 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Field trial on Ocean Estimation for Multi-Vessel Multi-Float-based Active perception
Jun 17, 2021

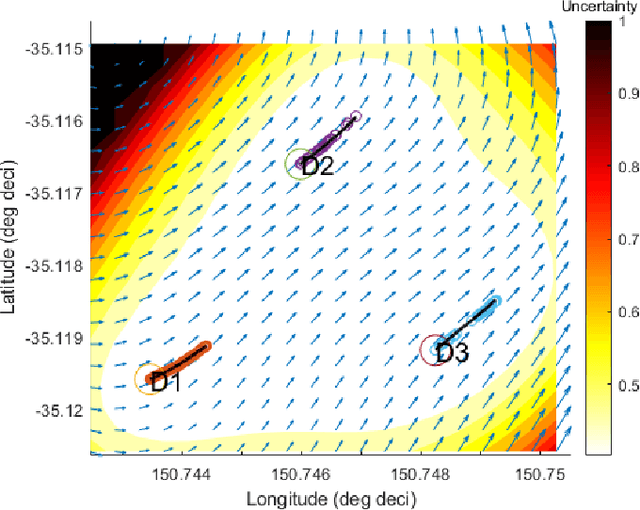
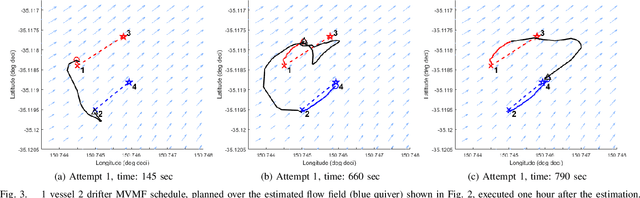
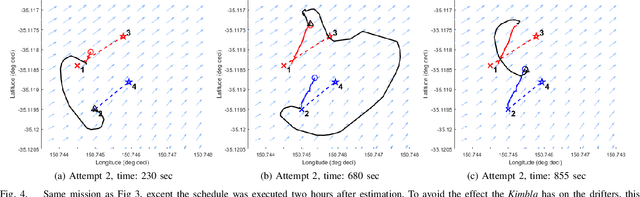
Marine vehicles have been used for various scientific missions where information over features of interest is collected. In order to maximise efficiency in collecting information over a large search space, we should be able to deploy a large number of autonomous vehicles that make a decision based on the latest understanding of the target feature in the environment. In our previous work, we have presented a hierarchical framework for the multi-vessel multi-float (MVMF) problem where surface vessels drop and pick up underactuated floats in a time-minimal way. In this paper, we present the field trial results using the framework with a number of drifters and floats. We discovered a number of important aspects that need to be considered in the proposed framework, and present the potential approaches to address the challenges.
HCGR: Hyperbolic Contrastive Graph Representation Learning for Session-based Recommendation
Jul 06, 2021

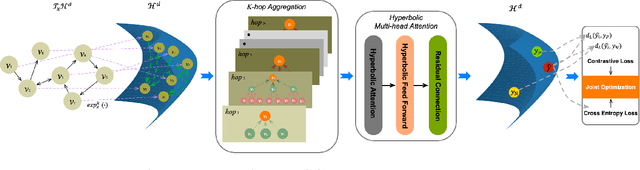
Session-based recommendation (SBR) learns users' preferences by capturing the short-term and sequential patterns from the evolution of user behaviors. Among the studies in the SBR field, graph-based approaches are a relatively powerful kind of way, which generally extract item information by message aggregation under Euclidean space. However, such methods can't effectively extract the hierarchical information contained among consecutive items in a session, which is critical to represent users' preferences. In this paper, we present a hyperbolic contrastive graph recommender (HCGR), a principled session-based recommendation framework involving Lorentz hyperbolic space to adequately capture the coherence and hierarchical representations of the items. Within this framework, we design a novel adaptive hyperbolic attention computation to aggregate the graph message of each user's preference in a session-based behavior sequence. In addition, contrastive learning is leveraged to optimize the item representation by considering the geodesic distance between positive and negative samples in hyperbolic space. Extensive experiments on four real-world datasets demonstrate that HCGR consistently outperforms state-of-the-art baselines by 0.43$\%$-28.84$\%$ in terms of $HitRate$, $NDCG$ and $MRR$.
A New Approach for Image Authentication Framework for Media Forensics Purpose
Oct 03, 2021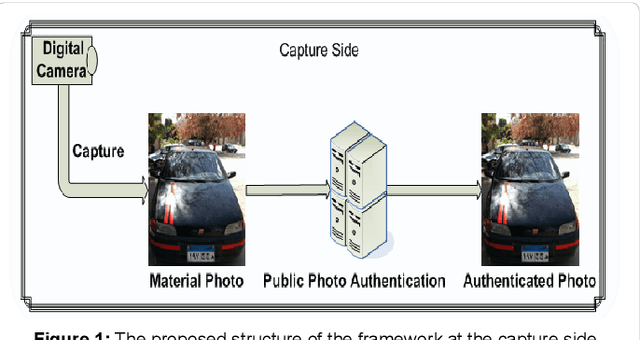

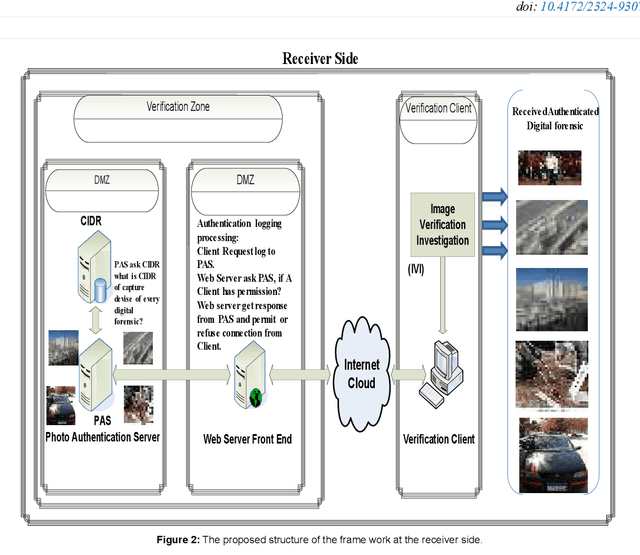
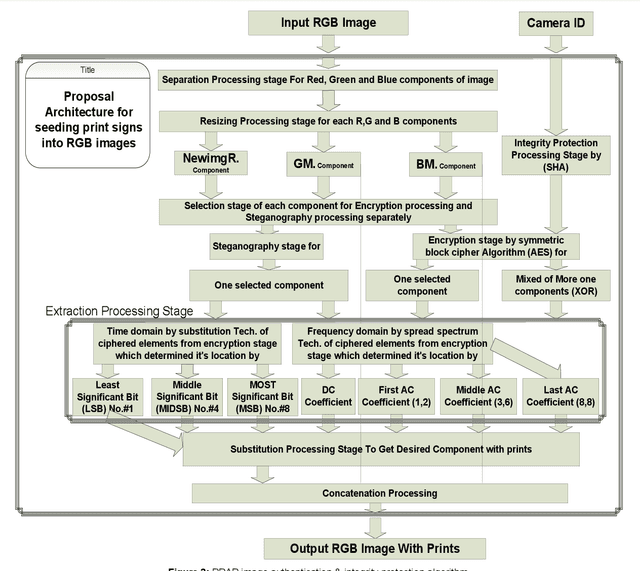
With the increasing widely spread digital media become using in most fields such as medical care, Oceanography, Exploration processing, security purpose, military fields and astronomy, evidence in criminals and more vital fields and then digital Images become have different appreciation values according to what is important of carried information by digital images. Due to the easy manipulation property of digital images (by proper computer software) makes us doubtful when are juries using digital images as forensic evidence in courts, especially, if the digital images are main evidence to demonstrate the relationship between suspects and the criminals. Obviously, here demonstrate importance of data Originality Protection methods to detect unauthorized process like modification or duplication and then enhancement protection of evidence to guarantee rights of incriminatory. In this paper, we shall introduce a novel digital forensic security framework for digital image authentication and originality identification techniques and related methodologies, algorithms and protocols that are applied on camera captured images. The approach depends on implanting secret code into RGB images that should indicate any unauthorized modification on the image under investigation. The secret code generation depends mainly on two main parameter types, namely the image characteristics and capturing device identifier. In this paper, the architecture framework will be analyzed, explained and discussed together with the associated protocols, algorithms and methodologies. Also, the secret code deduction and insertion techniques will be analyzed and discussed, in addition to the image benchmarking and quality testing techniques.
* 11 pages, 19 figures and one table
Novel EEG-based BCIs for Elderly Rehabilitation Enhancement
Oct 08, 2021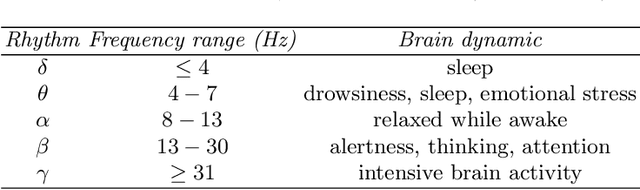
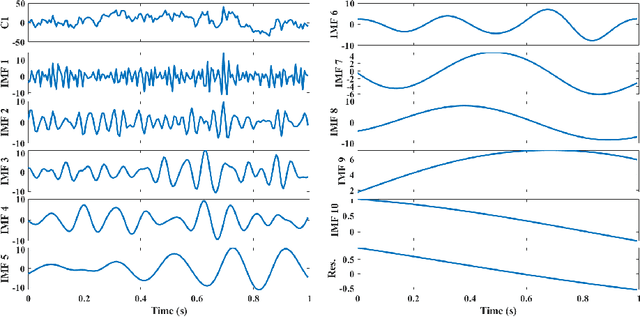
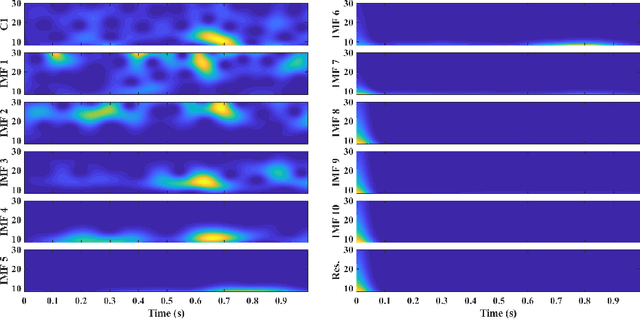

The ageing process may lead to cognitive and physical impairments, which may affect elderly everyday life. In recent years, the use of Brain Computer Interfaces (BCIs) based on Electroencephalography (EEG) has revealed to be particularly effective to promote and enhance rehabilitation procedures, especially by exploiting motor imagery experimental paradigms. Moreover, BCIs seem to increase patients' engagement and have proved to be reliable tools for elderly overall wellness improvement. However, EEG signals usually present a low signal-to-noise ratio and can be recorded for a limited time. Thus, irrelevant information and faulty samples could affect the BCI performance. Introducing a methodology that allows the extraction of informative components from the EEG signal while maintaining its intrinsic characteristics, may provide a solution to both the described issues: noisy data may be avoided by having only relevant components and combining relevant components may represent a good strategy to substitute the data without requiring long or repeated EEG recordings. Moreover, substituting faulty trials may significantly improve the classification performances of a BCI when translating imagined movement to rehabilitation systems. To this end, in this work the EEG signal decomposition by means of multivariate empirical mode decomposition is proposed to obtain its oscillatory modes, called Intrinsic Mode Functions (IMFs). Subsequently, a novel procedure for relevant IMF selection criterion based on the IMF time-frequency representation and entropy is provided. After having verified the reliability of the EEG signal reconstruction with the relevant IMFs only, the relevant IMFs are combined to produce new artificial data and provide new samples to use for BCI training.
Imposing Relation Structure in Language-Model Embeddings Using Contrastive Learning
Sep 04, 2021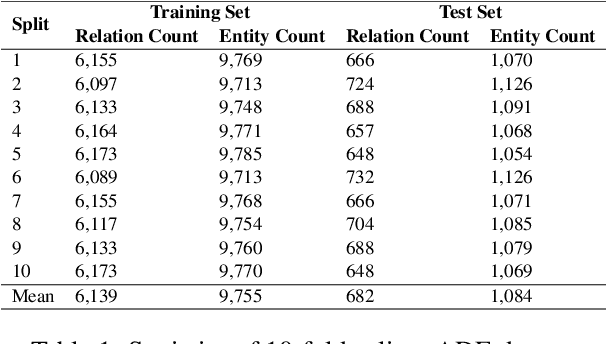
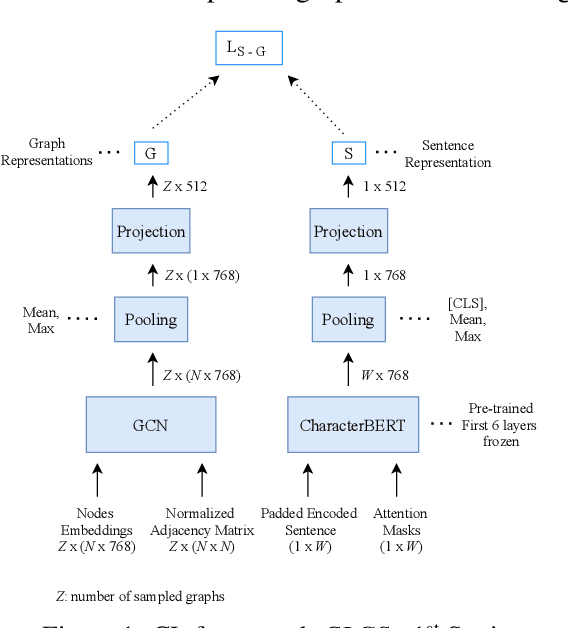
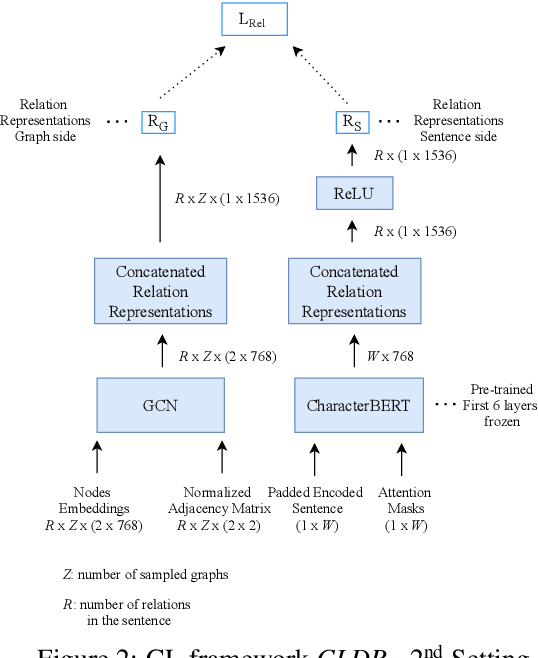
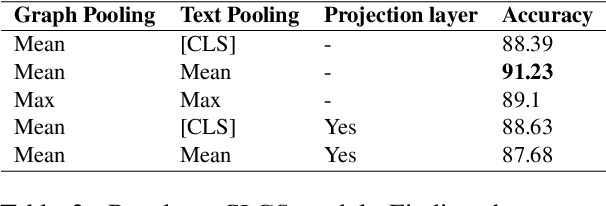
Though language model text embeddings have revolutionized NLP research, their ability to capture high-level semantic information, such as relations between entities in text, is limited. In this paper, we propose a novel contrastive learning framework that trains sentence embeddings to encode the relations in a graph structure. Given a sentence (unstructured text) and its graph, we use contrastive learning to impose relation-related structure on the token-level representations of the sentence obtained with a CharacterBERT (El Boukkouri et al.,2020) model. The resulting relation-aware sentence embeddings achieve state-of-the-art results on the relation extraction task using only a simple KNN classifier, thereby demonstrating the success of the proposed method. Additional visualization by a tSNE analysis shows the effectiveness of the learned representation space compared to baselines. Furthermore, we show that we can learn a different space for named entity recognition, again using a contrastive learning objective, and demonstrate how to successfully combine both representation spaces in an entity-relation task.
A Source-Criticism Debiasing Method for GloVe Embeddings
Jun 25, 2021
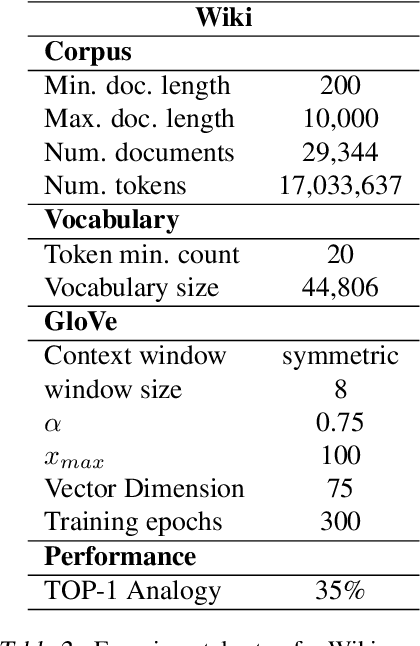
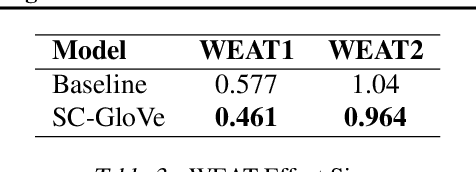
It is well-documented that word embeddings trained on large public corpora consistently exhibit known human social biases. Although many methods for debiasing exist, almost all fixate on completely eliminating biased information from the embeddings and often diminish training set size in the process. In this paper, we present a simple yet effective method for debiasing GloVe word embeddings (Pennington et al., 2014) which works by incorporating explicit information about training set bias rather than removing biased data outright. Our method runs quickly and efficiently with the help of a fast bias gradient approximation method from Brunet et al. (2019). As our approach is akin to the notion of 'source criticism' in the humanities, we term our method Source-Critical GloVe (SC-GloVe). We show that SC-GloVe reduces the effect size on Word Embedding Association Test (WEAT) sets without sacrificing training data or TOP-1 performance.
OFDM-guided Deep Joint Source Channel Coding for Wireless Multipath Fading Channels
Sep 11, 2021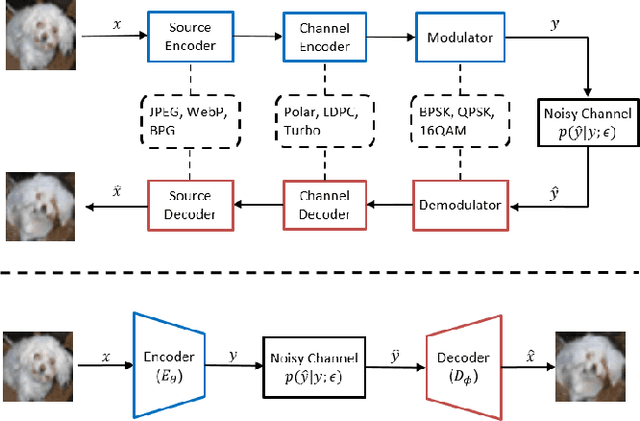
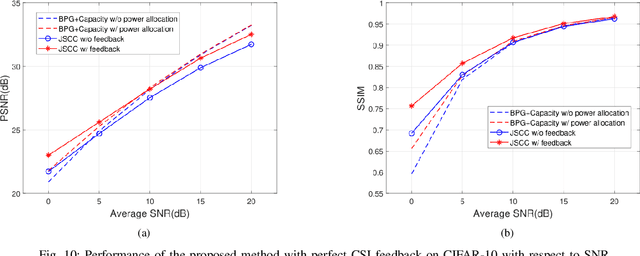

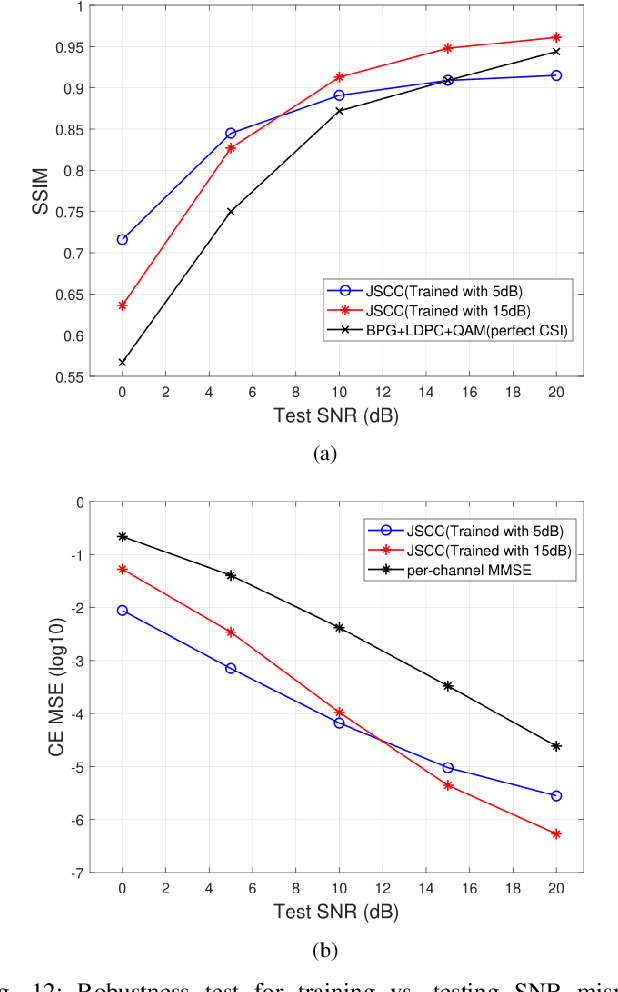
We investigate joint source channel coding (JSCC) for wireless image transmission over multipath fading channels. Inspired by recent works on deep learning based JSCC and model-based learning methods, we combine an autoencoder with orthogonal frequency division multiplexing (OFDM) to cope with multipath fading. The proposed encoder and decoder use convolutional neural networks (CNNs) and directly map the source images to complex-valued baseband samples for OFDM transmission. The multipath channel and OFDM are represented by non-trainable (deterministic) but differentiable layers so that the system can be trained end-to-end. Furthermore, our JSCC decoder further incorporates explicit channel estimation, equalization, and additional subnets to enhance the performance. The proposed method exhibits 2.5 -- 4 dB SNR gain for the equivalent image quality compared to conventional schemes that employ state-of-the-art but separate source and channel coding such as BPG and LDPC. The performance further improves when the system incorporates the channel state information (CSI) feedback. The proposed scheme is robust against OFDM signal clipping and parameter mismatch for the channel model used in training and evaluation.
Topos and Stacks of Deep Neural Networks
Jul 12, 2021
Every known artificial deep neural network (DNN) corresponds to an object in a canonical Grothendieck's topos; its learning dynamic corresponds to a flow of morphisms in this topos. Invariance structures in the layers (like CNNs or LSTMs) correspond to Giraud's stacks. This invariance is supposed to be responsible of the generalization property, that is extrapolation from learning data under constraints. The fibers represent pre-semantic categories (Culioli, Thom), over which artificial languages are defined, with internal logics, intuitionist, classical or linear (Girard). Semantic functioning of a network is its ability to express theories in such a language for answering questions in output about input data. Quantities and spaces of semantic information are defined by analogy with the homological interpretation of Shannon's entropy (P.Baudot and D.B. 2015). They generalize the measures found by Carnap and Bar-Hillel (1952). Amazingly, the above semantical structures are classified by geometric fibrant objects in a closed model category of Quillen, then they give rise to homotopical invariants of DNNs and of their semantic functioning. Intentional type theories (Martin-Loef) organize these objects and fibrations between them. Information contents and exchanges are analyzed by Grothendieck's derivators.
Single-Server Private Linear Transformation: The Joint Privacy Case
Jun 09, 2021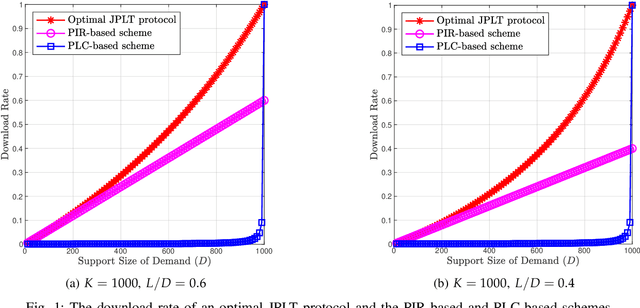
This paper introduces the problem of Private Linear Transformation (PLT) which generalizes the problems of private information retrieval and private linear computation. The PLT problem includes one or more remote server(s) storing (identical copies of) $K$ messages and a user who wants to compute $L$ independent linear combinations of a $D$-subset of messages. The objective of the user is to perform the computation by downloading minimum possible amount of information from the server(s), while protecting the identities of the $D$ messages required for the computation. In this work, we focus on the single-server setting of the PLT problem when the identities of the $D$ messages required for the computation must be protected jointly. We consider two different models, depending on whether the coefficient matrix of the required $L$ linear combinations generates a Maximum Distance Separable (MDS) code. We prove that the capacity for both models is given by $L/(K-D+L)$, where the capacity is defined as the supremum of all achievable download rates. Our converse proofs are based on linear-algebraic and information-theoretic arguments that establish connections between PLT schemes and linear codes. We also present an achievability scheme for each of the models being considered.
Rapid detection and recognition of whole brain activity in a freely behaving Caenorhabditis elegans
Sep 23, 2021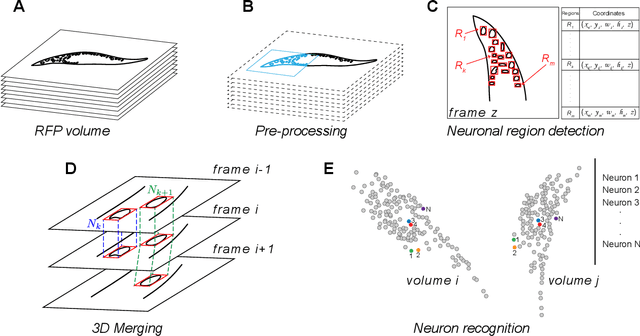

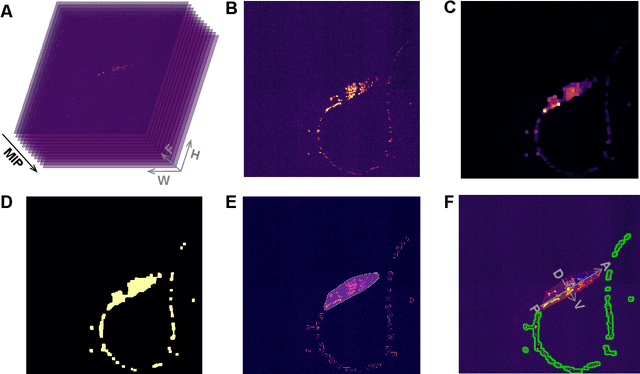
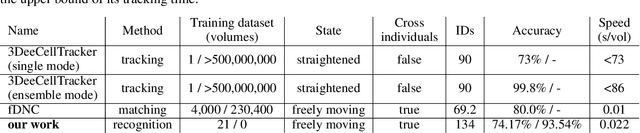
Advanced volumetric imaging methods and genetically encoded activity indicators have permitted a comprehensive characterization of whole brain activity at single neuron resolution in \textit{Caenorhabditis elegans}. The constant motion and deformation of the mollusc nervous system, however, impose a great challenge for a consistent identification of densely packed neurons in a behaving animal. Here, we propose a cascade solution for long-term and rapid recognition of head ganglion neurons in a freely moving \textit{C. elegans}. First, potential neuronal regions from a stack of fluorescence images are detected by a deep learning algorithm. Second, 2 dimensional neuronal regions are fused into 3 dimensional neuron entities. Third, by exploiting the neuronal density distribution surrounding a neuron and relative positional information between neurons, a multi-class artificial neural network transforms engineered neuronal feature vectors into digital neuronal identities. Under the constraint of a small number (20-40 volumes) of training samples, our bottom-up approach is able to process each volume - $1024 \times 1024 \times 18$ in voxels - in less than 1 second and achieves an accuracy of $91\%$ in neuronal detection and $74\%$ in neuronal recognition. Our work represents an important development towards a rapid and fully automated algorithm for decoding whole brain activity underlying natural animal behaviors.