 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SFP: Spurious Feature-targeted Pruning for Out-of-Distribution Generalization
May 19, 2023
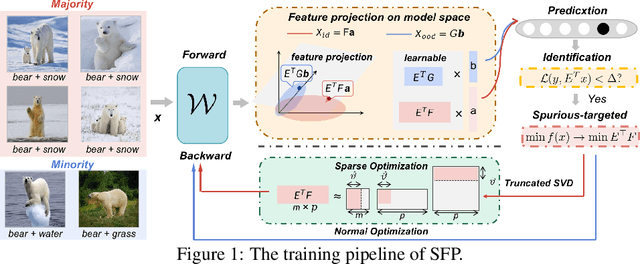
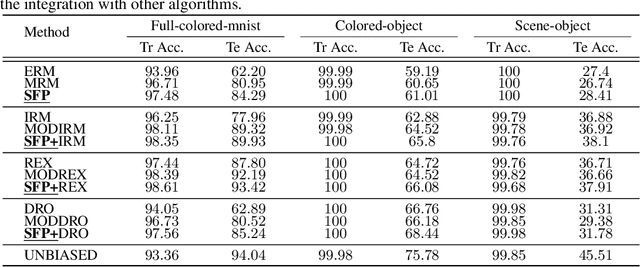

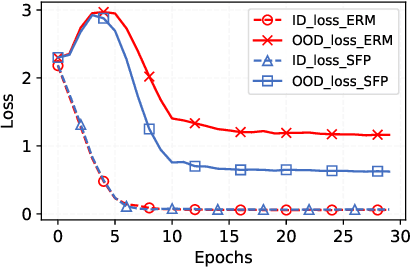
Model substructure learning aims to find an invariant network substructure that can have better out-of-distribution (OOD) generalization than the original full structure. Existing works usually search the invariant substructure using modular risk minimization (MRM) with fully exposed out-domain data, which may bring about two drawbacks: 1) Unfairness, due to the dependence of the full exposure of out-domain data; and 2) Sub-optimal OOD generalization, due to the equally feature-untargeted pruning on the whole data distribution. Based on the idea that in-distribution (ID) data with spurious features may have a lower experience risk, in this paper, we propose a novel Spurious Feature-targeted model Pruning framework, dubbed SFP, to automatically explore invariant substructures without referring to the above drawbacks. Specifically, SFP identifies spurious features within ID instances during training using our theoretically verified task loss, upon which, SFP attenuates the corresponding feature projections in model space to achieve the so-called spurious feature-targeted pruning. This is typically done by removing network branches with strong dependencies on identified spurious features, thus SFP can push the model learning toward invariant features and pull that out of spurious features and devise optimal OOD generalization. Moreover, we also conduct detailed theoretical analysis to provide the rationality guarantee and a proof framework for OOD structures via model sparsity, and for the first time, reveal how a highly biased data distribution affects the model's OOD generalization. Experiments on various OOD datasets show that SFP can significantly outperform both structure-based and non-structure-based OOD generalization SOTAs, with accuracy improvement up to 4.72% and 23.35%, respectively
Latent Interactive A2C for Improved RL in Open Many-Agent Systems
May 09, 2023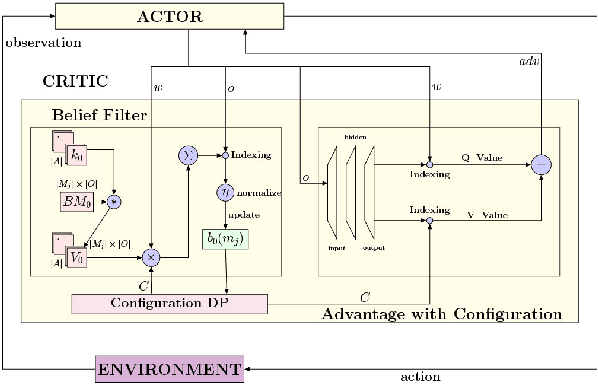
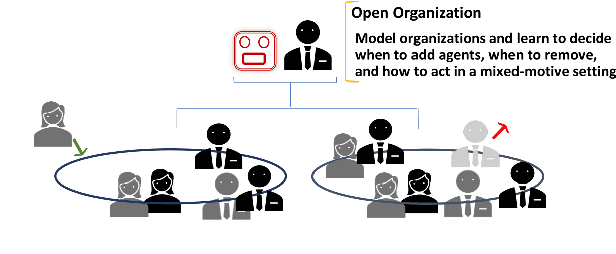
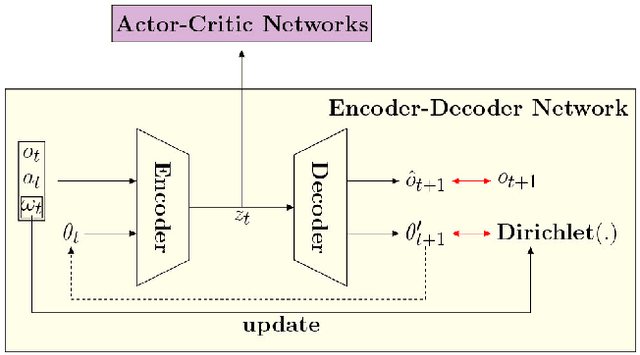
There is a prevalence of multiagent reinforcement learning (MARL) methods that engage in centralized training. But, these methods involve obtaining various types of information from the other agents, which may not be feasible in competitive or adversarial settings. A recent method, the interactive advantage actor critic (IA2C), engages in decentralized training coupled with decentralized execution, aiming to predict the other agents' actions from possibly noisy observations. In this paper, we present the latent IA2C that utilizes an encoder-decoder architecture to learn a latent representation of the hidden state and other agents' actions. Our experiments in two domains -- each populated by many agents -- reveal that the latent IA2C significantly improves sample efficiency by reducing variance and converging faster. Additionally, we introduce open versions of these domains where the agent population may change over time, and evaluate on these instances as well.
Collective Large-scale Wind Farm Multivariate Power Output Control Based on Hierarchical Communication Multi-Agent Proximal Policy Optimization
May 17, 2023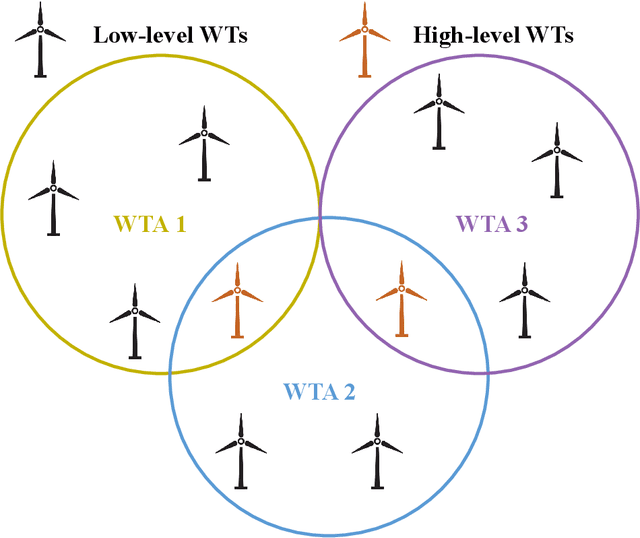

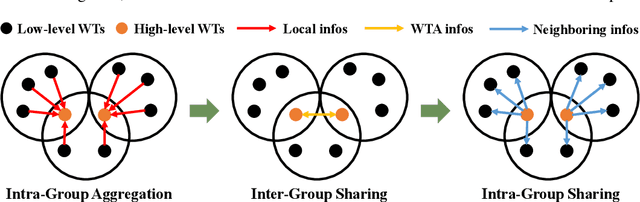
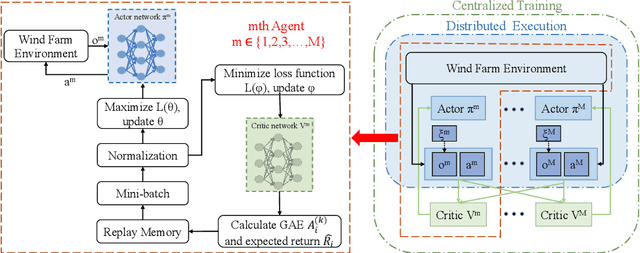
Wind power is becoming an increasingly important source of renewable energy worldwide. However, wind farm power control faces significant challenges due to the high system complexity inherent in these farms. A novel communication-based multi-agent deep reinforcement learning large-scale wind farm multivariate control is proposed to handle this challenge and maximize power output. A wind farm multivariate power model is proposed to study the influence of wind turbines (WTs) wake on power. The multivariate model includes axial induction factor, yaw angle, and tilt angle controllable variables. The hierarchical communication multi-agent proximal policy optimization (HCMAPPO) algorithm is proposed to coordinate the multivariate large-scale wind farm continuous controls. The large-scale wind farm is divided into multiple wind turbine aggregators (WTAs), and neighboring WTAs can exchange information through hierarchical communication to maximize the wind farm power output. Simulation results demonstrate that the proposed multivariate HCMAPPO can significantly increase wind farm power output compared to the traditional PID control, coordinated model-based predictive control, and multi-agent deep deterministic policy gradient algorithm. Particularly, the HCMAPPO algorithm can be trained with the environment based on the thirteen-turbine wind farm and effectively applied to larger wind farms. At the same time, there is no significant increase in the fatigue damage of the wind turbine blade from the wake control as the wind farm scale increases. The multivariate HCMAPPO control can realize the collective large-scale wind farm maximum power output.
PDP: Parameter-free Differentiable Pruning is All You Need
May 18, 2023
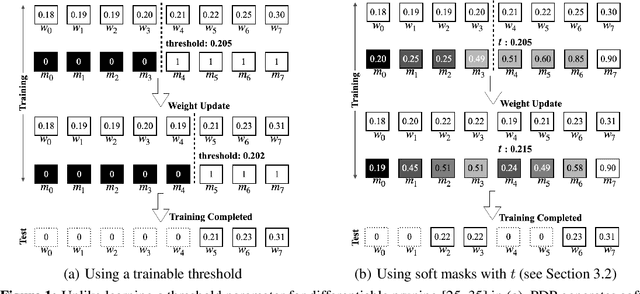

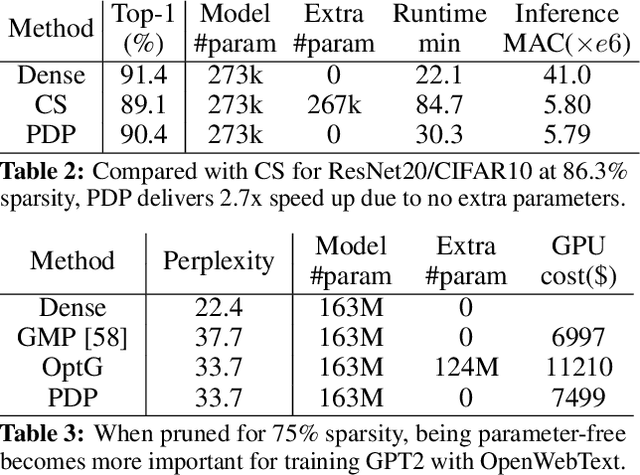
DNN pruning is a popular way to reduce the size of a model, improve the inference latency, and minimize the power consumption on DNN accelerators. However, existing approaches might be too complex, expensive or ineffective to apply to a variety of vision/language tasks, DNN architectures and to honor structured pruning constraints. In this paper, we propose an efficient yet effective train-time pruning scheme, Parameter-free Differentiable Pruning (PDP), which offers state-of-the-art qualities in model size, accuracy, and training cost. PDP uses a dynamic function of weights during training to generate soft pruning masks for the weights in a parameter-free manner for a given pruning target. While differentiable, the simplicity and efficiency of PDP make it universal enough to deliver state-of-the-art random/structured/channel pruning results on various vision and natural language tasks. For example, for MobileNet-v1, PDP can achieve 68.2% top-1 ImageNet1k accuracy at 86.6% sparsity, which is 1.7% higher accuracy than those from the state-of-the-art algorithms. Also, PDP yields over 83.1% accuracy on Multi-Genre Natural Language Inference with 90% sparsity for BERT, while the next best from the existing techniques shows 81.5% accuracy. In addition, PDP can be applied to structured pruning, such as N:M pruning and channel pruning. For 1:4 structured pruning of ResNet18, PDP improved the top-1 ImageNet1k accuracy by over 3.6% over the state-of-the-art. For channel pruning of ResNet50, PDP reduced the top-1 ImageNet1k accuracy by 0.6% from the state-of-the-art.
A Simple Generative Model of Logical Reasoning and Statistical Learning
May 18, 2023Statistical learning and logical reasoning are two major fields of AI expected to be unified for human-like machine intelligence. Most existing work considers how to combine existing logical and statistical systems. However, there is no theory of inference so far explaining how basic approaches to statistical learning and logical reasoning stem from a common principle. Inspired by the fact that much empirical work in neuroscience suggests Bayesian (or probabilistic generative) approaches to brain function including learning and reasoning, we here propose a simple Bayesian model of logical reasoning and statistical learning. The theory is statistically correct as it satisfies Kolmogorov's axioms, is consistent with both Fenstad's representation theorem and maximum likelihood estimation and performs exact Bayesian inference with a linear-time complexity. The theory is logically correct as it is a data-driven generalisation of uncertain reasoning from consistency, possibility, inconsistency and impossibility. The theory is correct in terms of machine learning as its solution to generation and prediction tasks on the MNIST dataset is not only empirically reasonable but also theoretically correct against the K nearest neighbour method. We simply model how data causes symbolic knowledge in terms of its satisfiability in formal logic. Symbolic reasoning emerges as a result of the process of going the causality forwards and backwards. The forward and backward processes correspond to an interpretation and inverse interpretation in formal logic, respectively. The inverse interpretation differentiates our work from the mainstream often referred to as inverse entailment, inverse deduction or inverse resolution. The perspective gives new insights into learning and reasoning towards human-like machine intelligence.
A Probabilistic Framework for Lifelong Test-Time Adaptation
Dec 19, 2022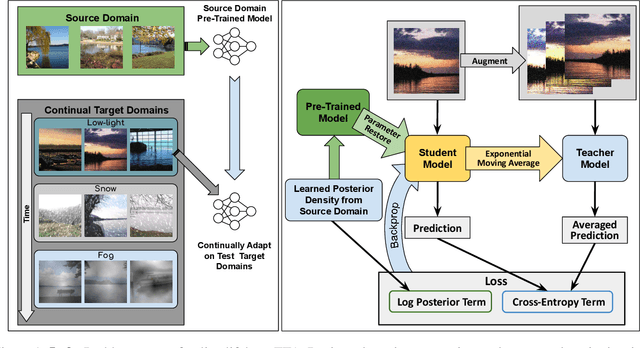
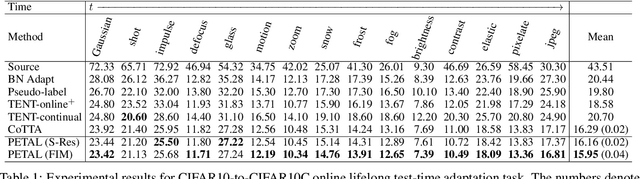
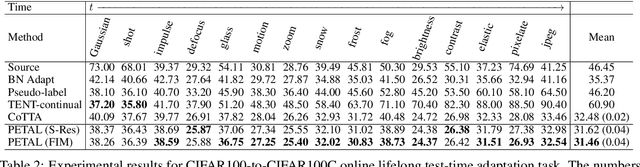
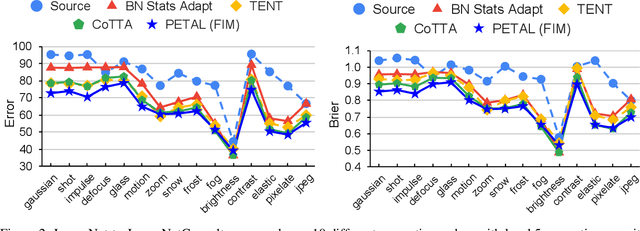
Test-time adaptation is the problem of adapting a source pre-trained model using test inputs from a target domain without access to source domain data. Most of the existing approaches address the setting in which the target domain is stationary. Moreover, these approaches are prone to making erroneous predictions with unreliable uncertainty estimates when distribution shifts occur. Hence, test-time adaptation in the face of non-stationary target domain shift becomes a problem of significant interest. To address these issues, we propose a principled approach, PETAL (Probabilistic lifElong Test-time Adaptation with seLf-training prior), which looks into this problem from a probabilistic perspective using a partly data-dependent prior. A student-teacher framework, where the teacher model is an exponential moving average of the student model naturally emerges from this probabilistic perspective. In addition, the knowledge from the posterior distribution obtained for the source task acts as a regularizer. To handle catastrophic forgetting in the long term, we also propose a data-driven model parameter resetting mechanism based on the Fisher information matrix (FIM). Moreover, improvements in experimental results suggest that FIM based data-driven parameter restoration contributes to reducing the error accumulation and maintaining the knowledge of recent domain by restoring only the irrelevant parameters. In terms of predictive error rate as well as uncertainty based metrics such as Brier score and negative log-likelihood, our method achieves better results than the current state-of-the-art for online lifelong test time adaptation across various benchmarks, such as CIFAR-10C, CIFAR-100C, ImageNetC, and ImageNet3DCC datasets.
Interactive Text-to-SQL Generation via Editable Step-by-Step Explanations
May 12, 2023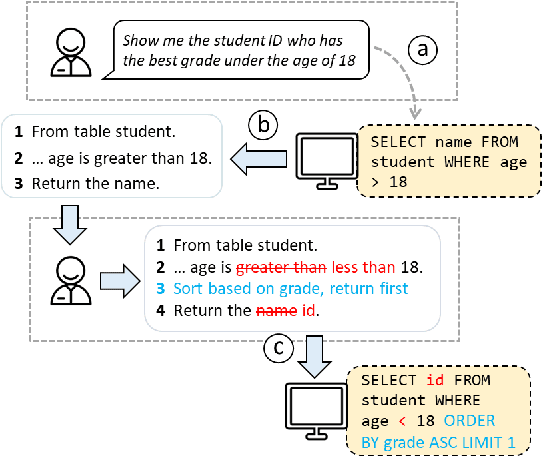
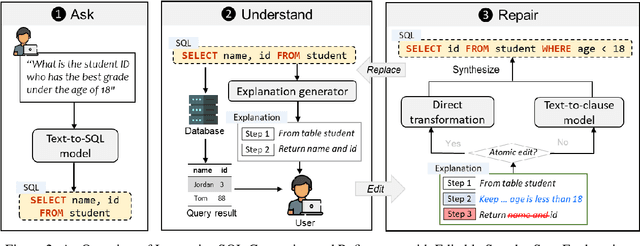
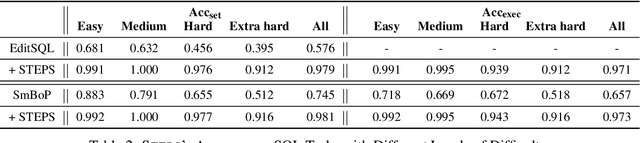
Relational databases play an important role in this Big Data era. However, it is challenging for non-experts to fully unleash the analytical power of relational databases, since they are not familiar with database languages such as SQL. Many techniques have been proposed to automatically generate SQL from natural language, but they suffer from two issues: (1) they still make many mistakes, particularly for complex queries, and (2) they do not provide a flexible way for non-expert users to validate and refine the incorrect queries. To address these issues, we introduce a new interaction mechanism that allows users directly edit a step-by-step explanation of an incorrect SQL to fix SQL errors. Experiments on the Spider benchmark show that our approach outperforms three SOTA approaches by at least 31.6% in terms of execution accuracy. A user study with 24 participants further shows that our approach helped users solve significantly more SQL tasks with less time and higher confidence, demonstrating its potential to expand access to databases, particularly for non-experts.
Multi-Agent Reinforcement Learning for Network Routing in Integrated Access Backhaul Networks
May 12, 2023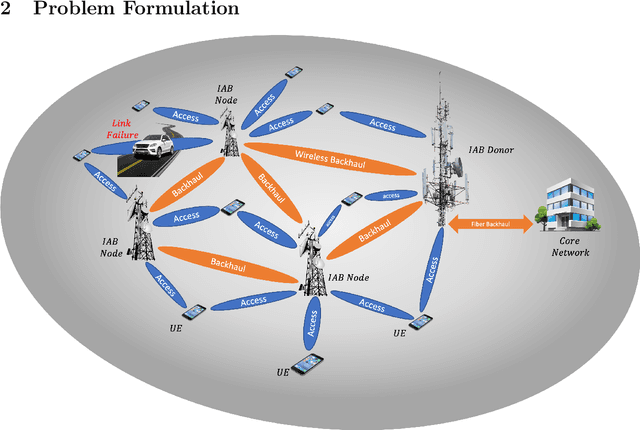
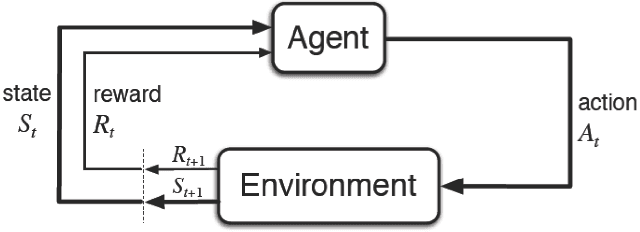
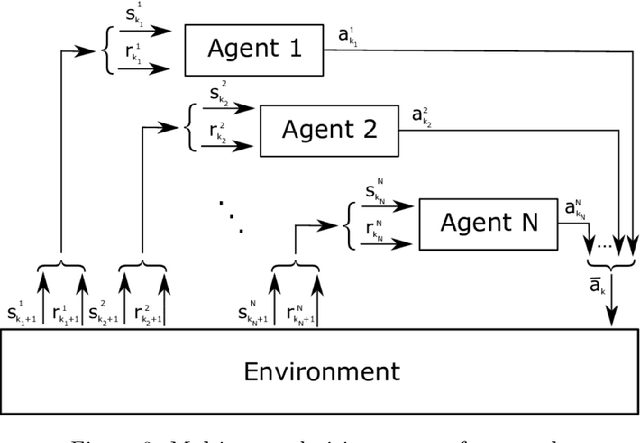

We investigate the problem of wireless routing in integrated access backhaul (IAB) networks consisting of fiber-connected and wireless base stations and multiple users. The physical constraints of these networks prevent the use of a central controller, and base stations have limited access to real-time network conditions. We aim to maximize packet arrival ratio while minimizing their latency, for this purpose, we formulate the problem as a multi-agent partially observed Markov decision process (POMDP). To solve this problem, we develop a Relational Advantage Actor Critic (Relational A2C) algorithm that uses Multi-Agent Reinforcement Learning (MARL) and information about similar destinations to derive a joint routing policy on a distributed basis. We present three training paradigms for this algorithm and demonstrate its ability to achieve near-centralized performance. Our results show that Relational A2C outperforms other reinforcement learning algorithms, leading to increased network efficiency and reduced selfish agent behavior. To the best of our knowledge, this work is the first to optimize routing strategy for IAB networks.
VBOC: Learning the Viability Boundary of a Robot Manipulator using Optimal Control
May 12, 2023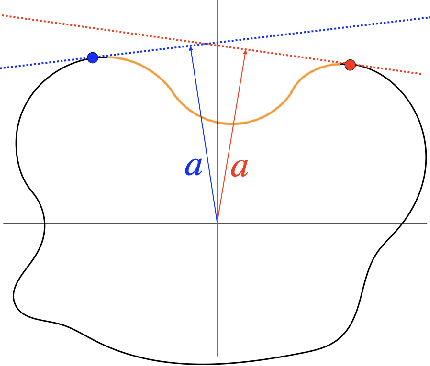
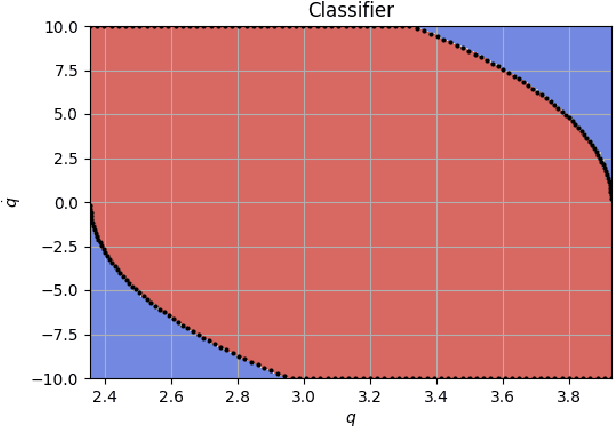
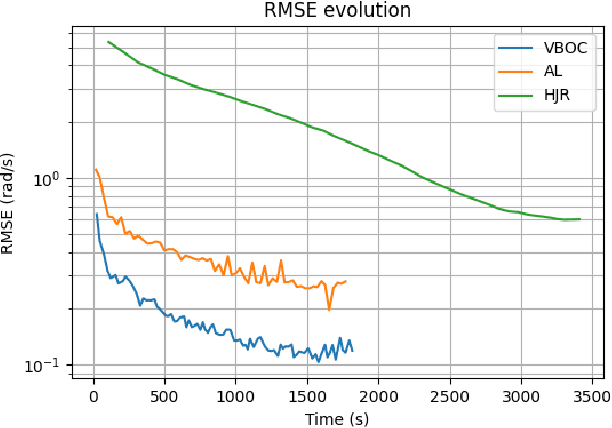
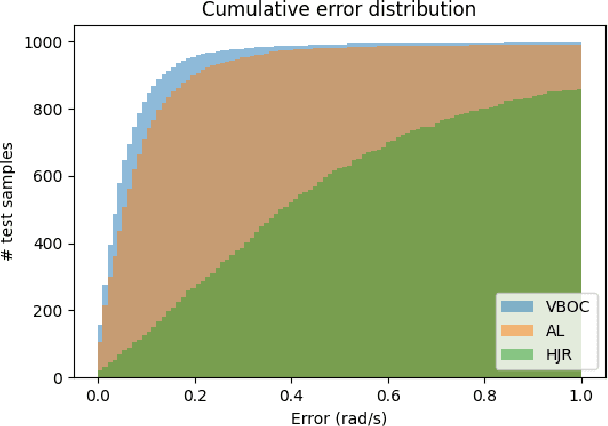
Safety is often the most important requirement in robotics applications. Nonetheless, control techniques that can provide safety guarantees are still extremely rare for nonlinear systems, such as robot manipulators. A well-known tool to ensure safety is the Viability kernel, which is the largest set of states from which safety can be ensured. Unfortunately, computing such a set for a nonlinear system is extremely challenging in general. Several numerical algorithms for approximating it have been proposed in the literature, but they suffer from the curse of dimensionality. This paper presents a new approach for numerically approximating the viability kernel of robot manipulators. Our approach solves optimal control problems to compute states that are guaranteed to be on the boundary of the set. This allows us to learn directly the set boundary, therefore learning in a smaller dimensional space. Compared to the state of the art on systems up to dimension 6, our algorithm resulted to be more than 2 times as accurate for the same computation time, or 6 times as fast to reach the same accuracy.
Unlocking the Potential of Medical Imaging with ChatGPT's Intelligent Diagnostics
May 12, 2023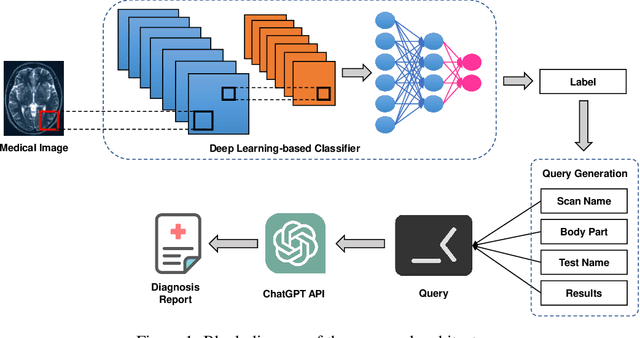
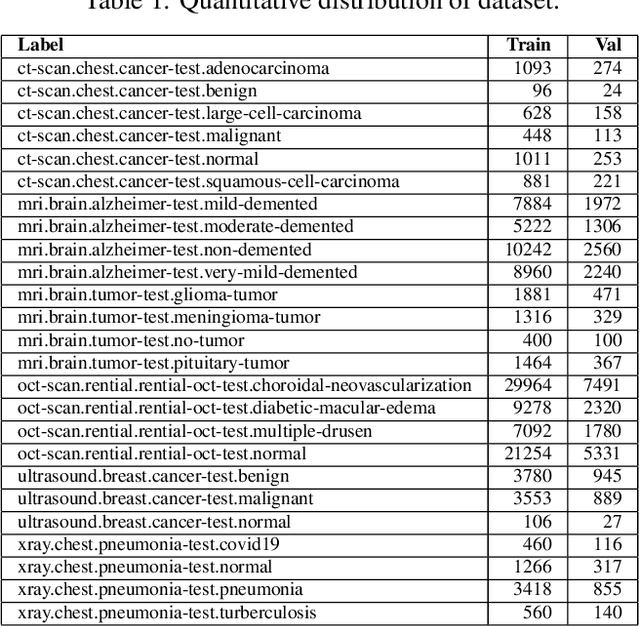
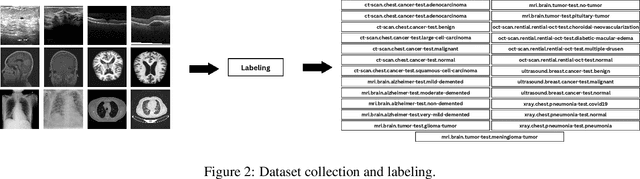
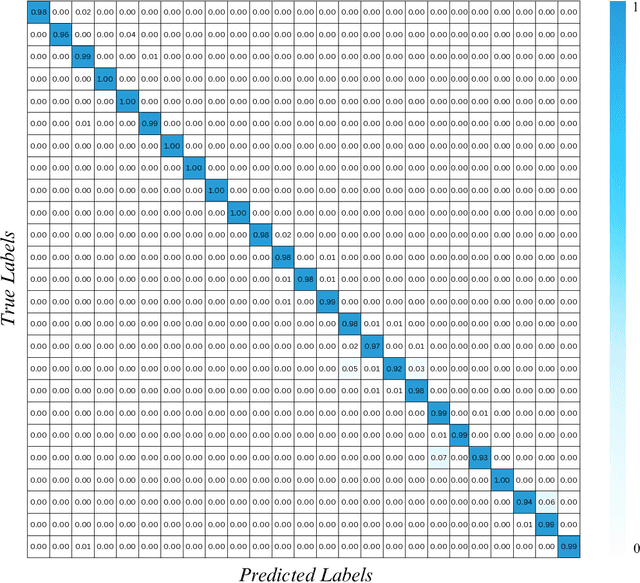
Medical imaging is an essential tool for diagnosing various healthcare diseases and conditions. However, analyzing medical images is a complex and time-consuming task that requires expertise and experience. This article aims to design a decision support system to assist healthcare providers and patients in making decisions about diagnosing, treating, and managing health conditions. The proposed architecture contains three stages: 1) data collection and labeling, 2) model training, and 3) diagnosis report generation. The key idea is to train a deep learning model on a medical image dataset to extract four types of information: the type of image scan, the body part, the test image, and the results. This information is then fed into ChatGPT to generate automatic diagnostics. The proposed system has the potential to enhance decision-making, reduce costs, and improve the capabilities of healthcare providers. The efficacy of the proposed system is analyzed by conducting extensive experiments on a large medical image dataset. The experimental outcomes exhibited promising performance for automatic diagnosis through medical images.