 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CRUISE-Screening: Living Literature Reviews Toolbox
Sep 04, 2023
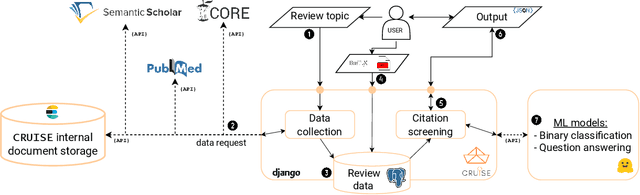

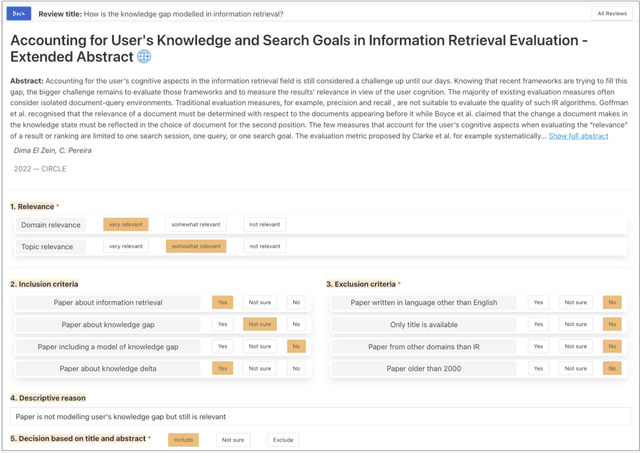
Keeping up with research and finding related work is still a time-consuming task for academics. Researchers sift through thousands of studies to identify a few relevant ones. Automation techniques can help by increasing the efficiency and effectiveness of this task. To this end, we developed CRUISE-Screening, a web-based application for conducting living literature reviews - a type of literature review that is continuously updated to reflect the latest research in a particular field. CRUISE-Screening is connected to several search engines via an API, which allows for updating the search results periodically. Moreover, it can facilitate the process of screening for relevant publications by using text classification and question answering models. CRUISE-Screening can be used both by researchers conducting literature reviews and by those working on automating the citation screening process to validate their algorithms. The application is open-source: https://github.com/ProjectDoSSIER/cruise-screening, and a demo is available under this URL: https://citation-screening.ec.tuwien.ac.at. We discuss the limitations of our tool in Appendix A.
Raw Data Is All You Need: Virtual Axle Detector with Enhanced Receptive Field
Sep 04, 2023Rising maintenance costs of ageing infrastructure necessitate innovative monitoring techniques. This paper presents a new approach for axle detection, enabling real-time application of Bridge Weigh-In-Motion (BWIM) systems without dedicated axle detectors. The proposed method adapts the Virtual Axle Detector (VAD) model to handle raw acceleration data, which allows the receptive field to be increased. The proposed Virtual Axle Detector with Enhanced Receptive field (VADER) improves the \(F_1\) score by 73\% and spatial accuracy by 39\%, while cutting computational and memory costs by 99\% compared to the state-of-the-art VAD. VADER reaches a \(F_1\) score of 99.4\% and a spatial error of 4.13~cm when using a representative training set and functional sensors. We also introduce a novel receptive field (RF) rule for an object-size driven design of Convolutional Neural Network (CNN) architectures. Based on this rule, our results suggest that models using raw data could achieve better performance than those using spectrograms, offering a compelling reason to consider raw data as input.
Pure Monte Carlo Counterfactual Regret Minimization
Sep 04, 2023
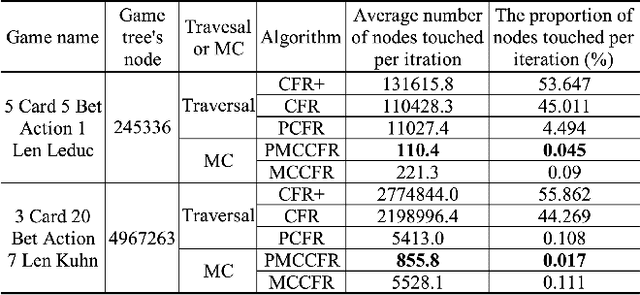
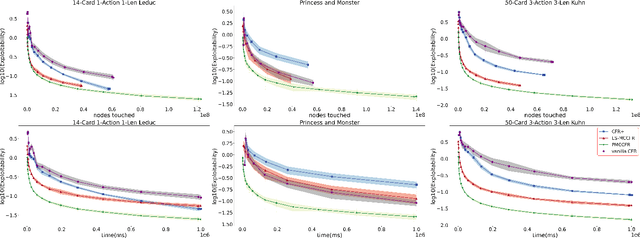
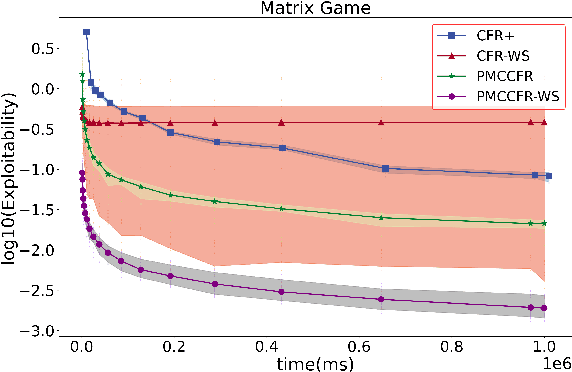
Counterfactual Regret Minimization (CFR) and its variants are the best algorithms so far for solving large-scale incomplete information games. Building upon CFR, this paper proposes a new algorithm named Pure CFR (PCFR) for achieving better performance. PCFR can be seen as a combination of CFR and Fictitious Play (FP), inheriting the concept of counterfactual regret (value) from CFR, and using the best response strategy instead of the regret matching strategy for the next iteration. Our theoretical proof that PCFR can achieve Blackwell approachability enables PCFR's ability to combine with any CFR variant including Monte Carlo CFR (MCCFR). The resultant Pure MCCFR (PMCCFR) can significantly reduce time and space complexity. Particularly, the convergence speed of PMCCFR is at least three times more than that of MCCFR. In addition, since PMCCFR does not pass through the path of strictly dominated strategies, we developed a new warm-start algorithm inspired by the strictly dominated strategies elimination method. Consequently, the PMCCFR with new warm start algorithm can converge by two orders of magnitude faster than the CFR+ algorithm.
Passing Heatmap Prediction Based on Transformer Model and Tracking Data
Sep 04, 2023Although the data-driven analysis of football players' performance has been developed for years, most research only focuses on the on-ball event including shots and passes, while the off-ball movement remains a little-explored area in this domain. Players' contributions to the whole match are evaluated unfairly, those who have more chances to score goals earn more credit than others, while the indirect and unnoticeable impact that comes from continuous movement has been ignored. This research presents a novel deep-learning network architecture which is capable to predict the potential end location of passes and how players' movement before the pass affects the final outcome. Once analysed more than 28,000 pass events, a robust prediction can be achieved with more than 0.7 Top-1 accuracy. And based on the prediction, a better understanding of the pitch control and pass option could be reached to measure players' off-ball movement contribution to defensive performance. Moreover, this model could provide football analysts a better tool and metric to understand how players' movement over time contributes to the game strategy and final victory.
An ML-assisted OTFS vs. OFDM adaptable modem
Sep 04, 2023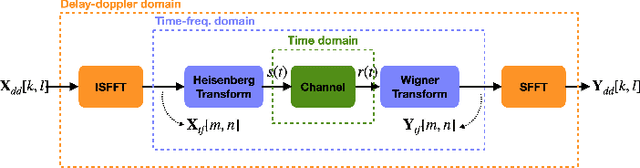
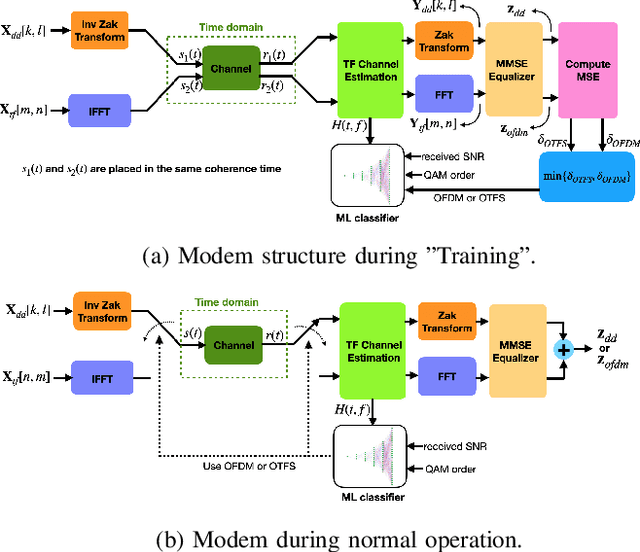
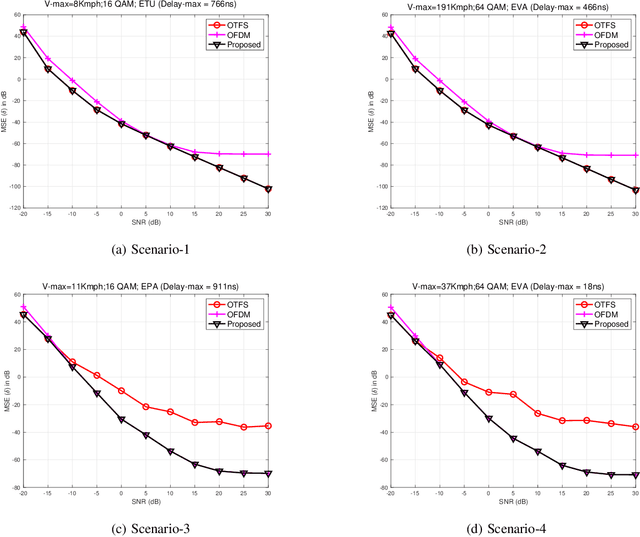
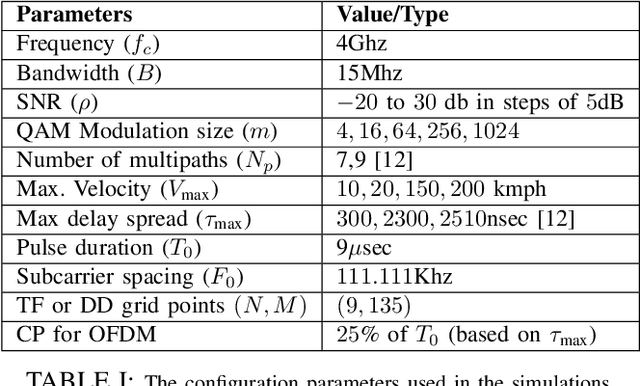
The Orthogonal-Time-Frequency-Space (OTFS) signaling is known to be resilient to doubly-dispersive channels, which impacts high mobility scenarios. On the other hand, the Orthogonal-Frequency-Division-Multiplexing (OFDM) waveforms enjoy the benefits of the reuse of legacy architectures, simplicity of receiver design, and low-complexity detection. Several studies that compare the performance of OFDM and OTFS have indicated mixed outcomes due to the plethora of system parameters at play beyond high-mobility conditions. In this work, we exemplify this observation using simulations and propose a deep neural network (DNN)-based adaptation scheme to switch between using either an OTFS or OFDM signal processing chain at the transmitter and receiver for optimal mean-squared-error (MSE) performance. The DNN classifier is trained to switch between the two schemes by observing the channel condition, received SNR, and modulation format. We compare the performance of the OTFS, OFDM, and the proposed switched-waveform scheme. The simulations indicate superior performance with the proposed scheme with a well-trained DNN, thus improving the MSE performance of the communication significantly.
This Is a Local Domain: On Amassing Country-Code Top-Level Domains from Public Data
Sep 04, 2023Domain lists are a key ingredient for representative censuses of the Web. Unfortunately, such censuses typically lack a view on domains under country-code top-level domains (ccTLDs). This introduces unwanted bias: many countries have a rich local Web that remains hidden if their ccTLDs are not considered. The reason ccTLDs are rarely considered is that gaining access -- if possible at all -- is often laborious. To tackle this, we ask: what can we learn about ccTLDs from public sources? We extract domain names under ccTLDs from 6 years of public data from Certificate Transparency logs and Common Crawl. We compare this against ground truth for 19 ccTLDs for which we have the full DNS zone. We find that public data covers 43%-80% of these ccTLDs, and that coverage grows over time. By also comparing port scan data we then show that these public sources reveal a significant part of the Web presence under a ccTLD. We conclude that in the absence of full access to ccTLDs, domain names learned from public sources can be a good proxy when performing Web censuses.
Defect Detection in Synthetic Fibre Ropes using Detectron2 Framework
Sep 04, 2023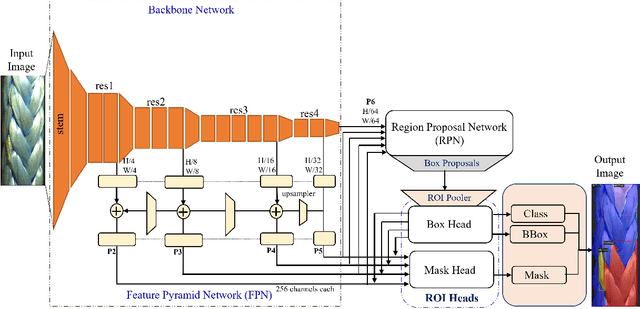
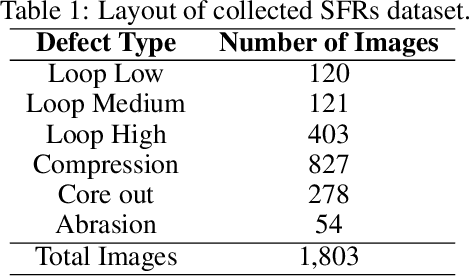


Fibre ropes with the latest technology have emerged as an appealing alternative to steel ropes for offshore industries due to their lightweight and high tensile strength. At the same time, frequent inspection of these ropes is essential to ensure the proper functioning and safety of the entire system. The development of deep learning (DL) models in condition monitoring (CM) applications offers a simpler and more effective approach for defect detection in synthetic fibre ropes (SFRs). The present paper investigates the performance of Detectron2, a state-of-the-art library for defect detection and instance segmentation. Detectron2 with Mask R-CNN architecture is used for segmenting defects in SFRs. Mask R-CNN with various backbone configurations has been trained and tested on an experimentally obtained dataset comprising 1,803 high-dimensional images containing seven damage classes (loop high, loop medium, loop low, compression, core out, abrasion, and normal respectively) for SFRs. By leveraging the capabilities of Detectron2, this study aims to develop an automated and efficient method for detecting defects in SFRs, enhancing the inspection process, and ensuring the safety of the fibre ropes.
Better Practices for Domain Adaptation
Sep 07, 2023


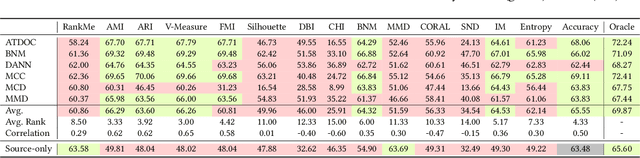
Distribution shifts are all too common in real-world applications of machine learning. Domain adaptation (DA) aims to address this by providing various frameworks for adapting models to the deployment data without using labels. However, the domain shift scenario raises a second more subtle challenge: the difficulty of performing hyperparameter optimisation (HPO) for these adaptation algorithms without access to a labelled validation set. The unclear validation protocol for DA has led to bad practices in the literature, such as performing HPO using the target test labels when, in real-world scenarios, they are not available. This has resulted in over-optimism about DA research progress compared to reality. In this paper, we analyse the state of DA when using good evaluation practice, by benchmarking a suite of candidate validation criteria and using them to assess popular adaptation algorithms. We show that there are challenges across all three branches of domain adaptation methodology including Unsupervised Domain Adaptation (UDA), Source-Free Domain Adaptation (SFDA), and Test Time Adaptation (TTA). While the results show that realistically achievable performance is often worse than expected, they also show that using proper validation splits is beneficial, as well as showing that some previously unexplored validation metrics provide the best options to date. Altogether, our improved practices covering data, training, validation and hyperparameter optimisation form a new rigorous pipeline to improve benchmarking, and hence research progress, within this important field going forward.
DGSD: Dynamical Graph Self-Distillation for EEG-Based Auditory Spatial Attention Detection
Sep 07, 2023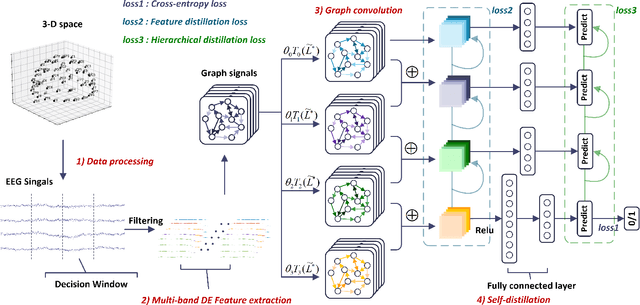
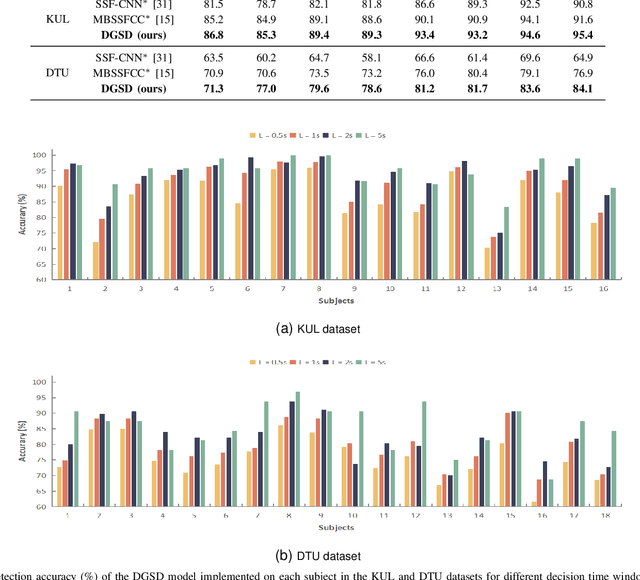
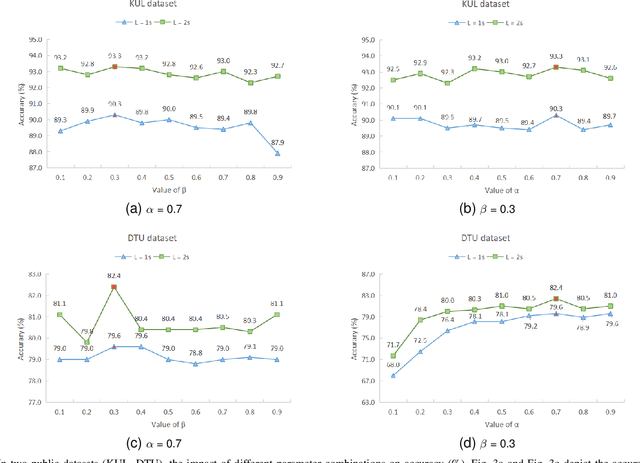

Auditory Attention Detection (AAD) aims to detect target speaker from brain signals in a multi-speaker environment. Although EEG-based AAD methods have shown promising results in recent years, current approaches primarily rely on traditional convolutional neural network designed for processing Euclidean data like images. This makes it challenging to handle EEG signals, which possess non-Euclidean characteristics. In order to address this problem, this paper proposes a dynamical graph self-distillation (DGSD) approach for AAD, which does not require speech stimuli as input. Specifically, to effectively represent the non-Euclidean properties of EEG signals, dynamical graph convolutional networks are applied to represent the graph structure of EEG signals, which can also extract crucial features related to auditory spatial attention in EEG signals. In addition, to further improve AAD detection performance, self-distillation, consisting of feature distillation and hierarchical distillation strategies at each layer, is integrated. These strategies leverage features and classification results from the deepest network layers to guide the learning of shallow layers. Our experiments are conducted on two publicly available datasets, KUL and DTU. Under a 1-second time window, we achieve results of 90.0\% and 79.6\% accuracy on KUL and DTU, respectively. We compare our DGSD method with competitive baselines, and the experimental results indicate that the detection performance of our proposed DGSD method is not only superior to the best reproducible baseline but also significantly reduces the number of trainable parameters by approximately 100 times.
Experimental Study of Adversarial Attacks on ML-based xApps in O-RAN
Sep 07, 2023Open Radio Access Network (O-RAN) is considered as a major step in the evolution of next-generation cellular networks given its support for open interfaces and utilization of artificial intelligence (AI) into the deployment, operation, and maintenance of RAN. However, due to the openness of the O-RAN architecture, such AI models are inherently vulnerable to various adversarial machine learning (ML) attacks, i.e., adversarial attacks which correspond to slight manipulation of the input to the ML model. In this work, we showcase the vulnerability of an example ML model used in O-RAN, and experimentally deploy it in the near-real time (near-RT) RAN intelligent controller (RIC). Our ML-based interference classifier xApp (extensible application in near-RT RIC) tries to classify the type of interference to mitigate the interference effect on the O-RAN system. We demonstrate the first-ever scenario of how such an xApp can be impacted through an adversarial attack by manipulating the data stored in a shared database inside the near-RT RIC. Through a rigorous performance analysis deployed on a laboratory O-RAN testbed, we evaluate the performance in terms of capacity and the prediction accuracy of the interference classifier xApp using both clean and perturbed data. We show that even small adversarial attacks can significantly decrease the accuracy of ML application in near-RT RIC, which can directly impact the performance of the entire O-RAN deployment.