 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CrossFusion: Interleaving Cross-modal Complementation for Noise-resistant 3D Object Detection
Apr 19, 2023
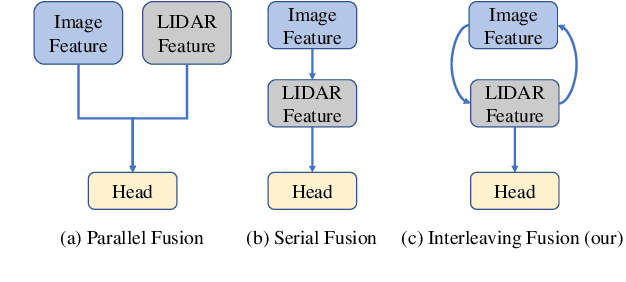
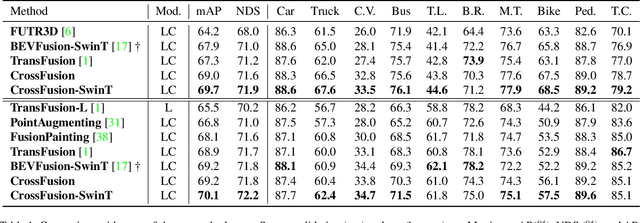
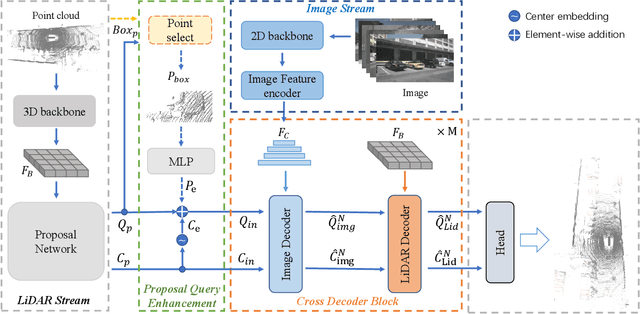

The combination of LiDAR and camera modalities is proven to be necessary and typical for 3D object detection according to recent studies. Existing fusion strategies tend to overly rely on the LiDAR modal in essence, which exploits the abundant semantics from the camera sensor insufficiently. However, existing methods cannot rely on information from other modalities because the corruption of LiDAR features results in a large domain gap. Following this, we propose CrossFusion, a more robust and noise-resistant scheme that makes full use of the camera and LiDAR features with the designed cross-modal complementation strategy. Extensive experiments we conducted show that our method not only outperforms the state-of-the-art methods under the setting without introducing an extra depth estimation network but also demonstrates our model's noise resistance without re-training for the specific malfunction scenarios by increasing 5.2\% mAP and 2.4\% NDS.
A Latent Space Theory for Emergent Abilities in Large Language Models
Apr 19, 2023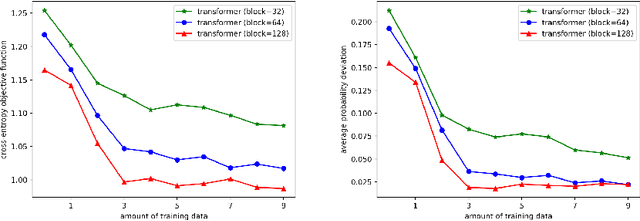
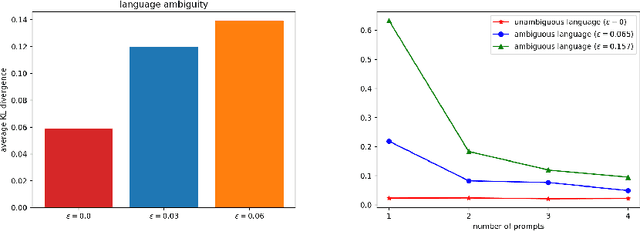
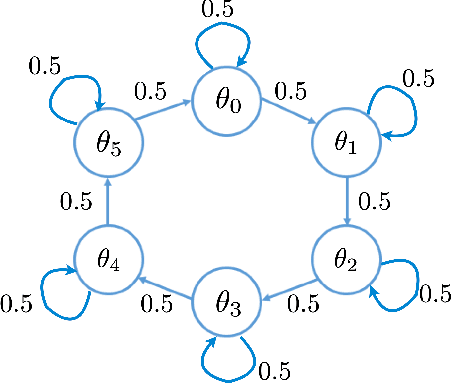
Languages are not created randomly but rather to communicate information. There is a strong association between languages and their underlying meanings, resulting in a sparse joint distribution that is heavily peaked according to their correlations. Moreover, these peak values happen to match with the marginal distribution of languages due to the sparsity. With the advent of LLMs trained on big data and large models, we can now precisely assess the marginal distribution of languages, providing a convenient means of exploring the sparse structures in the joint distribution for effective inferences. In this paper, we categorize languages as either unambiguous or {\epsilon}-ambiguous and present quantitative results to demonstrate that the emergent abilities of LLMs, such as language understanding, in-context learning, chain-of-thought prompting, and effective instruction fine-tuning, can all be attributed to Bayesian inference on the sparse joint distribution of languages.
BRENT: Bidirectional Retrieval Enhanced Norwegian Transformer
Apr 19, 2023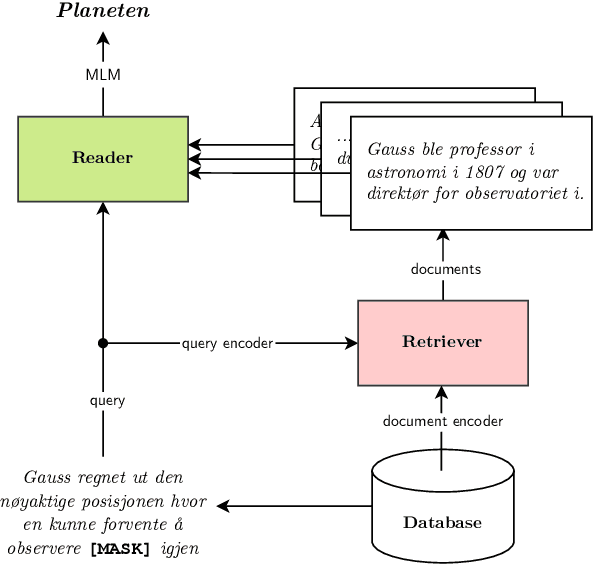
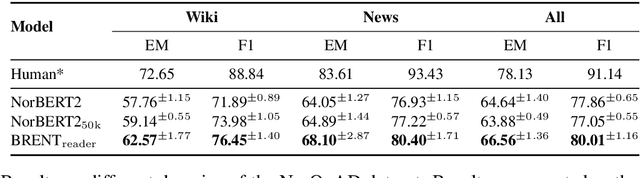
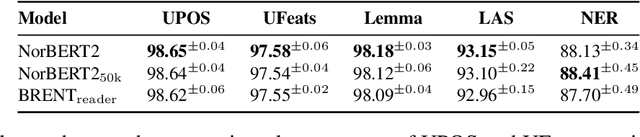
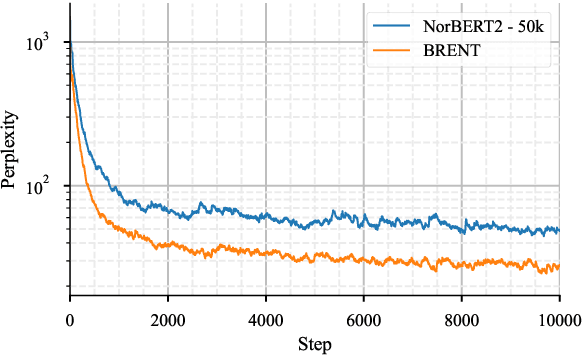
Retrieval-based language models are increasingly employed in question-answering tasks. These models search in a corpus of documents for relevant information instead of having all factual knowledge stored in its parameters, thereby enhancing efficiency, transparency, and adaptability. We develop the first Norwegian retrieval-based model by adapting the REALM framework and evaluating it on various tasks. After training, we also separate the language model, which we call the reader, from the retriever components, and show that this can be fine-tuned on a range of downstream tasks. Results show that retrieval augmented language modeling improves the reader's performance on extractive question-answering, suggesting that this type of training improves language models' general ability to use context and that this does not happen at the expense of other abilities such as part-of-speech tagging, dependency parsing, named entity recognition, and lemmatization. Code, trained models, and data are made publicly available.
Exploring Causes of Demographic Variations In Face Recognition Accuracy
Apr 14, 2023

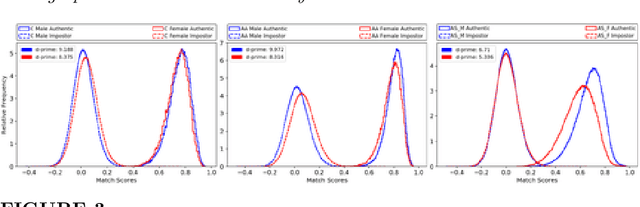
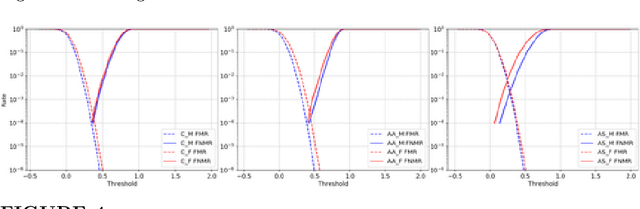
In recent years, media reports have called out bias and racism in face recognition technology. We review experimental results exploring several speculated causes for asymmetric cross-demographic performance. We consider accuracy differences as represented by variations in non-mated (impostor) and / or mated (genuine) distributions for 1-to-1 face matching. Possible causes explored include differences in skin tone, face size and shape, imbalance in number of identities and images in the training data, and amount of face visible in the test data ("face pixels"). We find that demographic differences in face pixel information of the test images appear to most directly impact the resultant differences in face recognition accuracy.
BEVFusion4D: Learning LiDAR-Camera Fusion Under Bird's-Eye-View via Cross-Modality Guidance and Temporal Aggregation
Mar 30, 2023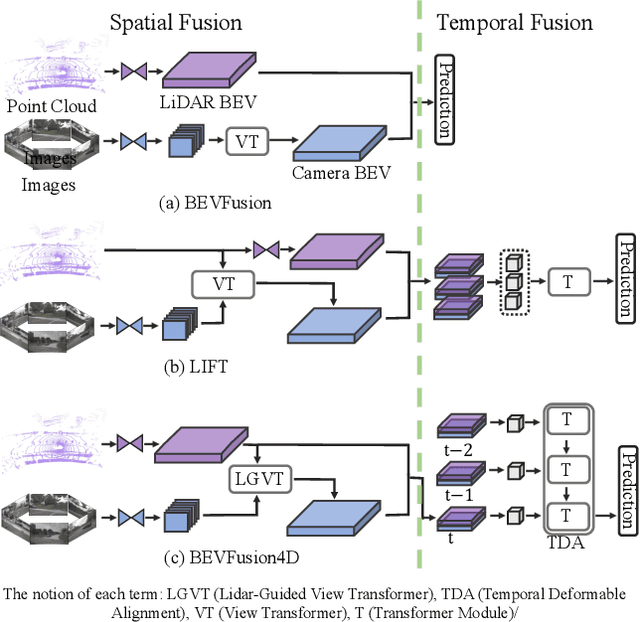
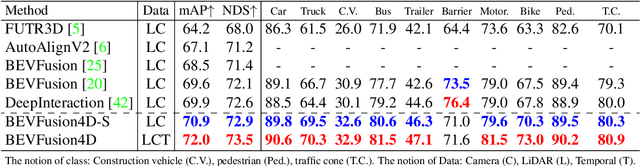

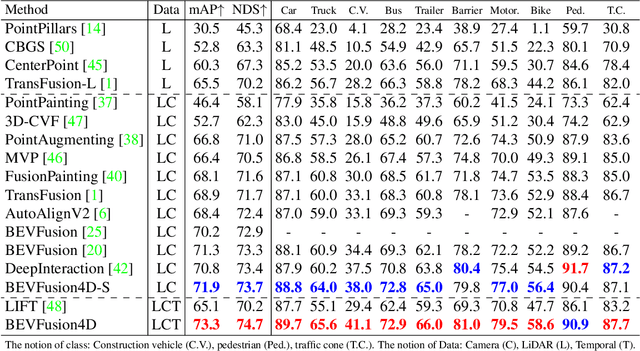
Integrating LiDAR and Camera information into Bird's-Eye-View (BEV) has become an essential topic for 3D object detection in autonomous driving. Existing methods mostly adopt an independent dual-branch framework to generate LiDAR and camera BEV, then perform an adaptive modality fusion. Since point clouds provide more accurate localization and geometry information, they could serve as a reliable spatial prior to acquiring relevant semantic information from the images. Therefore, we design a LiDAR-Guided View Transformer (LGVT) to effectively obtain the camera representation in BEV space and thus benefit the whole dual-branch fusion system. LGVT takes camera BEV as the primitive semantic query, repeatedly leveraging the spatial cue of LiDAR BEV for extracting image features across multiple camera views. Moreover, we extend our framework into the temporal domain with our proposed Temporal Deformable Alignment (TDA) module, which aims to aggregate BEV features from multiple historical frames. Including these two modules, our framework dubbed BEVFusion4D achieves state-of-the-art results in 3D object detection, with 72.0% mAP and 73.5% NDS on the nuScenes validation set, and 73.3% mAP and 74.7% NDS on nuScenes test set, respectively.
SLM: End-to-end Feature Selection via Sparse Learnable Masks
Apr 06, 2023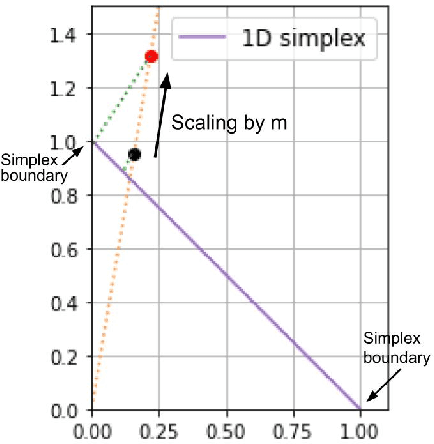
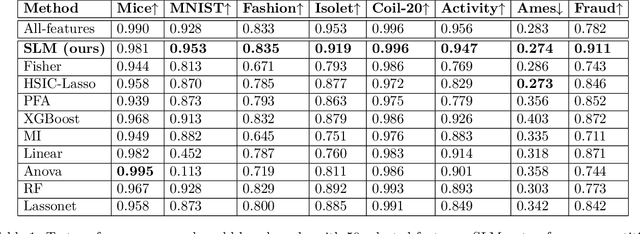
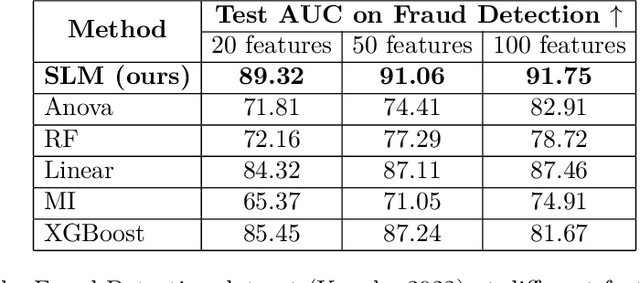
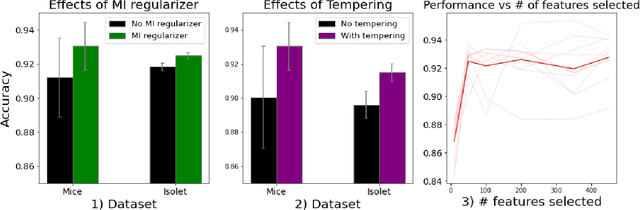
Feature selection has been widely used to alleviate compute requirements during training, elucidate model interpretability, and improve model generalizability. We propose SLM -- Sparse Learnable Masks -- a canonical approach for end-to-end feature selection that scales well with respect to both the feature dimension and the number of samples. At the heart of SLM lies a simple but effective learnable sparse mask, which learns which features to select, and gives rise to a novel objective that provably maximizes the mutual information (MI) between the selected features and the labels, which can be derived from a quadratic relaxation of mutual information from first principles. In addition, we derive a scaling mechanism that allows SLM to precisely control the number of features selected, through a novel use of sparsemax. This allows for more effective learning as demonstrated in ablation studies. Empirically, SLM achieves state-of-the-art results against a variety of competitive baselines on eight benchmark datasets, often by a significant margin, especially on those with real-world challenges such as class imbalance.
Representing Affect Information in Word Embeddings
Sep 21, 2022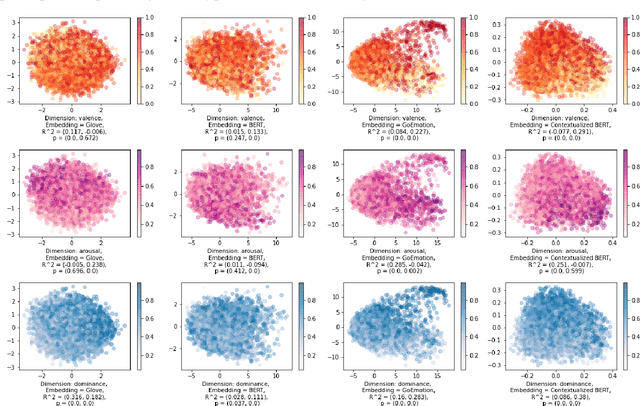
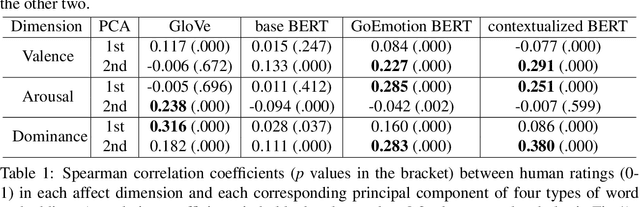

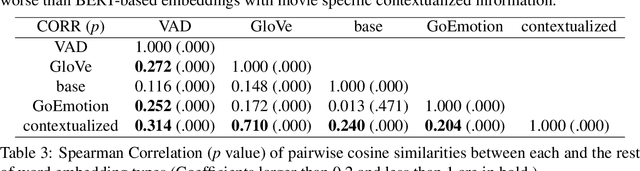
A growing body of research in natural language processing (NLP) and natural language understanding (NLU) is investigating human-like knowledge learned or encoded in the word embeddings from large language models. This is a step towards understanding what knowledge language models capture that resembles human understanding of language and communication. Here, we investigated whether and how the affect meaning of a word (i.e., valence, arousal, dominance) is encoded in word embeddings pre-trained in large neural networks. We used the human-labeled dataset as the ground truth and performed various correlational and classification tests on four types of word embeddings. The embeddings varied in being static or contextualized, and how much affect specific information was prioritized during the pre-training and fine-tuning phase. Our analyses show that word embedding from the vanilla BERT model did not saliently encode the affect information of English words. Only when the BERT model was fine-tuned on emotion-related tasks or contained extra contextualized information from emotion-rich contexts could the corresponding embedding encode more relevant affect information.
Multivariate regression modeling in integrative analysis via sparse regularization
Apr 15, 2023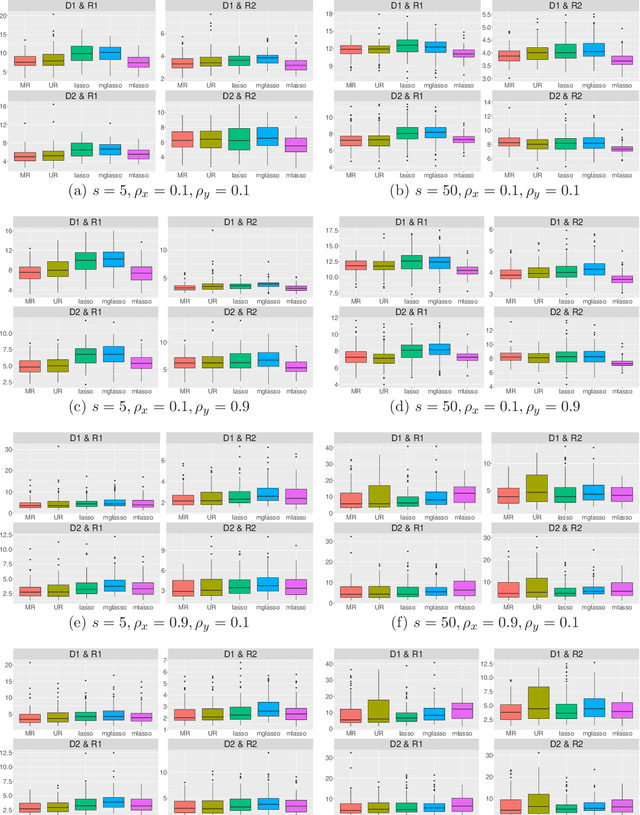
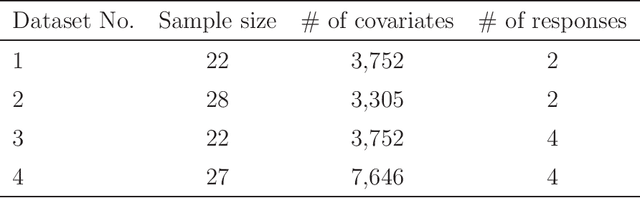
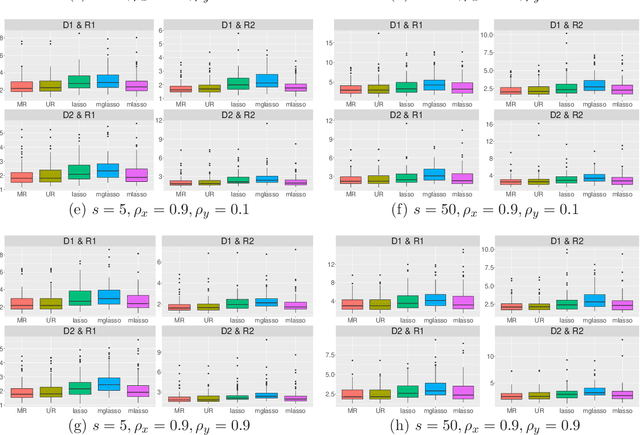
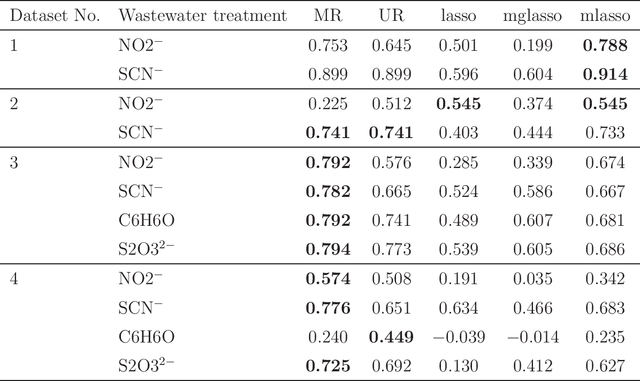
The multivariate regression model basically offers the analysis of a single dataset with multiple responses. However, such a single-dataset analysis often leads to unsatisfactory results. Integrative analysis is an effective method to pool useful information from multiple independent datasets and provides better performance than single-dataset analysis. In this study, we propose a multivariate regression modeling in integrative analysis. The integration is achieved by sparse estimation that performs variable and group selection. Based on the idea of alternating direction method of multipliers, we develop its computational algorithm that enjoys the convergence property. The performance of the proposed method is demonstrated through Monte Carlo simulation and analyzing wastewater treatment data with microbe measurements.
Wireless Channel Charting: Theory, Practice, and Applications
Apr 17, 2023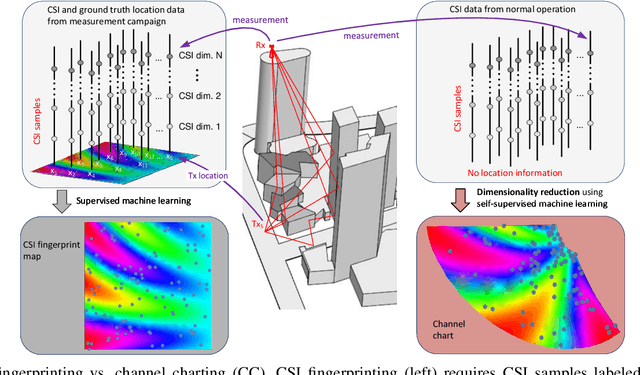
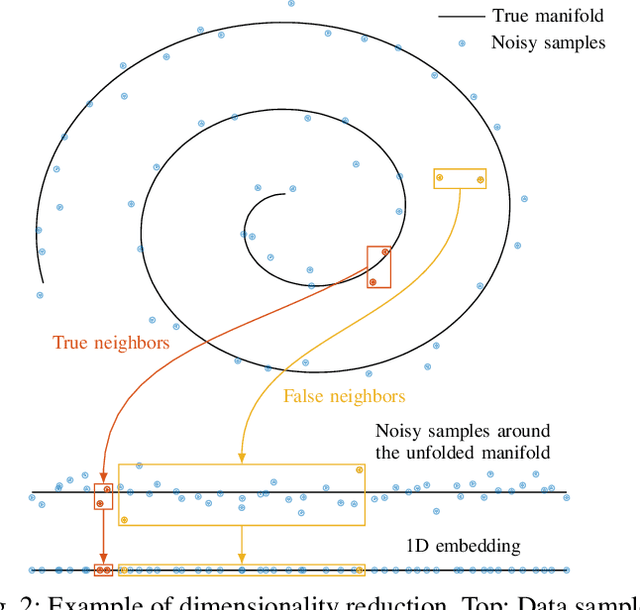
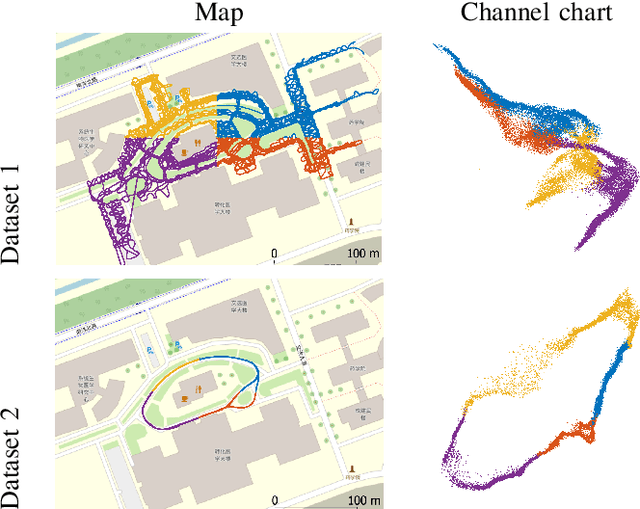
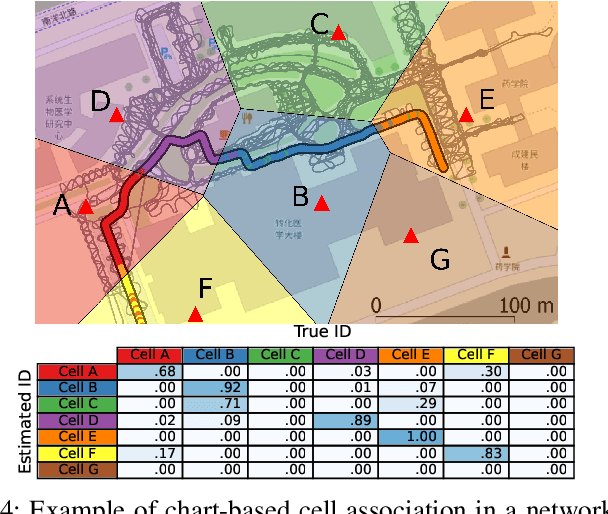
Channel charting is a recently proposed framework that applies dimensionality reduction to channel state information (CSI) in wireless systems with the goal of associating a pseudo-position to each mobile user in a low-dimensional space: the channel chart. Channel charting summarizes the entire CSI dataset in a self-supervised manner, which opens up a range of applications that are tied to user location. In this article, we introduce the theoretical underpinnings of channel charting and present an overview of recent algorithmic developments and experimental results obtained in the field. We furthermore discuss concrete application examples of channel charting to network- and user-related applications, and we provide a perspective on future developments and challenges as well as the role of channel charting in next-generation wireless networks.
Deep Audio-Visual Singing Voice Transcription based on Self-Supervised Learning Models
Apr 24, 2023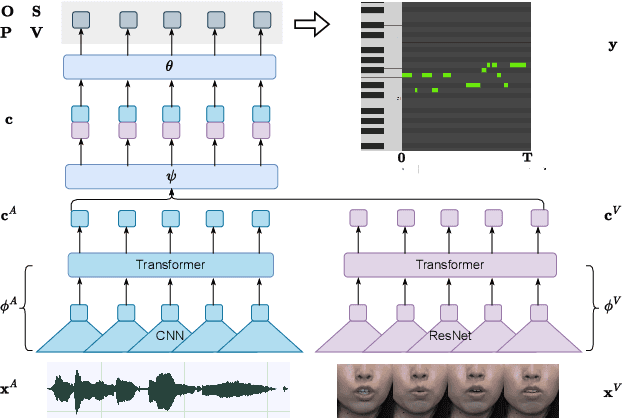
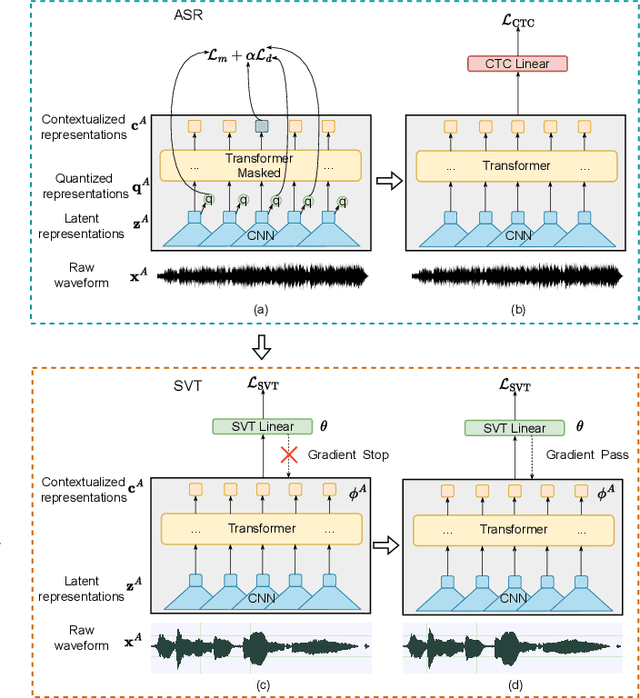
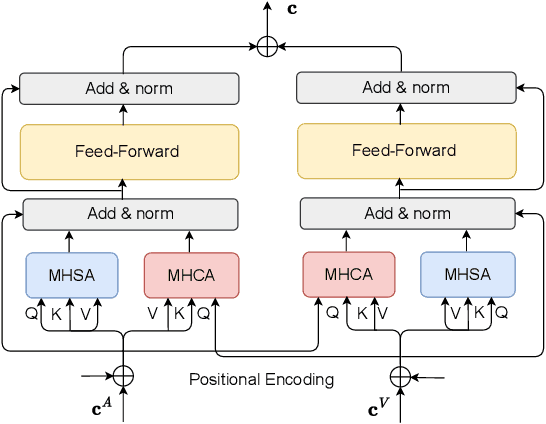
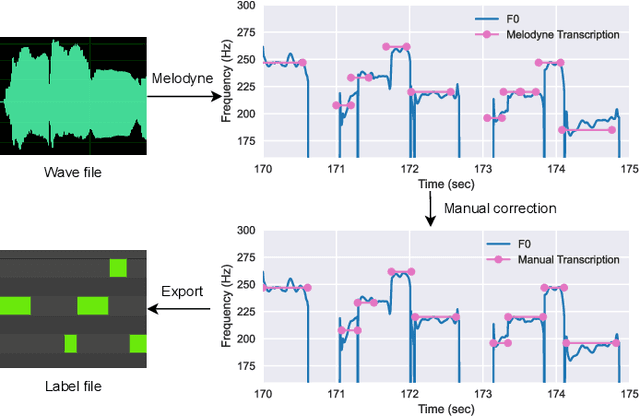
Singing voice transcription converts recorded singing audio to musical notation. Sound contamination (such as accompaniment) and lack of annotated data make singing voice transcription an extremely difficult task. We take two approaches to tackle the above challenges: 1) introducing multimodal learning for singing voice transcription together with a new multimodal singing dataset, N20EMv2, enhancing noise robustness by utilizing video information (lip movements to predict the onset/offset of notes), and 2) adapting self-supervised learning models from the speech domain to the singing voice transcription task, significantly reducing annotated data requirements while preserving pretrained features. We build a self-supervised learning based audio-only singing voice transcription system, which not only outperforms current state-of-the-art technologies as a strong baseline, but also generalizes well to out-of-domain singing data. We then develop a self-supervised learning based video-only singing voice transcription system that detects note onsets and offsets with an accuracy of about 80\%. Finally, based on the powerful acoustic and visual representations extracted by the above two systems as well as the feature fusion design, we create an audio-visual singing voice transcription system that improves the noise robustness significantly under different acoustic environments compared to the audio-only systems.