 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Data-Driven Nonlinear TDOA for Accurate Source Localization in Complex Signal Dynamics
Aug 03, 2023
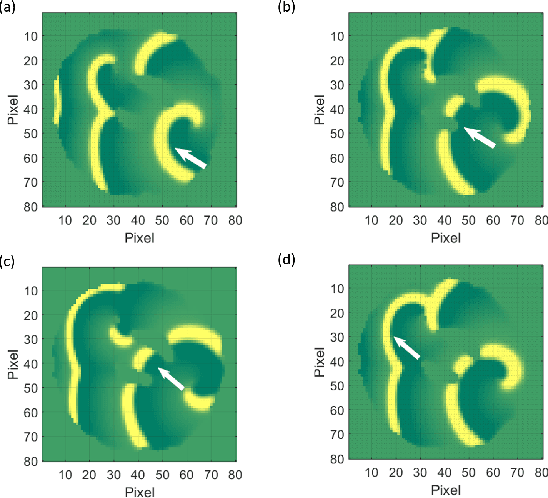
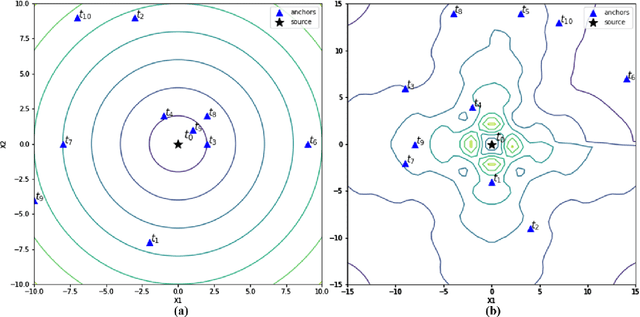
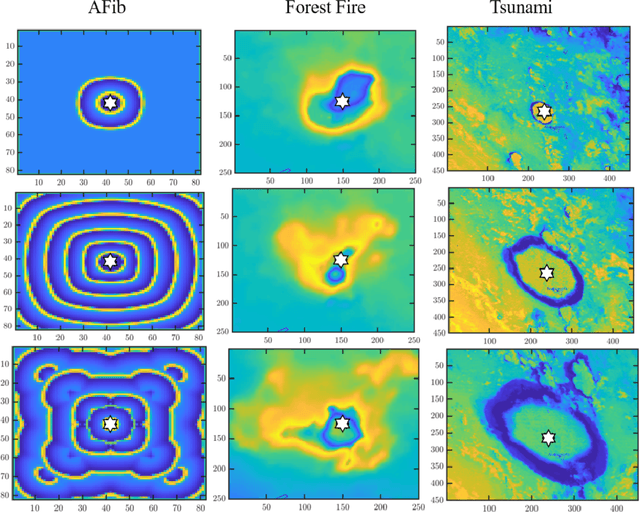
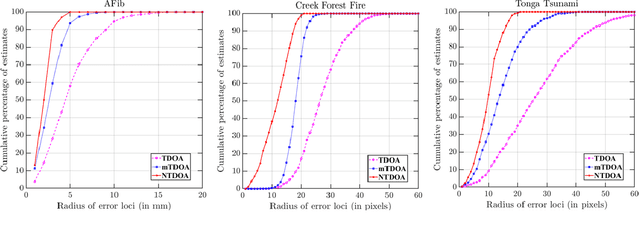
The complex and dynamic propagation of oscillations and waves is often triggered by sources at unknown locations. Accurate source localization enables the elimination of the rotor core in atrial fibrillation (AFib) as an effective treatment for such severe cardiac disorder; it also finds potential use in locating the spreading source in natural disasters such as forest fires and tsunamis. However, existing approaches such as time of arrival (TOA) and time difference of arrival (TDOA) do not yield accurate localization results since they tacitly assume a constant signal propagation speed whereas realistic propagation is often non-static and heterogeneous. In this paper, we develop a nonlinear TDOA (NTDOA) approach which utilizes observational data from various positions to jointly learn the propagation speed at different angles and distances as well as the location of the source itself. Through examples of simulating the complex dynamics of electrical signals along the surface of the heart and satellite imagery from forest fires and tsunamis, we show that with a small handful of measurements, NTDOA, as a data-driven approach, can successfully locate the spreading source, leading also to better forecasting of the speed and direction of subsequent propagation.
Signal Reconstruction from Mel-spectrogram Based on Bi-level Consistency of Full-band Magnitude and Phase
Jul 23, 2023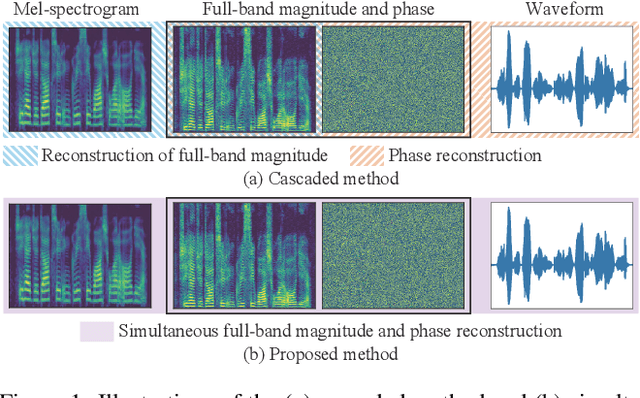
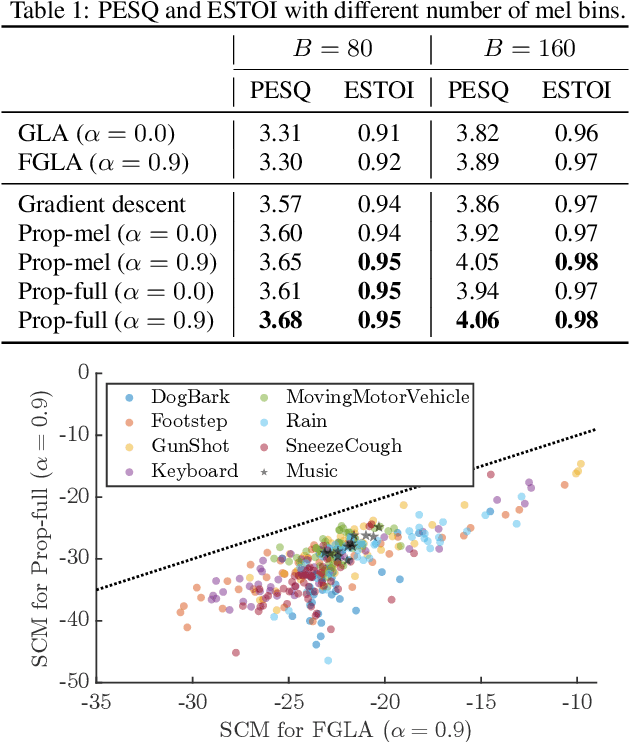
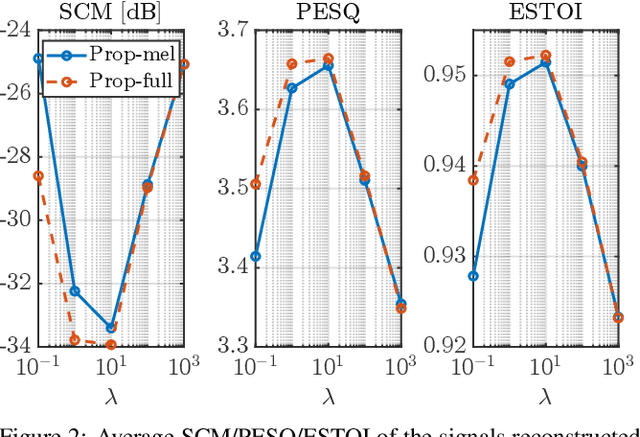
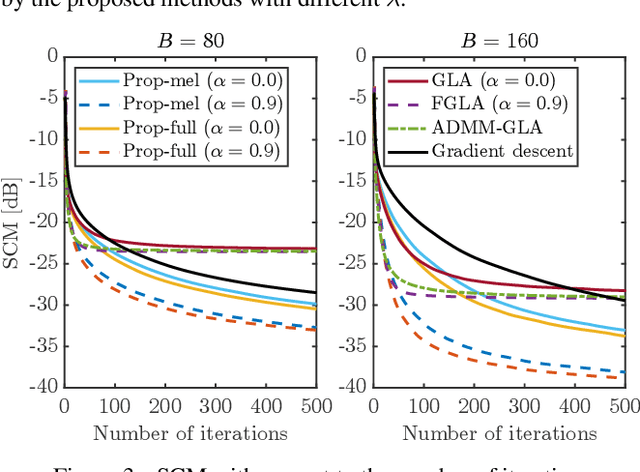
We propose an optimization-based method for reconstructing a time-domain signal from a low-dimensional spectral representation such as a mel-spectrogram. Phase reconstruction has been studied to reconstruct a time-domain signal from the full-band short-time Fourier transform (STFT) magnitude. The Griffin-Lim algorithm (GLA) has been widely used because it relies only on the redundancy of STFT and is applicable to various audio signals. In this paper, we jointly reconstruct the full-band magnitude and phase by considering the bi-level relationships among the time-domain signal, its STFT coefficients, and its mel-spectrogram. The proposed method is formulated as a rigorous optimization problem and estimates the full-band magnitude based on the criterion used in GLA. Our experiments demonstrate the effectiveness of the proposed method on speech, music, and environmental signals.
The Regular Expression Inference Challenge
Aug 15, 2023
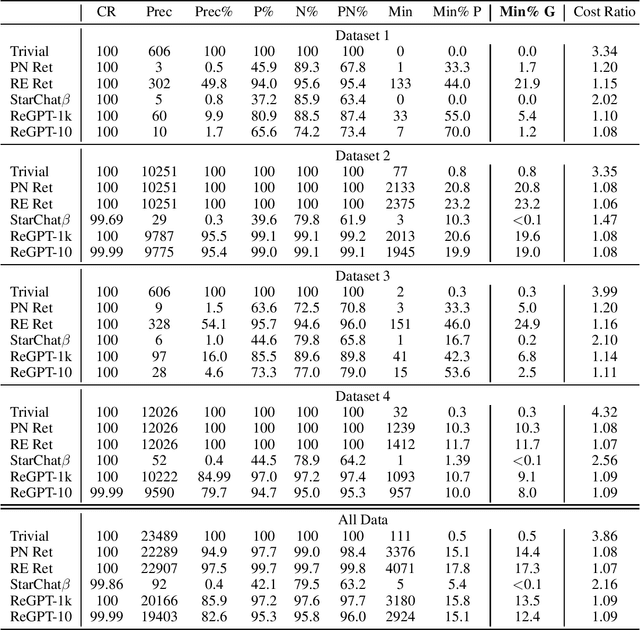


We propose \emph{regular expression inference (REI)} as a challenge for code/language modelling, and the wider machine learning community. REI is a supervised machine learning (ML) and program synthesis task, and poses the problem of finding minimal regular expressions from examples: Given two finite sets of strings $P$ and $N$ and a cost function $\text{cost}(\cdot)$, the task is to generate an expression $r$ that accepts all strings in $P$ and rejects all strings in $N$, while no other such expression $r'$ exists with $\text{cost}(r')<\text{cost}(r)$. REI has advantages as a challenge problem: (i) regular expressions are well-known, widely used, and a natural idealisation of code; (ii) REI's asymptotic worst-case complexity is well understood; (iii) REI has a small number of easy to understand parameters (e.g.~$P$ or $N$ cardinality, string lengths of examples, or the cost function); this lets us easily finetune REI-hardness; (iv) REI is an unsolved problem for deep learning based ML. Recently, an REI solver was implemented on GPUs, using program synthesis techniques. This enabled, for the first time, fast generation of minimal expressions for complex REI instances. Building on this advance, we generate and publish the first large-scale datasets for REI, and devise and evaluate several initial heuristic and machine learning baselines. We invite the community to participate and explore ML methods that learn to solve REI problems. We believe that progress in REI directly translates to code/language modelling.
Eco-Friendly Sensing for Human Activity Recognition
Aug 10, 2023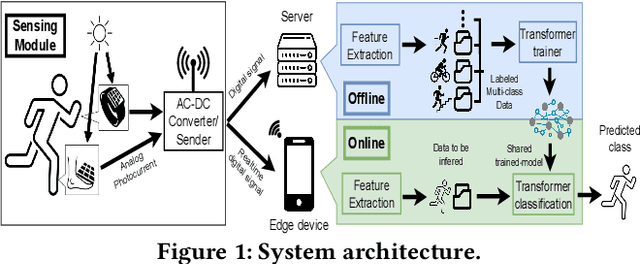
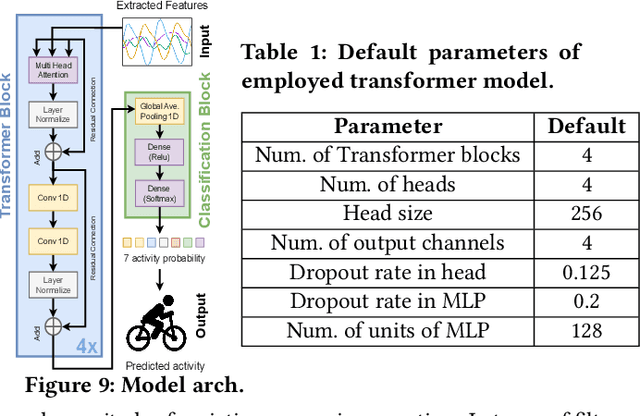
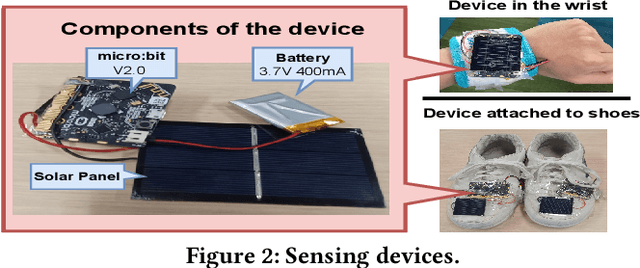
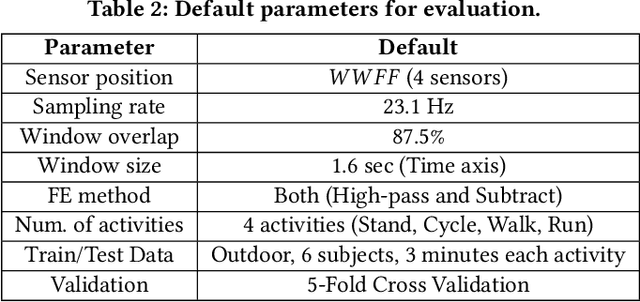
With the increasing number of IoT devices, there is a growing demand for energy-free sensors. Human activity recognition holds immense value in numerous daily healthcare applications. However, the majority of current sensing modalities consume energy, thus limiting their sustainable adoption. In this paper, we present a novel activity recognition system that not only operates without requiring energy for sensing but also harvests energy. Our proposed system utilizes photovoltaic cells, attached to the wrist and shoes, as eco-friendly sensing devices for activity recognition. By capturing photovoltaic readings and employing a deep transformer model with powerful learning capabilities, the system effectively recognizes user activities. To ensure robust performance across various subjects, time periods, and lighting conditions, the system incorporates feature extraction and different processing modules. The evaluation of the proposed system on realistic indoor and outdoor environments demonstrated its ability to recognize activities with an accuracy of 91.7%.
Using Twitter Data to Determine Hurricane Category: An Experiment
Aug 10, 2023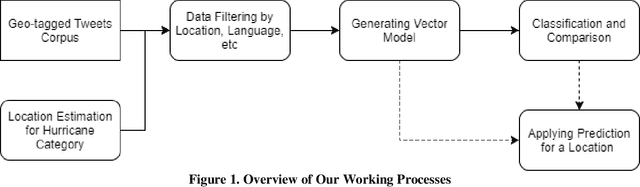
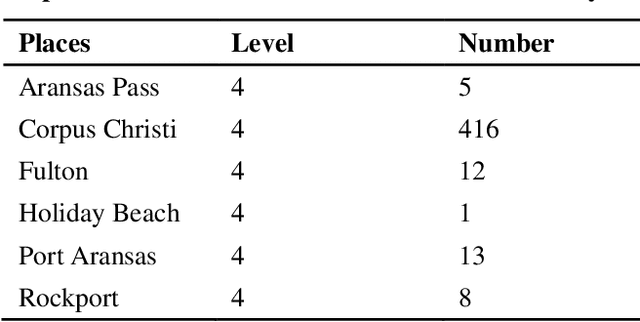
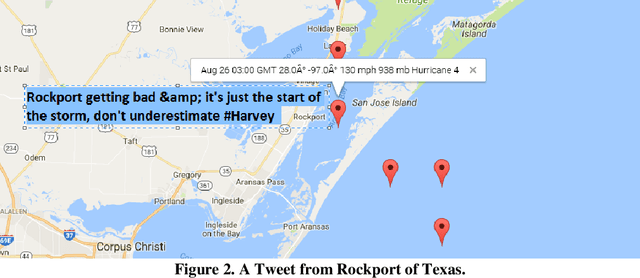

Social media posts contain an abundant amount of information about public opinion on major events, especially natural disasters such as hurricanes. Posts related to an event, are usually published by the users who live near the place of the event at the time of the event. Special correlation between the social media data and the events can be obtained using data mining approaches. This paper presents research work to find the mappings between social media data and the severity level of a disaster. Specifically, we have investigated the Twitter data posted during hurricanes Harvey and Irma, and attempted to find the correlation between the Twitter data of a specific area and the hurricane level in that area. Our experimental results indicate a positive correlation between them. We also present a method to predict the hurricane category for a specific area using relevant Twitter data.
Improving Probabilistic Bisimulation for MDPs Using Machine Learning
Jul 30, 2023


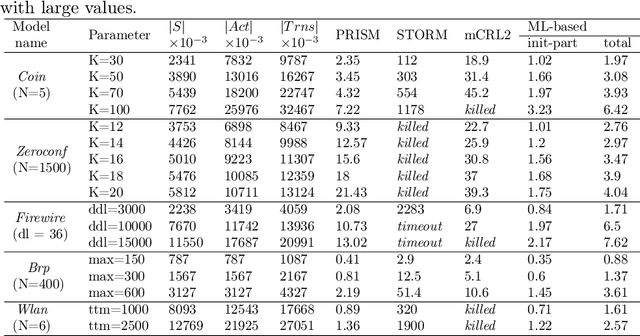
The utilization of model checking has been suggested as a formal verification technique for analyzing critical systems. However, the primary challenge in applying to complex systems is state space explosion problem. To address this issue, bisimulation minimization has emerged as a prominent method for reducing the number of states in a labeled transition system, aiming to overcome the difficulties associated with the state space explosion problem. In the case of systems exhibiting stochastic behaviors, probabilistic bisimulation is employed to minimize a given model, obtaining its equivalent form with fewer states. Recently, various techniques have been introduced to decrease the time complexity of the iterative methods used to compute probabilistic bisimulation for stochastic systems that display nondeterministic behaviors. In this paper, we propose a new technique to partition the state space of a given probabilistic model to its bisimulation classes. This technique uses the PRISM program of a given model and constructs some small versions of the model to train a classifier. It then applies machine learning classification techniques to approximate the related partition. The resulting partition is used as an initial one for the standard bisimulation technique in order to reduce the running time of the method. The experimental results show that the approach can decrease significantly the running time compared to state-of-the-art tools.
IVP-VAE: Modeling EHR Time Series with Initial Value Problem Solvers
May 11, 2023
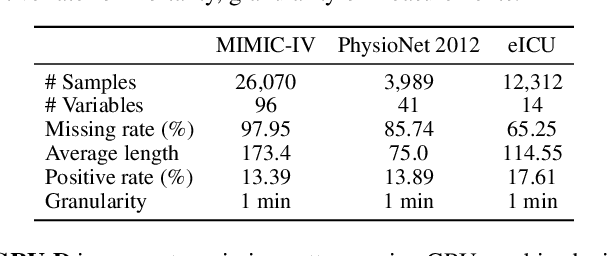
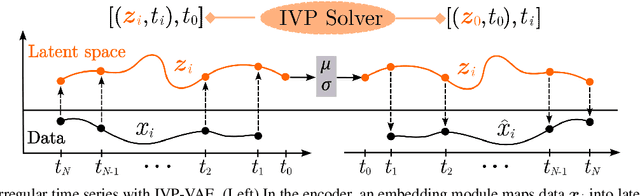
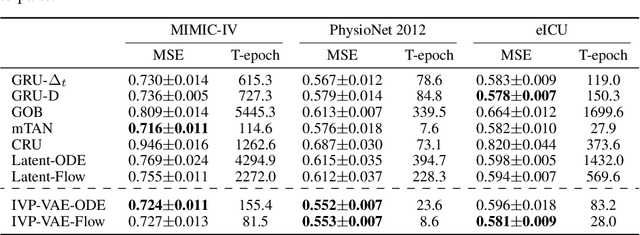
Continuous-time models such as Neural ODEs and Neural Flows have shown promising results in analyzing irregularly sampled time series frequently encountered in electronic health records. Based on these models, time series are typically processed with a hybrid of an initial value problem (IVP) solver and a recurrent neural network within the variational autoencoder architecture. Sequentially solving IVPs makes such models computationally less efficient. In this paper, we propose to model time series purely with continuous processes whose state evolution can be approximated directly by IVPs. This eliminates the need for recurrent computation and enables multiple states to evolve in parallel. We further fuse the encoder and decoder with one IVP solver based on its invertibility, which leads to fewer parameters and faster convergence. Experiments on three real-world datasets show that the proposed approach achieves comparable extrapolation and classification performance while gaining more than one order of magnitude speedup over other continuous-time counterparts.
Unified Data-Free Compression: Pruning and Quantization without Fine-Tuning
Aug 14, 2023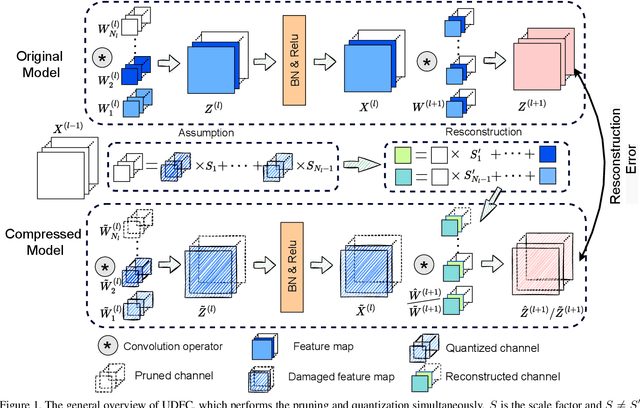
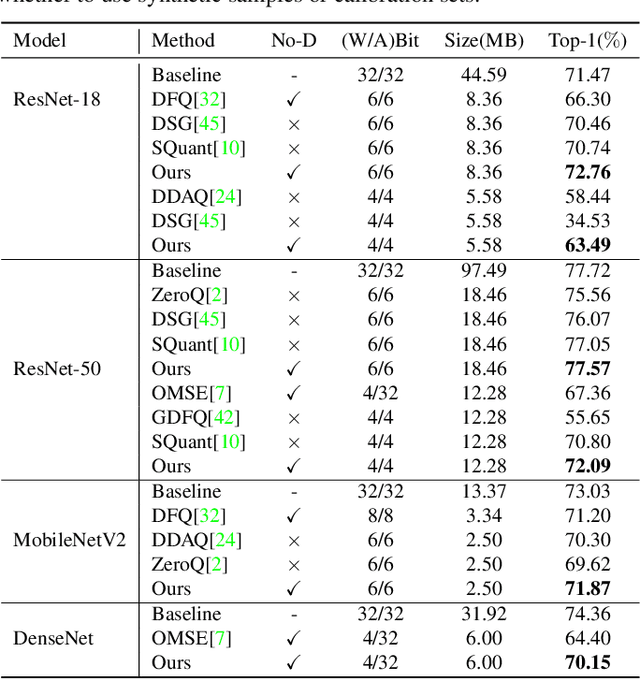
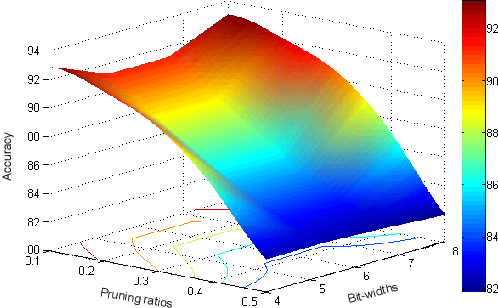
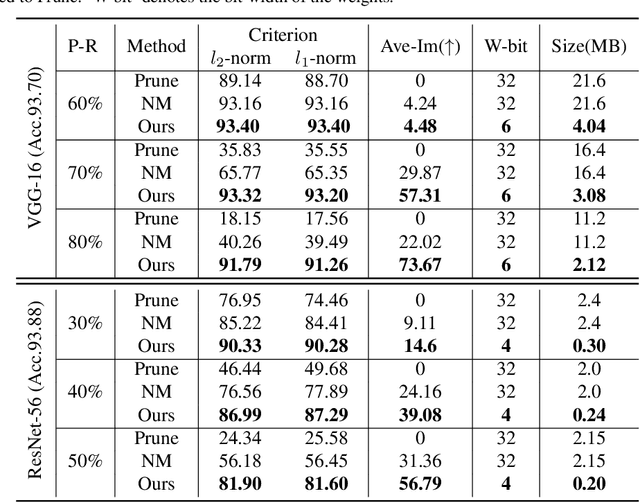
Structured pruning and quantization are promising approaches for reducing the inference time and memory footprint of neural networks. However, most existing methods require the original training dataset to fine-tune the model. This not only brings heavy resource consumption but also is not possible for applications with sensitive or proprietary data due to privacy and security concerns. Therefore, a few data-free methods are proposed to address this problem, but they perform data-free pruning and quantization separately, which does not explore the complementarity of pruning and quantization. In this paper, we propose a novel framework named Unified Data-Free Compression(UDFC), which performs pruning and quantization simultaneously without any data and fine-tuning process. Specifically, UDFC starts with the assumption that the partial information of a damaged(e.g., pruned or quantized) channel can be preserved by a linear combination of other channels, and then derives the reconstruction form from the assumption to restore the information loss due to compression. Finally, we formulate the reconstruction error between the original network and its compressed network, and theoretically deduce the closed-form solution. We evaluate the UDFC on the large-scale image classification task and obtain significant improvements over various network architectures and compression methods. For example, we achieve a 20.54% accuracy improvement on ImageNet dataset compared to SOTA method with 30% pruning ratio and 6-bit quantization on ResNet-34.
Adversarial Sleeping Bandit Problems with Multiple Plays: Algorithm and Ranking Application
Jul 27, 2023This paper presents an efficient algorithm to solve the sleeping bandit with multiple plays problem in the context of an online recommendation system. The problem involves bounded, adversarial loss and unknown i.i.d. distributions for arm availability. The proposed algorithm extends the sleeping bandit algorithm for single arm selection and is guaranteed to achieve theoretical performance with regret upper bounded by $\bigO(kN^2\sqrt{T\log T})$, where $k$ is the number of arms selected per time step, $N$ is the total number of arms, and $T$ is the time horizon.
SimpleMapping: Real-Time Visual-Inertial Dense Mapping with Deep Multi-View Stereo
Jun 14, 2023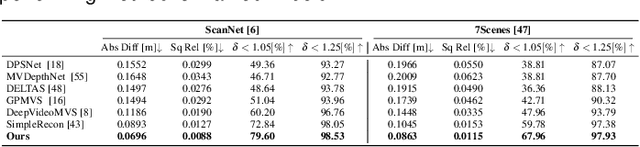
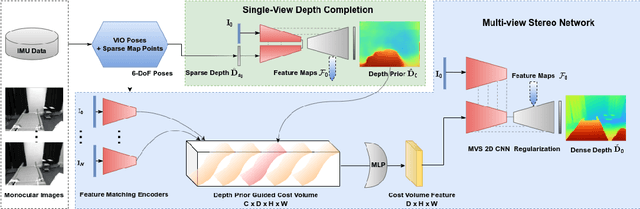
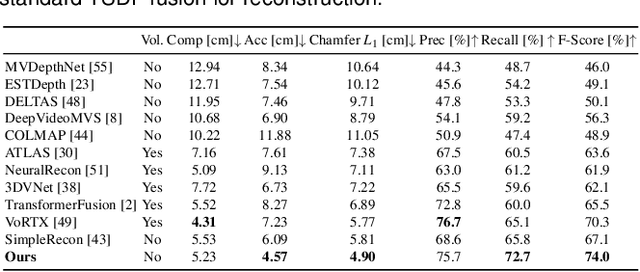
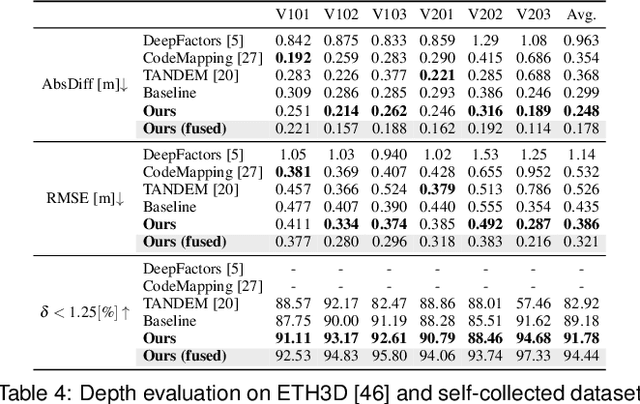
We present a real-time visual-inertial dense mapping method capable of performing incremental 3D mesh reconstruction with high quality using only sequential monocular images and inertial measurement unit (IMU) readings. 6-DoF camera poses are estimated by a robust feature-based visual-inertial odometry (VIO), which also generates noisy sparse 3D map points as a by-product. We propose a sparse point aided multi-view stereo neural network (SPA-MVSNet) that can effectively leverage the informative but noisy sparse points from the VIO system. The sparse depth from VIO is firstly completed by a single-view depth completion network. This dense depth map, although naturally limited in accuracy, is then used as a prior to guide our MVS network in the cost volume generation and regularization for accurate dense depth prediction. Predicted depth maps of keyframe images by the MVS network are incrementally fused into a global map using TSDF-Fusion. We extensively evaluate both the proposed SPA-MVSNet and the entire visual-inertial dense mapping system on several public datasets as well as our own dataset, demonstrating the system's impressive generalization capabilities and its ability to deliver high-quality 3D mesh reconstruction online. Our proposed dense mapping system achieves a 39.7% improvement in F-score over existing systems when evaluated on the challenging scenarios of the EuRoC dataset. We plan to release the code of this work upon acceptance.