 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Machine Learning Approaches for Principle Prediction in Naturally Occurring Stories
Nov 19, 2022

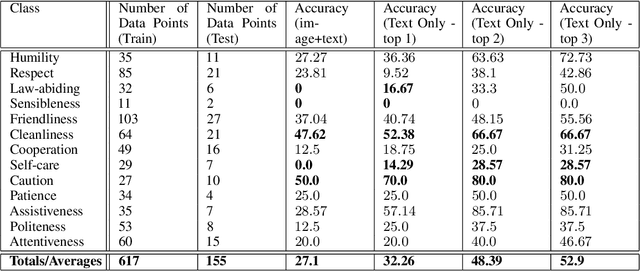

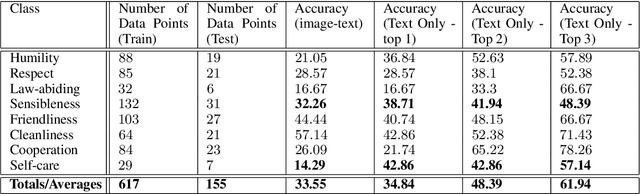
Value alignment is the task of creating autonomous systems whose values align with those of humans. Past work has shown that stories are a potentially rich source of information on human values; however, past work has been limited to considering values in a binary sense. In this work, we explore the use of machine learning models for the task of normative principle prediction on naturally occurring story data. To do this, we extend a dataset that has been previously used to train a binary normative classifier with annotations of moral principles. We then use this dataset to train a variety of machine learning models, evaluate these models and compare their results against humans who were asked to perform the same task. We show that while individual principles can be classified, the ambiguity of what "moral principles" represent, poses a challenge for both human participants and autonomous systems which are faced with the same task.
Explaining Image Classifiers with Multiscale Directional Image Representation
Nov 24, 2022
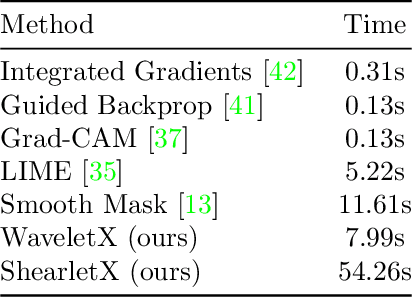


Image classifiers are known to be difficult to interpret and therefore require explanation methods to understand their decisions. We present ShearletX, a novel mask explanation method for image classifiers based on the shearlet transform -- a multiscale directional image representation. Current mask explanation methods are regularized by smoothness constraints that protect against undesirable fine-grained explanation artifacts. However, the smoothness of a mask limits its ability to separate fine-detail patterns, that are relevant for the classifier, from nearby nuisance patterns, that do not affect the classifier. ShearletX solves this problem by avoiding smoothness regularization all together, replacing it by shearlet sparsity constraints. The resulting explanations consist of a few edges, textures, and smooth parts of the original image, that are the most relevant for the decision of the classifier. To support our method, we propose a mathematical definition for explanation artifacts and an information theoretic score to evaluate the quality of mask explanations. We demonstrate the superiority of ShearletX over previous mask based explanation methods using these new metrics, and present exemplary situations where separating fine-detail patterns allows explaining phenomena that were not explainable before.
Reduction Algorithms for Persistence Diagrams of Networks: CoralTDA and PrunIT
Nov 24, 2022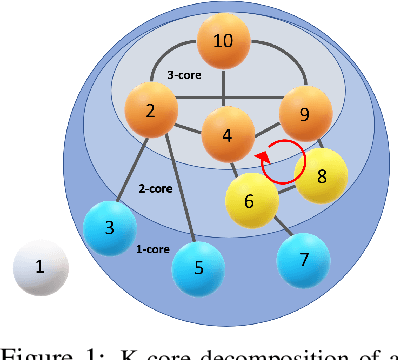


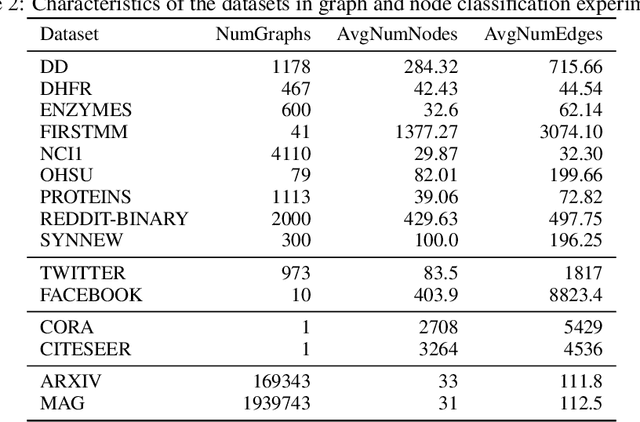
Topological data analysis (TDA) delivers invaluable and complementary information on the intrinsic properties of data inaccessible to conventional methods. However, high computational costs remain the primary roadblock hindering the successful application of TDA in real-world studies, particularly with machine learning on large complex networks. Indeed, most modern networks such as citation, blockchain, and online social networks often have hundreds of thousands of vertices, making the application of existing TDA methods infeasible. We develop two new, remarkably simple but effective algorithms to compute the exact persistence diagrams of large graphs to address this major TDA limitation. First, we prove that $(k+1)$-core of a graph $\mathcal{G}$ suffices to compute its $k^{th}$ persistence diagram, $PD_k(\mathcal{G})$. Second, we introduce a pruning algorithm for graphs to compute their persistence diagrams by removing the dominated vertices. Our experiments on large networks show that our novel approach can achieve computational gains up to 95%. The developed framework provides the first bridge between the graph theory and TDA, with applications in machine learning of large complex networks. Our implementation is available at https://github.com/cakcora/PersistentHomologyWithCoralPrunit
Hand Guided High Resolution Feature Enhancement for Fine-Grained Atomic Action Segmentation within Complex Human Assemblies
Nov 24, 2022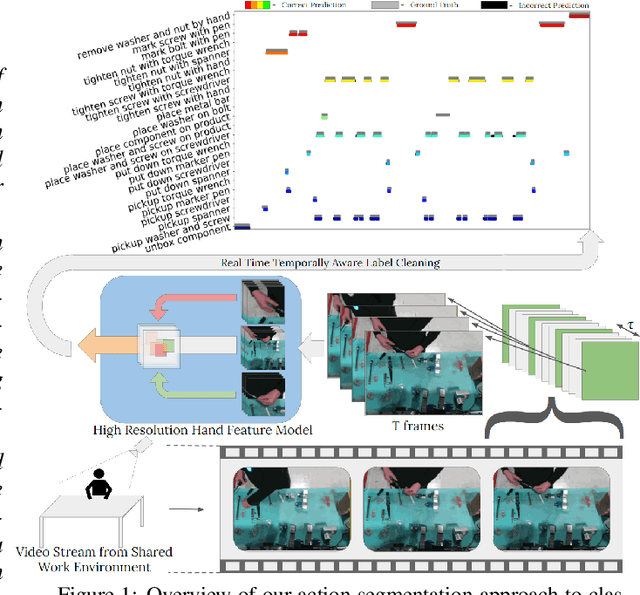
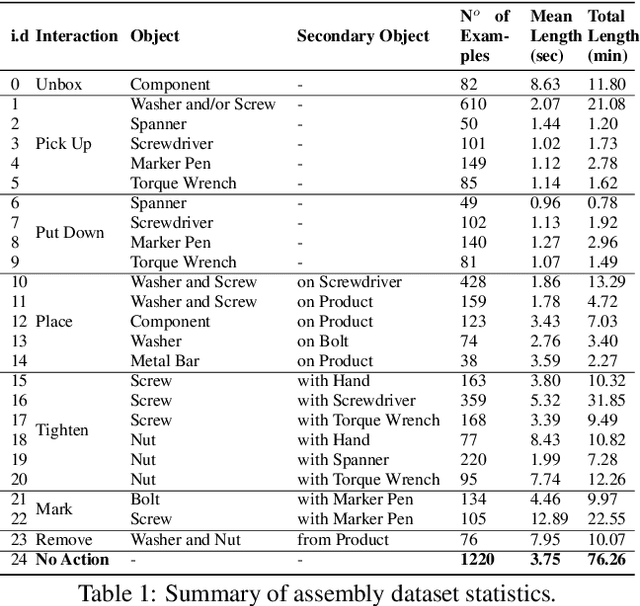
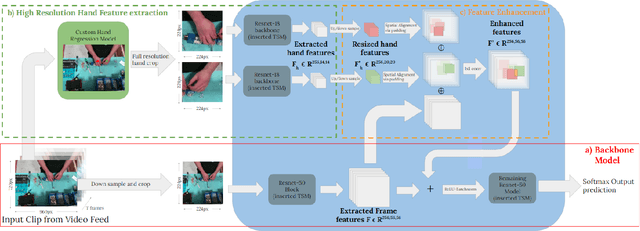
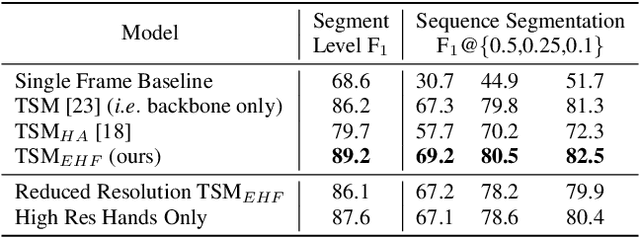
Due to the rapid temporal and fine-grained nature of complex human assembly atomic actions, traditional action segmentation approaches requiring the spatial (and often temporal) down sampling of video frames often loose vital fine-grained spatial and temporal information required for accurate classification within the manufacturing domain. In order to fully utilise higher resolution video data (often collected within the manufacturing domain) and facilitate real time accurate action segmentation - required for human robot collaboration - we present a novel hand location guided high resolution feature enhanced model. We also propose a simple yet effective method of deploying offline trained action recognition models for real time action segmentation on temporally short fine-grained actions, through the use of surround sampling while training and temporally aware label cleaning at inference. We evaluate our model on a novel action segmentation dataset containing 24 (+background) atomic actions from video data of a real world robotics assembly production line. Showing both high resolution hand features as well as traditional frame wide features improve fine-grained atomic action classification, and that though temporally aware label clearing our model is capable of surpassing similar encoder/decoder methods, while allowing for real time classification.
Solving Bilevel Knapsack Problem using Graph Neural Networks
Nov 24, 2022
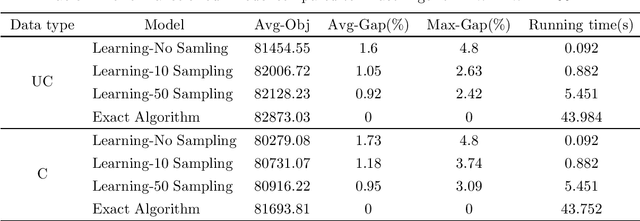
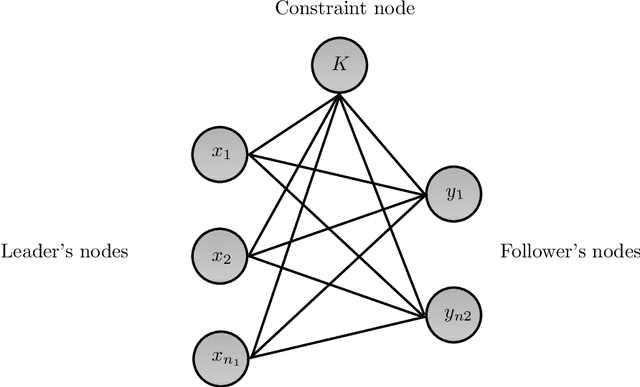
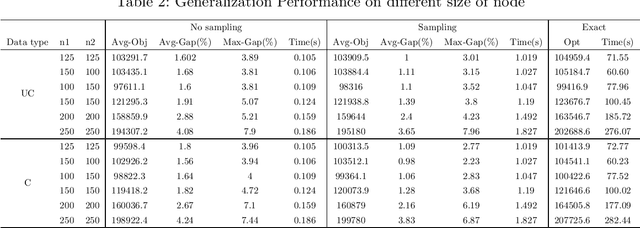
The Bilevel Optimization Problem is a hierarchical optimization problem with two agents, a leader and a follower. The leader make their own decisions first, and the followers make the best choices accordingly. The leader knows the information of the followers, and the goal of the problem is to find the optimal solution by considering the reactions of the followers from the leader's point of view. For the Bilevel Optimization Problem, there are no general and efficient algorithms or commercial solvers to get an optimal solution, and it is very difficult to get a good solution even for a simple problem. In this paper, we propose a deep learning approach using Graph Neural Networks to solve the bilevel knapsack problem. We train the model to predict the leader's solution and use it to transform the hierarchical optimization problem into a single-level optimization problem to get the solution. Our model found the feasible solution that was about 500 times faster than the exact algorithm with $1.7\%$ optimal gap. Also, our model performed well on problems of different size from the size it was trained on.
Ham2Pose: Animating Sign Language Notation into Pose Sequences
Nov 24, 2022
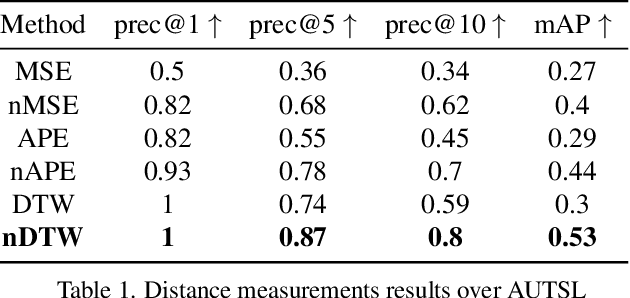

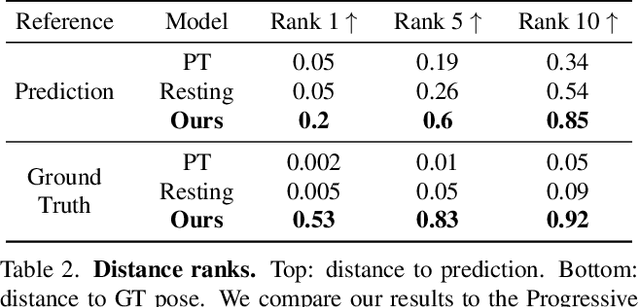
Translating spoken languages into Sign languages is necessary for open communication between the hearing and hearing-impaired communities. To achieve this goal, we propose the first method for animating a text written in HamNoSys, a lexical Sign language notation, into signed pose sequences. As HamNoSys is universal, our proposed method offers a generic solution invariant to the target Sign language. Our method gradually generates pose predictions using transformer encoders that create meaningful representations of the text and poses while considering their spatial and temporal information. We use weak supervision for the training process and show that our method succeeds in learning from partial and inaccurate data. Additionally, we offer a new distance measurement for pose sequences, normalized Dynamic Time Warping (nDTW), based on DTW over normalized keypoints trajectories, and validate its correctness using AUTSL, a large-scale Sign language dataset. We show that it measures the distance between pose sequences more accurately than existing measurements and use it to assess the quality of our generated pose sequences. Code for the data pre-processing, the model, and the distance measurement is publicly released for future research.
Scientific Paper Classification Based on Graph Neural Network with Hypergraph Self-attention Mechanism
Oct 07, 2022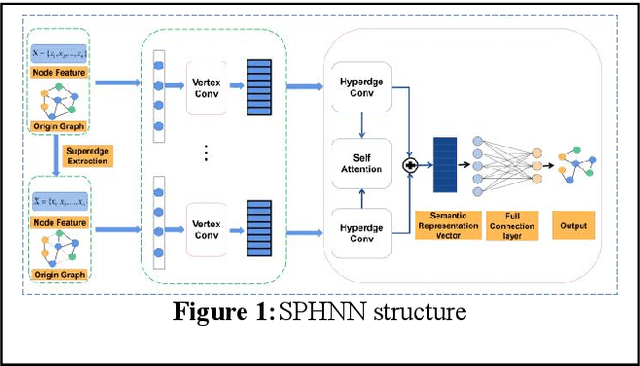
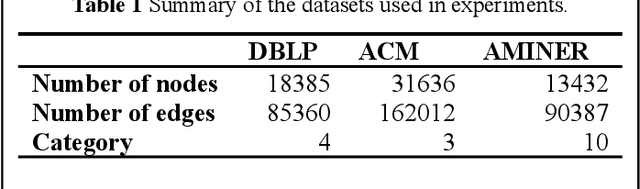
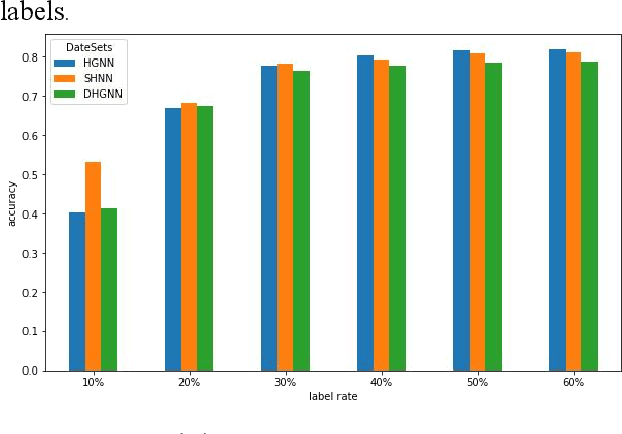
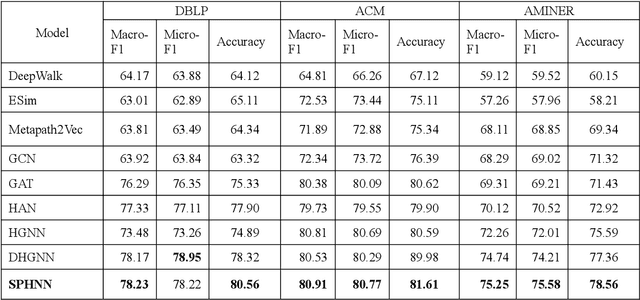
The number of scientific papers has increased rapidly in recent years. How to make good use of scientific papers for research is very important. Through the high-quality classification of scientific papers, researchers can quickly find the resource content they need from the massive scientific resources. The classification of scientific papers will effectively help researchers filter redundant information, obtain search results quickly and accurately, and improve the search quality, which is necessary for scientific resource management. This paper proposed a science-technique paper classification method based on hypergraph neural network(SPHNN). In the heterogeneous information network of scientific papers, the repeated high-order subgraphs are modeled as hyperedges composed of multiple related nodes. Then the whole heterogeneous information network is transformed into a hypergraph composed of different hyperedges. The graph convolution operation is carried out on the hypergraph structure, and the hyperedges self-attention mechanism is introduced to aggregate different types of nodes in the hypergraph, so that the final node representation can effectively maintain high-order nearest neighbor relationships and complex semantic information. Finally, by comparing with other methods, we proved that the model proposed in this paper has improved its performance.
Representation Power of Graph Convolutions : Neural Tangent Kernel Analysis
Oct 18, 2022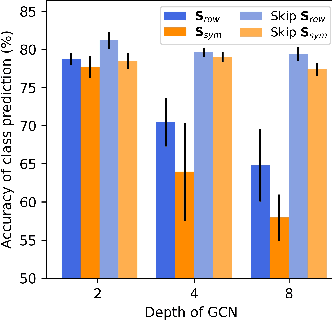
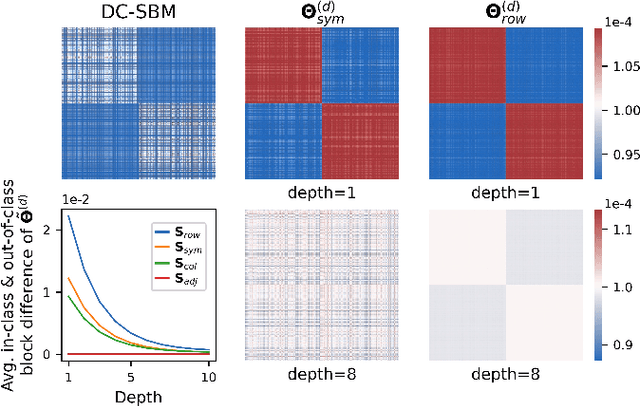
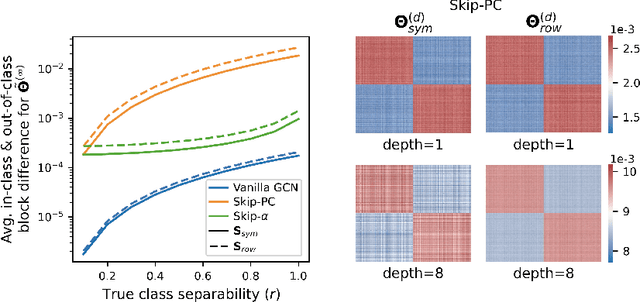
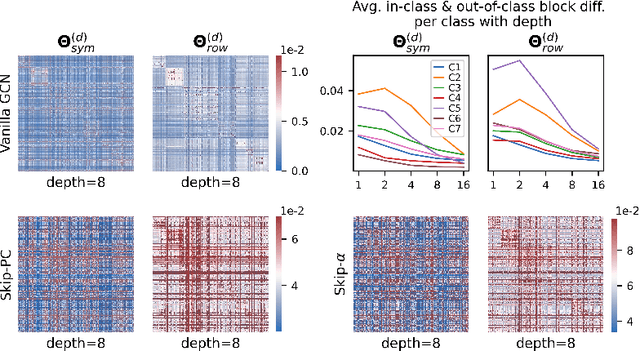
The fundamental principle of Graph Neural Networks (GNNs) is to exploit the structural information of the data by aggregating the neighboring nodes using a graph convolution. Therefore, understanding its influence on the network performance is crucial. Convolutions based on graph Laplacian have emerged as the dominant choice with the symmetric normalization of the adjacency matrix $A$, defined as $D^{-1/2}AD^{-1/2}$, being the most widely adopted one, where $D$ is the degree matrix. However, some empirical studies show that row normalization $D^{-1}A$ outperforms it in node classification. Despite the widespread use of GNNs, there is no rigorous theoretical study on the representation power of these convolution operators, that could explain this behavior. In this work, we analyze the influence of the graph convolutions theoretically using Graph Neural Tangent Kernel in a semi-supervised node classification setting. Under a Degree Corrected Stochastic Block Model, we prove that: (i) row normalization preserves the underlying class structure better than other convolutions; (ii) performance degrades with network depth due to over-smoothing, but the loss in class information is the slowest in row normalization; (iii) skip connections retain the class information even at infinite depth, thereby eliminating over-smoothing. We finally validate our theoretical findings on real datasets.
Taxonomy of Abstractive Dialogue Summarization: Scenarios, Approaches and Future Directions
Oct 18, 2022
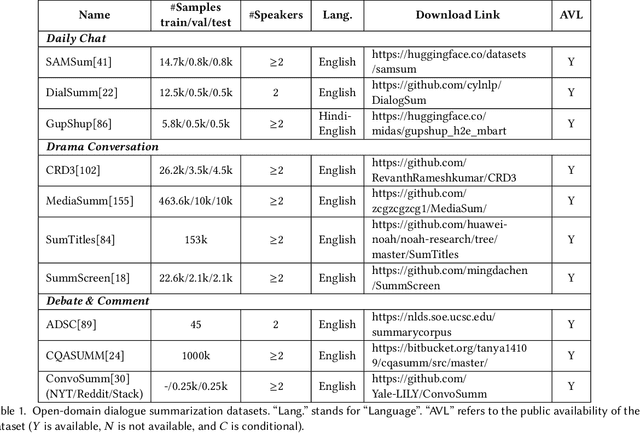
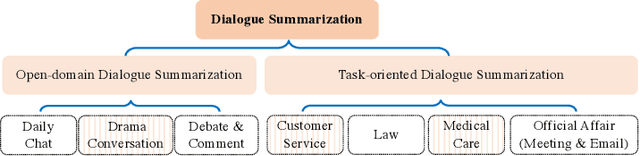
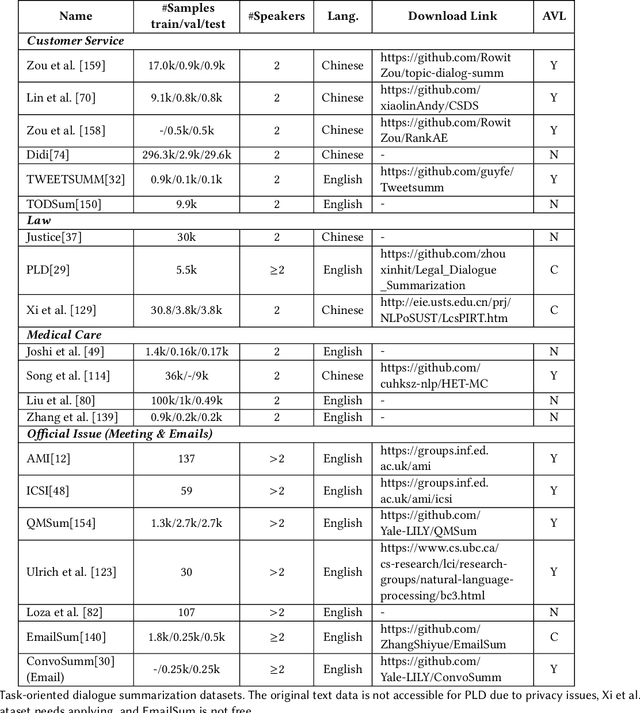
Abstractive dialogue summarization is to generate a concise and fluent summary covering the salient information in a dialogue among two or more interlocutors. It has attracted great attention in recent years based on the massive emergence of social communication platforms and an urgent requirement for efficient dialogue information understanding and digestion. Different from news or articles in traditional document summarization, dialogues bring unique characteristics and additional challenges, including different language styles and formats, scattered information, flexible discourse structures and unclear topic boundaries. This survey provides a comprehensive investigation on existing work for abstractive dialogue summarization from scenarios, approaches to evaluations. It categorizes the task into two broad categories according to the type of input dialogues, i.e., open-domain and task-oriented, and presents a taxonomy of existing techniques in three directions, namely, injecting dialogue features, designing auxiliary training tasks and using additional data.A list of datasets under different scenarios and widely-accepted evaluation metrics are summarized for completeness. After that, the trends of scenarios and techniques are summarized, together with deep insights on correlations between extensively exploited features and different scenarios. Based on these analyses, we recommend future directions including more controlled and complicated scenarios, technical innovations and comparisons, publicly available datasets in special domains, etc.
Deep Scattering Spectrum germaneness to Fault Detection and Diagnosis for Component-level Prognostics and Health Management (PHM)
Oct 20, 2022
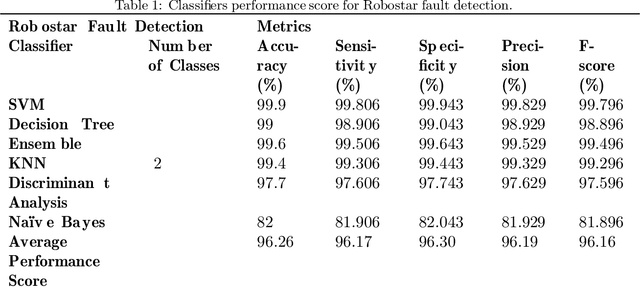
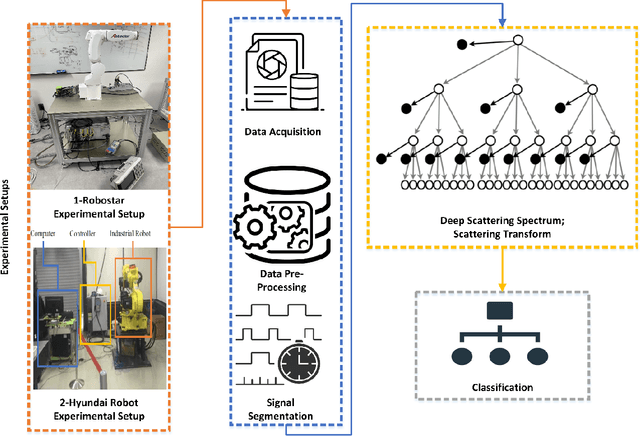
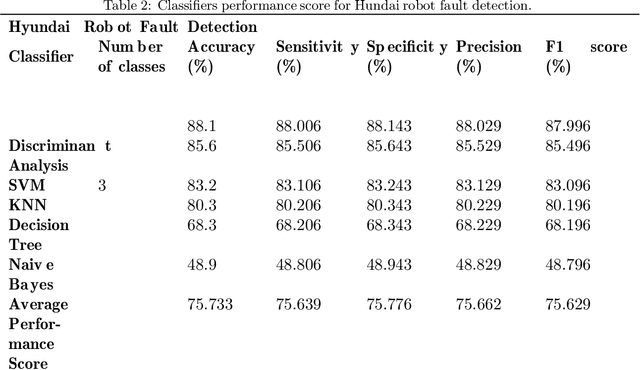
In fault detection and diagnosis of prognostics and health management (PHM) systems, most of the methodologies utilize machine learning (ML) or deep learning (DL) through which either some features are extracted beforehand (in the case of ML) or filters are used to extract features autonomously (in case of DL) to perform the critical classification task. Particularly in the fault detection and diagnosis of industrial robots where electric current, vibration or acoustic emissions signals are the primary sources of information, a feature domain that can map the signals into their constituent components with compressed information at different levels can reduce the complexities and size of typical ML and DL-based frameworks. The Deep Scattering Spectrum (DSS) is one of the strategies that use the Wavelet Transform (WT) analogy to separate and extract the information encoded in a signal's various temporal and frequency domains. As a result, the focus of this work is on the study of the DSS's relevance to fault detection and daignosis for mechanical components of industrail robots. We used multiple industrial robots and distinct mechanical faults to build an approach for classifying the faults using low-variance features extracted from the input signals. The presented approach was implemented on the practical test benches and demonstrated satisfactory performance in fault detection and diagnosis for simple and complex classification problems with a classification accuracy of 99.7% and 88.1%, respectively.