 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Bio-inspired Polarization Event Camera
Dec 02, 2021
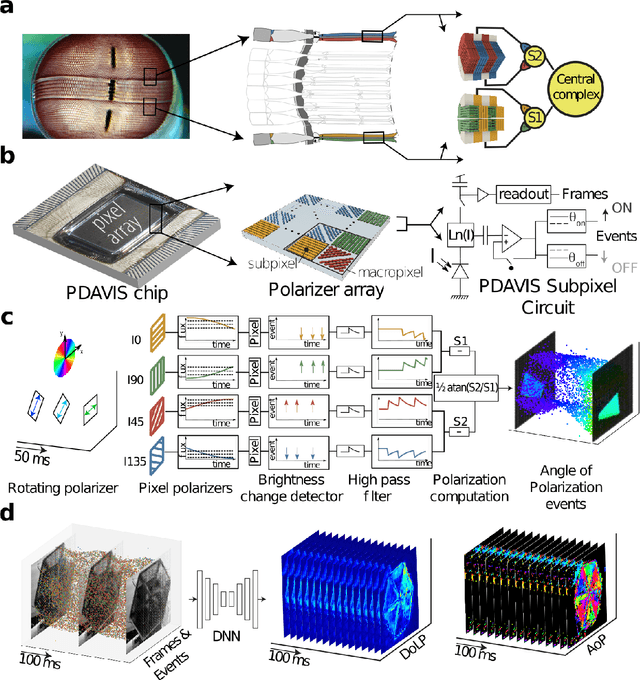
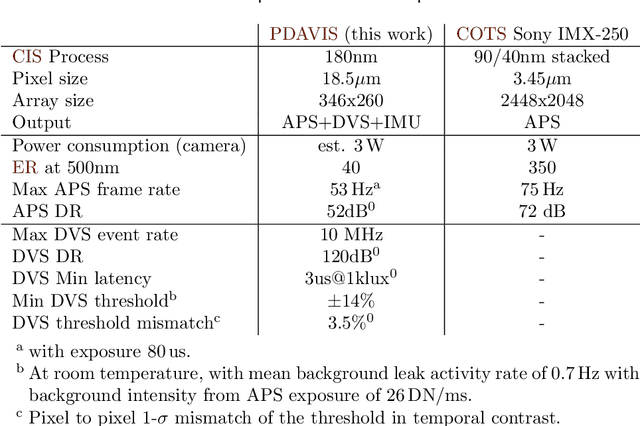
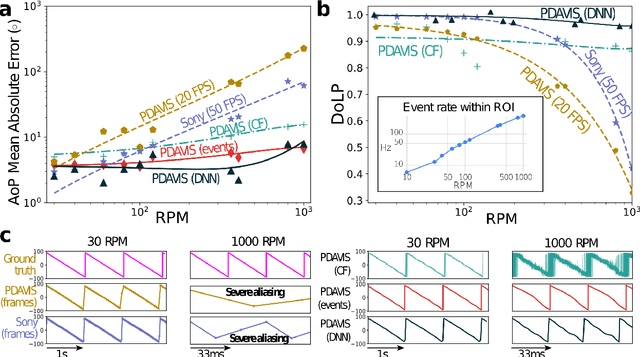

The stomatopod (mantis shrimp) visual system has recently provided a blueprint for the design of paradigm-shifting polarization and multispectral imaging sensors, enabling solutions to challenging medical and remote sensing problems. However, these bioinspired sensors lack the high dynamic range (HDR) and asynchronous polarization vision capabilities of the stomatopod visual system, limiting temporal resolution to \~12 ms and dynamic range to \~ 72 dB. Here we present a novel stomatopod-inspired polarization camera which mimics the sustained and transient biological visual pathways to save power and sample data beyond the maximum Nyquist frame rate. This bio-inspired sensor simultaneously captures both synchronous intensity frames and asynchronous polarization brightness change information with sub-millisecond latencies over a million-fold range of illumination. Our PDAVIS camera is comprised of 346x260 pixels, organized in 2-by-2 macropixels, which filter the incoming light with four linear polarization filters offset by 45 degrees. Polarization information is reconstructed using both low cost and latency event-based algorithms and more accurate but slower deep neural networks. Our sensor is used to image HDR polarization scenes which vary at high speeds and to observe dynamical properties of single collagen fibers in bovine tendon under rapid cyclical loads
A Comparative Study of Calibration Methods for Imbalanced Class Incremental Learning
Feb 01, 2022Deep learning approaches are successful in a wide range of AI problems and in particular for visual recognition tasks. However, there are still open problems among which is the capacity to handle streams of visual information and the management of class imbalance in datasets. Existing research approaches these two problems separately while they co-occur in real world applications. Here, we study the problem of learning incrementally from imbalanced datasets. We focus on algorithms which have a constant deep model complexity and use a bounded memory to store exemplars of old classes across incremental states. Since memory is bounded, old classes are learned with fewer images than new classes and an imbalance due to incremental learning is added to the initial dataset imbalance. A score prediction bias in favor of new classes appears and we evaluate a comprehensive set of score calibration methods to reduce it. Evaluation is carried with three datasets, using two dataset imbalance configurations and three bounded memory sizes. Results show that most calibration methods have beneficial effect and that they are most useful for lower bounded memory sizes, which are most interesting in practice. As a secondary contribution, we remove the usual distillation component from the loss function of incremental learning algorithms. We show that simpler vanilla fine tuning is a stronger backbone for imbalanced incremental learning algorithms.
TASSY -- A Text Annotation Survey System
Dec 16, 2021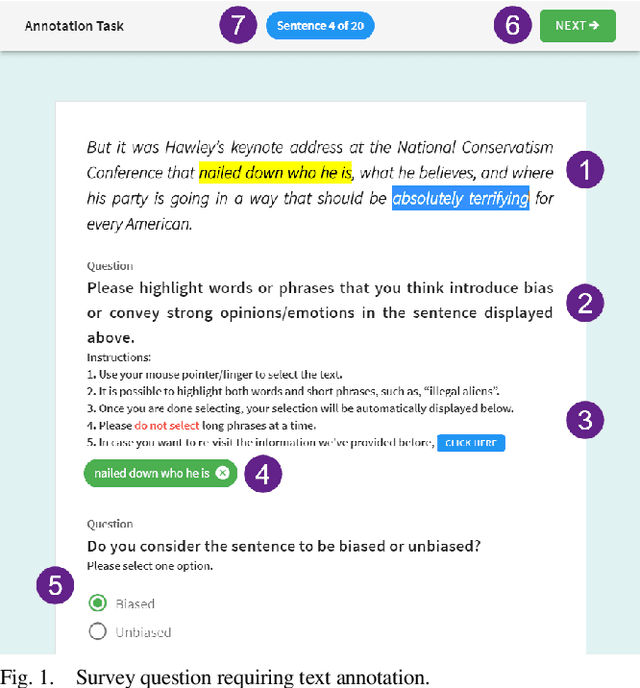
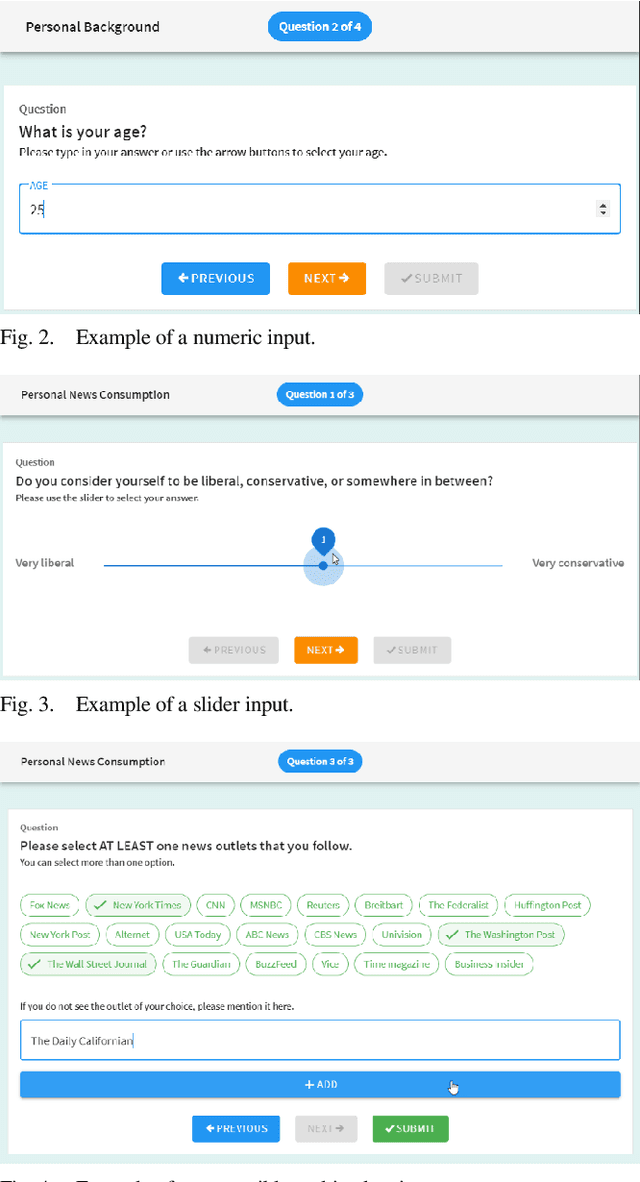
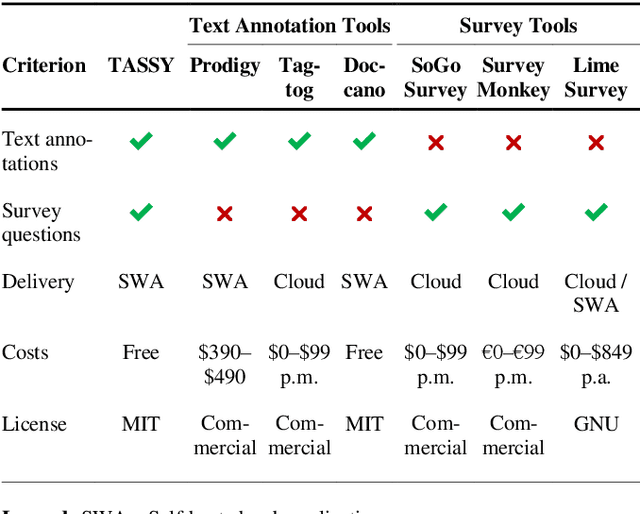
We present a free and open-source tool for creating web-based surveys that include text annotation tasks. Existing tools offer either text annotation or survey functionality but not both. Combining the two input types is particularly relevant for investigating a reader's perception of a text which also depends on the reader's background, such as age, gender, and education. Our tool caters primarily to the needs of researchers in the Library and Information Sciences, the Social Sciences, and the Humanities who apply Content Analysis to investigate, e.g., media bias, political communication, or fake news.
Relevance Vector Machine with Weakly Informative Hyperprior and Extended Predictive Information Criterion
May 07, 2020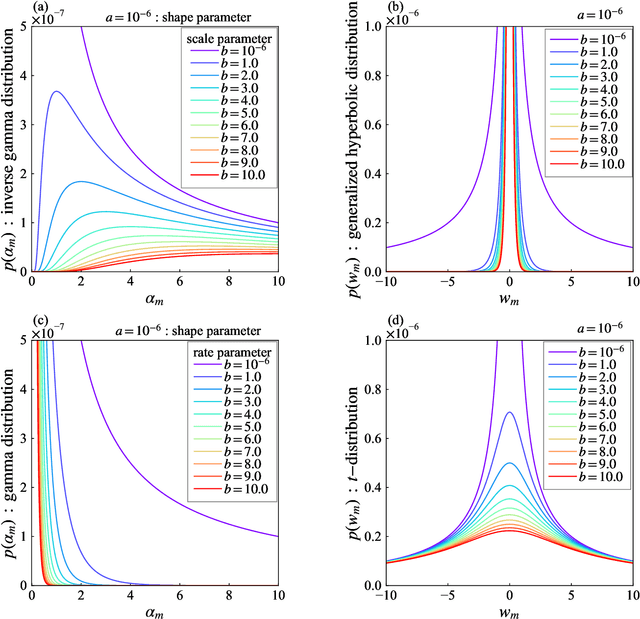
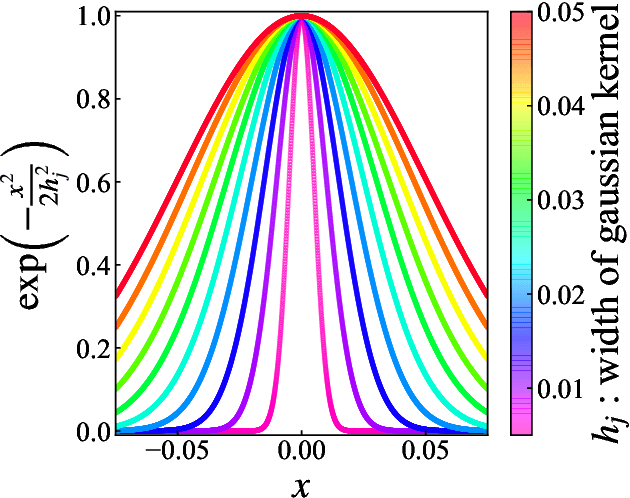
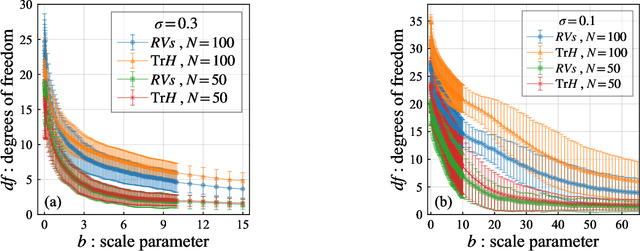
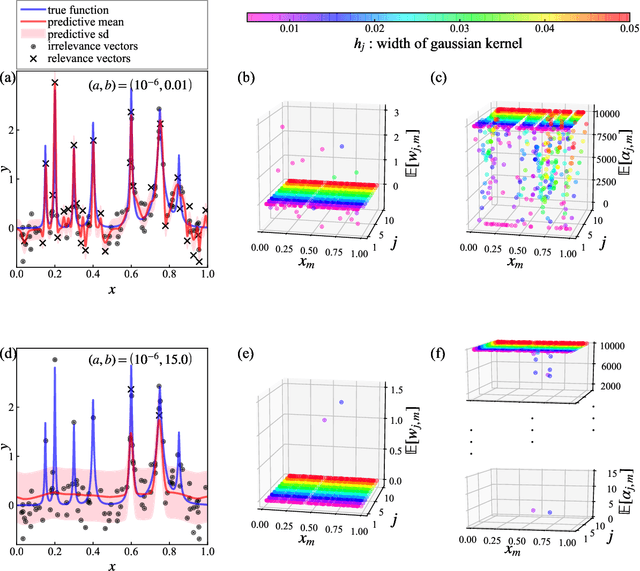
In the variational relevance vector machine, the gamma distribution is representative as a hyperprior over the noise precision of automatic relevance determination prior. Instead of the gamma hyperprior, we propose to use the inverse gamma hyperprior with a shape parameter close to zero and a scale parameter not necessary close to zero. This hyperprior is associated with the concept of a weakly informative prior. The effect of this hyperprior is investigated through regression to non-homogeneous data. Because it is difficult to capture the structure of such data with a single kernel function, we apply the multiple kernel method, in which multiple kernel functions with different widths are arranged for input data. We confirm that the degrees of freedom in a model is controlled by adjusting the scale parameter and keeping the shape parameter close to zero. A candidate for selecting the scale parameter is the predictive information criterion. However the estimated model using this criterion seems to cause over-fitting. This is because the multiple kernel method makes the model a situation where the dimension of the model is larger than the data size. To select an appropriate scale parameter even in such a situation, we also propose an extended prediction information criterion. It is confirmed that a multiple kernel relevance vector regression model with good predictive accuracy can be obtained by selecting the scale parameter minimizing extended prediction information criterion.
Supervised Visual Attention for Simultaneous Multimodal Machine Translation
Jan 23, 2022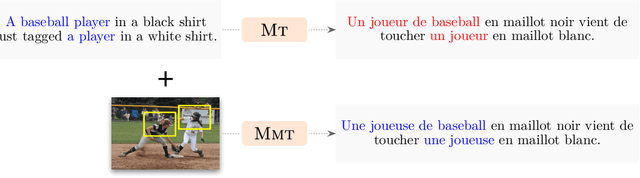
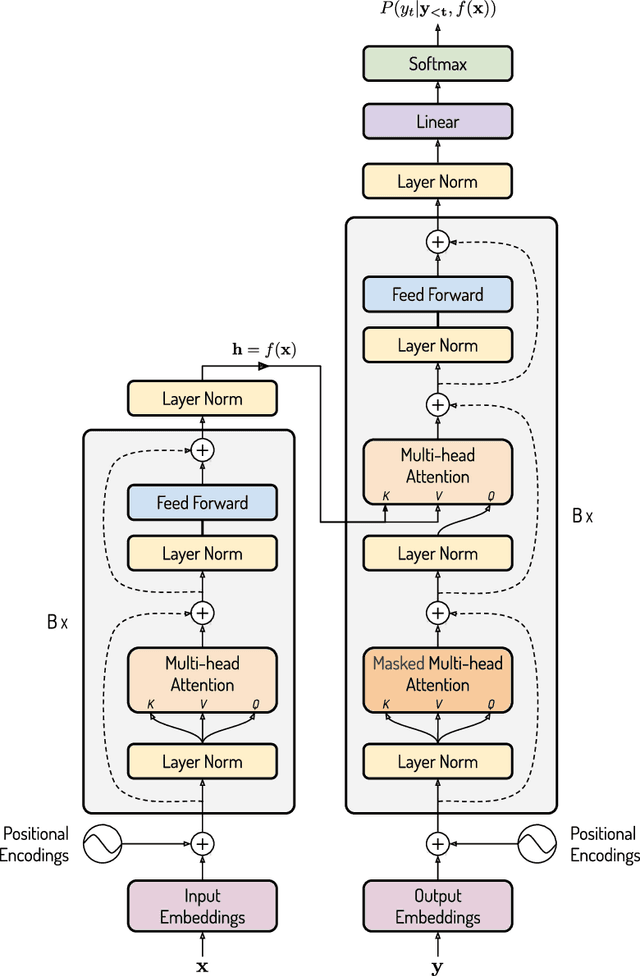
Recently, there has been a surge in research in multimodal machine translation (MMT), where additional modalities such as images are used to improve translation quality of textual systems. A particular use for such multimodal systems is the task of simultaneous machine translation, where visual context has been shown to complement the partial information provided by the source sentence, especially in the early phases of translation (Caglayanet al., 2020a; Imankulova et al., 2020). In this paper, we propose the first Transformer-based simultaneous MMT architecture, which has not been previously explored in the field. Additionally, we extend this model with an auxiliary supervision signal that guides its visual attention mechanism using labelled phrase-region alignments. We perform comprehensive experiments on three language directions and conduct thorough quantitative and qualitative analyses using both automatic metrics and manual inspection. Our results show that (i) supervised visual attention consistently improves the translation quality of the MMT models, and (ii) fine-tuning the MMT with supervision loss enabled leads to better performance than training the MMT from scratch. Compared to the state-of-the-art, our proposed model achieves improvements of up to 2.3 BLEU and 3.5 METEOR points.
CMTR: Cross-modality Transformer for Visible-infrared Person Re-identification
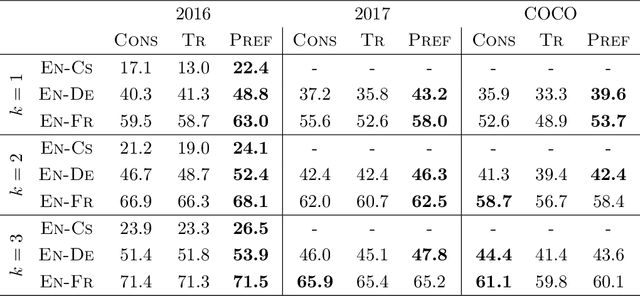
Oct 18, 2021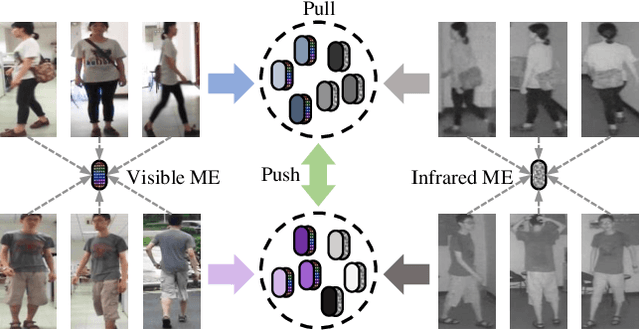
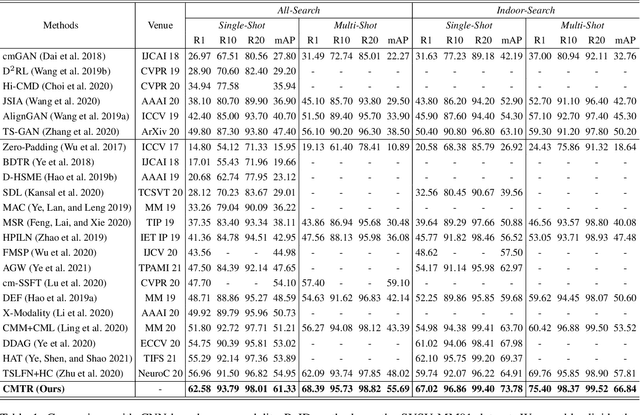
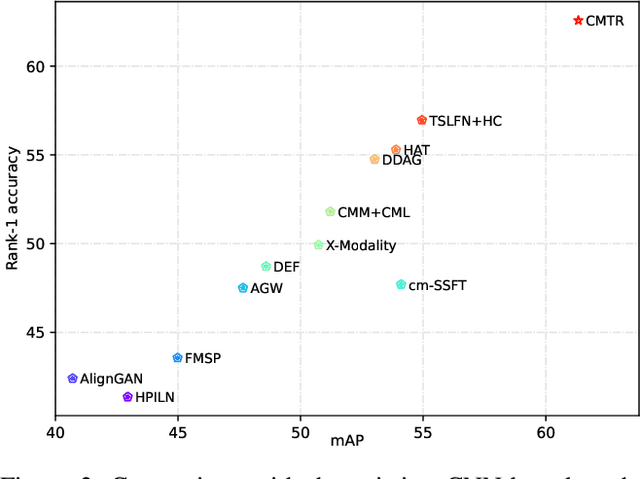
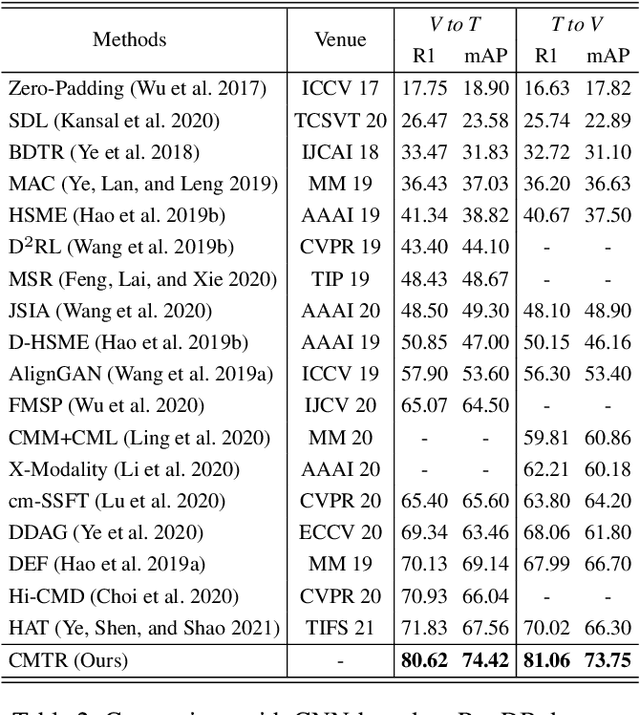
Visible-infrared cross-modality person re-identification is a challenging ReID task, which aims to retrieve and match the same identity's images between the heterogeneous visible and infrared modalities. Thus, the core of this task is to bridge the huge gap between these two modalities. The existing convolutional neural network-based methods mainly face the problem of insufficient perception of modalities' information, and can not learn good discriminative modality-invariant embeddings for identities, which limits their performance. To solve these problems, we propose a cross-modality transformer-based method (CMTR) for the visible-infrared person re-identification task, which can explicitly mine the information of each modality and generate better discriminative features based on it. Specifically, to capture modalities' characteristics, we design the novel modality embeddings, which are fused with token embeddings to encode modalities' information. Furthermore, to enhance representation of modality embeddings and adjust matching embeddings' distribution, we propose a modality-aware enhancement loss based on the learned modalities' information, reducing intra-class distance and enlarging inter-class distance. To our knowledge, this is the first work of applying transformer network to the cross-modality re-identification task. We implement extensive experiments on the public SYSU-MM01 and RegDB datasets, and our proposed CMTR model's performance significantly surpasses existing outstanding CNN-based methods.
UAV Path Planning using Global and Local Map Information with Deep Reinforcement Learning
Nov 02, 2020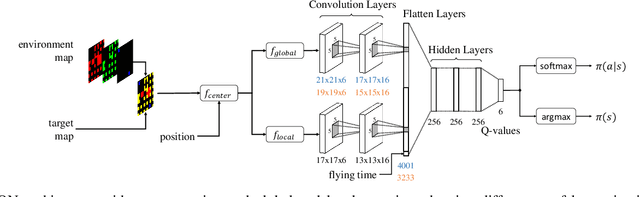
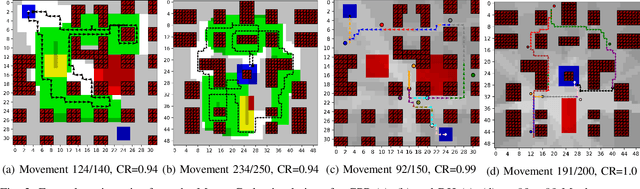
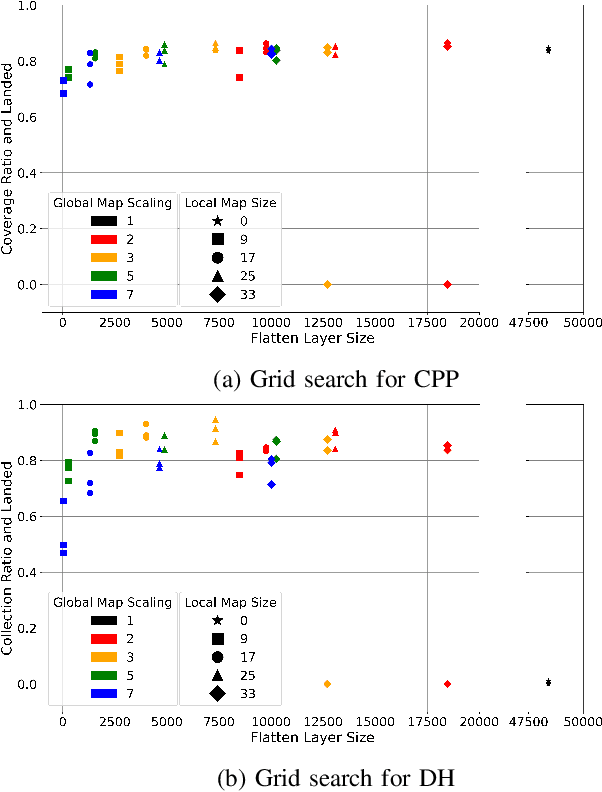
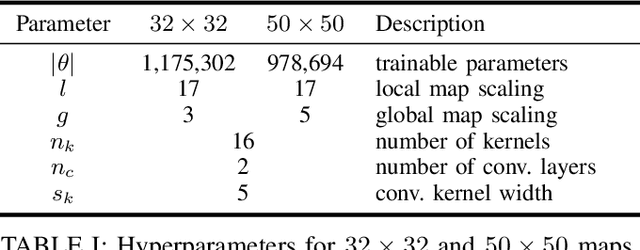
Path planning methods for autonomous unmanned aerial vehicles (UAVs) are typically designed for one specific type of mission. In this work, we present a method for autonomous UAV path planning based on deep reinforcement learning (DRL) that can be applied to a wide range of mission scenarios. Specifically, we compare coverage path planning (CPP), where the UAV's goal is to survey an area of interest to data harvesting (DH), where the UAV collects data from distributed Internet of Things (IoT) sensor devices. By exploiting structured map information of the environment, we train double deep Q-networks (DDQNs) with identical architectures on both distinctly different mission scenarios, to make movement decisions that balance the respective mission goal with navigation constraints. By introducing a novel approach exploiting a compressed global map of the environment combined with a cropped but uncompressed local map showing the vicinity of the UAV agent, we demonstrate that the proposed method can efficiently scale to large environments. We also extend previous results for generalizing control policies that require no retraining when scenario parameters change and offer a detailed analysis of crucial map processing parameters' effects on path planning performance.
Active Learning-Based Multistage Sequential Decision-Making Model with Application on Common Bile Duct Stone Evaluation
Jan 13, 2022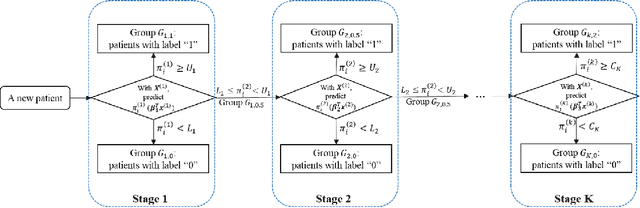
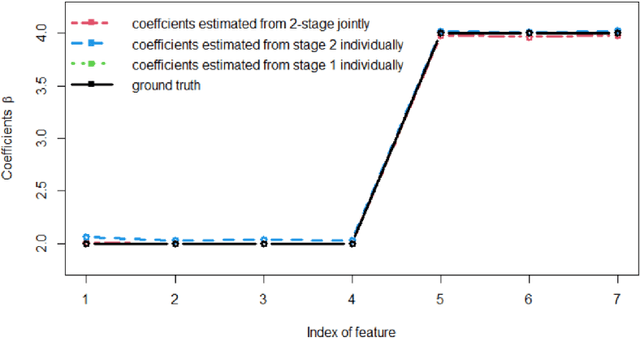
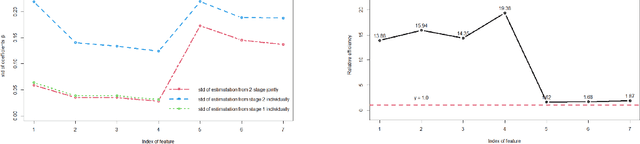
Multistage sequential decision-making scenarios are commonly seen in the healthcare diagnosis process. In this paper, an active learning-based method is developed to actively collect only the necessary patient data in a sequential manner. There are two novelties in the proposed method. First, unlike the existing ordinal logistic regression model which only models a single stage, we estimate the parameters for all stages together. Second, it is assumed that the coefficients for common features in different stages are kept consistent. The effectiveness of the proposed method is validated in both a simulation study and a real case study. Compared with the baseline method where the data is modeled individually and independently, the proposed method improves the estimation efficiency by 62\%-1838\%. For both simulation and testing cohorts, the proposed method is more effective, stable, interpretable, and computationally efficient on parameter estimation. The proposed method can be easily extended to a variety of scenarios where decision-making can be done sequentially with only necessary information.
SwiftAgg: Communication-Efficient and Dropout-Resistant Secure Aggregation for Federated Learning with Worst-Case Security Guarantees
Feb 08, 2022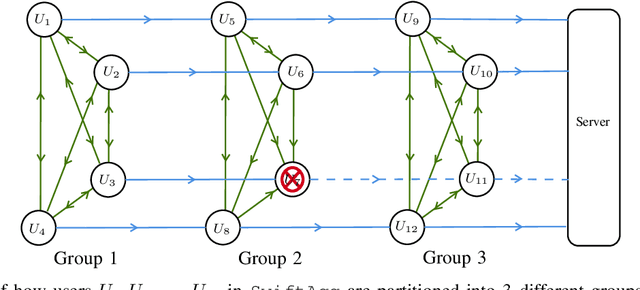
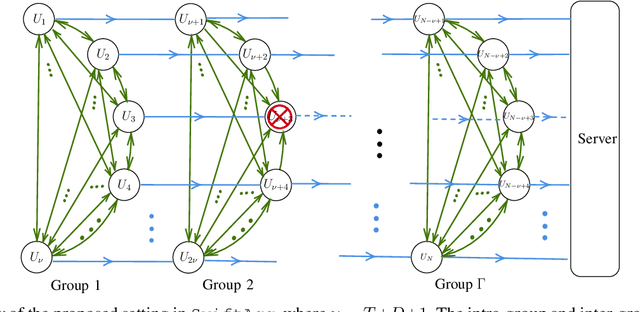

We propose SwiftAgg, a novel secure aggregation protocol for federated learning systems, where a central server aggregates local models of $N$ distributed users, each of size $L$, trained on their local data, in a privacy-preserving manner. Compared with state-of-the-art secure aggregation protocols, SwiftAgg significantly reduces the communication overheads without any compromise on security. Specifically, in presence of at most $D$ dropout users, SwiftAgg achieves a users-to-server communication load of $(T+1)L$ and a users-to-users communication load of up to $(N-1)(T+D+1)L$, with a worst-case information-theoretic security guarantee, against any subset of up to $T$ semi-honest users who may also collude with the curious server. The key idea of SwiftAgg is to partition the users into groups of size $D+T+1$, then in the first phase, secret sharing and aggregation of the individual models are performed within each group, and then in the second phase, model aggregation is performed on $D+T+1$ sequences of users across the groups. If a user in a sequence drops out in the second phase, the rest of the sequence remain silent. This design allows only a subset of users to communicate with each other, and only the users in a single group to directly communicate with the server, eliminating the requirements of 1) all-to-all communication network across users; and 2) all users communicating with the server, for other secure aggregation protocols. This helps to substantially slash the communication costs of the system.
Short-term Multi-horizon Residential Electric Load Forecasting using Deep Learning and Signal Decomposition Methods
Feb 01, 2022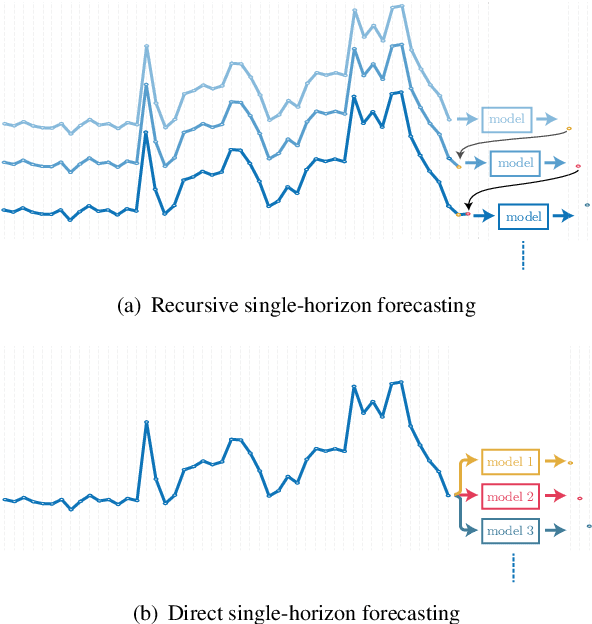

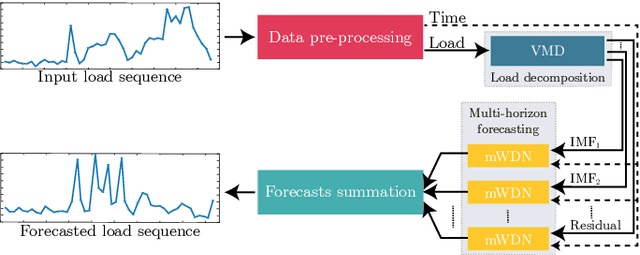
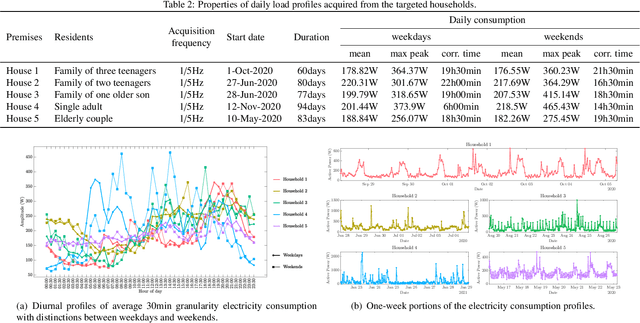
With the booming growth of advanced digital technologies, it has become possible for users as well as distributors of energy to obtain detailed and timely information about the electricity consumption of households. These technologies can also be used to forecast the household's electricity consumption (a.k.a. the load). In this paper, we investigate the use of Variational Mode Decomposition and deep learning techniques to improve the accuracy of the load forecasting problem. Although this problem has been studied in the literature, selecting an appropriate decomposition level and a deep learning technique providing better forecasting performance have garnered comparatively less attention. This study bridges this gap by studying the effect of six decomposition levels and five distinct deep learning networks. The raw load profiles are first decomposed into intrinsic mode functions using the Variational Mode Decomposition in order to mitigate their non-stationary aspect. Then, day, hour, and past electricity consumption data are fed as a three-dimensional input sequence to a four-level Wavelet Decomposition Network model. Finally, the forecast sequences related to the different intrinsic mode functions are combined to form the aggregate forecast sequence. The proposed method was assessed using load profiles of five Moroccan households from the Moroccan buildings' electricity consumption dataset (MORED) and was benchmarked against state-of-the-art time-series models and a baseline persistence model.