 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Centroids Matching: an efficient Continual Learning approach operating in the embedding space
Aug 03, 2022
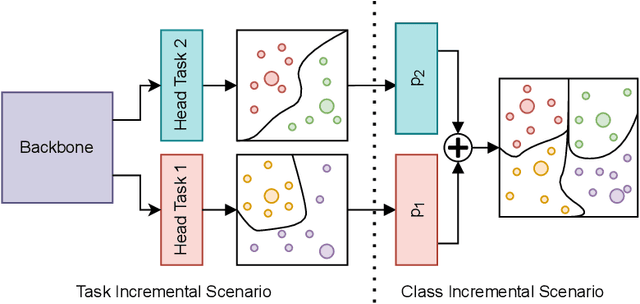
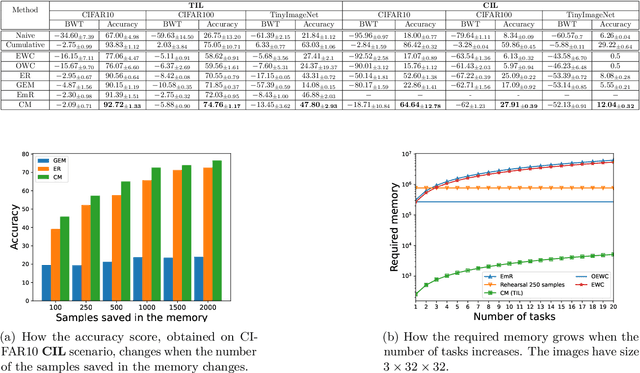

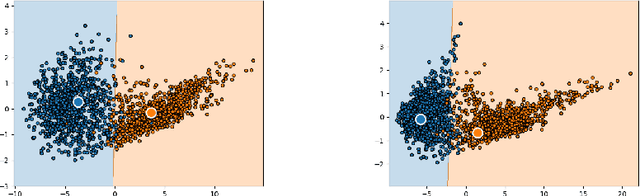
Catastrophic forgetting (CF) occurs when a neural network loses the information previously learned while training on a set of samples from a different distribution, i.e., a new task. Existing approaches have achieved remarkable results in mitigating CF, especially in a scenario called task incremental learning. However, this scenario is not realistic, and limited work has been done to achieve good results on more realistic scenarios. In this paper, we propose a novel regularization method called Centroids Matching, that, inspired by meta-learning approaches, fights CF by operating in the feature space produced by the neural network, achieving good results while requiring a small memory footprint. Specifically, the approach classifies the samples directly using the feature vectors produced by the neural network, by matching those vectors with the centroids representing the classes from the current task, or all the tasks up to that point. Centroids Matching is faster than competing baselines, and it can be exploited to efficiently mitigate CF, by preserving the distances between the embedding space produced by the model when past tasks were over, and the one currently produced, leading to a method that achieves high accuracy on all the tasks, without using an external memory when operating on easy scenarios, or using a small one for more realistic ones. Extensive experiments demonstrate that Centroids Matching achieves accuracy gains on multiple datasets and scenarios.
UFNRec: Utilizing False Negative Samples for Sequential Recommendation
Aug 08, 2022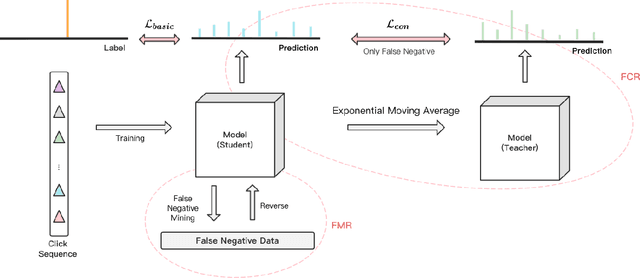
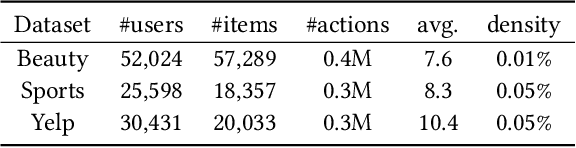
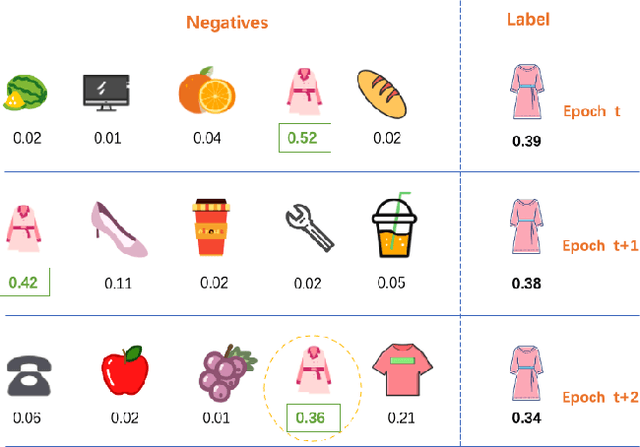
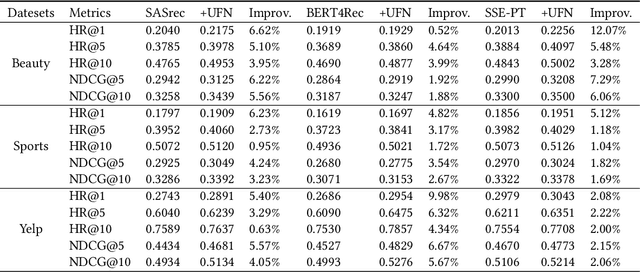
Sequential recommendation models are primarily optimized to distinguish positive samples from negative ones during training in which negative sampling serves as an essential component in learning the evolving user preferences through historical records. Except for randomly sampling negative samples from a uniformly distributed subset, many delicate methods have been proposed to mine negative samples with high quality. However, due to the inherent randomness of negative sampling, false negative samples are inevitably collected in model training. Current strategies mainly focus on removing such false negative samples, which leads to overlooking potential user interests, lack of recommendation diversity, less model robustness, and suffering from exposure bias. To this end, we propose a novel method that can Utilize False Negative samples for sequential Recommendation (UFNRec) to improve model performance. We first devise a simple strategy to extract false negative samples and then transfer these samples to positive samples in the following training process. Furthermore, we construct a teacher model to provide soft labels for false negative samples and design a consistency loss to regularize the predictions of these samples from the student model and the teacher model. To the best of our knowledge, this is the first work to utilize false negative samples instead of simply removing them for the sequential recommendation. Experiments on three benchmark public datasets are conducted using three widely applied SOTA models. The experiment results demonstrate that our proposed UFNRec can effectively draw information from false negative samples and further improve the performance of SOTA models. The code is available at https://github.com/UFNRec-code/UFNRec.
Short Blocklength Wiretap Channel Codes via Deep Learning: Design and Performance Evaluation
Jun 07, 2022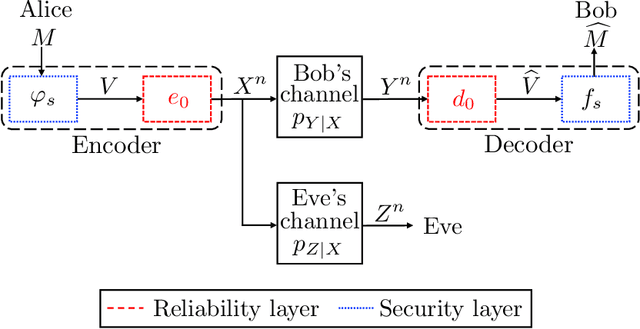
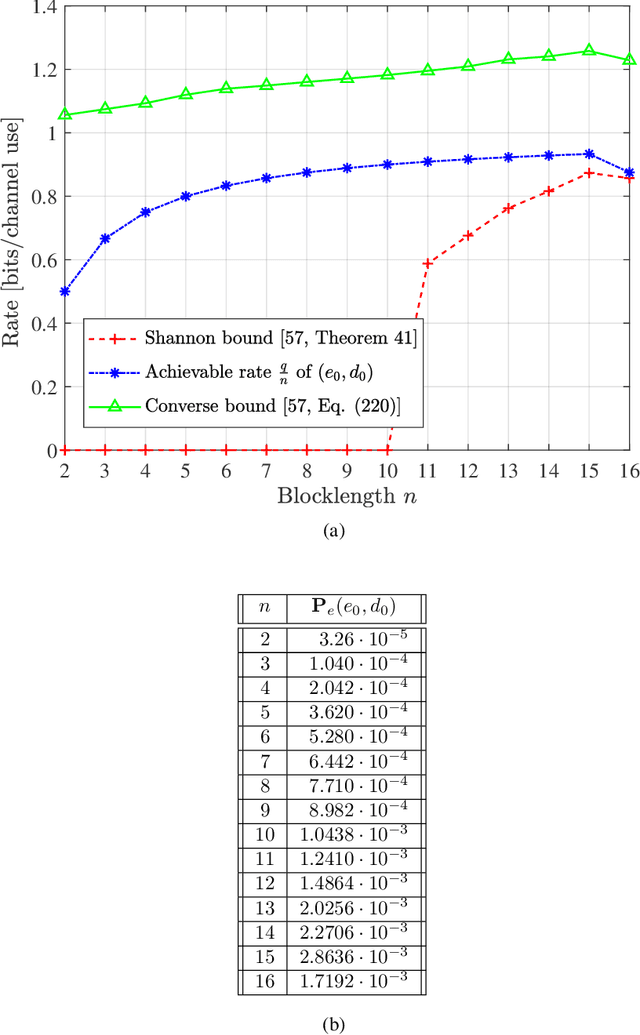
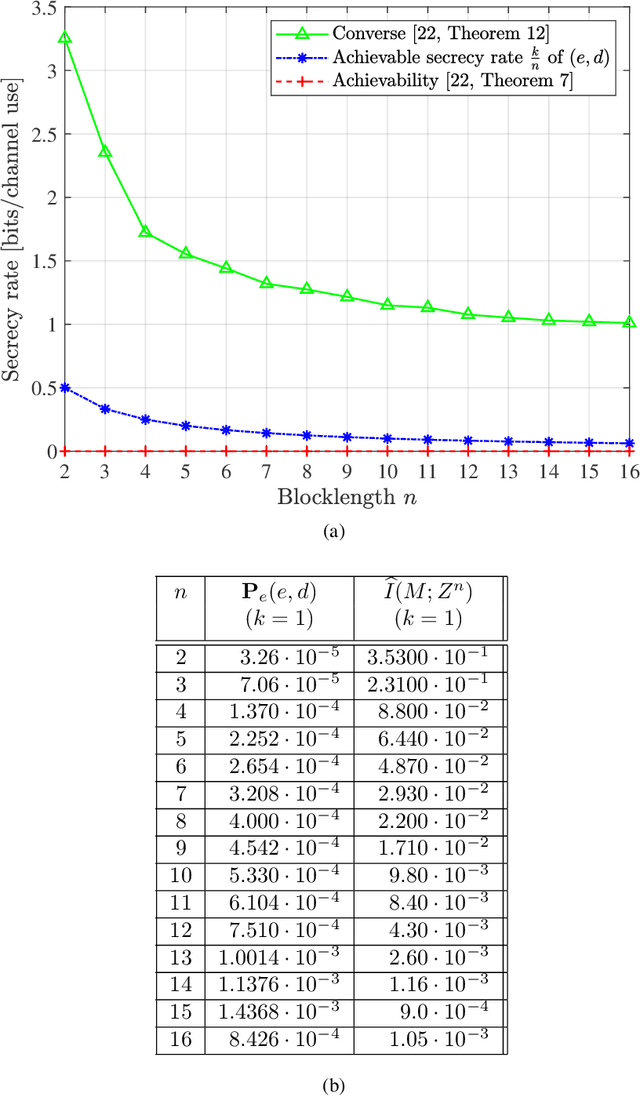
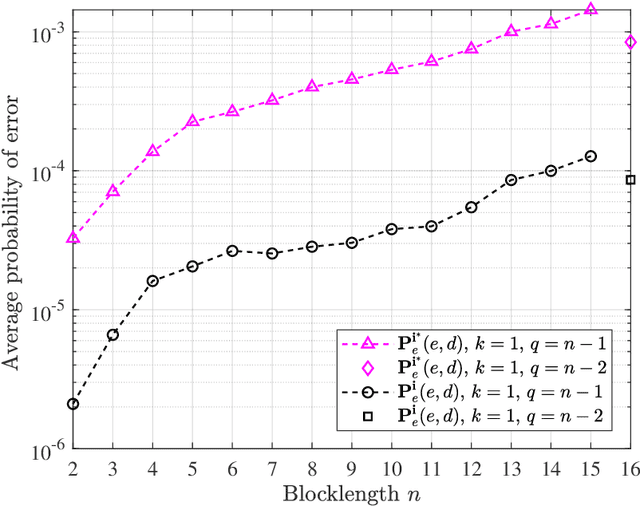
We design short blocklength codes for the Gaussian wiretap channel under information-theoretic security guarantees. Our approach consists in decoupling the reliability and secrecy constraints in our code design. Specifically, we handle the reliability constraint via an autoencoder, and handle the secrecy constraint with hash functions. For blocklengths smaller than or equal to 16, we evaluate through simulations the probability of error at the legitimate receiver and the leakage at the eavesdropper for our code construction. This leakage is defined as the mutual information between the confidential message and the eavesdropper's channel observations, and is empirically measured via a neural network-based mutual information estimator. Our simulation results provide examples of codes with positive secrecy rates that outperform the best known achievable secrecy rates obtained non-constructively for the Gaussian wiretap channel. Additionally, we show that our code design is suitable for the compound and arbitrarily varying Gaussian wiretap channels, for which the channel statistics are not perfectly known but only known to belong to a pre-specified uncertainty set. These models not only capture uncertainty related to channel statistics estimation, but also scenarios where the eavesdropper jams the legitimate transmission or influences its own channel statistics by changing its location.
An Overview of Distant Supervision for Relation Extraction with a Focus on Denoising and Pre-training Methods
Jul 17, 2022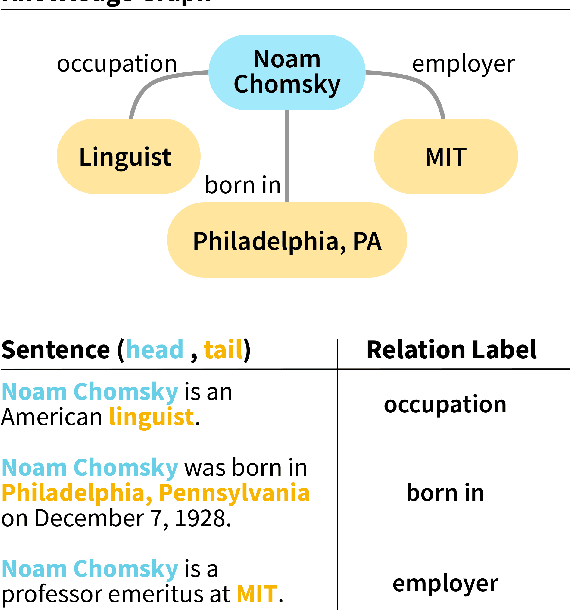
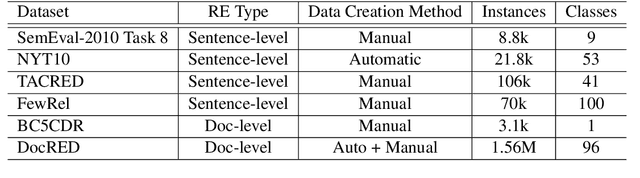

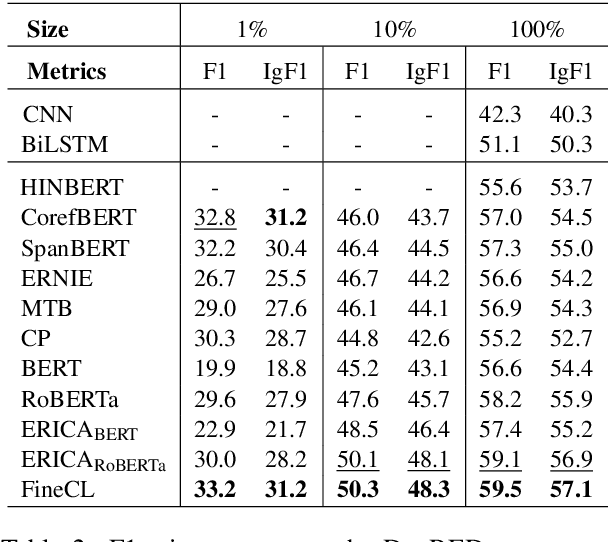
Relation Extraction (RE) is a foundational task of natural language processing. RE seeks to transform raw, unstructured text into structured knowledge by identifying relational information between entity pairs found in text. RE has numerous uses, such as knowledge graph completion, text summarization, question-answering, and search querying. The history of RE methods can be roughly organized into four phases: pattern-based RE, statistical-based RE, neural-based RE, and large language model-based RE. This survey begins with an overview of a few exemplary works in the earlier phases of RE, highlighting limitations and shortcomings to contextualize progress. Next, we review popular benchmarks and critically examine metrics used to assess RE performance. We then discuss distant supervision, a paradigm that has shaped the development of modern RE methods. Lastly, we review recent RE works focusing on denoising and pre-training methods.
Biologically Inspired Neural Path Finding
Jun 13, 2022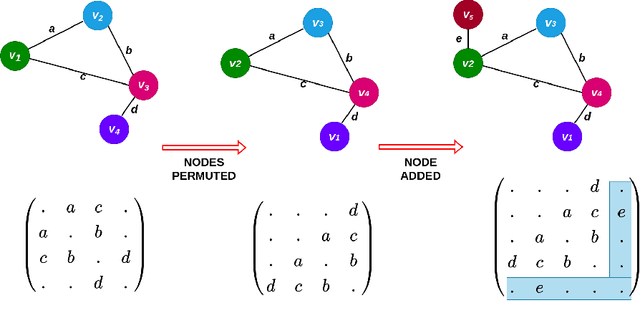
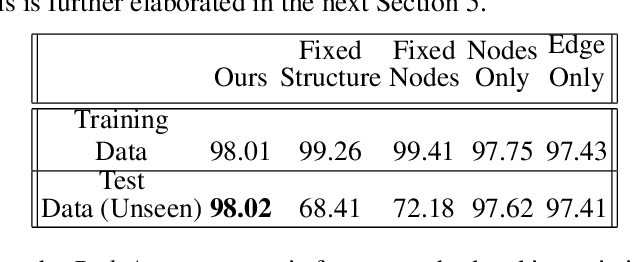
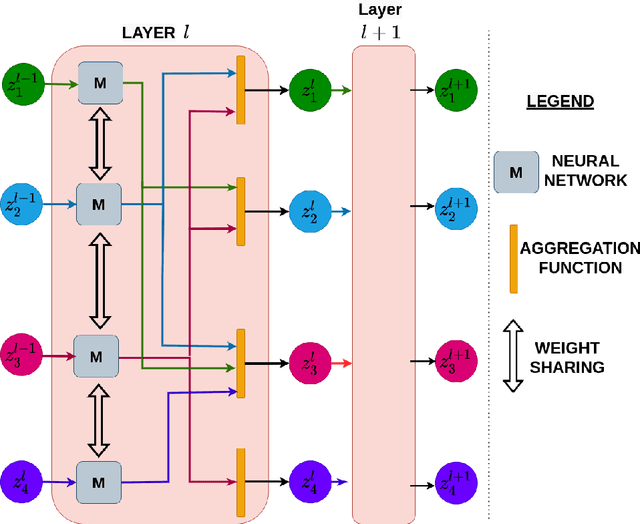
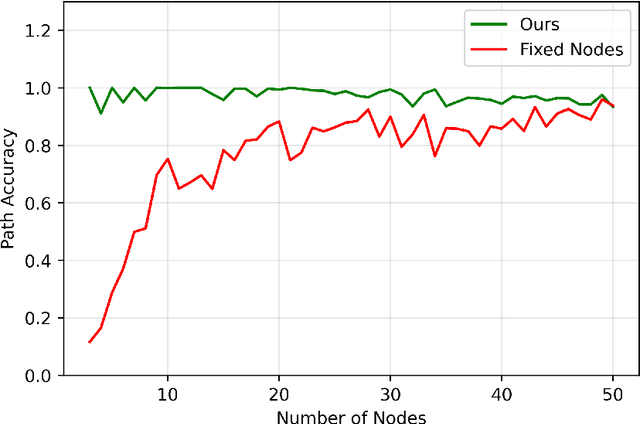
The human brain can be considered to be a graphical structure comprising of tens of billions of biological neurons connected by synapses. It has the remarkable ability to automatically re-route information flow through alternate paths in case some neurons are damaged. Moreover, the brain is capable of retaining information and applying it to similar but completely unseen scenarios. In this paper, we take inspiration from these attributes of the brain, to develop a computational framework to find the optimal low cost path between a source node and a destination node in a generalized graph. We show that our framework is capable of handling unseen graphs at test time. Moreover, it can find alternate optimal paths, when nodes are arbitrarily added or removed during inference, while maintaining a fixed prediction time. Code is available here: https://github.com/hangligit/pathfinding
Information Theoretic Key Agreement Protocol based on ECG signals
May 14, 2021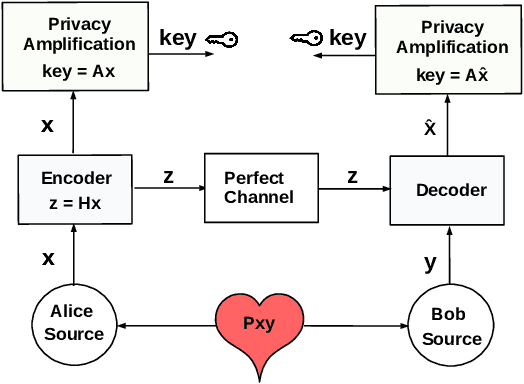
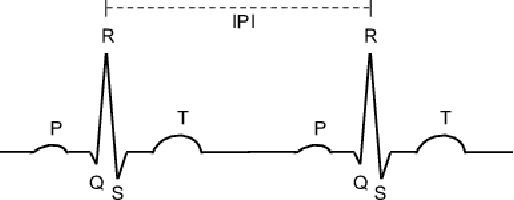
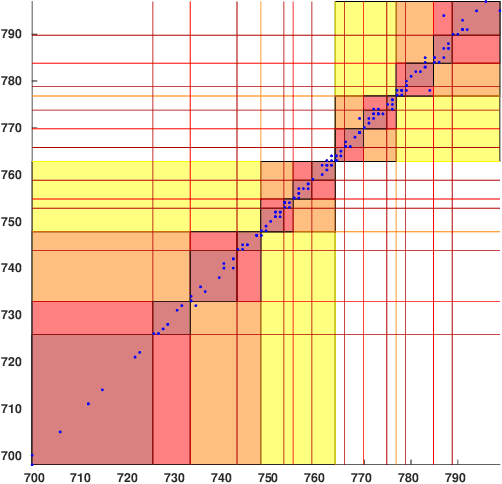
Wireless body area networks (WBANs) are becoming increasingly popular as they allow individuals to continuously monitor their vitals and physiological parameters remotely from the hospital. With the spread of the SARS-CoV-2 pandemic, the availability of portable pulse-oximeters and wearable heart rate detectors has boomed in the market. At the same time, in 2020 we assisted to an unprecedented increase of healthcare breaches, revealing the extreme vulnerability of the current generation of WBANs. Therefore, the development of new security protocols to ensure data protection, authentication, integrity and privacy within WBANs are highly needed. Here, we targeted a WBAN collecting ECG signals from different sensor nodes on the individual's body, we extracted the inter-pulse interval (i.e., R-R interval) sequence from each of them, and we developed a new information theoretic key agreement protocol that exploits the inherent randomness of ECG to ensure authentication between sensor pairs within the WBAN. After proper pre-processing, we provide an analytical solution that ensures robust authentication; we provide a unique information reconciliation matrix, which gives good performance for all ECG sensor pairs; and we can show that a relationship between information reconciliation and privacy amplification matrices can be found. Finally, we show the trade-off between the level of security, in terms of key generation rate, and the complexity of the error correction scheme implemented in the system.
Bilateral Network with Channel Splitting Network and Transformer for Thermal Image Super-Resolution
Jun 24, 2022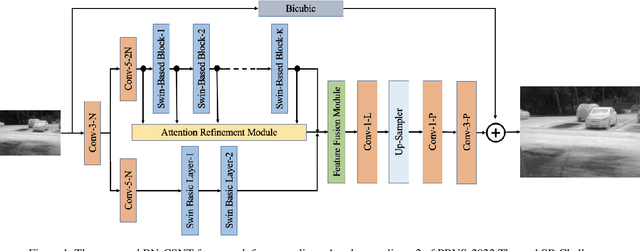
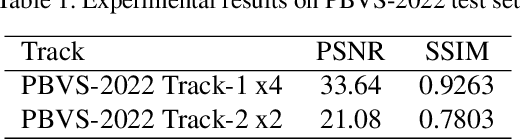
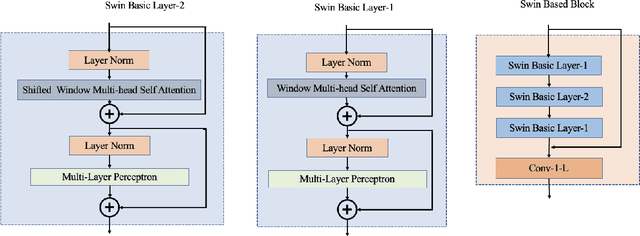
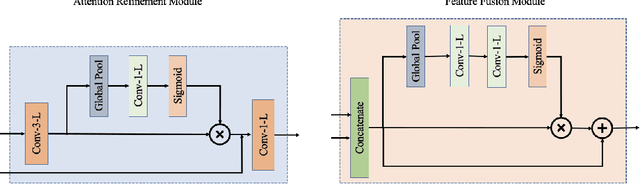
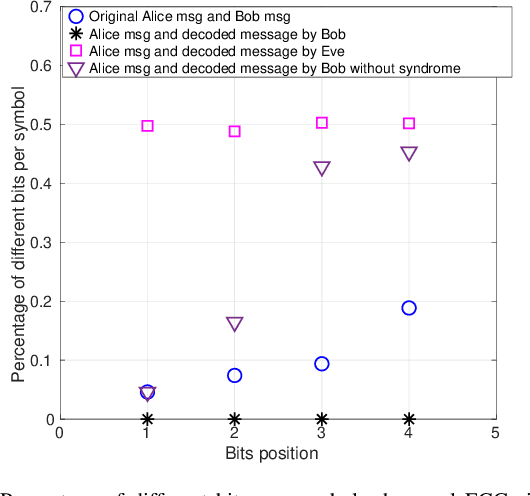
In recent years, the Thermal Image Super-Resolution (TISR) problem has become an attractive research topic. TISR would been used in a wide range of fields, including military, medical, agricultural and animal ecology. Due to the success of PBVS-2020 and PBVS-2021 workshop challenge, the result of TISR keeps improving and attracts more researchers to sign up for PBVS-2022 challenge. In this paper, we will introduce the technical details of our submission to PBVS-2022 challenge designing a Bilateral Network with Channel Splitting Network and Transformer(BN-CSNT) to tackle the TISR problem. Firstly, we designed a context branch based on channel splitting network with transformer to obtain sufficient context information. Secondly, we designed a spatial branch with shallow transformer to extract low level features which can preserve the spatial information. Finally, for the context branch in order to fuse the features from channel splitting network and transformer, we proposed an attention refinement module, and then features from context branch and spatial branch are fused by proposed feature fusion module. The proposed method can achieve PSNR=33.64, SSIM=0.9263 for x4 and PSNR=21.08, SSIM=0.7803 for x2 in the PBVS-2022 challenge test dataset.
A Multi-Dimensional Matrix Pencil-Based Channel Prediction Method for Massive MIMO with Mobility
Aug 03, 2022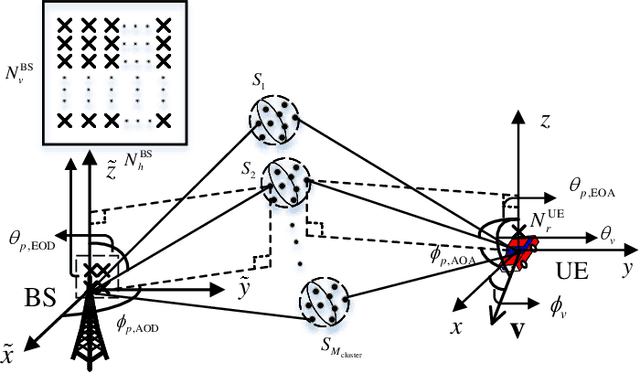
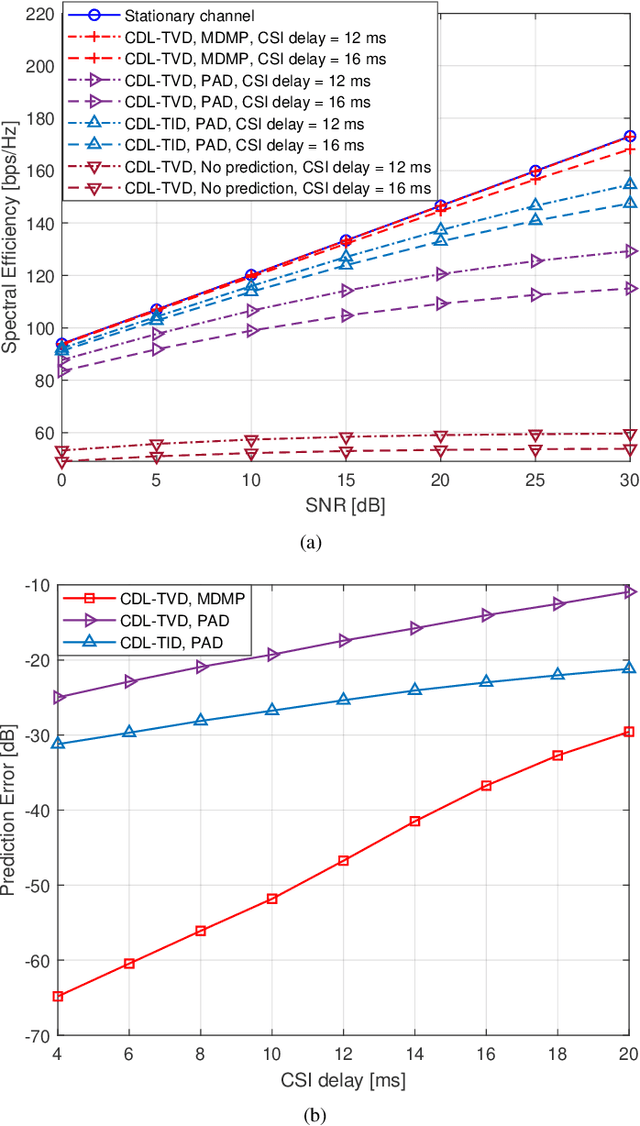
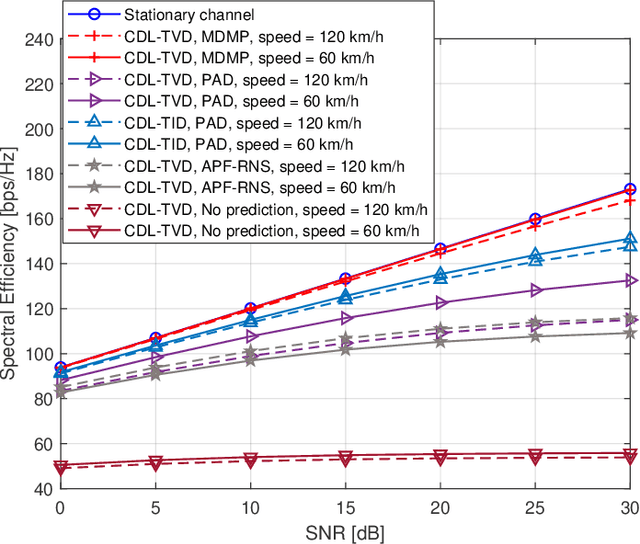
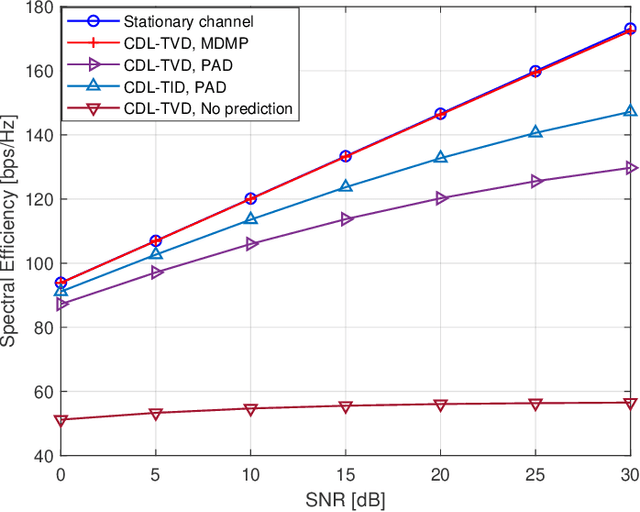
This paper addresses the mobility problem in massive multiple-input multiple-output systems, which leads to significant performance losses in the practical deployment of the fifth generation mobile communication networks. We propose a novel channel prediction method based on multi-dimensional matrix pencil (MDMP), which estimates the path parameters by exploiting the angular-frequency-domain and angular-time-domain structures of the wideband channel. The MDMP method also entails a novel path pairing scheme to pair the delay and Doppler, based on the super-resolution property of the angle estimation. Our method is able to deal with the realistic constraint of time-varying path delays introduced by user movements, which has not been considered so far in the literature. We prove theoretically that in the scenario with time-varying path delays, the prediction error converges to zero with the increasing number of the base station (BS) antennas, providing that only two arbitrary channel samples are known. We also derive a lower-bound of the number of the BS antennas to achieve a satisfactory performance. Simulation results under the industrial channel model of 3GPP demonstrate that our proposed MDMP method approaches the performance of the stationary scenario even when the users' velocity reaches 120 km/h and the latency of the channel state information is as large as 16 ms.
SURIMI: Supervised Radio Map Augmentation with Deep Learning and a Generative Adversarial Network for Fingerprint-based Indoor Positioning
Jul 13, 2022
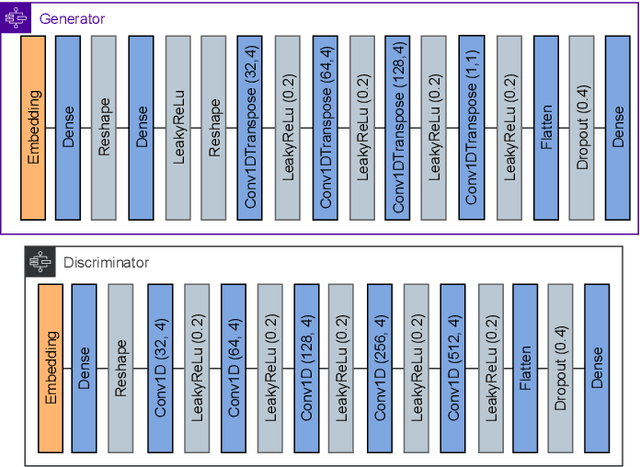
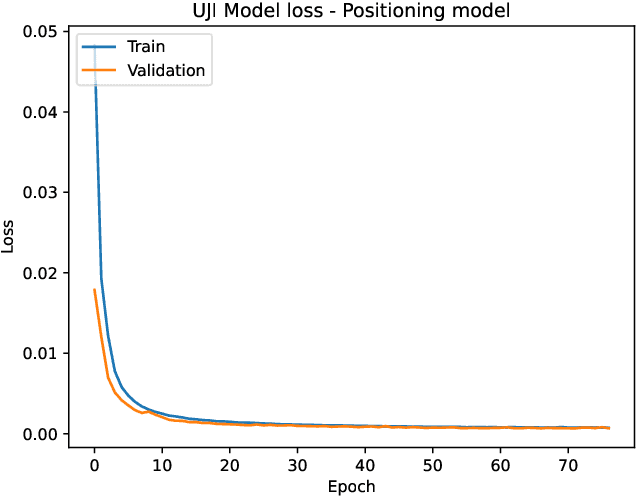
Indoor Positioning based on Machine Learning has drawn increasing attention both in the academy and the industry as meaningful information from the reference data can be extracted. Many researchers are using supervised, semi-supervised, and unsupervised Machine Learning models to reduce the positioning error and offer reliable solutions to the end-users. In this article, we propose a new architecture by combining Convolutional Neural Network (CNN), Long short-term memory (LSTM) and Generative Adversarial Network (GAN) in order to increase the training data and thus improve the position accuracy. The proposed combination of supervised and unsupervised models was tested in 17 public datasets, providing an extensive analysis of its performance. As a result, the positioning error has been reduced in more than 70% of them.
Learning Representations for CSI Adaptive Quantization and Feedback
Jul 13, 2022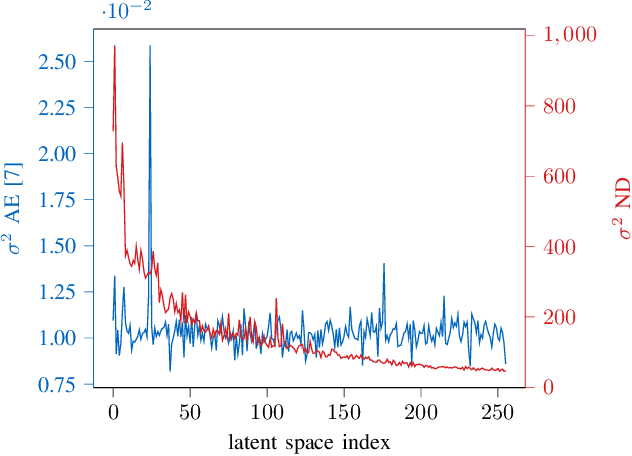
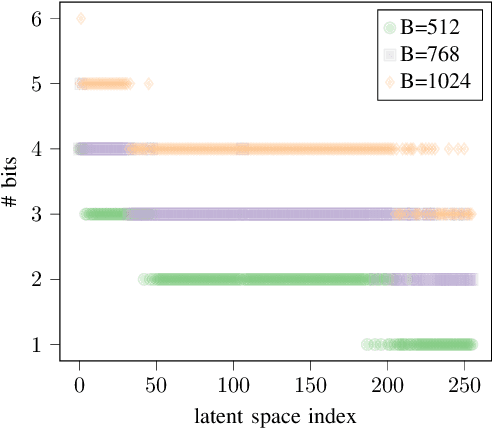
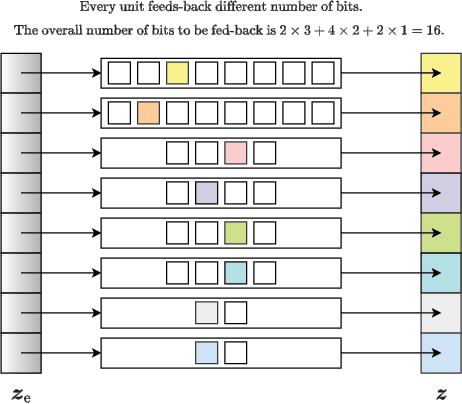
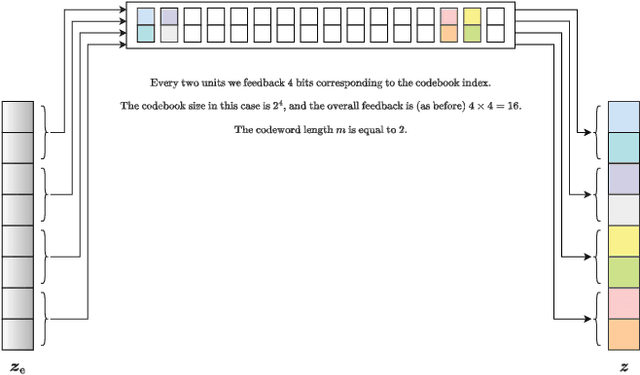
In this work, we propose an efficient method for channel state information (CSI) adaptive quantization and feedback in frequency division duplexing (FDD) systems. Existing works mainly focus on the implementation of autoencoder (AE) neural networks (NNs) for CSI compression, and consider straightforward quantization methods, e.g., uniform quantization, which are generally not optimal. With this strategy, it is hard to achieve a low reconstruction error, especially, when the available number of bits reserved for the latent space quantization is small. To address this issue, we recommend two different methods: one based on a post training quantization and the second one in which the codebook is found during the training of the AE. Both strategies achieve better reconstruction accuracy compared to standard quantization techniques.