 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeleResilienceBench: Quantifying Resilience for LLM Reasoning in Telecommunications
May 11, 2026Deploying large language models in telecommunications requires more than task accuracy. In realistic workflows, a model may inherit partially completed reasoning from a prior step, an upstream agent, or its own earlier generation, and must continue that reasoning even when it is already going wrong. We introduce TeleResilienceBench, a benchmark that quantifies this capability, which we term reasoning resilience, across seven telecom sub-domains drawn from the GSMA Open-Telco LLM suite. Instances are constructed by collecting failures from a weak generator model, truncating the flawed reasoning trace at its midpoint, and asking a target model to continue and correct it. We propose the Correct Flip Rate (CFR) as a direct measure of successful recovery and evaluate eight models spanning the Qwen3.5, Gemma4, and Nemotron-3 families. Our results show that even the strongest model achieves a macro-average CFR of only 29.1%, and scale does not reliably improve resilience within families. Nemotron-3-nano 4b outperforms all Qwen3.5 variants including the 27b model and leads the auxiliary TeleMath numerical evaluation at 23.4% CR%, offering the best resilience-to-cost ratio in the set. A difficulty-stratified analysis further reveals that existing telecom benchmark difficulty labels reflect factual specificity rather than reasoning depth, suggesting that current evaluations measure knowledge coverage more than reasoning ability.
TeleEmbedBench: A Multi-Corpus Embedding Benchmark for RAG in Telecommunications
Apr 20, 2026Large language models (LLMs) are increasingly deployed in the telecommunications domain for critical tasks, relying heavily on Retrieval-Augmented Generation (RAG) to adapt general-purpose models to continuously evolving standards. However, a significant gap exists in evaluating the embedding models that power these RAG pipelines, as general-purpose benchmarks fail to capture the dense, acronym-heavy, and highly cross-referential nature of telecommunications corpora. To address this, we introduce TeleEmbedBench, the first large-scale, multi-corpus embedding benchmark designed specifically for telecommunications. The benchmark spans three heterogeneous corpora: O-RAN Alliance specifications, 3GPP release documents, and the srsRAN open-source codebase, comprising 9,000 question-chunk pairs across three standard chunk sizes (512, 1024, and 2048 tokens). To construct this dataset at scale without manual annotation bottlenecks, we employ a novel automated pipeline where one LLM generates specific queries from text chunks and a secondary LLM validates them across strict criteria. We comprehensively evaluate eight embedding models, spanning standard sentence-transformers and LLM-based embedders. Our results demonstrate that LLM-based embedders, such as Qwen3 and EmbeddingGemma, consistently and significantly outperform traditional sentence-transformers in both retrieval accuracy and robustness against cross-domain interference. Additionally, we introduce TeleEmbedBench-Clean to evaluate model robustness against noisy, incomplete user queries. Finally, our analysis reveals that while domain-specific task instructions improve embedder performance for raw source code, they paradoxically degrade retrieval performance for natural language telecommunications specifications.
Tele-LLM-Hub: Building Context-Aware Multi-Agent LLM Systems for Telecom Networks
Nov 18, 2025This paper introduces Tele-LLM-Hub, a user friendly low-code solution for rapid prototyping and deployment of context aware multi-agent (MA) Large Language Model (LLM) systems tailored for 5G and beyond. As telecom wireless networks become increasingly complex, intelligent LLM applications must share a domainspecific understanding of network state. We propose TeleMCP, the Telecom Model Context Protocol, to enable structured and context-rich communication between agents in telecom environments. Tele-LLM-Hub actualizes TeleMCP through a low-code interface that supports agent creation, workflow composition, and interaction with software stacks such as srsRAN. Key components include a direct chat interface, a repository of pre-built systems, an Agent Maker leveraging finetuning with our RANSTRUCT framework, and an MA-Maker for composing MA workflows. The goal of Tele-LLM-Hub is to democratize the design of contextaware MA systems and accelerate innovation in next-generation wireless networks.
AI5GTest: AI-Driven Specification-Aware Automated Testing and Validation of 5G O-RAN Components
Jun 11, 2025The advent of Open Radio Access Networks (O-RAN) has transformed the telecommunications industry by promoting interoperability, vendor diversity, and rapid innovation. However, its disaggregated architecture introduces complex testing challenges, particularly in validating multi-vendor components against O-RAN ALLIANCE and 3GPP specifications. Existing frameworks, such as those provided by Open Testing and Integration Centres (OTICs), rely heavily on manual processes, are fragmented and prone to human error, leading to inconsistency and scalability issues. To address these limitations, we present AI5GTest -- an AI-powered, specification-aware testing framework designed to automate the validation of O-RAN components. AI5GTest leverages a cooperative Large Language Models (LLM) framework consisting of Gen-LLM, Val-LLM, and Debug-LLM. Gen-LLM automatically generates expected procedural flows for test cases based on 3GPP and O-RAN specifications, while Val-LLM cross-references signaling messages against these flows to validate compliance and detect deviations. If anomalies arise, Debug-LLM performs root cause analysis, providing insight to the failure cause. To enhance transparency and trustworthiness, AI5GTest incorporates a human-in-the-loop mechanism, where the Gen-LLM presents top-k relevant official specifications to the tester for approval before proceeding with validation. Evaluated using a range of test cases obtained from O-RAN TIFG and WG5-IOT test specifications, AI5GTest demonstrates a significant reduction in overall test execution time compared to traditional manual methods, while maintaining high validation accuracy.
Deep Learning based Fast and Accurate Beamforming for Millimeter-Wave Systems
Sep 19, 2023The widespread proliferation of mmW devices has led to a surge of interest in antenna arrays. This interest in arrays is due to their ability to steer beams in desired directions, for the purpose of increasing signal-power and/or decreasing interference levels. To enable beamforming, array coefficients are typically stored in look-up tables (LUTs) for subsequent referencing. While LUTs enable fast sweep times, their limited memory size restricts the number of beams the array can produce. Consequently, a receiver is likely to be offset from the main beam, thus decreasing received power, and resulting in sub-optimal performance. In this letter, we present BeamShaper, a deep neural network (DNN) framework, which enables fast and accurate beamsteering in any desirable 3-D direction. Unlike traditional finite-memory LUTs which support a fixed set of beams, BeamShaper utilizes a trained NN model to generate the array coefficients for arbitrary directions in \textit{real-time}. Our simulations show that BeamShaper outperforms contemporary LUT based solutions in terms of cosine-similarity and central angle in time scales that are slightly higher than LUT based solutions. Additionally, we show that our DNN based approach has the added advantage of being more resilient to the effects of quantization noise generated while using digital phase-shifters.
Experimental Study of Adversarial Attacks on ML-based xApps in O-RAN
Sep 07, 2023Open Radio Access Network (O-RAN) is considered as a major step in the evolution of next-generation cellular networks given its support for open interfaces and utilization of artificial intelligence (AI) into the deployment, operation, and maintenance of RAN. However, due to the openness of the O-RAN architecture, such AI models are inherently vulnerable to various adversarial machine learning (ML) attacks, i.e., adversarial attacks which correspond to slight manipulation of the input to the ML model. In this work, we showcase the vulnerability of an example ML model used in O-RAN, and experimentally deploy it in the near-real time (near-RT) RAN intelligent controller (RIC). Our ML-based interference classifier xApp (extensible application in near-RT RIC) tries to classify the type of interference to mitigate the interference effect on the O-RAN system. We demonstrate the first-ever scenario of how such an xApp can be impacted through an adversarial attack by manipulating the data stored in a shared database inside the near-RT RIC. Through a rigorous performance analysis deployed on a laboratory O-RAN testbed, we evaluate the performance in terms of capacity and the prediction accuracy of the interference classifier xApp using both clean and perturbed data. We show that even small adversarial attacks can significantly decrease the accuracy of ML application in near-RT RIC, which can directly impact the performance of the entire O-RAN deployment.
Interference Suppression Using Deep Learning: Current Approaches and Open Challenges
Dec 16, 2021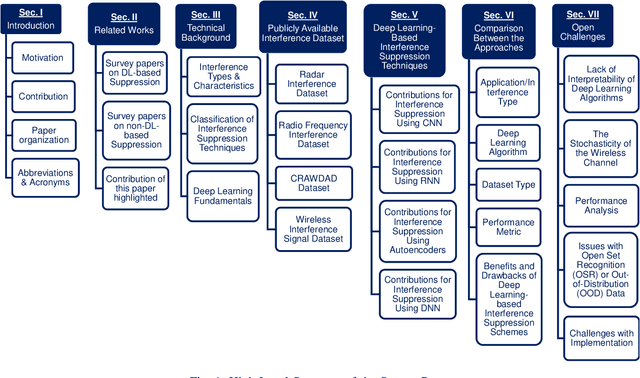
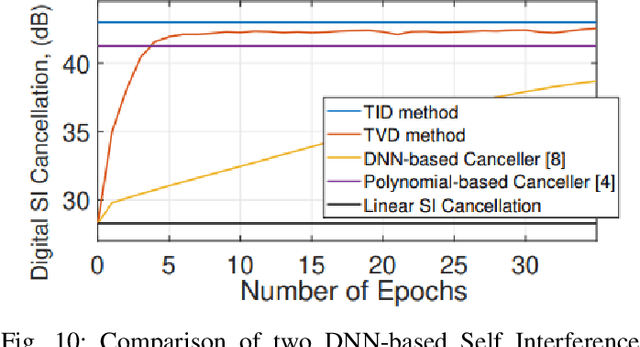
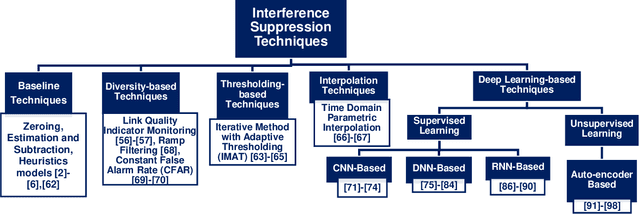
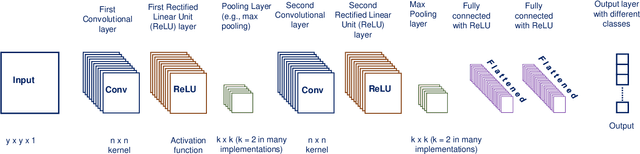
In light of the finite nature of the wireless spectrum and the increasing demand for spectrum use arising from recent technological breakthroughs in wireless communication, the problem of interference continues to persist. Despite recent advancements in resolving interference issues, interference still presents a difficult challenge to effective usage of the spectrum. This is partly due to the rise in the use of license-free and managed shared bands for Wi-Fi, long term evolution (LTE) unlicensed (LTE-U), LTE licensed assisted access (LAA), 5G NR, and other opportunistic spectrum access solutions. As a result of this, the need for efficient spectrum usage schemes that are robust against interference has never been more important. In the past, most solutions to interference have addressed the problem by using avoidance techniques as well as non-AI mitigation approaches (for example, adaptive filters). The key downside to non-AI techniques is the need for domain expertise in the extraction or exploitation of signal features such as cyclostationarity, bandwidth and modulation of the interfering signals. More recently, researchers have successfully explored AI/ML enabled physical (PHY) layer techniques, especially deep learning which reduces or compensates for the interfering signal instead of simply avoiding it. The underlying idea of ML based approaches is to learn the interference or the interference characteristics from the data, thereby sidelining the need for domain expertise in suppressing the interference. In this paper, we review a wide range of techniques that have used deep learning to suppress interference. We provide comparison and guidelines for many different types of deep learning techniques in interference suppression. In addition, we highlight challenges and potential future research directions for the successful adoption of deep learning in interference suppression.