 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Lower Bound for the Sample Complexity of Inverse Reinforcement Learning
Mar 07, 2021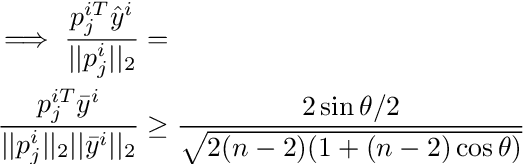
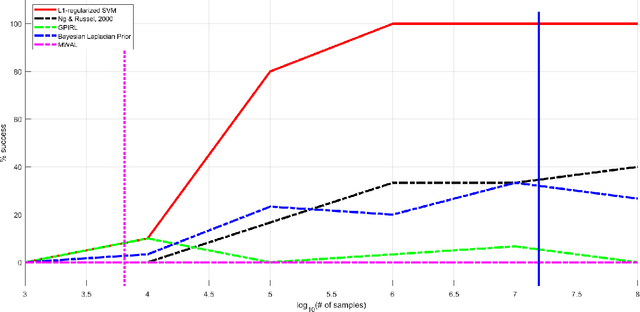
Inverse reinforcement learning (IRL) is the task of finding a reward function that generates a desired optimal policy for a given Markov Decision Process (MDP). This paper develops an information-theoretic lower bound for the sample complexity of the finite state, finite action IRL problem. A geometric construction of $\beta$-strict separable IRL problems using spherical codes is considered. Properties of the ensemble size as well as the Kullback-Leibler divergence between the generated trajectories are derived. The resulting ensemble is then used along with Fano's inequality to derive a sample complexity lower bound of $O(n \log n)$, where $n$ is the number of states in the MDP.
On the Correctness and Sample Complexity of Inverse Reinforcement Learning
Jun 02, 2019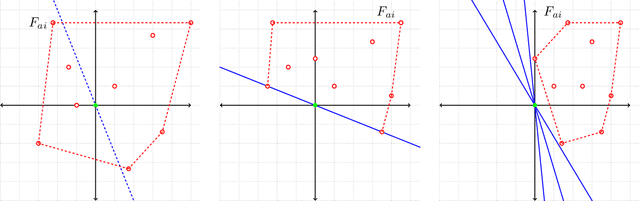
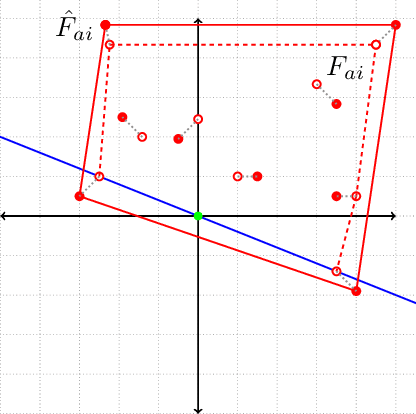
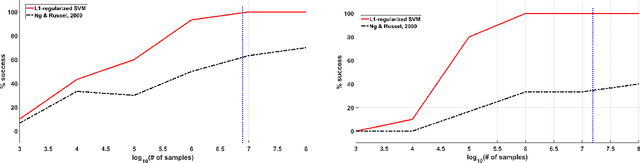
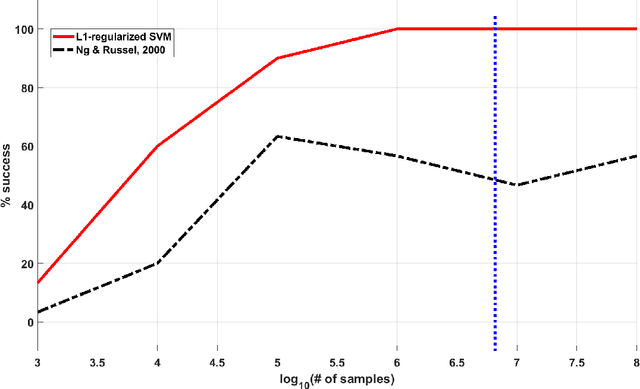
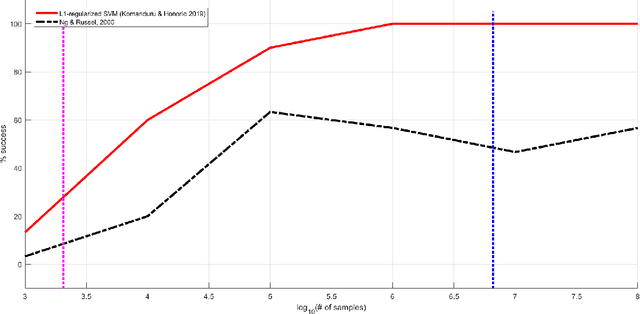
Inverse reinforcement learning (IRL) is the problem of finding a reward function that generates a given optimal policy for a given Markov Decision Process. This paper looks at an algorithmic-independent geometric analysis of the IRL problem with finite states and actions. A L1-regularized Support Vector Machine formulation of the IRL problem motivated by the geometric analysis is then proposed with the basic objective of the inverse reinforcement problem in mind: to find a reward function that generates a specified optimal policy. The paper further analyzes the proposed formulation of inverse reinforcement learning with $n$ states and $k$ actions, and shows a sample complexity of $O(n^2 \log (nk))$ for recovering a reward function that generates a policy that satisfies Bellman's optimality condition with respect to the true transition probabilities.