 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
An Analysis of a BERT Deep Learning Strategy on a Technology Assisted Review Task
Apr 16, 2021
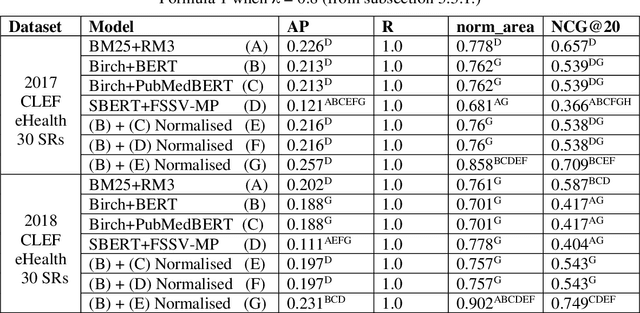
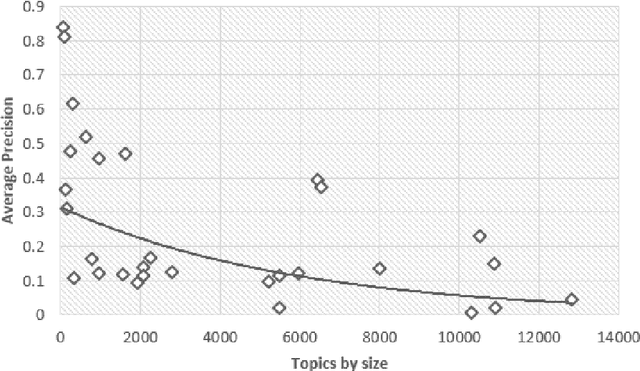
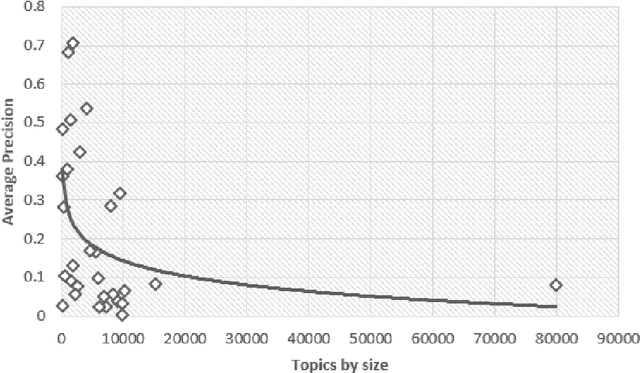
Document screening is a central task within Evidenced Based Medicine, which is a clinical discipline that supplements scientific proof to back medical decisions. Given the recent advances in DL (Deep Learning) methods applied to Information Retrieval tasks, I propose a DL document classification approach with BERT or PubMedBERT embeddings and a DL similarity search path using SBERT embeddings to reduce physicians' tasks of screening and classifying immense amounts of documents to answer clinical queries. I test and evaluate the retrieval effectiveness of my DL strategy on the 2017 and 2018 CLEF eHealth collections. I find that the proposed DL strategy works, I compare it to the recently successful BM25 plus RM3 model, and conclude that the suggested method accomplishes advanced retrieval performance in the initial ranking of the articles with the aforementioned datasets, for the CLEF eHealth Technologically Assisted Reviews in Empirical Medicine Task.
Semantic XAI for contextualized demand forecasting explanations
Apr 01, 2021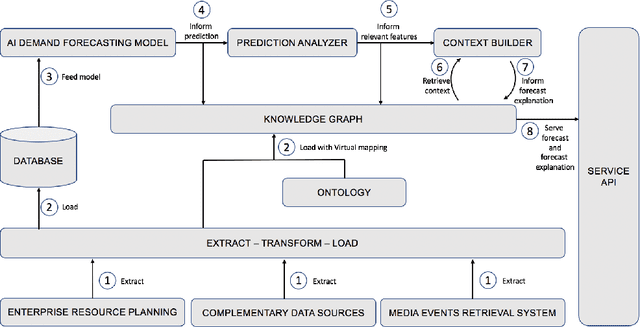
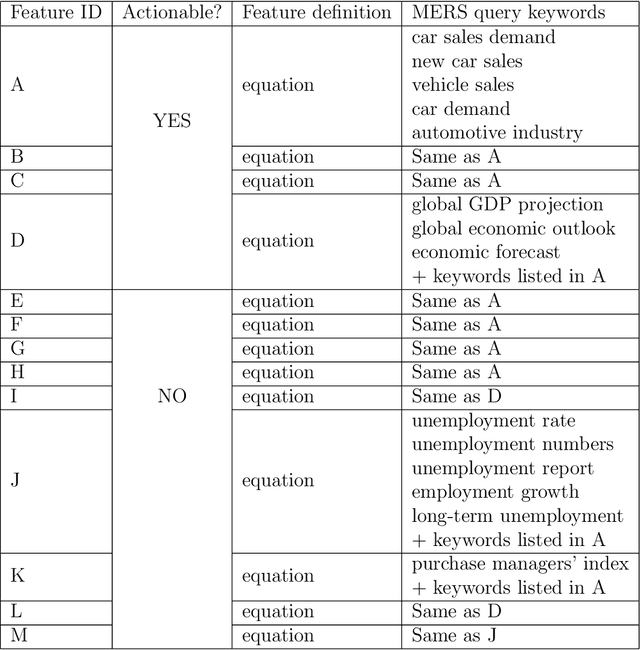
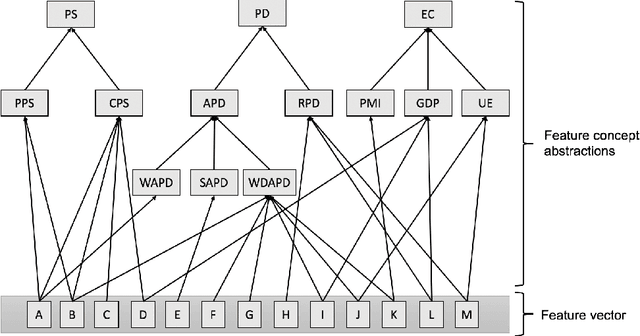
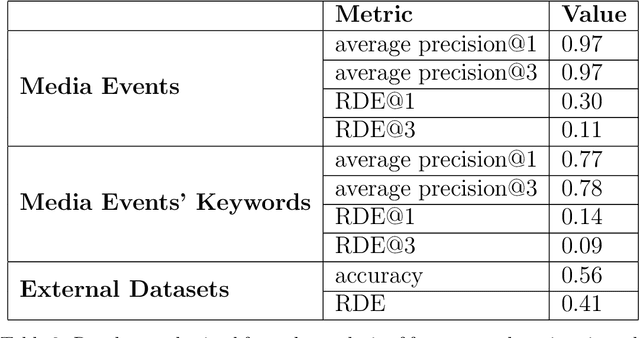
The paper proposes a novel architecture for explainable AI based on semantic technologies and AI. We tailor the architecture for the domain of demand forecasting and validate it on a real-world case study. The provided explanations combine concepts describing features relevant to a particular forecast, related media events, and metadata regarding external datasets of interest. The knowledge graph provides concepts that convey feature information at a higher abstraction level. By using them, explanations do not expose sensitive details regarding the demand forecasting models. The explanations also emphasize actionable dimensions where suitable. We link domain knowledge, forecasted values, and forecast explanations in a Knowledge Graph. The ontology and dataset we developed for this use case are publicly available for further research.
Discrete-continuous Action Space Policy Gradient-based Attention for Image-Text Matching
Apr 21, 2021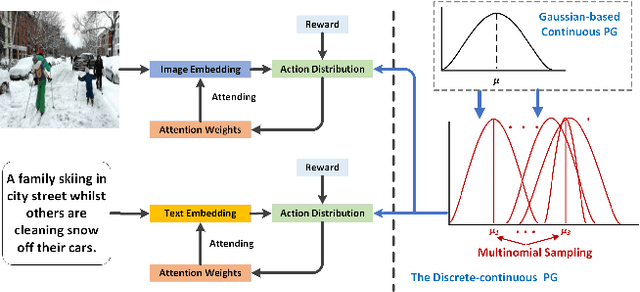
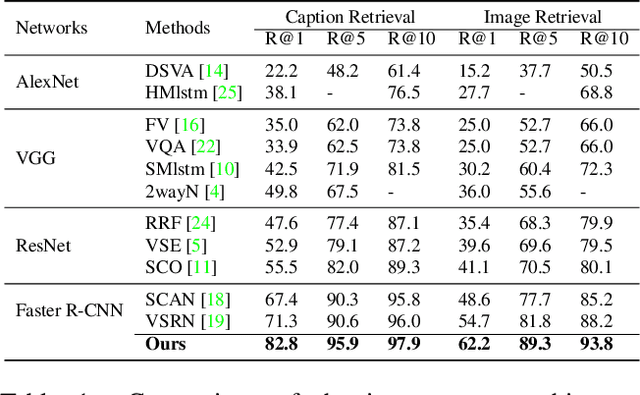
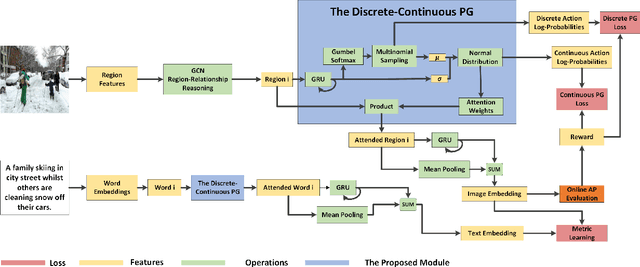
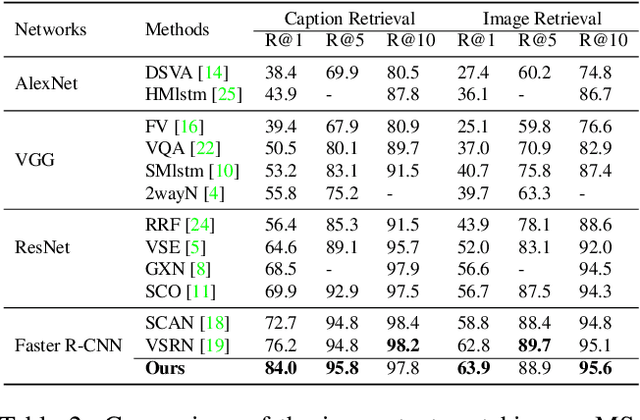
Image-text matching is an important multi-modal task with massive applications. It tries to match the image and the text with similar semantic information. Existing approaches do not explicitly transform the different modalities into a common space. Meanwhile, the attention mechanism which is widely used in image-text matching models does not have supervision. We propose a novel attention scheme which projects the image and text embedding into a common space and optimises the attention weights directly towards the evaluation metrics. The proposed attention scheme can be considered as a kind of supervised attention and requiring no additional annotations. It is trained via a novel Discrete-continuous action space policy gradient algorithm, which is more effective in modelling complex action space than previous continuous action space policy gradient. We evaluate the proposed methods on two widely-used benchmark datasets: Flickr30k and MS-COCO, outperforming the previous approaches by a large margin.
Multi-Attention-Based Soft Partition Network for Vehicle Re-Identification
Apr 21, 2021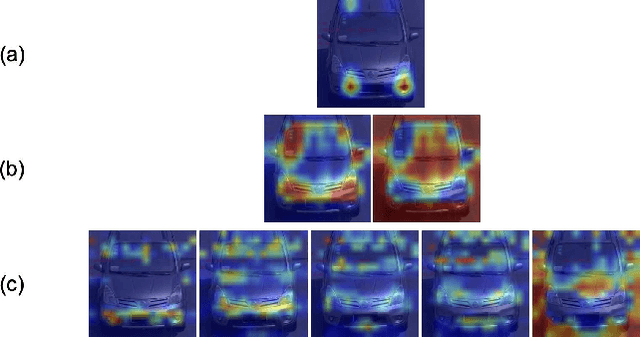
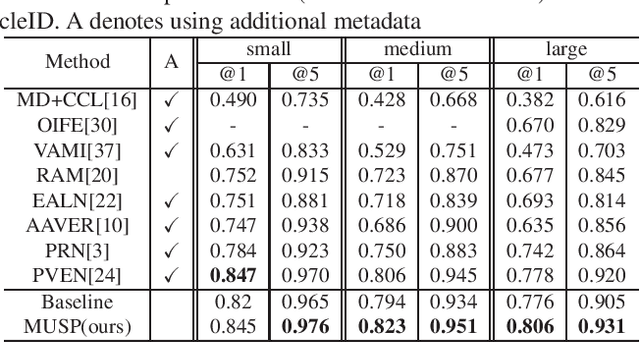
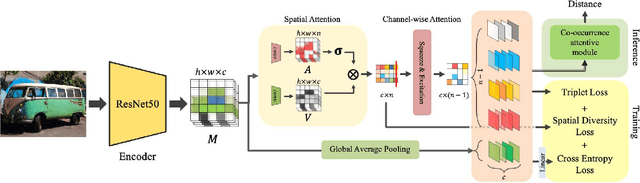
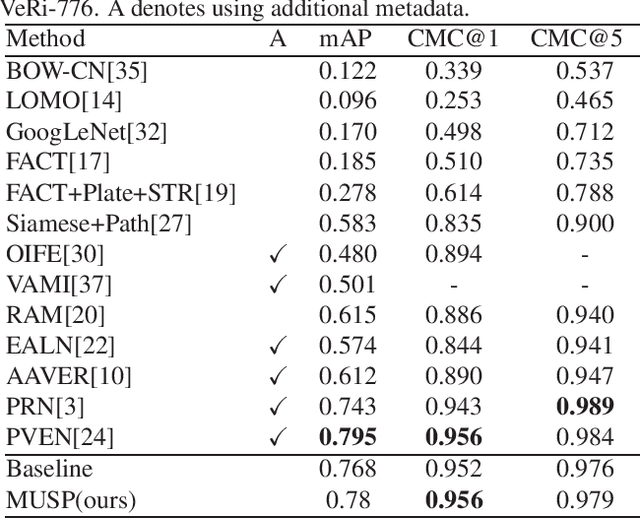
Vehicle re-identification (Re-ID) distinguishes between the same vehicle and other vehicles in images. It is challenging due to significant intra-instance differences between identical vehicles from different views and subtle inter-instance differences of similar vehicles. Researchers have tried to address this problem by extracting features robust to variations of viewpoints and environments. More recently, they tried to improve performance by using additional metadata such as key points, orientation, and temporal information. Although these attempts have been relatively successful, they all require expensive annotations. Therefore, this paper proposes a novel deep neural network called a multi-attention-based soft partition (MUSP) network to solve this problem. This network does not use metadata and only uses multiple soft attentions to identify a specific vehicle area. This function was performed by metadata in previous studies. Experiments verified that MUSP achieved state-of-the-art (SOTA) performance for the VehicleID dataset without any additional annotations and was comparable to VeRi-776 and VERI-Wild.
Distributed support-vector-machine over dynamic balanced directed networks
Apr 01, 2021


In this paper, we consider the binary classification problem via distributed Support-Vector-Machines (SVM), where the idea is to train a network of agents, with limited share of data, to cooperatively learn the SVM classifier for the global database. Agents only share processed information regarding the classifier parameters and the gradient of the local loss functions instead of their raw data. In contrast to the existing work, we propose a continuous-time algorithm that incorporates network topology changes in discrete jumps. This hybrid nature allows us to remove chattering that arises because of the discretization of the underlying CT process. We show that the proposed algorithm converges to the SVM classifier over time-varying weight balanced directed graphs by using arguments from the matrix perturbation theory.
AMR Parsing with Action-Pointer Transformer
Apr 29, 2021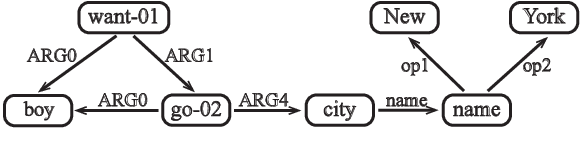
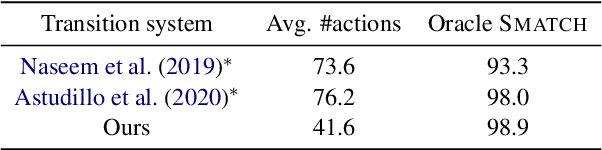

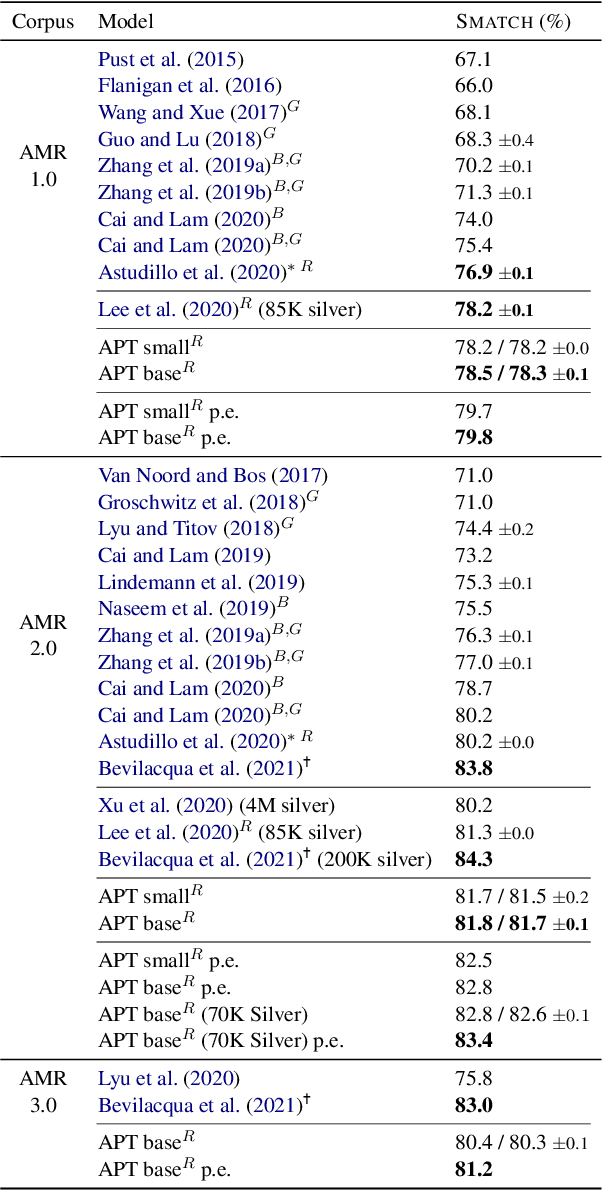
Abstract Meaning Representation parsing is a sentence-to-graph prediction task where target nodes are not explicitly aligned to sentence tokens. However, since graph nodes are semantically based on one or more sentence tokens, implicit alignments can be derived. Transition-based parsers operate over the sentence from left to right, capturing this inductive bias via alignments at the cost of limited expressiveness. In this work, we propose a transition-based system that combines hard-attention over sentences with a target-side action pointer mechanism to decouple source tokens from node representations and address alignments. We model the transitions as well as the pointer mechanism through straightforward modifications within a single Transformer architecture. Parser state and graph structure information are efficiently encoded using attention heads. We show that our action-pointer approach leads to increased expressiveness and attains large gains (+1.6 points) against the best transition-based AMR parser in very similar conditions. While using no graph re-categorization, our single model yields the second best Smatch score on AMR 2.0 (81.8), which is further improved to 83.4 with silver data and ensemble decoding.
A Non-Intrusive Machine Learning Solution for Malware Detection and Data Theft Classification in Smartphones
Feb 12, 2021
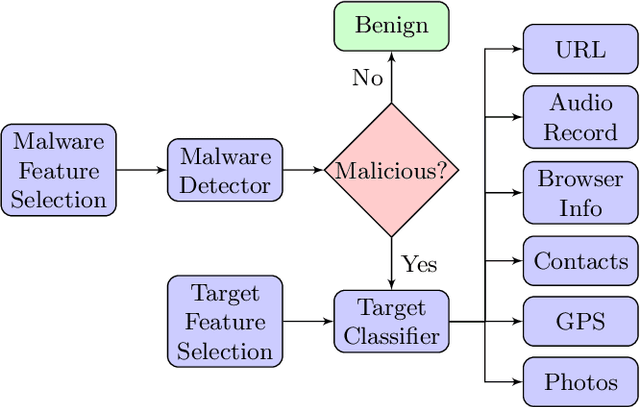
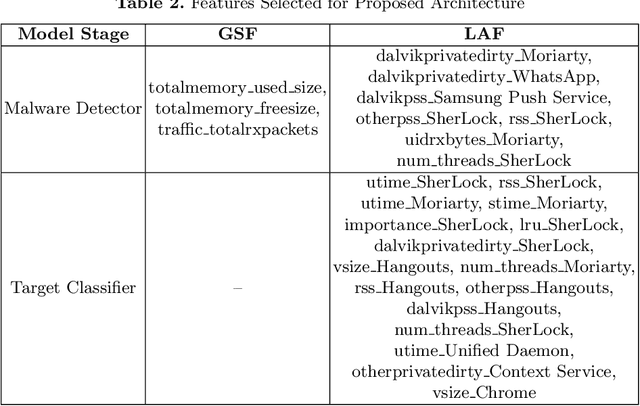
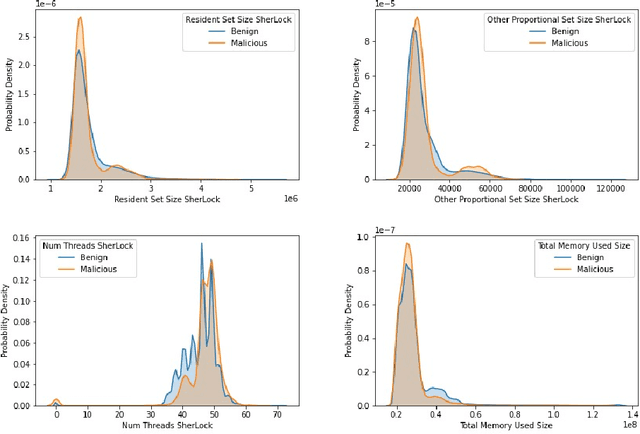
Smartphones contain information that is more sensitive and personal than those found on computers and laptops. With an increase in the versatility of smartphone functionality, more data has become vulnerable and exposed to attackers. Successful mobile malware attacks could steal a user's location, photos, or even banking information. Due to a lack of post-attack strategies firms also risk going out of business due to data theft. Thus, there is a need besides just detecting malware intrusion in smartphones but to also identify the data that has been stolen to assess, aid in recovery and prevent future attacks. In this paper, we propose an accessible, non-intrusive machine learning solution to not only detect malware intrusion but also identify the type of data stolen for any app under supervision. We do this with Android usage data obtained by utilising publicly available data collection framework- SherLock. We test the performance of our architecture for multiple users on real-world data collected using the same framework. Our architecture exhibits less than 9% inaccuracy in detecting malware and can classify with 83% certainty on the type of data that is being stolen.
Data Quality as Predictor of Voice Anti-Spoofing Generalization
Mar 26, 2021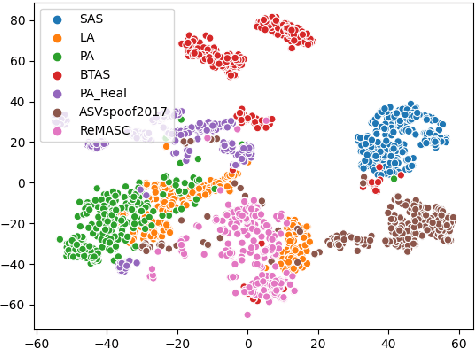
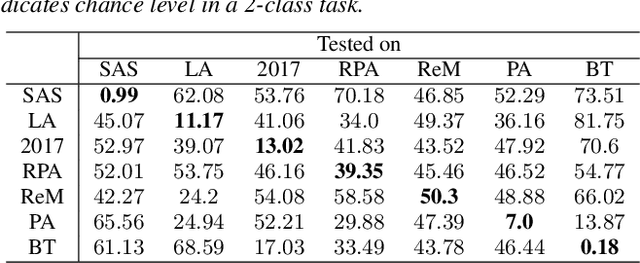
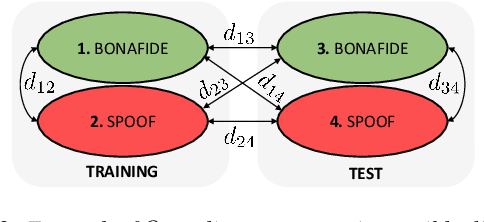
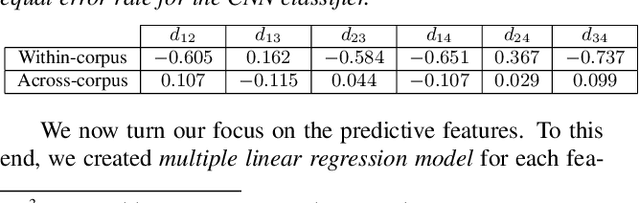
Voice anti-spoofing aims at classifying a given speech input either as a bonafide human sample, or a spoofing attack (e.g. synthetic or replayed sample). Numerous voice anti-spoofing methods have been proposed but most of them fail to generalize across domains (corpora) -- and we do not know \emph{why}. We outline a novel interpretative framework for gauging the impact of data quality upon anti-spoofing performance. Our within- and between-domain experiments pool data from seven public corpora and three anti-spoofing methods based on Gaussian mixture and convolutive neural network models. We assess the impacts of long-term spectral information, speaker population (through x-vector speaker embeddings), signal-to-noise ratio, and selected voice quality features.
How consistent is my model with the data? Information-Theoretic Model Check
Dec 19, 2017
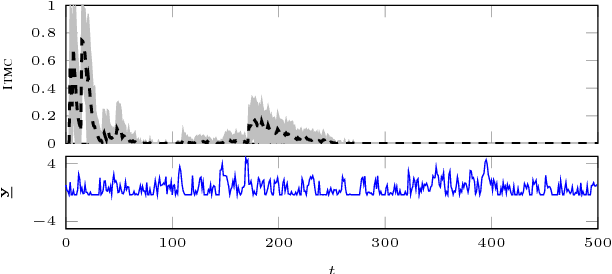
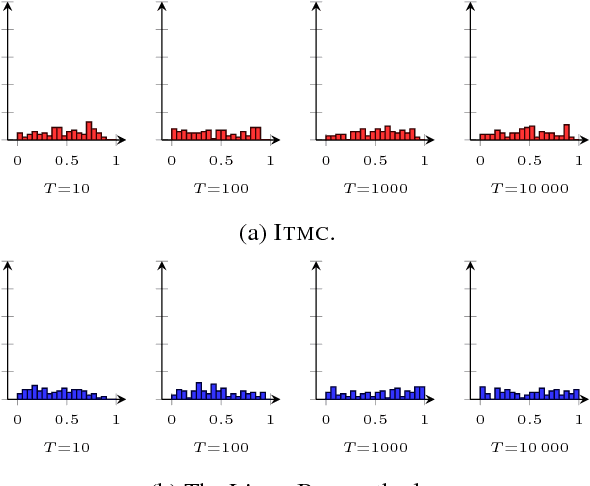
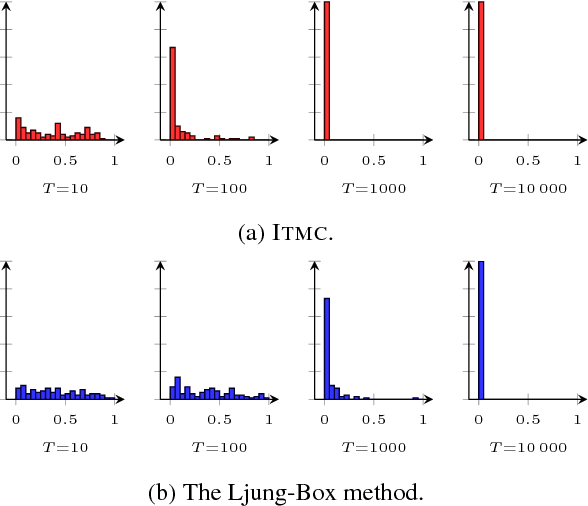
The choice of model class is fundamental in statistical learning and system identification, no matter whether the class is derived from physical principles or is a generic black-box. We develop a method to evaluate the specified model class by assessing its capability of reproducing data that is similar to the observed data record. This model check is based on the information-theoretic properties of models viewed as data generators and is applicable to e.g. sequential data and nonlinear dynamical models. The method can be understood as a specific two-sided posterior predictive test. We apply the information-theoretic model check to both synthetic and real data and compare it with a classical whiteness test.
iLQR for Piecewise-Smooth Hybrid Dynamical Systems
Mar 26, 2021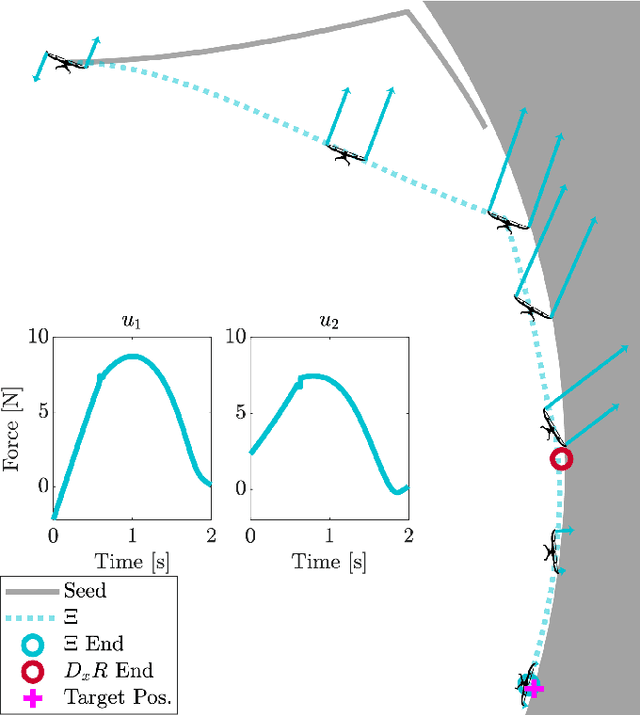
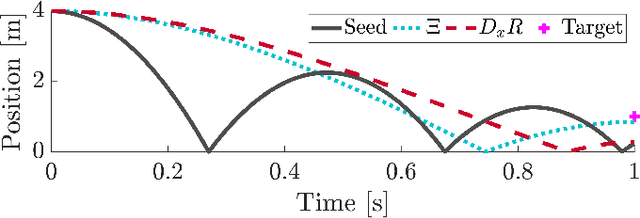
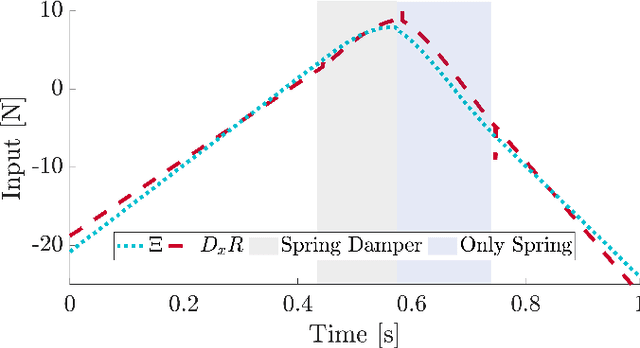
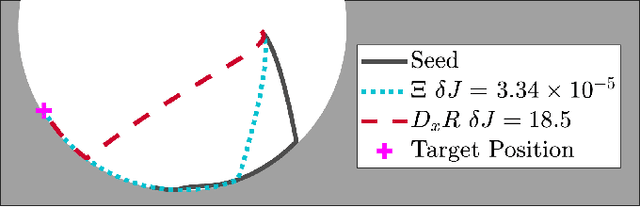
Trajectory optimization is a popular strategy for planning trajectories for robotic systems. However, many robotic tasks require changing contact conditions, which is difficult due to the hybrid nature of the dynamics. The optimal sequence and timing of these modes are typically not known ahead of time. In this work, we extend the Iterative Linear Quadratic Regulator (iLQR) method to a class of piecewise smooth hybrid dynamical systems by allowing for changing hybrid modes in the forward pass, using the saltation matrix to update the gradient information in the backwards pass, and using a reference extension to account for mode mismatch. We demonstrate these changes on a variety of hybrid systems and compare the different strategies for computing the gradients.