 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Localization-based OFDM framework for RIS-aided systems
Mar 22, 2023
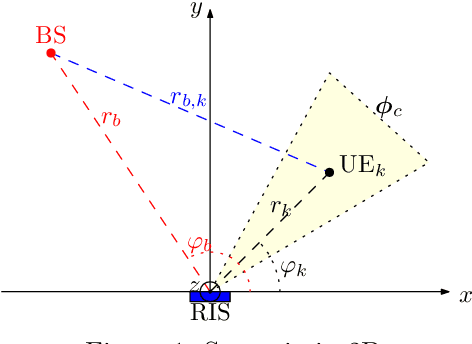
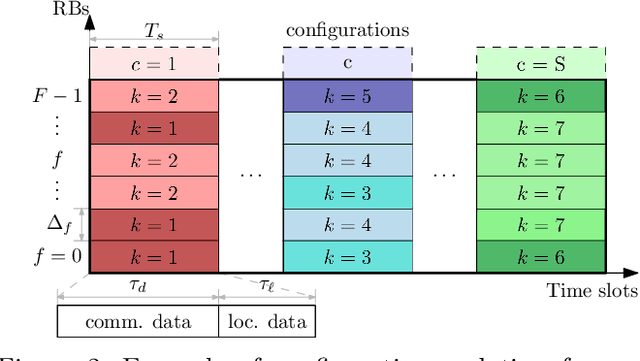
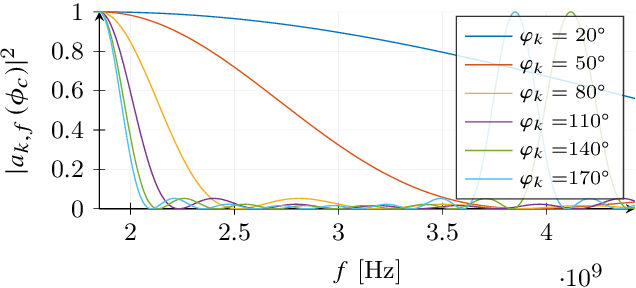
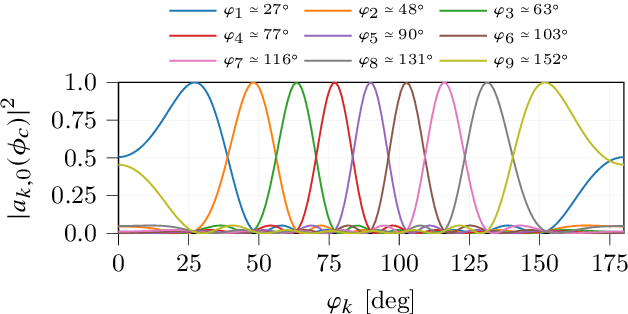
Efficient integration of reconfigurable intelligent surfaces (RISs) into the current wireless network standard is not a trivial task due to the overhead generated by performing channel estimation (CE) and phase-shift optimization. In this paper, we propose a framework enabling the coexistence between orthogonal-frequency division multiplexing (OFDM) and RIS technologies. Instead of wasting communication symbols for the CE and optimization, the proposed framework exploits the localization information obtainable by RIS-aided communications to provide a robust allocation strategy for user multiplexing. The results demonstrate the effectiveness of the proposed approach with respect to CE-based transmission methods.
Fast Latent Factor Analysis via a Fuzzy PID-Incorporated Stochastic Gradient Descent Algorithm
Mar 07, 2023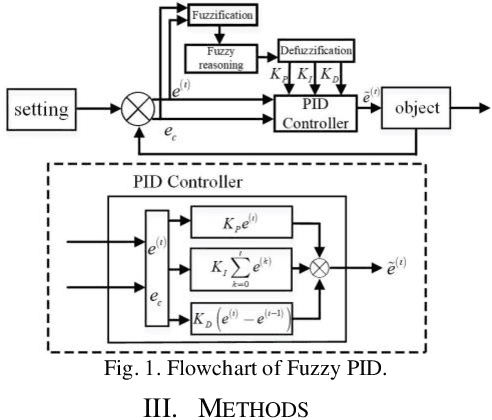

A high-dimensional and incomplete (HDI) matrix can describe the complex interactions among numerous nodes in various big data-related applications. A stochastic gradient descent (SGD)-based latent factor analysis (LFA) model is remarkably effective in extracting valuable information from an HDI matrix. However, such a model commonly encounters the problem of slow convergence because a standard SGD algorithm learns a latent factor relying on the stochastic gradient of current instance error only without considering past update information. To address this critical issue, this paper innovatively proposes a Fuzzy PID-incorporated SGD (FPS) algorithm with two-fold ideas: 1) rebuilding the instance learning error by considering the past update information in an efficient way following the principle of PID, and 2) implementing hyper-parameters and gain parameters adaptation following the fuzzy rules. With it, an FPS-incorporated LFA model is further achieved for fast processing an HDI matrix. Empirical studies on six HDI datasets demonstrate that the proposed FPS-incorporated LFA model significantly outperforms the state-of-the-art LFA models in terms of computational efficiency for predicting the missing data of an HDI matrix with competitive accuracy.
Data Games: A Game-Theoretic Approach to Swarm Robotic Data Collection
Mar 07, 2023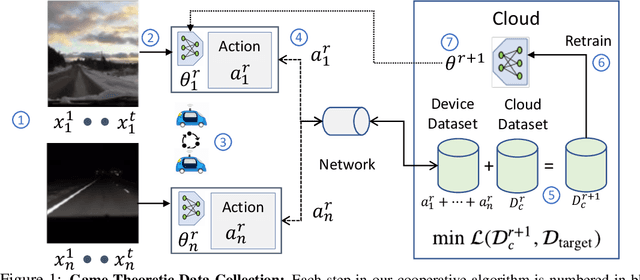
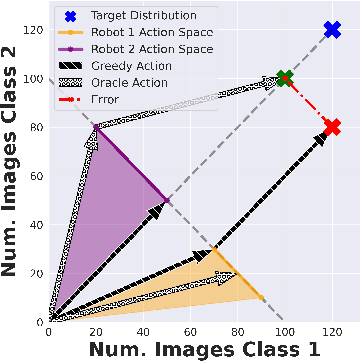
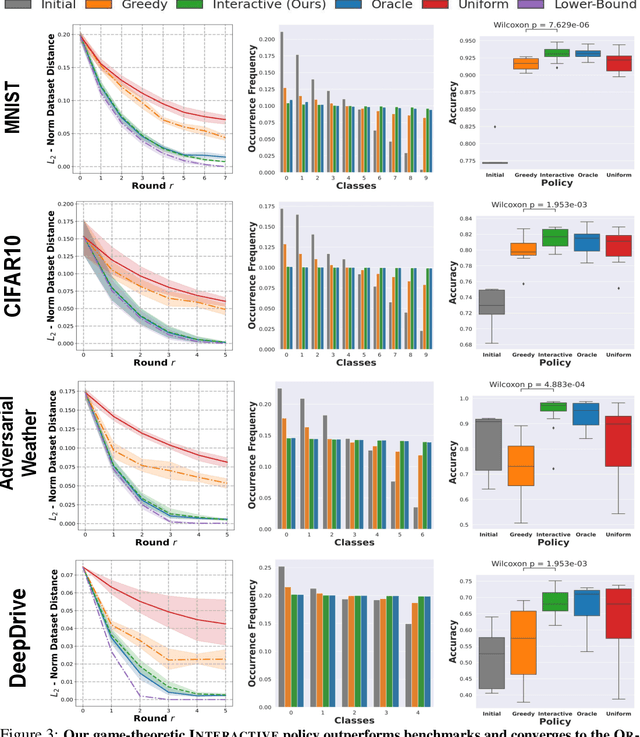
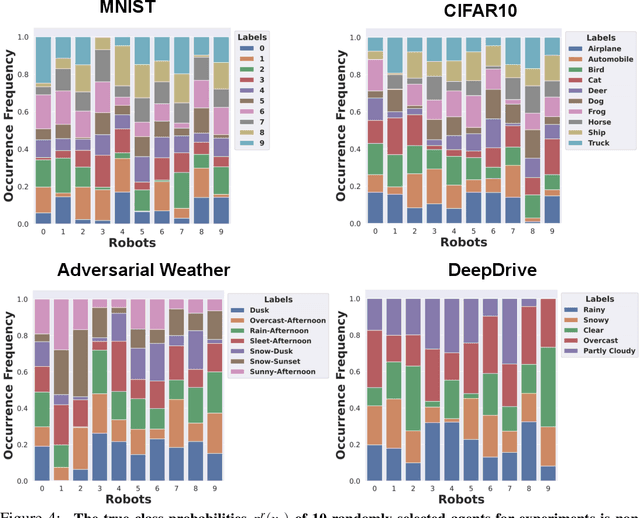
Fleets of networked autonomous vehicles (AVs) collect terabytes of sensory data, which is often transmitted to central servers (the ''cloud'') for training machine learning (ML) models. Ideally, these fleets should upload all their data, especially from rare operating contexts, in order to train robust ML models. However, this is infeasible due to prohibitive network bandwidth and data labeling costs. Instead, we propose a cooperative data sampling strategy where geo-distributed AVs collaborate to collect a diverse ML training dataset in the cloud. Since the AVs have a shared objective but minimal information about each other's local data distribution and perception model, we can naturally cast cooperative data collection as an $N$-player mathematical game. We show that our cooperative sampling strategy uses minimal information to converge to a centralized oracle policy with complete information about all AVs. Moreover, we theoretically characterize the performance benefits of our game-theoretic strategy compared to greedy sampling. Finally, we experimentally demonstrate that our method outperforms standard benchmarks by up to $21.9\%$ on 4 perception datasets, including for autonomous driving in adverse weather conditions. Crucially, our experimental results on real-world datasets closely align with our theoretical guarantees.
Group Testing with Side Information via Generalized Approximate Message Passing
Nov 07, 2022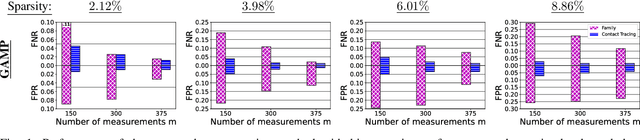
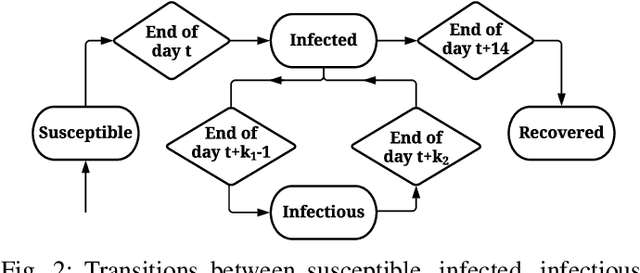
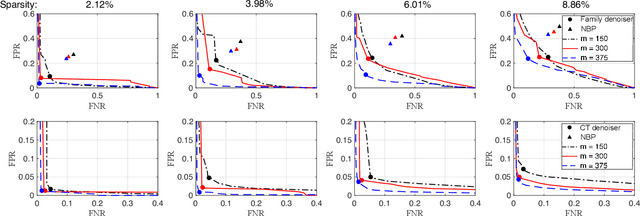
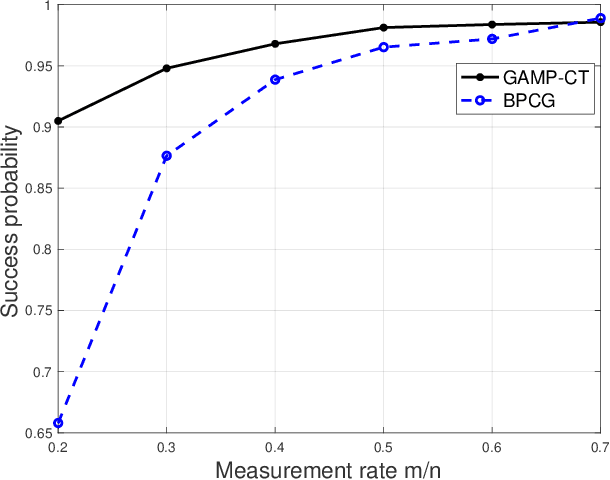
Group testing can help maintain a widespread testing program using fewer resources amid a pandemic. In a group testing setup, we are given n samples, one per individual. Each individual is either infected or uninfected. These samples are arranged into m < n pooled samples, where each pool is obtained by mixing a subset of the n individual samples. Infected individuals are then identified using a group testing algorithm. In this paper, we incorporate side information (SI) collected from contact tracing (CT) into nonadaptive/single-stage group testing algorithms. We generate different types of possible CT SI data by incorporating different possible characteristics of the spread of the disease. These data are fed into a group testing framework based on generalized approximate message passing (GAMP). Numerical results show that our GAMP-based algorithms provide improved accuracy. Compared to a loopy belief propagation algorithm, our proposed framework can increase the success probability by 0.25 for a group testing problem of n = 500 individuals with m = 100 pooled samples.
Why and When: Understanding System Initiative during Conversational Collaborative Search
Mar 23, 2023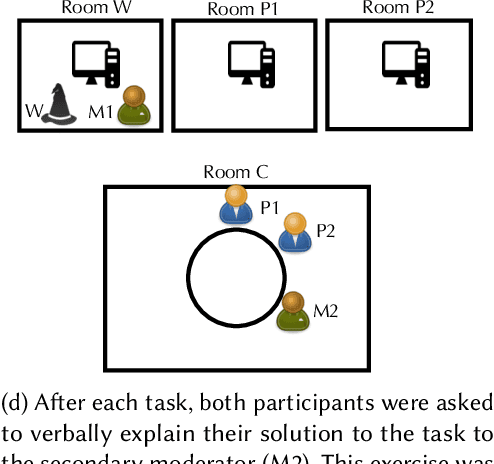
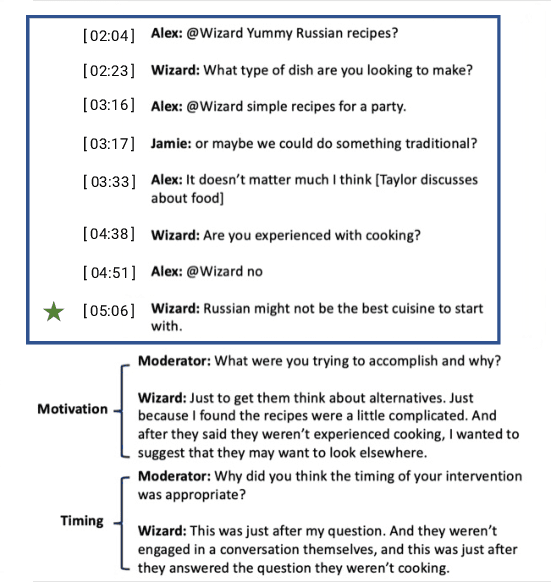
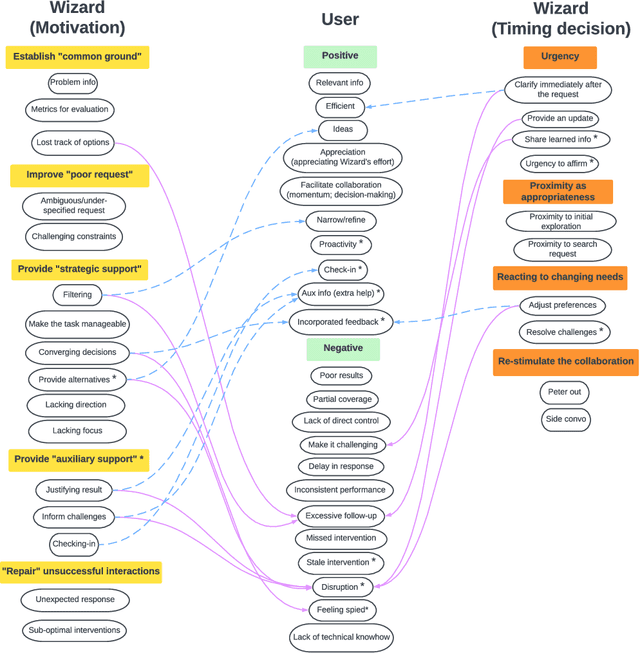
In the last decade, conversational search has attracted considerable attention. However, most research has focused on systems that can support a \emph{single} searcher. In this paper, we explore how systems can support \emph{multiple} searchers collaborating over an instant messaging platform (i.e., Slack). We present a ``Wizard of Oz'' study in which 27 participant pairs collaborated on three information-seeking tasks over Slack. Participants were unable to search on their own and had to gather information by interacting with a \emph{searchbot} directly from the Slack channel. The role of the searchbot was played by a reference librarian. Conversational search systems must be capable of engaging in \emph{mixed-initiative} interaction by taking and relinquishing control of the conversation to fulfill different objectives. Discourse analysis research suggests that conversational agents can take \emph{two} levels of initiative: dialog- and task-level initiative. Agents take dialog-level initiative to establish mutual belief between agents and task-level initiative to influence the goals of the other agents. During the study, participants were exposed to three experimental conditions in which the searchbot could take different levels of initiative: (1) no initiative, (2) only dialog-level initiative, and (3) both dialog- and task-level initiative. In this paper, we focus on understanding the Wizard's actions. Specifically, we focus on understanding the Wizard's motivations for taking initiative and their rationale for the timing of each intervention. To gain insights about the Wizard's actions, we conducted a stimulated recall interview with the Wizard. We present findings from a qualitative analysis of this interview data and discuss implications for designing conversational search systems to support collaborative search.
FedDiSC: A Computation-efficient Federated Learning Framework for Power Systems Disturbance and Cyber Attack Discrimination
Apr 07, 2023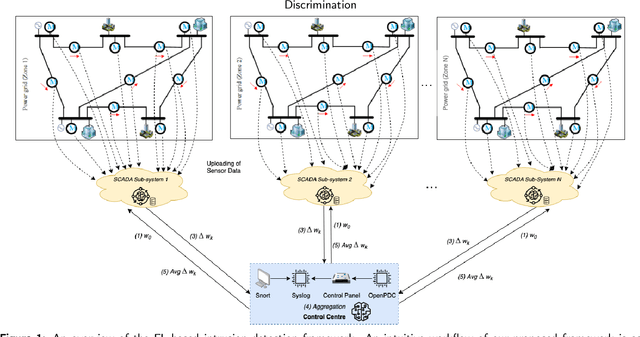
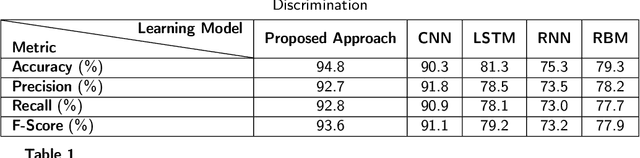
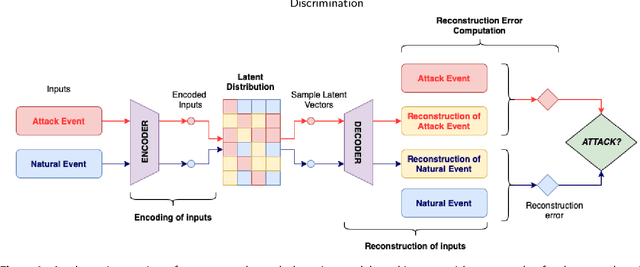
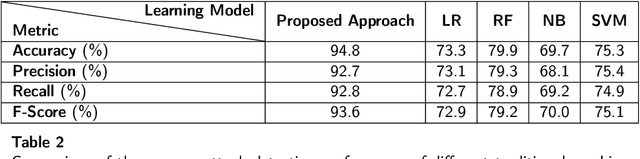
With the growing concern about the security and privacy of smart grid systems, cyberattacks on critical power grid components, such as state estimation, have proven to be one of the top-priority cyber-related issues and have received significant attention in recent years. However, cyberattack detection in smart grids now faces new challenges, including privacy preservation and decentralized power zones with strategic data owners. To address these technical bottlenecks, this paper proposes a novel Federated Learning-based privacy-preserving and communication-efficient attack detection framework, known as FedDiSC, that enables Discrimination between power System disturbances and Cyberattacks. Specifically, we first propose a Federated Learning approach to enable Supervisory Control and Data Acquisition subsystems of decentralized power grid zones to collaboratively train an attack detection model without sharing sensitive power related data. Secondly, we put forward a representation learning-based Deep Auto-Encoder network to accurately detect power system and cybersecurity anomalies. Lastly, to adapt our proposed framework to the timeliness of real-world cyberattack detection in SGs, we leverage the use of a gradient privacy-preserving quantization scheme known as DP-SIGNSGD to improve its communication efficiency. Extensive simulations of the proposed framework on publicly available Industrial Control Systems datasets demonstrate that the proposed framework can achieve superior detection accuracy while preserving the privacy of sensitive power grid related information. Furthermore, we find that the gradient quantization scheme utilized improves communication efficiency by 40% when compared to a traditional federated learning approach without gradient quantization which suggests suitability in a real-world scenario.
Decentralized Riemannian natural gradient methods with Kronecker-product approximations
Mar 16, 2023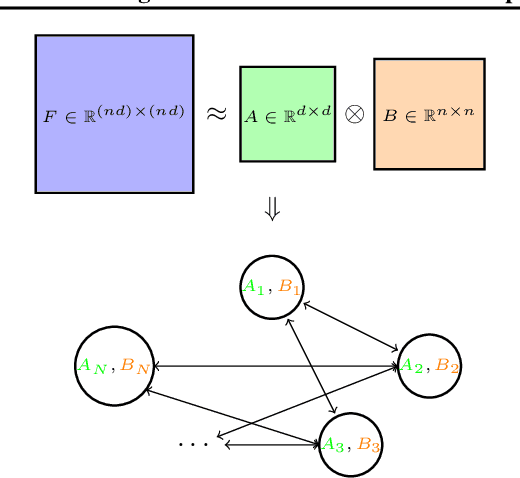
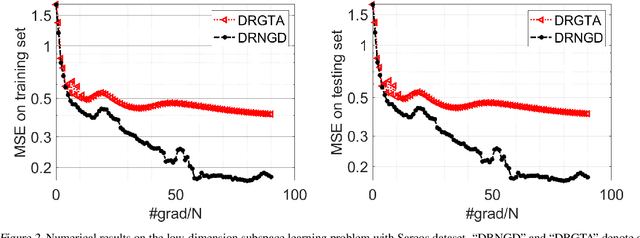
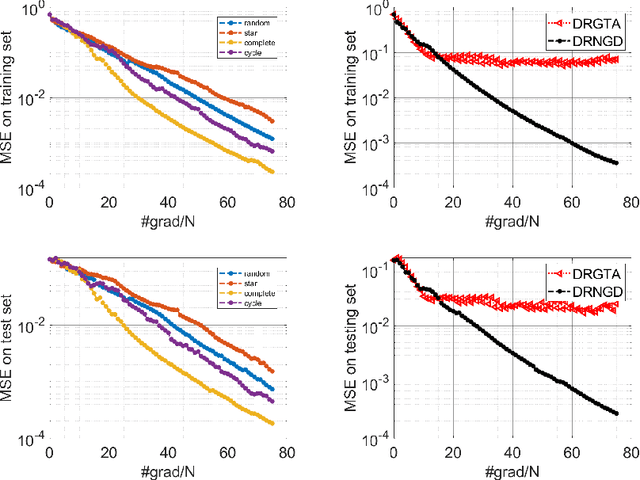

With a computationally efficient approximation of the second-order information, natural gradient methods have been successful in solving large-scale structured optimization problems. We study the natural gradient methods for the large-scale decentralized optimization problems on Riemannian manifolds, where the local objective function defined by the local dataset is of a log-probability type. By utilizing the structure of the Riemannian Fisher information matrix (RFIM), we present an efficient decentralized Riemannian natural gradient descent (DRNGD) method. To overcome the communication issue of the high-dimension RFIM, we consider a class of structured problems for which the RFIM can be approximated by a Kronecker product of two low-dimension matrices. By performing the communications over the Kronecker factors, a high-quality approximation of the RFIM can be obtained in a low cost. We prove that DRNGD converges to a stationary point with the best-known rate of $\mathcal{O}(1/K)$. Numerical experiments demonstrate the efficiency of our proposed method compared with the state-of-the-art ones. To the best of our knowledge, this is the first Riemannian second-order method for solving decentralized manifold optimization problems.
GVP: Generative Volumetric Primitives
Mar 31, 2023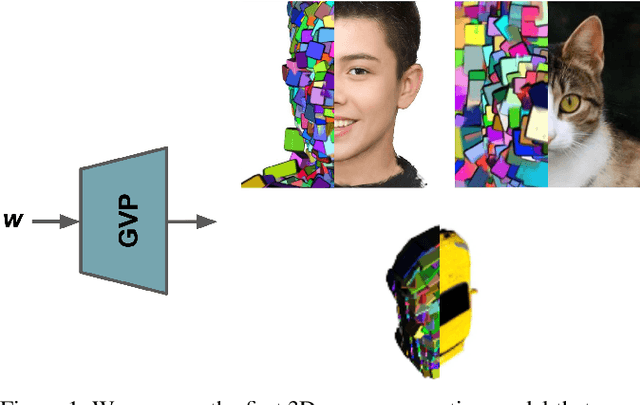
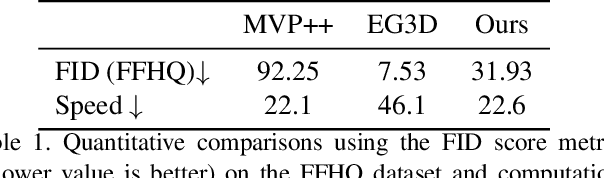
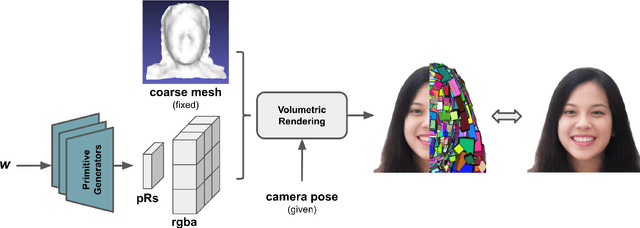

Advances in 3D-aware generative models have pushed the boundary of image synthesis with explicit camera control. To achieve high-resolution image synthesis, several attempts have been made to design efficient generators, such as hybrid architectures with both 3D and 2D components. However, such a design compromises multiview consistency, and the design of a pure 3D generator with high resolution is still an open problem. In this work, we present Generative Volumetric Primitives (GVP), the first pure 3D generative model that can sample and render 512-resolution images in real-time. GVP jointly models a number of volumetric primitives and their spatial information, both of which can be efficiently generated via a 2D convolutional network. The mixture of these primitives naturally captures the sparsity and correspondence in the 3D volume. The training of such a generator with a high degree of freedom is made possible through a knowledge distillation technique. Experiments on several datasets demonstrate superior efficiency and 3D consistency of GVP over the state-of-the-art.
Disentangling Writer and Character Styles for Handwriting Generation
Mar 31, 2023
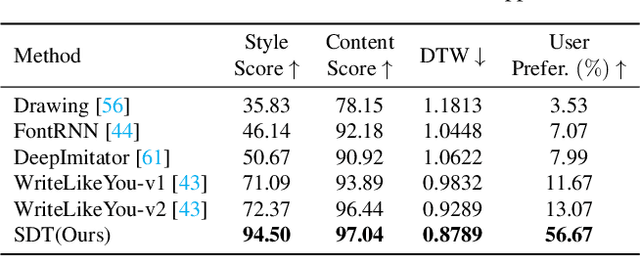

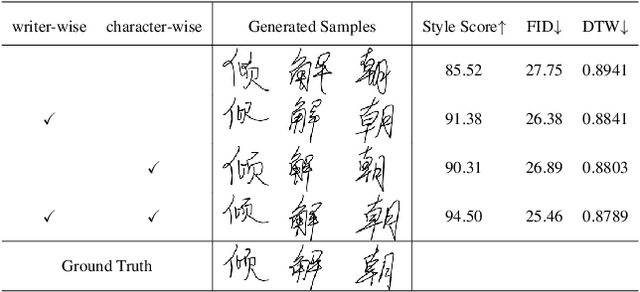
Training machines to synthesize diverse handwritings is an intriguing task. Recently, RNN-based methods have been proposed to generate stylized online Chinese characters. However, these methods mainly focus on capturing a person's overall writing style, neglecting subtle style inconsistencies between characters written by the same person. For example, while a person's handwriting typically exhibits general uniformity (e.g., glyph slant and aspect ratios), there are still small style variations in finer details (e.g., stroke length and curvature) of characters. In light of this, we propose to disentangle the style representations at both writer and character levels from individual handwritings to synthesize realistic stylized online handwritten characters. Specifically, we present the style-disentangled Transformer (SDT), which employs two complementary contrastive objectives to extract the style commonalities of reference samples and capture the detailed style patterns of each sample, respectively. Extensive experiments on various language scripts demonstrate the effectiveness of SDT. Notably, our empirical findings reveal that the two learned style representations provide information at different frequency magnitudes, underscoring the importance of separate style extraction. Our source code is public at: https://github.com/dailenson/SDT.
Automatic Detection of Out-of-body Frames in Surgical Videos for Privacy Protection Using Self-supervised Learning and Minimal Labels
Mar 31, 2023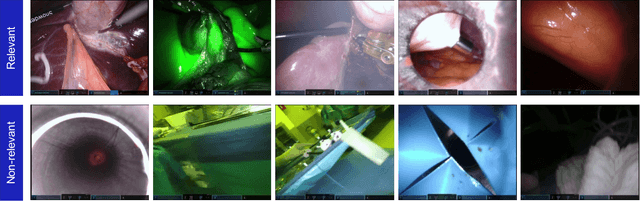
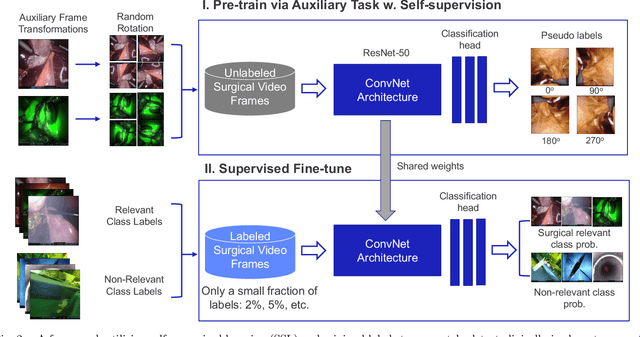
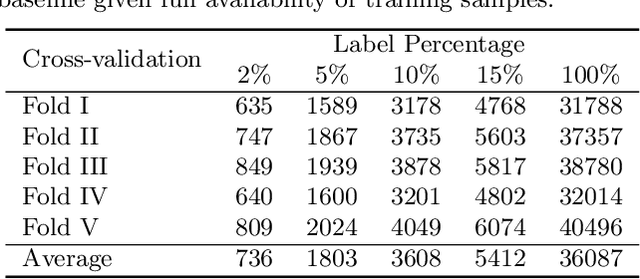
Endoscopic video recordings are widely used in minimally invasive robot-assisted surgery, but when the endoscope is outside the patient's body, it can capture irrelevant segments that may contain sensitive information. To address this, we propose a framework that accurately detects out-of-body frames in surgical videos by leveraging self-supervision with minimal data labels. We use a massive amount of unlabeled endoscopic images to learn meaningful representations in a self-supervised manner. Our approach, which involves pre-training on an auxiliary task and fine-tuning with limited supervision, outperforms previous methods for detecting out-of-body frames in surgical videos captured from da Vinci X and Xi surgical systems. The average F1 scores range from 96.00 to 98.02. Remarkably, using only 5% of the training labels, our approach still maintains an average F1 score performance above 97, outperforming fully-supervised methods with 95% fewer labels. These results demonstrate the potential of our framework to facilitate the safe handling of surgical video recordings and enhance data privacy protection in minimally invasive surgery.