 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Slideflow: Deep Learning for Digital Histopathology with Real-Time Whole-Slide Visualization
Apr 09, 2023
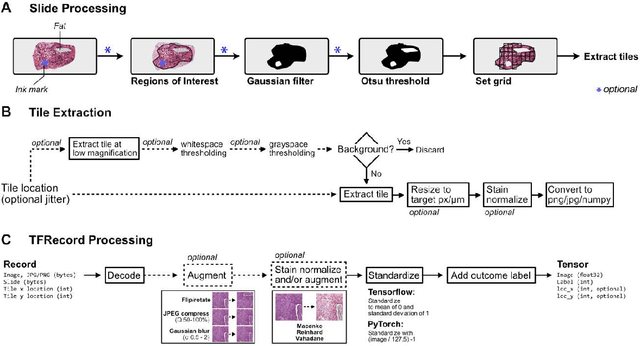
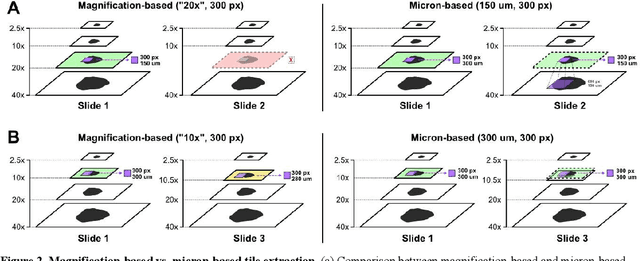
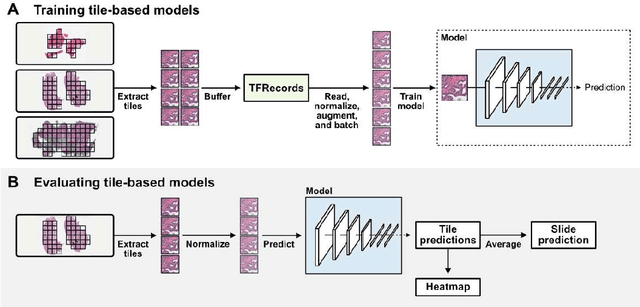
Deep learning methods have emerged as powerful tools for analyzing histopathological images, but current methods are often specialized for specific domains and software environments, and few open-source options exist for deploying models in an interactive interface. Experimenting with different deep learning approaches typically requires switching software libraries and reprocessing data, reducing the feasibility and practicality of experimenting with new architectures. We developed a flexible deep learning library for histopathology called Slideflow, a package which supports a broad array of deep learning methods for digital pathology and includes a fast whole-slide interface for deploying trained models. Slideflow includes unique tools for whole-slide image data processing, efficient stain normalization and augmentation, weakly-supervised whole-slide classification, uncertainty quantification, feature generation, feature space analysis, and explainability. Whole-slide image processing is highly optimized, enabling whole-slide tile extraction at 40X magnification in 2.5 seconds per slide. The framework-agnostic data processing pipeline enables rapid experimentation with new methods built with either Tensorflow or PyTorch, and the graphical user interface supports real-time visualization of slides, predictions, heatmaps, and feature space characteristics on a variety of hardware devices, including ARM-based devices such as the Raspberry Pi.
Predictive Maneuver Planning with Deep Reinforcement Learning (PMP-DRL) for comfortable and safe autonomous driving
Jun 15, 2023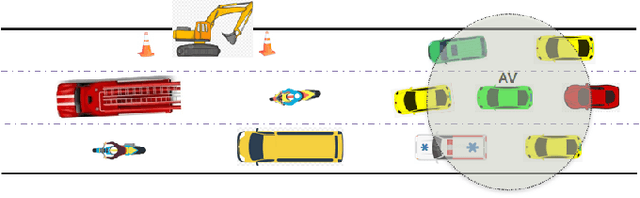
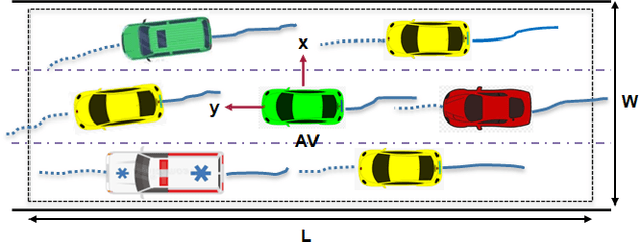
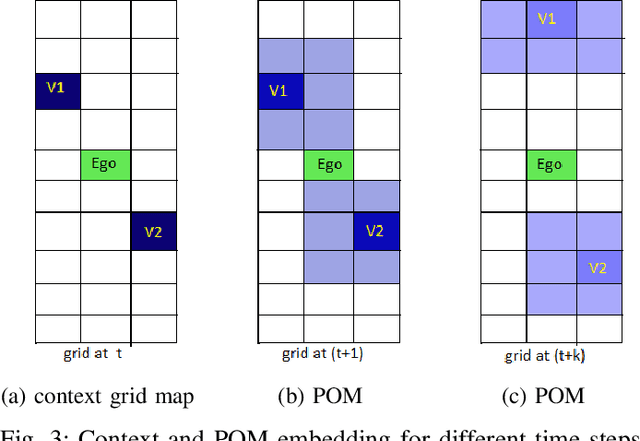
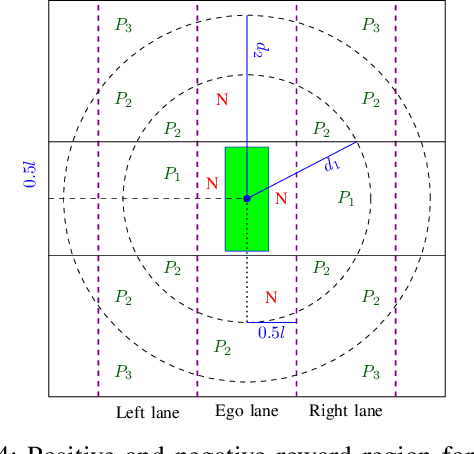
This paper presents a Predictive Maneuver Planning with Deep Reinforcement Learning (PMP-DRL) model for maneuver planning. Traditional rule-based maneuver planning approaches often have to improve their abilities to handle the variabilities of real-world driving scenarios. By learning from its experience, a Reinforcement Learning (RL)-based driving agent can adapt to changing driving conditions and improve its performance over time. Our proposed approach combines a predictive model and an RL agent to plan for comfortable and safe maneuvers. The predictive model is trained using historical driving data to predict the future positions of other surrounding vehicles. The surrounding vehicles' past and predicted future positions are embedded in context-aware grid maps. At the same time, the RL agent learns to make maneuvers based on this spatio-temporal context information. Performance evaluation of PMP-DRL has been carried out using simulated environments generated from publicly available NGSIM US101 and I80 datasets. The training sequence shows the continuous improvement in the driving experiences. It shows that proposed PMP-DRL can learn the trade-off between safety and comfortability. The decisions generated by the recent imitation learning-based model are compared with the proposed PMP-DRL for unseen scenarios. The results clearly show that PMP-DRL can handle complex real-world scenarios and make better comfortable and safe maneuver decisions than rule-based and imitative models.
Low Complexity Time Synchronization for Zero-padding based Waveforms
Mar 13, 2023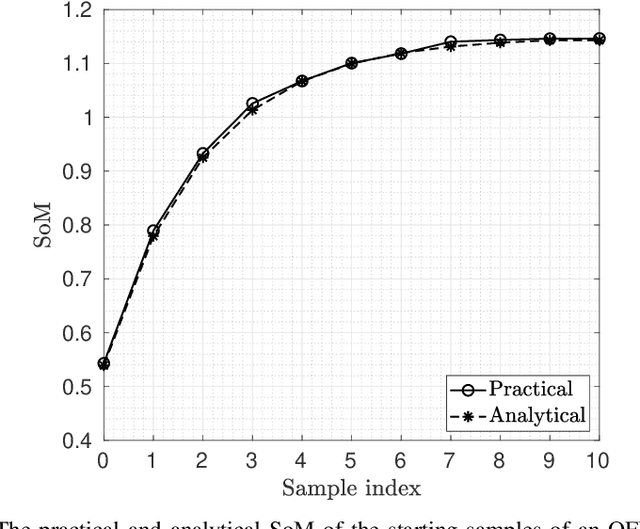
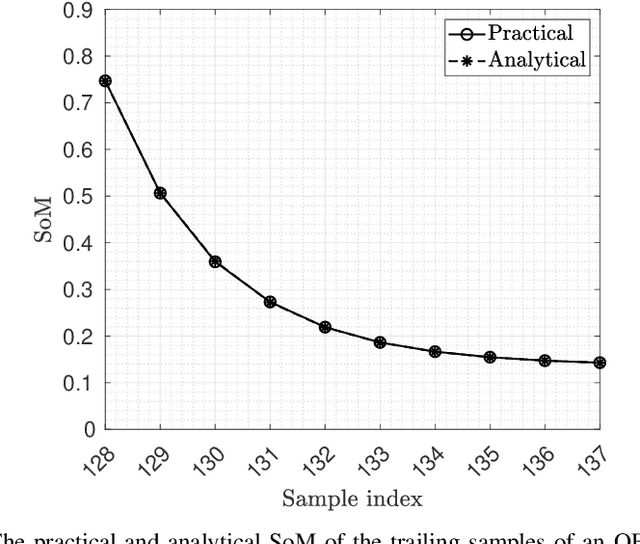
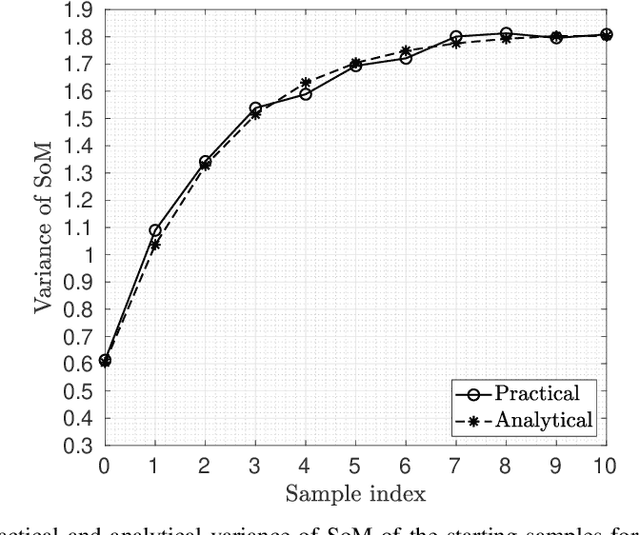
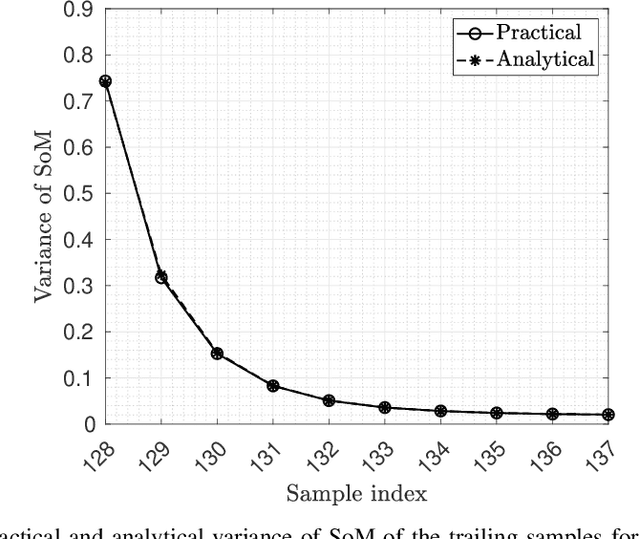
The discussion on using zero padding (ZP) instead of a cyclic prefix (CP) for enhancing channel estimation and equalization performance is a recurring topic in waveform design for future wireless systems that high spectral efficiency and location awareness are the key factors. This is particularly true for orthogonal signals, such as orthogonal frequency-division multiplexing (OFDM). ZP-OFDM is appealing for joint communications and sensing (JCS) in 6G networks because it takes the advantage of both OFDM and pulse radar. In term of communication, ZP-OFDM compared to CP-OFDM, has higher power efficiency and lower bit error rate (BER). However, time synchronization is challenging in ZP-OFDM systems due to the lack of CP. In terms of sensing, ZP facilitates ranging methods, such as time-sum-of-arrival (TSOA). In this paper, we propose a moment-based timing offset (TO) estimator for multiple-input multiple-output (MIMO) ZP-OFDM system without the need for pilots. We then introduce the which significantly improves the estimation accuracy of the previous estimator. We show that the proposed method asymptotically reaches the maximum likelihood (ML) estimator. Simulation results show very high probability of lock-in for the proposed estimators under various practical scenarios.
TauPETGen: Text-Conditional Tau PET Image Synthesis Based on Latent Diffusion Models
Jun 21, 2023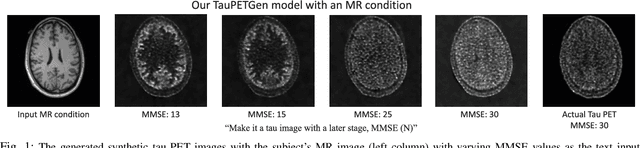
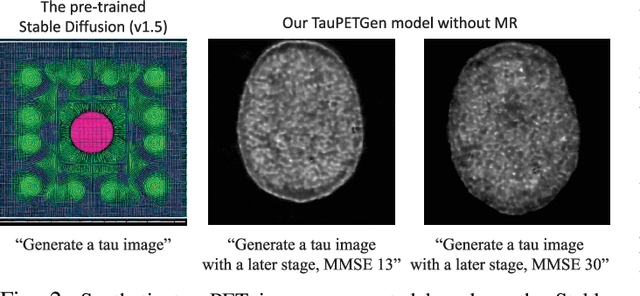
In this work, we developed a novel text-guided image synthesis technique which could generate realistic tau PET images from textual descriptions and the subject's MR image. The generated tau PET images have the potential to be used in examining relations between different measures and also increasing the public availability of tau PET datasets. The method was based on latent diffusion models. Both textual descriptions and the subject's MR prior image were utilized as conditions during image generation. The subject's MR image can provide anatomical details, while the text descriptions, such as gender, scan time, cognitive test scores, and amyloid status, can provide further guidance regarding where the tau neurofibrillary tangles might be deposited. Preliminary experimental results based on clinical [18F]MK-6240 datasets demonstrate the feasibility of the proposed method in generating realistic tau PET images at different clinical stages.
MLonMCU: TinyML Benchmarking with Fast Retargeting
Jun 15, 2023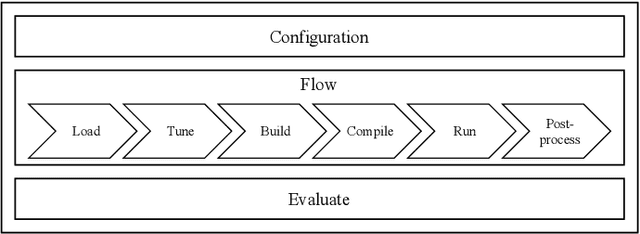

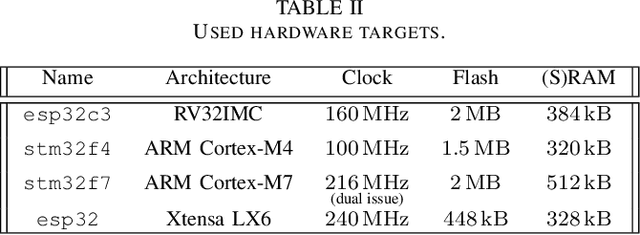

While there exist many ways to deploy machine learning models on microcontrollers, it is non-trivial to choose the optimal combination of frameworks and targets for a given application. Thus, automating the end-to-end benchmarking flow is of high relevance nowadays. A tool called MLonMCU is proposed in this paper and demonstrated by benchmarking the state-of-the-art TinyML frameworks TFLite for Microcontrollers and TVM effortlessly with a large number of configurations in a low amount of time.
Implementing BERT and fine-tuned RobertA to detect AI generated news by ChatGPT
Jun 09, 2023

The abundance of information on social media has increased the necessity of accurate real-time rumour detection. Manual techniques of identifying and verifying fake news generated by AI tools are impracticable and time-consuming given the enormous volume of information generated every day. This has sparked an increase in interest in creating automated systems to find fake news on the Internet. The studies in this research demonstrate that the BERT and RobertA models with fine-tuning had the best success in detecting AI generated news. With a score of 98%, tweaked RobertA in particular showed excellent precision. In conclusion, this study has shown that neural networks can be used to identify bogus news AI generation news created by ChatGPT. The RobertA and BERT models' excellent performance indicates that these models can play a critical role in the fight against misinformation.
ExtPerFC: An Efficient 2D and 3D Perception Hardware-Software Framework for Mobile Cobot
Jun 08, 2023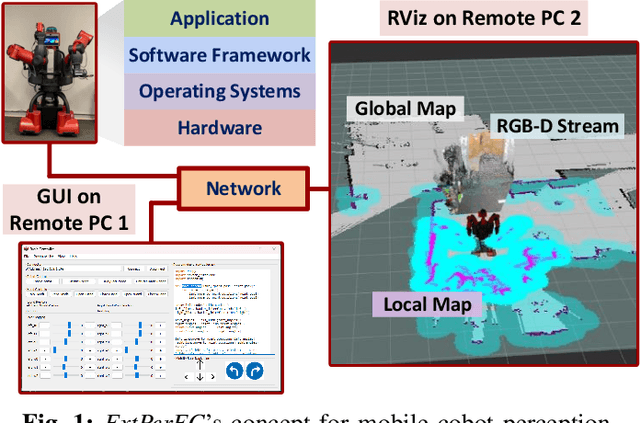


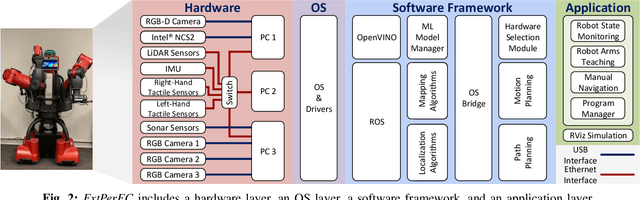
As the reliability of the robot's perception correlates with the number of integrated sensing modalities to tackle uncertainty, a practical solution to manage these sensors from different computers, operate them simultaneously, and maintain their real-time performance on the existing robotic system with minimal effort is needed. In this work, we present an end-to-end software-hardware framework, namely ExtPerFC, that supports both conventional hardware and software components and integrates machine learning object detectors without requiring an additional dedicated graphic processor unit (GPU). We first design our framework to achieve real-time performance on the existing robotic system, guarantee configuration optimization, and concentrate on code reusability. We then mathematically model and utilize our transfer learning strategies for 2D object detection and fuse them into depth images for 3D depth estimation. Lastly, we systematically test the proposed framework on the Baxter robot with two 7-DOF arms, a four-wheel mobility base, and an Intel RealSense D435i RGB-D camera. The results show that the robot achieves real-time performance while executing other tasks (e.g., map building, localization, navigation, object detection, arm moving, and grasping) simultaneously with available hardware like Intel onboard CPUS/GPUs on distributed computers. Also, to comprehensively control, program, and monitor the robot system, we design and introduce an end-user application. The source code is available at https://github.com/tuantdang/perception_framework.
Time Encoding Sampling of Bandpass Signals
Feb 15, 2023This paper investigates the problem of sampling and reconstructing bandpass signals using time encoding machine(TEM). It is shown that the sampling in principle is equivalent to periodic non-uniform sampling (PNS). Then the TEM parameters can be set according to the signal bandwidth and amplitude instead of upper-edge frequency and amplitude as in the case of bandlimited/lowpass signals. For a bandpass signal of a single information band, it can be perfectly reconstructed if the TEM parameters are such that the difference between any consecutive values of the time sequence in each channel is bounded by the inverse of the signal bandwidth. A reconstruction method incorporating the interpolation functions of PNS is proposed. Numerical experiments validate the feasibility and effectiveness of the proposed TEM scheme.
Label-efficient Time Series Representation Learning: A Review
Feb 13, 2023
The scarcity of labeled data is one of the main challenges of applying deep learning models on time series data in the real world. Therefore, several approaches, e.g., transfer learning, self-supervised learning, and semi-supervised learning, have been recently developed to promote the learning capability of deep learning models from the limited time series labels. In this survey, for the first time, we provide a novel taxonomy to categorize existing approaches that address the scarcity of labeled data problem in time series data based on their reliance on external data sources. Moreover, we present a review of the recent advances in each approach and conclude the limitations of the current works and provide future directions that could yield better progress in the field.
Studying Generalization on Memory-Based Methods in Continual Learning
Jun 20, 2023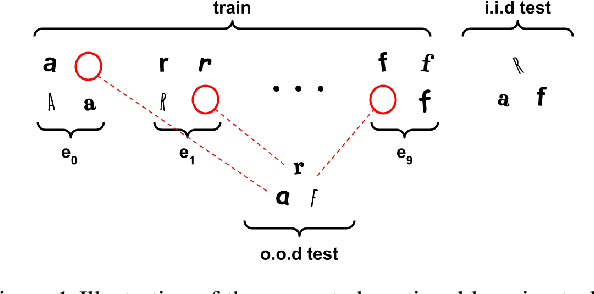
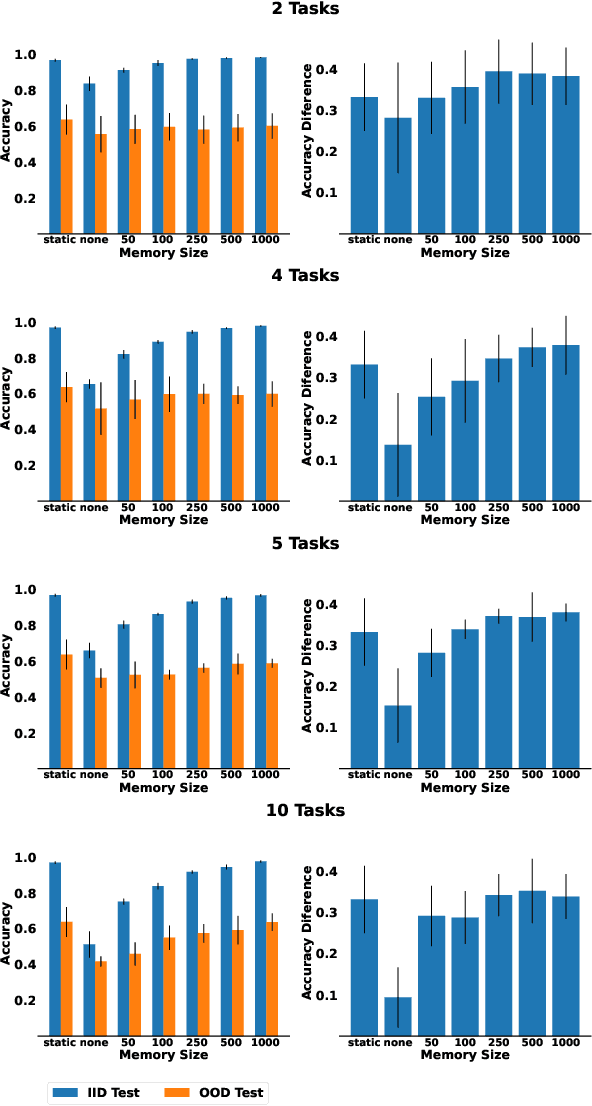
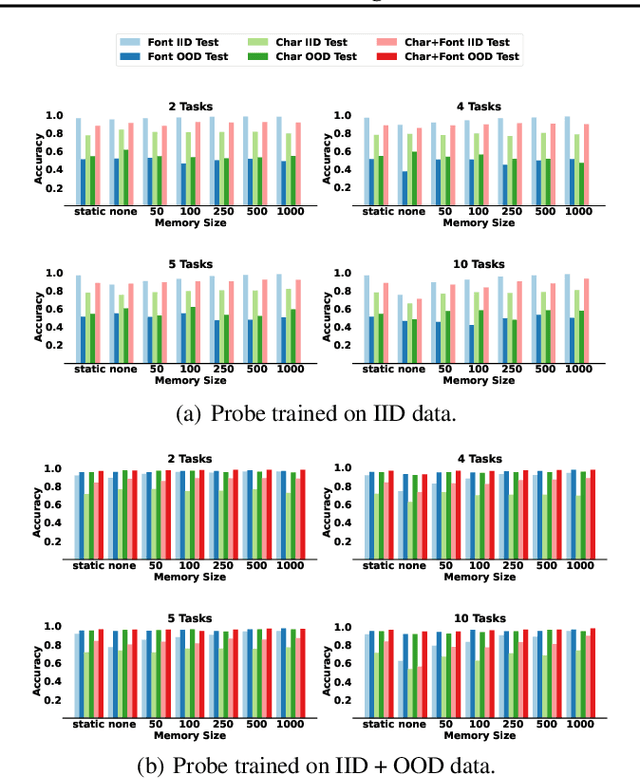
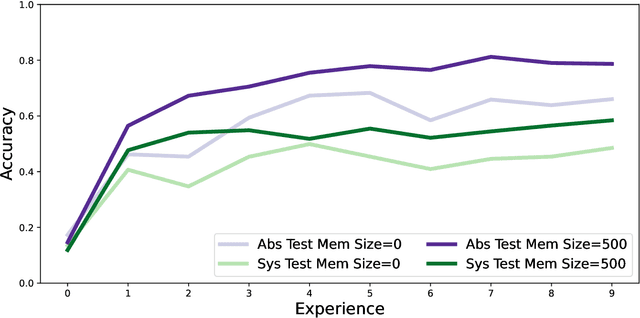
One of the objectives of Continual Learning is to learn new concepts continually over a stream of experiences and at the same time avoid catastrophic forgetting. To mitigate complete knowledge overwriting, memory-based methods store a percentage of previous data distributions to be used during training. Although these methods produce good results, few studies have tested their out-of-distribution generalization properties, as well as whether these methods overfit the replay memory. In this work, we show that although these methods can help in traditional in-distribution generalization, they can strongly impair out-of-distribution generalization by learning spurious features and correlations. Using a controlled environment, the Synbol benchmark generator (Lacoste et al., 2020), we demonstrate that this lack of out-of-distribution generalization mainly occurs in the linear classifier.