 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multimodal Interactions Using Pretrained Unimodal Models for SIMMC 2.0
Dec 18, 2021



This paper presents our work on the Situated Interactive MultiModal Conversations 2.0 challenge held at Dialog State Tracking Challenge 10. SIMMC 2.0 includes 4 subtasks, and we introduce our multimodal approaches for the subtask \#1, \#2 and the generation of subtask \#4. SIMMC 2.0 dataset is a multimodal dataset containing image and text information, which is more challenging than the problem of only text-based conversations because it must be solved by understanding the relationship between image and text. Therefore, since there is a limit to solving only text models such as BERT or GPT2, we propose a multimodal model combining image and text. We first pretrain the multimodal model to understand the relationship between image and text, then finetune our model for each task. We achieve the 3rd best performance in subtask \#1, \#2 and a runner-up in the generation of subtask \#4. The source code is available at https://github.com/rungjoo/simmc2.0.
AIS: A nonlinear activation function for industrial safety engineering
Nov 27, 2021
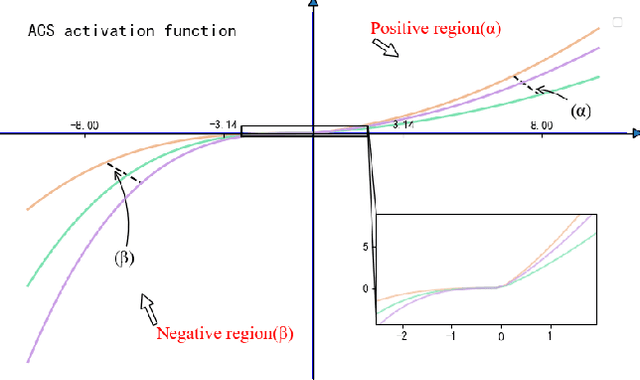
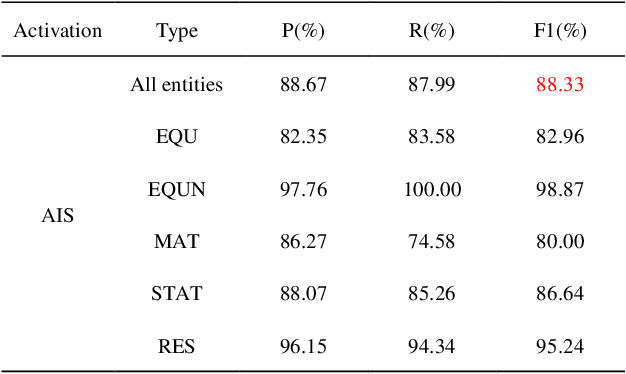
In the task of Chinese named entity recognition based on deep learning, activation function plays an irreplaceable role, it introduces nonlinear characteristics into neural network, so that the fitted model can be applied to various tasks. However, the information density of industrial safety analysis text is relatively high, and the correlation and similarity between the information are large, which is easy to cause the problem of high deviation and high standard deviation of the model, no specific activation function has been designed in previous studies, and the traditional activation function has the problems of gradient vanishing and negative region, which also lead to the recognition accuracy of the model can not be further improved. To solve these problems, a novel activation function AIS is proposed in this paper. AIS is an activation function applied in industrial safety engineering, which is composed of two piecewise nonlinear functions. In the positive region, the structure combining exponential function and quadratic function is used to alleviate the problem of deviation and standard deviation, and the linear function is added to modify it, which makes the whole activation function smoother and overcomes the problem of gradient vanishing. In the negative region, the cubic function structure is used to solve the negative region problem and accelerate the convergence of the model. Based on the deep learning model of BERT-BiLSTM-CRF, the performance of AIS is evaluated. The results show that, compared with other activation functions, AIS overcomes the problems of gradient vanishing and negative region, reduces the deviation of the model, speeds up the model fitting, and improves the extraction ability of the model for industrial entities.
CoreLM: Coreference-aware Language Model Fine-Tuning
Nov 04, 2021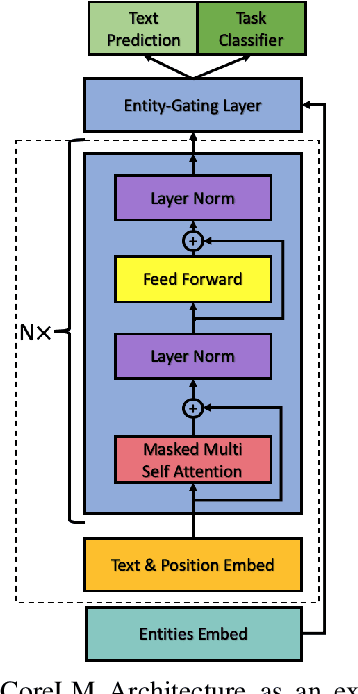
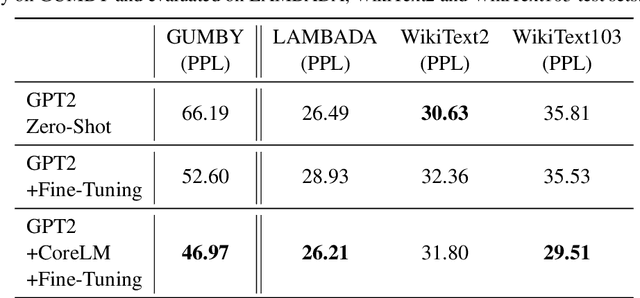
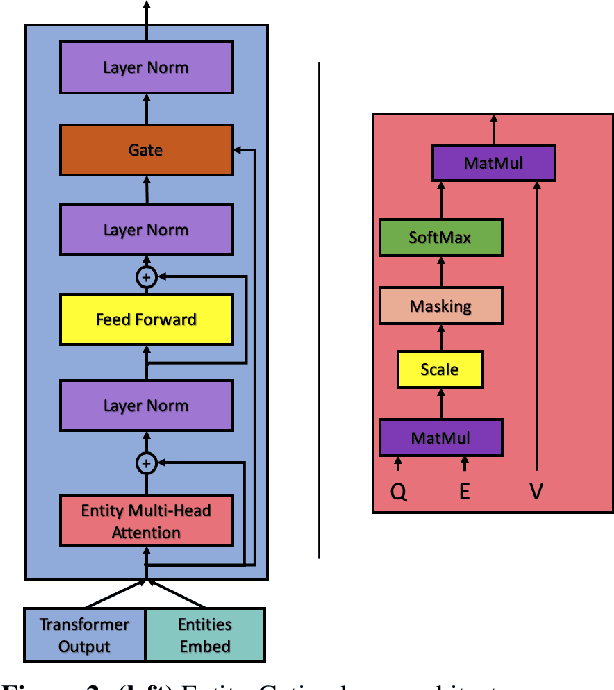
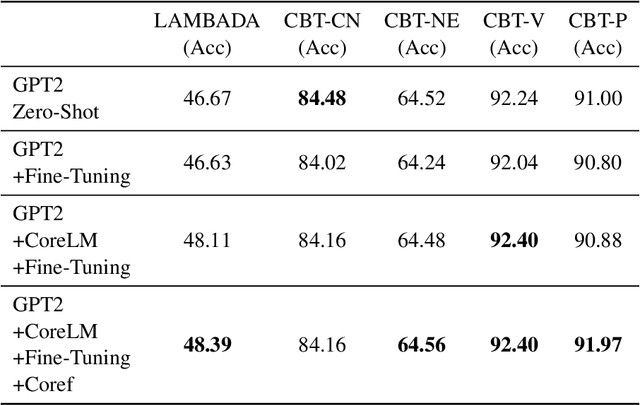
Language Models are the underpin of all modern Natural Language Processing (NLP) tasks. The introduction of the Transformers architecture has contributed significantly into making Language Modeling very effective across many NLP task, leading to significant advancements in the field. However, Transformers come with a big computational cost, which grows quadratically with respect to the input length. This presents a challenge as to understand long texts requires a lot of context. In this paper, we propose a Fine-Tuning framework, named CoreLM, that extends the architecture of current Pretrained Language Models so that they incorporate explicit entity information. By introducing entity representations, we make available information outside the contextual space of the model, which results in a better Language Model for a fraction of the computational cost. We implement our approach using GPT2 and compare the fine-tuned model to the original. Our proposed model achieves a lower Perplexity in GUMBY and LAMBDADA datasets when compared to GPT2 and a fine-tuned version of GPT2 without any changes. We also compare the models' performance in terms of Accuracy in LAMBADA and Children's Book Test, with and without the use of model-created coreference annotations.
Boosting Video Representation Learning with Multi-Faceted Integration
Jan 11, 2022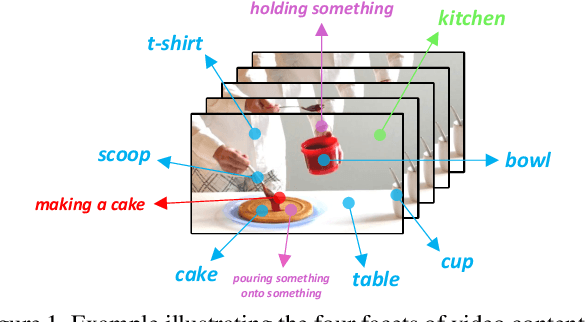
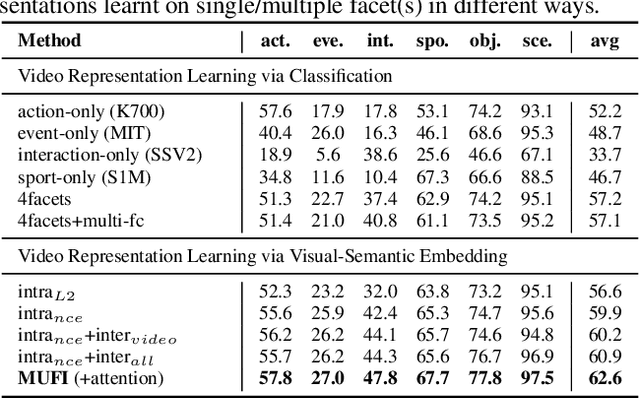
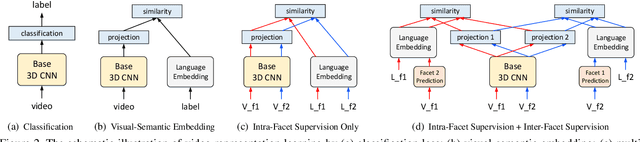
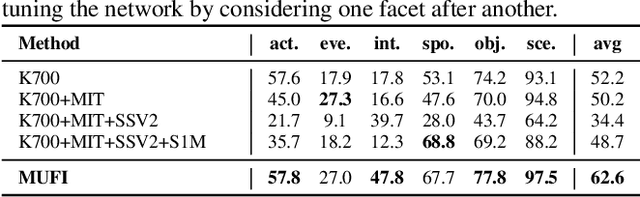
Video content is multifaceted, consisting of objects, scenes, interactions or actions. The existing datasets mostly label only one of the facets for model training, resulting in the video representation that biases to only one facet depending on the training dataset. There is no study yet on how to learn a video representation from multifaceted labels, and whether multifaceted information is helpful for video representation learning. In this paper, we propose a new learning framework, MUlti-Faceted Integration (MUFI), to aggregate facets from different datasets for learning a representation that could reflect the full spectrum of video content. Technically, MUFI formulates the problem as visual-semantic embedding learning, which explicitly maps video representation into a rich semantic embedding space, and jointly optimizes video representation from two perspectives. One is to capitalize on the intra-facet supervision between each video and its own label descriptions, and the second predicts the "semantic representation" of each video from the facets of other datasets as the inter-facet supervision. Extensive experiments demonstrate that learning 3D CNN via our MUFI framework on a union of four large-scale video datasets plus two image datasets leads to superior capability of video representation. The pre-learnt 3D CNN with MUFI also shows clear improvements over other approaches on several downstream video applications. More remarkably, MUFI achieves 98.1%/80.9% on UCF101/HMDB51 for action recognition and 101.5% in terms of CIDEr-D score on MSVD for video captioning.
Multi-View representation learning in Multi-Task Scene
Jan 15, 2022
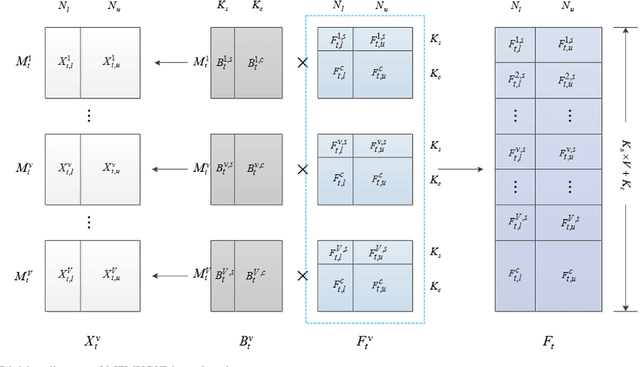
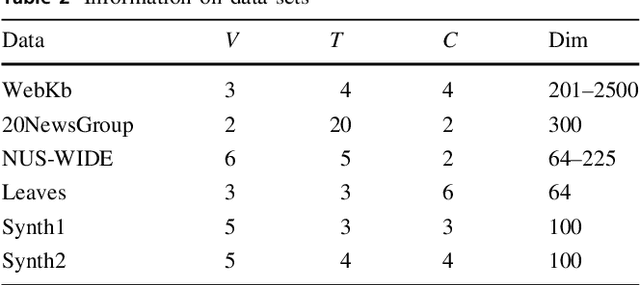
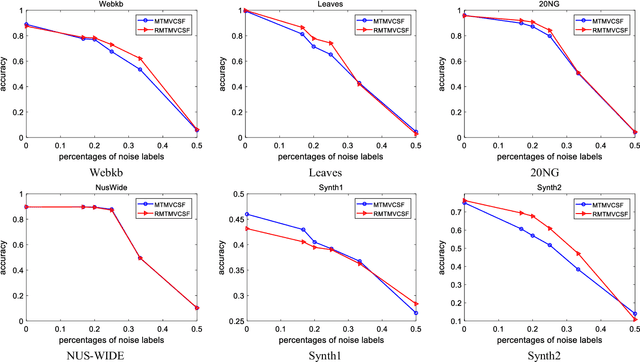
Over recent decades have witnessed considerable progress in whether multi-task learning or multi-view learning, but the situation that consider both learning scenes simultaneously has received not too much attention. How to utilize multiple views latent representation of each single task to improve each learning task performance is a challenge problem. Based on this, we proposed a novel semi-supervised algorithm, termed as Multi-Task Multi-View learning based on Common and Special Features (MTMVCSF). In general, multi-views are the different aspects of an object and every view includes the underlying common or special information of this object. As a consequence, we will mine multiple views jointly latent factor of each learning task which consists of each view special feature and the common feature of all views. By this way, the original multi-task multi-view data has degenerated into multi-task data, and exploring the correlations among multiple tasks enables to make an improvement on the performance of learning algorithm. Another obvious advantage of this approach is that we get latent representation of the set of unlabeled instances by the constraint of regression task with labeled instances. The performance of classification and semi-supervised clustering task in these latent representations perform obviously better than it in raw data. Furthermore, an anti-noise multi-task multi-view algorithm called AN-MTMVCSF is proposed, which has a strong adaptability to noise labels. The effectiveness of these algorithms is proved by a series of well-designed experiments on both real world and synthetic data.
* 32 pages
Sensory attenuation develops as a result of sensorimotor experience
Nov 04, 2021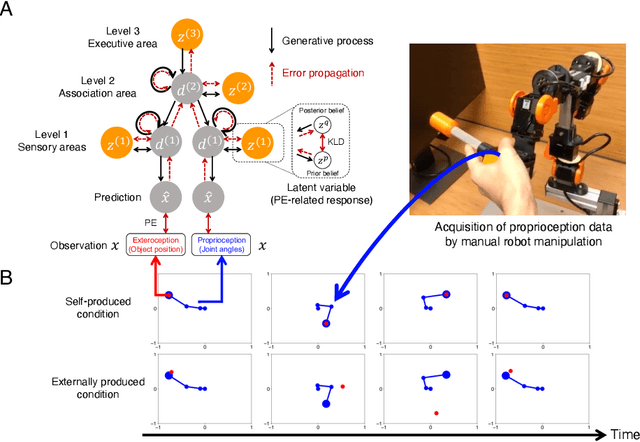
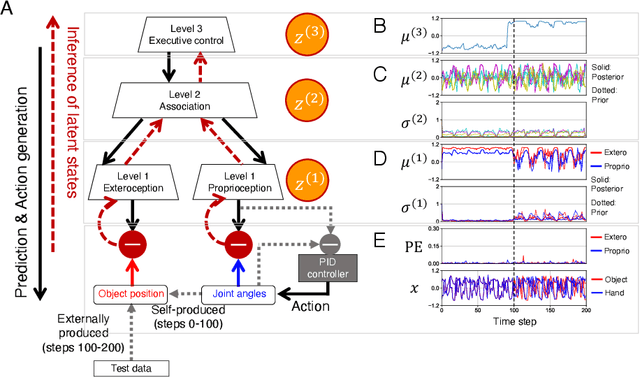
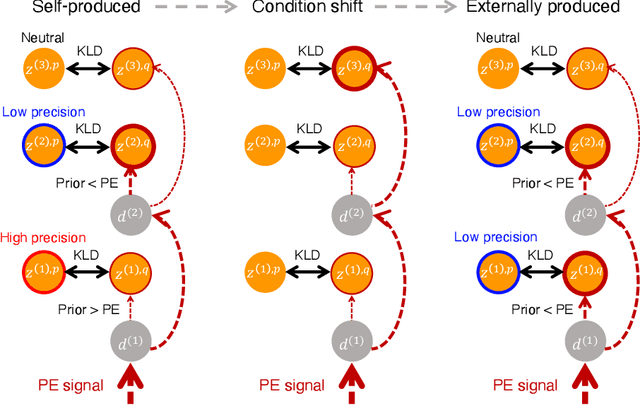
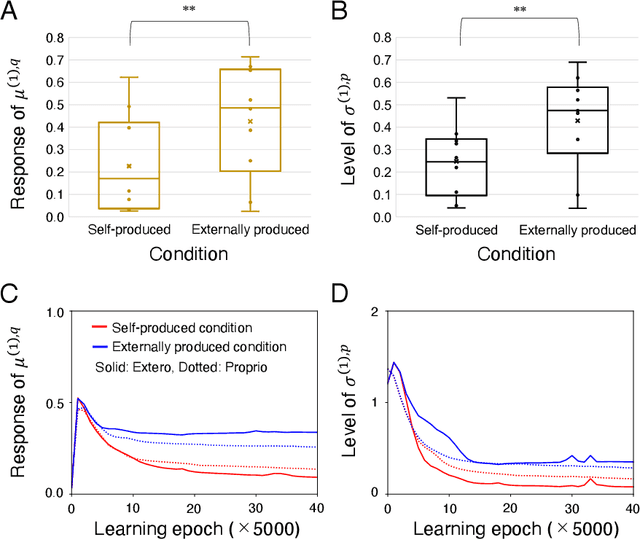
The brain attenuates its responses to self-produced exteroceptions (e.g., we cannot tickle ourselves). Is this phenomenon, called sensory attenuation, enabled innately, or is it acquired through learning? To explore the latter possibility, we created a neural network model consisting of sensory (proprioceptive and exteroceptive), association, and executive areas. A simulated robot controlled by the network learned to acquire motor patterns with self-produced or externally produced exteroceptive feedback. We found that the robot first increased responses in sensory and association areas for both self-produced and externally produced conditions in the early stage of learning, but then, gradually it attenuated responses in sensory areas only for self-produced conditions. The robot spontaneously acquired a capacity to switch (attenuate or amplify) responses in sensory areas depending on the conditions by switching the neural state of the executive area. This suggests that proactive control of sensory-information flow inside the network was self-organized through learning. We also found that innate alterations in the modulation of sensory-information flow induced some characteristics analogous to schizophrenia and autism spectrum disorder. This study provides a novel perspective on neural mechanisms underlying perceptual phenomena and psychiatric disorders.
Solving the Data Sparsity Problem in Predicting the Success of the Startups with Machine Learning Methods
Dec 15, 2021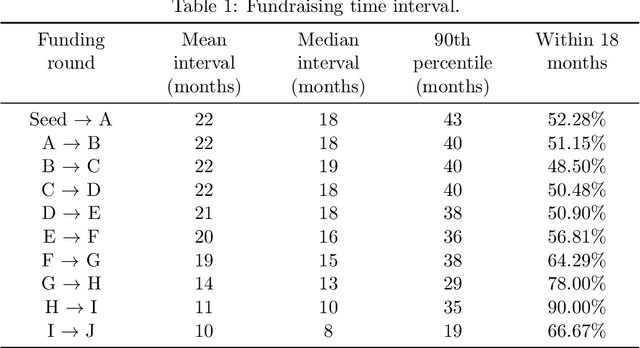
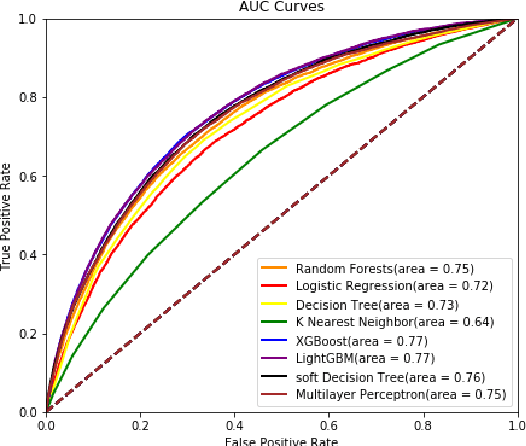
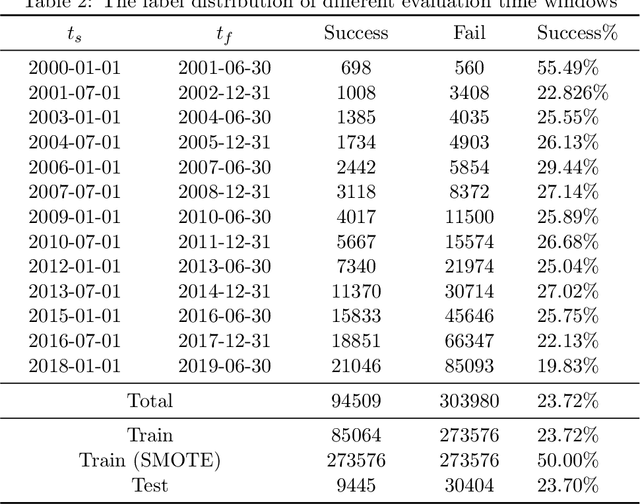
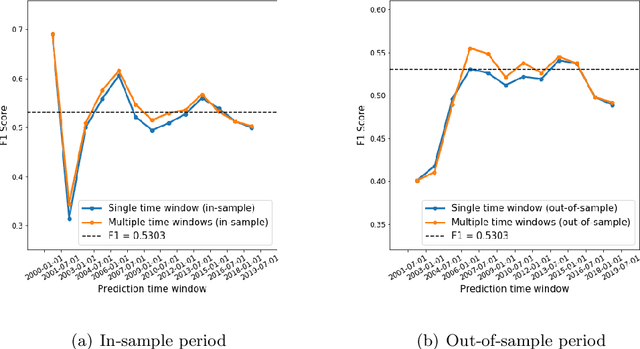
Predicting the success of startup companies is of great importance for both startup companies and investors. It is difficult due to the lack of available data and appropriate general methods. With data platforms like Crunchbase aggregating the information of startup companies, it is possible to predict with machine learning algorithms. Existing research suffers from the data sparsity problem as most early-stage startup companies do not have much data available to the public. We try to leverage the recent algorithms to solve this problem. We investigate several machine learning algorithms with a large dataset from Crunchbase. The results suggest that LightGBM and XGBoost perform best and achieve 53.03% and 52.96% F1 scores. We interpret the predictions from the perspective of feature contribution. We construct portfolios based on the models and achieve high success rates. These findings have substantial implications on how machine learning methods can help startup companies and investors.
Moment Transform-Based Compressive Sensing in Image Processing
Nov 14, 2021
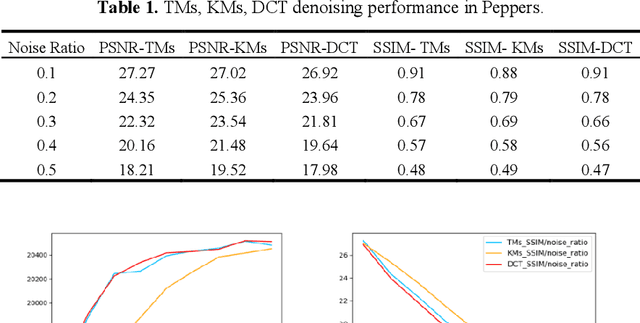
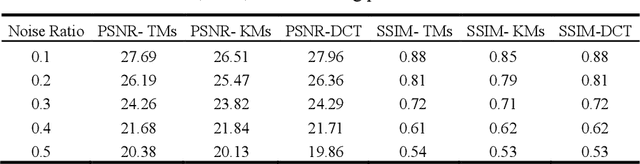
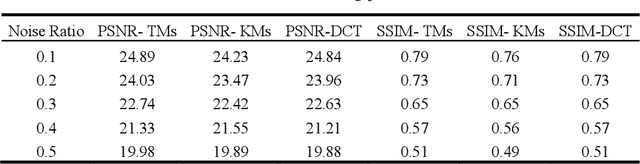
Over the last decades, images have become an important source of information in many domains, thus their high quality has become necessary to acquire better information. One of the important issues that arise is image denoising, which means recovering a signal from inaccurately and/or partially measured samples. This interpretation is highly correlated to the compressive sensing theory, which is a revolutionary technology and implies that if a signal is sparse then the original signal can be obtained from a few measured values, which are much less, than the ones suggested by other used theories like Shannon's sampling theories. A strong factor in Compressive Sensing (CS) theory to achieve the sparsest solution and the noise removal from the corrupted image is the selection of the basis dictionary. In this paper, Discrete Cosine Transform (DCT) and moment transform (Tchebichef, Krawtchouk) are compared in order to achieve image denoising of Gaussian additive white noise based on compressive sensing and sparse approximation theory. The experimental results revealed that the basis dictionaries constructed by the moment transform perform competitively to the traditional DCT. The latter transform shows a higher PSNR of 30.82 dB and the same 0.91 SSIM value as the Tchebichef transform. Moreover, from the sparsity point of view, Krawtchouk moments provide approximately 20-30% more sparse results than DCT.
Self- and Pseudo-self-supervised Prediction of Speaker and Key-utterance for Multi-party Dialogue Reading Comprehension
Sep 08, 2021
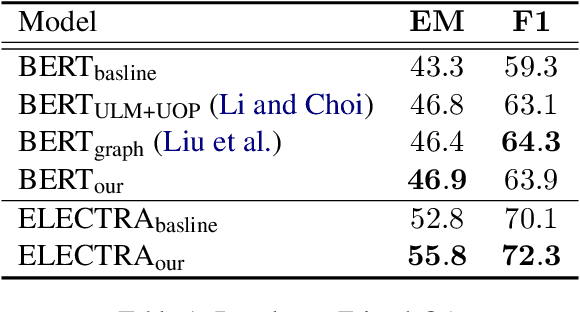
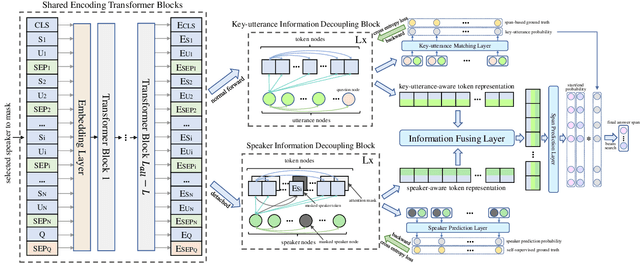
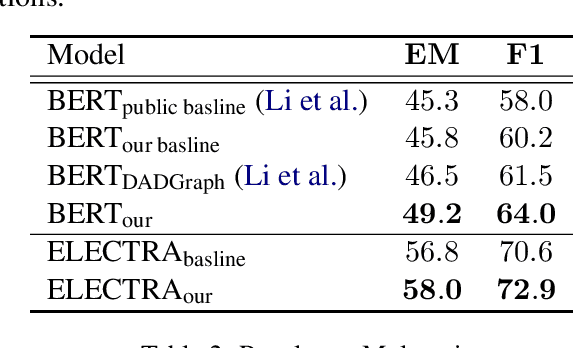
Multi-party dialogue machine reading comprehension (MRC) brings tremendous challenge since it involves multiple speakers at one dialogue, resulting in intricate speaker information flows and noisy dialogue contexts. To alleviate such difficulties, previous models focus on how to incorporate these information using complex graph-based modules and additional manually labeled data, which is usually rare in real scenarios. In this paper, we design two labour-free self- and pseudo-self-supervised prediction tasks on speaker and key-utterance to implicitly model the speaker information flows, and capture salient clues in a long dialogue. Experimental results on two benchmark datasets have justified the effectiveness of our method over competitive baselines and current state-of-the-art models.
Image Denoising with Control over Deep Network Hallucination
Jan 02, 2022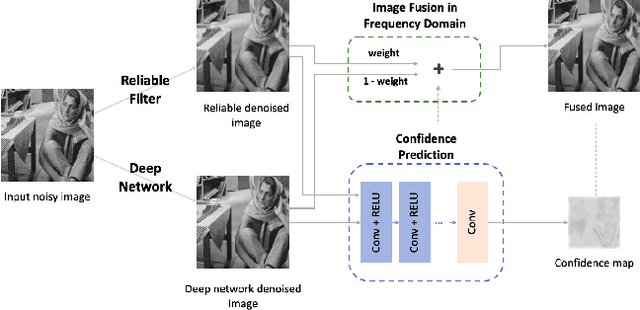
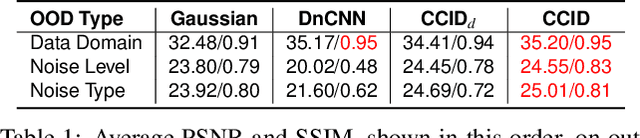

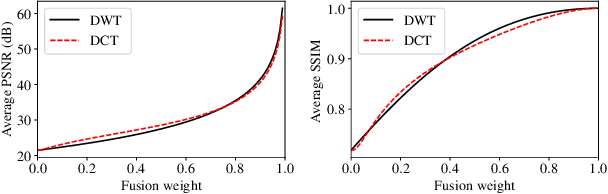
Deep image denoisers achieve state-of-the-art results but with a hidden cost. As witnessed in recent literature, these deep networks are capable of overfitting their training distributions, causing inaccurate hallucinations to be added to the output and generalizing poorly to varying data. For better control and interpretability over a deep denoiser, we propose a novel framework exploiting a denoising network. We call it controllable confidence-based image denoising (CCID). In this framework, we exploit the outputs of a deep denoising network alongside an image convolved with a reliable filter. Such a filter can be a simple convolution kernel which does not risk adding hallucinated information. We propose to fuse the two components with a frequency-domain approach that takes into account the reliability of the deep network outputs. With our framework, the user can control the fusion of the two components in the frequency domain. We also provide a user-friendly map estimating spatially the confidence in the output that potentially contains network hallucination. Results show that our CCID not only provides more interpretability and control, but can even outperform both the quantitative performance of the deep denoiser and that of the reliable filter, especially when the test data diverge from the training data.