 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
The Alternating-Time μ-Calculus With Disjunctive Explicit Strategies
May 30, 2023
Alternating-time temporal logic (ATL) and its extensions, including the alternating-time $\mu$-calculus (AMC), serve the specification of the strategic abilities of coalitions of agents in concurrent game structures. The key ingredient of the logic are path quantifiers specifying that some coalition of agents has a joint strategy to enforce a given goal. This basic setup has been extended to let some of the agents (revocably) commit to using certain named strategies, as in ATL with explicit strategies (ATLES). In the present work, we extend ATLES with fixpoint operators and strategy disjunction, arriving at the alternating-time $\mu$-calculus with disjunctive explicit strategies (AMCDES), which allows for a more flexible formulation of temporal properties (e.g. fairness) and, through strategy disjunction, a form of controlled nondeterminism in commitments. Our main result is an ExpTime upper bound for satisfiability checking (which is thus ExpTime-complete). We also prove upper bounds QP (quasipolynomial time) and NP $\cap$ coNP for model checking under fixed interpretations of explicit strategies, and NP under open interpretation. Our key technical tool is a treatment of the AMCDES within the generic framework of coalgebraic logic, which in particular reduces the analysis of most reasoning tasks to the treatment of a very simple one-step logic featuring only propositional operators and next-step operators without nesting; we give a new model construction principle for this one-step logic that relies on a set-valued variant of first-order resolution.
* Full version with appendix as well as corrected set-valued resolution method
Neural approaches to spoken content embedding
Aug 28, 2023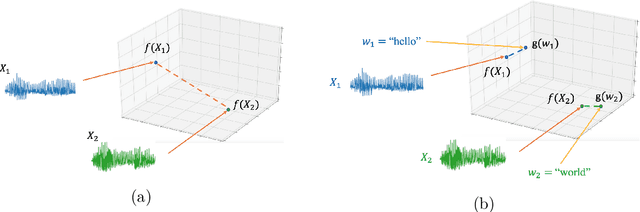
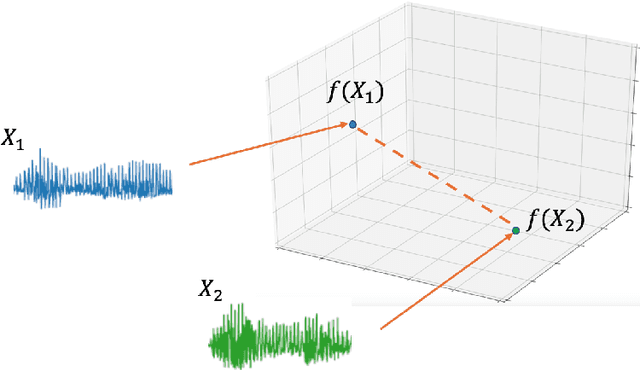
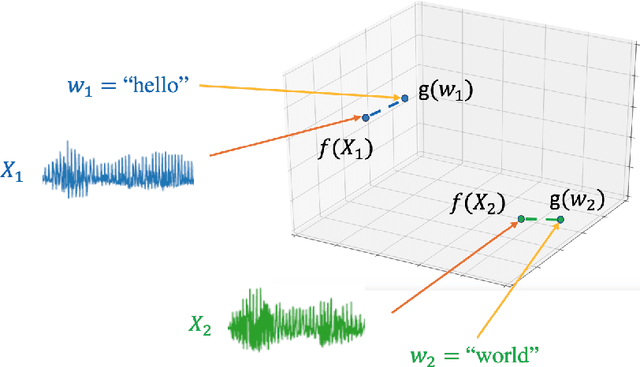
Comparing spoken segments is a central operation to speech processing. Traditional approaches in this area have favored frame-level dynamic programming algorithms, such as dynamic time warping, because they require no supervision, but they are limited in performance and efficiency. As an alternative, acoustic word embeddings -- fixed-dimensional vector representations of variable-length spoken word segments -- have begun to be considered for such tasks as well. However, the current space of such discriminative embedding models, training approaches, and their application to real-world downstream tasks is limited. We start by considering ``single-view" training losses where the goal is to learn an acoustic word embedding model that separates same-word and different-word spoken segment pairs. Then, we consider ``multi-view" contrastive losses. In this setting, acoustic word embeddings are learned jointly with embeddings of character sequences to generate acoustically grounded embeddings of written words, or acoustically grounded word embeddings. In this thesis, we contribute new discriminative acoustic word embedding (AWE) and acoustically grounded word embedding (AGWE) approaches based on recurrent neural networks (RNNs). We improve model training in terms of both efficiency and performance. We take these developments beyond English to several low-resource languages and show that multilingual training improves performance when labeled data is limited. We apply our embedding models, both monolingual and multilingual, to the downstream tasks of query-by-example speech search and automatic speech recognition. Finally, we show how our embedding approaches compare with and complement more recent self-supervised speech models.
Hybrid PLS-ML Authentication Scheme for V2I Communication Networks
Aug 28, 2023Vehicular communication networks are rapidly emerging as vehicles become smarter. However, these networks are increasingly susceptible to various attacks. The situation is exacerbated by the rise in automated vehicles complicates, emphasizing the need for security and authentication measures to ensure safe and effective traffic management. In this paper, we propose a novel hybrid physical layer security (PLS)-machine learning (ML) authentication scheme by exploiting the position of the transmitter vehicle as a device fingerprint. We use a time-of-arrival (ToA) based localization mechanism where the ToA is estimated at roadside units (RSUs), and the coordinates of the transmitter vehicle are extracted at the base station (BS).Furthermore, to track the mobility of the moving legitimate vehicle, we use ML model trained on several system parameters. We try two ML models for this purpose, i.e., support vector regression and decision tree. To evaluate our scheme, we conduct binary hypothesis testing on the estimated positions with the help of the ground truths provided by the ML model, which classifies the transmitter node as legitimate or malicious. Moreover, we consider the probability of false alarm and the probability of missed detection as performance metrics resulting from the binary hypothesis testing, and mean absolute error (MAE), mean square error (MSE), and coefficient of determination $\text{R}^2$ to further evaluate the ML models. We also compare our scheme with a baseline scheme that exploits the angle of arrival at RSUs for authentication. We observe that our proposed position-based mechanism outperforms the baseline scheme significantly in terms of missed detections.
A Homomorphic Encryption Framework for Privacy-Preserving Spiking Neural Networks
Aug 10, 2023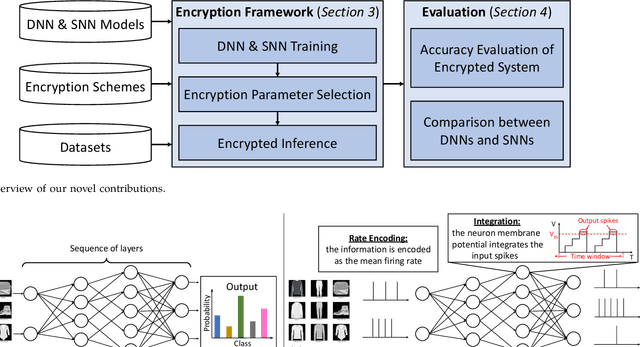
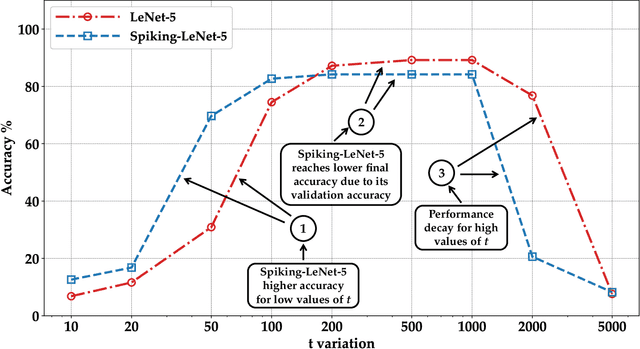
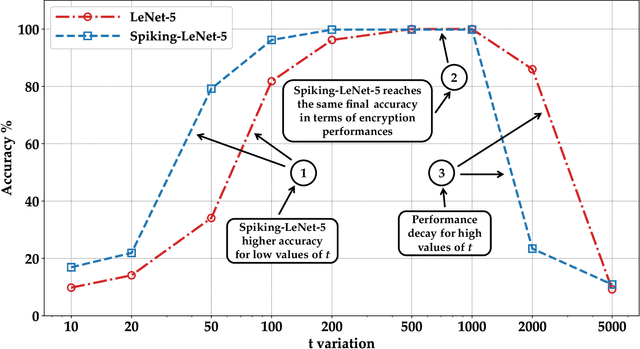
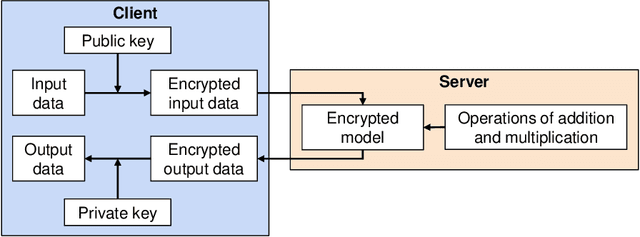
Machine learning (ML) is widely used today, especially through deep neural networks (DNNs), however, increasing computational load and resource requirements have led to cloud-based solutions. To address this problem, a new generation of networks called Spiking Neural Networks (SNN) has emerged, which mimic the behavior of the human brain to improve efficiency and reduce energy consumption. These networks often process large amounts of sensitive information, such as confidential data, and thus privacy issues arise. Homomorphic encryption (HE) offers a solution, allowing calculations to be performed on encrypted data without decrypting it. This research compares traditional DNNs and SNNs using the Brakerski/Fan-Vercauteren (BFV) encryption scheme. The LeNet-5 model, a widely-used convolutional architecture, is used for both DNN and SNN models based on the LeNet-5 architecture, and the networks are trained and compared using the FashionMNIST dataset. The results show that SNNs using HE achieve up to 40% higher accuracy than DNNs for low values of the plaintext modulus t, although their execution time is longer due to their time-coding nature with multiple time-steps.
LSTM-based QoE Evaluation for Web Microservices' Reputation Scoring
Aug 25, 2023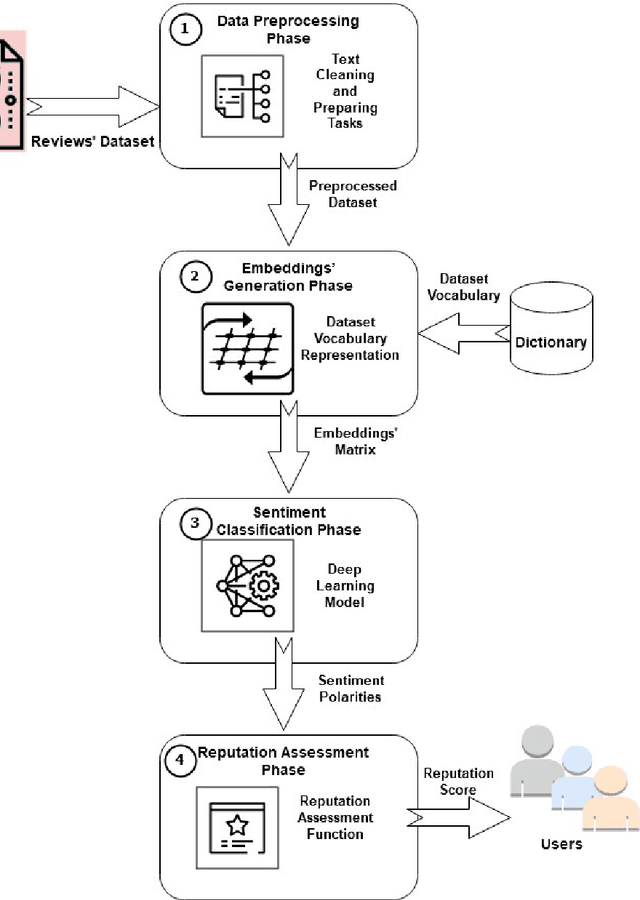

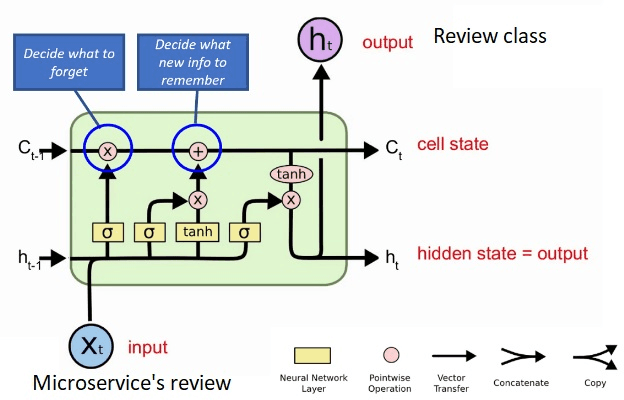
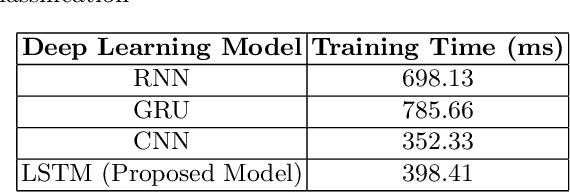
Sentiment analysis is the task of mining the authors' opinions about specific entities. It allows organizations to monitor different services in real time and act accordingly. Reputation is what is generally said or believed about people or things. Informally, reputation combines the measure of reliability derived from feedback, reviews, and ratings gathered from users, which reflect their quality of experience (QoE) and can either increase or harm the reputation of the provided services. In this study, we propose to perform sentiment analysis on web microservices reviews to exploit the provided information to assess and score the microservices' reputation. Our proposed approach uses the Long Short-Term Memory (LSTM) model to perform sentiment analysis and the Net Brand Reputation (NBR) algorithm to assess reputation scores for microservices. This approach is tested on a set of more than 10,000 reviews related to 15 Amazon Web microservices, and the experimental results have shown that our approach is more accurate than existing approaches, with an accuracy and precision of 93% obtained after applying an oversampling strategy and a resulting reputation score of the considered microservices community of 89%.
Fine-tuning can cripple your foundation model; preserving features may be the solution
Aug 25, 2023
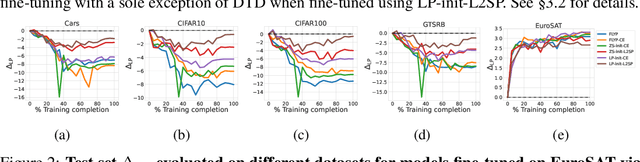
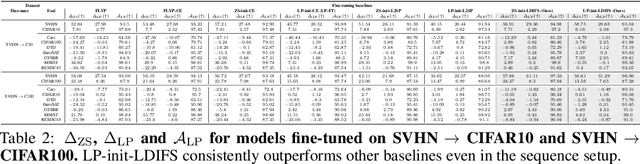
Pre-trained foundation models, owing primarily to their enormous capacity and exposure to vast amount of training data scraped from the internet, enjoy the advantage of storing knowledge about plenty of real-world concepts. Such models are typically fine-tuned on downstream datasets to produce remarkable state-of-the-art performances. While various fine-tuning methods have been devised and are shown to be highly effective, we observe that a fine-tuned model's ability to recognize concepts on tasks $\textit{different}$ from the downstream one is reduced significantly compared to its pre-trained counterpart. This is clearly undesirable as a huge amount of time and money went into learning those very concepts in the first place. We call this undesirable phenomenon "concept forgetting" and via experiments show that most end-to-end fine-tuning approaches suffer heavily from this side effect. To this end, we also propose a rather simple fix to this problem by designing a method called LDIFS (short for $\ell_2$ distance in feature space) that simply preserves the features of the original foundation model during fine-tuning. We show that LDIFS significantly reduces concept forgetting without having noticeable impact on the downstream task performance.
Correcting Motion Distortion for LIDAR HD-Map Localization
Aug 25, 2023Because scanning-LIDAR sensors require finite time to create a point cloud, sensor motion during a scan warps the resulting image, a phenomenon known as motion distortion or rolling shutter. Motion-distortion correction methods exist, but they rely on external measurements or Bayesian filtering over multiple LIDAR scans. In this paper we propose a novel algorithm that performs snapshot processing to obtain a motion-distortion correction. Snapshot processing, which registers a current LIDAR scan to a reference image without using external sensors or Bayesian filtering, is particularly relevant for localization to a high-definition (HD) map. Our approach, which we call Velocity-corrected Iterative Compact Ellipsoidal Transformation (VICET), extends the well-known Normal Distributions Transform (NDT) algorithm to solve jointly for both a 6 Degree-of-Freedom (DOF) rigid transform between two LIDAR scans and a set of 6DOF motion states that describe distortion within the current LIDAR scan. Using experiments, we show that VICET achieves significantly higher accuracy than NDT or Iterative Closest Point (ICP) algorithms when localizing a distorted raw LIDAR scan against an undistorted HD Map. We recommend the reader explore our open-source code and visualizations at https://github.com/mcdermatt/VICET, which supplements this manuscript.
Real-time Seismic Intensity Prediction using Self-supervised Contrastive GNN for Earthquake Early Warning
Jun 25, 2023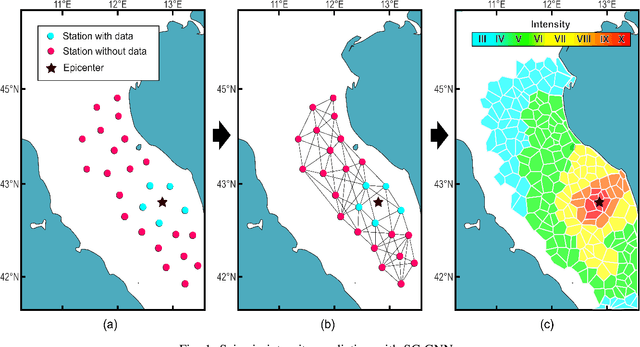
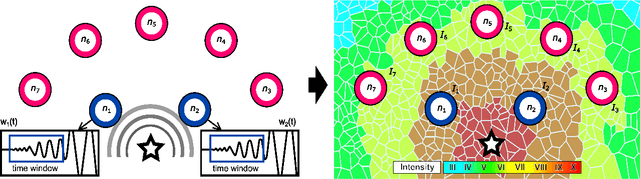
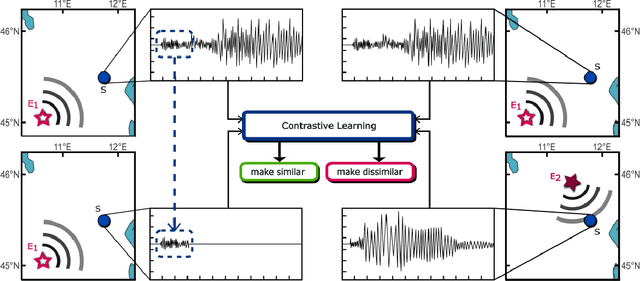
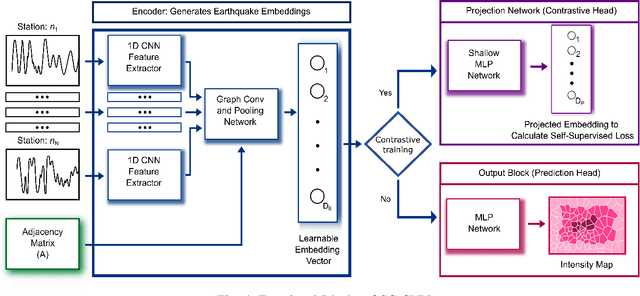
Seismic intensity prediction in a geographical area from early or initial seismic waves received by a few seismic stations is a critical component of an effective Earthquake Early Warning (EEW) system. State-of-the-art deep learning-based techniques for this task suffer from limited accuracy in the prediction and, more importantly, require input waveforms of a large time window from a handful number of seismic stations, which is not practical for EEW systems. To overcome the above limitations, in this paper, we propose a novel deep learning approach, Seismic Contrastive Graph Neural Network (SC-GNN) for highly accurate seismic intensity prediction using a small portion of initial seismic waveforms received by a few seismic stations. The SC-GNN comprises two key components: (i) a graph neural network (GNN) to propagate spatiotemporal information through the nodes of a graph-like structure of seismic station distribution and wave propagation, and (ii) a self-supervised contrastive learning component to train the model with larger time windows and make predictions using shorter initial waveforms. The efficacy of our proposed model is thoroughly evaluated through experiments on three real-world seismic datasets, showing superior performance over existing state-of-the-art techniques. In particular, the SC-GNN model demonstrates a substantial reduction in mean squared error (MSE) and the lowest standard deviation of the error, indicating its robustness, reliability, and a strong positive relationship between predicted and actual values. More importantly, the model maintains superior performance even with 5s input waveforms, making it particularly efficient for EEW systems.
3ET: Efficient Event-based Eye Tracking using a Change-Based ConvLSTM Network
Aug 22, 2023This paper presents a sparse Change-Based Convolutional Long Short-Term Memory (CB-ConvLSTM) model for event-based eye tracking, key for next-generation wearable healthcare technology such as AR/VR headsets. We leverage the benefits of retina-inspired event cameras, namely their low-latency response and sparse output event stream, over traditional frame-based cameras. Our CB-ConvLSTM architecture efficiently extracts spatio-temporal features for pupil tracking from the event stream, outperforming conventional CNN structures. Utilizing a delta-encoded recurrent path enhancing activation sparsity, CB-ConvLSTM reduces arithmetic operations by approximately 4.7$\times$ without losing accuracy when tested on a \texttt{v2e}-generated event dataset of labeled pupils. This increase in efficiency makes it ideal for real-time eye tracking in resource-constrained devices. The project code and dataset are openly available at \url{https://github.com/qinche106/cb-convlstm-eyetracking}.
SHIELD: Sustainable Hybrid Evolutionary Learning Framework for Carbon, Wastewater, and Energy-Aware Data Center Management
Aug 24, 2023Today's cloud data centers are often distributed geographically to provide robust data services. But these geo-distributed data centers (GDDCs) have a significant associated environmental impact due to their increasing carbon emissions and water usage, which needs to be curtailed. Moreover, the energy costs of operating these data centers continue to rise. This paper proposes a novel framework to co-optimize carbon emissions, water footprint, and energy costs of GDDCs, using a hybrid workload management framework called SHIELD that integrates machine learning guided local search with a decomposition-based evolutionary algorithm. Our framework considers geographical factors and time-based differences in power generation/use, costs, and environmental impacts to intelligently manage workload distribution across GDDCs and data center operation. Experimental results show that SHIELD can realize 34.4x speedup and 2.1x improvement in Pareto Hypervolume while reducing the carbon footprint by up to 3.7x, water footprint by up to 1.8x, energy costs by up to 1.3x, and a cumulative improvement across all objectives (carbon, water, cost) of up to 4.8x compared to the state-of-the-art.