 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Self-Supervised Multi-Object Tracking with Cross-Input Consistency
Nov 10, 2021
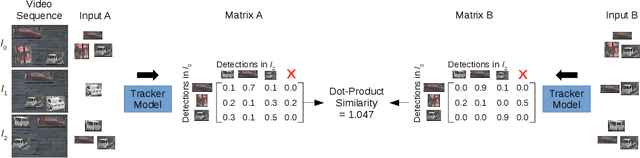
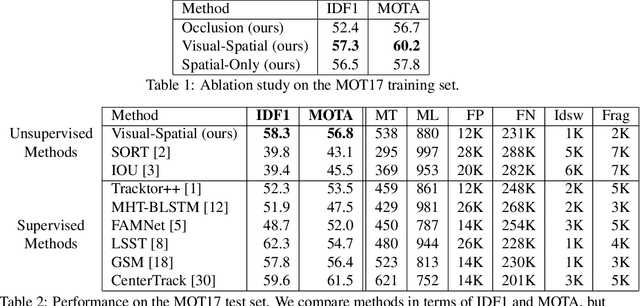
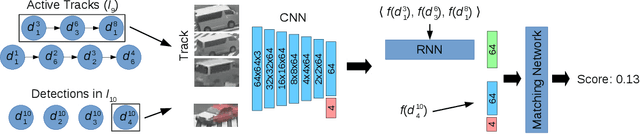
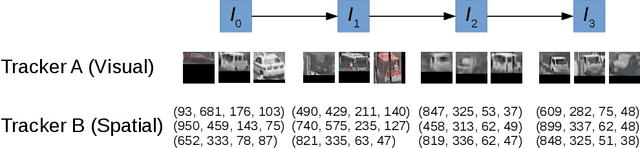
In this paper, we propose a self-supervised learning procedure for training a robust multi-object tracking (MOT) model given only unlabeled video. While several self-supervisory learning signals have been proposed in prior work on single-object tracking, such as color propagation and cycle-consistency, these signals cannot be directly applied for training RNN models, which are needed to achieve accurate MOT: they yield degenerate models that, for instance, always match new detections to tracks with the closest initial detections. We propose a novel self-supervisory signal that we call cross-input consistency: we construct two distinct inputs for the same sequence of video, by hiding different information about the sequence in each input. We then compute tracks in that sequence by applying an RNN model independently on each input, and train the model to produce consistent tracks across the two inputs. We evaluate our unsupervised method on MOT17 and KITTI -- remarkably, we find that, despite training only on unlabeled video, our unsupervised approach outperforms four supervised methods published in the last 1--2 years, including Tracktor++, FAMNet, GSM, and mmMOT.
Patch vs. Global Image-Based Unsupervised Anomaly Detection in MR Brain Scans of Early Parkinsonian Patients
Oct 25, 2021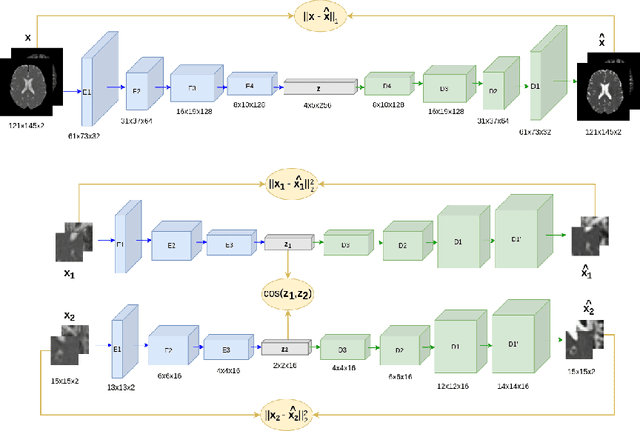
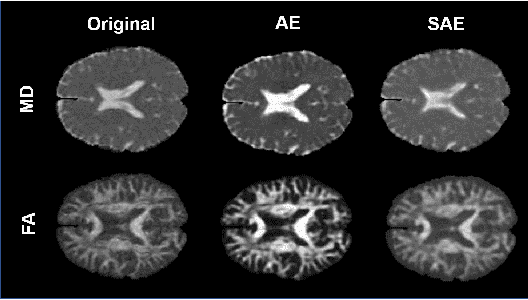
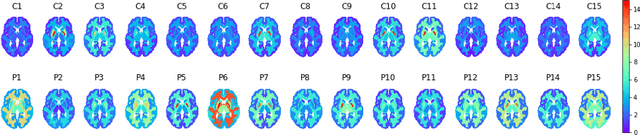
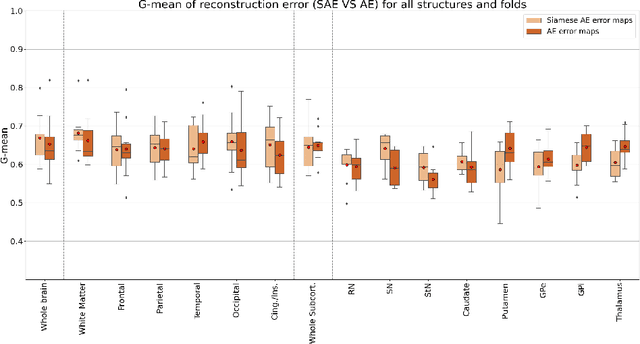
Although neural networks have proven very successful in a number of medical image analysis applications, their use remains difficult when targeting subtle tasks such as the identification of barely visible brain lesions, especially given the lack of annotated datasets. Good candidate approaches are patch-based unsupervised pipelines which have both the advantage to increase the number of input data and to capture local and fine anomaly patterns distributed in the image, while potential inconveniences are the loss of global structural information. We illustrate this trade-off on Parkinson's disease (PD) anomaly detection comparing the performance of two anomaly detection models based on a spatial auto-encoder (AE) and an adaptation of a patch-fed siamese auto-encoder (SAE). On average, the SAE model performs better, showing that patches may indeed be advantageous.
Recovering Accurate Labeling Information from Partially Valid Data for Effective Multi-Label Learning
Jun 20, 2020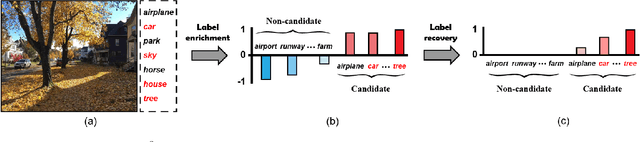
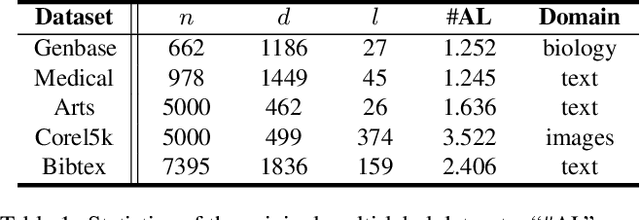
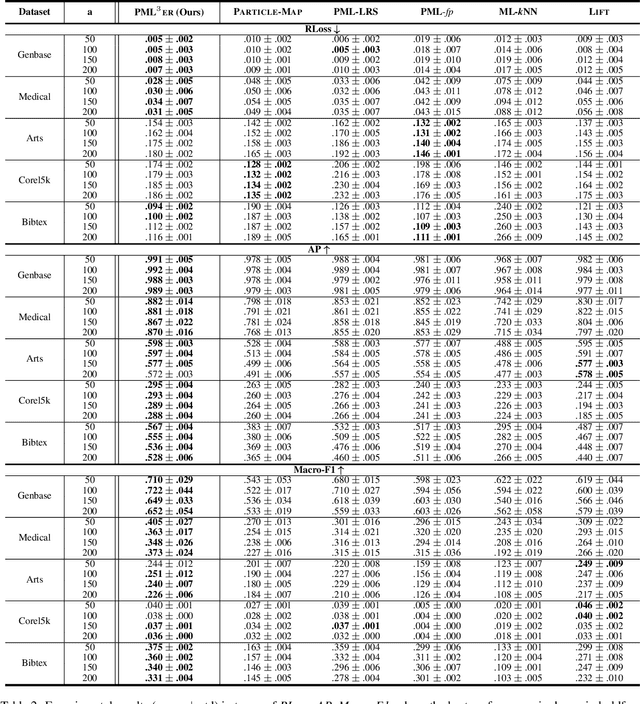

Partial Multi-label Learning (PML) aims to induce the multi-label predictor from datasets with noisy supervision, where each training instance is associated with several candidate labels but only partially valid. To address the noisy issue, the existing PML methods basically recover the ground-truth labels by leveraging the ground-truth confidence of the candidate label, \ie the likelihood of a candidate label being a ground-truth one. However, they neglect the information from non-candidate labels, which potentially contributes to the ground-truth label recovery. In this paper, we propose to recover the ground-truth labels, \ie estimating the ground-truth confidences, from the label enrichment, composed of the relevance degrees of candidate labels and irrelevance degrees of non-candidate labels. Upon this observation, we further develop a novel two-stage PML method, namely \emph{\underline{P}artial \underline{M}ulti-\underline{L}abel \underline{L}earning with \underline{L}abel \underline{E}nrichment-\underline{R}ecovery} (\baby), where in the first stage, it estimates the label enrichment with unconstrained label propagation, then jointly learns the ground-truth confidence and multi-label predictor given the label enrichment. Experimental results validate that \baby outperforms the state-of-the-art PML methods.
Multimodal End-to-End Group Emotion Recognition using Cross-Modal Attention
Nov 10, 2021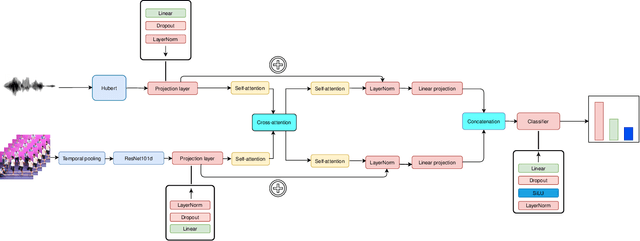
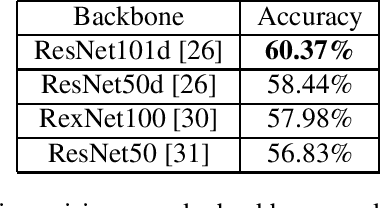
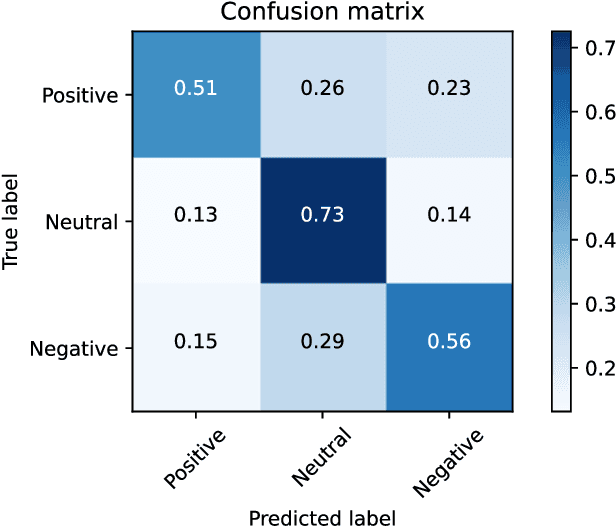
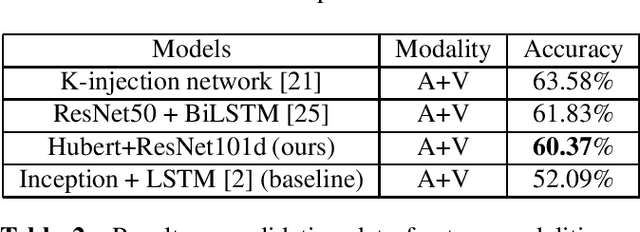
Classifying group-level emotions is a challenging task due to complexity of video, in which not only visual, but also audio information should be taken into consideration. Existing works on multimodal emotion recognition are using bulky approach, where pretrained neural networks are used as a feature extractors and then extracted features are being fused. However, this approach does not consider attributes of multimodal data and feature extractors cannot be fine-tuned for specific task which can be disadvantageous for overall model accuracy. To this end, our impact is twofold: (i) we train model end-to-end, which allows early layers of neural network to be adapted with taking into account later, fusion layers, of two modalities; (ii) all layers of our model was fine-tuned for downstream task of emotion recognition, so there were no need to train neural networks from scratch. Our model achieves best validation accuracy of 60.37% which is approximately 8.5% higher, than VGAF dataset baseline and is competitive with existing works, audio and video modalities.
Combining Parameter Identification and Trajectory Optimization: Real-time Planning for Information Gain
Jun 06, 2019
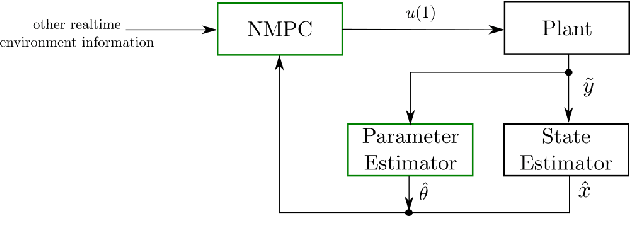
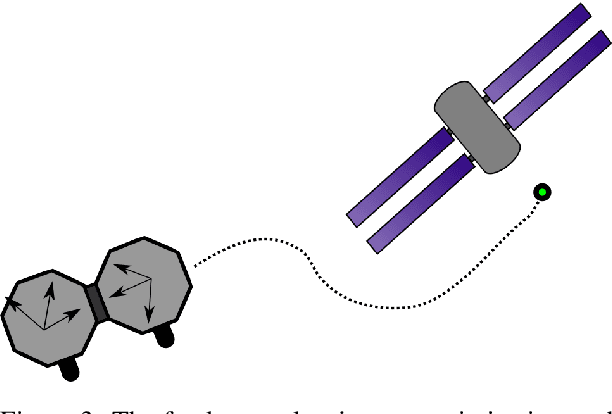
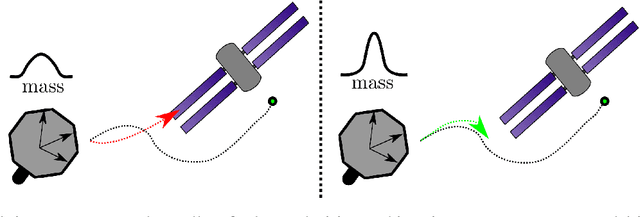
Robotic systems often operate with uncertainties in their dynamics, for example, unknown inertial properties. Broadly, there are two approaches for controlling uncertain systems: design robust controllers in spite of uncertainty, or characterize a system before attempting to control it. This paper proposes a middle-ground approach, making trajectory progress while also accounting for gaining information about the system. More specifically, it combines excitation trajectories which are usually intended to optimize information gain for an estimator, with goal-driven trajectory optimization metrics. For this purpose, a measure of information gain is incorporated (using the Fisher Information Matrix) in a real-time planning framework to produce trajectories favorable for estimation. At the same time, the planner receives stable parameter updates from the estimator, enhancing the system model. An implementation of this learn-as-you-go approach utilizing an Unscented Kalman Filter (UKF) and Nonlinear Model Predictive Controller (NMPC) is demonstrated in simulation. Results for cases with and without information gain and online parameter updates in the system model are presented.
Pansharpening by convolutional neural networks in the full resolution framework
Nov 16, 2021
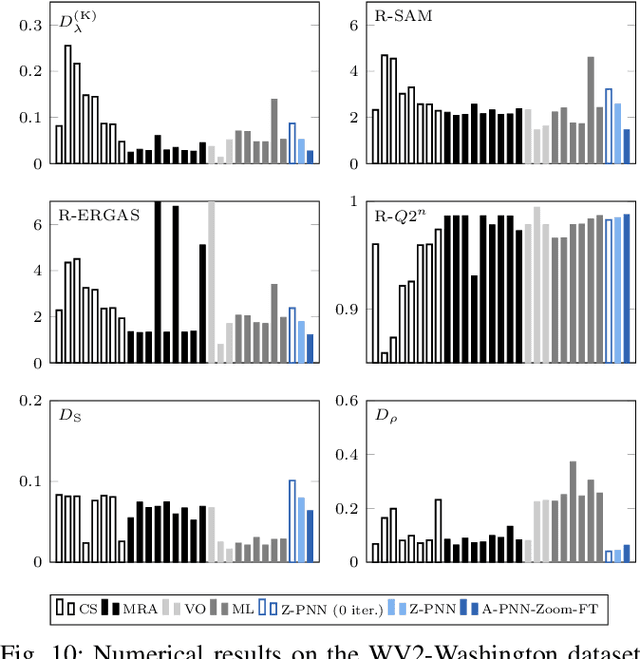
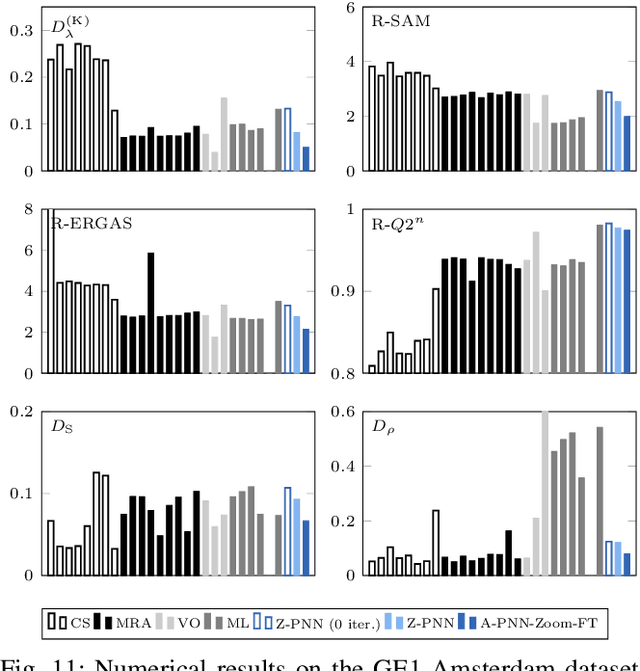

In recent years, there has been a growing interest on deep learning-based pansharpening. Research has mainly focused on architectures. However, lacking a ground truth, model training is also a major issue. A popular approach is to train networks in a reduced resolution domain, using the original data as ground truths. The trained networks are then used on full resolution data, relying on an implicit scale invariance hypothesis. Results are generally good at reduced resolution, but more questionable at full resolution. Here, we propose a full-resolution training framework for deep learning-based pansharpening. Training takes place in the high resolution domain, relying only on the original data, with no loss of information. To ensure spectral and spatial fidelity, suitable losses are defined, which force the pansharpened output to be consistent with the available panchromatic and multispectral input. Experiments carried out on WorldView-3, WorldView-2, and GeoEye-1 images show that methods trained with the proposed framework guarantee an excellent performance in terms of both full-resolution numerical indexes and visual quality. The framework is fully general, and can be used to train and fine-tune any deep learning-based pansharpening network.
Towards Integrative Multi-Modal Personal Health Navigation Systems: Framework and Application
Nov 16, 2021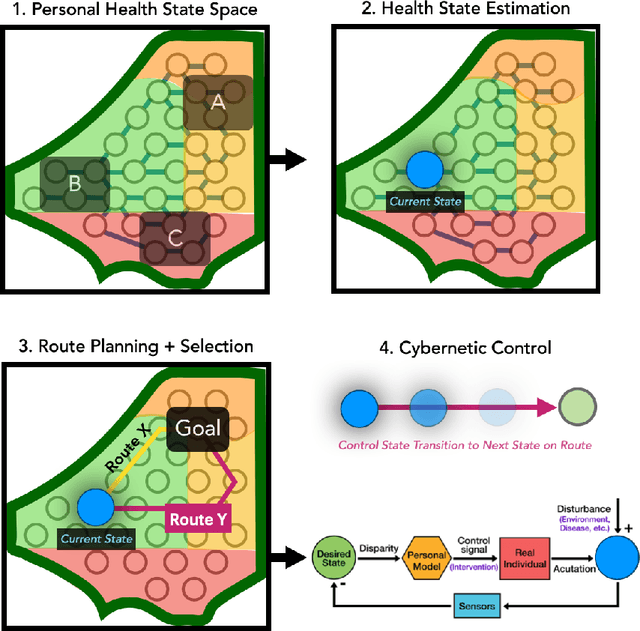
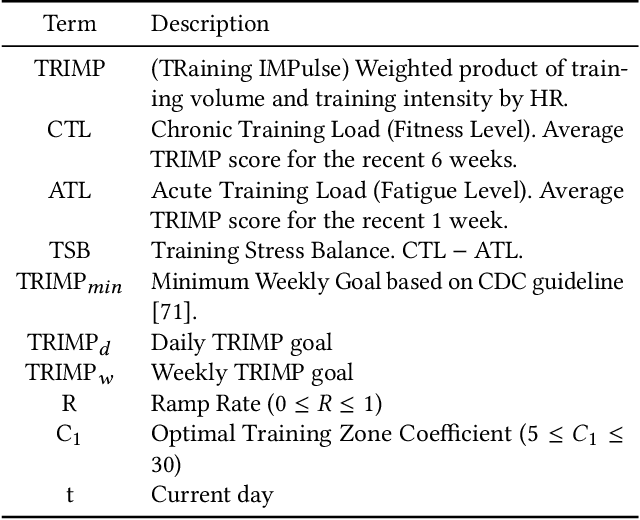
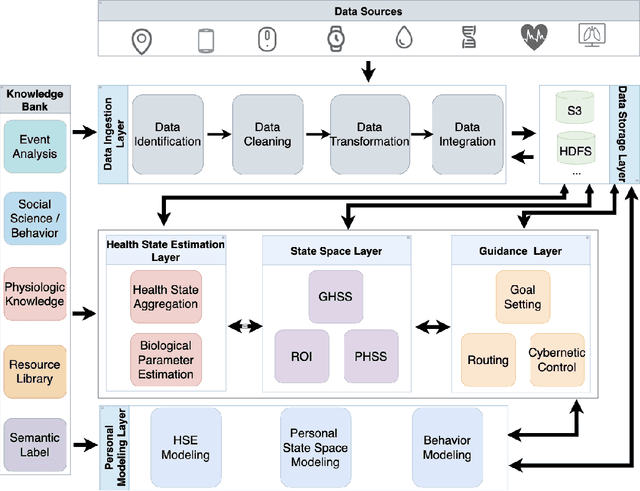
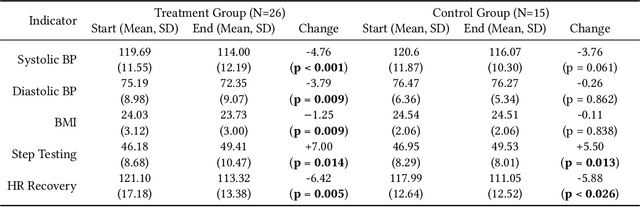
It is well understood that an individual's health trajectory is influenced by choices made in each moment, such as from lifestyle or medical decisions. With the advent of modern sensing technologies, individuals have more data and information about themselves than any other time in history. How can we use this data to make the best decisions to keep the health state optimal? We propose a generalized Personal Health Navigation (PHN) framework. PHN takes individuals towards their personal health goals through a system which perpetually digests data streams, estimates current health status, computes the best route through intermediate states utilizing personal models, and guides the best inputs that carry a user towards their goal. In addition to describing the general framework, we test the PHN system in two experiments within the field of cardiology. First, we prospectively test a knowledge-infused cardiovascular PHN system with a pilot clinical trial of 41 users. Second, we build a data-driven personalized model on cardiovascular exercise response variability on a smartwatch data-set of 33,269 real-world users. We conclude with critical challenges in health computing for PHN systems that require deep future investigation.
Contextual Information Enhanced Convolutional Neural Networks for Retinal Vessel Segmentation in Color Fundus Images
Mar 25, 2021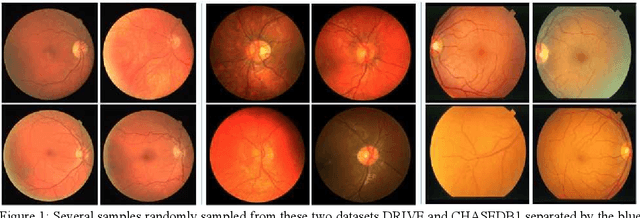

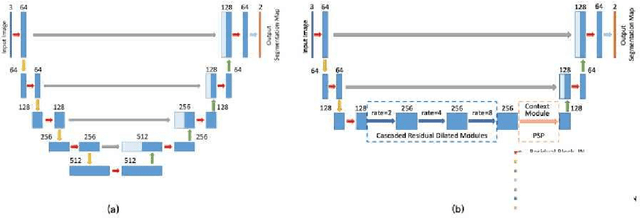
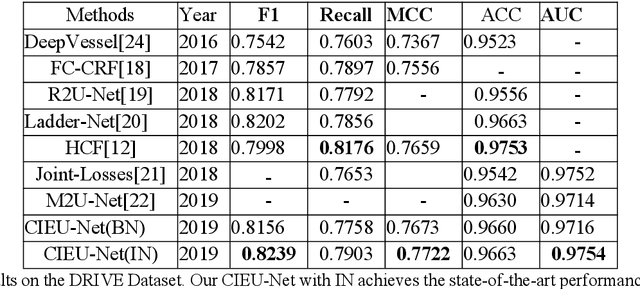
Accurate retinal vessel segmentation is a challenging problem in color fundus image analysis. An automatic retinal vessel segmentation system can effectively facilitate clinical diagnosis and ophthalmological research. Technically, this problem suffers from various degrees of vessel thickness, perception of details, and contextual feature fusion. For addressing these challenges, a deep learning based method has been proposed and several customized modules have been integrated into the well-known encoder-decoder architecture U-net, which is mainly employed in medical image segmentation. Structurally, cascaded dilated convolutional modules have been integrated into the intermediate layers, for obtaining larger receptive field and generating denser encoded feature maps. Also, the advantages of the pyramid module with spatial continuity have been taken, for multi-thickness perception, detail refinement, and contextual feature fusion. Additionally, the effectiveness of different normalization approaches has been discussed in network training for different datasets with specific properties. Experimentally, sufficient comparative experiments have been enforced on three retinal vessel segmentation datasets, DRIVE, CHASEDB1, and the unhealthy dataset STARE. As a result, the proposed method outperforms the work of predecessors and achieves state-of-the-art performance in Sensitivity/Recall, F1-score and MCC.
Real Time Integration Centre of Mass (riCOM) Reconstruction for 4D-STEM
Dec 08, 2021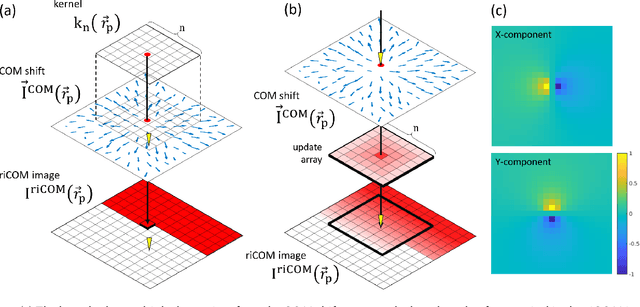
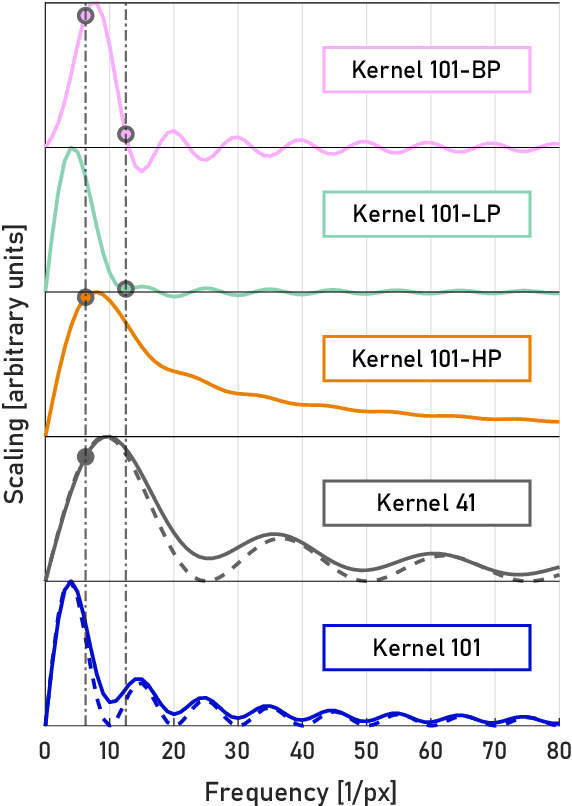
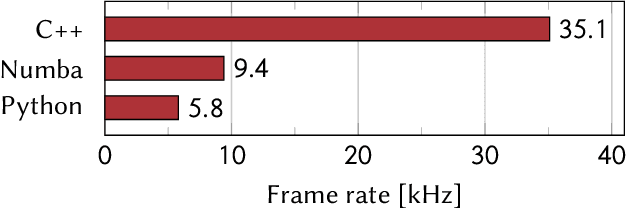
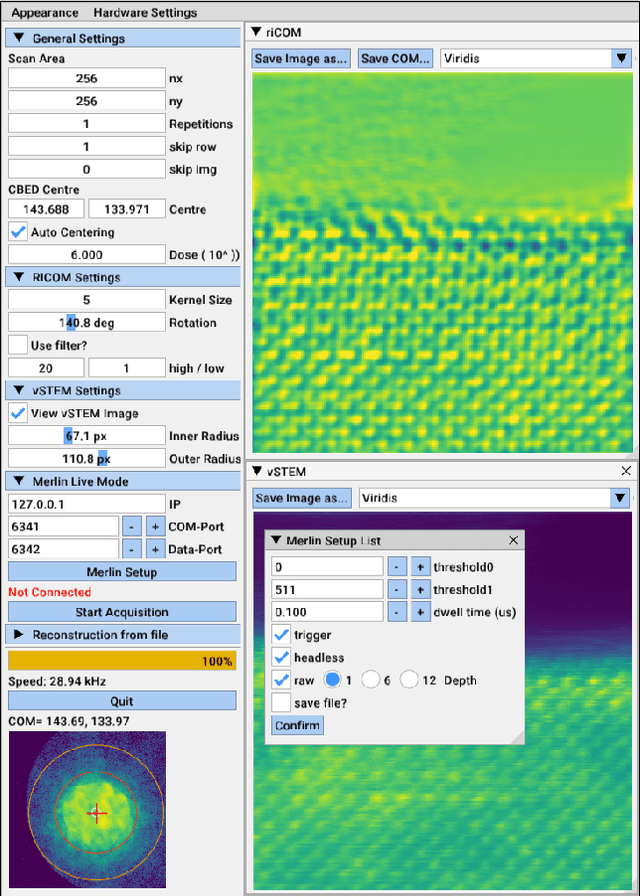
A real-time image reconstruction method for scanning transmission electron microscopy (STEM) is proposed. The method uses the concept of integrated centre of mass (iCOM) and creates a live-updated image based on diffraction patterns collected at each probe position during scanning. It is shown that the method has similar characteristics to the traditional iCOM approach. However, by reformulating the integration method, the reconstruction process can be divided into sub-units, with each unit requiring only information from a single probe position, such that the resulting image can be updated each time a new probe position is visited without storing any intermediate diffraction patterns. As a certain position in the image is only influenced by its surrounding pixels in the immediate vicinity, the image update provides interpretable images being build up while the scanning is being performed. The results show clearer features at higher spatial frequency, such as atomic column positions. It is also demonstrated that common post processing methods, such as a band pass filter, can be directly integrated in the real time processing flow. By comparing with other reconstruction methods, it is shown that the proposed method can produce high quality reconstructions with good noise robustness at extremely low memory and computational requirements. We further present an efficient, interactive open source implementation of the concept, compatible with frame-based, as well as event-based camera/file types. The proposed method provides the attractive feature of immediate feedback that microscope operators have become used to for e.g. conventional HAADF STEM imaging allowing for rapid decision making and fine tuning to obtain the best possible images for beam sensitive samples at the lowest possible dose.
PIVODL: Privacy-preserving vertical federated learning over distributed labels
Aug 25, 2021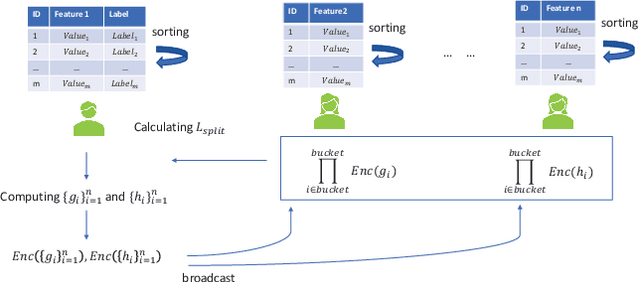
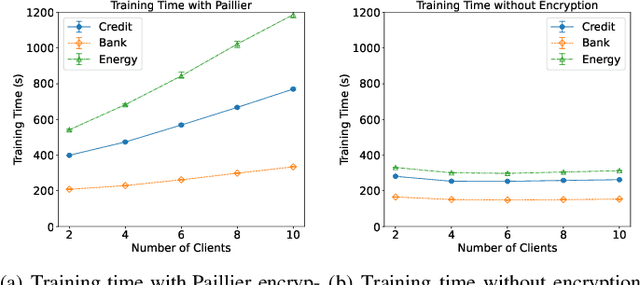
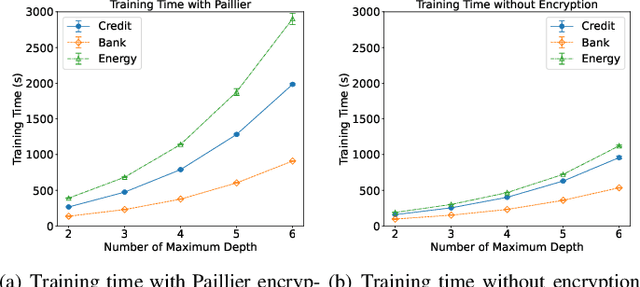
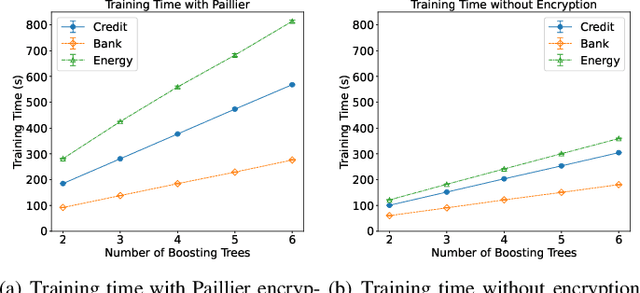
Federated learning (FL) is an emerging privacy preserving machine learning protocol that allows multiple devices to collaboratively train a shared global model without revealing their private local data. Non-parametric models like gradient boosting decision trees (GBDT) have been commonly used in FL for vertically partitioned data. However, all these studies assume that all the data labels are stored on only one client, which may be unrealistic for real-world applications. Therefore, in this work, we propose a secure vertical FL framework, named PIVODL, to train GBDT with data labels distributed on multiple devices. Both homomorphic encryption and differential privacy are adopted to prevent label information from being leaked through transmitted gradients and leaf values. Our experimental results show that both information leakage and model performance degradation of the proposed PIVODL are negligible.