 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Job recommendations: benchmarking of collaborative filtering methods for classifieds
Jan 19, 2023
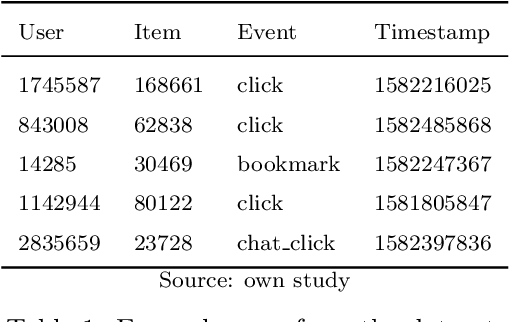
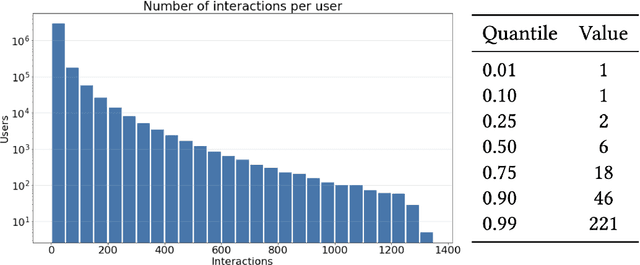
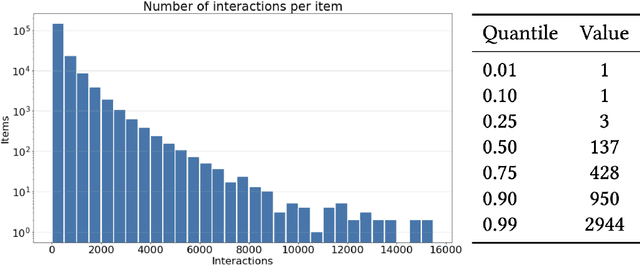
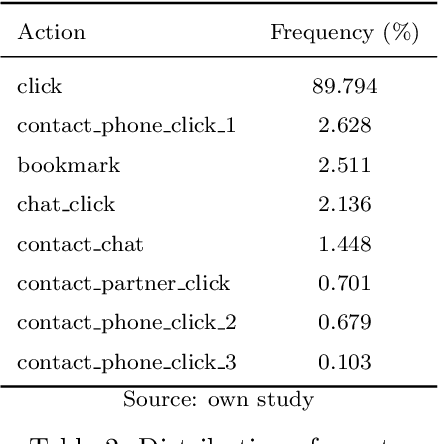
Classifieds provide many challenges for recommendation methods, due to the limited information regarding users and items. In this paper, we explore recommendation methods for classifieds using the example of OLX Jobs. The goal of the paper is to benchmark different recommendation methods for jobs classifieds in order to improve advertisements' conversion rate and user satisfaction. In our research, we implemented methods that are scalable and represent different approaches to recommendation, namely ALS, LightFM, Prod2Vec, RP3beta, and SLIM. We performed a laboratory comparison of methods with regard to accuracy, diversity, and scalability (memory and time consumption during training and in prediction). Online A/B tests were also carried out by sending millions of messages with recommendations to evaluate models in a real-world setting. In addition, we have published the dataset that we created for the needs of our research. To the best of our knowledge, this is the first dataset of this kind. The dataset contains 65,502,201 events performed on OLX Jobs by 3,295,942 users, who interacted with (displayed, replied to, or bookmarked) 185,395 job ads in two weeks of 2020. We demonstrate that RP3beta, SLIM, and ALS perform significantly better than Prod2Vec and LightFM when tested in a laboratory setting. Online A/B tests also demonstrated that sending messages with recommendations generated by the ALS and RP3beta models increases the number of users contacting advertisers. Additionally, RP3beta had a 20% greater impact on this metric than ALS.
SoftEnNet: Symbiotic Monocular Depth Estimation and Lumen Segmentation for Colonoscopy Endorobots
Jan 19, 2023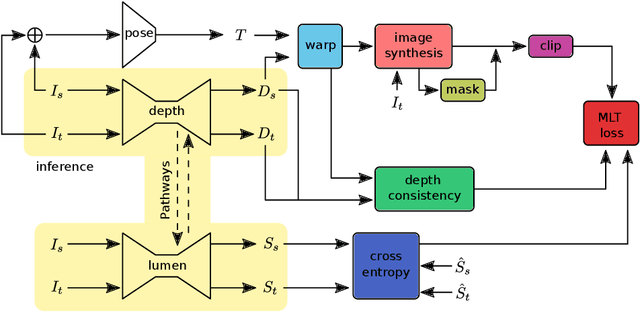
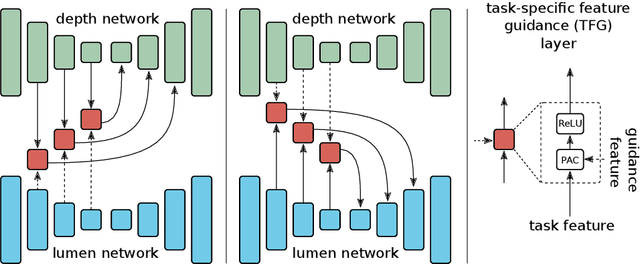
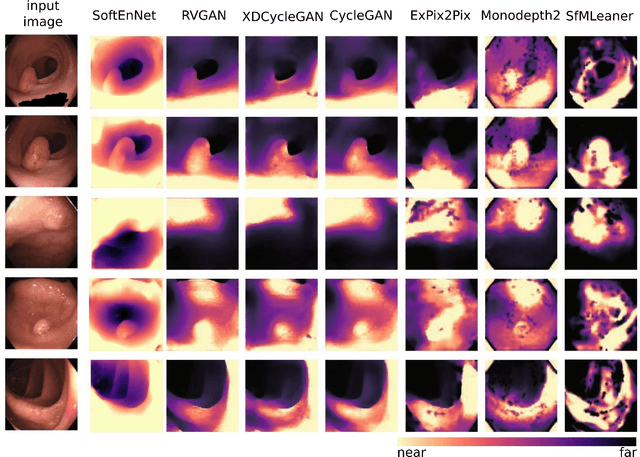
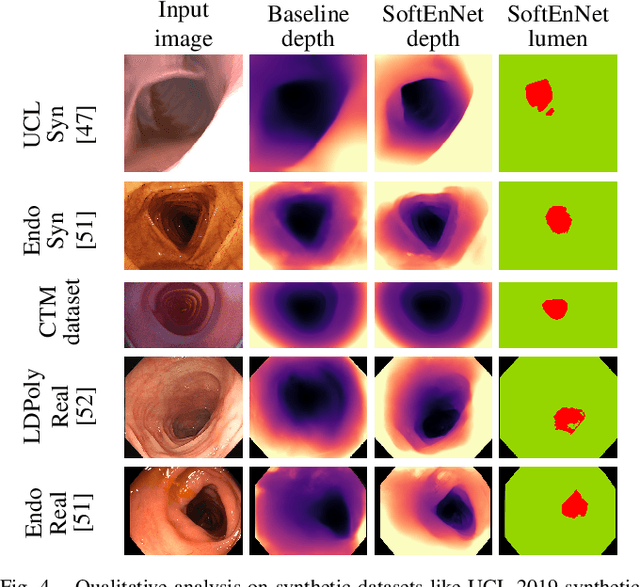
Colorectal cancer is the third most common cause of cancer death worldwide. Optical colonoscopy is the gold standard for detecting colorectal cancer; however, about 25 percent of polyps are missed during the procedure. A vision-based autonomous endorobot can improve colonoscopy procedures significantly through systematic, complete screening of the colonic mucosa. The reliable robot navigation needed requires a three-dimensional understanding of the environment and lumen tracking to support autonomous tasks. We propose a novel multi-task model that simultaneously predicts dense depth and lumen segmentation with an ensemble of deep networks. The depth estimation sub-network is trained in a self-supervised fashion guided by view synthesis; the lumen segmentation sub-network is supervised. The two sub-networks are interconnected with pathways that enable information exchange and thereby mutual learning. As the lumen is in the image's deepest visual space, lumen segmentation helps with the depth estimation at the farthest location. In turn, the estimated depth guides the lumen segmentation network as the lumen location defines the farthest scene location. Unlike other environments, view synthesis often fails in the colon because of the deformable wall, textureless surface, specularities, and wide field of view image distortions, all challenges that our pipeline addresses. We conducted qualitative analysis on a synthetic dataset and quantitative analysis on a colon training model and real colonoscopy videos. The experiments show that our model predicts accurate scale-invariant depth maps and lumen segmentation from colonoscopy images in near real-time.
JCSE: Contrastive Learning of Japanese Sentence Embeddings and Its Applications
Jan 19, 2023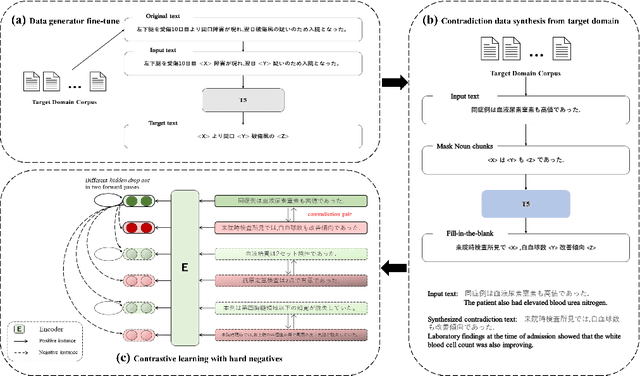
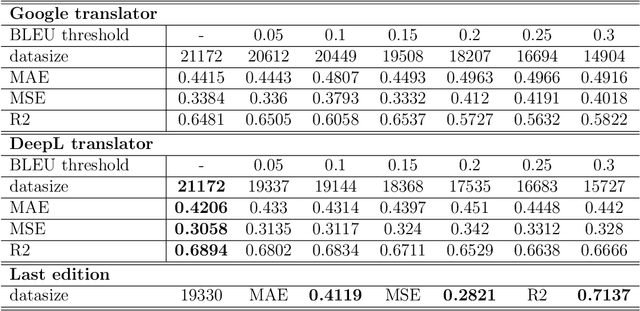
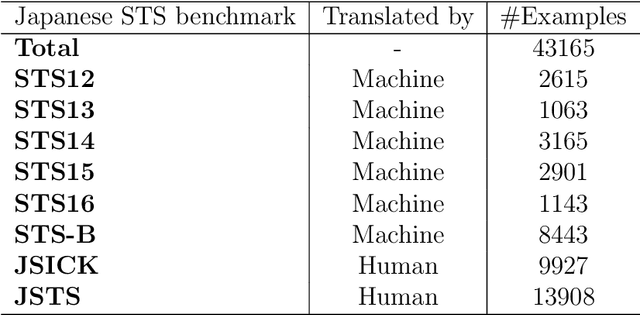
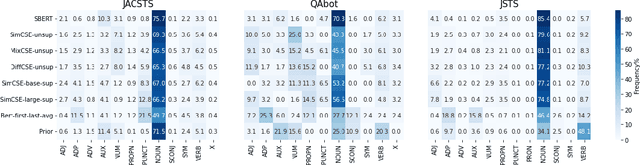
Contrastive learning is widely used for sentence representation learning. Despite this prevalence, most studies have focused exclusively on English and few concern domain adaptation for domain-specific downstream tasks, especially for low-resource languages like Japanese, which are characterized by insufficient target domain data and the lack of a proper training strategy. To overcome this, we propose a novel Japanese sentence representation framework, JCSE (derived from ``Contrastive learning of Sentence Embeddings for Japanese''), that creates training data by generating sentences and synthesizing them with sentences available in a target domain. Specifically, a pre-trained data generator is finetuned to a target domain using our collected corpus. It is then used to generate contradictory sentence pairs that are used in contrastive learning for adapting a Japanese language model to a specific task in the target domain. Another problem of Japanese sentence representation learning is the difficulty of evaluating existing embedding methods due to the lack of benchmark datasets. Thus, we establish a comprehensive Japanese Semantic Textual Similarity (STS) benchmark on which various embedding models are evaluated. Based on this benchmark result, multiple embedding methods are chosen and compared with JCSE on two domain-specific tasks, STS in a clinical domain and information retrieval in an educational domain. The results show that JCSE achieves significant performance improvement surpassing direct transfer and other training strategies. This empirically demonstrates JCSE's effectiveness and practicability for downstream tasks of a low-resource language.
Evaluation of the potential of Near Infrared Hyperspectral Imaging for monitoring the invasive brown marmorated stink bug
Jan 19, 2023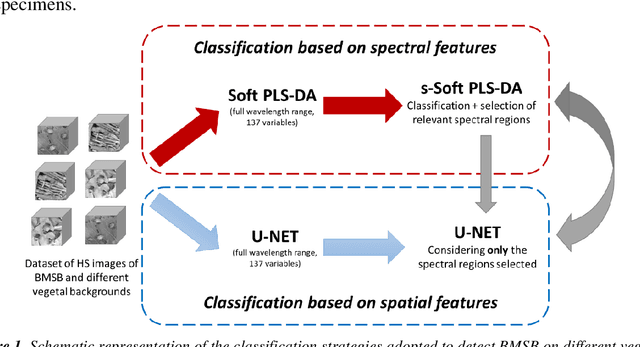
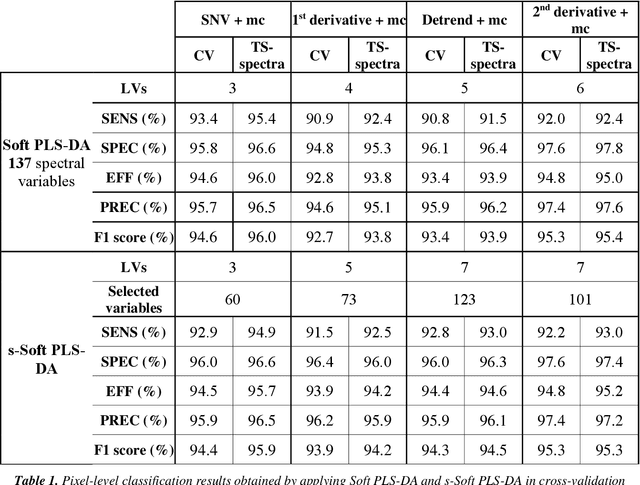
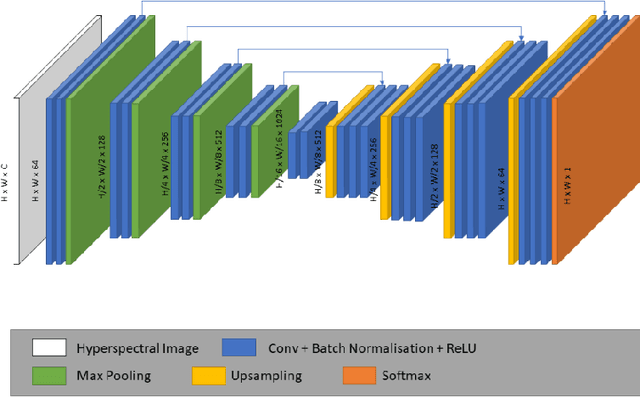
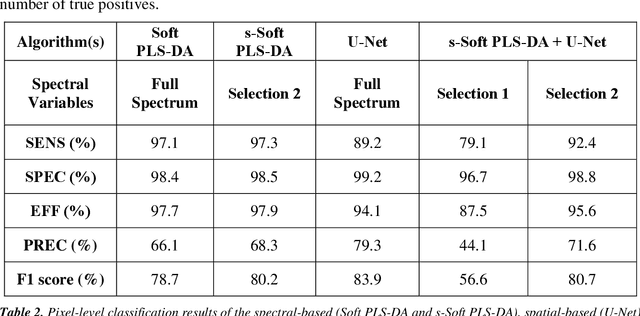
The brown marmorated stink bug (BMSB), Halyomorpha halys, is an invasive insect pest of global importance that damages several crops, compromising agri-food production. Field monitoring procedures are fundamental to perform risk assessment operations, in order to promptly face crop infestations and avoid economical losses. To improve pest management, spectral cameras mounted on Unmanned Aerial Vehicles (UAVs) and other Internet of Things (IoT) devices, such as smart traps or unmanned ground vehicles, could be used as an innovative technology allowing fast, efficient and real-time monitoring of insect infestations. The present study consists in a preliminary evaluation at the laboratory level of Near Infrared Hyperspectral Imaging (NIR-HSI) as a possible technology to detect BMSB specimens on different vegetal backgrounds, overcoming the problem of BMSB mimicry. Hyperspectral images of BMSB were acquired in the 980-1660 nm range, considering different vegetal backgrounds selected to mimic a real field application scene. Classification models were obtained following two different chemometric approaches. The first approach was focused on modelling spectral information and selecting relevant spectral regions for discrimination by means of sparse-based variable selection coupled with Soft Partial Least Squares Discriminant Analysis (s-Soft PLS-DA) classification algorithm. The second approach was based on modelling spatial and spectral features contained in the hyperspectral images using Convolutional Neural Networks (CNN). Finally, to further improve BMSB detection ability, the two strategies were merged, considering only the spectral regions selected by s-Soft PLS-DA for CNN modelling.
* Accepted manuscript
Automated Cancer Subtyping via Vector Quantization Mutual Information Maximization
Jun 22, 2022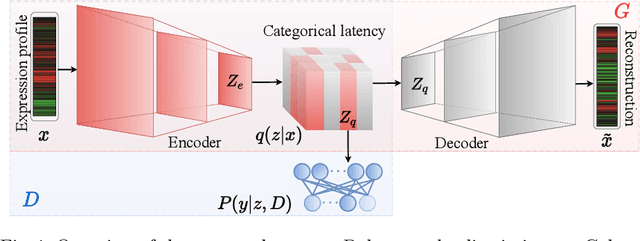
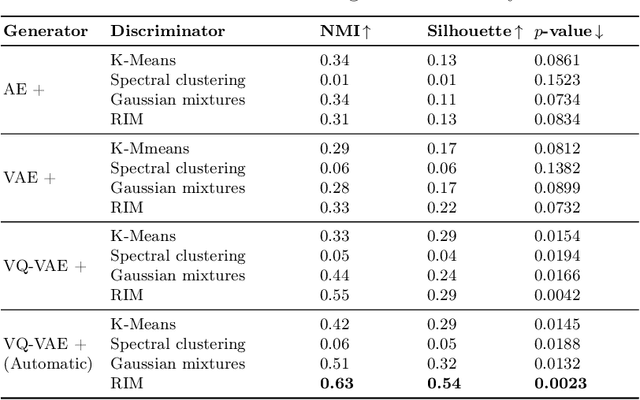
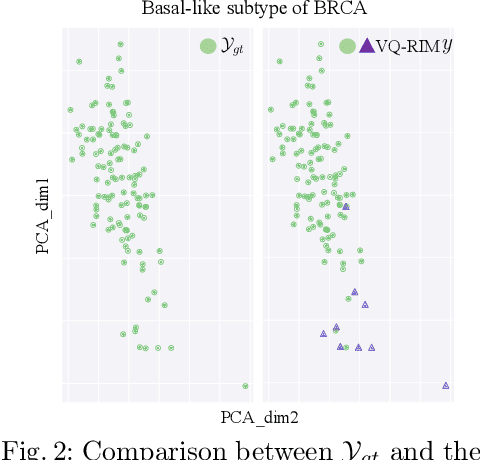
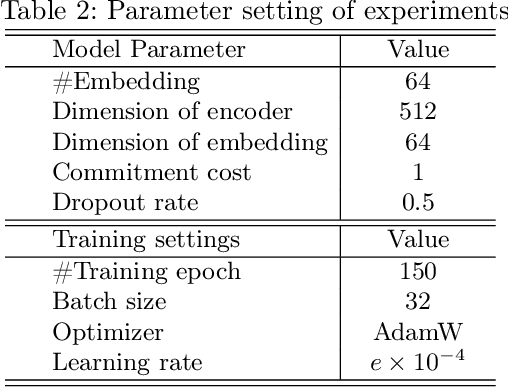
Cancer subtyping is crucial for understanding the nature of tumors and providing suitable therapy. However, existing labelling methods are medically controversial, and have driven the process of subtyping away from teaching signals. Moreover, cancer genetic expression profiles are high-dimensional, scarce, and have complicated dependence, thereby posing a serious challenge to existing subtyping models for outputting sensible clustering. In this study, we propose a novel clustering method for exploiting genetic expression profiles and distinguishing subtypes in an unsupervised manner. The proposed method adaptively learns categorical correspondence from latent representations of expression profiles to the subtypes output by the model. By maximizing the problem -- agnostic mutual information between input expression profiles and output subtypes, our method can automatically decide a suitable number of subtypes. Through experiments, we demonstrate that our proposed method can refine existing controversial labels, and, by further medical analysis, this refinement is proven to have a high correlation with cancer survival rates.
Efficient Relation-aware Neighborhood Aggregation in Graph Neural Networks via Tensor Decomposition
Dec 21, 2022
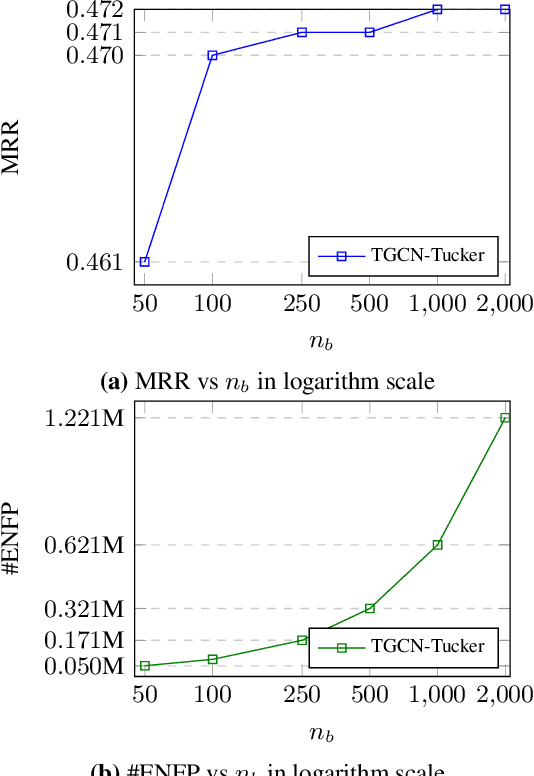
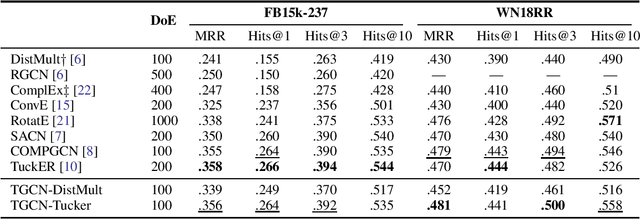
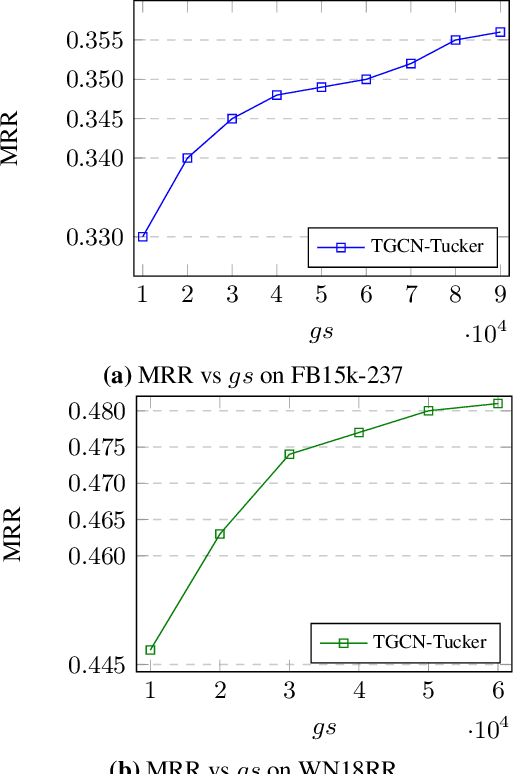
Many Graph Neural Networks (GNNs) are proposed for KG embedding. However, lots of these methods neglect the importance of the information of relations and combine it with the information of entities inefficiently and mostly additively, leading to low expressiveness. To address this issue, we introduce a general knowledge graph encoder incorporating tensor decomposition in the aggregation function of Relational Graph Convolutional Network (R-GCN). In our model, the parameters of a low-rank core projection tensor, used to transform neighbor entities, are shared across relations to benefit from multi-task learning and produce expressive relation-aware representations. Besides, we propose a low-rank estimation of the core tensor using CP decomposition to compress the model, which is also applicable, as a regularization method, to other similar GNNs. We train our model using a contrastive loss, which relieves the training limitation of the 1-N method on huge graphs. We achieved favorably competitive results on FB15-237 and WN18RR with embeddings in comparably lower dimensions; particularly, we improved R-GCN performance on FB15-237 by 36% with the same decoder.
DCC: A Cascade based Approach to Detect Communities in Social Networks
Dec 21, 2022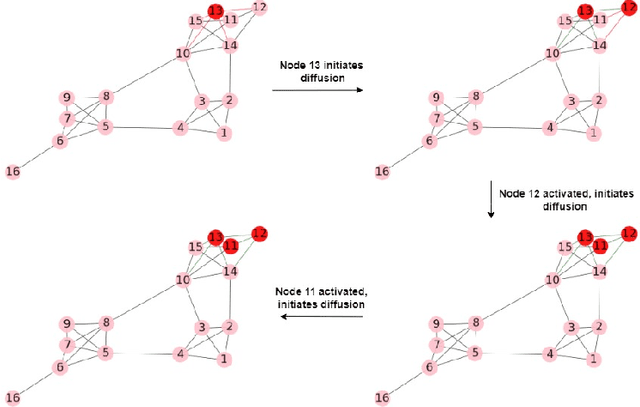
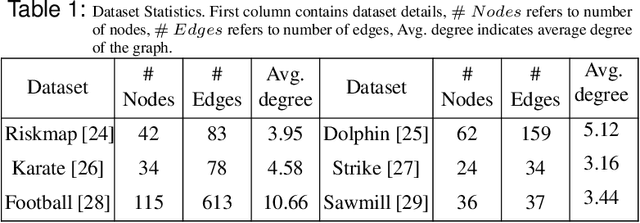
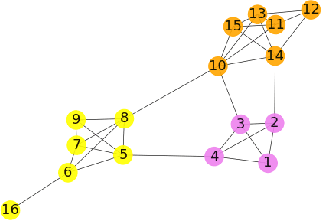
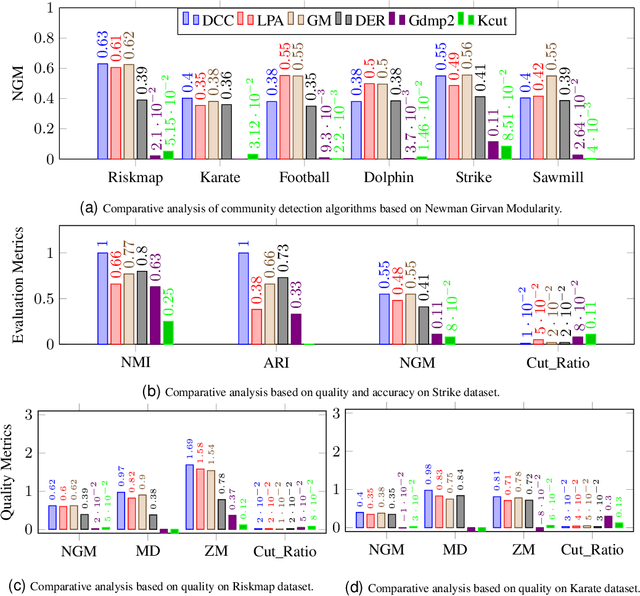
Community detection in Social Networks is associated with finding and grouping the most similar nodes inherent in the network. These similar nodes are identified by computing tie strength. Stronger ties indicates higher proximity shared by connected node pairs. This work is motivated by Granovetter's argument that suggests that strong ties lies within densely connected nodes and the theory that community cores in real-world networks are densely connected. In this paper, we have introduced a novel method called \emph{Disjoint Community detection using Cascades (DCC)} which demonstrates the effectiveness of a new local density based tie strength measure on detecting communities. Here, tie strength is utilized to decide the paths followed for propagating information. The idea is to crawl through the tuple information of cascades towards the community core guided by increasing tie strength. Considering the cascade generation step, a novel preferential membership method has been developed to assign community labels to unassigned nodes. The efficacy of $DCC$ has been analyzed based on quality and accuracy on several real-world datasets and baseline community detection algorithms.
ImPaKT: A Dataset for Open-Schema Knowledge Base Construction
Dec 21, 2022

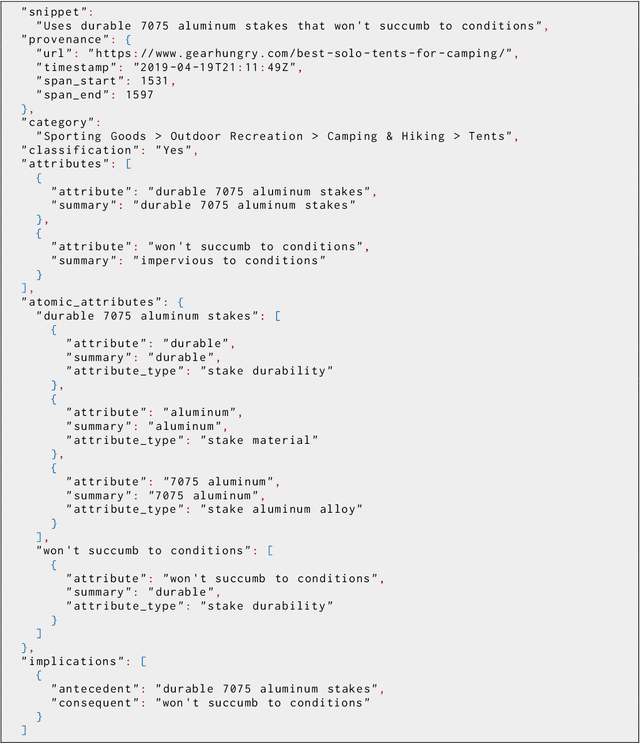
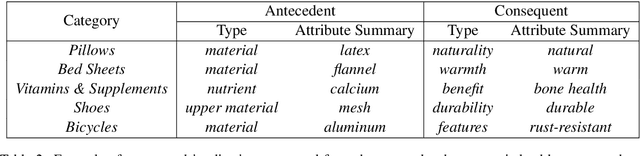
Large language models have ushered in a golden age of semantic parsing. The seq2seq paradigm allows for open-schema and abstractive attribute and relation extraction given only small amounts of finetuning data. Language model pretraining has simultaneously enabled great strides in natural language inference, reasoning about entailment and implication in free text. These advances motivate us to construct ImPaKT, a dataset for open-schema information extraction, consisting of around 2500 text snippets from the C4 corpus, in the shopping domain (product buying guides), professionally annotated with extracted attributes, types, attribute summaries (attribute schema discovery from idiosyncratic text), many-to-one relations between compound and atomic attributes, and implication relations. We release this data in hope that it will be useful in fine tuning semantic parsers for information extraction and knowledge base construction across a variety of domains. We evaluate the power of this approach by fine-tuning the open source UL2 language model on a subset of the dataset, extracting a set of implication relations from a corpus of product buying guides, and conducting human evaluations of the resulting predictions.
Jointly Learning Span Extraction and Sequence Labeling for Information Extraction from Business Documents
May 26, 2022
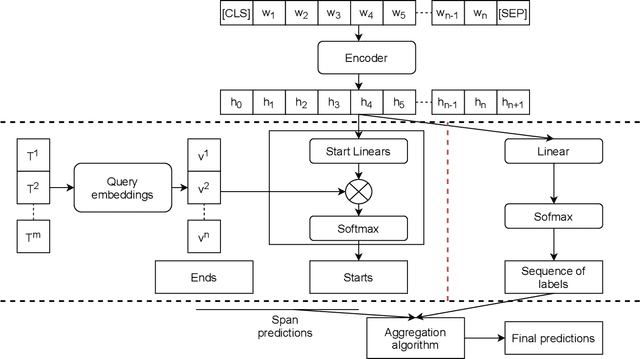
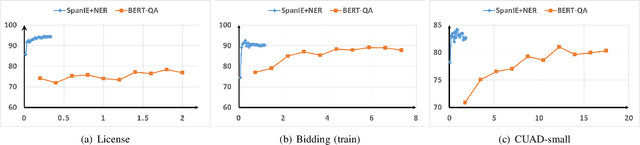
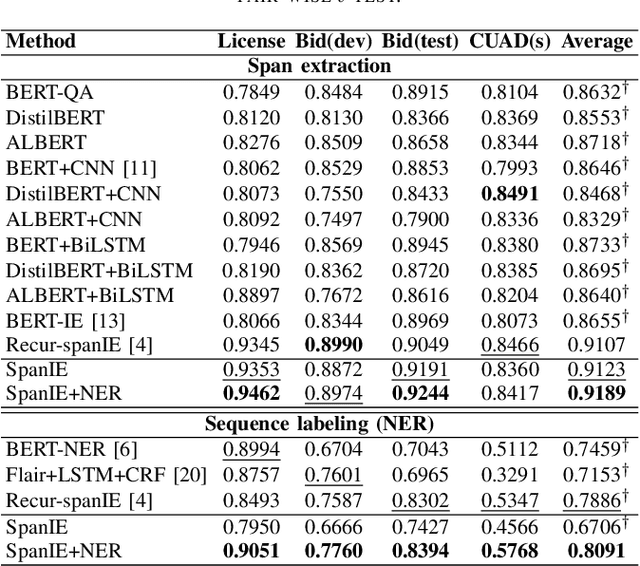
This paper introduces a new information extraction model for business documents. Different from prior studies which only base on span extraction or sequence labeling, the model takes into account advantage of both span extraction and sequence labeling. The combination allows the model to deal with long documents with sparse information (the small amount of extracted information). The model is trained end-to-end to jointly optimize the two tasks in a unified manner. Experimental results on four business datasets in English and Japanese show that the model achieves promising results and is significantly faster than the normal span-based extraction method. The code is also available.
Mapping smallholder cashew plantations to inform sustainable tree crop expansion in Benin
Jan 01, 2023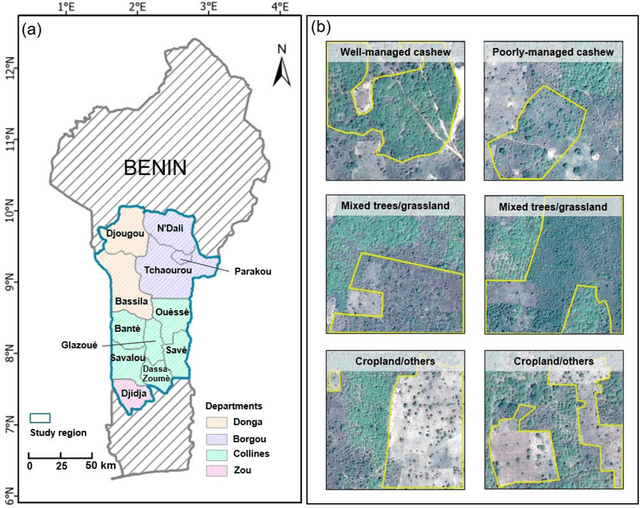

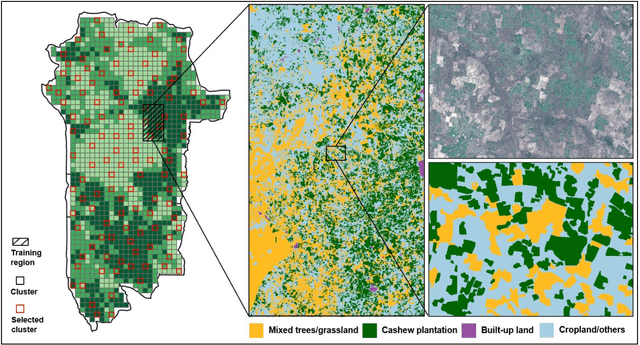
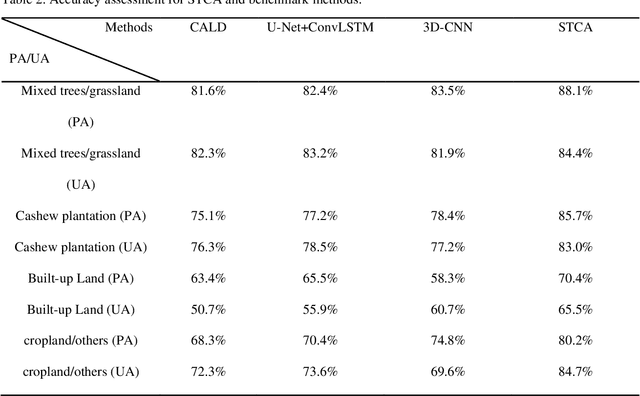
Cashews are grown by over 3 million smallholders in more than 40 countries worldwide as a principal source of income. As the third largest cashew producer in Africa, Benin has nearly 200,000 smallholder cashew growers contributing 15% of the country's national export earnings. However, a lack of information on where and how cashew trees grow across the country hinders decision-making that could support increased cashew production and poverty alleviation. By leveraging 2.4-m Planet Basemaps and 0.5-m aerial imagery, newly developed deep learning algorithms, and large-scale ground truth datasets, we successfully produced the first national map of cashew in Benin and characterized the expansion of cashew plantations between 2015 and 2021. In particular, we developed a SpatioTemporal Classification with Attention (STCA) model to map the distribution of cashew plantations, which can fully capture texture information from discriminative time steps during a growing season. We further developed a Clustering Augmented Self-supervised Temporal Classification (CASTC) model to distinguish high-density versus low-density cashew plantations by automatic feature extraction and optimized clustering. Results show that the STCA model has an overall accuracy of 80% and the CASTC model achieved an overall accuracy of 77.9%. We found that the cashew area in Benin has doubled from 2015 to 2021 with 60% of new plantation development coming from cropland or fallow land, while encroachment of cashew plantations into protected areas has increased by 70%. Only half of cashew plantations were high-density in 2021, suggesting high potential for intensification. Our study illustrates the power of combining high-resolution remote sensing imagery and state-of-the-art deep learning algorithms to better understand tree crops in the heterogeneous smallholder landscape.