 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Latent SDEs on Homogeneous Spaces
Jun 28, 2023
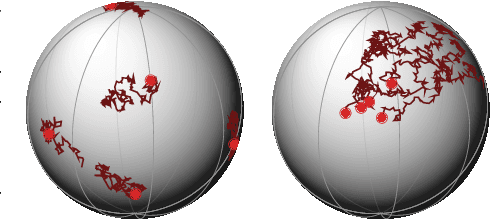
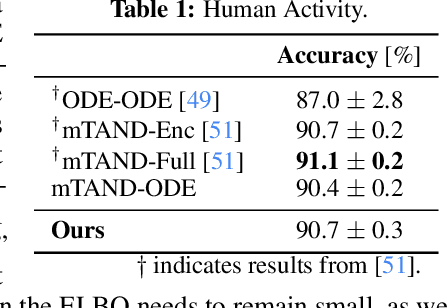
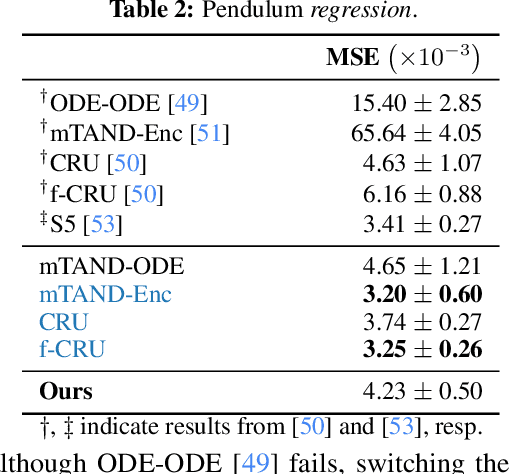
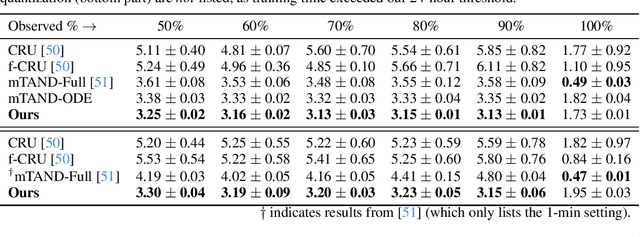
We consider the problem of variational Bayesian inference in a latent variable model where a (possibly complex) observed stochastic process is governed by the solution of a latent stochastic differential equation (SDE). Motivated by the challenges that arise when trying to learn an (almost arbitrary) latent neural SDE from large-scale data, such as efficient gradient computation, we take a step back and study a specific subclass instead. In our case, the SDE evolves on a homogeneous latent space and is induced by stochastic dynamics of the corresponding (matrix) Lie group. In learning problems, SDEs on the unit $n$-sphere are arguably the most relevant incarnation of this setup. Notably, for variational inference, the sphere not only facilitates using a truly uninformative prior SDE, but we also obtain a particularly simple and intuitive expression for the Kullback-Leibler divergence between the approximate posterior and prior process in the evidence lower bound. Experiments demonstrate that a latent SDE of the proposed type can be learned efficiently by means of an existing one-step geometric Euler-Maruyama scheme. Despite restricting ourselves to a less diverse class of SDEs, we achieve competitive or even state-of-the-art performance on various time series interpolation and classification benchmarks.
Diversity is Strength: Mastering Football Full Game with Interactive Reinforcement Learning of Multiple AIs
Jun 28, 2023

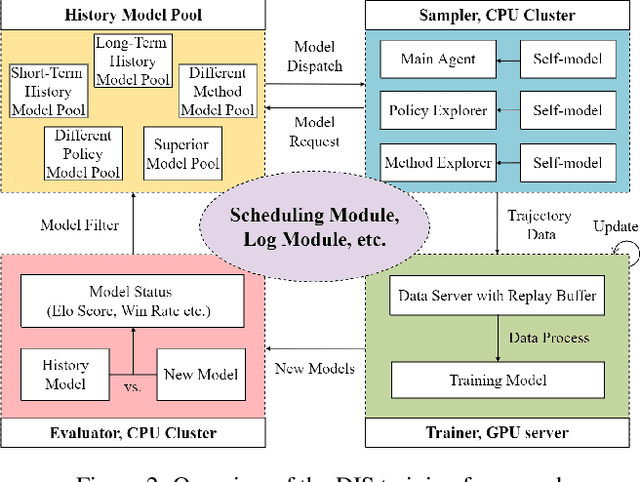
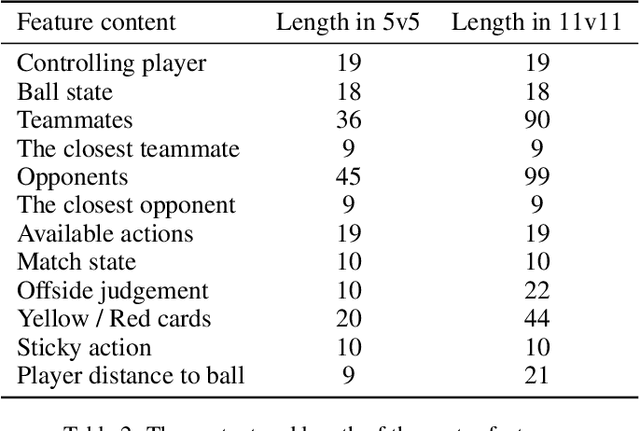
Training AI with strong and rich strategies in multi-agent environments remains an important research topic in Deep Reinforcement Learning (DRL). The AI's strength is closely related to its diversity of strategies, and this relationship can guide us to train AI with both strong and rich strategies. To prove this point, we propose Diversity is Strength (DIS), a novel DRL training framework that can simultaneously train multiple kinds of AIs. These AIs are linked through an interconnected history model pool structure, which enhances their capabilities and strategy diversities. We also design a model evaluation and screening scheme to select the best models to enrich the model pool and obtain the final AI. The proposed training method provides diverse, generalizable, and strong AI strategies without using human data. We tested our method in an AI competition based on Google Research Football (GRF) and won the 5v5 and 11v11 tracks. The method enables a GRF AI to have a high level on both 5v5 and 11v11 tracks for the first time, which are under complex multi-agent environments. The behavior analysis shows that the trained AI has rich strategies, and the ablation experiments proved that the designed modules benefit the training process.
ICSVR: Investigating Compositional and Semantic Understanding in Video Retrieval Models
Jun 28, 2023
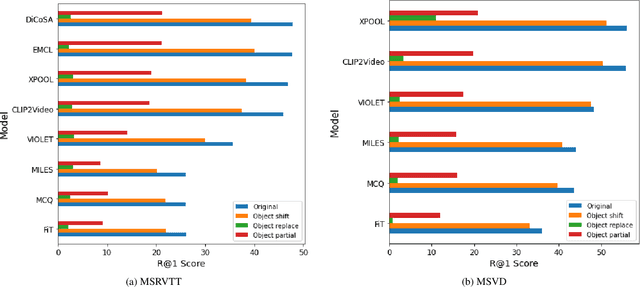
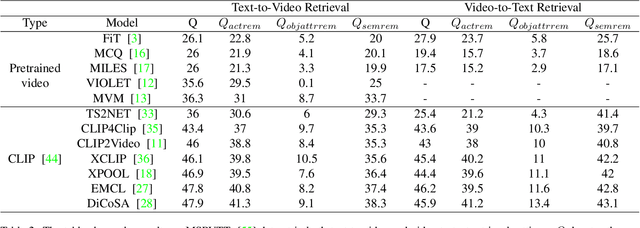
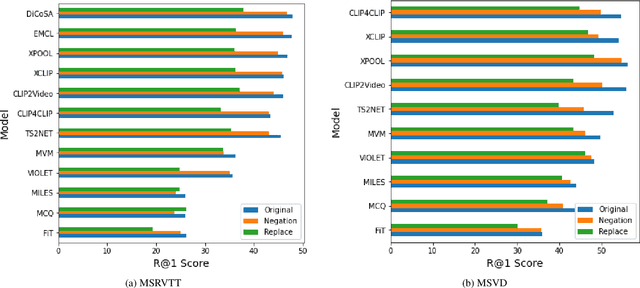
Video retrieval (VR) involves retrieving the ground truth video from the video database given a text caption or vice-versa. The two important components of compositionality: objects \& attributes and actions are joined using correct semantics to form a proper text query. These components (objects \& attributes, actions and semantics) each play an important role to help distinguish among videos and retrieve the correct ground truth video. However, it is unclear what is the effect of these components on the video retrieval performance. We therefore, conduct a systematic study to evaluate the compositional and semantic understanding of video retrieval models on standard benchmarks such as MSRVTT, MSVD and DIDEMO. The study is performed on two categories of video retrieval models: (i) which are pre-trained on video-text pairs and fine-tuned on downstream video retrieval datasets (Eg. Frozen-in-Time, Violet, MCQ etc.) (ii) which adapt pre-trained image-text representations like CLIP for video retrieval (Eg. CLIP4Clip, XCLIP, CLIP2Video etc.). Our experiments reveal that actions and semantics play a minor role compared to objects \& attributes in video understanding. Moreover, video retrieval models that use pre-trained image-text representations (CLIP) have better semantic and compositional understanding as compared to models pre-trained on video-text data.
CLANet: A Comprehensive Framework for Cross-Batch Cell Line Identification Using Brightfield Images
Jun 28, 2023

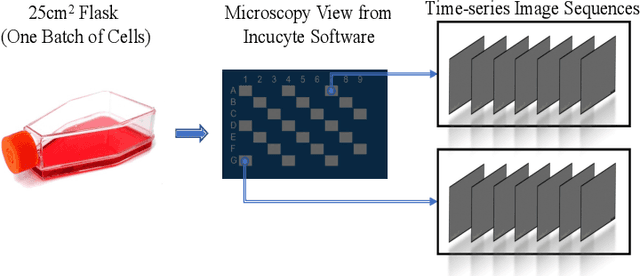

Cell line authentication plays a crucial role in the biomedical field, ensuring researchers work with accurately identified cells. Supervised deep learning has made remarkable strides in cell line identification by studying cell morphological features through cell imaging. However, batch effects, a significant issue stemming from the different times at which data is generated, lead to substantial shifts in the underlying data distribution, thus complicating reliable differentiation between cell lines from distinct batch cultures. To address this challenge, we introduce CLANet, a pioneering framework for cross-batch cell line identification using brightfield images, specifically designed to tackle three distinct batch effects. We propose a cell cluster-level selection method to efficiently capture cell density variations, and a self-supervised learning strategy to manage image quality variations, thus producing reliable patch representations. Additionally, we adopt multiple instance learning(MIL) for effective aggregation of instance-level features for cell line identification. Our innovative time-series segment sampling module further enhances MIL's feature-learning capabilities, mitigating biases from varying incubation times across batches. We validate CLANet using data from 32 cell lines across 93 experimental batches from the AstraZeneca Global Cell Bank. Our results show that CLANet outperforms related approaches (e.g. domain adaptation, MIL), demonstrating its effectiveness in addressing batch effects in cell line identification.
Fine-grained 3D object recognition: an approach and experiments
Jun 28, 2023Three-dimensional (3D) object recognition technology is being used as a core technology in advanced technologies such as autonomous driving of automobiles. There are two sets of approaches for 3D object recognition: (i) hand-crafted approaches like Global Orthographic Object Descriptor (GOOD), and (ii) deep learning-based approaches such as MobileNet and VGG. However, it is needed to know which of these approaches works better in an open-ended domain where the number of known categories increases over time, and the system should learn about new object categories using few training examples. In this paper, we first implemented an offline 3D object recognition system that takes an object view as input and generates category labels as output. In the offline stage, instance-based learning (IBL) is used to form a new category and we use K-fold cross-validation to evaluate the obtained object recognition performance. We then test the proposed approach in an online fashion by integrating the code into a simulated teacher test. As a result, we concluded that the approach using deep learning features is more suitable for open-ended fashion. Moreover, we observed that concatenating the hand-crafted and deep learning features increases the classification accuracy.
Multi-View Frequency-Attention Alternative to CNN Frontends for Automatic Speech Recognition
Jun 12, 2023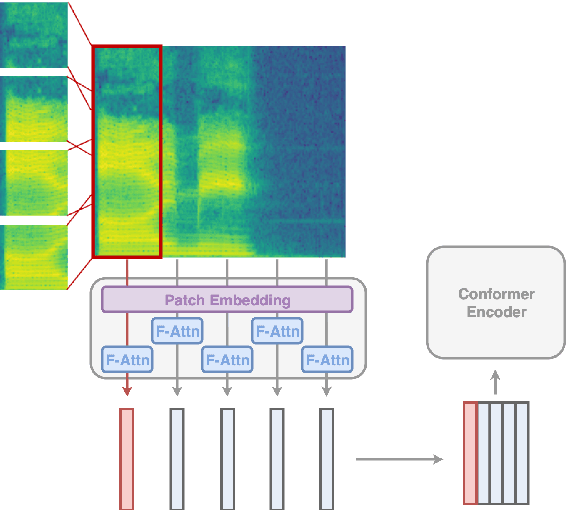
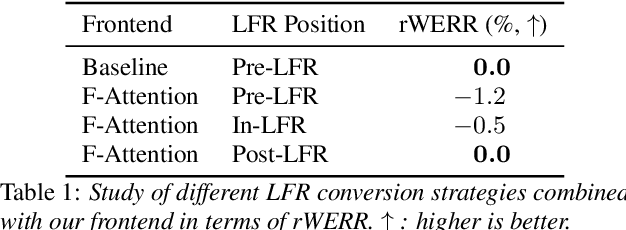
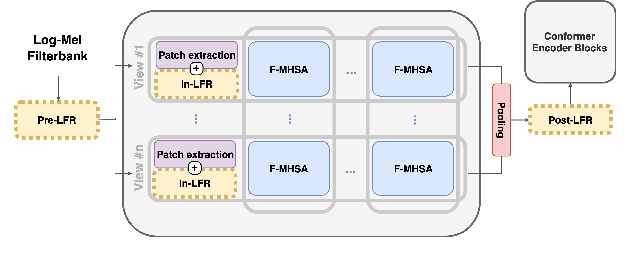
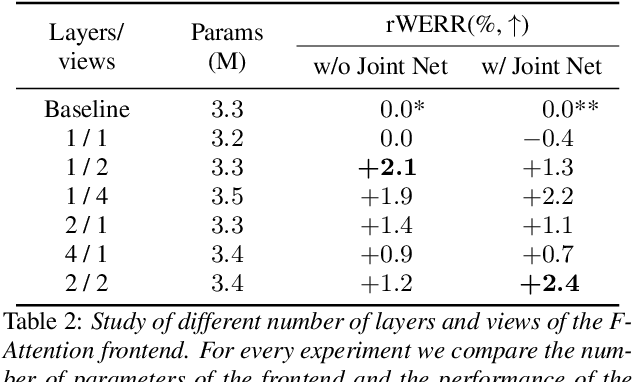
Convolutional frontends are a typical choice for Transformer-based automatic speech recognition to preprocess the spectrogram, reduce its sequence length, and combine local information in time and frequency similarly. However, the width and height of an audio spectrogram denote different information, e.g., due to reverberation as well as the articulatory system, the time axis has a clear left-to-right dependency. On the contrary, vowels and consonants demonstrate very different patterns and occupy almost disjoint frequency ranges. Therefore, we hypothesize, global attention over frequencies is beneficial over local convolution. We obtain 2.4 % relative word error rate reduction (rWERR) on a production scale Conformer transducer replacing its convolutional neural network frontend by the proposed F-Attention module on Alexa traffic. To demonstrate generalizability, we validate this on public LibriSpeech data with a long short term memory-based listen attend and spell architecture obtaining 4.6 % rWERR and demonstrate robustness to (simulated) noisy conditions.
Occlusion-aware Risk Assessment and Driving Strategy for Autonomous Vehicles Using Simplified Reachability Quantification
Jun 12, 2023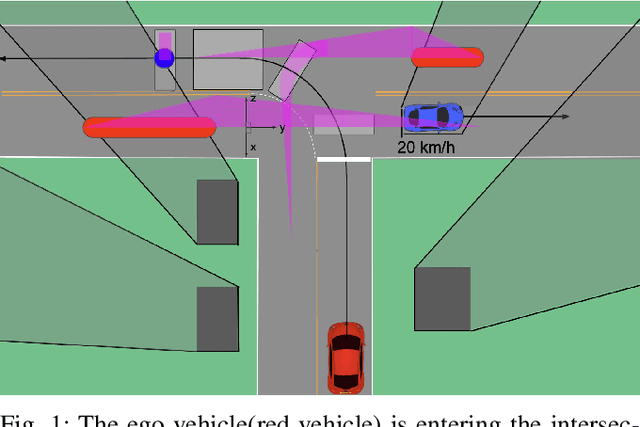
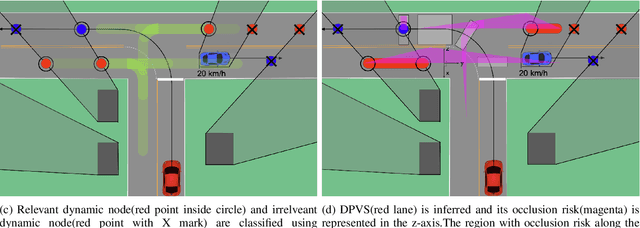
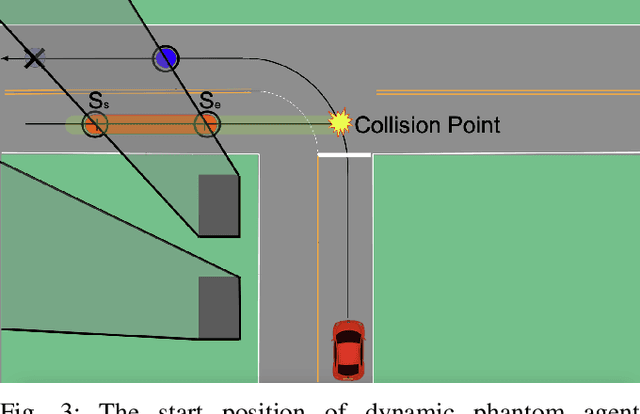
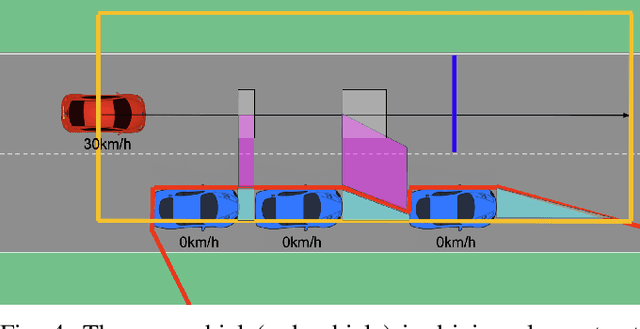
There are several unresolved challenges for autonomous vehicles. One of them is safely navigating among occluded pedestrians and vehicles. Much of the previous work tried to solve this problem by generating phantom cars and assessing their risk. In this paper, motivated by the previous works, we propose an algorithm that efficiently assesses risks of phantom pedestrians/vehicles using Simplified Reachability Quantification. We utilized this occlusion risk to set a speed limit at the risky position when planning the velocity profile of an autonomous vehicle. This allows an autonomous vehicle to safely and efficiently drive in occluded areas. The proposed algorithm was evaluated in various scenarios in the CARLA simulator and it reduced the average collision rate by 6.14X, the discomfort score by 5.03X, while traversal time was increased by 1.48X compared to baseline 1, and computation time was reduced by 20.15X compared to baseline 2.
MobileASR: A resource-aware on-device personalisation framework for automatic speech recognition in mobile phones
Jun 15, 2023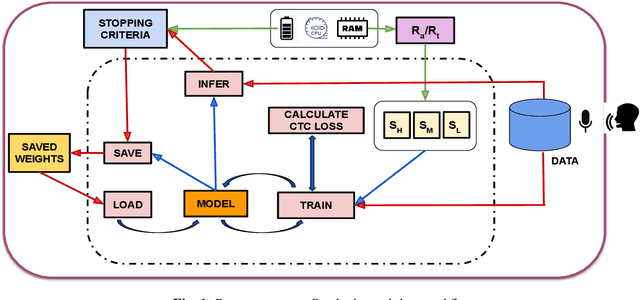
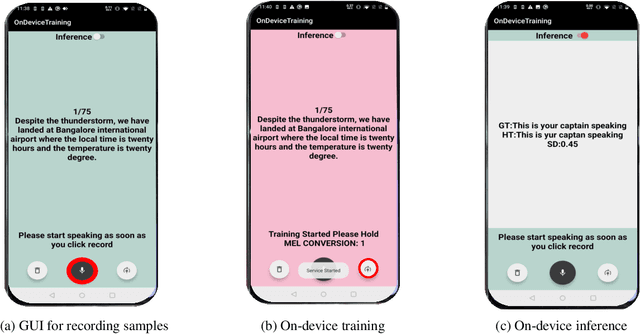
We describe a comprehensive methodology for developing user-voice personalised ASR models by effectively training models on mobile phones, allowing user data and models to be stored and used locally. To achieve this, we propose a resource-aware sub-model based training approach that considers the RAM, and battery capabilities of mobile phones. We also investigate the relationship between available resources and training time, highlighting the effectiveness of using sub-models in such scenarios. By taking into account the evaluation metric and battery constraints of the mobile phones, we are able to perform efficient training and halt the process accordingly. To simulate real users, we use speakers with various accents. The entire on-device training and evaluation framework was then tested on various mobile phones across brands. We show that fine-tuning the models and selecting the right hyperparameter values is a trade-off between the lowest achievable performance metric, on-device training time, and memory consumption. Overall, our methodology offers a comprehensive solution for developing personalized ASR models while leveraging the capabilities of mobile phones, and balancing the need for accuracy with resource constraints.
Computing large deviation prefactors of stochastic dynamical systems based on machine learning
Jun 20, 2023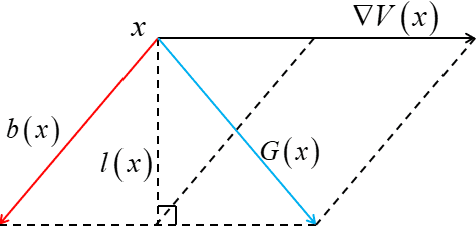

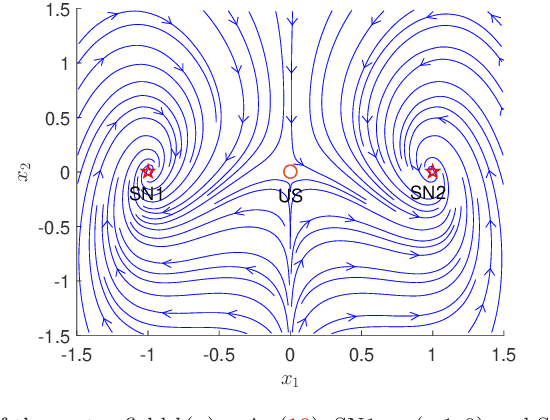
In this paper, we present large deviation theory that characterizes the exponential estimate for rare events of stochastic dynamical systems in the limit of weak noise. We aim to consider next-to-leading-order approximation for more accurate calculation of mean exit time via computing large deviation prefactors with the research efforts of machine learning. More specifically, we design a neural network framework to compute quasipotential, most probable paths and prefactors based on the orthogonal decomposition of vector field. We corroborate the higher effectiveness and accuracy of our algorithm with a practical example. Numerical experiments demonstrate its powerful function in exploring internal mechanism of rare events triggered by weak random fluctuations.
Low Latency Edge Classification GNN for Particle Trajectory Tracking on FPGAs
Jun 20, 2023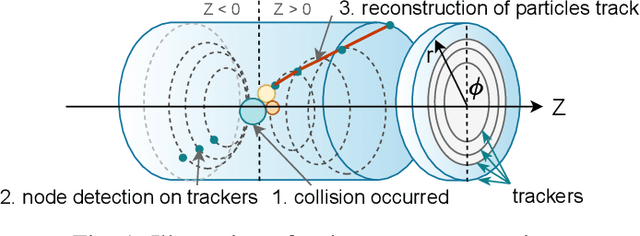
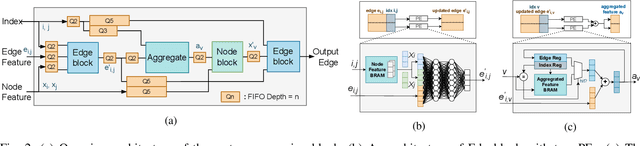
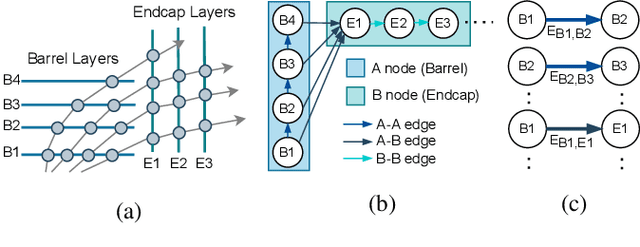
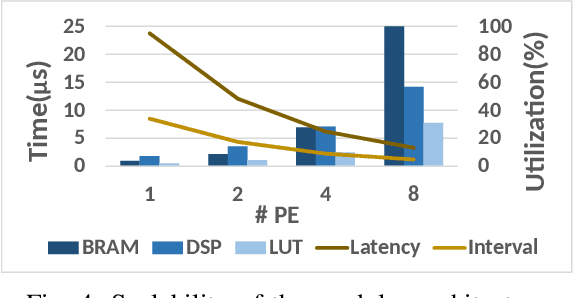
In-time particle trajectory reconstruction in the Large Hadron Collider is challenging due to the high collision rate and numerous particle hits. Using GNN (Graph Neural Network) on FPGA has enabled superior accuracy with flexible trajectory classification. However, existing GNN architectures have inefficient resource usage and insufficient parallelism for edge classification. This paper introduces a resource-efficient GNN architecture on FPGAs for low latency particle tracking. The modular architecture facilitates design scalability to support large graphs. Leveraging the geometric properties of hit detectors further reduces graph complexity and resource usage. Our results on Xilinx UltraScale+ VU9P demonstrate 1625x and 1574x performance improvement over CPU and GPU respectively.