 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Physics Informed Recurrent Neural Networks for Seismic Response Evaluation of Nonlinear Systems
Aug 16, 2023
Dynamic response evaluation in structural engineering is the process of determining the response of a structure, such as member forces, node displacements, etc when subjected to dynamic loads such as earthquakes, wind, or impact. This is an important aspect of structural analysis, as it enables engineers to assess structural performance under extreme loading conditions and make informed decisions about the design and safety of the structure. Conventional methods for dynamic response evaluation involve numerical simulations using finite element analysis (FEA), where the structure is modeled using finite elements, and the equations of motion are solved numerically. Although effective, this approach can be computationally intensive and may not be suitable for real-time applications. To address these limitations, recent advancements in machine learning, specifically artificial neural networks, have been applied to dynamic response evaluation in structural engineering. These techniques leverage large data sets and sophisticated algorithms to learn the complex relationship between inputs and outputs, making them ideal for such problems. In this paper, a novel approach is proposed for evaluating the dynamic response of multi-degree-of-freedom (MDOF) systems using physics-informed recurrent neural networks. The focus of this paper is to evaluate the seismic (earthquake) response of nonlinear structures. The predicted response will be compared to state-of-the-art methods such as FEA to assess the efficacy of the physics-informed RNN model.
Challenges and Opportunities of Using Transformer-Based Multi-Task Learning in NLP Through ML Lifecycle: A Survey
Aug 16, 2023The increasing adoption of natural language processing (NLP) models across industries has led to practitioners' need for machine learning systems to handle these models efficiently, from training to serving them in production. However, training, deploying, and updating multiple models can be complex, costly, and time-consuming, mainly when using transformer-based pre-trained language models. Multi-Task Learning (MTL) has emerged as a promising approach to improve efficiency and performance through joint training, rather than training separate models. Motivated by this, we first provide an overview of transformer-based MTL approaches in NLP. Then, we discuss the challenges and opportunities of using MTL approaches throughout typical ML lifecycle phases, specifically focusing on the challenges related to data engineering, model development, deployment, and monitoring phases. This survey focuses on transformer-based MTL architectures and, to the best of our knowledge, is novel in that it systematically analyses how transformer-based MTL in NLP fits into ML lifecycle phases. Furthermore, we motivate research on the connection between MTL and continual learning (CL), as this area remains unexplored. We believe it would be practical to have a model that can handle both MTL and CL, as this would make it easier to periodically re-train the model, update it due to distribution shifts, and add new capabilities to meet real-world requirements.
Graph Relation Aware Continual Learning
Aug 16, 2023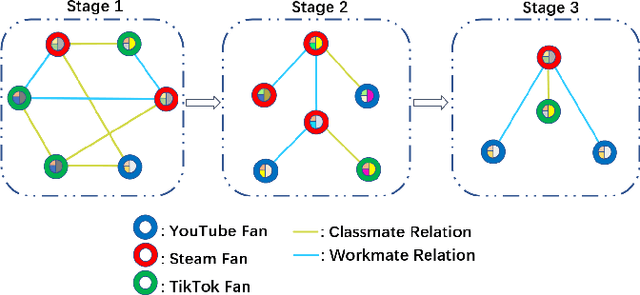
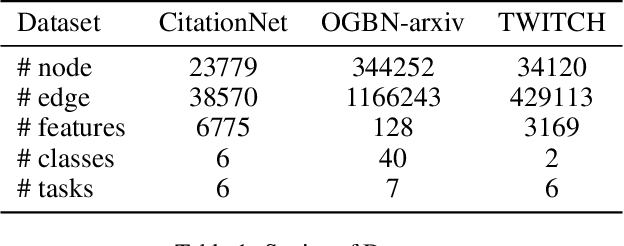
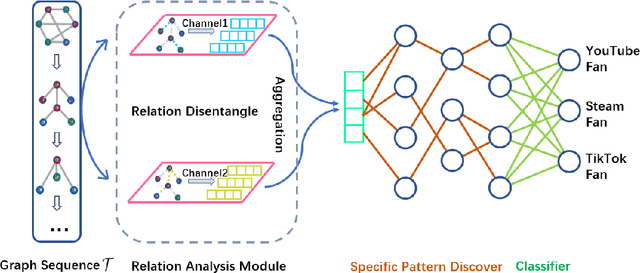
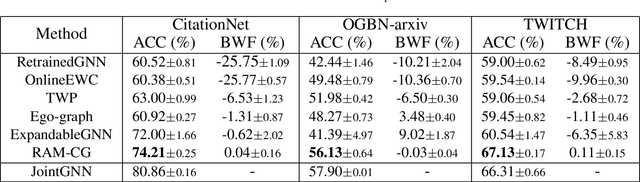
Continual graph learning (CGL) studies the problem of learning from an infinite stream of graph data, consolidating historical knowledge, and generalizing it to the future task. At once, only current graph data are available. Although some recent attempts have been made to handle this task, we still face two potential challenges: 1) most of existing works only manipulate on the intermediate graph embedding and ignore intrinsic properties of graphs. It is non-trivial to differentiate the transferred information across graphs. 2) recent attempts take a parameter-sharing policy to transfer knowledge across time steps or progressively expand new architecture given shifted graph distribution. Learning a single model could loss discriminative information for each graph task while the model expansion scheme suffers from high model complexity. In this paper, we point out that latent relations behind graph edges can be attributed as an invariant factor for the evolving graphs and the statistical information of latent relations evolves. Motivated by this, we design a relation-aware adaptive model, dubbed as RAM-CG, that consists of a relation-discovery modular to explore latent relations behind edges and a task-awareness masking classifier to accounts for the shifted. Extensive experiments show that RAM-CG provides significant 2.2%, 6.9% and 6.6% accuracy improvements over the state-of-the-art results on CitationNet, OGBN-arxiv and TWITCH dataset, respective.
Mlinear: Rethink the Linear Model for Time-series Forecasting
May 08, 2023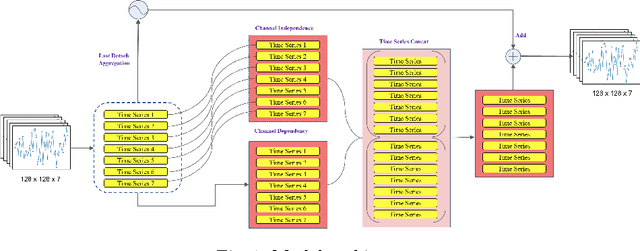
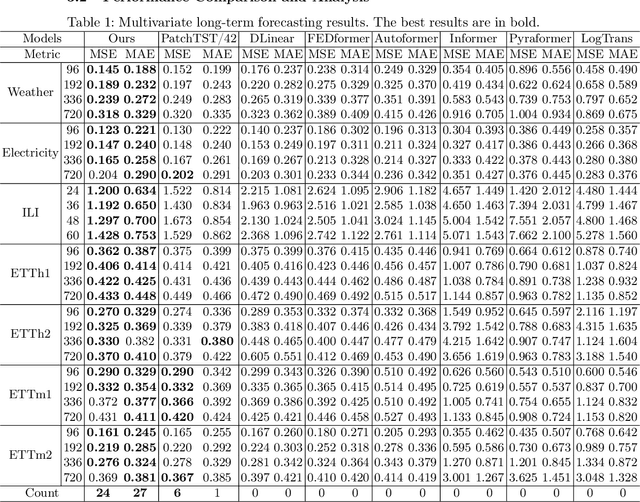
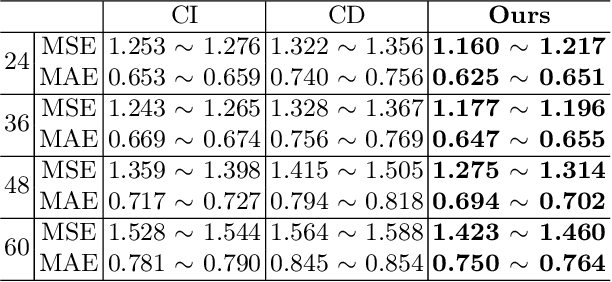
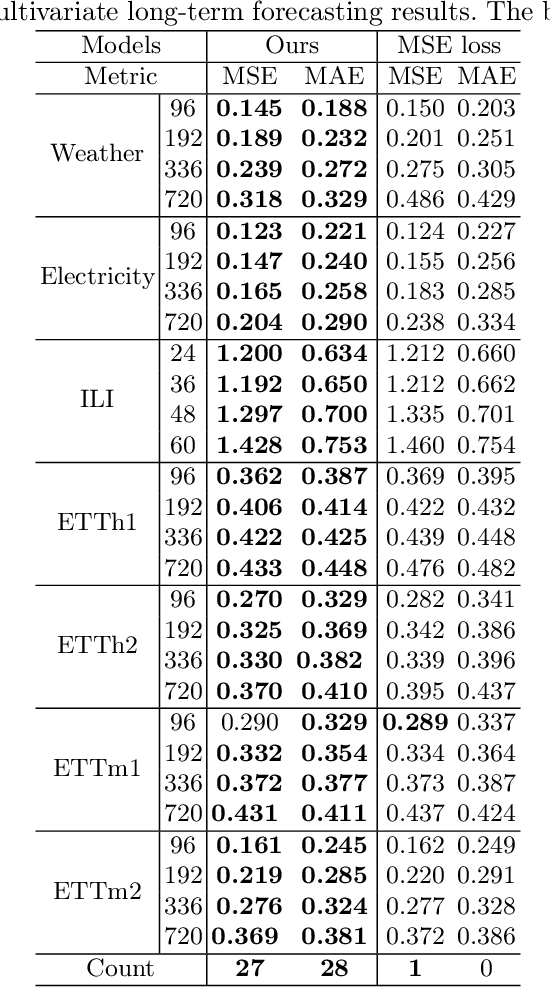
Recently, significant advancements have been made in time-series forecasting research, with an increasing focus on analyzing the inherent characteristics of time-series data, rather than solely focusing on designing forecasting models.In this paper, we follow this trend and carefully examine previous work to propose an efficient time series forecasting model based on linear models. The model consists of two important core components: (1) the integration of different semantics brought by single-channel and multi-channel data for joint forecasting; (2) the use of a novel loss function that replaces the traditional MSE loss and MAE loss to achieve higher forecasting accuracy.On widely-used benchmark time series datasets, our model not only outperforms the current SOTA, but is also 10 $\times$ speedup and has fewer parameters than the latest SOTA model.
Diffusion Variational Autoencoder for Tackling Stochasticity in Multi-Step Regression Stock Price Prediction
Aug 18, 2023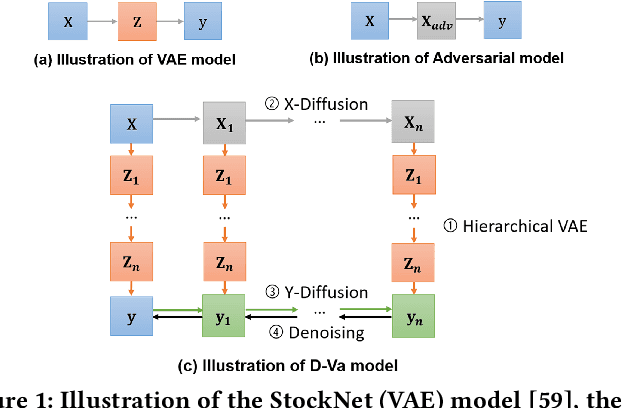
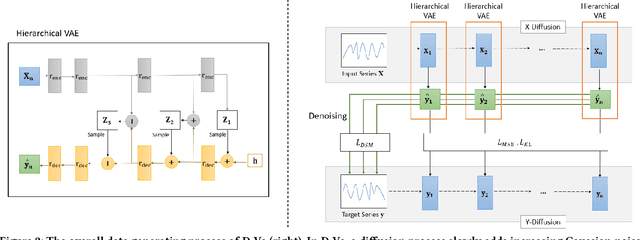

Multi-step stock price prediction over a long-term horizon is crucial for forecasting its volatility, allowing financial institutions to price and hedge derivatives, and banks to quantify the risk in their trading books. Additionally, most financial regulators also require a liquidity horizon of several days for institutional investors to exit their risky assets, in order to not materially affect market prices. However, the task of multi-step stock price prediction is challenging, given the highly stochastic nature of stock data. Current solutions to tackle this problem are mostly designed for single-step, classification-based predictions, and are limited to low representation expressiveness. The problem also gets progressively harder with the introduction of the target price sequence, which also contains stochastic noise and reduces generalizability at test-time. To tackle these issues, we combine a deep hierarchical variational-autoencoder (VAE) and diffusion probabilistic techniques to do seq2seq stock prediction through a stochastic generative process. The hierarchical VAE allows us to learn the complex and low-level latent variables for stock prediction, while the diffusion probabilistic model trains the predictor to handle stock price stochasticity by progressively adding random noise to the stock data. Our Diffusion-VAE (D-Va) model is shown to outperform state-of-the-art solutions in terms of its prediction accuracy and variance. More importantly, the multi-step outputs can also allow us to form a stock portfolio over the prediction length. We demonstrate the effectiveness of our model outputs in the portfolio investment task through the Sharpe ratio metric and highlight the importance of dealing with different types of prediction uncertainties.
SDR-GAIN: A High Real-Time Occluded Pedestrian Pose Completion Method for Autonomous Driving
Jun 10, 2023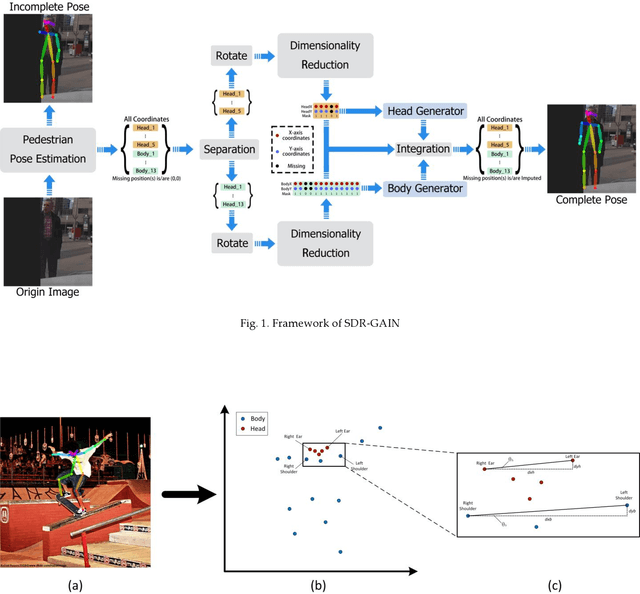
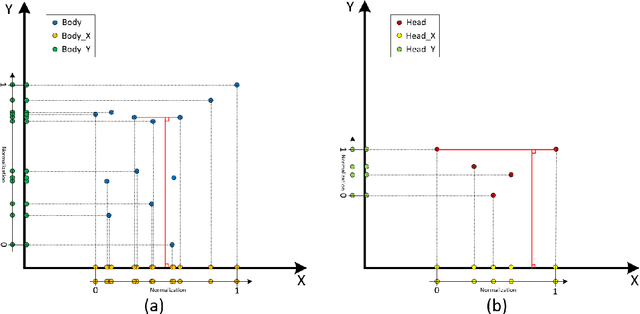
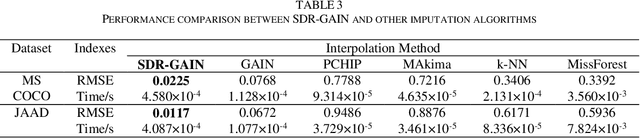
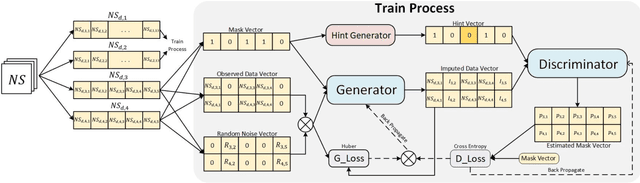
To mitigate the challenges arising from partial occlusion in human pose keypoint based pedestrian detection methods , we present a novel pedestrian pose keypoint completion method called the separation and dimensionality reduction-based generative adversarial imputation networks (SDR-GAIN). Firstly, we utilize OpenPose to estimate pedestrian poses in images. Then, we isolate the head and torso keypoints of pedestrians with incomplete keypoints due to occlusion or other factors and perform dimensionality reduction to enhance features and further unify feature distribution. Finally, we introduce two generative models based on the generative adversarial networks (GAN) framework, which incorporate Huber loss, residual structure, and L1 regularization to generate missing parts of the incomplete head and torso pose keypoints of partially occluded pedestrians, resulting in pose completion. Our experiments on MS COCO and JAAD datasets demonstrate that SDR-GAIN outperforms basic GAIN framework, interpolation methods PCHIP and MAkima, machine learning methods k-NN and MissForest in terms of pose completion task. Furthermore, the SDR-GAIN algorithm exhibits a remarkably short running time of approximately 0.4ms and boasts exceptional real-time performance. As such, it holds significant practical value in the domain of autonomous driving, wherein high system response speeds are of paramount importance. Specifically, it excels at rapidly and precisely capturing human pose key points, thus enabling an expanded range of applications for pedestrian detection tasks based on pose key points, including but not limited to pedestrian behavior recognition and prediction.
CASSINI: Network-Aware Job Scheduling in Machine Learning Clusters
Aug 01, 2023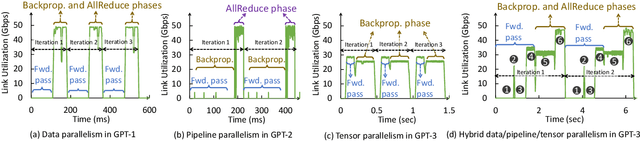
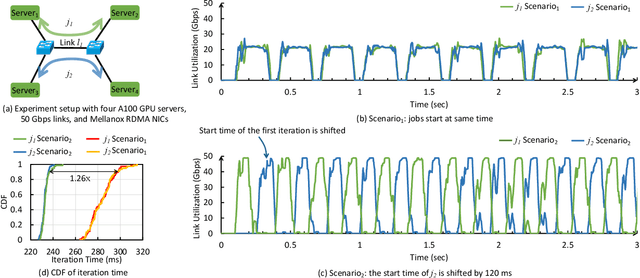
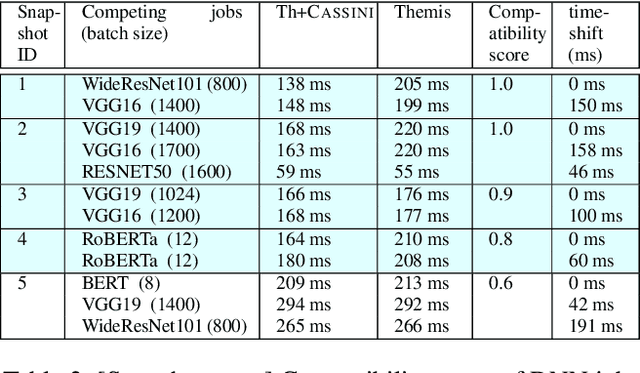

We present CASSINI, a network-aware job scheduler for machine learning (ML) clusters. CASSINI introduces a novel geometric abstraction to consider the communication pattern of different jobs while placing them on network links. To do so, CASSINI uses an affinity graph that finds a series of time-shift values to adjust the communication phases of a subset of jobs, such that the communication patterns of jobs sharing the same network link are interleaved with each other. Experiments with 13 common ML models on a 24-server testbed demonstrate that compared to the state-of-the-art ML schedulers, CASSINI improves the average and tail completion time of jobs by up to 1.6x and 2.5x, respectively. Moreover, we show that CASSINI reduces the number of ECN marked packets in the cluster by up to 33x.
Extended Preintegration for Relative State Estimation of Leader-Follower Platform
Aug 15, 2023Relative state estimation using exteroceptive sensors suffers from limitations of the field of view (FOV) and false detection, that the proprioceptive sensor (IMU) data are usually engaged to compensate. Recently ego-motion constraint obtained by Inertial measurement unit (IMU) preintegration has been extensively used in simultaneous localization and mapping (SLAM) to alleviate the computation burden. This paper introduces an extended preintegration incorporating the IMU preintegration of two platforms to formulate the motion constraint of relative state. One merit of this analytic constraint is that it can be seamlessly integrated into the unified graph optimization framework to implement the relative state estimation in a high-performance real-time tracking thread, another point is a full smoother design with this precise constraint to optimize the 3D coordinate and refine the state for the refinement thread. We compare extensively in simulations the proposed algorithms with two existing approaches to confirm our outperformance. In the real virtual reality (VR) application design with the proposed estimator, we properly realize the visual tracking of the six degrees of freedom (6DoF) controller suitable for almost all scenarios, including the challenging environment with missing features, light mutation, dynamic scenes, etc. The demo video is at https://www.youtube.com/watch?v=0idb9Ls2iAM. For the benefit of the community, we make the source code public.
DiffGuard: Semantic Mismatch-Guided Out-of-Distribution Detection using Pre-trained Diffusion Models
Aug 15, 2023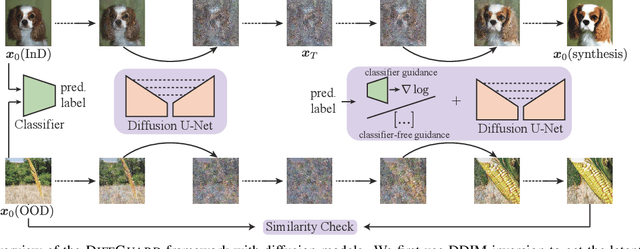
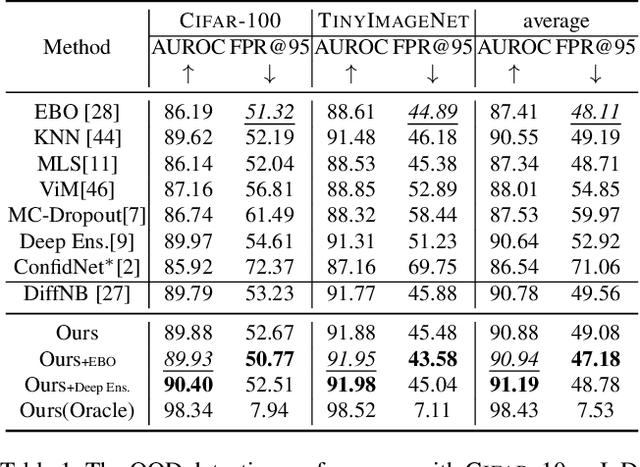

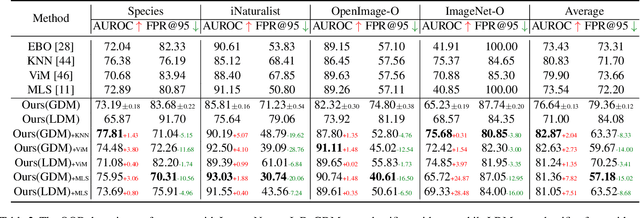
Given a classifier, the inherent property of semantic Out-of-Distribution (OOD) samples is that their contents differ from all legal classes in terms of semantics, namely semantic mismatch. There is a recent work that directly applies it to OOD detection, which employs a conditional Generative Adversarial Network (cGAN) to enlarge semantic mismatch in the image space. While achieving remarkable OOD detection performance on small datasets, it is not applicable to ImageNet-scale datasets due to the difficulty in training cGANs with both input images and labels as conditions. As diffusion models are much easier to train and amenable to various conditions compared to cGANs, in this work, we propose to directly use pre-trained diffusion models for semantic mismatch-guided OOD detection, named DiffGuard. Specifically, given an OOD input image and the predicted label from the classifier, we try to enlarge the semantic difference between the reconstructed OOD image under these conditions and the original input image. We also present several test-time techniques to further strengthen such differences. Experimental results show that DiffGuard is effective on both Cifar-10 and hard cases of the large-scale ImageNet, and it can be easily combined with existing OOD detection techniques to achieve state-of-the-art OOD detection results.
Grasp Transfer based on Self-Aligning Implicit Representations of Local Surfaces
Aug 15, 2023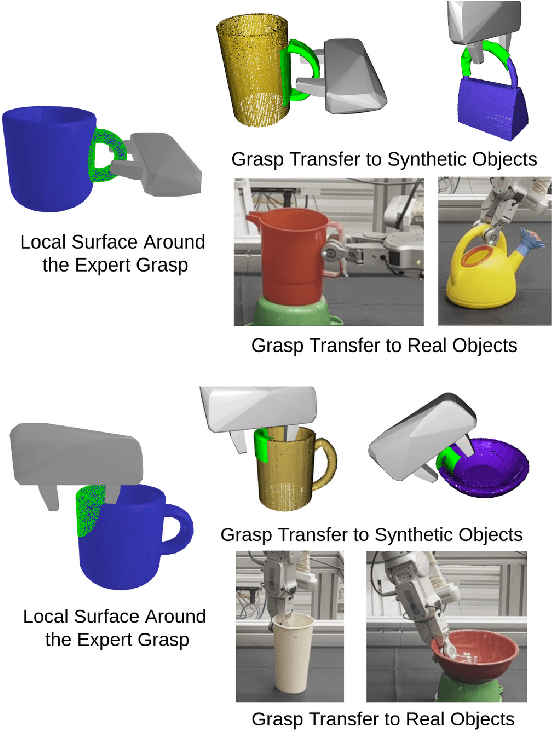
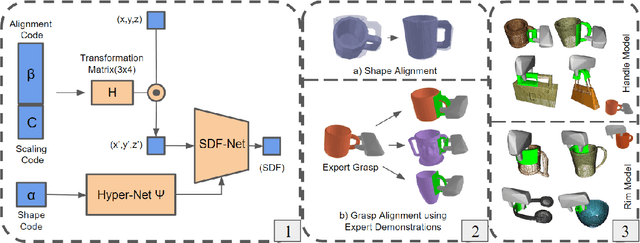


Objects we interact with and manipulate often share similar parts, such as handles, that allow us to transfer our actions flexibly due to their shared functionality. This work addresses the problem of transferring a grasp experience or a demonstration to a novel object that shares shape similarities with objects the robot has previously encountered. Existing approaches for solving this problem are typically restricted to a specific object category or a parametric shape. Our approach, however, can transfer grasps associated with implicit models of local surfaces shared across object categories. Specifically, we employ a single expert grasp demonstration to learn an implicit local surface representation model from a small dataset of object meshes. At inference time, this model is used to transfer grasps to novel objects by identifying the most geometrically similar surfaces to the one on which the expert grasp is demonstrated. Our model is trained entirely in simulation and is evaluated on simulated and real-world objects that are not seen during training. Evaluations indicate that grasp transfer to unseen object categories using this approach can be successfully performed both in simulation and real-world experiments. The simulation results also show that the proposed approach leads to better spatial precision and grasp accuracy compared to a baseline approach.