 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Scalable Mutual Information Estimation using Dependence Graphs
Jan 27, 2018
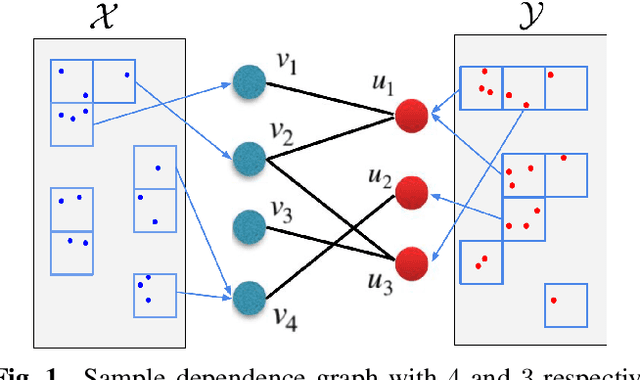
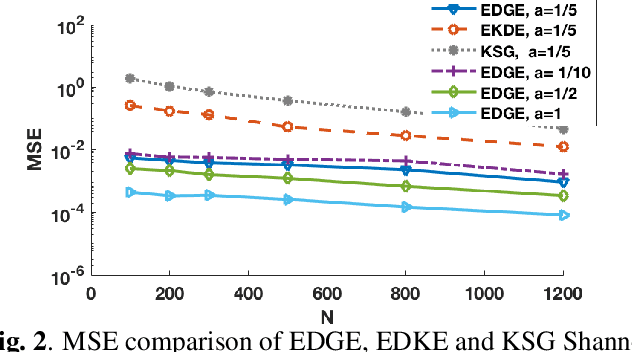
We propose a unified method for empirical non-parametric estimation of general Mutual Information (MI) function between the random vectors in $\mathbb{R}^d$ based on $N$ i.i.d. samples. The proposed low complexity estimator is based on a bipartite graph, referred to as dependence graph. The data points are mapped to the vertices of this graph using randomized Locality Sensitive Hashing (LSH). The vertex and edge weights are defined in terms of marginal and joint hash collisions. For a given set of hash parameters $\epsilon(1), \ldots, \epsilon(k)$, a base estimator is defined as a weighted average of the transformed edge weights. The proposed estimator, called the ensemble dependency graph estimator (EDGE), is obtained as a weighted average of the base estimators, where the weights are computed offline as the solution of a linear programming problem. EDGE achieves optimal computational complexity $O(N)$, and can achieve the optimal parametric MSE rate of $O(1/N)$ if the density is $d$ times differentiable. To the best of our knowledge EDGE is the first non-parametric MI estimator that can achieve parametric MSE rates with linear time complexity.
Stylizing 3D Scene via Implicit Representation and HyperNetwork
May 27, 2021
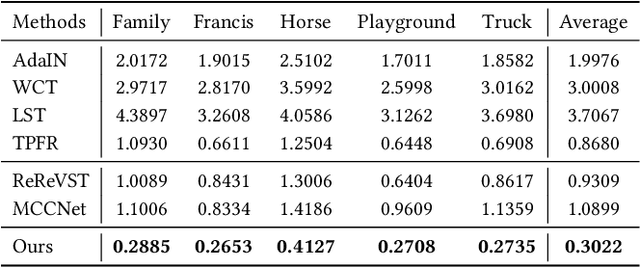
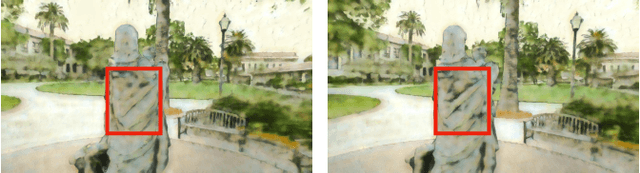
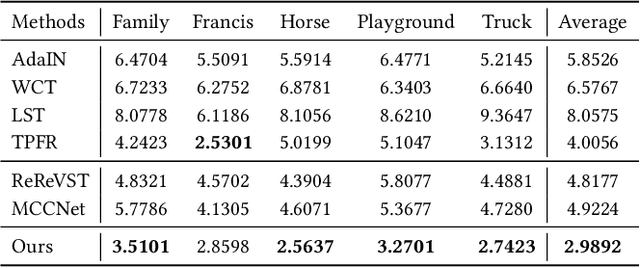
In this work, we aim to address the 3D scene stylization problem - generating stylized images of the scene at arbitrary novel view angles. A straightforward solution is to combine existing novel view synthesis and image/video style transfer approaches, which often leads to blurry results or inconsistent appearance. Inspired by the high quality results of the neural radiance fields (NeRF) method, we propose a joint framework to directly render novel views with the desired style. Our framework consists of two components: an implicit representation of the 3D scene with the neural radiance field model, and a hypernetwork to transfer the style information into the scene representation. In particular, our implicit representation model disentangles the scene into the geometry and appearance branches, and the hypernetwork learns to predict the parameters of the appearance branch from the reference style image. To alleviate the training difficulties and memory burden, we propose a two-stage training procedure and a patch sub-sampling approach to optimize the style and content losses with the neural radiance field model. After optimization, our model is able to render consistent novel views at arbitrary view angles with arbitrary style. Both quantitative evaluation and human subject study have demonstrated that the proposed method generates faithful stylization results with consistent appearance across different views.
Conditional generator and multi-sourcecorrelation guided brain tumor segmentation with missing MR modalities
May 27, 2021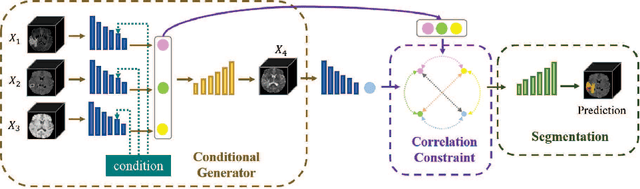
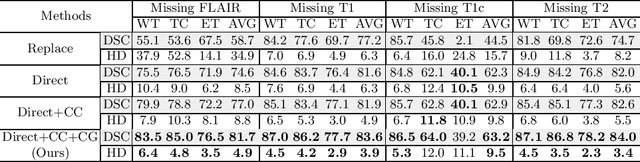
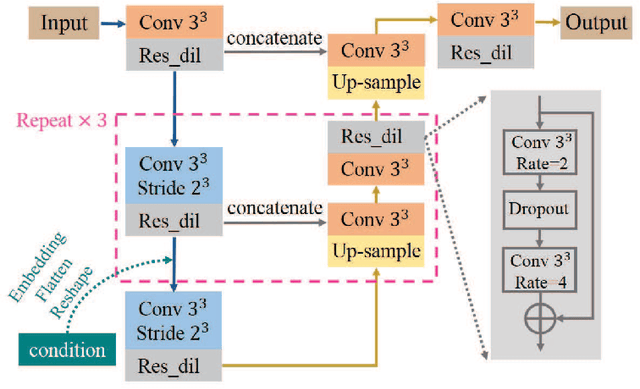
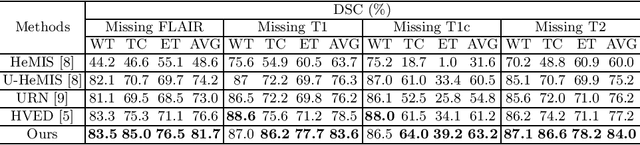
Brain tumor is one of the most high-risk cancers which causes the 5-year survival rate of only about 36%. Accurate diagnosis of brain tumor is critical for the treatment planning. However, complete data are not always available in clinical scenarios. In this paper, we propose a novel brain tumor segmentation network to deal with the missing data issue. To compensate for missing data, we propose to use a conditional generator to generate the missing modality under the condition of the available modalities. As the multi-modality has a strong correlation in tumor region, we design a correlation constraint network to leverage the multi-source information. On the one hand, the correlation constraint network can help the conditional generator to generate the missing modality which should keep the multi-source correlation with the available modalities. On the other hand, it can guide the segmentation network to learn the correlated feature representations to improve the segmentation performance. The proposed network consists of a conditional generator, a correlation constraint network and a segmentation network. We carried out extensive experiments on BraTS 2018 dataset to evaluate the proposed method.The experimental results demonstrate the importance of the proposed components and the superior performance of the proposed method com-pared with the state-of-the-art methods
PoseContrast: Class-Agnostic Object Viewpoint Estimation in the Wild with Pose-Aware Contrastive Learning
May 12, 2021
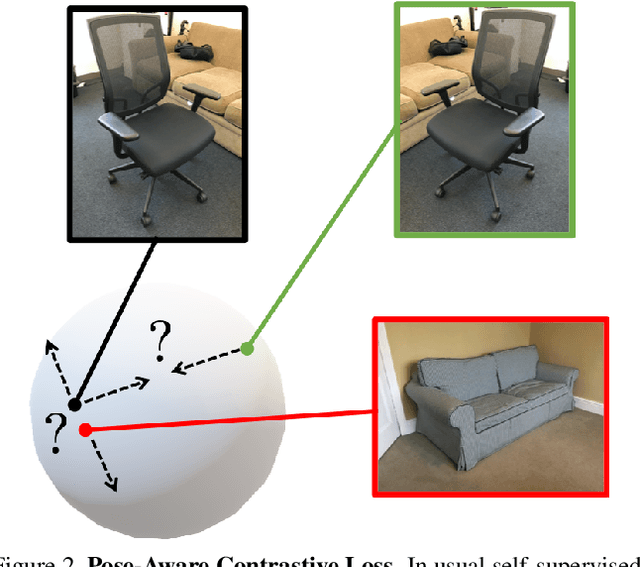
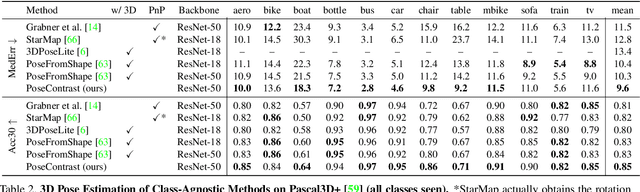
Motivated by the need of estimating the pose (viewpoint) of arbitrary objects in the wild, which is only covered by scarce and small datasets, we consider the challenging problem of class-agnostic 3D object pose estimation, with no 3D shape knowledge. The idea is to leverage features learned on seen classes to estimate the pose for classes that are unseen, yet that share similar geometries and canonical frames with seen classes. For this, we train a direct pose estimator in a class-agnostic way by sharing weights across all object classes, and we introduce a contrastive learning method that has three main ingredients: (i) the use of pre-trained, self-supervised, contrast-based features; (ii) pose-aware data augmentations; (iii) a pose-aware contrastive loss. We experimented on Pascal3D+ and ObjectNet3D, as well as Pix3D in a cross-dataset fashion, with both seen and unseen classes. We report state-of-the-art results, including against methods that use additional shape information, and also when we use detected bounding boxes.
Improving the Lexical Ability of Pretrained Language Models for Unsupervised Neural Machine Translation
Apr 14, 2021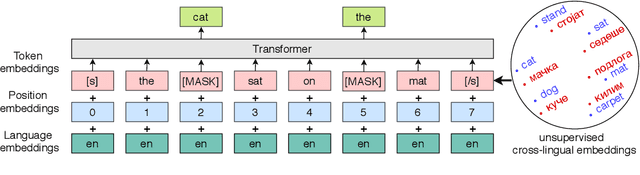
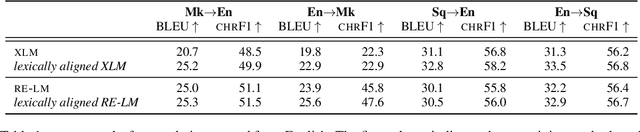
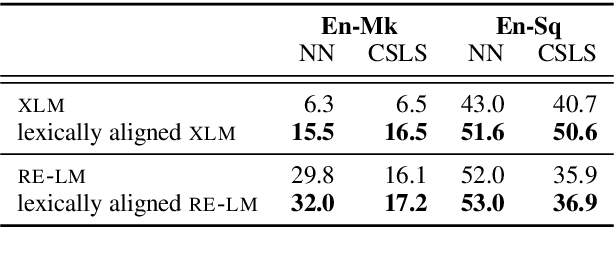
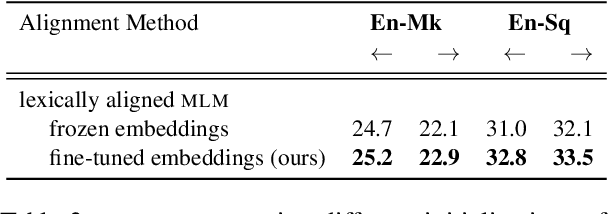
Successful methods for unsupervised neural machine translation (UNMT) employ crosslingual pretraining via self-supervision, often in the form of a masked language modeling or a sequence generation task, which requires the model to align the lexical- and high-level representations of the two languages. While cross-lingual pretraining works for similar languages with abundant corpora, it performs poorly in low-resource and distant languages. Previous research has shown that this is because the representations are not sufficiently aligned. In this paper, we enhance the bilingual masked language model pretraining with lexical-level information by using type-level cross-lingual subword embeddings. Empirical results demonstrate improved performance both on UNMT (up to 4.5 BLEU) and bilingual lexicon induction using our method compared to a UNMT baseline.
Understanding top-down attention using task-oriented ablation design
Jun 08, 2021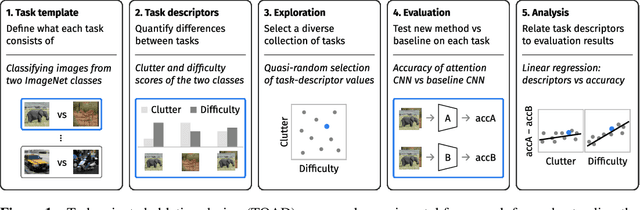
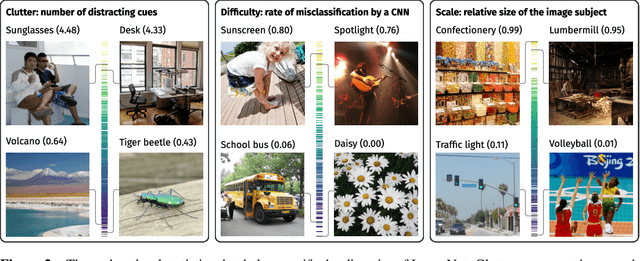
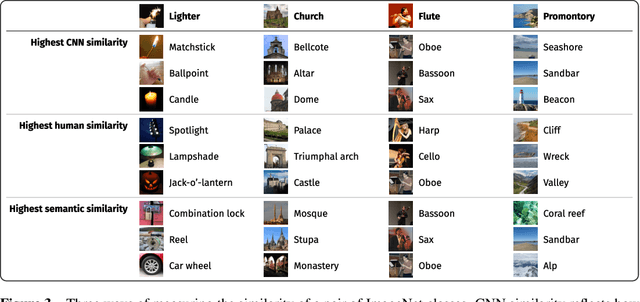
Top-down attention allows neural networks, both artificial and biological, to focus on the information most relevant for a given task. This is known to enhance performance in visual perception. But it remains unclear how attention brings about its perceptual boost, especially when it comes to naturalistic settings like recognising an object in an everyday scene. What aspects of a visual task does attention help to deal with? We aim to answer this with a computational experiment based on a general framework called task-oriented ablation design. First we define a broad range of visual tasks and identify six factors that underlie task variability. Then on each task we compare the performance of two neural networks, one with top-down attention and one without. These comparisons reveal the task-dependence of attention's perceptual boost, giving a clearer idea of the role attention plays. Whereas many existing cognitive accounts link attention to stimulus-level variables, such as visual clutter and object scale, we find greater explanatory power in system-level variables that capture the interaction between the model, the distribution of training data and the task format. This finding suggests a shift in how attention is studied could be fruitful. We make publicly available our code and results, along with statistics relevant to ImageNet-based experiments beyond this one. Our contribution serves to support the development of more human-like vision models and the design of more informative machine-learning experiments.
Priberam Labs at the NTCIR-15 SHINRA2020-ML: Classification Task
May 12, 2021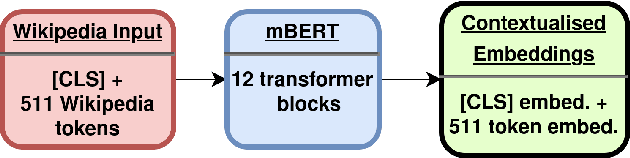
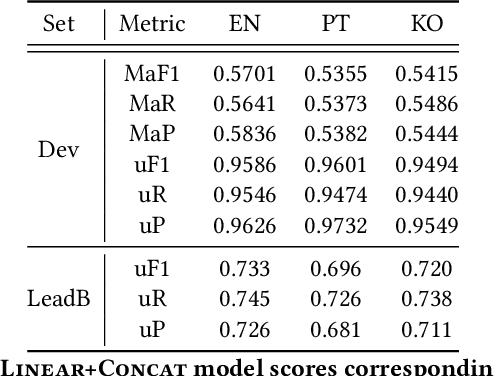
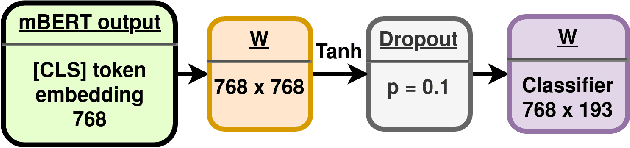
Wikipedia is an online encyclopedia available in 285 languages. It composes an extremely relevant Knowledge Base (KB), which could be leveraged by automatic systems for several purposes. However, the structure and organisation of such information are not prone to automatic parsing and understanding and it is, therefore, necessary to structure this knowledge. The goal of the current SHINRA2020-ML task is to leverage Wikipedia pages in order to categorise their corresponding entities across 268 hierarchical categories, belonging to the Extended Named Entity (ENE) ontology. In this work, we propose three distinct models based on the contextualised embeddings yielded by Multilingual BERT. We explore the performances of a linear layer with and without explicit usage of the ontology's hierarchy, and a Gated Recurrent Units (GRU) layer. We also test several pooling strategies to leverage BERT's embeddings and selection criteria based on the labels' scores. We were able to achieve good performance across a large variety of languages, including those not seen during the fine-tuning process (zero-shot languages).
Aggregation of Classifiers: A Justifiable Information Granularity Approach
Mar 15, 2017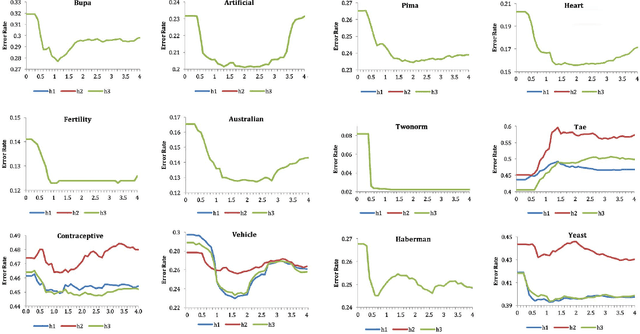
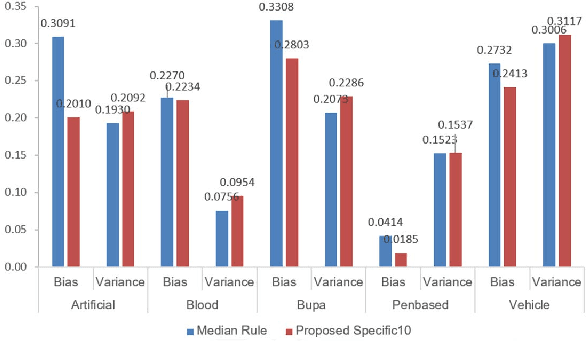

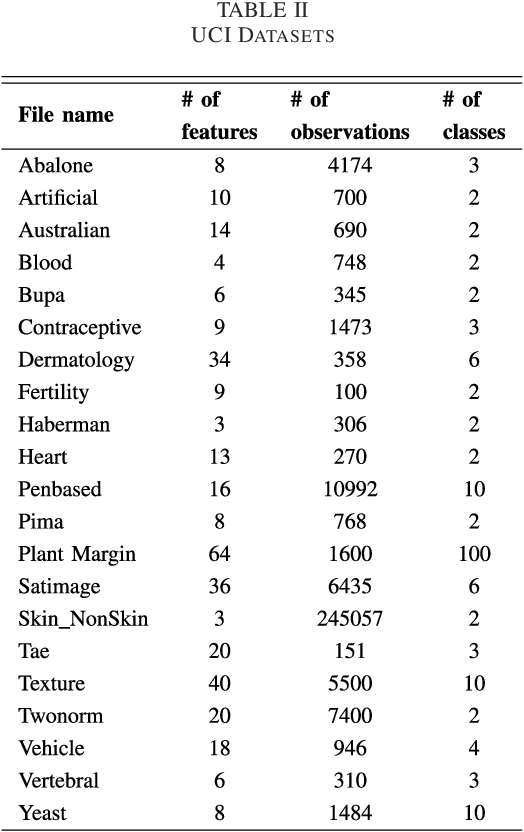
In this study, we introduce a new approach to combine multi-classifiers in an ensemble system. Instead of using numeric membership values encountered in fixed combining rules, we construct interval membership values associated with each class prediction at the level of meta-data of observation by using concepts of information granules. In the proposed method, uncertainty (diversity) of findings produced by the base classifiers is quantified by interval-based information granules. The discriminative decision model is generated by considering both the bounds and the length of the obtained intervals. We select ten and then fifteen learning algorithms to build a heterogeneous ensemble system and then conducted the experiment on a number of UCI datasets. The experimental results demonstrate that the proposed approach performs better than the benchmark algorithms including six fixed combining methods, one trainable combining method, AdaBoost, Bagging, and Random Subspace.
Comparison of Short Blocklength Slepian-Wolf Coding for Key Reconciliation
Mar 21, 2021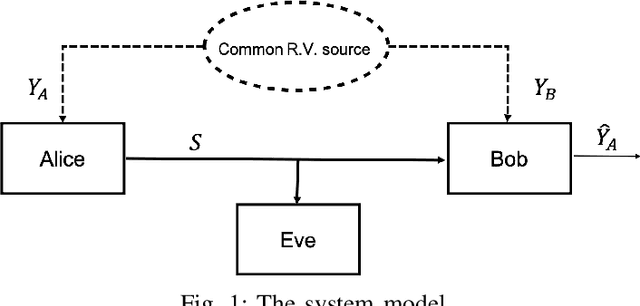
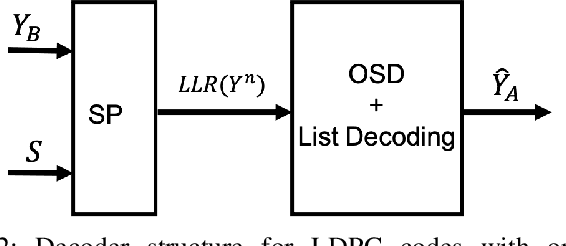
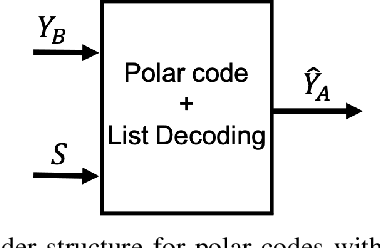
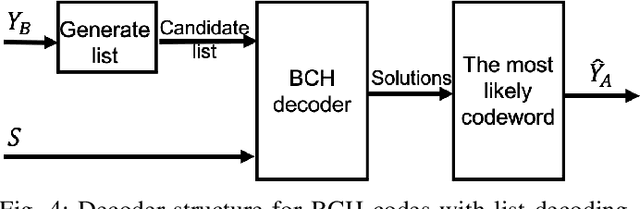
We focus Slepian-Wolf (SW) coding in the short blocklength for reconciliation in secret key generation and physical unclonable functions. In the problem formulation, two legitimate parties wish to generate a common secret key from a noisy observation of a common random source in the presence of a passive eavesdropper. We consider three different families of codes for key reconciliation. The selected codes show promising performances in information transmission in the short block-length regime. We implement and compare the performance of different codes for SW reconciliation in the terms of reliability and decoding complexity.
InScript: Narrative texts annotated with script information
Mar 15, 2017

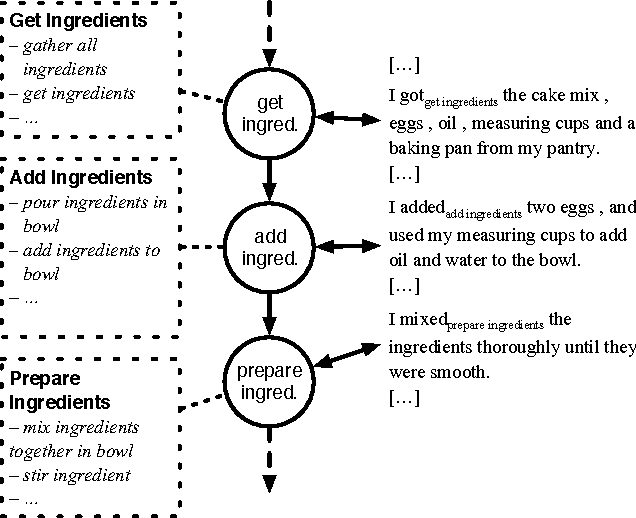
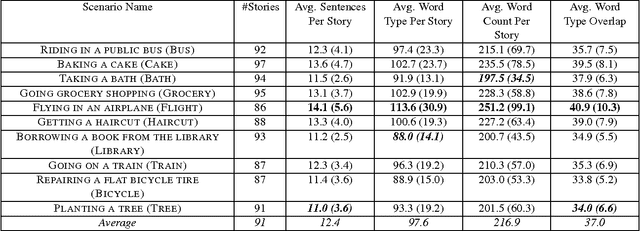
This paper presents the InScript corpus (Narrative Texts Instantiating Script structure). InScript is a corpus of 1,000 stories centered around 10 different scenarios. Verbs and noun phrases are annotated with event and participant types, respectively. Additionally, the text is annotated with coreference information. The corpus shows rich lexical variation and will serve as a unique resource for the study of the role of script knowledge in natural language processing.
* Paper accepted at LREC 2016, 9 pages, The corpus can be downloaded at: http://www.sfb1102.uni-saarland.de/?page_id=2582