 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Lexical Ability of Pretrained Language Models for Unsupervised Neural Machine Translation
Paper and Code
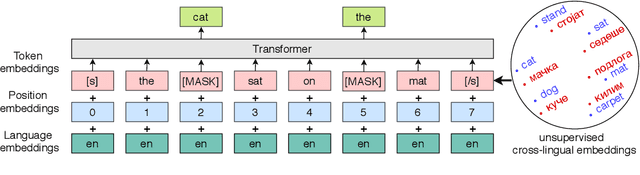
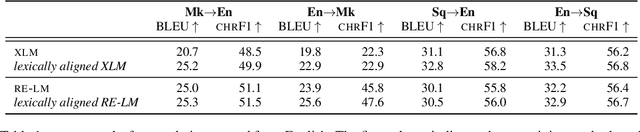
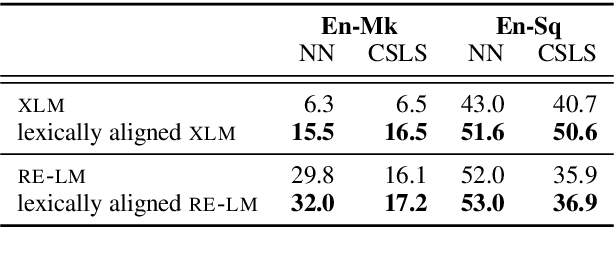
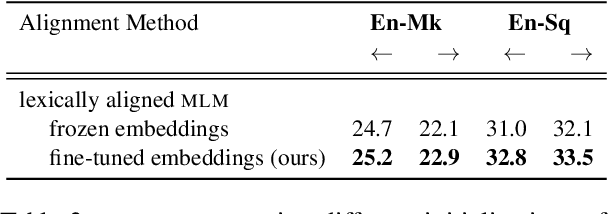
Successful methods for unsupervised neural machine translation (UNMT) employ crosslingual pretraining via self-supervision, often in the form of a masked language modeling or a sequence generation task, which requires the model to align the lexical- and high-level representations of the two languages. While cross-lingual pretraining works for similar languages with abundant corpora, it performs poorly in low-resource and distant languages. Previous research has shown that this is because the representations are not sufficiently aligned. In this paper, we enhance the bilingual masked language model pretraining with lexical-level information by using type-level cross-lingual subword embeddings. Empirical results demonstrate improved performance both on UNMT (up to 4.5 BLEU) and bilingual lexicon induction using our method compared to a UNMT baseline.