practice, an agent's preferences over the objectives may not be known apriori, and hence, we require policies that can generalize to arbitrary preferences at test time. In this work, we propose a new data-driven setup for offline MORL, where we wish to learn a preference-agnostic policy agent using only a finite dataset of offline demonstrations of other agents and their preferences. The key contributions of this work are two-fold. First, we introduce D4MORL, (D)atasets for MORL that are specifically designed for offline settings. It contains 1.8 million annotated demonstrations obtained by rolling out reference policies that optimize for randomly sampled preferences on 6 MuJoCo environments with 2-3 objectives each. Second, we propose Pareto-Efficient Decision Agents (PEDA), a family of offline MORL algorithms that builds and extends Decision Transformers via a novel preference-and-return-conditioned policy. Empirically, we show that PEDA closely approximates the behavioral policy on the D4MORL benchmark and provides an excellent approximation of the Pareto-front with appropriate conditioning, as measured by the hypervolume and sparsity metrics.
Online Learning with Adversaries: A Differential Inclusion Analysis
Apr 04, 2023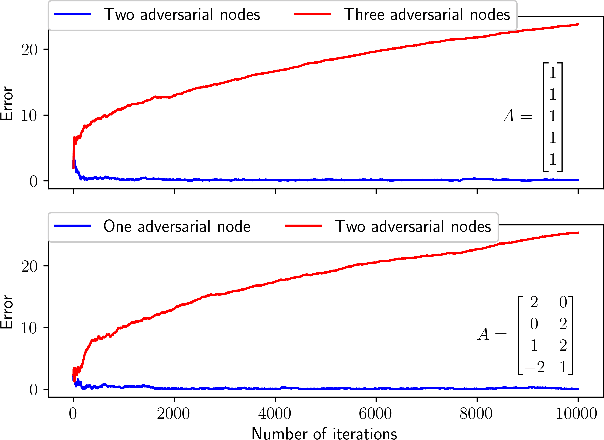
We consider the measurement model $Y = AX,$ where $X$ and, hence, $Y$ are random variables and $A$ is an a priori known tall matrix. At each time instance, a sample of one of $Y$'s coordinates is available, and the goal is to estimate $\mu := \mathbb{E}[X]$ via these samples. However, the challenge is that a small but unknown subset of $Y$'s coordinates are controlled by adversaries with infinite power: they can return any real number each time they are queried for a sample. For such an adversarial setting, we propose the first asynchronous online algorithm that converges to $\mu$ almost surely. We prove this result using a novel differential inclusion based two-timescale analysis. Two key highlights of our proof include: (a) the use of a novel Lyapunov function for showing that $\mu$ is the unique global attractor for our algorithm's limiting dynamics, and (b) the use of martingale and stopping time theory to show that our algorithm's iterates are almost surely bounded.
Quantum Persistent Homology for Time Series
Nov 08, 2022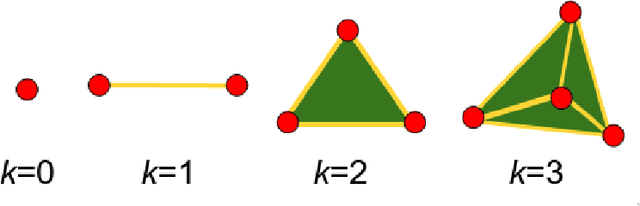
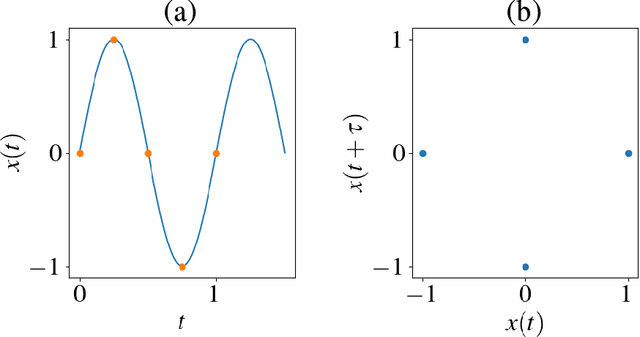
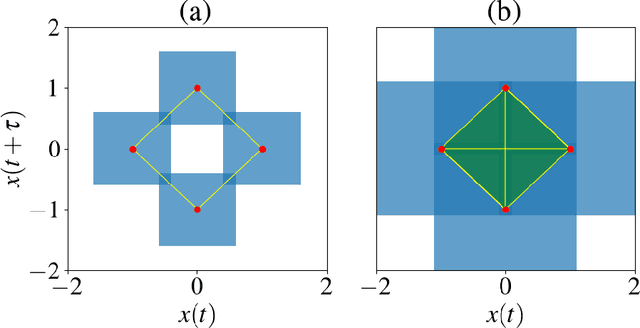
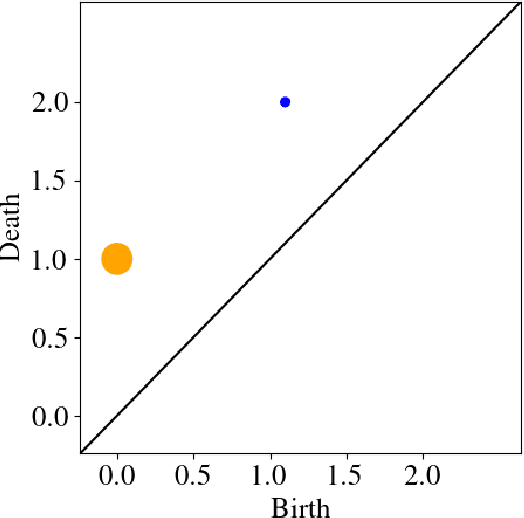
Persistent homology, a powerful mathematical tool for data analysis, summarizes the shape of data through tracking topological features across changes in different scales. Classical algorithms for persistent homology are often constrained by running times and memory requirements that grow exponentially on the number of data points. To surpass this problem, two quantum algorithms of persistent homology have been developed based on two different approaches. However, both of these quantum algorithms consider a data set in the form of a point cloud, which can be restrictive considering that many data sets come in the form of time series. In this paper, we alleviate this issue by establishing a quantum Takens's delay embedding algorithm, which turns a time series into a point cloud by considering a pertinent embedding into a higher dimensional space. Having this quantum transformation of time series to point clouds, then one may use a quantum persistent homology algorithm to extract the topological features from the point cloud associated with the original times series.
Unsupervised 4D LiDAR Moving Object Segmentation in Stationary Settings with Multivariate Occupancy Time Series
Dec 30, 2022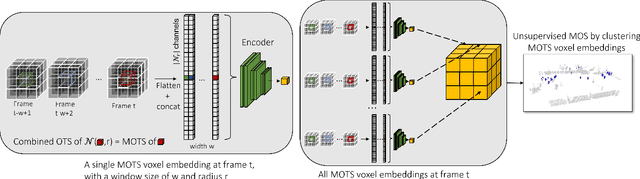

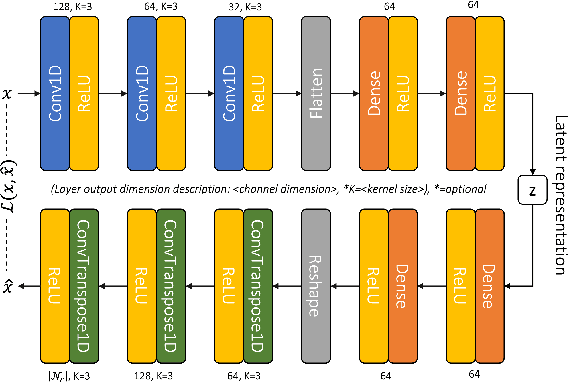

In this work, we address the problem of unsupervised moving object segmentation (MOS) in 4D LiDAR data recorded from a stationary sensor, where no ground truth annotations are involved. Deep learning-based state-of-the-art methods for LiDAR MOS strongly depend on annotated ground truth data, which is expensive to obtain and scarce in existence. To close this gap in the stationary setting, we propose a novel 4D LiDAR representation based on multivariate time series that relaxes the problem of unsupervised MOS to a time series clustering problem. More specifically, we propose modeling the change in occupancy of a voxel by a multivariate occupancy time series (MOTS), which captures spatio-temporal occupancy changes on the voxel level and its surrounding neighborhood. To perform unsupervised MOS, we train a neural network in a self-supervised manner to encode MOTS into voxel-level feature representations, which can be partitioned by a clustering algorithm into moving or stationary. Experiments on stationary scenes from the Raw KITTI dataset show that our fully unsupervised approach achieves performance that is comparable to that of supervised state-of-the-art approaches.
Cooperative Distributed MPC via Decentralized Real-Time Optimization: Implementation Results for Robot Formations
Jan 19, 2023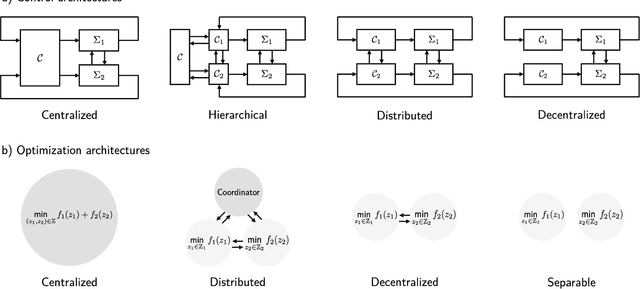


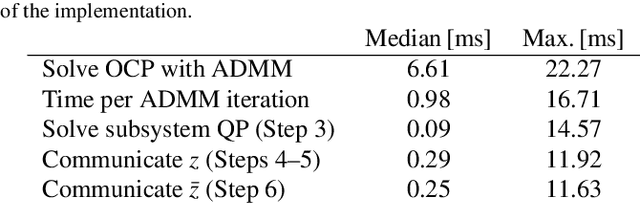
Distributed model predictive control (DMPC) is a flexible and scalable feedback control method applicable to a wide range of systems. While stability analysis of DMPC is quite well understood, there exist only limited implementation results for realistic applications involving distributed computation and networked communication. This article approaches formation control of mobile robots via a cooperative DMPC scheme. We discuss the implementation via decentralized optimization algorithms. To this end, we combine the alternating direction method of multipliers with decentralized sequential quadratic programming to solve the underlying optimal control problem in a decentralized fashion. Our approach only requires coupled subsystems to communicate and does not rely on a central coordinator. Our experimental results showcase the efficacy of DMPC for formation control and they demonstrate the real-time feasibility of the considered algorithms.
IoTFlowGenerator: Crafting Synthetic IoT Device Traffic Flows for Cyber Deception
May 01, 2023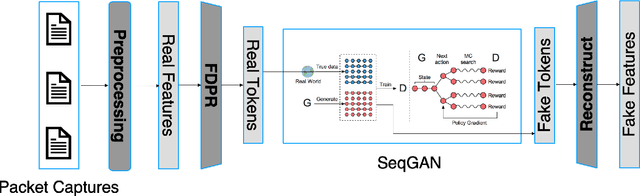
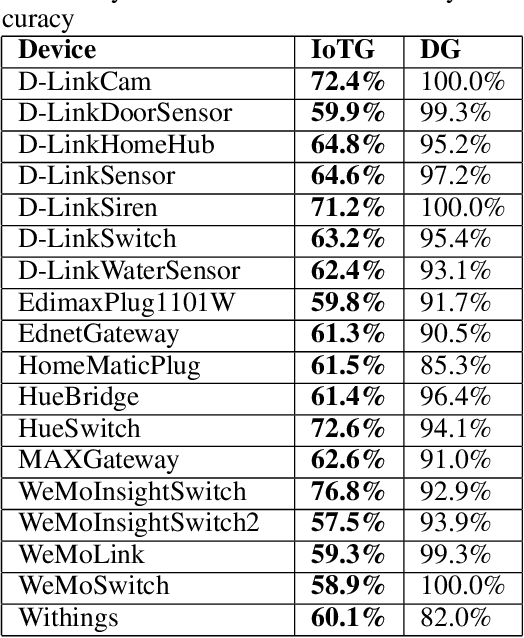
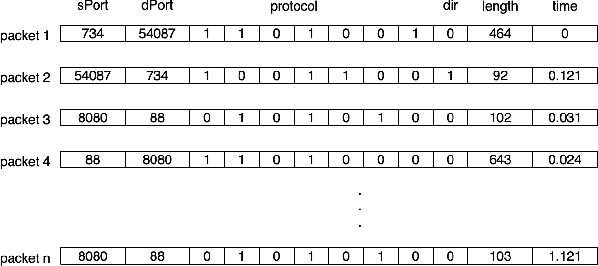

Over the years, honeypots emerged as an important security tool to understand attacker intent and deceive attackers to spend time and resources. Recently, honeypots are being deployed for Internet of things (IoT) devices to lure attackers, and learn their behavior. However, most of the existing IoT honeypots, even the high interaction ones, are easily detected by an attacker who can observe honeypot traffic due to lack of real network traffic originating from the honeypot. This implies that, to build better honeypots and enhance cyber deception capabilities, IoT honeypots need to generate realistic network traffic flows. To achieve this goal, we propose a novel deep learning based approach for generating traffic flows that mimic real network traffic due to user and IoT device interactions. A key technical challenge that our approach overcomes is scarcity of device-specific IoT traffic data to effectively train a generator. We address this challenge by leveraging a core generative adversarial learning algorithm for sequences along with domain specific knowledge common to IoT devices. Through an extensive experimental evaluation with 18 IoT devices, we demonstrate that the proposed synthetic IoT traffic generation tool significantly outperforms state of the art sequence and packet generators in remaining indistinguishable from real traffic even to an adaptive attacker.
Joint Modelling of Spoken Language Understanding Tasks with Integrated Dialog History
May 01, 2023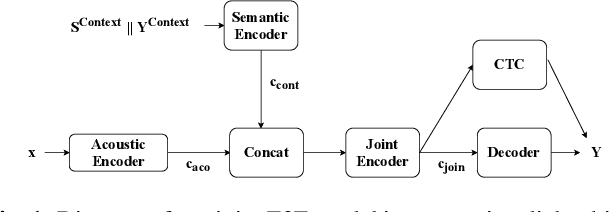

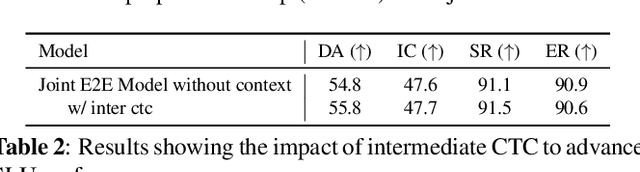

Most human interactions occur in the form of spoken conversations where the semantic meaning of a given utterance depends on the context. Each utterance in spoken conversation can be represented by many semantic and speaker attributes, and there has been an interest in building Spoken Language Understanding (SLU) systems for automatically predicting these attributes. Recent work has shown that incorporating dialogue history can help advance SLU performance. However, separate models are used for each SLU task, leading to an increase in inference time and computation cost. Motivated by this, we aim to ask: can we jointly model all the SLU tasks while incorporating context to facilitate low-latency and lightweight inference? To answer this, we propose a novel model architecture that learns dialog context to jointly predict the intent, dialog act, speaker role, and emotion for the spoken utterance. Note that our joint prediction is based on an autoregressive model and we need to decide the prediction order of dialog attributes, which is not trivial. To mitigate the issue, we also propose an order agnostic training method. Our experiments show that our joint model achieves similar results to task-specific classifiers and can effectively integrate dialog context to further improve the SLU performance.
Robustified Learning for Online Optimization with Memory Costs
May 01, 2023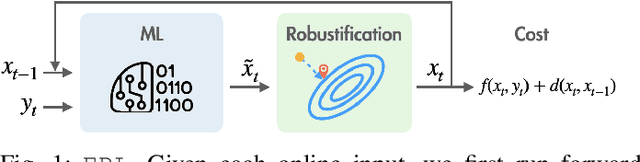
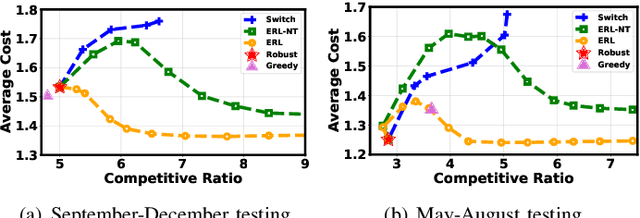


Online optimization with memory costs has many real-world applications, where sequential actions are made without knowing the future input. Nonetheless, the memory cost couples the actions over time, adding substantial challenges. Conventionally, this problem has been approached by various expert-designed online algorithms with the goal of achieving bounded worst-case competitive ratios, but the resulting average performance is often unsatisfactory. On the other hand, emerging machine learning (ML) based optimizers can improve the average performance, but suffer from the lack of worst-case performance robustness. In this paper, we propose a novel expert-robustified learning (ERL) approach, achieving {both} good average performance and robustness. More concretely, for robustness, ERL introduces a novel projection operator that robustifies ML actions by utilizing an expert online algorithm; for average performance, ERL trains the ML optimizer based on a recurrent architecture by explicitly considering downstream expert robustification. We prove that, for any $\lambda\geq1$, ERL can achieve $\lambda$-competitive against the expert algorithm and $\lambda\cdot C$-competitive against the optimal offline algorithm (where $C$ is the expert's competitive ratio). Additionally, we extend our analysis to a novel setting of multi-step memory costs. Finally, our analysis is supported by empirical experiments for an energy scheduling application.
Modeling Nonlinear Dynamics in Continuous Time with Inductive Biases on Decay Rates and/or Frequencies
Dec 26, 2022
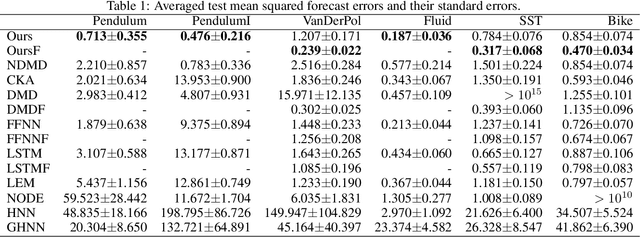
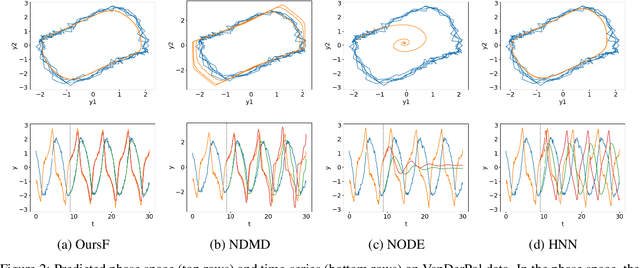

We propose a neural network-based model for nonlinear dynamics in continuous time that can impose inductive biases on decay rates and/or frequencies. Inductive biases are helpful for training neural networks especially when training data are small. The proposed model is based on the Koopman operator theory, where the decay rate and frequency information is used by restricting the eigenvalues of the Koopman operator that describe linear evolution in a Koopman space. We use neural networks to find an appropriate Koopman space, which are trained by minimizing multi-step forecasting and backcasting errors using irregularly sampled time-series data. Experiments on various time-series datasets demonstrate that the proposed method achieves higher forecasting performance given a single short training sequence than the existing methods.
AIRCADE: an Anechoic and IR Convolution-based Auralization Data-compilation Ensemble
Apr 24, 2023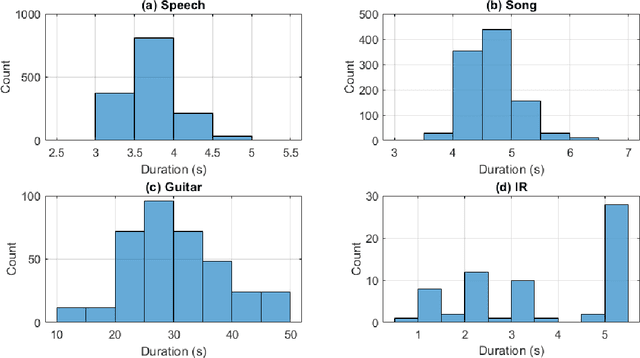
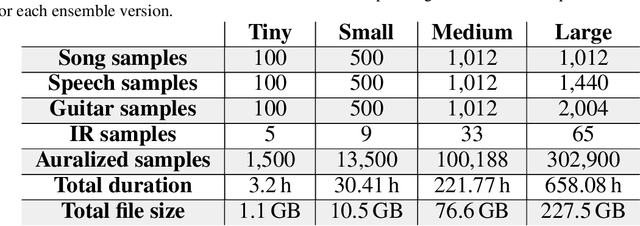
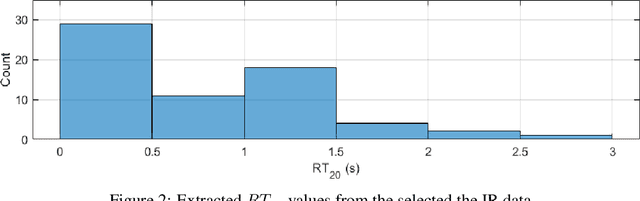
In this paper, we introduce a data-compilation ensemble, primarily intended to serve as a resource for researchers in the field of dereverberation, particularly for data-driven approaches. It comprises speech and song samples, together with acoustic guitar sounds, with original annotations pertinent to emotion recognition and Music Information Retrieval (MIR). Moreover, it includes a selection of impulse response (IR) samples with varying Reverberation Time (RT) values, providing a wide range of conditions for evaluation. This data-compilation can be used together with provided Python scripts, for generating auralized data ensembles in different sizes: tiny, small, medium and large. Additionally, the provided metadata annotations also allow for further analysis and investigation of the performance of dereverberation algorithms under different conditions. All data is licensed under Creative Commons Attribution 4.0 International License.