 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
'Labelling the Gaps': A Weakly Supervised Automatic Eye Gaze Estimation
Aug 12, 2022

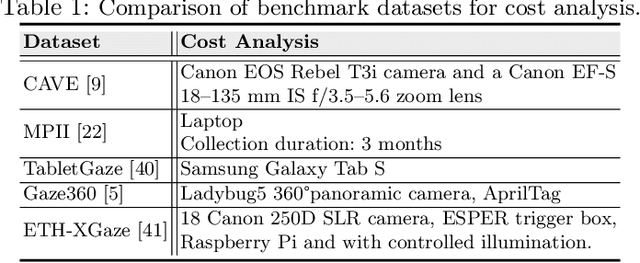
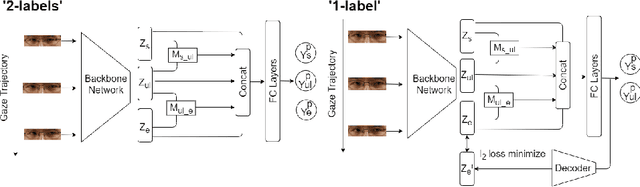
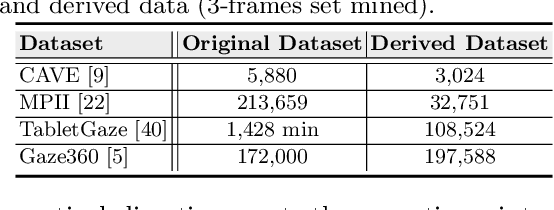
Over the past few years, there has been an increasing interest to interpret gaze direction in an unconstrained environment with limited supervision. Owing to data curation and annotation issues, replicating gaze estimation method to other platforms, such as unconstrained outdoor or AR/VR, might lead to significant drop in performance due to insufficient availability of accurately annotated data for model training. In this paper, we explore an interesting yet challenging problem of gaze estimation method with a limited amount of labelled data. The proposed method distills knowledge from the labelled subset with visual features; including identity-specific appearance, gaze trajectory consistency and motion features. Given a gaze trajectory, the method utilizes label information of only the start and the end frames of a gaze sequence. An extension of the proposed method further reduces the requirement of labelled frames to only the start frame with a minor drop in the generated label's quality. We evaluate the proposed method on four benchmark datasets (CAVE, TabletGaze, MPII and Gaze360) as well as web-crawled YouTube videos. Our proposed method reduces the annotation effort to as low as 2.67%, with minimal impact on performance; indicating the potential of our model enabling gaze estimation 'in-the-wild' setup.
Predictive Object-Centric Process Monitoring
Jul 20, 2022



The automation and digitalization of business processes has resulted in large amounts of data captured in information systems, which can aid businesses in understanding their processes better, improve workflows, or provide operational support. By making predictions about ongoing processes, bottlenecks can be identified and resources reallocated, as well as insights gained into the state of a process instance (case). Traditionally, data is extracted from systems in the form of an event log with a single identifying case notion, such as an order id for an Order to Cash (O2C) process. However, real processes often have multiple object types, for example, order, item, and package, so a format that forces the use of a single case notion does not reflect the underlying relations in the data. The Object-Centric Event Log (OCEL) format was introduced to correctly capture this information. The state-of-the-art predictive methods have been tailored to only traditional event logs. This thesis shows that a prediction method utilizing Generative Adversarial Networks (GAN), Long Short-Term Memory (LSTM) architectures, and Sequence to Sequence models (Seq2seq), can be augmented with the rich data contained in OCEL. Objects in OCEL can have attributes that are useful in predicting the next event and timestamp, such as a priority class attribute for an object type package indicating slower or faster processing. In the metrics of sequence similarity of predicted remaining events and mean absolute error (MAE) of the timestamp, the approach in this thesis matches or exceeds previous research, depending on whether selected object attributes are useful features for the model. Additionally, this thesis provides a web interface to predict the next sequence of activities from user input.
Facial Image Reconstruction from Functional Magnetic Resonance Imaging via GAN Inversion with Improved Attribute Consistency
Jul 03, 2022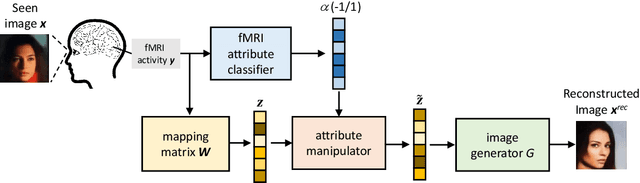


Neuroscience studies have revealed that the brain encodes visual content and embeds information in neural activity. Recently, deep learning techniques have facilitated attempts to address visual reconstructions by mapping brain activity to image stimuli using generative adversarial networks (GANs). However, none of these studies have considered the semantic meaning of latent code in image space. Omitting semantic information could potentially limit the performance. In this study, we propose a new framework to reconstruct facial images from functional Magnetic Resonance Imaging (fMRI) data. With this framework, the GAN inversion is first applied to train an image encoder to extract latent codes in image space, which are then bridged to fMRI data using linear transformation. Following the attributes identified from fMRI data using an attribute classifier, the direction in which to manipulate attributes is decided and the attribute manipulator adjusts the latent code to improve the consistency between the seen image and the reconstructed image. Our experimental results suggest that the proposed framework accomplishes two goals: (1) reconstructing clear facial images from fMRI data and (2) maintaining the consistency of semantic characteristics.
A Multi-Party Dialogue Ressource in French
Jul 25, 2022
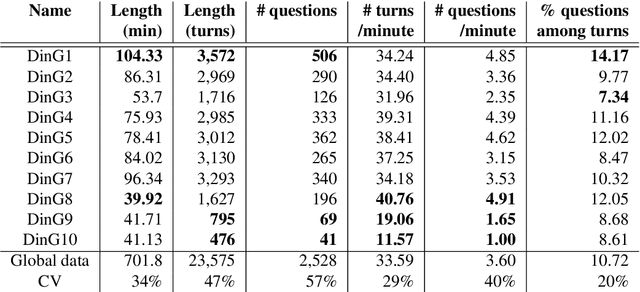

We present Dialogues in Games (DinG), a corpus of manual transcriptions of real-life, oral, spontaneous multi-party dialogues between French-speaking players of the board game Catan. Our objective is to make available a quality resource for French, composed of long dialogues, to facilitate their study in the style of (Asher et al., 2016). In a general dialogue setting, participants share personal information, which makes it impossible to disseminate the resource freely and openly. In DinG, the attention of the participants is focused on the game, which prevents them from talking about themselves. In addition, we are conducting a study on the nature of the questions in dialogue, through annotation (Cruz Blandon et al., 2019), in order to develop more natural automatic dialogue systems.
Analyzing Speaker Information in Self-Supervised Models to Improve Zero-Resource Speech Processing
Aug 02, 2021
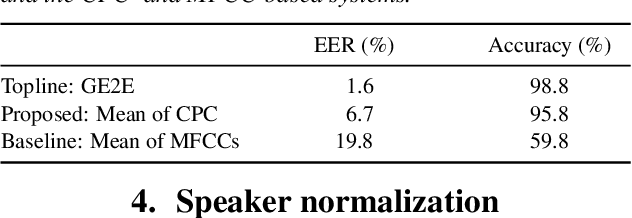
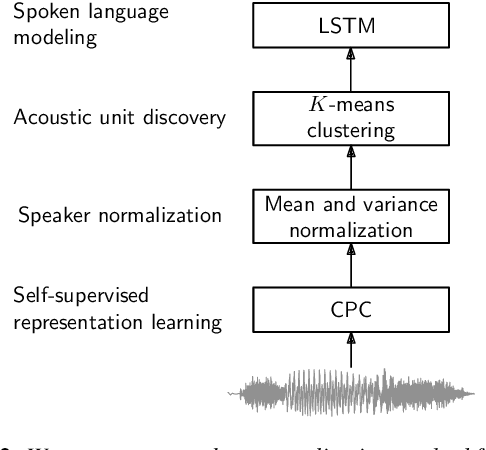
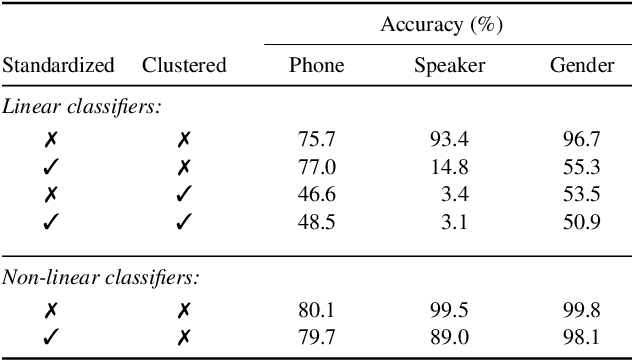
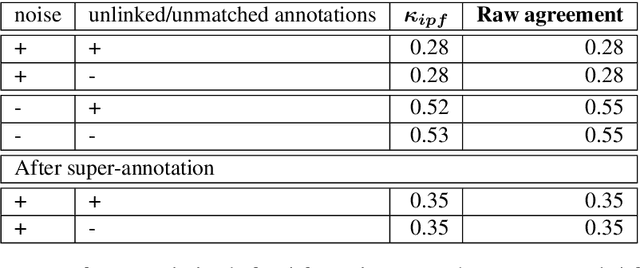
Contrastive predictive coding (CPC) aims to learn representations of speech by distinguishing future observations from a set of negative examples. Previous work has shown that linear classifiers trained on CPC features can accurately predict speaker and phone labels. However, it is unclear how the features actually capture speaker and phonetic information, and whether it is possible to normalize out the irrelevant details (depending on the downstream task). In this paper, we first show that the per-utterance mean of CPC features captures speaker information to a large extent. Concretely, we find that comparing means performs well on a speaker verification task. Next, probing experiments show that standardizing the features effectively removes speaker information. Based on this observation, we propose a speaker normalization step to improve acoustic unit discovery using K-means clustering of CPC features. Finally, we show that a language model trained on the resulting units achieves some of the best results in the ZeroSpeech2021~Challenge.
A Benchmark dataset for predictive maintenance
Jul 18, 2022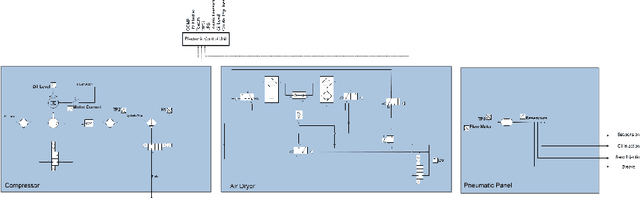
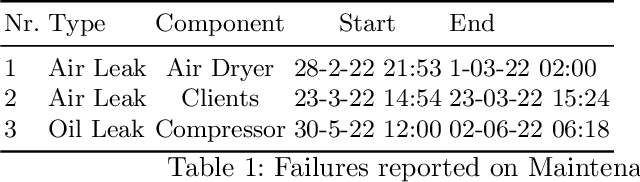
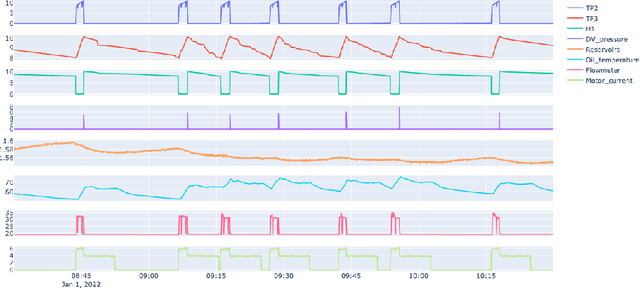
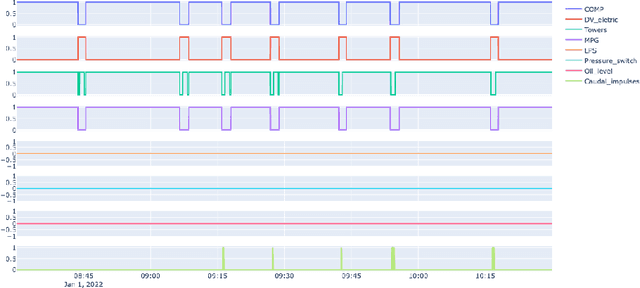
The paper describes the MetroPT data set, an outcome of a eXplainable Predictive Maintenance (XPM) project with an urban metro public transportation service in Porto, Portugal. The data was collected in 2022 that aimed to evaluate machine learning methods for online anomaly detection and failure prediction. By capturing several analogic sensor signals (pressure, temperature, current consumption), digital signals (control signals, discrete signals), and GPS information (latitude, longitude, and speed), we provide a dataset that can be easily used to evaluate online machine learning methods. This dataset contains some interesting characteristics and can be a good benchmark for predictive maintenance models.
Leveraging Dynamic Objects for Relative Localization Correction in a Connected Autonomous Vehicle Network
May 30, 2022



High-accurate localization is crucial for the safety and reliability of autonomous driving, especially for the information fusion of collective perception that aims to further improve road safety by sharing information in a communication network of ConnectedAutonomous Vehicles (CAV). In this scenario, small localization errors can impose additional difficulty on fusing the information from different CAVs. In this paper, we propose a RANSAC-based (RANdom SAmple Consensus) method to correct the relative localization errors between two CAVs in order to ease the information fusion among the CAVs. Different from previous LiDAR-based localization algorithms that only take the static environmental information into consideration, this method also leverages the dynamic objects for localization thanks to the real-time data sharing between CAVs. Specifically, in addition to the static objects like poles, fences, and facades, the object centers of the detected dynamic vehicles are also used as keypoints for the matching of two point sets. The experiments on the synthetic dataset COMAP show that the proposed method can greatly decrease the relative localization error between two CAVs to less than 20cmas far as there are enough vehicles and poles are correctly detected by bothCAVs. Besides, our proposed method is also highly efficient in runtime and can be used in real-time scenarios of autonomous driving.
A Spatially Separable Attention Mechanism for massive MIMO CSI Feedback
Aug 05, 2022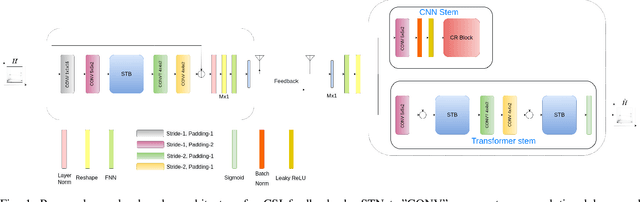
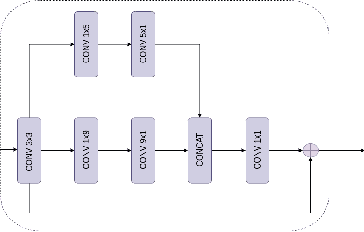
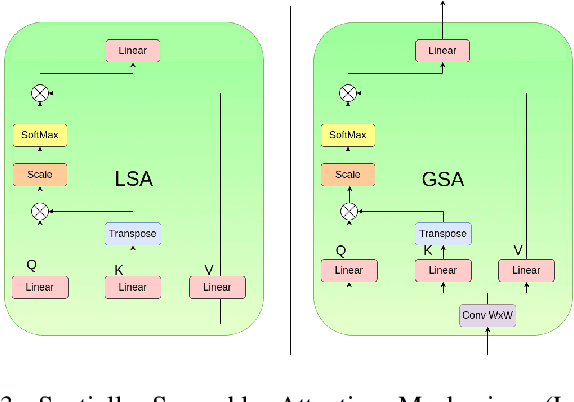
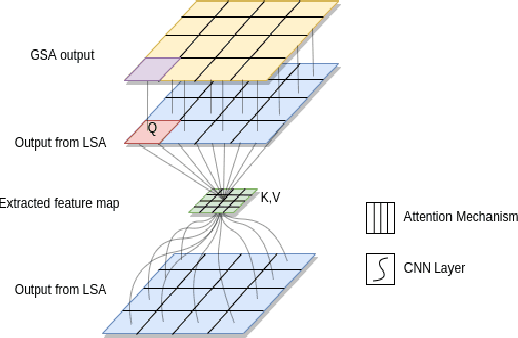
Channel State Information (CSI) Feedback plays a crucial role in achieving higher gains through beamforming. However, for a massive MIMO system, this feedback overhead is huge and grows linearly with the number of antennas. To reduce the feedback overhead several compressive sensing (CS) techniques were implemented in recent years but these techniques are often iterative and are computationally complex to realize in power-constrained user equipment (UE). Hence, a data-based deep learning approach took over in these recent years introducing a variety of neural networks for CSI compression. Specifically, transformer-based networks have been shown to achieve state-of-the-art performance. However, the multi-head attention operation, which is at the core of transformers, is computationally complex making transformers difficult to implement on a UE. In this work, we present a lightweight transformer named STNet which uses a spatially separable attention mechanism that is significantly less complex than the traditional full-attention. Equipped with this, STNet outperformed state-of-the-art models in some scenarios with approximately $1/10^{th}$ of the resources.
Rayleigh Regression Model for Ground Type Detection in SAR Imagery
Jul 23, 2022
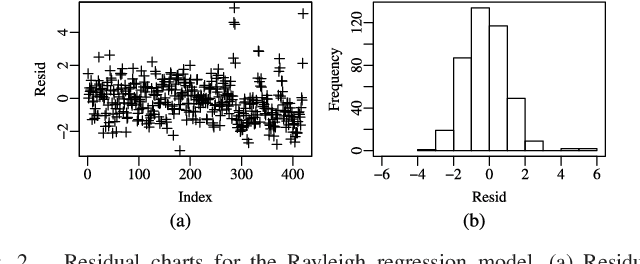
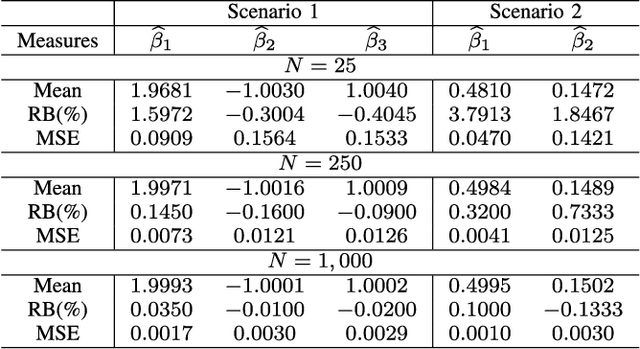
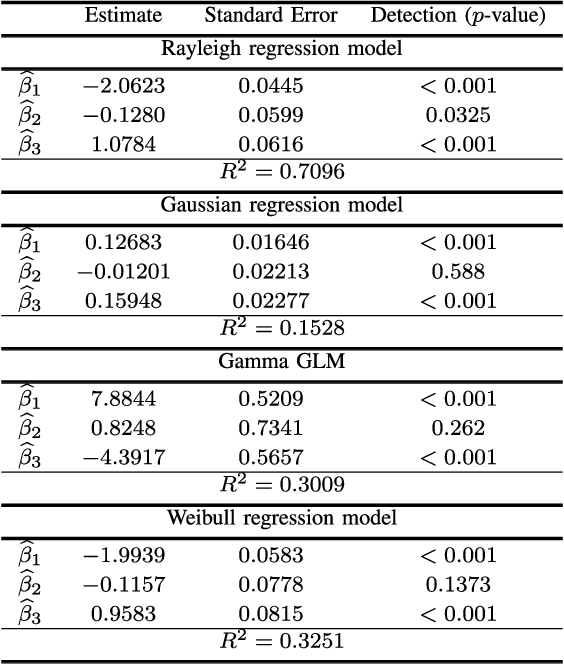
This letter proposes a regression model for nonnegative signals. The proposed regression estimates the mean of Rayleigh distributed signals by a structure which includes a set of regressors and a link function. For the proposed model, we present: (i)~parameter estimation; (ii)~large data record results; and (iii)~a detection technique. In this letter, we present closed-form expressions for the score vector and Fisher information matrix. The proposed model is submitted to extensive Monte Carlo simulations and to measured data. The Monte Carlo simulations are used to evaluate the performance of maximum likelihood estimators. Also, an application is performed comparing the detection results of the proposed model with Gaussian-, Gamma-, and Weibull-based regression models in SAR images.
* 9 pages, 2 figures, 2 tables
A Twitter-Driven Deep Learning Mechanism for the Determination of Vehicle Hijacking Spots in Cities
Aug 11, 2022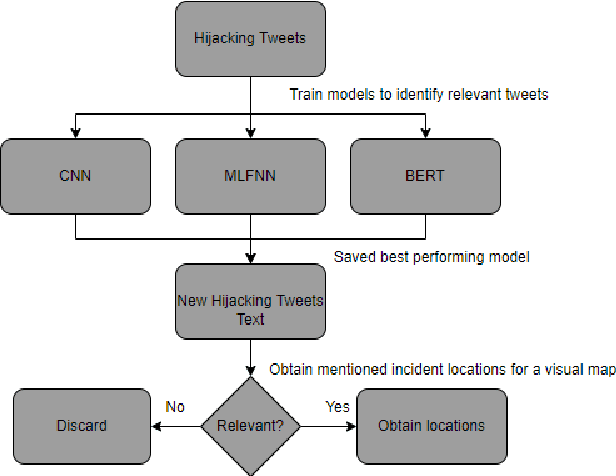
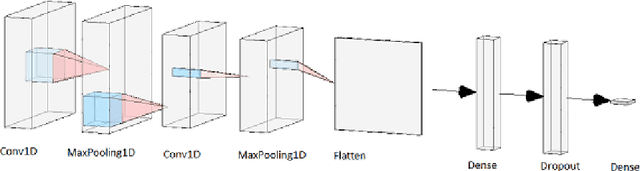
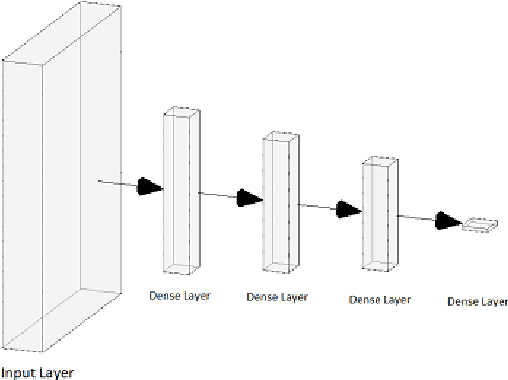
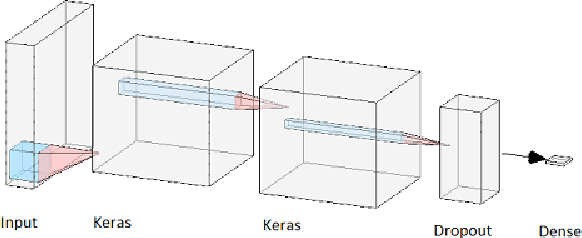
Vehicle hijacking is one of the leading crimes in many cities. For instance, in South Africa, drivers must constantly remain vigilant on the road in order to ensure that they do not become hijacking victims. This work is aimed at developing a map depicting hijacking spots in a city by using Twitter data. Tweets, which include the keyword "hijacking", are obtained in a designated city of Cape Town, in this work. In order to extract relevant tweets, these tweets are analyzed by using the following machine learning techniques: 1) a Multi-layer Feed-forward Neural Network (MLFNN); 2) Convolutional Neural Network; and Bidirectional Encoder Representations from Transformers (BERT). Through training and testing, CNN achieved an accuracy of 99.66%, while MLFNN and BERT achieve accuracies of 98.99% and 73.99% respectively. In terms of Recall, Precision and F1-score, CNN also achieved the best results. Therefore, CNN was used for the identification of relevant tweets. The relevant reports that it generates are visually presented on a points map of the City of Cape Town. This work used a small dataset of 426 tweets. In future, the use of evolutionary computation will be explored for purposes of optimizing the deep learning models. A mobile application is under development to make this information usable by the general public.