 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FL-AGCNS: Federated Learning Framework for Automatic Graph Convolutional Network Search
Apr 09, 2021
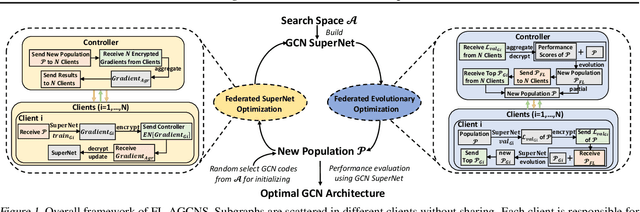
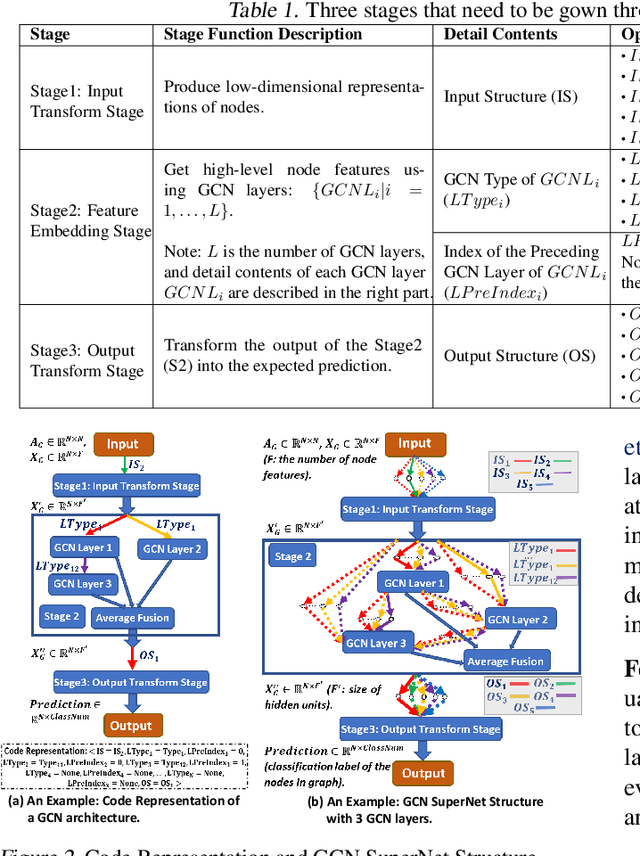
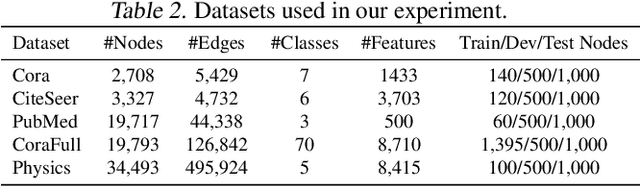
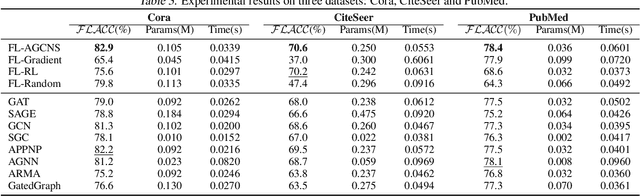
Recently, some Neural Architecture Search (NAS) techniques are proposed for the automatic design of Graph Convolutional Network (GCN) architectures. They bring great convenience to the use of GCN, but could hardly apply to the Federated Learning (FL) scenarios with distributed and private datasets, which limit their applications. Moreover, they need to train many candidate GCN models from scratch, which is inefficient for FL. To address these challenges, we propose FL-AGCNS, an efficient GCN NAS algorithm suitable for FL scenarios. FL-AGCNS designs a federated evolutionary optimization strategy to enable distributed agents to cooperatively design powerful GCN models while keeping personal information on local devices. Besides, it applies the GCN SuperNet and a weight sharing strategy to speed up the evaluation of GCN models. Experimental results show that FL-AGCNS can find better GCN models in short time under the FL framework, surpassing the state-of-the-arts NAS methods and GCN models.
Approximate Fisher Information Matrix to Characterise the Training of Deep Neural Networks
Oct 16, 2018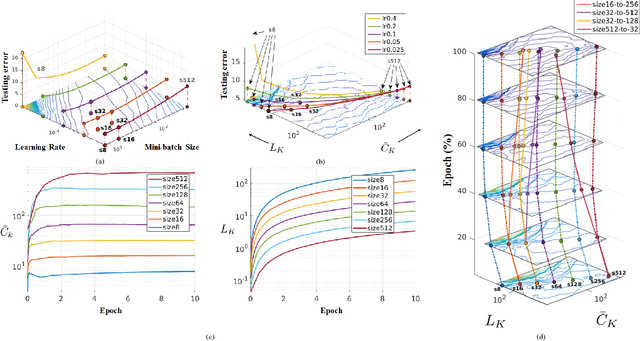
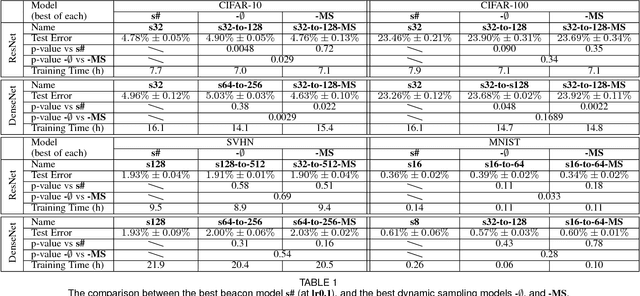
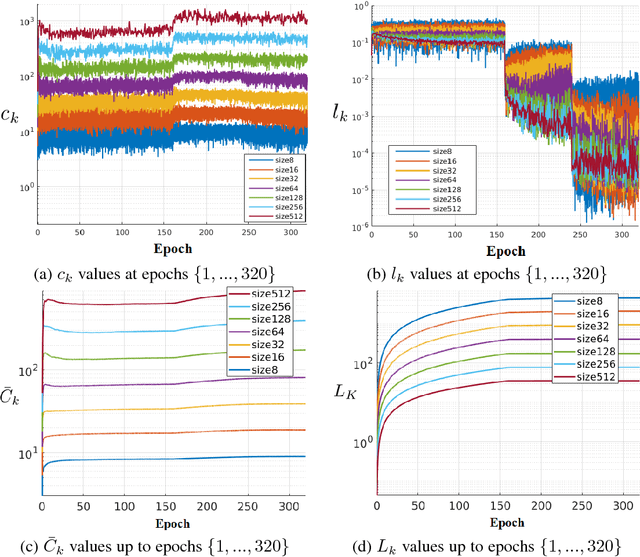
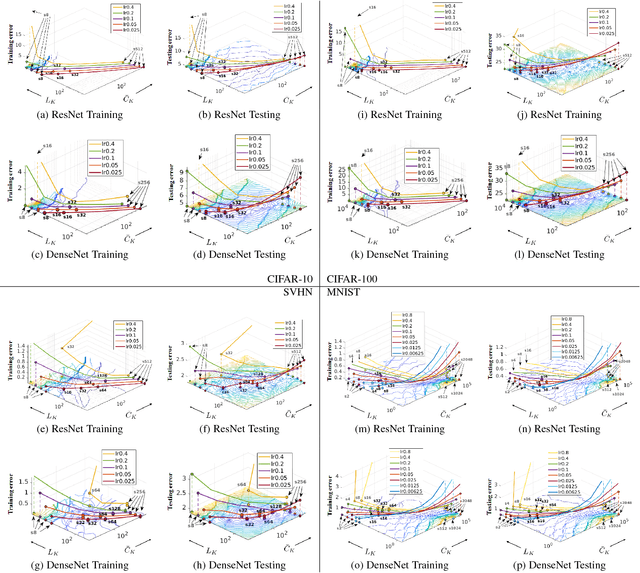
In this paper, we introduce a novel methodology for characterising the performance of deep learning networks (ResNets and DenseNet) with respect to training convergence and generalisation as a function of mini-batch size and learning rate for image classification. This methodology is based on novel measurements derived from the eigenvalues of the approximate Fisher information matrix, which can be efficiently computed even for high capacity deep models. Our proposed measurements can help practitioners to monitor and control the training process (by actively tuning the mini-batch size and learning rate) to allow for good training convergence and generalisation. Furthermore, the proposed measurements also allow us to show that it is possible to optimise the training process with a new dynamic sampling training approach that continuously and automatically change the mini-batch size and learning rate during the training process. Finally, we show that the proposed dynamic sampling training approach has a faster training time and a competitive classification accuracy compared to the current state of the art.
Dynamic Message Scheduling With Activity-Aware Residual Belief Propagation for Asynchronous mMTC Systems
Mar 07, 2021
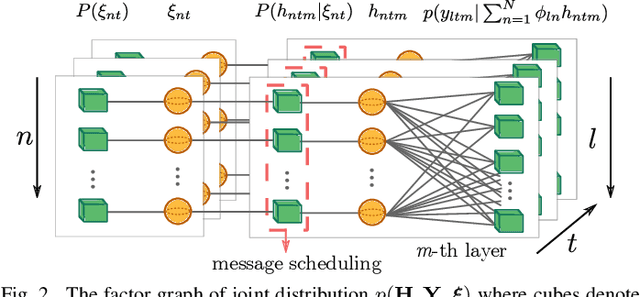
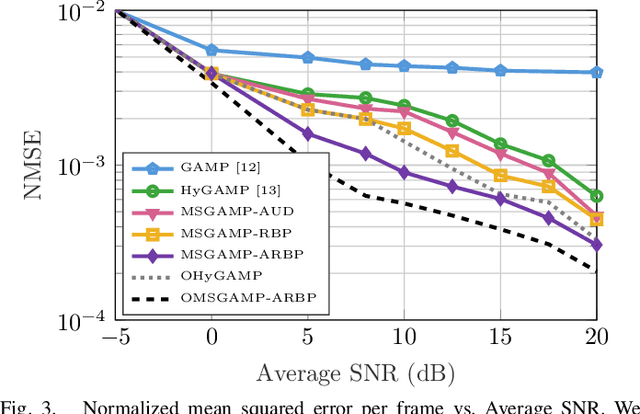
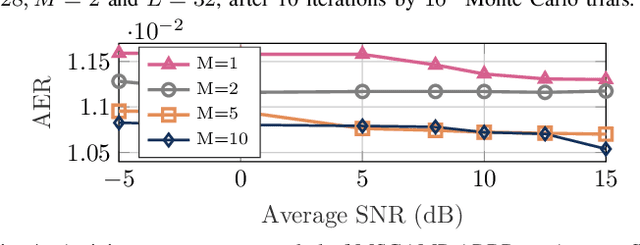
In this letter, we propose a joint active device detection and channel estimation framework based on factor graphs for asynchronous uplink grant-free massive multiple-antenna systems. We then develop the message-scheduling GAMP (MSGAMP) algorithm to perform joint active device detection and channel estimation. In MSGAMP we apply scheduling techniques based on the residual belief propagation (RBP) and the activity user detection (AUD) in which messages are generated using the latest available information. MSGAMP-type schemes show a good performance in terms of activity error rate and normalized mean squared error, requiring a smaller number of iterations for convergence and lower complexity than state-of-the-art techniques.
Transforming Multi-Conditioned Generation from Meaning Representation
Jan 12, 2021

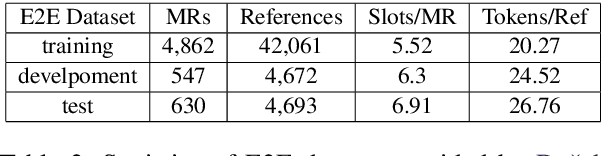

In task-oriented conversation systems, natural language generation systems that generate sentences with specific information related to conversation flow are useful. Our study focuses on language generation by considering various information representing the meaning of utterances as multiple conditions of generation. NLG from meaning representations, the conditions for sentence meaning, generally goes through two steps: sentence planning and surface realization. However, we propose a simple one-stage framework to generate utterances directly from MR (Meaning Representation). Our model is based on GPT2 and generates utterances with flat conditions on slot and value pairs, which does not need to determine the structure of the sentence. We evaluate several systems in the E2E dataset with 6 automatic metrics. Our system is a simple method, but it demonstrates comparable performance to previous systems in automated metrics. In addition, using only 10\% of the data set without any other techniques, our model achieves comparable performance, and shows the possibility of performing zero-shot generation and expanding to other datasets.
OAAE: Adversarial Autoencoders for Novelty Detection in Multi-modal Normality Case via Orthogonalized Latent Space
Jan 07, 2021
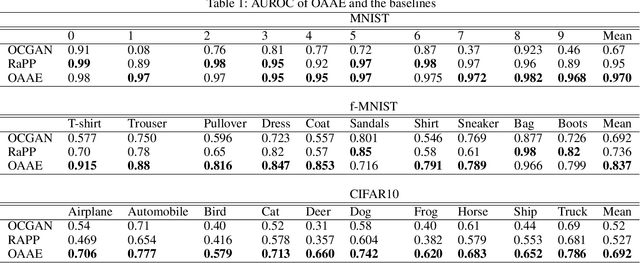
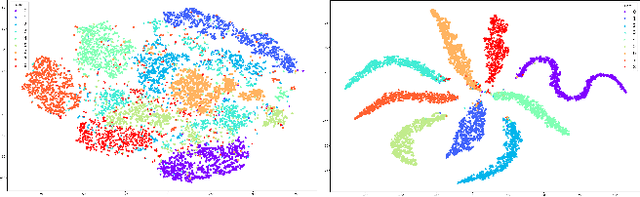
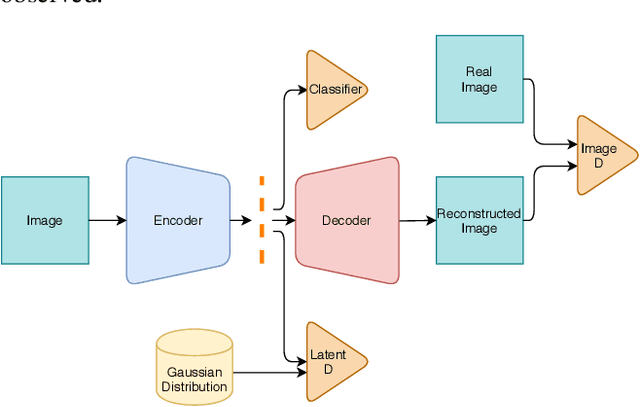
Novelty detection using deep generative models such as autoencoder, generative adversarial networks mostly takes image reconstruction error as novelty score function. However, image data, high dimensional as it is, contains a lot of different features other than class information which makes models hard to detect novelty data. The problem gets harder in multi-modal normality case. To address this challenge, we propose a new way of measuring novelty score in multi-modal normality cases using orthogonalized latent space. Specifically, we employ orthogonal low-rank embedding in the latent space to disentangle the features in the latent space using mutual class information. With the orthogonalized latent space, novelty score is defined by the change of each latent vector. Proposed algorithm was compared to state-of-the-art novelty detection algorithms using GAN such as RaPP and OCGAN, and experimental results show that ours outperforms those algorithms.
A Lower Bound for the Sample Complexity of Inverse Reinforcement Learning
Mar 07, 2021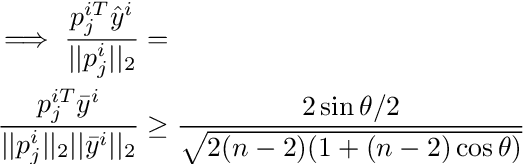
Inverse reinforcement learning (IRL) is the task of finding a reward function that generates a desired optimal policy for a given Markov Decision Process (MDP). This paper develops an information-theoretic lower bound for the sample complexity of the finite state, finite action IRL problem. A geometric construction of $\beta$-strict separable IRL problems using spherical codes is considered. Properties of the ensemble size as well as the Kullback-Leibler divergence between the generated trajectories are derived. The resulting ensemble is then used along with Fano's inequality to derive a sample complexity lower bound of $O(n \log n)$, where $n$ is the number of states in the MDP.
Delay-Tolerant Constrained OCO with Application to Network Resource Allocation
May 09, 2021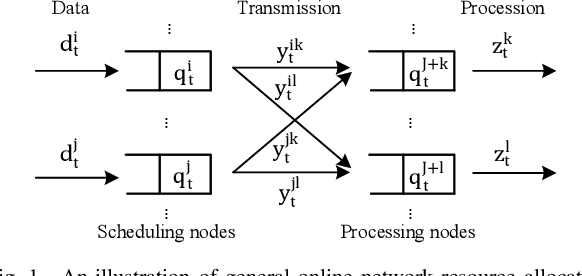
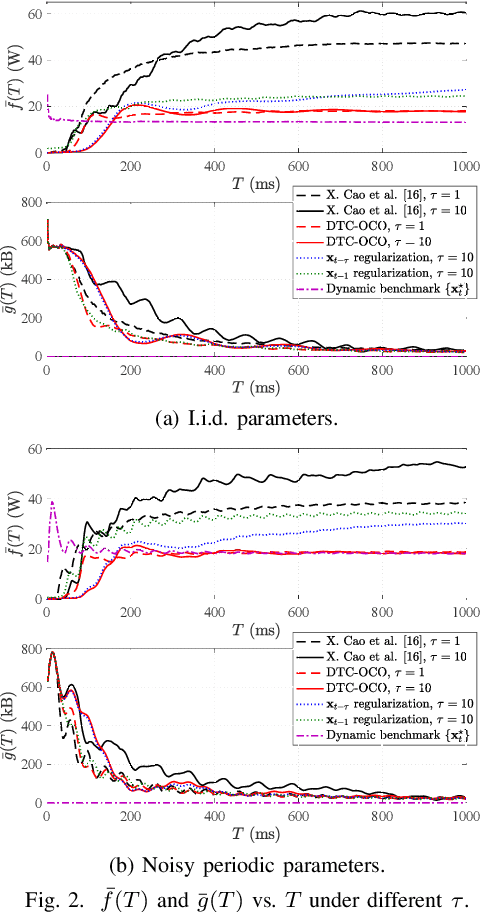

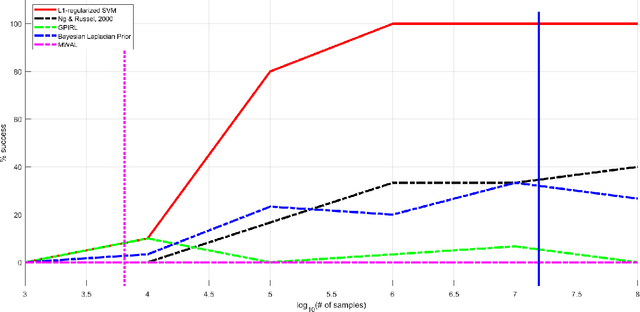
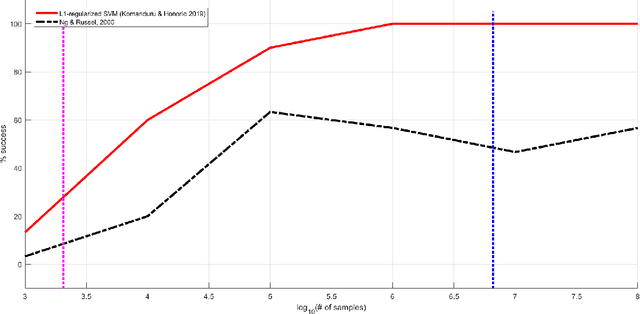
We consider online convex optimization (OCO) with multi-slot feedback delay, where an agent makes a sequence of online decisions to minimize the accumulation of time-varying convex loss functions, subject to short-term and long-term constraints that are possibly time-varying. The current convex loss function and the long-term constraint function are revealed to the agent only after the decision is made, and they may be delayed for multiple time slots. Existing work on OCO under this general setting has focused on the static regret, which measures the gap of losses between the online decision sequence and an offline benchmark that is fixed over time. In this work, we consider both the static regret and the more practically meaningful dynamic regret, where the benchmark is a time-varying sequence of per-slot optimizers. We propose an efficient algorithm, termed Delay-Tolerant Constrained-OCO (DTC-OCO), which uses a novel constraint penalty with double regularization to tackle the asynchrony between information feedback and decision updates. We derive upper bounds on its dynamic regret, static regret, and constraint violation, proving them to be sublinear under mild conditions. We further apply DTC-OCO to a general network resource allocation problem, which arises in many systems such as data networks and cloud computing. Simulation results demonstrate substantial performance gain of DTC-OCO over the known best alternative.
A Non-commutative Extension of Lee-Seung's Algorithm for Positive Semidefinite Factorizations
Jun 01, 2021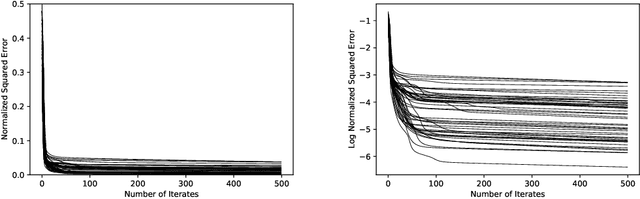

Given a matrix $X\in \mathbb{R}_+^{m\times n}$ with nonnegative entries, a Positive Semidefinite (PSD) factorization of $X$ is a collection of $r \times r$-dimensional PSD matrices $\{A_i\}$ and $\{B_j\}$ satisfying $X_{ij}= \mathrm{tr}(A_i B_j)$ for all $\ i\in [m],\ j\in [n]$. PSD factorizations are fundamentally linked to understanding the expressiveness of semidefinite programs as well as the power and limitations of quantum resources in information theory. The PSD factorization task generalizes the Non-negative Matrix Factorization (NMF) problem where we seek a collection of $r$-dimensional nonnegative vectors $\{a_i\}$ and $\{b_j\}$ satisfying $X_{ij}= a_i^\top b_j$, for all $i\in [m],\ j\in [n]$ -- one can recover the latter problem by choosing matrices in the PSD factorization to be diagonal. The most widely used algorithm for computing NMFs of a matrix is the Multiplicative Update algorithm developed by Lee and Seung, in which nonnegativity of the updates is preserved by scaling with positive diagonal matrices. In this paper, we describe a non-commutative extension of Lee-Seung's algorithm, which we call the Matrix Multiplicative Update (MMU) algorithm, for computing PSD factorizations. The MMU algorithm ensures that updates remain PSD by congruence scaling with the matrix geometric mean of appropriate PSD matrices, and it retains the simplicity of implementation that Lee-Seung's algorithm enjoys. Building on the Majorization-Minimization framework, we show that under our update scheme the squared loss objective is non-increasing and fixed points correspond to critical points. The analysis relies on Lieb's Concavity Theorem. Beyond PSD factorizations, we use the MMU algorithm as a primitive to calculate block-diagonal PSD factorizations and tensor PSD factorizations. We demonstrate the utility of our method with experiments on real and synthetic data.
Multi-Sensor Conflict Measurement and Information Fusion
Mar 12, 2018In sensing applications where multiple sensors observe the same scene, fusing sensor outputs can provide improved results. However, if some of the sensors are providing lower quality outputs, the fused results can be degraded. In this work, a multi-sensor conflict measure is proposed which estimates multi-sensor conflict by representing each sensor output as interval-valued information and examines the sensor output overlaps on all possible n-tuple sensor combinations. The conflict is based on the sizes of the intervals and how many sensors output values lie in these intervals. In this work, conflict is defined in terms of how little the output from multiple sensors overlap. That is, high degrees of overlap mean low sensor conflict, while low degrees of overlap mean high conflict. This work is a preliminary step towards a robust conflict and sensor fusion framework. In addition, a sensor fusion algorithm is proposed based on a weighted sum of sensor outputs, where the weights for each sensor diminish as the conflict measure increases. The proposed methods can be utilized to (1) assess a measure of multi-sensor conflict, and (2) improve sensor output fusion by lessening weighting for sensors with high conflict. Using this measure, a simulated example is given to explain the mechanics of calculating the conflict measure, and stereo camera 3D outputs are analyzed and fused. In the stereo camera case, the sensor output is corrupted by additive impulse noise, DC offset, and Gaussian noise. Impulse noise is common in sensors due to intermittent interference, a DC offset a sensor bias or registration error, and Gaussian noise represents a sensor output with low SNR. The results show that sensor output fusion based on the conflict measure shows improved accuracy over a simple averaging fusion strategy.
* 15 pages, 9 figures, conference paper
What does 2D geometric information really tell us about 3D face shape?
Apr 16, 2018

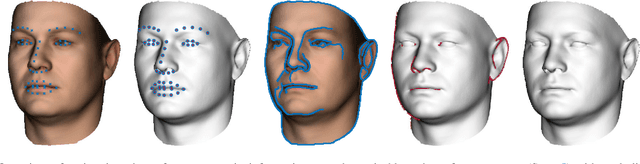
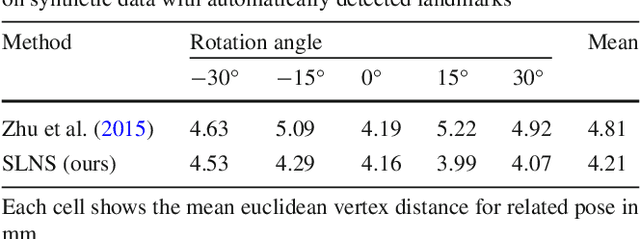
A face image contains geometric cues in the form of configurational information and contours that can be used to estimate 3D face shape. While it is clear that 3D reconstruction from 2D points is highly ambiguous if no further constraints are enforced, one might expect that the face-space constraint solves this problem. We show that this is not the case and that geometric information is an ambiguous cue. There are two sources for this ambiguity. The first is that, within the space of 3D face shapes, there are flexibility modes that remain when some parts of the face are fixed. The second occurs only under perspective projection and is a result of perspective transformation as camera distance varies. Two different faces, when viewed at different distances, can give rise to the same 2D geometry. To demonstrate these ambiguities, we develop new algorithms for fitting a 3D morphable model to 2D landmarks or contours under either orthographic or perspective projection and show how to compute flexibility modes for both cases. We show that both fitting problems can be posed as a separable nonlinear least squares problem and solved efficiently. We provide quantitative and qualitative evidence that the ambiguity exists in synthetic data and real images.