 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CNN AE: Convolution Neural Network combined with Autoencoder approach to detect survival chance of COVID 19 patients
Apr 18, 2021
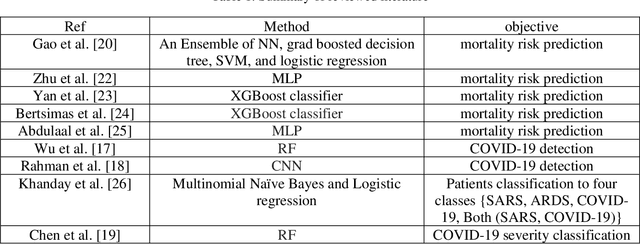
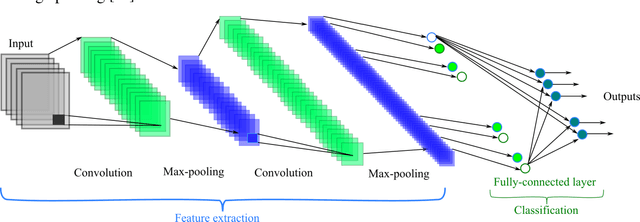
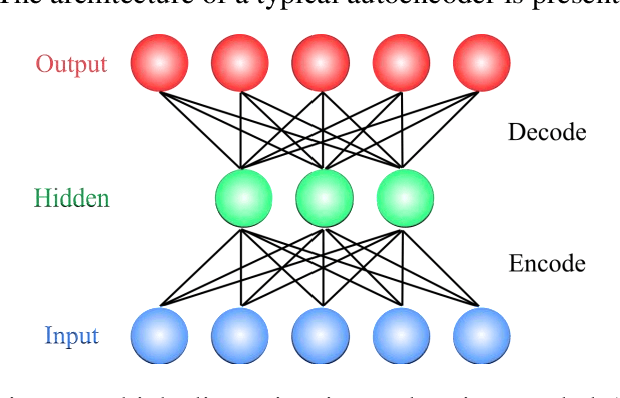
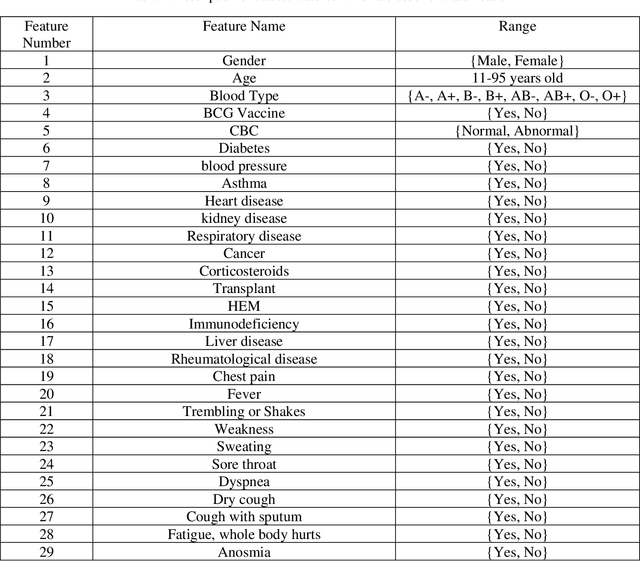
In this paper, we propose a novel method named CNN-AE to predict survival chance of COVID-19 patients using a CNN trained on clinical information. To further increase the prediction accuracy, we use the CNN in combination with an autoencoder. Our method is one of the first that aims to predict survival chance of already infected patients. We rely on clinical data to carry out the prediction. The motivation is that the required resources to prepare CT images are expensive and limited compared to the resources required to collect clinical data such as blood pressure, liver disease, etc. We evaluate our method on a publicly available clinical dataset of deceased and recovered patients which we have collected. Careful analysis of the dataset properties is also presented which consists of important features extraction and correlation computation between features. Since most of COVID-19 patients are usually recovered, the number of deceased samples of our dataset is low leading to data imbalance. To remedy this issue, a data augmentation procedure based on autoencoders is proposed. To demonstrate the generality of our augmentation method, we train random forest and Na\"ive Bayes on our dataset with and without augmentation and compare their performance. We also evaluate our method on another dataset for further generality verification. Experimental results reveal the superiority of CNN-AE method compared to the standard CNN as well as other methods such as random forest and Na\"ive Bayes. COVID-19 detection average accuracy of CNN-AE is 96.05% which is higher than CNN average accuracy of 92.49%. To show that clinical data can be used as a reliable dataset for COVID-19 survival chance prediction, CNN-AE is compared with a standard CNN which is trained on CT images.
Unavailable Transit Feed Specification: Making it Available with Recurrent Neural Networks
Feb 20, 2021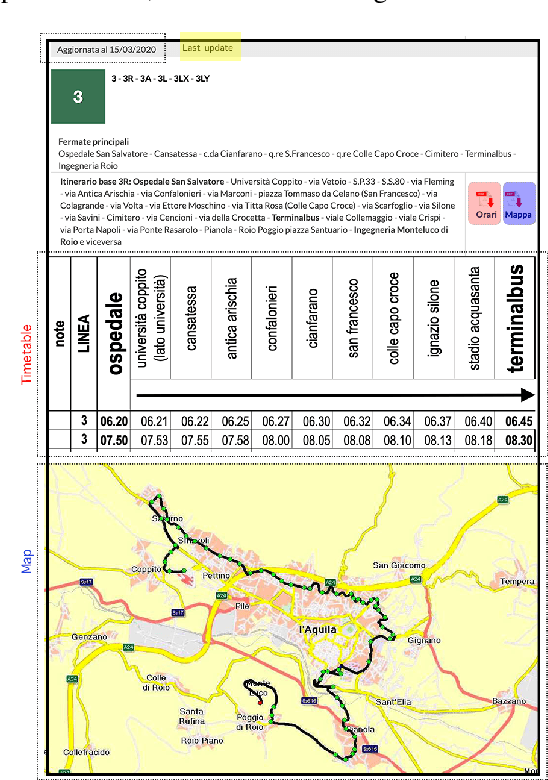
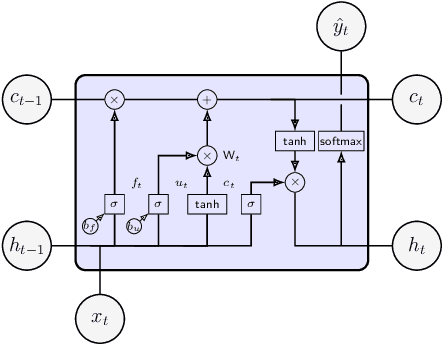
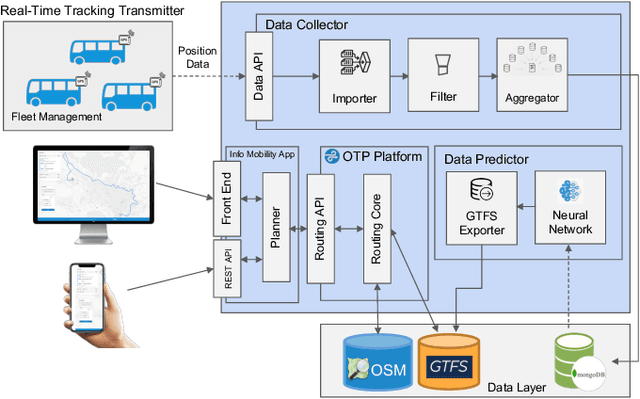
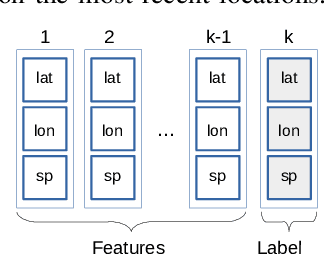
Studies on public transportation in Europe suggest that European inhabitants use buses in ca. 56% of all public transport travels. One of the critical factors affecting such a percentage and more, in general, the demand for public transport services, with an increasing reluctance to use them, is their quality. End-users can perceive quality from various perspectives, including the availability of information, i.e., the access to details about the transit and the provided services. The approach proposed in this paper, using innovative methodologies resorting on data mining and machine learning techniques, aims to make available the unavailable data about public transport. In particular, by mining GPS traces, we manage to reconstruct the complete transit graph of public transport. The approach has been successfully validated on a real dataset collected from the local bus system of the city of L'Aquila (Italy). The experimental results demonstrate that the proposed approach and implemented framework are both effective and efficient, thus being ready for deployment.
Sentimental LIAR: Extended Corpus and Deep Learning Models for Fake Claim Classification
Sep 01, 2020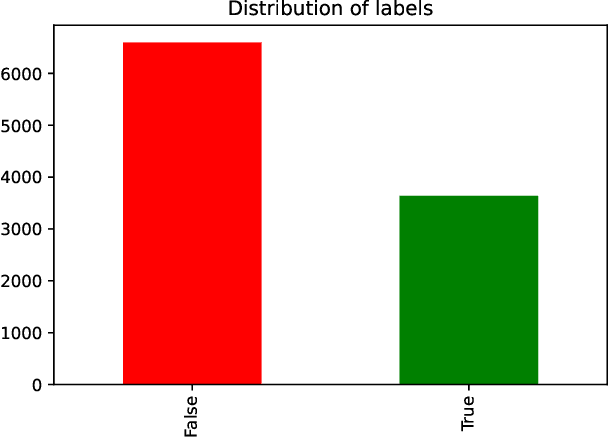
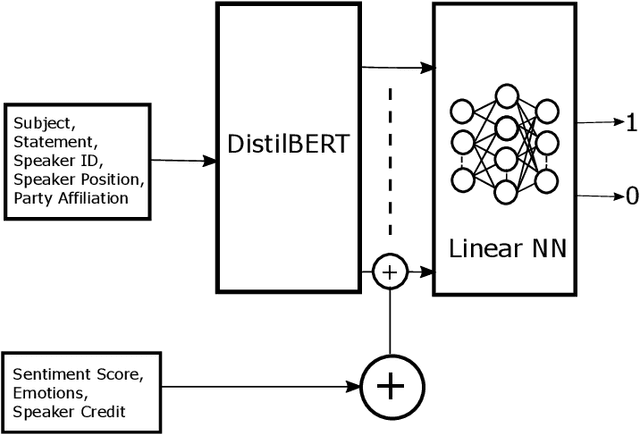
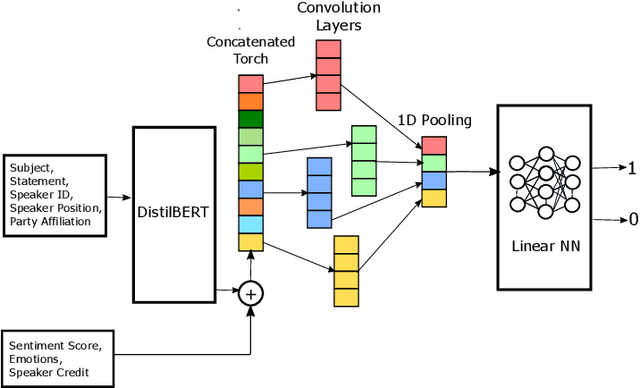
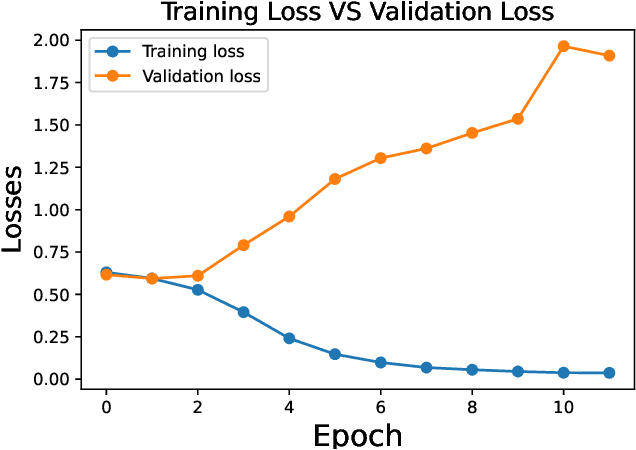
The rampant integration of social media in our every day lives and culture has given rise to fast and easier access to the flow of information than ever in human history. However, the inherently unsupervised nature of social media platforms has also made it easier to spread false information and fake news. Furthermore, the high volume and velocity of information flow in such platforms make manual supervision and control of information propagation infeasible. This paper aims to address this issue by proposing a novel deep learning approach for automated detection of false short-text claims on social media. We first introduce Sentimental LIAR, which extends the LIAR dataset of short claims by adding features based on sentiment and emotion analysis of claims. Furthermore, we propose a novel deep learning architecture based on the DistilBERT language model for classification of claims as genuine or fake. Our results demonstrate that the proposed architecture trained on Sentimental LIAR can achieve an accuracy of 70\%, which is an improvement of ~30\% over previously reported results for the LIAR benchmark.
Do We Need Sound for Sound Source Localization?
Jul 11, 2020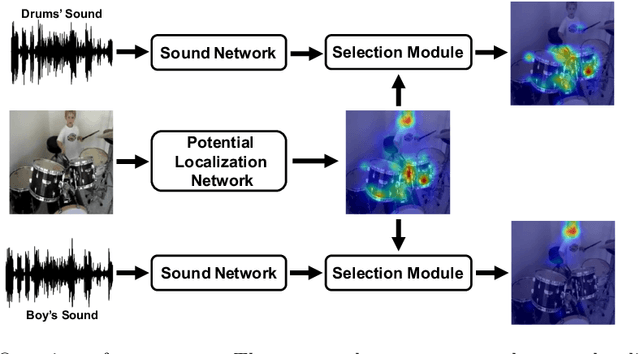
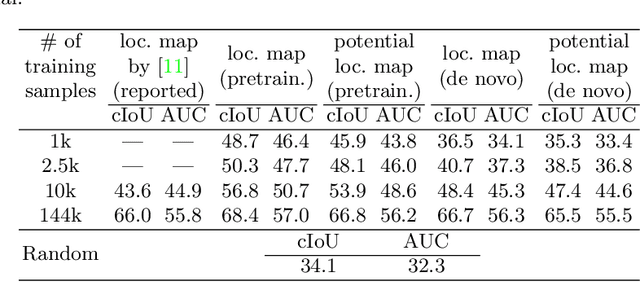


During the performance of sound source localization which uses both visual and aural information, it presently remains unclear how much either image or sound modalities contribute to the result, i.e. do we need both image and sound for sound source localization? To address this question, we develop an unsupervised learning system that solves sound source localization by decomposing this task into two steps: (i) "potential sound source localization", a step that localizes possible sound sources using only visual information (ii) "object selection", a step that identifies which objects are actually sounding using aural information. Our overall system achieves state-of-the-art performance in sound source localization, and more importantly, we find that despite the constraint on available information, the results of (i) achieve similar performance. From this observation and further experiments, we show that visual information is dominant in "sound" source localization when evaluated with the currently adopted benchmark dataset. Moreover, we show that the majority of sound-producing objects within the samples in this dataset can be inherently identified using only visual information, and thus that the dataset is inadequate to evaluate a system's capability to leverage aural information. As an alternative, we present an evaluation protocol that enforces both visual and aural information to be leveraged, and verify this property through several experiments.
Distributed Scheduling using Graph Neural Networks
Nov 18, 2020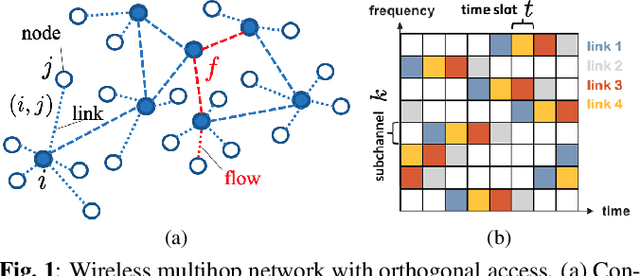
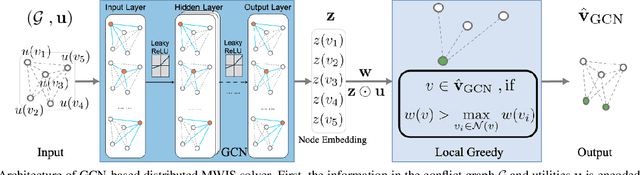
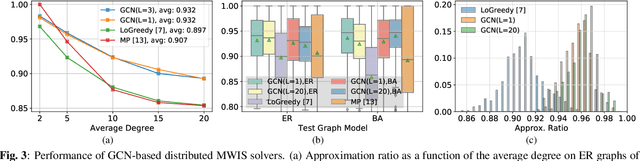
A fundamental problem in the design of wireless networks is to efficiently schedule transmission in a distributed manner. The main challenge stems from the fact that optimal link scheduling involves solving a maximum weighted independent set (MWIS) problem, which is NP-hard. For practical link scheduling schemes, distributed greedy approaches are commonly used to approximate the solution of the MWIS problem. However, these greedy schemes mostly ignore important topological information of the wireless networks. To overcome this limitation, we propose a distributed MWIS solver based on graph convolutional networks (GCNs). In a nutshell, a trainable GCN module learns topology-aware node embeddings that are combined with the network weights before calling a greedy solver. In small- to middle-sized wireless networks with tens of links, even a shallow GCN-based MWIS scheduler can leverage the topological information of the graph to reduce in half the suboptimality gap of the distributed greedy solver with good generalizability across graphs and minimal increase in complexity.
Leveraging Acoustic and Linguistic Embeddings from Pretrained speech and language Models for Intent Classification
Feb 15, 2021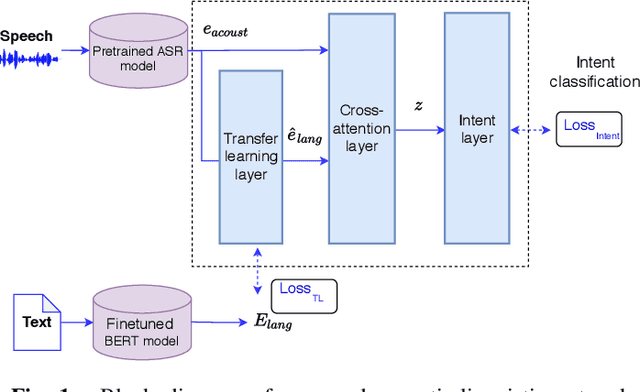
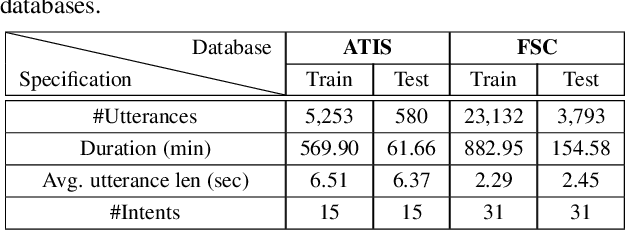
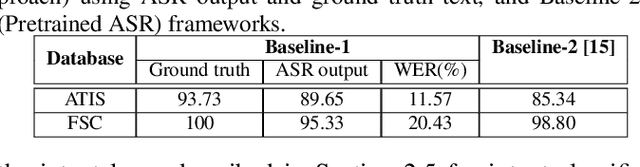
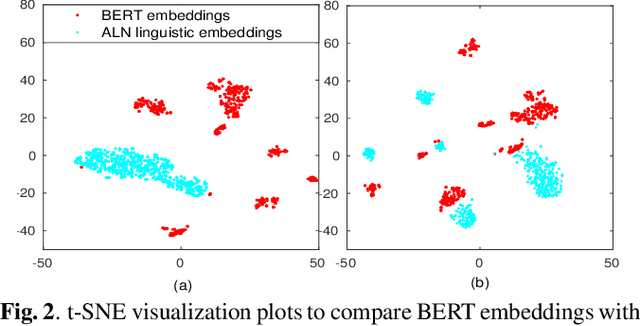
Intent classification is a task in spoken language understanding. An intent classification system is usually implemented as a pipeline process, with a speech recognition module followed by text processing that classifies the intents. There are also studies of end-to-end system that takes acoustic features as input and classifies the intents directly. Such systems don't take advantage of relevant linguistic information, and suffer from limited training data. In this work, we propose a novel intent classification framework that employs acoustic features extracted from a pretrained speech recognition system and linguistic features learned from a pretrained language model. We use knowledge distillation technique to map the acoustic embeddings towards linguistic embeddings. We perform fusion of both acoustic and linguistic embeddings through cross-attention approach to classify intents. With the proposed method, we achieve 90.86% and 99.07% accuracy on ATIS and Fluent speech corpus, respectively.
Vision-Aided Radio: User Identity Match in Radio and Video Domains Using Machine Learning
Oct 14, 2020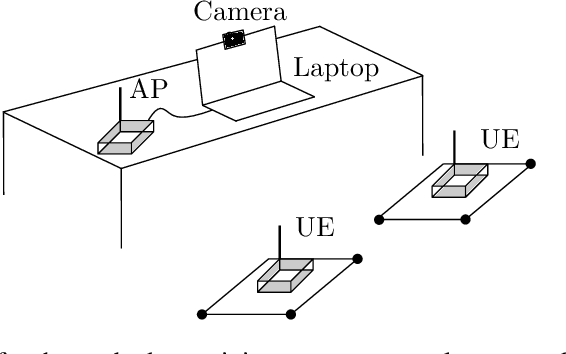
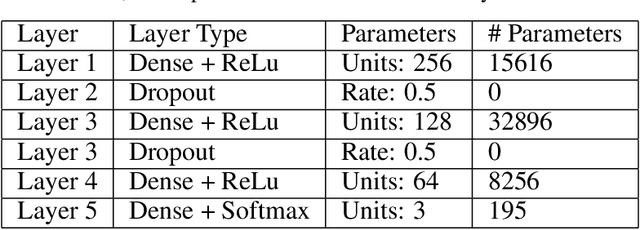
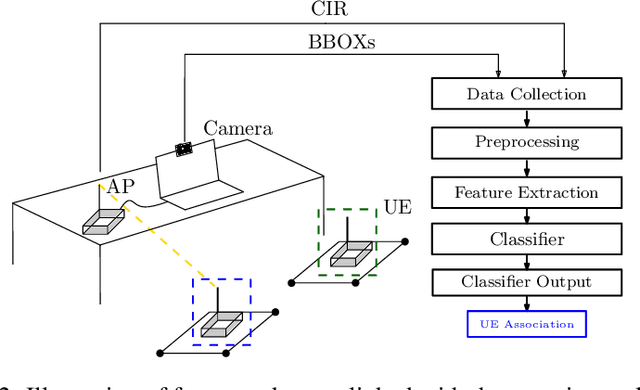
5G is designed to be an essential enabler and a leading infrastructure provider in the communication technology industry by supporting the demand for the growing data traffic and a variety of services with distinct requirements. The use of deep learning and computer vision tools has the means to increase the environmental awareness of the network with information from visual data. Information extracted via computer vision tools such as user position, movement direction, and speed can be promptly available for the network. However, the network must have a mechanism to match the identity of a user in both visual and radio systems. This mechanism is absent in the present literature. Therefore, we propose a framework to match the information from both visual and radio domains. This is an essential step to practical applications of computer vision tools in communications. We detail the proposed framework training and deployment phases for a presented setup. We carried out practical experiments using data collected in different types of environments. The work compares the use of Deep Neural Network and Random Forest classifiers and shows that the former performed better across all experiments, achieving classification accuracy greater than 99%.
Learning Integrodifferential Models for Image Denoising
Oct 21, 2020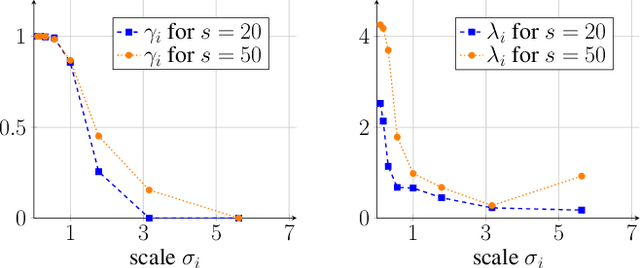
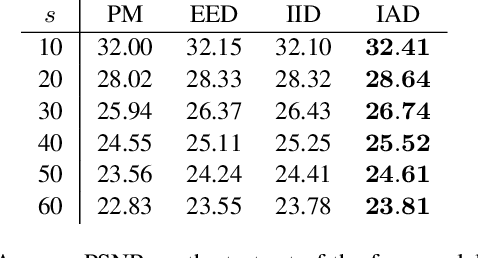

We introduce an integrodifferential extension of the edge-enhancing anisotropic diffusion model for image denoising. By accumulating weighted structural information on multiple scales, our model is the first to create anisotropy through multiscale integration. It follows the philosophy of combining the advantages of model-based and data-driven approaches within compact, insightful, and mathematically well-founded models with improved performance. We explore trained results of scale-adaptive weighting and contrast parameters to obtain an explicit modelling by smooth functions. This leads to a transparent model with only three parameters, without significantly decreasing its denoising performance. Experiments demonstrate that it outperforms its diffusion-based predecessors. We show that both multiscale information and anisotropy are crucial for its success.
Blockchain-Based Federated Learning in Mobile Edge Networks with Application in Internet of Vehicles
Mar 01, 2021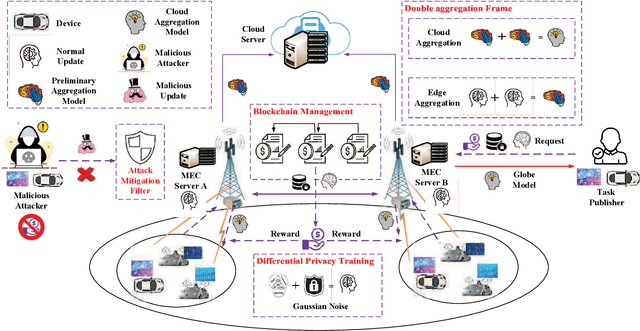
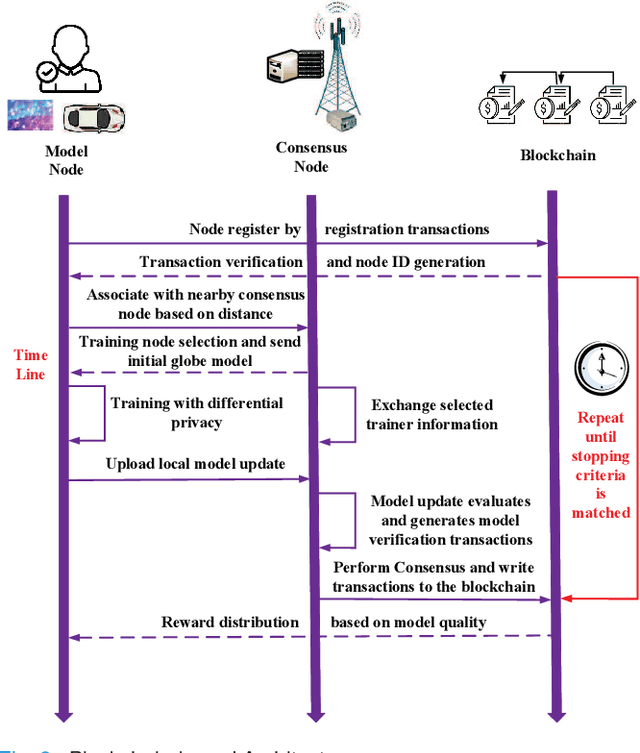
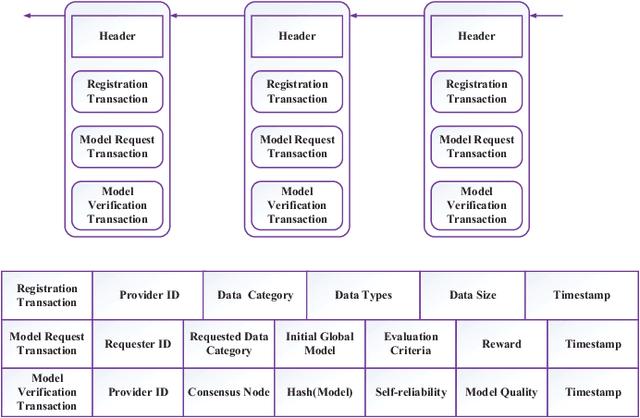

The rapid increase of the data scale in Internet of Vehicles (IoV) system paradigm, hews out new possibilities in boosting the service quality for the emerging applications through data sharing. Nevertheless, privacy concerns are major bottlenecks for data providers to share private data in traditional IoV networks. To this end, federated learning (FL) as an emerging learning paradigm, where data providers only send local model updates trained on their local raw data rather than upload any raw data, has been recently proposed to build a privacy-preserving data sharing models. Unfortunately, by analyzing on the differences of uploaded local model updates from data providers, private information can still be divulged, and performance of the system cannot be guaranteed when partial federated nodes executes malicious behavior. Additionally, traditional cloud-based FL poses challenges to the communication overhead with the rapid increase of terminal equipment in IoV system. All these issues inspire us to propose an autonomous blockchain empowered privacy-preserving FL framework in this paper, where the mobile edge computing (MEC) technology was naturally integrated in IoV system.
Semantic Segmentation for Partially Occluded Apple Trees Based on Deep Learning
Oct 14, 2020
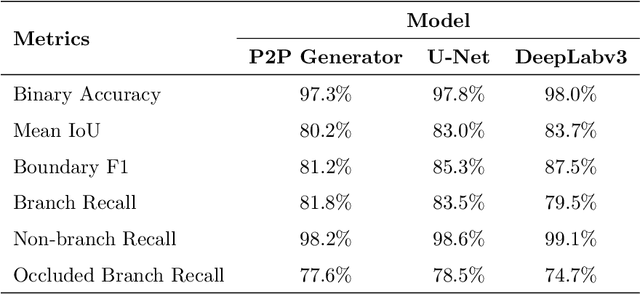


Fruit tree pruning and fruit thinning require a powerful vision system that can provide high resolution segmentation of the fruit trees and their branches. However, recent works only consider the dormant season, where there are minimal occlusions on the branches or fit a polynomial curve to reconstruct branch shape and hence, losing information about branch thickness. In this work, we apply two state-of-the-art supervised learning models U-Net and DeepLabv3, and a conditional Generative Adversarial Network Pix2Pix (with and without the discriminator) to segment partially occluded 2D-open-V apple trees. Binary accuracy, Mean IoU, Boundary F1 score and Occluded branch recall were used to evaluate the performances of the models. DeepLabv3 outperforms the other models at Binary accuracy, Mean IoU and Boundary F1 score, but is surpassed by Pix2Pix (without discriminator) and U-Net in Occluded branch recall. We define two difficulty indices to quantify the difficulty of the task: (1) Occlusion Difficulty Index and (2) Depth Difficulty Index. We analyze the worst 10 images in both difficulty indices by means of Branch Recall and Occluded Branch Recall. U-Net outperforms the other two models in the current metrics. On the other hand, Pix2Pix (without discriminator) provides more information on branch paths, which are not reflected by the metrics. This highlights the need for more specific metrics on recovering occluded information. Furthermore, this shows the usefulness of image-transfer networks for hallucination behind occlusions. Future work is required to further enhance the models to recover more information from occlusions such that this technology can be applied to automating agricultural tasks in a commercial environment.