 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Conformal Predictions for Longitudinal Data
Oct 04, 2023
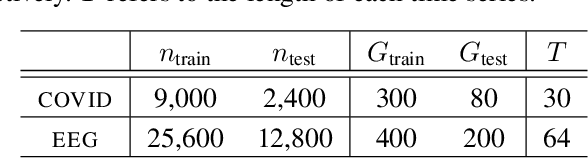
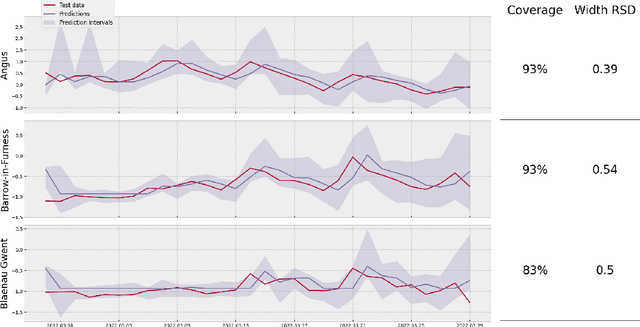

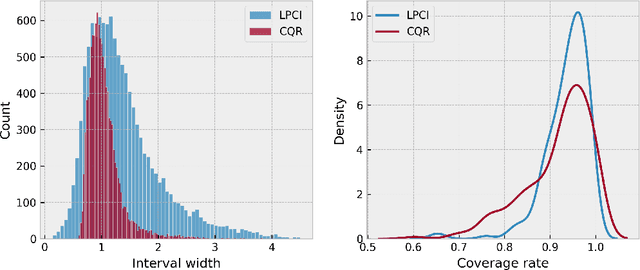
We introduce Longitudinal Predictive Conformal Inference (LPCI), a novel distribution-free conformal prediction algorithm for longitudinal data. Current conformal prediction approaches for time series data predominantly focus on the univariate setting, and thus lack cross-sectional coverage when applied individually to each time series in a longitudinal dataset. The current state-of-the-art for longitudinal data relies on creating infinitely-wide prediction intervals to guarantee both cross-sectional and asymptotic longitudinal coverage. The proposed LPCI method addresses this by ensuring that both longitudinal and cross-sectional coverages are guaranteed without resorting to infinitely wide intervals. In our approach, we model the residual data as a quantile fixed-effects regression problem, constructing prediction intervals with a trained quantile regressor. Our extensive experiments demonstrate that LPCI achieves valid cross-sectional coverage and outperforms existing benchmarks in terms of longitudinal coverage rates. Theoretically, we establish LPCI's asymptotic coverage guarantees for both dimensions, with finite-width intervals. The robust performance of LPCI in generating reliable prediction intervals for longitudinal data underscores its potential for broad applications, including in medicine, finance, and supply chain management.
R-LGP: A Reachability-guided Logic-geometric Programming Framework for Optimal Task and Motion Planning on Mobile Manipulators
Oct 04, 2023This paper presents an optimization-based solution to task and motion planning (TAMP) on mobile manipulators. Logic-geometric programming (LGP) has shown promising capabilities for optimally dealing with hybrid TAMP problems that involve abstract and geometric constraints. However, LGP does not scale well to high-dimensional systems (e.g. mobile manipulators) and can suffer from obstacle avoidance issues. In this work, we extend LGP with a sampling-based reachability graph to enable solving optimal TAMP on high-DoF mobile manipulators. The proposed reachability graph can incorporate environmental information (obstacles) to provide the planner with sufficient geometric constraints. This reachability-aware heuristic efficiently prunes infeasible sequences of actions in the continuous domain, hence, it reduces replanning by securing feasibility at the final full trajectory optimization. Our framework proves to be time-efficient in computing optimal and collision-free solutions, while outperforming the current state of the art on metrics of success rate, planning time, path length and number of steps. We validate our framework on the physical Toyota HSR robot and report comparisons on a series of mobile manipulation tasks of increasing difficulty.
Hedging Properties of Algorithmic Investment Strategies using Long Short-Term Memory and Time Series models for Equity Indices
Sep 27, 2023This paper proposes a novel approach to hedging portfolios of risky assets when financial markets are affected by financial turmoils. We introduce a completely novel approach to diversification activity not on the level of single assets but on the level of ensemble algorithmic investment strategies (AIS) built based on the prices of these assets. We employ four types of diverse theoretical models (LSTM - Long Short-Term Memory, ARIMA-GARCH - Autoregressive Integrated Moving Average - Generalized Autoregressive Conditional Heteroskedasticity, momentum, and contrarian) to generate price forecasts, which are then used to produce investment signals in single and complex AIS. In such a way, we are able to verify the diversification potential of different types of investment strategies consisting of various assets (energy commodities, precious metals, cryptocurrencies, or soft commodities) in hedging ensemble AIS built for equity indices (S&P 500 index). Empirical data used in this study cover the period between 2004 and 2022. Our main conclusion is that LSTM-based strategies outperform the other models and that the best diversifier for the AIS built for the S&P 500 index is the AIS built for Bitcoin. Finally, we test the LSTM model for a higher frequency of data (1 hour). We conclude that it outperforms the results obtained using daily data.
A Transformer-based Framework For Multi-variate Time Series: A Remaining Useful Life Prediction Use Case
Aug 19, 2023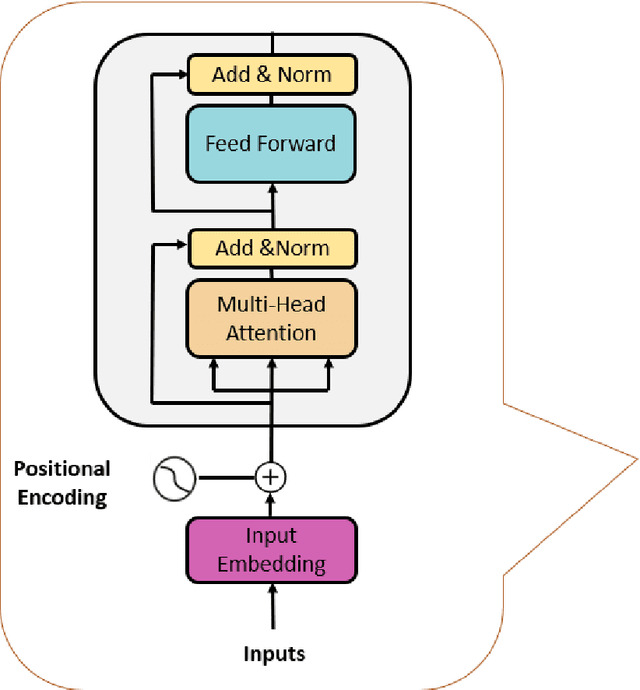

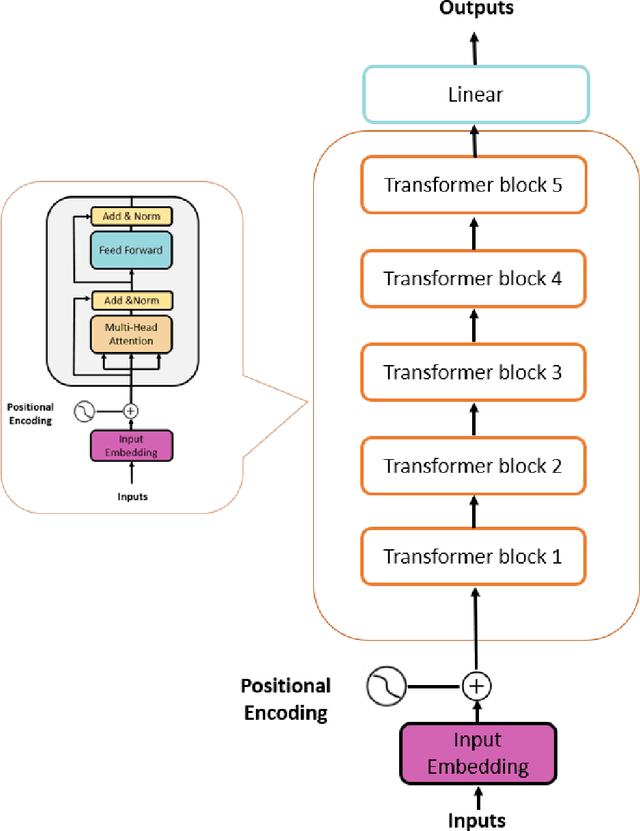

In recent times, Large Language Models (LLMs) have captured a global spotlight and revolutionized the field of Natural Language Processing. One of the factors attributed to the effectiveness of LLMs is the model architecture used for training, transformers. Transformer models excel at capturing contextual features in sequential data since time series data are sequential, transformer models can be leveraged for more efficient time series data prediction. The field of prognostics is vital to system health management and proper maintenance planning. A reliable estimation of the remaining useful life (RUL) of machines holds the potential for substantial cost savings. This includes avoiding abrupt machine failures, maximizing equipment usage, and serving as a decision support system (DSS). This work proposed an encoder-transformer architecture-based framework for multivariate time series prediction for a prognostics use case. We validated the effectiveness of the proposed framework on all four sets of the C-MAPPS benchmark dataset for the remaining useful life prediction task. To effectively transfer the knowledge and application of transformers from the natural language domain to time series, three model-specific experiments were conducted. Also, to enable the model awareness of the initial stages of the machine life and its degradation path, a novel expanding window method was proposed for the first time in this work, it was compared with the sliding window method, and it led to a large improvement in the performance of the encoder transformer model. Finally, the performance of the proposed encoder-transformer model was evaluated on the test dataset and compared with the results from 13 other state-of-the-art (SOTA) models in the literature and it outperformed them all with an average performance increase of 137.65% over the next best model across all the datasets.
Follow Anything: Open-set detection, tracking, and following in real-time
Aug 10, 2023



Tracking and following objects of interest is critical to several robotics use cases, ranging from industrial automation to logistics and warehousing, to healthcare and security. In this paper, we present a robotic system to detect, track, and follow any object in real-time. Our approach, dubbed ``follow anything'' (FAn), is an open-vocabulary and multimodal model -- it is not restricted to concepts seen at training time and can be applied to novel classes at inference time using text, images, or click queries. Leveraging rich visual descriptors from large-scale pre-trained models (foundation models), FAn can detect and segment objects by matching multimodal queries (text, images, clicks) against an input image sequence. These detected and segmented objects are tracked across image frames, all while accounting for occlusion and object re-emergence. We demonstrate FAn on a real-world robotic system (a micro aerial vehicle) and report its ability to seamlessly follow the objects of interest in a real-time control loop. FAn can be deployed on a laptop with a lightweight (6-8 GB) graphics card, achieving a throughput of 6-20 frames per second. To enable rapid adoption, deployment, and extensibility, we open-source all our code on our project webpage at https://github.com/alaamaalouf/FollowAnything . We also encourage the reader the watch our 5-minutes explainer video in this https://www.youtube.com/watch?v=6Mgt3EPytrw .
Generalized Benders Decomposition with Continual Learning for Hybrid Model Predictive Control in Dynamic Environment
Oct 10, 2023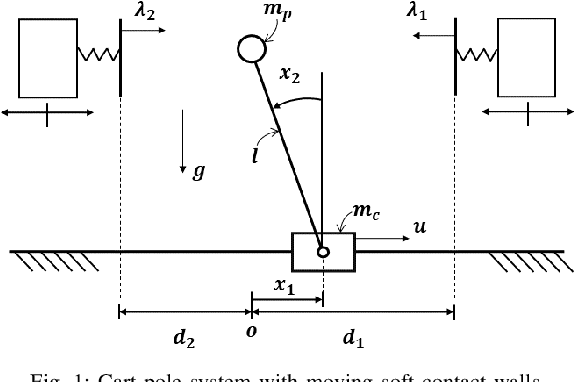
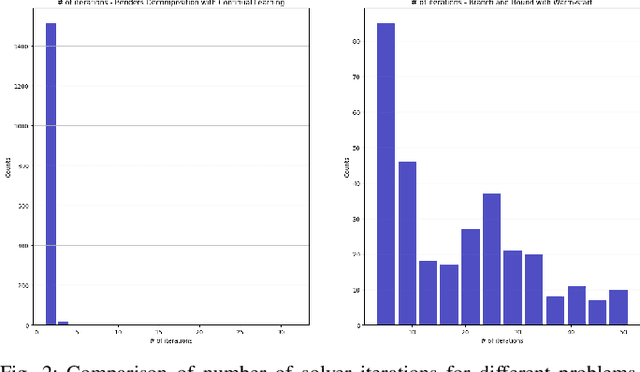
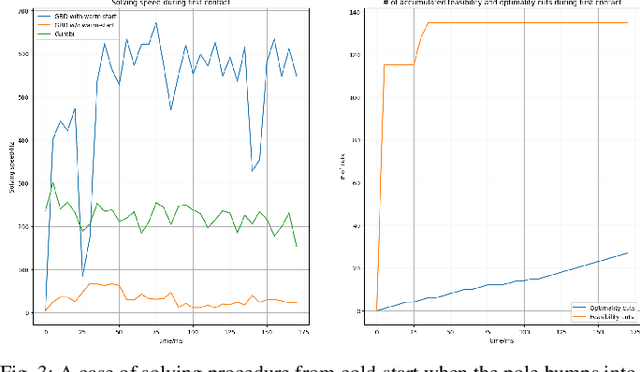
Hybrid model predictive control (MPC) with both continuous and discrete variables is widely applicable to robotic control tasks, especially those involving contact with the environment. Due to the combinatorial complexity, the solving speed of hybrid MPC can be insufficient for real-time applications. In this paper, we proposed a hybrid MPC solver based on Generalized Benders Decomposition (GBD) with continual learning. The algorithm accumulates cutting planes from the invariant dual space of the subproblems. After a short cold-start phase, the accumulated cuts provide warm-starts for the new problem instances to increase the solving speed. Despite the randomly changing environment that the control is unprepared for, the solving speed maintains. We verified our solver on controlling a cart-pole system with randomly moving soft contact walls and show that the solving speed is 2-3 times faster than the off-the-shelf solver Gurobi.
Precise Payload Delivery via Unmanned Aerial Vehicles: An Approach Using Object Detection Algorithms
Oct 10, 2023Recent years have seen tremendous advancements in the area of autonomous payload delivery via unmanned aerial vehicles, or drones. However, most of these works involve delivering the payload at a predetermined location using its GPS coordinates. By relying on GPS coordinates for navigation, the precision of payload delivery is restricted to the accuracy of the GPS network and the availability and strength of the GPS connection, which may be severely restricted by the weather condition at the time and place of operation. In this work we describe the development of a micro-class UAV and propose a novel navigation method that improves the accuracy of conventional navigation methods by incorporating a deep-learning-based computer vision approach to identify and precisely align the UAV with a target marked at the payload delivery position. This proposed method achieves a 500% increase in average horizontal precision over conventional GPS-based approaches.
Suppressing Overestimation in Q-Learning through Adversarial Behaviors
Oct 10, 2023
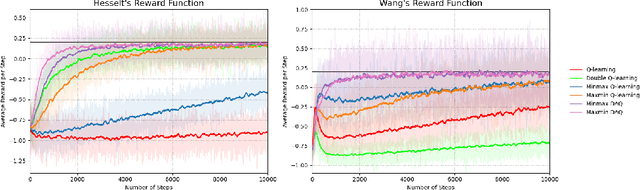
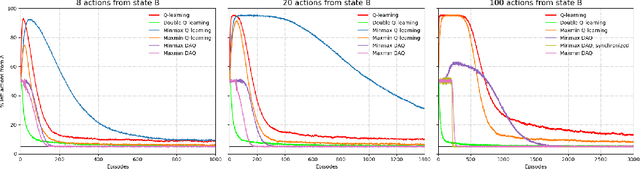
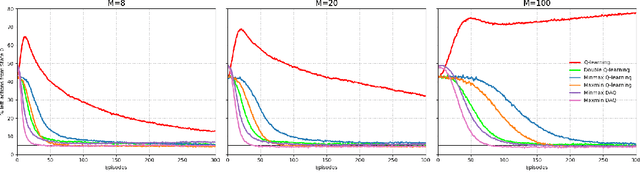
The goal of this paper is to propose a new Q-learning algorithm with a dummy adversarial player, which is called dummy adversarial Q-learning (DAQ), that can effectively regulate the overestimation bias in standard Q-learning. With the dummy player, the learning can be formulated as a two-player zero-sum game. The proposed DAQ unifies several Q-learning variations to control overestimation biases, such as maxmin Q-learning and minmax Q-learning (proposed in this paper) in a single framework. The proposed DAQ is a simple but effective way to suppress the overestimation bias thourgh dummy adversarial behaviors and can be easily applied to off-the-shelf reinforcement learning algorithms to improve the performances. A finite-time convergence of DAQ is analyzed from an integrated perspective by adapting an adversarial Q-learning. The performance of the suggested DAQ is empirically demonstrated under various benchmark environments.
Comparing the robustness of modern no-reference image- and video-quality metrics to adversarial attacks
Oct 10, 2023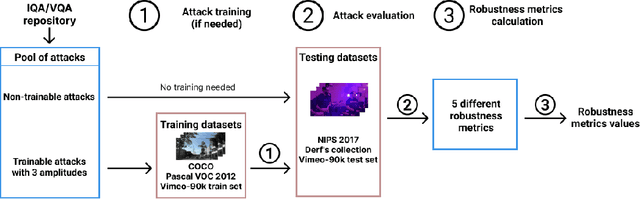
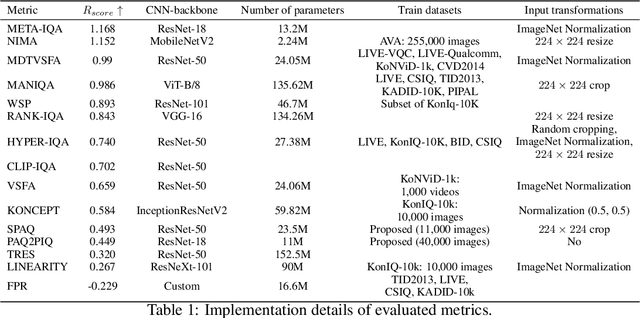
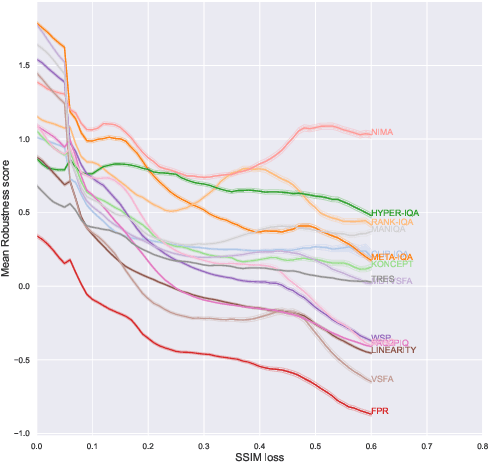
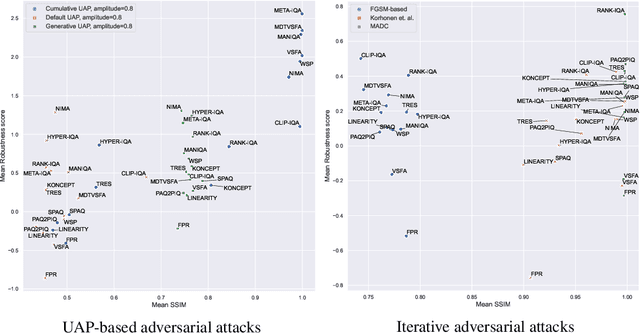
Nowadays neural-network-based image- and video-quality metrics show better performance compared to traditional methods. However, they also became more vulnerable to adversarial attacks that increase metrics' scores without improving visual quality. The existing benchmarks of quality metrics compare their performance in terms of correlation with subjective quality and calculation time. However, the adversarial robustness of image-quality metrics is also an area worth researching. In this paper, we analyse modern metrics' robustness to different adversarial attacks. We adopted adversarial attacks from computer vision tasks and compared attacks' efficiency against 15 no-reference image/video-quality metrics. Some metrics showed high resistance to adversarial attacks which makes their usage in benchmarks safer than vulnerable metrics. The benchmark accepts new metrics submissions for researchers who want to make their metrics more robust to attacks or to find such metrics for their needs. Try our benchmark using pip install robustness-benchmark.
QUANT: A Minimalist Interval Method for Time Series Classification
Aug 02, 2023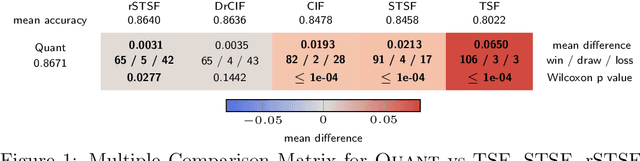
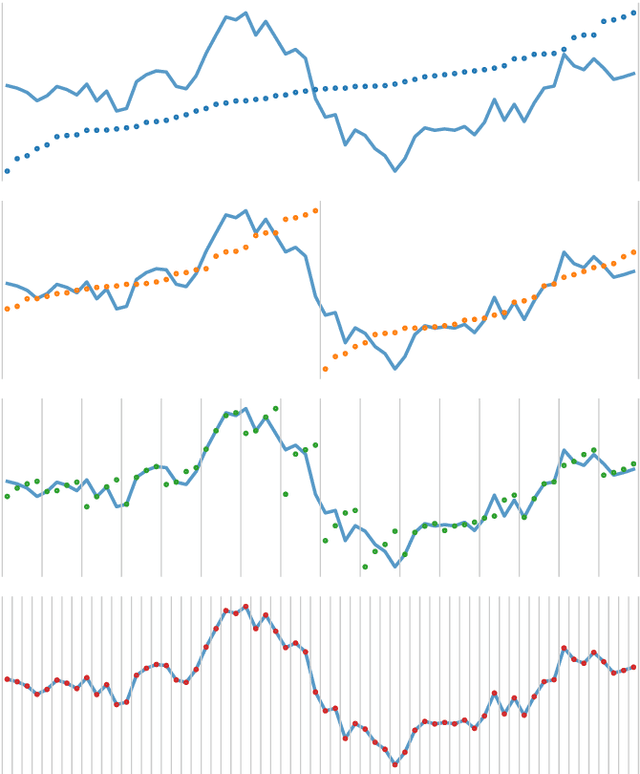
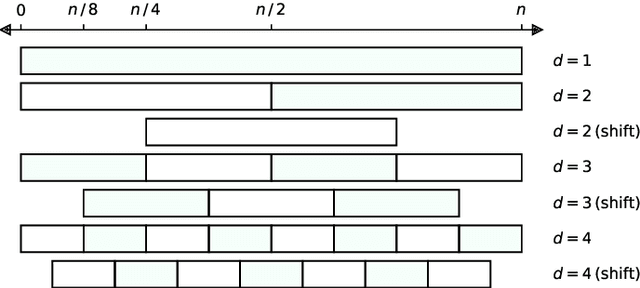
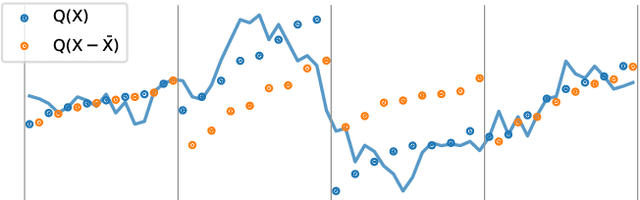
We show that it is possible to achieve the same accuracy, on average, as the most accurate existing interval methods for time series classification on a standard set of benchmark datasets using a single type of feature (quantiles), fixed intervals, and an 'off the shelf' classifier. This distillation of interval-based approaches represents a fast and accurate method for time series classification, achieving state-of-the-art accuracy on the expanded set of 142 datasets in the UCR archive with a total compute time (training and inference) of less than 15 minutes using a single CPU core.