 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Comprehensive Survey of Few-shot Learning: Evolution, Applications, Challenges, and Opportunities
May 24, 2022

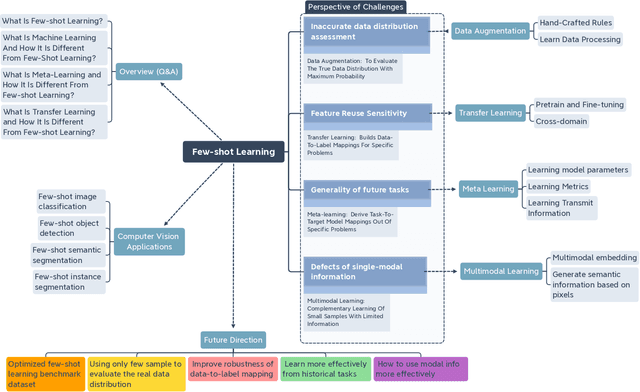
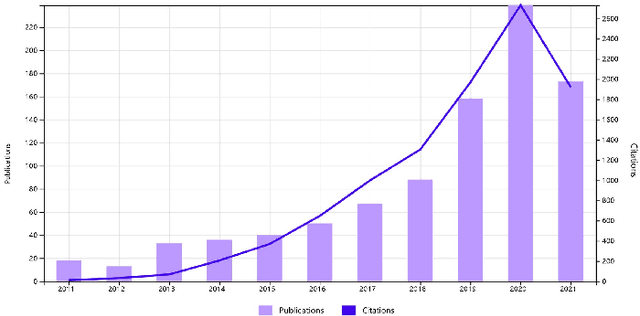
Few-shot learning (FSL) has emerged as an effective learning method and shows great potential. Despite the recent creative works in tackling FSL tasks, learning valid information rapidly from just a few or even zero samples still remains a serious challenge. In this context, we extensively investigated 200+ latest papers on FSL published in the past three years, aiming to present a timely and comprehensive overview of the most recent advances in FSL along with impartial comparisons of the strengths and weaknesses of the existing works. For the sake of avoiding conceptual confusion, we first elaborate and compare a set of similar concepts including few-shot learning, transfer learning, and meta-learning. Furthermore, we propose a novel taxonomy to classify the existing work according to the level of abstraction of knowledge in accordance with the challenges of FSL. To enrich this survey, in each subsection we provide in-depth analysis and insightful discussion about recent advances on these topics. Moreover, taking computer vision as an example, we highlight the important application of FSL, covering various research hotspots. Finally, we conclude the survey with unique insights into the technology evolution trends together with potential future research opportunities in the hope of providing guidance to follow-up research.
The Information in Emotion Communication
Feb 14, 2020How much information is transmitted when animals use emotions to communicate? It is clear that emotions are used as communication systems in humans and other species. The quantitative theory of emotion information presented here is based on Shannon's mathematical theory of information in communication systems. The theory explains myriad aspects of emotion communication and offers dozens of new directions for research. It is superior to the "contagion" theory of emotion spreading, which is currently dominant. One important application of the information theory of emotion communication is that it permits the development of emotion security systems for social networks to guard against the widespread emotion manipulation we see online today.
Data-Driven Sensor Selection Method Based on Proximal Optimization for High-Dimensional Data With Correlated Measurement Noise
May 12, 2022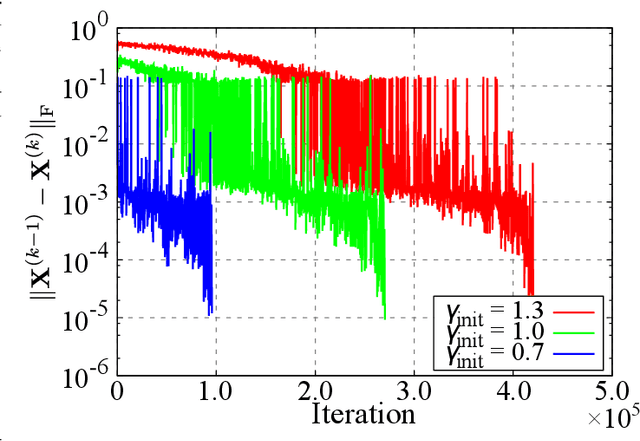
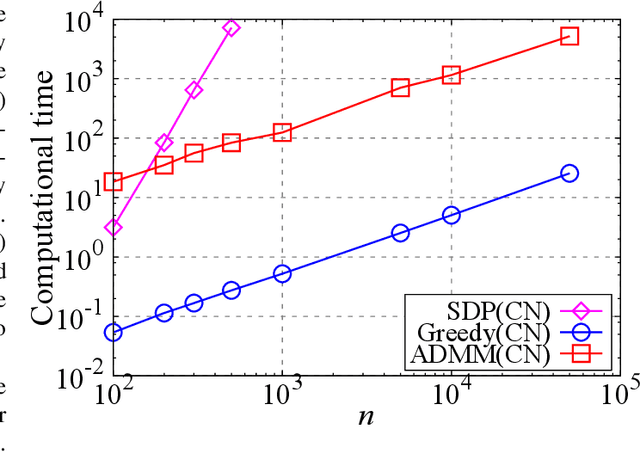
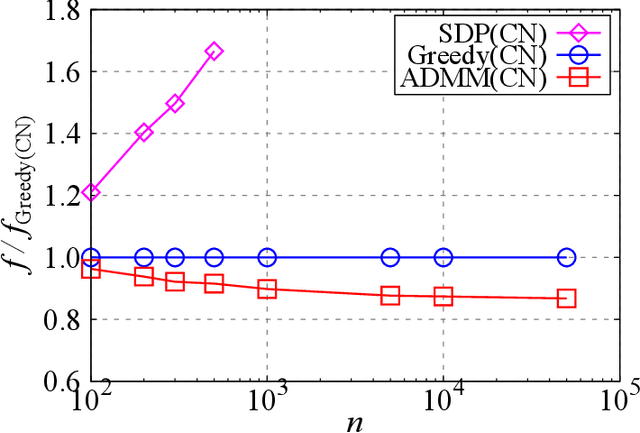
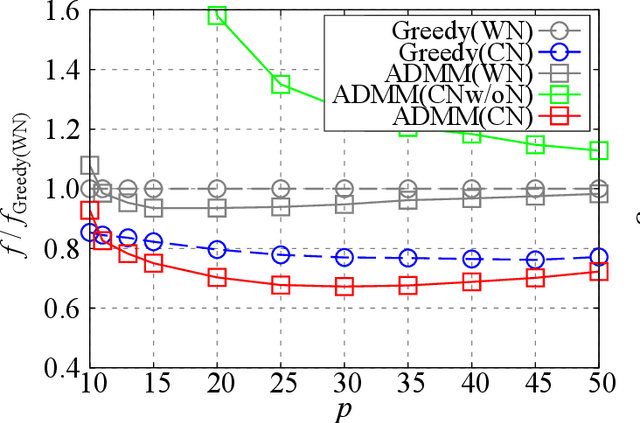
The present paper proposes a data-driven sensor selection method for a high-dimensional nondynamical system with strongly correlated measurement noise. The proposed method is based on proximal optimization and determines sensor locations by minimizing the trace of the inverse of the Fisher information matrix under a block-sparsity hard constraint. The proposed method can avoid the difficulty of sensor selection with strongly correlated measurement noise, in which the possible sensor locations must be known in advance for calculating the precision matrix for selecting sensor locations. The problem can be efficiently solved by the alternating direction method of multipliers, and the computational complexity of the proposed method is proportional to the number of potential sensor locations when it is used in combination with a low-rank expression of the measurement noise model. The advantage of the proposed method over existing sensor selection methods is demonstrated through experiments using artificial and real datasets.
StructToken : Rethinking Semantic Segmentation with Structural Prior
Apr 01, 2022
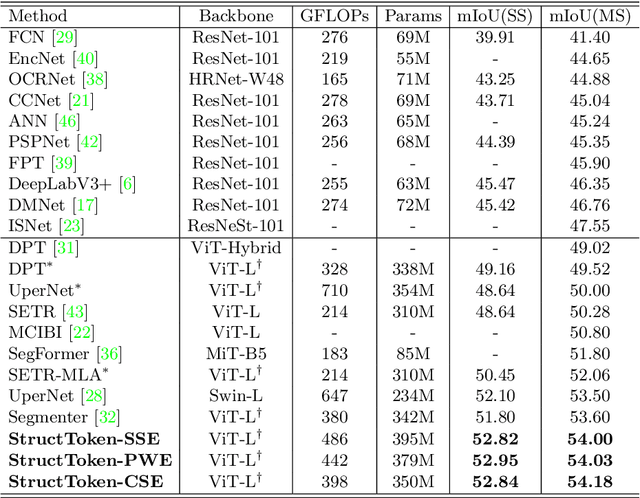
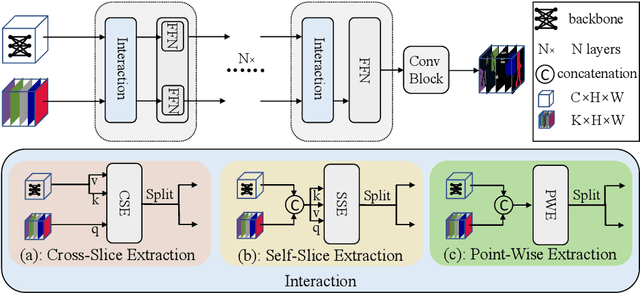
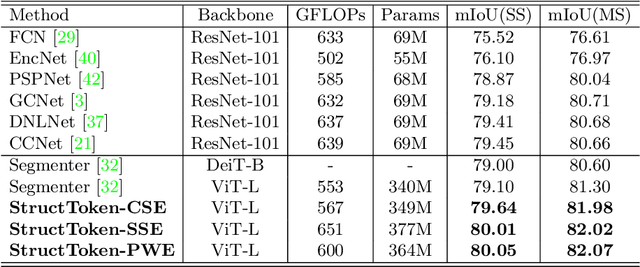
In this paper, we present structure token (StructToken), a new paradigm for semantic segmentation. From a perspective on semantic segmentation as per-pixel classification, the previous deep learning-based methods learn the per-pixel representation first through an encoder and a decoder head and then classify each pixel representation to a specific category to obtain the semantic masks. Differently, we propose a structure-aware algorithm that takes structural information as prior to predict semantic masks directly without per-pixel classification. Specifically, given an input image, the learnable structure token interacts with the image representations to reason the final semantic masks. Three interaction approaches are explored and the results not only outperform the state-of-the-art methods but also contain more structural information. Experiments are conducted on three widely used datasets including ADE20k, Cityscapes, and COCO-Stuff 10K. We hope that structure token could serve as an alternative for semantic segmentation and inspire future research.
How Tempering Fixes Data Augmentation in Bayesian Neural Networks
May 27, 2022
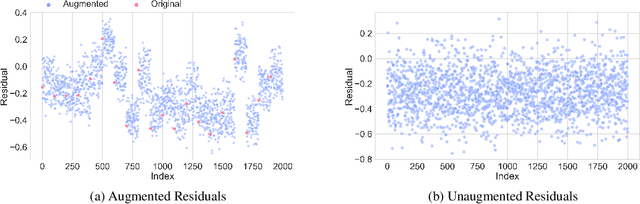
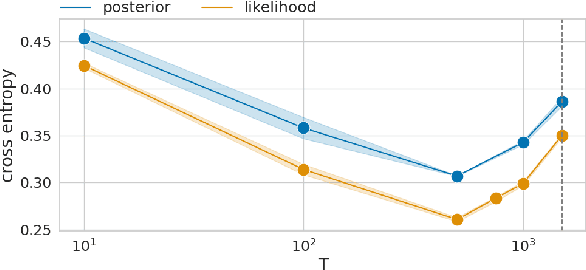
While Bayesian neural networks (BNNs) provide a sound and principled alternative to standard neural networks, an artificial sharpening of the posterior usually needs to be applied to reach comparable performance. This is in stark contrast to theory, dictating that given an adequate prior and a well-specified model, the untempered Bayesian posterior should achieve optimal performance. Despite the community's extensive efforts, the observed gains in performance still remain disputed with several plausible causes pointing at its origin. While data augmentation has been empirically recognized as one of the main drivers of this effect, a theoretical account of its role, on the other hand, is largely missing. In this work we identify two interlaced factors concurrently influencing the strength of the cold posterior effect, namely the correlated nature of augmentations and the degree of invariance of the employed model to such transformations. By theoretically analyzing simplified settings, we prove that tempering implicitly reduces the misspecification arising from modeling augmentations as i.i.d. data. The temperature mimics the role of the effective sample size, reflecting the gain in information provided by the augmentations. We corroborate our theoretical findings with extensive empirical evaluations, scaling to realistic BNNs. By relying on the framework of group convolutions, we experiment with models of varying inherent degree of invariance, confirming its hypothesized relationship with the optimal temperature.
On the Decentralization of Blockchain-enabled Asynchronous Federated Learning
May 20, 2022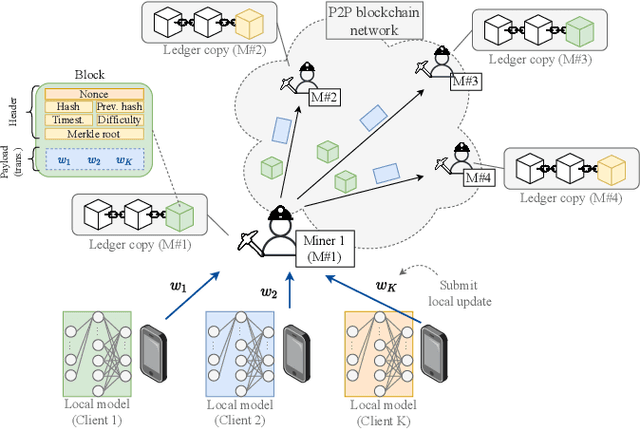
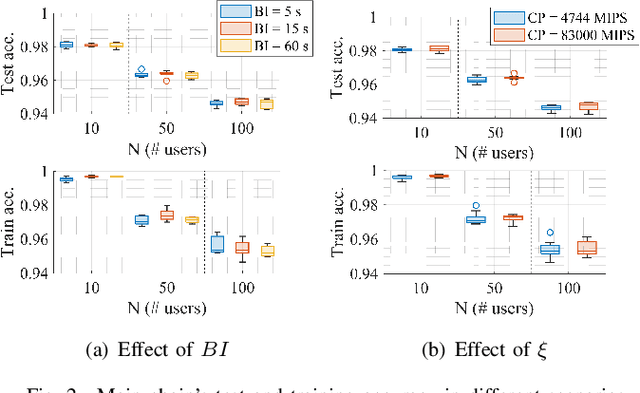
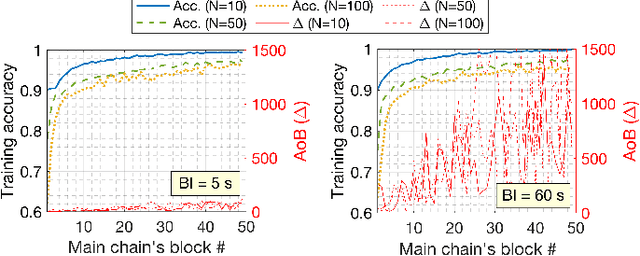
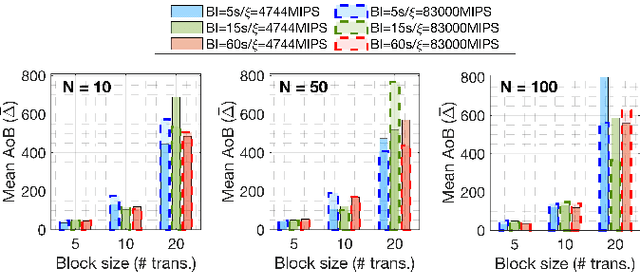
Federated learning (FL), thanks in part to the emergence of the edge computing paradigm, is expected to enable true real-time applications in production environments. However, its original dependence on a central server for orchestration raises several concerns in terms of security, privacy, and scalability. To solve some of these worries, blockchain technology is expected to bring decentralization, robustness, and enhanced trust to FL. The empowerment of FL through blockchain (also referred to as FLchain), however, has some implications in terms of ledger inconsistencies and age of information (AoI), which are naturally inherited from the blockchain's fully decentralized operation. Such issues stem from the fact that, given the temporary ledger versions in the blockchain, FL devices may use different models for training, and that, given the asynchronicity of the FL operation, stale local updates (computed using outdated models) may be generated. In this paper, we shed light on the implications of the FLchain setting and study the effect that both the AoI and ledger inconsistencies have on the FL performance. To that end, we provide a faithful simulation tool that allows capturing the decentralized and asynchronous nature of the FLchain operation.
Improving genetic risk prediction across diverse population by disentangling ancestry representations
May 10, 2022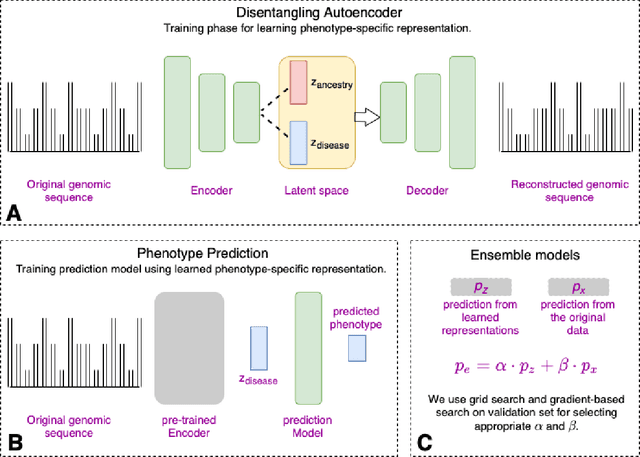
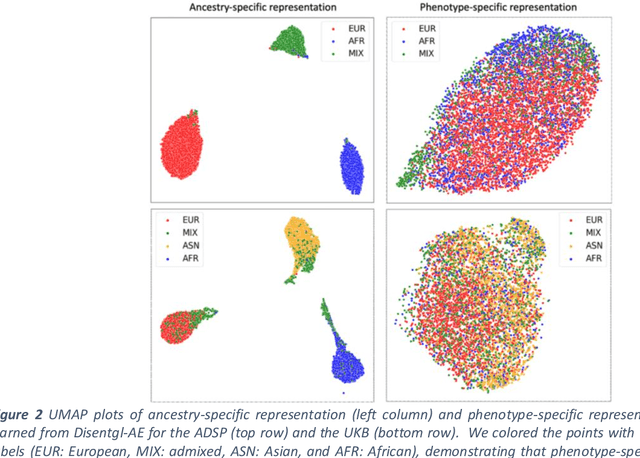
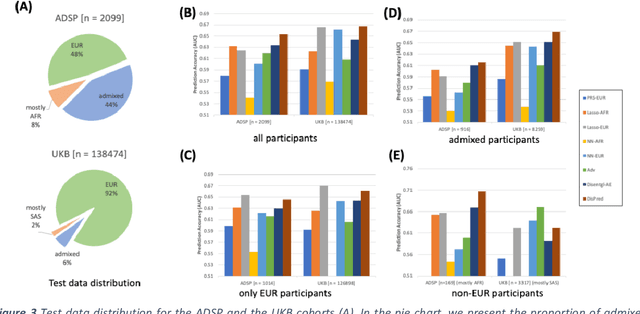
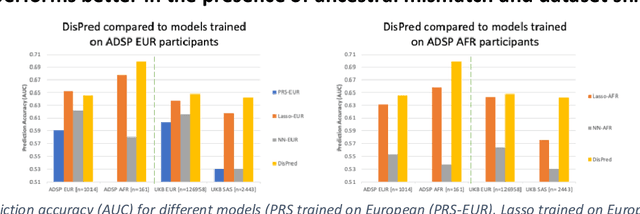
Risk prediction models using genetic data have seen increasing traction in genomics. However, most of the polygenic risk models were developed using data from participants with similar (mostly European) ancestry. This can lead to biases in the risk predictors resulting in poor generalization when applied to minority populations and admixed individuals such as African Americans. To address this bias, largely due to the prediction models being confounded by the underlying population structure, we propose a novel deep-learning framework that leverages data from diverse population and disentangles ancestry from the phenotype-relevant information in its representation. The ancestry disentangled representation can be used to build risk predictors that perform better across minority populations. We applied the proposed method to the analysis of Alzheimer's disease genetics. Comparing with standard linear and nonlinear risk prediction methods, the proposed method substantially improves risk prediction in minority populations, particularly for admixed individuals.
Robust Deep Reinforcement Learning via Multi-View Information Bottleneck
Feb 26, 2021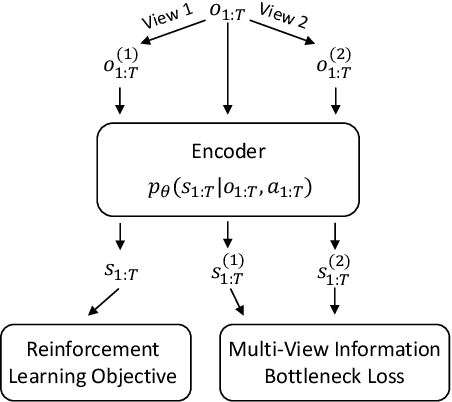
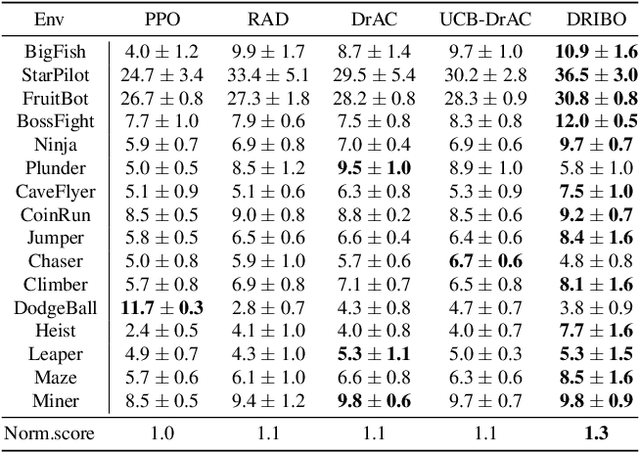

Deep reinforcement learning (DRL) agents are often sensitive to visual changes that were unseen in their training environments. To address this problem, we introduce a robust representation learning approach for RL. We introduce an auxiliary objective based on the multi-view information bottleneck (MIB) principle which encourages learning representations that are both predictive of the future and less sensitive to task-irrelevant distractions. This enables us to train high-performance policies that are robust to visual distractions and can generalize to unseen environments. We demonstrate that our approach can achieve SOTA performance on challenging visual control tasks, even when the background is replaced with natural videos. In addition, we show that our approach outperforms well-established baselines on generalization to unseen environments using the large-scale Procgen benchmark.
Group Meritocratic Fairness in Linear Contextual Bandits
Jun 07, 2022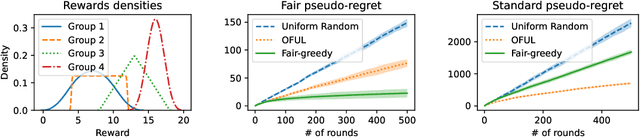
We study the linear contextual bandit problem where an agent has to select one candidate from a pool and each candidate belongs to a sensitive group. In this setting, candidates' rewards may not be directly comparable between groups, for example when the agent is an employer hiring candidates from different ethnic groups and some groups have a lower reward due to discriminatory bias and/or social injustice. We propose a notion of fairness that states that the agent's policy is fair when it selects a candidate with highest relative rank, which measures how good the reward is when compared to candidates from the same group. This is a very strong notion of fairness, since the relative rank is not directly observed by the agent and depends on the underlying reward model and on the distribution of rewards. Thus we study the problem of learning a policy which approximates a fair policy under the condition that the contexts are independent between groups and the distribution of rewards of each group is absolutely continuous. In particular, we design a greedy policy which at each round constructs a ridge regression estimator from the observed context-reward pairs, and then computes an estimate of the relative rank of each candidate using the empirical cumulative distribution function. We prove that the greedy policy achieves, after $T$ rounds, up to log factors and with high probability, a fair pseudo-regret of order $\sqrt{dT}$, where $d$ is the dimension of the context vectors. The policy also satisfies demographic parity at each round when averaged over all possible information available before the selection. We finally show with a proof of concept simulation that our policy achieves sub-linear fair pseudo-regret also in practice.
White-box Membership Attack Against Machine Learning Based Retinopathy Classification
May 30, 2022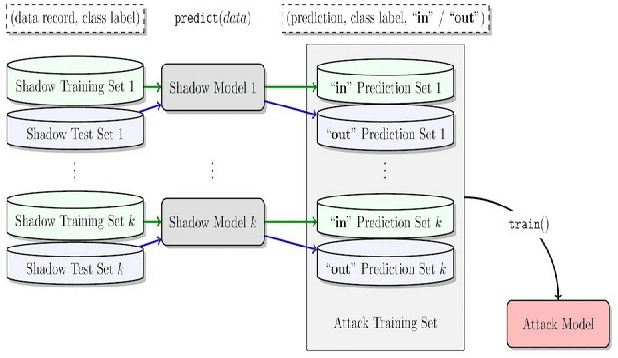
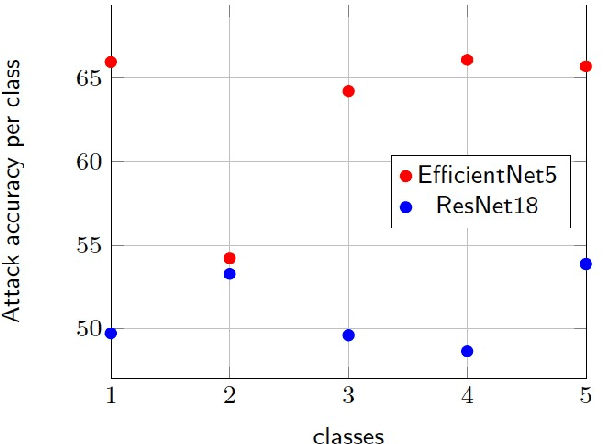
The advances in machine learning (ML) have greatly improved AI-based diagnosis aid systems in medical imaging. However, being based on collecting medical data specific to individuals induces several security issues, especially in terms of privacy. Even though the owner of the images like a hospital put in place strict privacy protection provisions at the level of its information system, the model trained over his images still holds disclosure potential. The trained model may be accessible to an attacker as: 1) White-box: accessing to the model architecture and parameters; 2) Black box: where he can only query the model with his own inputs through an appropriate interface. Existing attack methods include: feature estimation attacks (FEA), membership inference attack (MIA), model memorization attack (MMA) and identification attacks (IA). In this work we focus on MIA against a model that has been trained to detect diabetic retinopathy from retinal images. Diabetic retinopathy is a condition that can cause vision loss and blindness in the people who have diabetes. MIA is the process of determining whether a data sample comes from the training data set of a trained ML model or not. From a privacy perspective in our use case where a diabetic retinopathy classification model is given to partners that have at their disposal images along with patients' identifiers, inferring the membership status of a data sample can help to state if a patient has contributed or not to the training of the model.