 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Text-Guided Texturing by Synchronized Multi-View Diffusion
Nov 21, 2023
This paper introduces a novel approach to synthesize texture to dress up a given 3D object, given a text prompt. Based on the pretrained text-to-image (T2I) diffusion model, existing methods usually employ a project-and-inpaint approach, in which a view of the given object is first generated and warped to another view for inpainting. But it tends to generate inconsistent texture due to the asynchronous diffusion of multiple views. We believe such asynchronous diffusion and insufficient information sharing among views are the root causes of the inconsistent artifact. In this paper, we propose a synchronized multi-view diffusion approach that allows the diffusion processes from different views to reach a consensus of the generated content early in the process, and hence ensures the texture consistency. To synchronize the diffusion, we share the denoised content among different views in each denoising step, specifically blending the latent content in the texture domain from views with overlap. Our method demonstrates superior performance in generating consistent, seamless, highly detailed textures, comparing to state-of-the-art methods.
Towards a more inductive world for drug repurposing approaches
Nov 21, 2023Drug-target interaction (DTI) prediction is a challenging, albeit essential task in drug repurposing. Learning on graph models have drawn special attention as they can significantly reduce drug repurposing costs and time commitment. However, many current approaches require high-demanding additional information besides DTIs that complicates their evaluation process and usability. Additionally, structural differences in the learning architecture of current models hinder their fair benchmarking. In this work, we first perform an in-depth evaluation of current DTI datasets and prediction models through a robust benchmarking process, and show that DTI prediction methods based on transductive models lack generalization and lead to inflated performance when evaluated as previously done in the literature, hence not being suited for drug repurposing approaches. We then propose a novel biologically-driven strategy for negative edge subsampling and show through in vitro validation that newly discovered interactions are indeed true. We envision this work as the underpinning for future fair benchmarking and robust model design. All generated resources and tools are publicly available as a python package.
Unveiling Public Perceptions: Machine Learning-Based Sentiment Analysis of COVID-19 Vaccines in India
Nov 19, 2023In March 2020, the World Health Organisation declared COVID-19 a global pandemic as it spread to nearly every country. By mid-2021, India had introduced three vaccines: Covishield, Covaxin, and Sputnik. To ensure successful vaccination in a densely populated country like India, understanding public sentiment was crucial. Social media, particularly Reddit with over 430 million users, played a vital role in disseminating information. This study employs data mining techniques to analyze Reddit data and gauge Indian sentiments towards COVID-19 vaccines. Using Python's Text Blob library, comments are annotated to assess general sentiments. Results show that most Reddit users in India expressed neutrality about vaccination, posing a challenge for the Indian government's efforts to vaccinate a significant portion of the population.
Implementation of AI Deep Learning Algorithm For Multi-Modal Sentiment Analysis
Nov 19, 2023A multi-modal emotion recognition method was established by combining two-channel convolutional neural network with ring network. This method can extract emotional information effectively and improve learning efficiency. The words were vectorized with GloVe, and the word vector was input into the convolutional neural network. Combining attention mechanism and maximum pool converter BiSRU channel, the local deep emotion and pre-post sequential emotion semantics are obtained. Finally, multiple features are fused and input as the polarity of emotion, so as to achieve the emotion analysis of the target. Experiments show that the emotion analysis method based on feature fusion can effectively improve the recognition accuracy of emotion data set and reduce the learning time. The model has a certain generalization.
3D Guidewire Shape Reconstruction from Monoplane Fluoroscopic Images
Nov 19, 2023Endovascular navigation, essential for diagnosing and treating endovascular diseases, predominantly hinges on fluoroscopic images due to the constraints in sensory feedback. Current shape reconstruction techniques for endovascular intervention often rely on either a priori information or specialized equipment, potentially subjecting patients to heightened radiation exposure. While deep learning holds potential, it typically demands extensive data. In this paper, we propose a new method to reconstruct the 3D guidewire by utilizing CathSim, a state-of-the-art endovascular simulator, and a 3D Fluoroscopy Guidewire Reconstruction Network (3D-FGRN). Our 3D-FGRN delivers results on par with conventional triangulation from simulated monoplane fluoroscopic images. Our experiments accentuate the efficiency of the proposed network, demonstrating it as a promising alternative to traditional methods.
TCuPGAN: A novel framework developed for optimizing human-machine interactions in citizen science
Nov 23, 2023In the era of big data in scientific research, there is a necessity to leverage techniques which reduce human effort in labeling and categorizing large datasets by involving sophisticated machine tools. To combat this problem, we present a novel, general purpose model for 3D segmentation that leverages patch-wise adversariality and Long Short-Term Memory to encode sequential information. Using this model alongside citizen science projects which use 3D datasets (image cubes) on the Zooniverse platforms, we propose an iterative human-machine optimization framework where only a fraction of the 2D slices from these cubes are seen by the volunteers. We leverage the patch-wise discriminator in our model to provide an estimate of which slices within these image cubes have poorly generalized feature representations, and correspondingly poor machine performance. These images with corresponding machine proposals would be presented to volunteers on Zooniverse for correction, leading to a drastic reduction in the volunteer effort on citizen science projects. We trained our model on ~2300 liver tissue 3D electron micrographs. Lipid droplets were segmented within these images through human annotation via the `Etch A Cell - Fat Checker' citizen science project, hosted on the Zooniverse platform. In this work, we demonstrate this framework and the selection methodology which resulted in a measured reduction in volunteer effort by more than 60%. We envision this type of joint human-machine partnership will be of great use on future Zooniverse projects.
MonoNav: MAV Navigation via Monocular Depth Estimation and Reconstruction
Nov 23, 2023A major challenge in deploying the smallest of Micro Aerial Vehicle (MAV) platforms (< 100 g) is their inability to carry sensors that provide high-resolution metric depth information (e.g., LiDAR or stereo cameras). Current systems rely on end-to-end learning or heuristic approaches that directly map images to control inputs, and struggle to fly fast in unknown environments. In this work, we ask the following question: using only a monocular camera, optical odometry, and offboard computation, can we create metrically accurate maps to leverage the powerful path planning and navigation approaches employed by larger state-of-the-art robotic systems to achieve robust autonomy in unknown environments? We present MonoNav: a fast 3D reconstruction and navigation stack for MAVs that leverages recent advances in depth prediction neural networks to enable metrically accurate 3D scene reconstruction from a stream of monocular images and poses. MonoNav uses off-the-shelf pre-trained monocular depth estimation and fusion techniques to construct a map, then searches over motion primitives to plan a collision-free trajectory to the goal. In extensive hardware experiments, we demonstrate how MonoNav enables the Crazyflie (a 37 g MAV) to navigate fast (0.5 m/s) in cluttered indoor environments. We evaluate MonoNav against a state-of-the-art end-to-end approach, and find that the collision rate in navigation is significantly reduced (by a factor of 4). This increased safety comes at the cost of conservatism in terms of a 22% reduction in goal completion.
ChiMed-GPT: A Chinese Medical Large Language Model with Full Training Regime and Better Alignment to Human Preferences
Nov 23, 2023
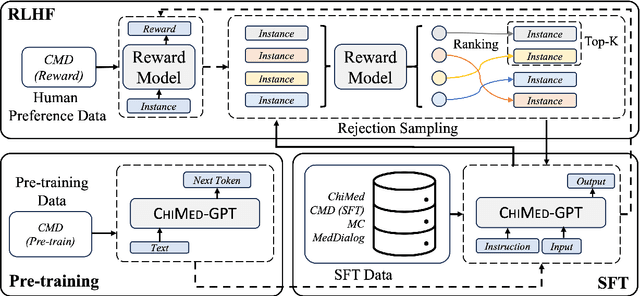

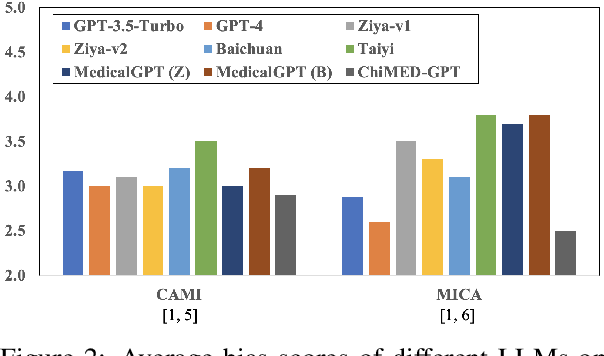
Recently, the increasing demand for superior medical services has highlighted the discrepancies in the medical infrastructure. With big data, especially texts, forming the foundation of medical services, there is an exigent need for effective natural language processing (NLP) solutions tailored to the healthcare domain. Conventional approaches leveraging pre-trained models present promising results in this domain and current large language models (LLMs) offer advanced foundation for medical text processing. However, most medical LLMs are trained only with supervised fine-tuning (SFT), even though it efficiently empowers LLMs to understand and respond to medical instructions but is ineffective in learning domain knowledge and aligning with human preference. Another engineering barrier that prevents current medical LLM from better text processing ability is their restricted context length (e.g., 2,048 tokens), making it hard for the LLMs to process long context, which is frequently required in the medical domain. In this work, we propose ChiMed-GPT, a new benchmark LLM designed explicitly for Chinese medical domain, with enlarged context length to 4,096 tokens and undergoes a comprehensive training regime with pre-training, SFT, and RLHF. Evaluations on real-world tasks including information extraction, question answering, and dialogue generation demonstrate ChiMed-GPT's superior performance over general domain LLMs. Furthermore, we analyze possible biases through prompting ChiMed-GPT to perform attitude scales regarding discrimination of patients, so as to contribute to further responsible development of LLMs in the medical domain. The code and model are released at https://github.com/synlp/ChiMed-GPT.
Comparison of model selection techniques for seafloor scattering statistics
Nov 14, 2023In quantitative analysis of seafloor imagery, it is common to model the collection of individual pixel intensities scattered by the seafloor as a random variable with a given statistical distribution. There is a considerable literature on statistical models for seafloor scattering, mostly focused on areas with statistically homogeneous properties (i.e. exhibiting spatial stationarity). For more complex seafloors, the pixel intensity distribution is more appropriately modeled using a mixture of simple distributions. For very complex seafloors, fitting 3 or more mixture components makes physical sense, but the statistical model becomes much more complex in these cases. Therefore, picking the number of components of the mixture model is a decision that must be made, using a priori information, or using a data driven approach. However, this information is time consuming to collect, and depends on the skill and experience of the human. Therefore, a data-driven approach is advantageous to use, and is explored in this work. Criteria for choosing a model always need to balance the trade-off for the best fit for the data on the one hand and the model complexity on the other hand. In this work, we compare several statistical model selection criteria, e.g., the Bayesian information criterion. Examples are given for SAS data collected by an autonomous underwater vehicle in a rocky environment off the coast of Bergen, Norway using data from the HISAS-1032 synthetic aperture sonar system.
Explicit Change Relation Learning for Change Detection in VHR Remote Sensing Images
Nov 14, 2023Change detection has always been a concerned task in the interpretation of remote sensing images. It is essentially a unique binary classification task with two inputs, and there is a change relationship between these two inputs. At present, the mining of change relationship features is usually implicit in the network architectures that contain single-branch or two-branch encoders. However, due to the lack of artificial prior design for change relationship features, these networks cannot learn enough change semantic information and lose more accurate change detection performance. So we propose a network architecture NAME for the explicit mining of change relation features. In our opinion, the change features of change detection should be divided into pre-changed image features, post-changed image features and change relation features. In order to fully mine these three kinds of change features, we propose the triple branch network combining the transformer and convolutional neural network (CNN) to extract and fuse these change features from two perspectives of global information and local information, respectively. In addition, we design the continuous change relation (CCR) branch to further obtain the continuous and detail change relation features to improve the change discrimination capability of the model. The experimental results show that our network performs better, in terms of F1, IoU, and OA, than those of the existing advanced networks for change detection on four public very high-resolution (VHR) remote sensing datasets. Our source code is available at https://github.com/DalongZ/NAME.