 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Machine Learning Approach to Improving Timing Consistency between Global Route and Detailed Route
May 11, 2023
Due to the unavailability of routing information in design stages prior to detailed routing (DR), the tasks of timing prediction and optimization pose major challenges. Inaccurate timing prediction wastes design effort, hurts circuit performance, and may lead to design failure. This work focuses on timing prediction after clock tree synthesis and placement legalization, which is the earliest opportunity to time and optimize a "complete" netlist. The paper first documents that having "oracle knowledge" of the final post-DR parasitics enables post-global routing (GR) optimization to produce improved final timing outcomes. To bridge the gap between GR-based parasitic and timing estimation and post-DR results during post-GR optimization, machine learning (ML)-based models are proposed, including the use of features for macro blockages for accurate predictions for designs with macros. Based on a set of experimental evaluations, it is demonstrated that these models show higher accuracy than GR-based timing estimation. When used during post-GR optimization, the ML-based models show demonstrable improvements in post-DR circuit performance. The methodology is applied to two different tool flows - OpenROAD and a commercial tool flow - and results on 45nm bulk and 12nm FinFET enablements show improvements in post-DR slack metrics without increasing congestion. The models are demonstrated to be generalizable to designs generated under different clock period constraints and are robust to training data with small levels of noise.
tieval: An Evaluation Framework for Temporal Information Extraction Systems
Jan 11, 2023
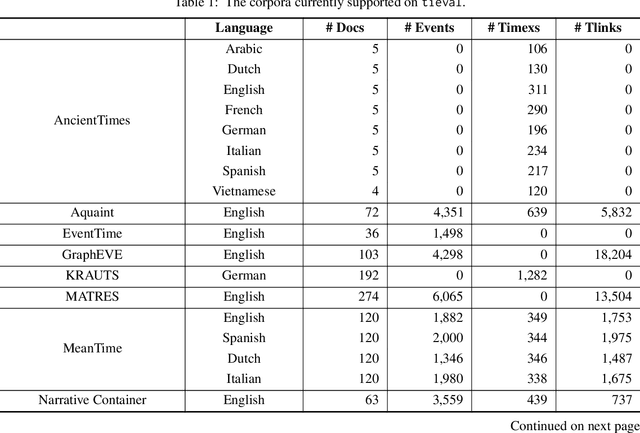

Temporal information extraction (TIE) has attracted a great deal of interest over the last two decades, leading to the development of a significant number of datasets. Despite its benefits, having access to a large volume of corpora makes it difficult when it comes to benchmark TIE systems. On the one hand, different datasets have different annotation schemes, thus hindering the comparison between competitors across different corpora. On the other hand, the fact that each corpus is commonly disseminated in a different format requires a considerable engineering effort for a researcher/practitioner to develop parsers for all of them. This constraint forces researchers to select a limited amount of datasets to evaluate their systems which consequently limits the comparability of the systems. Yet another obstacle that hinders the comparability of the TIE systems is the evaluation metric employed. While most research works adopt traditional metrics such as precision, recall, and $F_1$, a few others prefer temporal awareness -- a metric tailored to be more comprehensive on the evaluation of temporal systems. Although the reason for the absence of temporal awareness in the evaluation of most systems is not clear, one of the factors that certainly weights this decision is the necessity to implement the temporal closure algorithm in order to compute temporal awareness, which is not straightforward to implement neither is currently easily available. All in all, these problems have limited the fair comparison between approaches and consequently, the development of temporal extraction systems. To mitigate these problems, we have developed tieval, a Python library that provides a concise interface for importing different corpora and facilitates system evaluation. In this paper, we present the first public release of tieval and highlight its most relevant features.
The Training Process of Many Deep Networks Explores the Same Low-Dimensional Manifold
May 02, 2023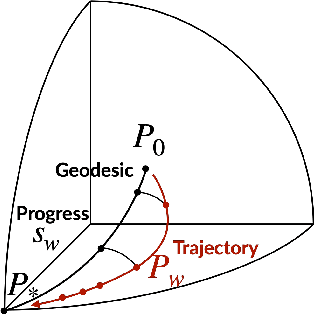
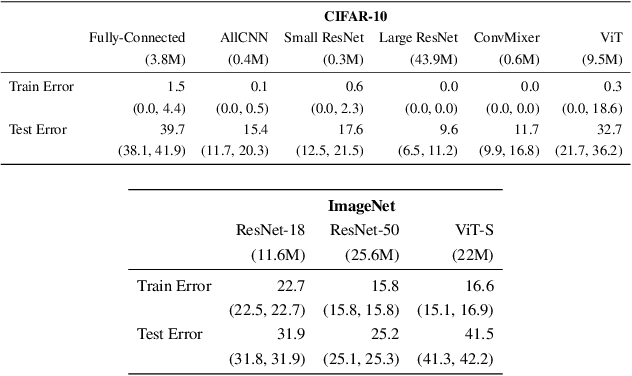
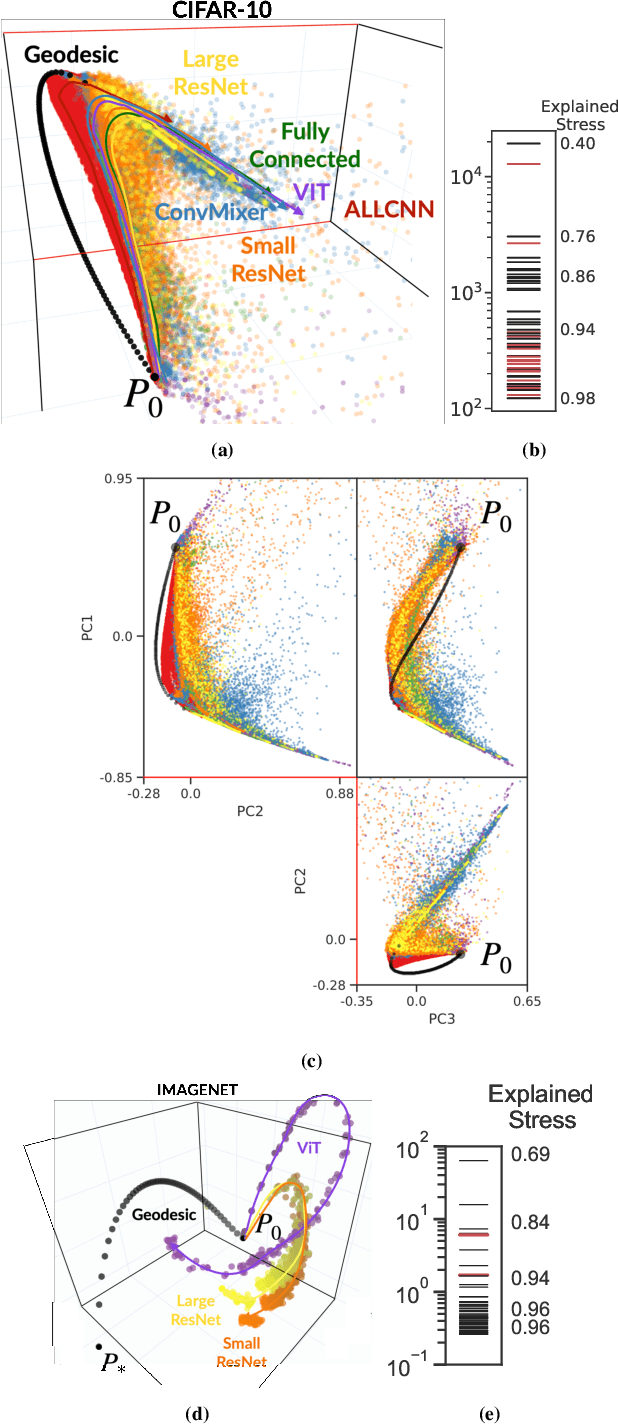
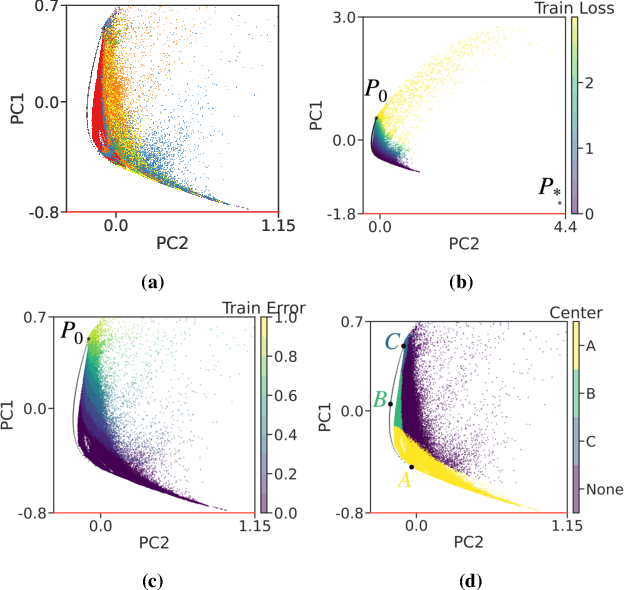
We develop information-geometric techniques to analyze the trajectories of the predictions of deep networks during training. By examining the underlying high-dimensional probabilistic models, we reveal that the training process explores an effectively low-dimensional manifold. Networks with a wide range of architectures, sizes, trained using different optimization methods, regularization techniques, data augmentation techniques, and weight initializations lie on the same manifold in the prediction space. We study the details of this manifold to find that networks with different architectures follow distinguishable trajectories but other factors have a minimal influence; larger networks train along a similar manifold as that of smaller networks, just faster; and networks initialized at very different parts of the prediction space converge to the solution along a similar manifold.
Reinforcement Learning with Partial Parametric Model Knowledge
Apr 26, 2023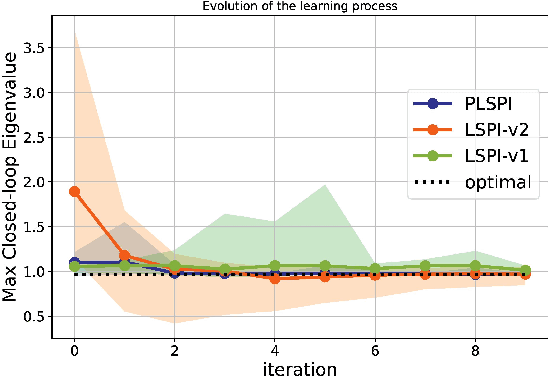
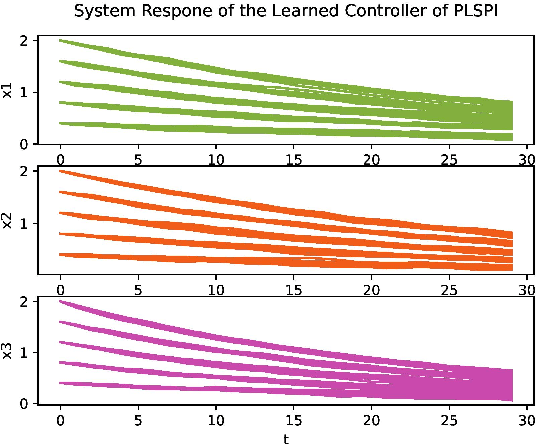
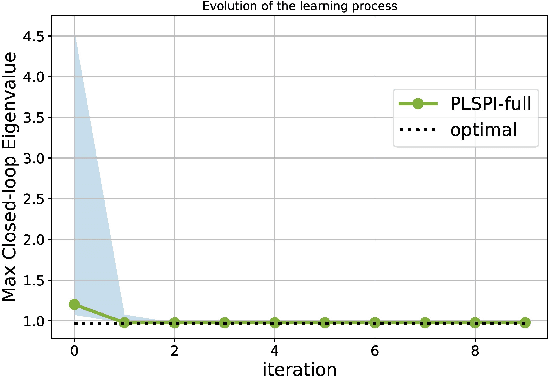
We adapt reinforcement learning (RL) methods for continuous control to bridge the gap between complete ignorance and perfect knowledge of the environment. Our method, Partial Knowledge Least Squares Policy Iteration (PLSPI), takes inspiration from both model-free RL and model-based control. It uses incomplete information from a partial model and retains RL's data-driven adaption towards optimal performance. The linear quadratic regulator provides a case study; numerical experiments demonstrate the effectiveness and resulting benefits of the proposed method.
Simulation of Dynamic Environments for SLAM
May 07, 2023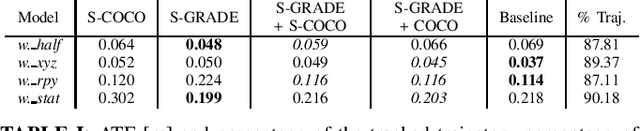
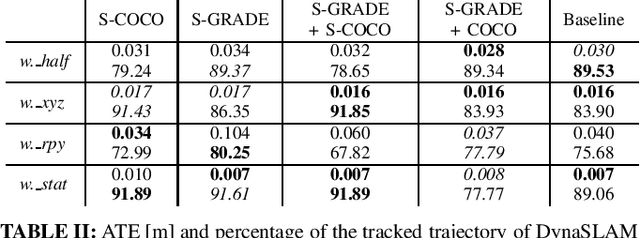
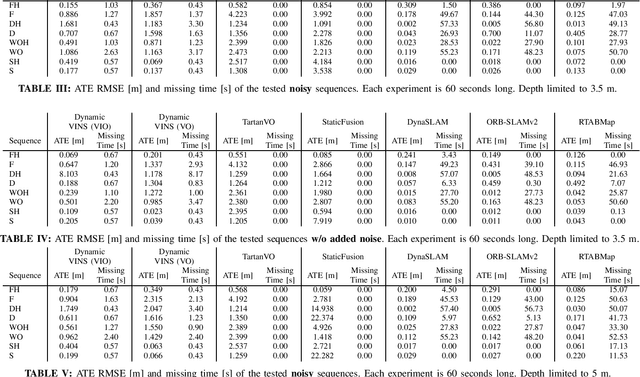

Simulation engines are widely adopted in robotics. However, they lack either full simulation control, ROS integration, realistic physics, or photorealism. Recently, synthetic data generation and realistic rendering has advanced tasks like target tracking and human pose estimation. However, when focusing on vision applications, there is usually a lack of information like sensor measurements or time continuity. On the other hand, simulations for most robotics tasks are performed in (semi)static environments, with specific sensors and low visual fidelity. To solve this, we introduced in our previous work a fully customizable framework for generating realistic animated dynamic environments (GRADE) [1]. We use GRADE to generate an indoor dynamic environment dataset and then compare multiple SLAM algorithms on different sequences. By doing that, we show how current research over-relies on known benchmarks, failing to generalize. Our tests with refined YOLO and Mask R-CNN models provide further evidence that additional research in dynamic SLAM is necessary. The code, results, and generated data are provided as open-source at https://eliabntt.github.io/grade-rrSimulation of Dynamic Environments for SLAM
MrTF: Model Refinery for Transductive Federated Learning
May 07, 2023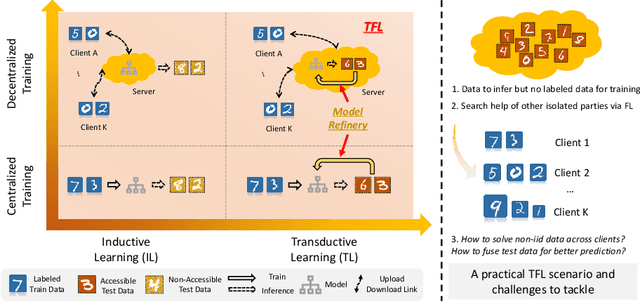
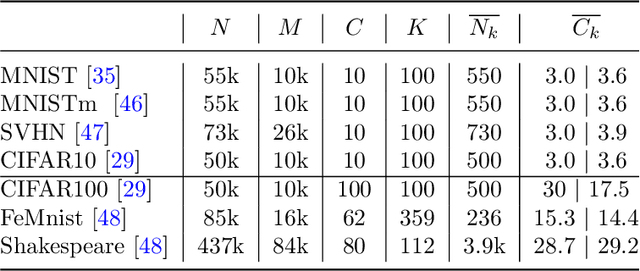
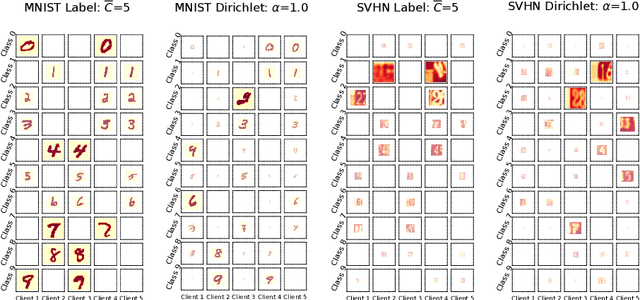
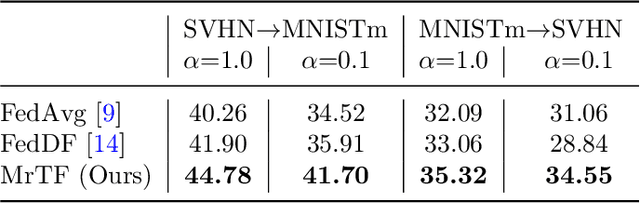
We consider a real-world scenario in which a newly-established pilot project needs to make inferences for newly-collected data with the help of other parties under privacy protection policies. Current federated learning (FL) paradigms are devoted to solving the data heterogeneity problem without considering the to-be-inferred data. We propose a novel learning paradigm named transductive federated learning (TFL) to simultaneously consider the structural information of the to-be-inferred data. On the one hand, the server could use the pre-available test samples to refine the aggregated models for robust model fusion, which tackles the data heterogeneity problem in FL. On the other hand, the refinery process incorporates test samples into training and could generate better predictions in a transductive manner. We propose several techniques including stabilized teachers, rectified distillation, and clustered label refinery to facilitate the model refinery process. Abundant experimental studies verify the superiorities of the proposed \underline{M}odel \underline{r}efinery framework for \underline{T}ransductive \underline{F}ederated learning (MrTF). The source code is available at \url{https://github.com/lxcnju/MrTF}.
CatFLW: Cat Facial Landmarks in the Wild Dataset
May 07, 2023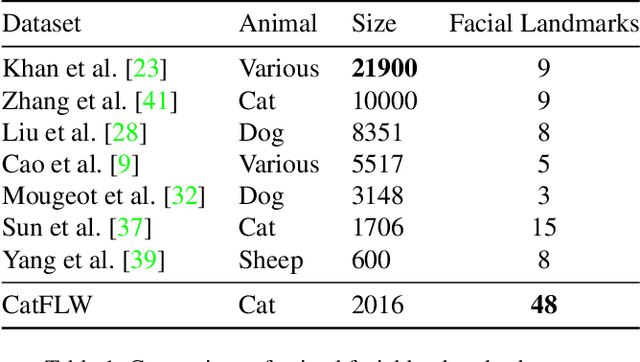


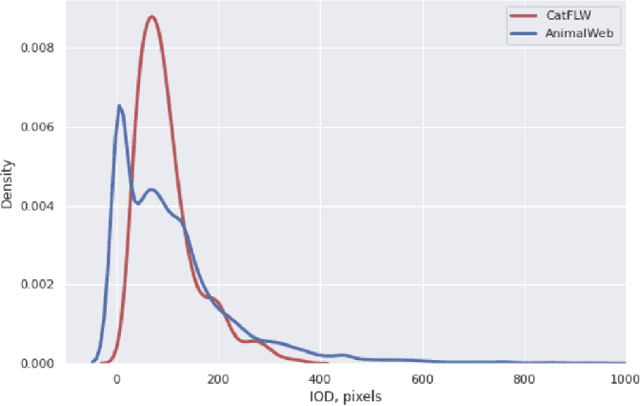
Animal affective computing is a quickly growing field of research, where only recently first efforts to go beyond animal tracking into recognizing their internal states, such as pain and emotions, have emerged. In most mammals, facial expressions are an important channel for communicating information about these states. However, unlike the human domain, there is an acute lack of datasets that make automation of facial analysis of animals feasible. This paper aims to fill this gap by presenting a dataset called Cat Facial Landmarks in the Wild (CatFLW) which contains 2016 images of cat faces in different environments and conditions, annotated with 48 facial landmarks specifically chosen for their relationship with underlying musculature, and relevance to cat-specific facial Action Units (CatFACS). To the best of our knowledge, this dataset has the largest amount of cat facial landmarks available. In addition, we describe a semi-supervised (human-in-the-loop) method of annotating images with landmarks, used for creating this dataset, which significantly reduces the annotation time and could be used for creating similar datasets for other animals. The dataset is available on request.
Knowledge Soft Integration for Multimodal Recommendation
May 12, 2023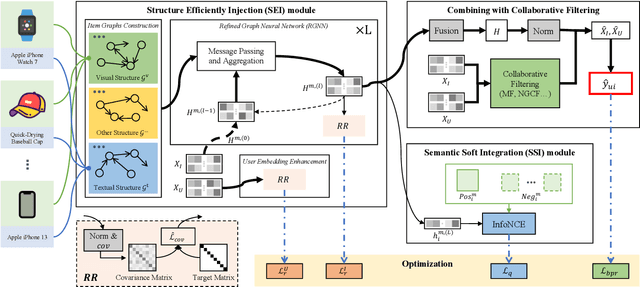
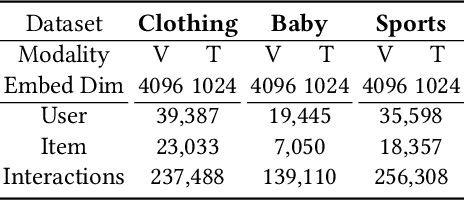
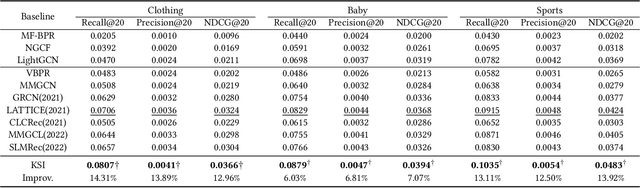
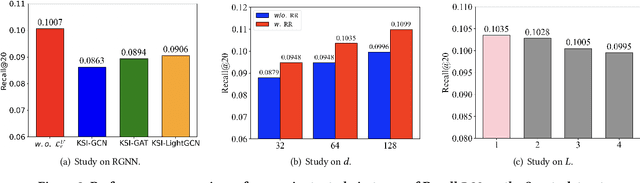
One of the main challenges in modern recommendation systems is how to effectively utilize multimodal content to achieve more personalized recommendations. Despite various proposed solutions, most of them overlook the mismatch between the knowledge gained from independent feature extraction processes and downstream recommendation tasks. Specifically, multimodal feature extraction processes do not incorporate prior knowledge relevant to recommendation tasks, while recommendation tasks often directly use these multimodal features as side information. This mismatch can lead to model fitting biases and performance degradation, which this paper refers to as the \textit{curse of knowledge} problem. To address this issue, we propose using knowledge soft integration to balance the utilization of multimodal features and the curse of knowledge problem it brings about. To achieve this, we put forward a Knowledge Soft Integration framework for the multimodal recommendation, abbreviated as KSI, which is composed of the Structure Efficiently Injection (SEI) module and the Semantic Soft Integration (SSI) module. In the SEI module, we model the modality correlation between items using Refined Graph Neural Network (RGNN), and introduce a regularization term to reduce the redundancy of user/item representations. In the SSI module, we design a self-supervised retrieval task to further indirectly integrate the semantic knowledge of multimodal features, and enhance the semantic discrimination of item representations. Extensive experiments on three benchmark datasets demonstrate the superiority of KSI and validate the effectiveness of its two modules.
Intercomparison of Brown Dwarf Model Grids and Atmospheric Retrieval Using Machine Learning
May 12, 2023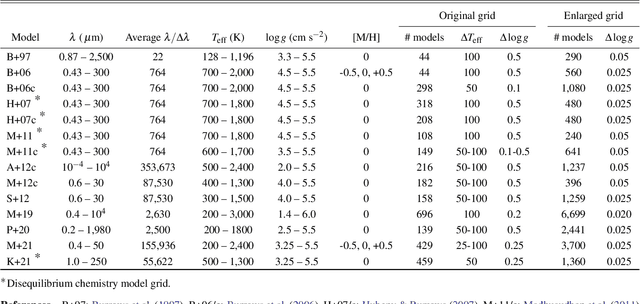
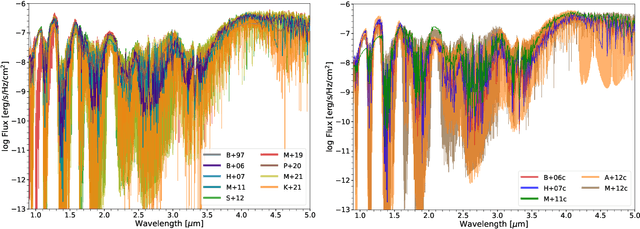
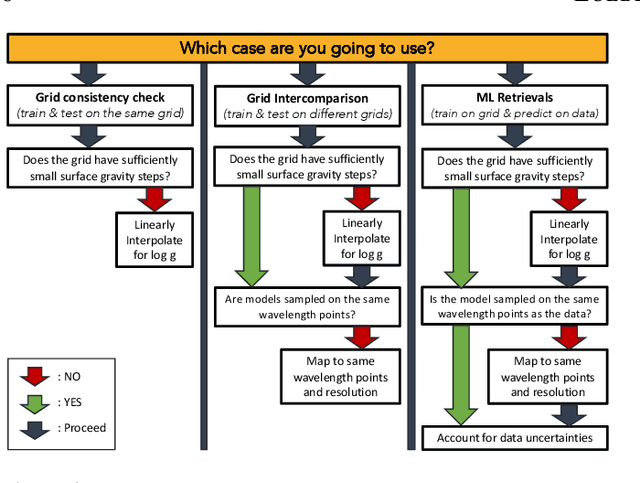
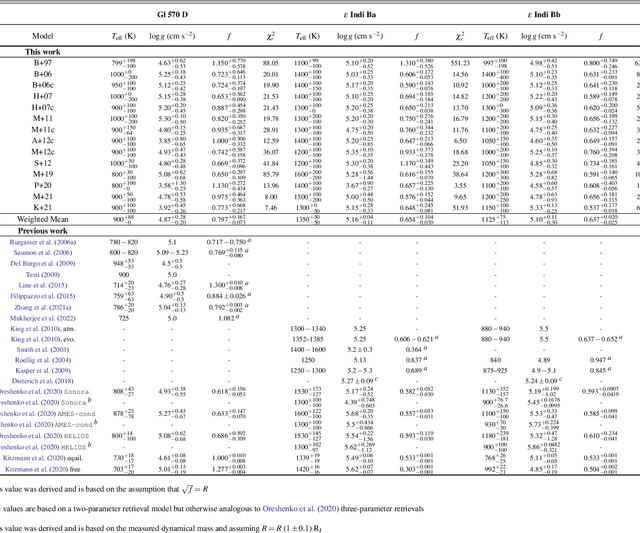
Understanding differences between sub-stellar spectral data and models has proven to be a major challenge, especially for self-consistent model grids that are necessary for a thorough investigation of brown dwarf atmospheres. Using the supervised machine learning method of the random forest, we study the information content of 14 previously published model grids of brown dwarfs (from 1997 to 2021). The random forest method allows us to analyze the predictive power of these model grids, as well as interpret data within the framework of Approximate Bayesian Computation (ABC). Our curated dataset includes 3 benchmark brown dwarfs (Gl 570D, {\epsilon} Indi Ba and Bb) as well as a sample of 19 L and T dwarfs; this sample was previously analyzed in Lueber et al. (2022) using traditional Bayesian methods (nested sampling). We find that the effective temperature of a brown dwarf can be robustly predicted independent of the model grid chosen for the interpretation. However, inference of the surface gravity is model-dependent. Specifically, the BT-Settl, Sonora Bobcat and Sonora Cholla model grids tend to predict logg ~3-4 (cgs units) even after data blueward of 1.2 {\mu}m have been disregarded to mitigate for our incomplete knowledge of the shapes of alkali lines. Two major, longstanding challenges associated with understanding the influence of clouds in brown dwarf atmospheres remain: our inability to model them from first principles and also to robustly validate these models.
Optimum Methods for Quasi-Orthographic Surface Imaging
May 14, 2023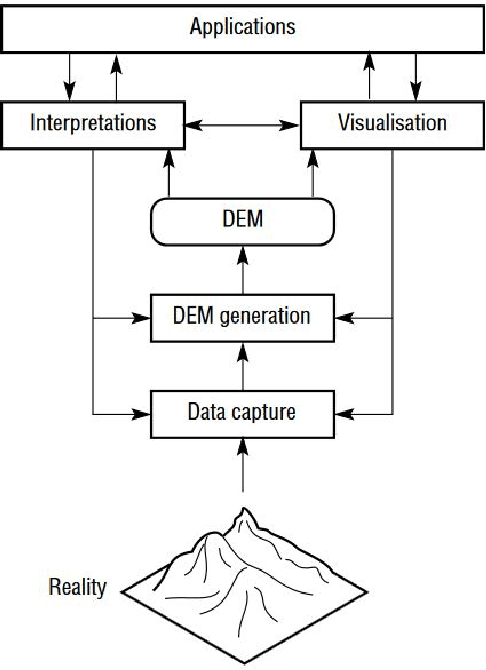
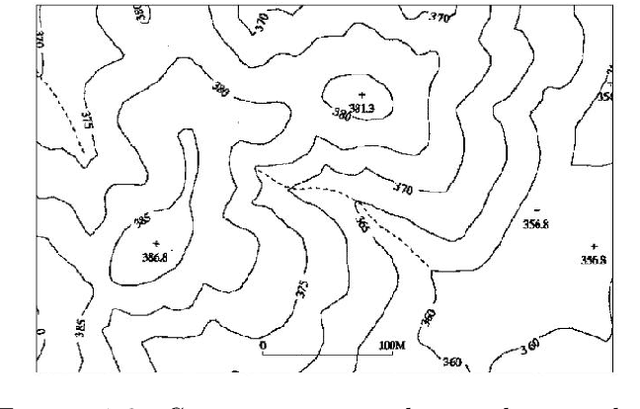

The need for fast, effective and accurate surveys have become increasingly necessary. A major part of the research is supported by photographic surveys which are used for capturing expansive natural surfaces using a wide range of sensors -- visual, infrared, ultrasonic, radio, etc. Because of the unpredictability and fast-varying characteristic of natural surfaces, it is often very difficult to capture and reconstruct them accurately. Moreover, the non-smooth nature results in the occlusion of major areas when a small number of captures are used for reconstruction, resulting in loss of important and maybe significant information or surface features. In a perfect orthographic reconstruction, images must be captured normal to each point on the surface which is practically implausible. This thesis aims at proposing several algorithms for deciding optimal capture points, given a surface, such that the optimal captures can be used for an approximate orthographic reconstruction. An approximate orthographic capture has been attributed to a small field of view and a closed form relationship has been derived for evaluating local orthographic capture region which varies depending on the point of capture on the surface. Based on the formula to calculate approximate local orthographic regions, several algorithms have been developed using non-convex optimization techniques for covering the entire surface with minimum number of such capture points. The algorithms have been compared on the basis of accuracy and computational complexity and parameters have been tuned depending on the nature of the surface. A separate algorithm has been proposed to identify such capture points empirically depending on the local surface-curvatures. Given these algorithms, users can make informed choices regarding which to adopt in their application as per their requirements.