 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adversarial Attacks and Defenses for Wireless Signal Classifiers using CDI-aware GANs
Nov 30, 2023
We introduce a Channel Distribution Information (CDI)-aware Generative Adversarial Network (GAN), designed to address the unique challenges of adversarial attacks in wireless communication systems. The generator in this CDI-aware GAN maps random input noise to the feature space, generating perturbations intended to deceive a target modulation classifier. Its discriminators play a dual role: one enforces that the perturbations follow a Gaussian distribution, making them indistinguishable from Gaussian noise, while the other ensures these perturbations account for realistic channel effects and resemble no-channel perturbations. Our proposed CDI-aware GAN can be used as an attacker and a defender. In attack scenarios, the CDI-aware GAN demonstrates its prowess by generating robust adversarial perturbations that effectively deceive the target classifier, outperforming known methods. Furthermore, CDI-aware GAN as a defender significantly improves the target classifier's resilience against adversarial attacks.
ElasticDiffusion: Training-free Arbitrary Size Image Generation
Nov 30, 2023Diffusion models have revolutionized image generation in recent years, yet they are still limited to a few sizes and aspect ratios. We propose ElasticDiffusion, a novel training-free decoding method that enables pretrained text-to-image diffusion models to generate images with various sizes. ElasticDiffusion attempts to decouple the generation trajectory of a pretrained model into local and global signals. The local signal controls low-level pixel information and can be estimated on local patches, while the global signal is used to maintain overall structural consistency and is estimated with a reference image. We test our method on CelebA-HQ (faces) and LAION-COCO (objects/indoor/outdoor scenes). Our experiments and qualitative results show superior image coherence quality across aspect ratios compared to MultiDiffusion and the standard decoding strategy of Stable Diffusion. Code: https://github.com/MoayedHajiAli/ElasticDiffusion-official.git
How to Build an AI Tutor that Can Adapt to Any Course and Provide Accurate Answers Using Large Language Model and Retrieval-Augmented Generation
Nov 30, 2023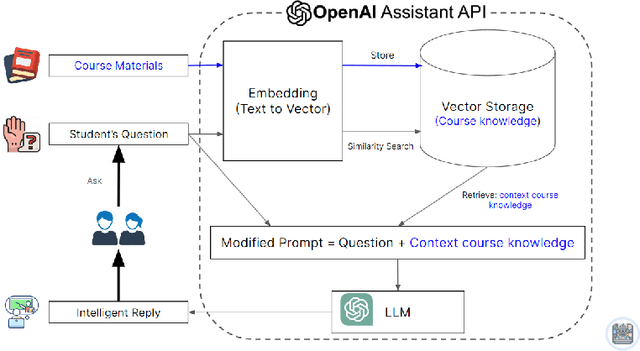
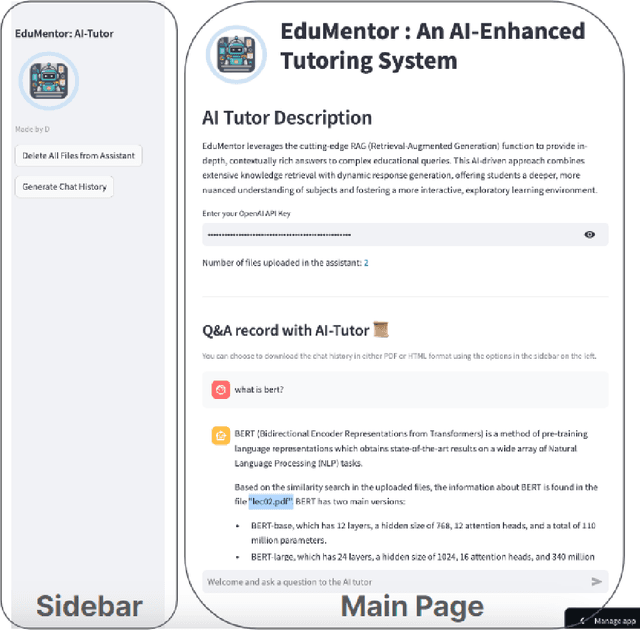
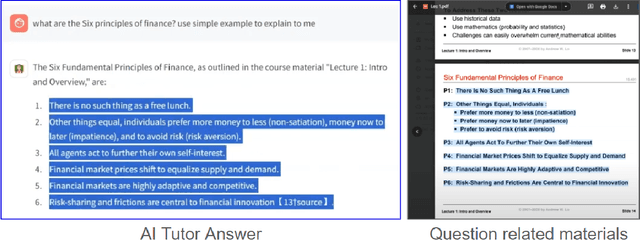
Artificial intelligence is transforming education through data-driven, personalized learning solutions. This paper introduces AI Tutor, an innovative web application that provides personalized tutoring in any subject using state-of-the-art Large Language Model (LLM). AI Tutor ingests course materials to construct an adaptive knowledge base tailored to the course. When students pose questions, it retrieves the most relevant information and generates detailed, conversational responses citing supporting evidence. The system is powered by advanced large language models and Retrieval-Augmented Generation (RAG) techniques for accurate, natural question answering. We present a fully-functional web interface and video demonstration that showcase AI Tutor's versatility across diverse subjects and its ability to produce pedagogically cogent responses. While an initial prototype, this work represents a pioneering step toward AI-enabled tutoring systems that can democratize access to high-quality, customized educational support.
Mavericks at ArAIEval Shared Task: Towards a Safer Digital Space -- Transformer Ensemble Models Tackling Deception and Persuasion
Nov 30, 2023In this paper, we highlight our approach for the "Arabic AI Tasks Evaluation (ArAiEval) Shared Task 2023". We present our approaches for task 1-A and task 2-A of the shared task which focus on persuasion technique detection and disinformation detection respectively. Detection of persuasion techniques and disinformation has become imperative to avoid distortion of authentic information. The tasks use multigenre snippets of tweets and news articles for the given binary classification problem. We experiment with several transformer-based models that were pre-trained on the Arabic language. We fine-tune these state-of-the-art models on the provided dataset. Ensembling is employed to enhance the performance of the systems. We achieved a micro F1-score of 0.742 on task 1-A (8th rank on the leaderboard) and 0.901 on task 2-A (7th rank on the leaderboard) respectively.
Measuring Pointwise $\mathcal{V}$-Usable Information In-Context-ly
Oct 18, 2023In-context learning (ICL) is a new learning paradigm that has gained popularity along with the development of large language models. In this work, we adapt a recently proposed hardness metric, pointwise $\mathcal{V}$-usable information (PVI), to an in-context version (in-context PVI). Compared to the original PVI, in-context PVI is more efficient in that it requires only a few exemplars and does not require fine-tuning. We conducted a comprehensive empirical analysis to evaluate the reliability of in-context PVI. Our findings indicate that in-context PVI estimates exhibit similar characteristics to the original PVI. Specific to the in-context setting, we show that in-context PVI estimates remain consistent across different exemplar selections and numbers of shots. The variance of in-context PVI estimates across different exemplar selections is insignificant, which suggests that in-context PVI are stable. Furthermore, we demonstrate how in-context PVI can be employed to identify challenging instances. Our work highlights the potential of in-context PVI and provides new insights into the capabilities of ICL.
Learning to Compose SuperWeights for Neural Parameter Allocation Search
Dec 03, 2023Neural parameter allocation search (NPAS) automates parameter sharing by obtaining weights for a network given an arbitrary, fixed parameter budget. Prior work has two major drawbacks we aim to address. First, there is a disconnect in the sharing pattern between the search and training steps, where weights are warped for layers of different sizes during the search to measure similarity, but not during training, resulting in reduced performance. To address this, we generate layer weights by learning to compose sets of SuperWeights, which represent a group of trainable parameters. These SuperWeights are created to be large enough so they can be used to represent any layer in the network, but small enough that they are computationally efficient. The second drawback we address is the method of measuring similarity between shared parameters. Whereas prior work compared the weights themselves, we argue this does not take into account the amount of conflict between the shared weights. Instead, we use gradient information to identify layers with shared weights that wish to diverge from each other. We demonstrate that our SuperWeight Networks consistently boost performance over the state-of-the-art on the ImageNet and CIFAR datasets in the NPAS setting. We further show that our approach can generate parameters for many network architectures using the same set of weights. This enables us to support tasks like efficient ensembling and anytime prediction, outperforming fully-parameterized ensembles with 17% fewer parameters.
Graph Coordinates and Conventional Neural Networks -- An Alternative for Graph Neural Networks
Dec 03, 2023Graph-based data present unique challenges and opportunities for machine learning. Graph Neural Networks (GNNs), and especially those algorithms that capture graph topology through message passing for neighborhood aggregation, have been a leading solution. However, these networks often require substantial computational resources and may not optimally leverage the information contained in the graph's topology, particularly for large-scale or complex graphs. We propose Topology Coordinate Neural Network (TCNN) and Directional Virtual Coordinate Neural Network (DVCNN) as novel and efficient alternatives to message passing GNNs, that directly leverage the graph's topology, sidestepping the computational challenges presented by competing algorithms. Our proposed methods can be viewed as a reprise of classic techniques for graph embedding for neural network feature engineering, but they are novel in that our embedding techniques leverage ideas in Graph Coordinates (GC) that are lacking in current practice. Experimental results, benchmarked against the Open Graph Benchmark Leaderboard, demonstrate that TCNN and DVCNN achieve competitive or superior performance to message passing GNNs. For similar levels of accuracy and ROC-AUC, TCNN and DVCNN need far fewer trainable parameters than contenders of the OGBN Leaderboard. The proposed TCNN architecture requires fewer parameters than any neural network method currently listed in the OGBN Leaderboard for both OGBN-Proteins and OGBN-Products datasets. Conversely, our methods achieve higher performance for a similar number of trainable parameters. By providing an efficient and effective alternative to message passing GNNs, our work expands the toolbox of techniques for graph-based machine learning.
Hide Your Model: A Parameter Transmission-free Federated Recommender System
Nov 28, 2023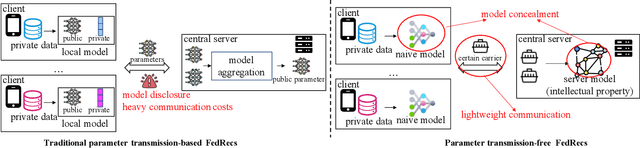


With the growing concerns regarding user data privacy, Federated Recommender System (FedRec) has garnered significant attention recently due to its privacy-preserving capabilities. Existing FedRecs generally adhere to a learning protocol in which a central server shares a global recommendation model with clients, and participants achieve collaborative learning by frequently communicating the model's public parameters. Nevertheless, this learning framework has two drawbacks that limit its practical usability: (1) It necessitates a global-sharing recommendation model; however, in real-world scenarios, information related to the recommender model, including its algorithm and parameters, constitutes the platforms' intellectual property. Hence, service providers are unlikely to release such information actively. (2) The communication costs of model parameter transmission are expensive since the model parameters are usually high-dimensional matrices. With the model size increasing, the communication burden will be the bottleneck for such traditional FedRecs. Given the above limitations, this paper introduces a novel parameter transmission-free federated recommendation framework that balances the protection between users' data privacy and platforms' model privacy, namely PTF-FedRec. Specifically, participants in PTF-FedRec collaboratively exchange knowledge by sharing their predictions within a privacy-preserving mechanism. Through this way, the central server can learn a recommender model without disclosing its model parameters or accessing clients' raw data, preserving both the server's model privacy and users' data privacy. Besides, since clients and the central server only need to communicate prediction scores which are just a few real numbers, the overhead is significantly reduced compared to traditional FedRecs.
Virtual Fusion with Contrastive Learning for Single Sensor-based Activity Recognition
Dec 01, 2023Various types of sensors can be used for Human Activity Recognition (HAR), and each of them has different strengths and weaknesses. Sometimes a single sensor cannot fully observe the user's motions from its perspective, which causes wrong predictions. While sensor fusion provides more information for HAR, it comes with many inherent drawbacks like user privacy and acceptance, costly set-up, operation, and maintenance. To deal with this problem, we propose Virtual Fusion - a new method that takes advantage of unlabeled data from multiple time-synchronized sensors during training, but only needs one sensor for inference. Contrastive learning is adopted to exploit the correlation among sensors. Virtual Fusion gives significantly better accuracy than training with the same single sensor, and in some cases, it even surpasses actual fusion using multiple sensors at test time. We also extend this method to a more general version called Actual Fusion within Virtual Fusion (AFVF), which uses a subset of training sensors during inference. Our method achieves state-of-the-art accuracy and F1-score on UCI-HAR and PAMAP2 benchmark datasets. Implementation is available upon request.
VEXIR2Vec: An Architecture-Neutral Embedding Framework for Binary Similarity
Dec 01, 2023We propose VEXIR2Vec, a code embedding framework for finding similar functions in binaries. Our representations rely on VEX IR, the intermediate representation used by binary analysis tools like Valgrind and angr. Our proposed embeddings encode both syntactic and semantic information to represent a function, and is both application and architecture independent. We also propose POV, a custom Peephole Optimization engine that normalizes the VEX IR for effective similarity analysis. We design several optimizations like copy/constant propagation, constant folding, common subexpression elimination and load-store elimination in POV. We evaluate our framework on two experiments -- diffing and searching -- involving binaries targeting different architectures, compiled using different compilers and versions, optimization sequences, and obfuscations. We show results on several standard projects and on real-world vulnerabilities. Our results show that VEXIR2Vec achieves superior precision and recall values compared to the state-of-the-art works. Our framework is highly scalable and is built as a multi-threaded, parallel library by only using open-source tools. VEXIR2Vec achieves about $3.2 \times$ speedup on the closest competitor, and orders-of-magnitude speedup on other tools.