 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hybrid Machine Learning Forecasts for the UEFA EURO 2020
Jun 07, 2021
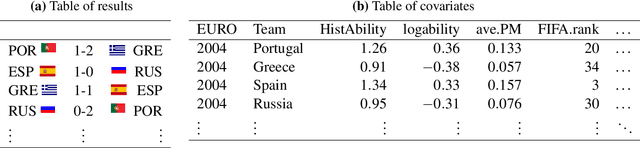
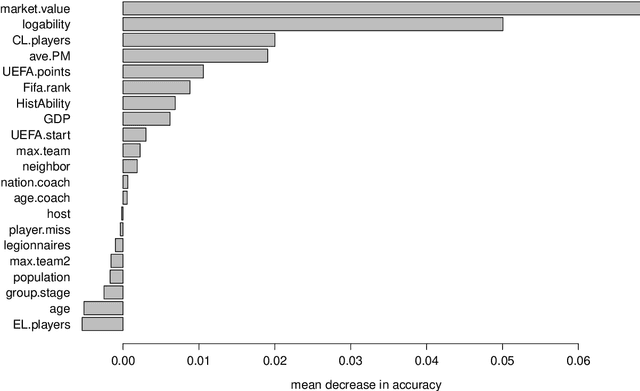
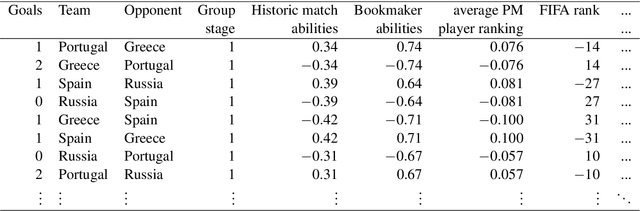
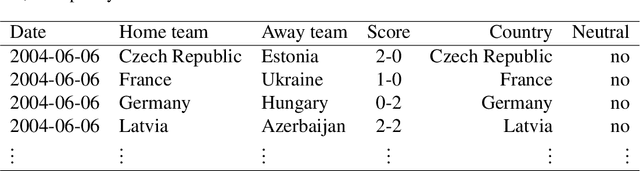
Three state-of-the-art statistical ranking methods for forecasting football matches are combined with several other predictors in a hybrid machine learning model. Namely an ability estimate for every team based on historic matches; an ability estimate for every team based on bookmaker consensus; average plus-minus player ratings based on their individual performances in their home clubs and national teams; and further team covariates (e.g., market value, team structure) and country-specific socio-economic factors (population, GDP). The proposed combined approach is used for learning the number of goals scored in the matches from the four previous UEFA EUROs 2004-2016 and then applied to current information to forecast the upcoming UEFA EURO 2020. Based on the resulting estimates, the tournament is simulated repeatedly and winning probabilities are obtained for all teams. A random forest model favors the current World Champion France with a winning probability of 14.8% before England (13.5%) and Spain (12.3%). Additionally, we provide survival probabilities for all teams and at all tournament stages.
Parallelizing Contextual Linear Bandits
May 21, 2021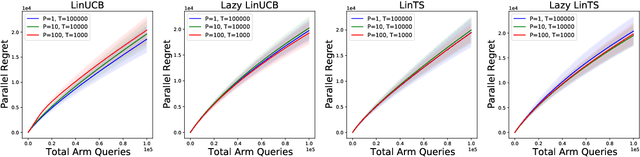
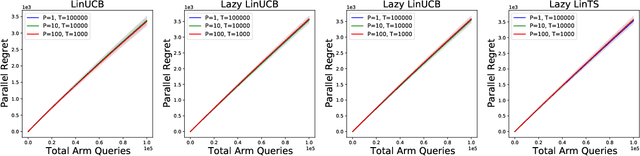

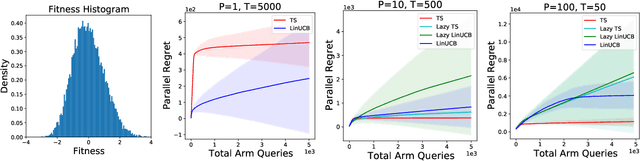
Standard approaches to decision-making under uncertainty focus on sequential exploration of the space of decisions. However, \textit{simultaneously} proposing a batch of decisions, which leverages available resources for parallel experimentation, has the potential to rapidly accelerate exploration. We present a family of (parallel) contextual linear bandit algorithms, whose regret is nearly identical to their perfectly sequential counterparts -- given access to the same total number of oracle queries -- up to a lower-order "burn-in" term that is dependent on the context-set geometry. We provide matching information-theoretic lower bounds on parallel regret performance to establish our algorithms are asymptotically optimal in the time horizon. Finally, we also present an empirical evaluation of these parallel algorithms in several domains, including materials discovery and biological sequence design problems, to demonstrate the utility of parallelized bandits in practical settings.
Augmented Tensor Decomposition with Stochastic Optimization
Jun 15, 2021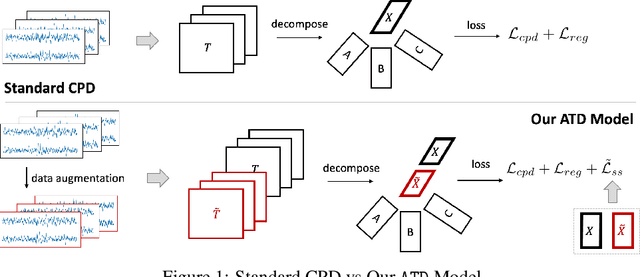

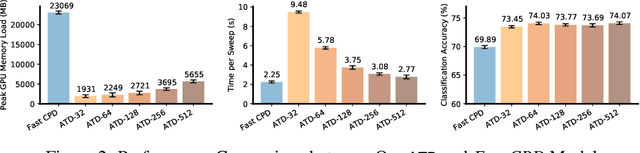
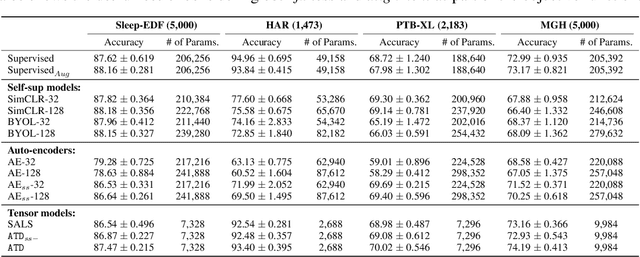
Tensor decompositions are powerful tools for dimensionality reduction and feature interpretation of multidimensional data such as signals. Existing tensor decomposition objectives (e.g., Frobenius norm) are designed for fitting raw data under statistical assumptions, which may not align with downstream classification tasks. Also, real-world tensor data are usually high-ordered and have large dimensions with millions or billions of entries. Thus, it is expensive to decompose the whole tensor with traditional algorithms. In practice, raw tensor data also contains redundant information while data augmentation techniques may be used to smooth out noise in samples. This paper addresses the above challenges by proposing augmented tensor decomposition (ATD), which effectively incorporates data augmentations to boost downstream classification. To reduce the memory footprint of the decomposition, we propose a stochastic algorithm that updates the factor matrices in a batch fashion. We evaluate ATD on multiple signal datasets. It shows comparable or better performance (e.g., up to 15% in accuracy) over self-supervised and autoencoder baselines with less than 5% of model parameters, achieves 0.6% ~ 1.3% accuracy gain over other tensor-based baselines, and reduces the memory footprint by 9X when compared to standard tensor decomposition algorithms.
Neural Abstractive Unsupervised Summarization of Online News Discussions
Jun 07, 2021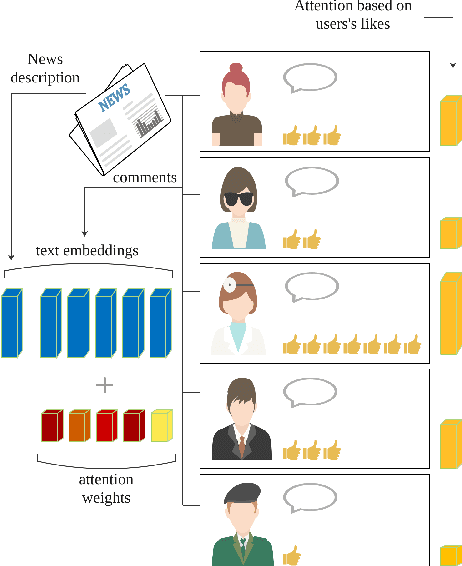
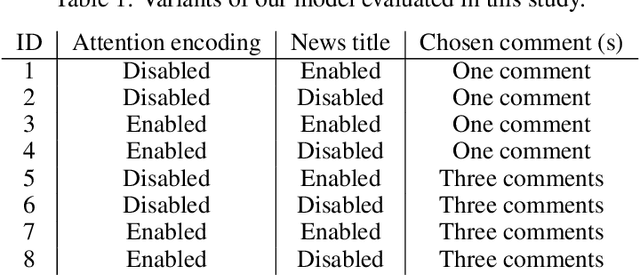
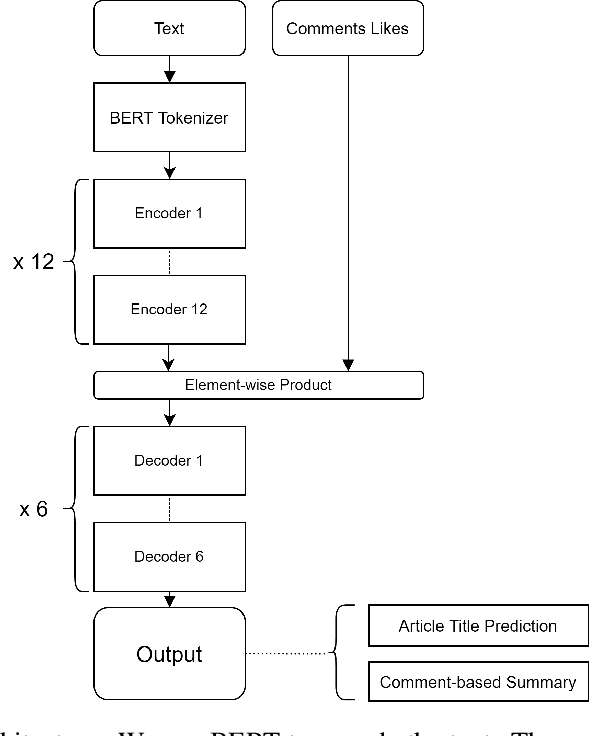
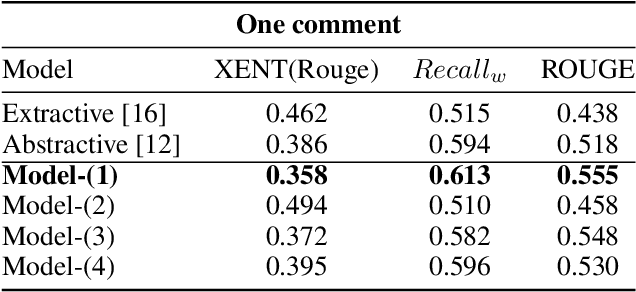
Summarization has usually relied on gold standard summaries to train extractive or abstractive models. Social media brings a hurdle to summarization techniques since it requires addressing a multi-document multi-author approach. We address this challenging task by introducing a novel method that generates abstractive summaries of online news discussions. Our method extends a BERT-based architecture, including an attention encoding that fed comments' likes during the training stage. To train our model, we define a task which consists of reconstructing high impact comments based on popularity (likes). Accordingly, our model learns to summarize online discussions based on their most relevant comments. Our novel approach provides a summary that represents the most relevant aspects of a news item that users comment on, incorporating the social context as a source of information to summarize texts in online social networks. Our model is evaluated using ROUGE scores between the generated summary and each comment on the thread. Our model, including the social attention encoding, significantly outperforms both extractive and abstractive summarization methods based on such evaluation.
Why Should I Trust a Model is Private? Using Shifts in Model Explanation for Evaluating Privacy-Preserving Emotion Recognition Model
Apr 18, 2021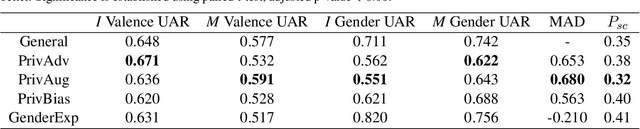
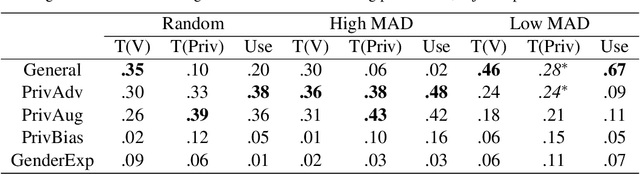
Privacy preservation is a crucial component of any real-world application. Yet, in applications relying on machine learning backends, this is challenging because models often capture more than a designer may have envisioned, resulting in the potential leakage of sensitive information. For example, emotion recognition models are susceptible to learning patterns between the target variable and other sensitive variables, patterns that can be maliciously re-purposed to obtain protected information. In this paper, we concentrate on using interpretable methods to evaluate a model's efficacy to preserve privacy with respect to sensitive variables. We focus on saliency-based explanations, explanations that highlight regions of the input text, which allows us to understand how model explanations shift when models are trained to preserve privacy. We show how certain commonly-used methods that seek to preserve privacy might not align with human perception of privacy preservation. We also show how some of these induce spurious correlations in the model between the input and the primary as well as secondary task, even if the improvement in evaluation metric is significant. Such correlations can hence lead to false assurances about the perceived privacy of the model because especially when used in cross corpus conditions. We conduct crowdsourcing experiments to evaluate the inclination of the evaluators to choose a particular model for a given task when model explanations are provided, and find that correlation of interpretation differences with sociolinguistic biases can be used as a proxy for user trust.
Deep Proxy Causal Learning and its Application to Confounded Bandit Policy Evaluation
Jun 07, 2021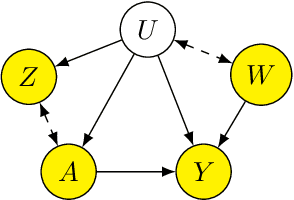
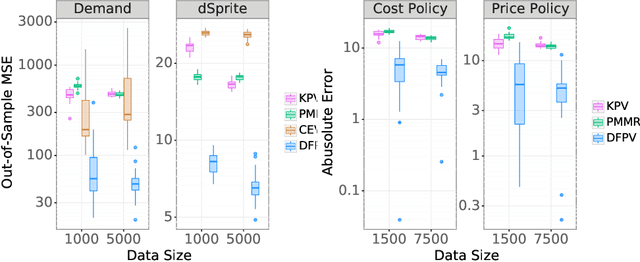

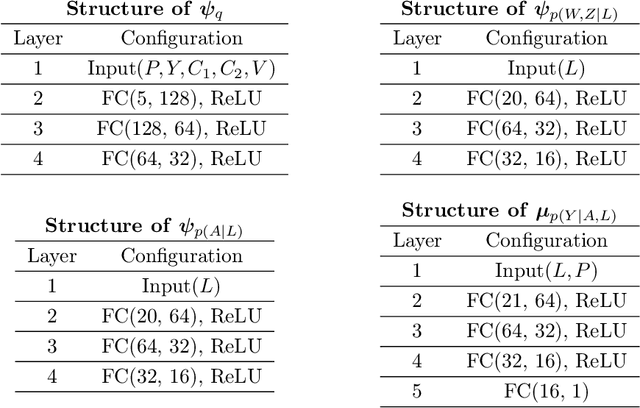
Proxy causal learning (PCL) is a method for estimating the causal effect of treatments on outcomes in the presence of unobserved confounding, using proxies (structured side information) for the confounder. This is achieved via two-stage regression: in the first stage, we model relations among the treatment and proxies; in the second stage, we use this model to learn the effect of treatment on the outcome, given the context provided by the proxies. PCL guarantees recovery of the true causal effect, subject to identifiability conditions. We propose a novel method for PCL, the deep feature proxy variable method (DFPV), to address the case where the proxies, treatments, and outcomes are high-dimensional and have nonlinear complex relationships, as represented by deep neural network features. We show that DFPV outperforms recent state-of-the-art PCL methods on challenging synthetic benchmarks, including settings involving high dimensional image data. Furthermore, we show that PCL can be applied to off-policy evaluation for the confounded bandit problem, in which DFPV also exhibits competitive performance.
Bilateral Personalized Dialogue Generation with Dynamic Persona-Aware Fusion
Jun 15, 2021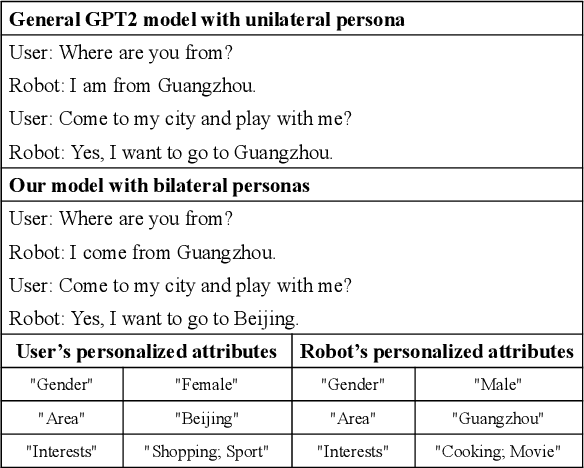
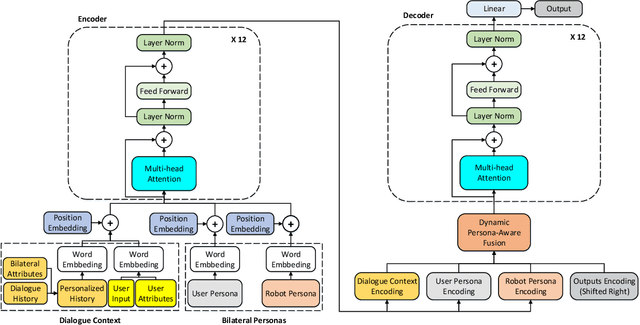
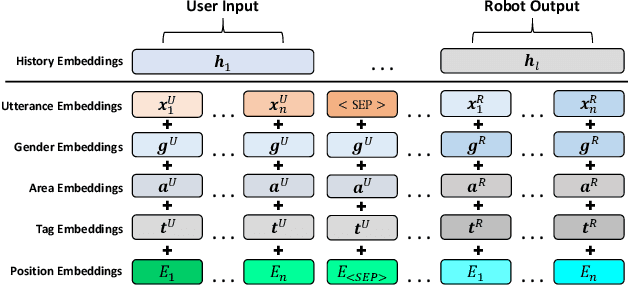
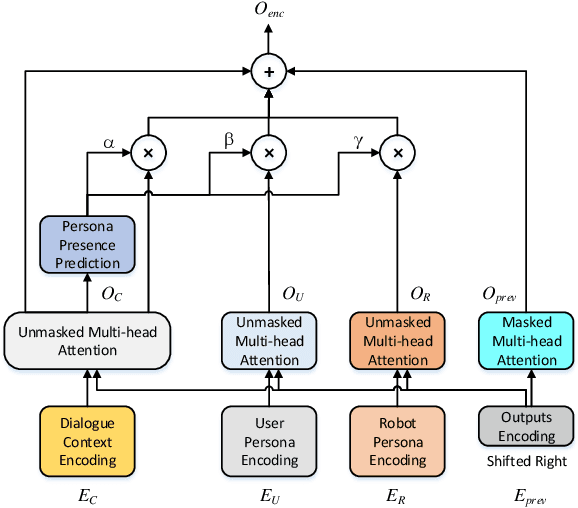
Generating personalized responses is one of the major challenges in natural human-robot interaction. Current researches in this field mainly focus on generating responses consistent with the robot's pre-assigned persona, while ignoring the user's persona. Such responses may be inappropriate or even offensive, which may lead to the bad user experience. Therefore, we propose a bilateral personalized dialogue generation (BPDG) method with dynamic persona-aware fusion via multi-task transfer learning to generate responses consistent with both personas. The proposed method aims to accomplish three learning tasks: 1) an encoder is trained with dialogue utterances added with corresponded personalized attributes and relative position (language model task), 2) a dynamic persona-aware fusion module predicts the persona presence to adaptively fuse the contextual and bilateral personas encodings (persona prediction task) and 3) a decoder generates natural, fluent and personalized responses (dialogue generation task). To make the generated responses more personalized and bilateral persona-consistent, the Conditional Mutual Information Maximum (CMIM) criterion is adopted to select the final response from the generated candidates. The experimental results show that the proposed method outperforms several state-of-the-art methods in terms of both automatic and manual evaluations.
A Semi-Personalized System for User Cold Start Recommendation on Music Streaming Apps
Jun 07, 2021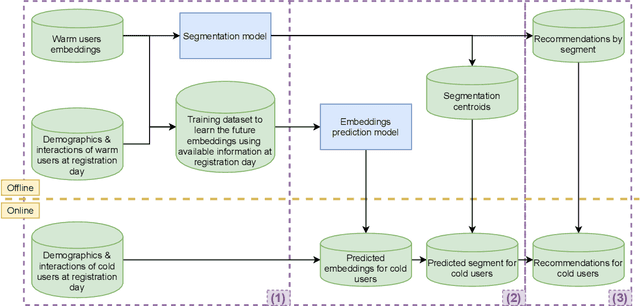
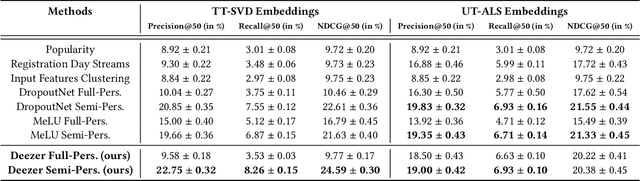
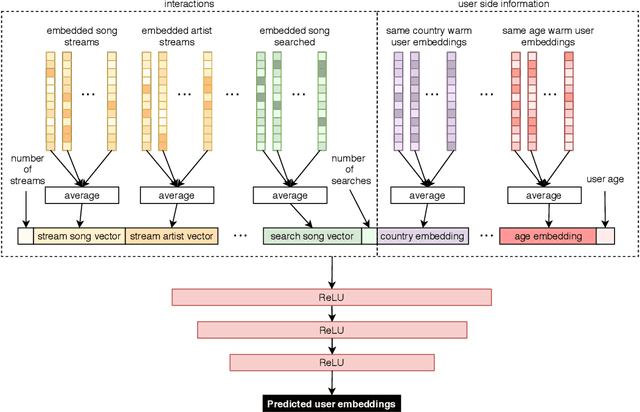

Music streaming services heavily rely on recommender systems to improve their users' experience, by helping them navigate through a large musical catalog and discover new songs, albums or artists. However, recommending relevant and personalized content to new users, with few to no interactions with the catalog, is challenging. This is commonly referred to as the user cold start problem. In this applied paper, we present the system recently deployed on the music streaming service Deezer to address this problem. The solution leverages a semi-personalized recommendation strategy, based on a deep neural network architecture and on a clustering of users from heterogeneous sources of information. We extensively show the practical impact of this system and its effectiveness at predicting the future musical preferences of cold start users on Deezer, through both offline and online large-scale experiments. Besides, we publicly release our code as well as anonymized usage data from our experiments. We hope that this release of industrial resources will benefit future research on user cold start recommendation.
ReadTwice: Reading Very Large Documents with Memories
May 11, 2021
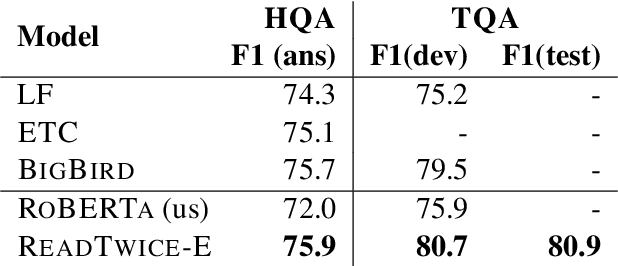
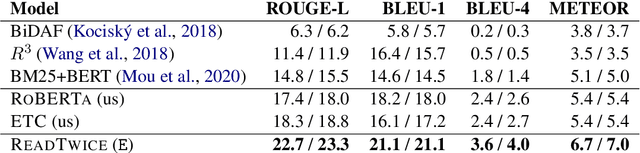
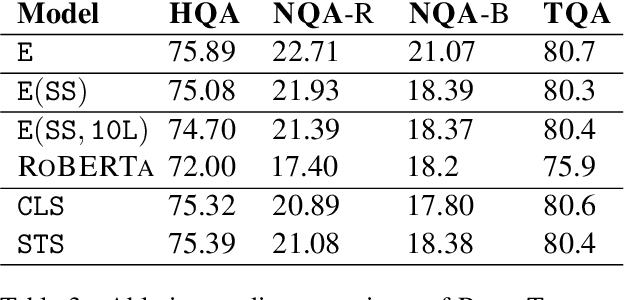
Knowledge-intensive tasks such as question answering often require assimilating information from different sections of large inputs such as books or article collections. We propose ReadTwice, a simple and effective technique that combines several strengths of prior approaches to model long-range dependencies with Transformers. The main idea is to read text in small segments, in parallel, summarizing each segment into a memory table to be used in a second read of the text. We show that the method outperforms models of comparable size on several question answering (QA) datasets and sets a new state of the art on the challenging NarrativeQA task, with questions about entire books. Source code and pre-trained checkpoints for ReadTwice can be found at https://goo.gle/research-readtwice.
$α$-Geodesical Skew Divergence
Apr 05, 2021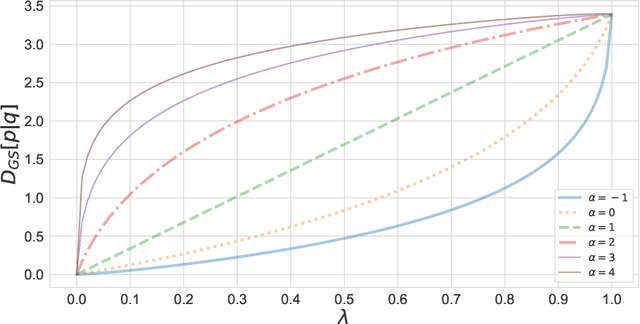
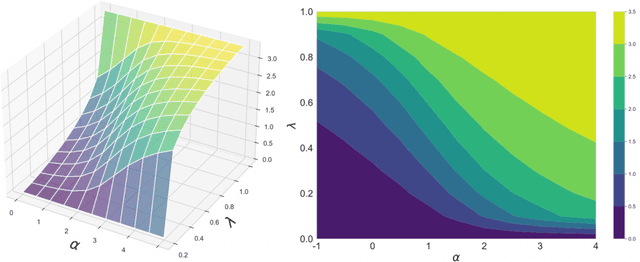
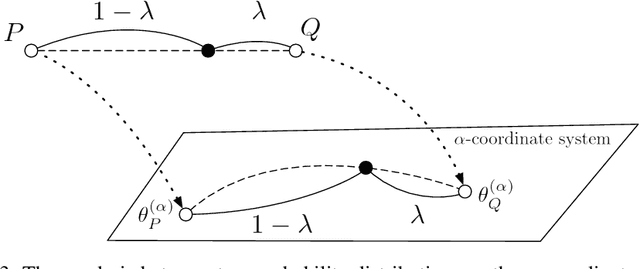
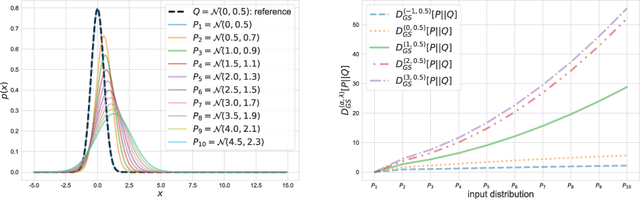
The asymmetric skew divergence smooths one of the distributions by mixing it, to a degree determined by the parameter $\lambda$, with the other distribution. Such divergence is an approximation of the KL divergence that does not require the target distribution to be absolutely continuous with respect to the source distribution. In this paper, an information geometric generalization of the skew divergence called the $\alpha$-geodesical skew divergence is proposed, and its properties are studied.