 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Effective and Stable Role-Based Multi-Agent Collaboration by Structural Information Principles
Apr 03, 2023
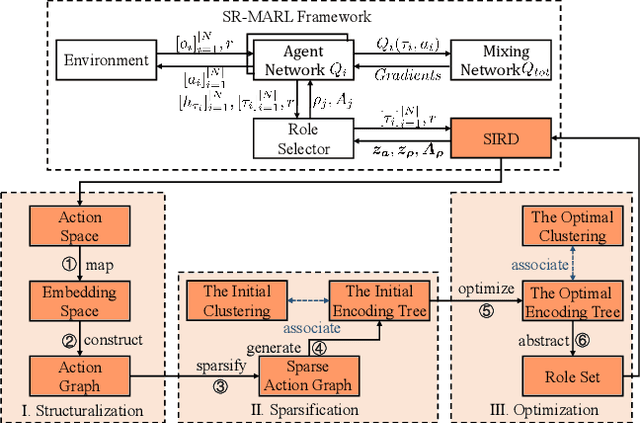
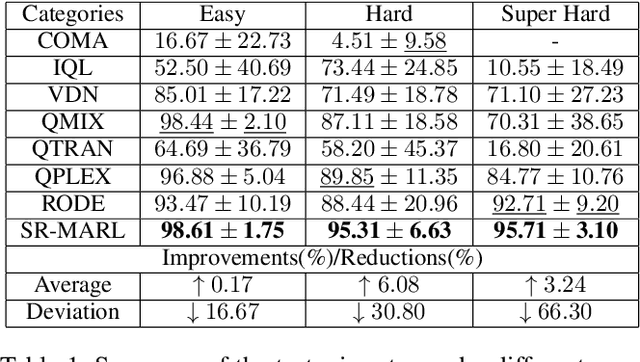
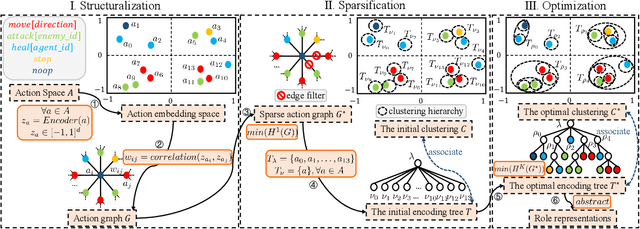
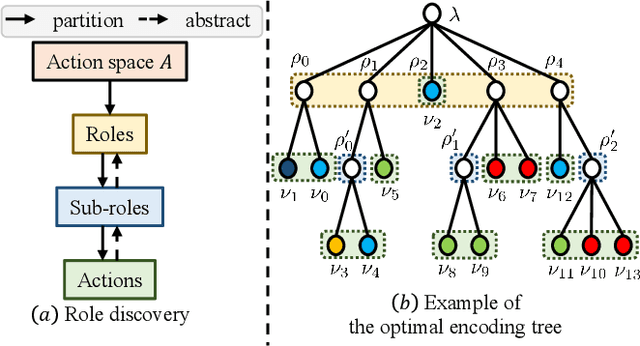
Role-based learning is a promising approach to improving the performance of Multi-Agent Reinforcement Learning (MARL). Nevertheless, without manual assistance, current role-based methods cannot guarantee stably discovering a set of roles to effectively decompose a complex task, as they assume either a predefined role structure or practical experience for selecting hyperparameters. In this article, we propose a mathematical Structural Information principles-based Role Discovery method, namely SIRD, and then present a SIRD optimizing MARL framework, namely SR-MARL, for multi-agent collaboration. The SIRD transforms role discovery into a hierarchical action space clustering. Specifically, the SIRD consists of structuralization, sparsification, and optimization modules, where an optimal encoding tree is generated to perform abstracting to discover roles. The SIRD is agnostic to specific MARL algorithms and flexibly integrated with various value function factorization approaches. Empirical evaluations on the StarCraft II micromanagement benchmark demonstrate that, compared with state-of-the-art MARL algorithms, the SR-MARL framework improves the average test win rate by 0.17%, 6.08%, and 3.24%, and reduces the deviation by 16.67%, 30.80%, and 66.30%, under easy, hard, and super hard scenarios.
Resetting the Optimizer in Deep RL: An Empirical Study
Jun 30, 2023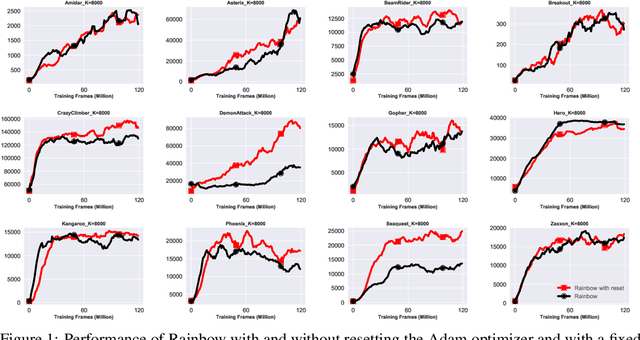
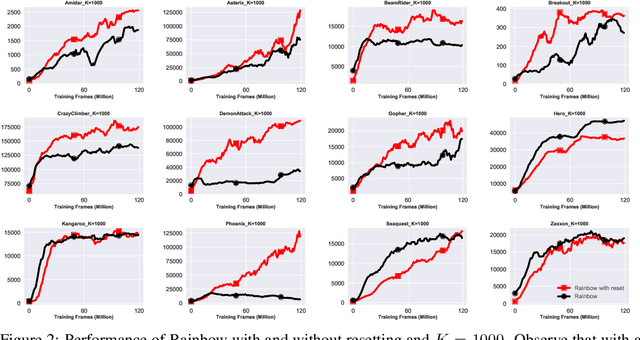
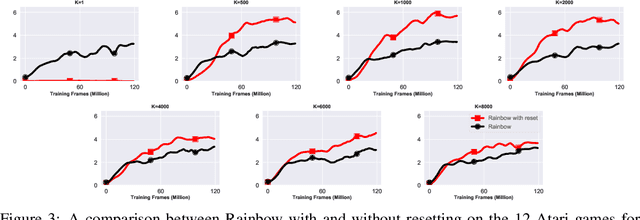
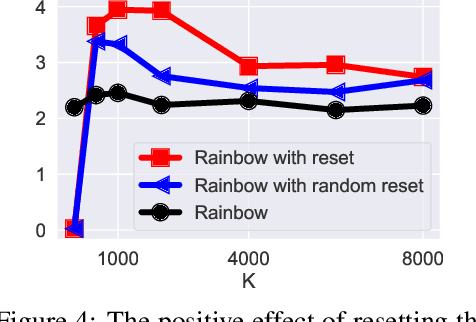
We focus on the task of approximating the optimal value function in deep reinforcement learning. This iterative process is comprised of approximately solving a sequence of optimization problems where the objective function can change per iteration. The common approach to solving the problem is to employ modern variants of the stochastic gradient descent algorithm such as Adam. These optimizers maintain their own internal parameters such as estimates of the first and the second moment of the gradient, and update these parameters over time. Therefore, information obtained in previous iterations is being used to solve the optimization problem in the current iteration. We hypothesize that this can contaminate the internal parameters of the employed optimizer in situations where the optimization landscape of the previous iterations is quite different from the current iteration. To hedge against this effect, a simple idea is to reset the internal parameters of the optimizer when starting a new iteration. We empirically investigate this resetting strategy by employing various optimizers in conjunction with the Rainbow algorithm. We demonstrate that this simple modification unleashes the true potential of modern optimizers, and significantly improves the performance of deep RL on the Atari benchmark.
SummQA at MEDIQA-Chat 2023:In-Context Learning with GPT-4 for Medical Summarization
Jun 30, 2023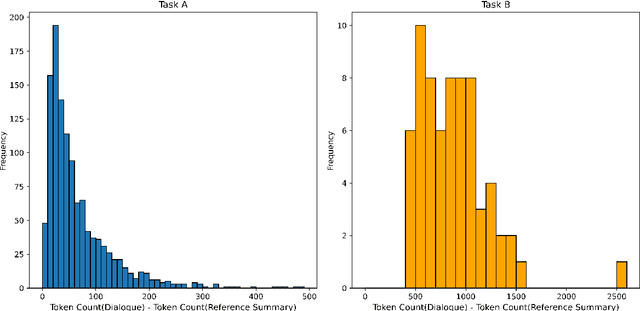
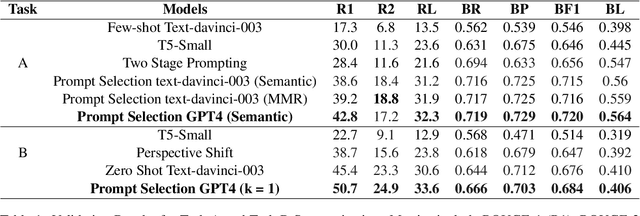
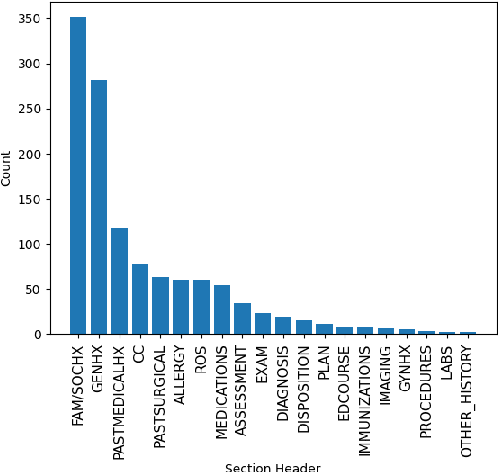

Medical dialogue summarization is challenging due to the unstructured nature of medical conversations, the use of medical terminology in gold summaries, and the need to identify key information across multiple symptom sets. We present a novel system for the Dialogue2Note Medical Summarization tasks in the MEDIQA 2023 Shared Task. Our approach for section-wise summarization (Task A) is a two-stage process of selecting semantically similar dialogues and using the top-k similar dialogues as in-context examples for GPT-4. For full-note summarization (Task B), we use a similar solution with k=1. We achieved 3rd place in Task A (2nd among all teams), 4th place in Task B Division Wise Summarization (2nd among all teams), 15th place in Task A Section Header Classification (9th among all teams), and 8th place among all teams in Task B. Our results highlight the effectiveness of few-shot prompting for this task, though we also identify several weaknesses of prompting-based approaches. We compare GPT-4 performance with several finetuned baselines. We find that GPT-4 summaries are more abstractive and shorter. We make our code publicly available.
Accurate 2D Reconstruction for PET Scanners based on the Analytical White Image Model
Jun 30, 2023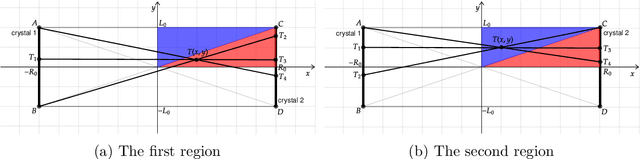

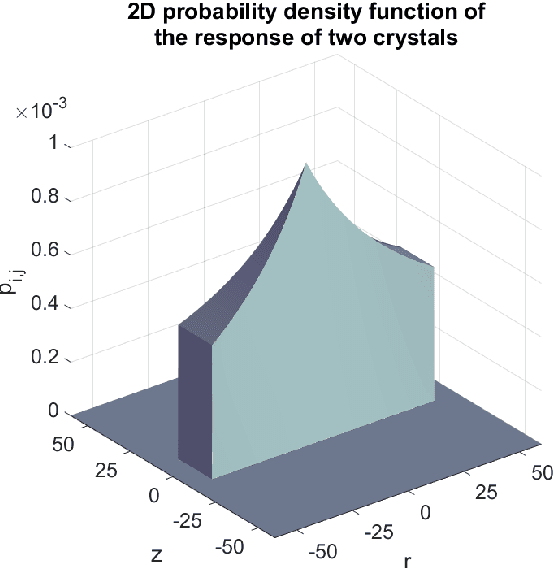
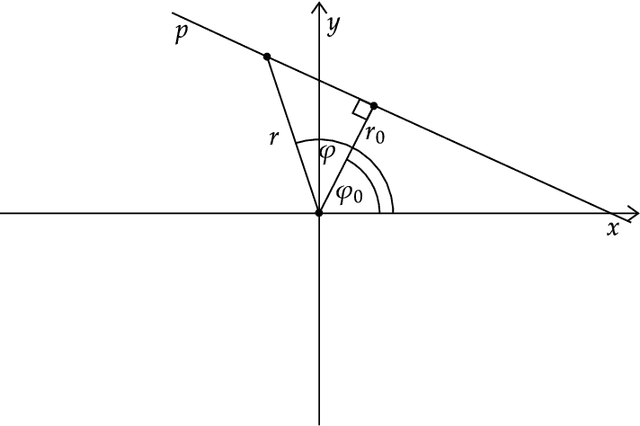
In this paper, we provide a precise mathematical model of crystal-to-crystal response which is used to generate the white image - a necessary compensation model needed to overcome the physical limitations of the PET scanner. We present a closed-form solution, as well as several accurate approximations, due to the complexity of the exact mathematical expressions. We prove, experimentally and analytically, that the difference between the best approximations and real crystal-to-crystal response is insignificant. The obtained responses are used to generate the white image compensation model. It can be written as a single closed-form expression making it easy to implement in known reconstruction methods. The maximum likelihood expectation maximization (MLEM) algorithm is modified and our white image model is integrated into it. The modified MLEM algorithm is not based on the system matrix, rather it is based on ray-driven projections and back-projections. The compensation model provides all necessary information about the system. Finally, we check our approach on synthetic and real data. For the real-world acquisition, we use the Raytest ClearPET camera for small animals and the NEMA NU 4-2008 phantom. The proposed approach overperforms competitive, non-compensated reconstruction methods.
Training-free Object Counting with Prompts
Jun 30, 2023
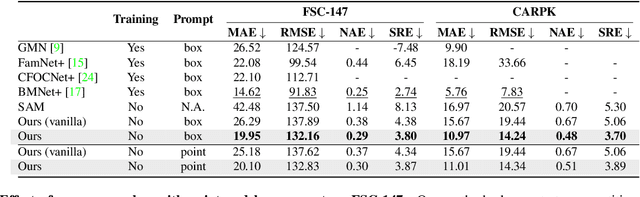

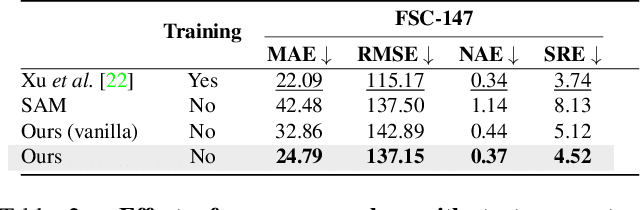
This paper tackles the problem of object counting in images. Existing approaches rely on extensive training data with point annotations for each object, making data collection labor-intensive and time-consuming. To overcome this, we propose a training-free object counter that treats the counting task as a segmentation problem. Our approach leverages the Segment Anything Model (SAM), known for its high-quality masks and zero-shot segmentation capability. However, the vanilla mask generation method of SAM lacks class-specific information in the masks, resulting in inferior counting accuracy. To overcome this limitation, we introduce a prior-guided mask generation method that incorporates three types of priors into the segmentation process, enhancing efficiency and accuracy. Additionally, we tackle the issue of counting objects specified through free-form text by proposing a two-stage approach that combines reference object selection and prior-guided mask generation. Extensive experiments on standard datasets demonstrate the competitive performance of our training-free counter compared to learning-based approaches. This paper presents a promising solution for counting objects in various scenarios without the need for extensive data collection and model training. Code is available at https://github.com/shizenglin/training-free-object-counter.
Comparing Algorithm Selection Approaches on Black-Box Optimization Problems
Jun 30, 2023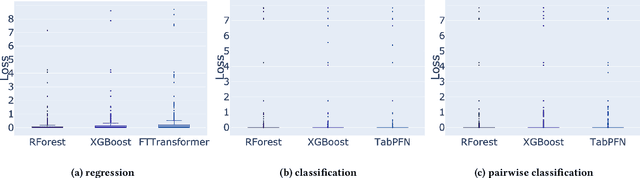
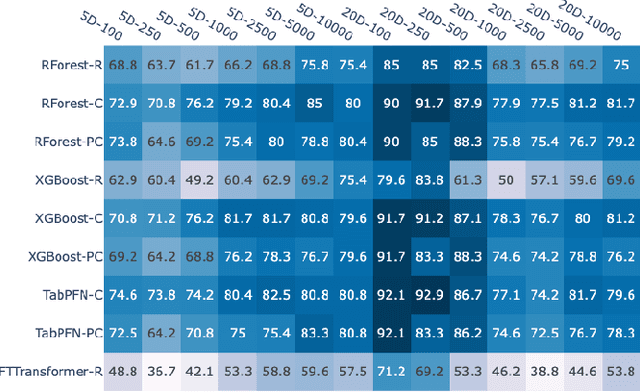
Performance complementarity of solvers available to tackle black-box optimization problems gives rise to the important task of algorithm selection (AS). Automated AS approaches can help replace tedious and labor-intensive manual selection, and have already shown promising performance in various optimization domains. Automated AS relies on machine learning (ML) techniques to recommend the best algorithm given the information about the problem instance. Unfortunately, there are no clear guidelines for choosing the most appropriate one from a variety of ML techniques. Tree-based models such as Random Forest or XGBoost have consistently demonstrated outstanding performance for automated AS. Transformers and other tabular deep learning models have also been increasingly applied in this context. We investigate in this work the impact of the choice of the ML technique on AS performance. We compare four ML models on the task of predicting the best solver for the BBOB problems for 7 different runtime budgets in 2 dimensions. While our results confirm that a per-instance AS has indeed impressive potential, we also show that the particular choice of the ML technique is of much minor importance.
AI and Non AI Assessments for Dementia
Jun 30, 2023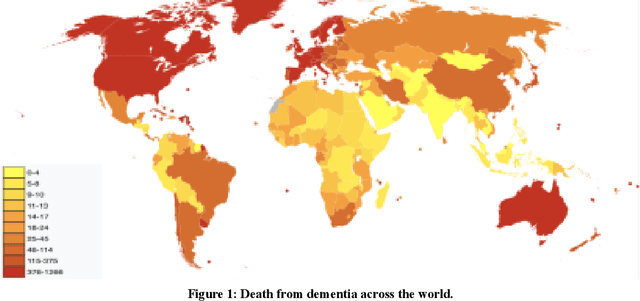
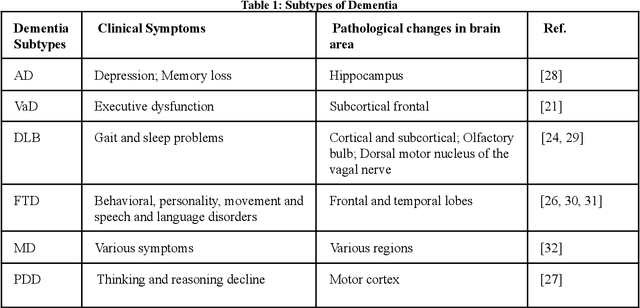
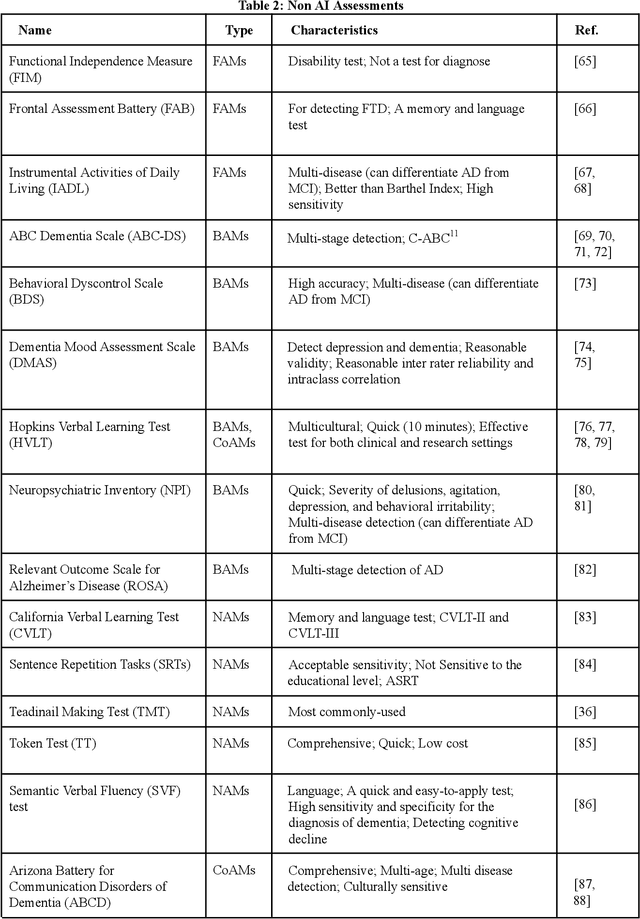

Current progress in the artificial intelligence domain has led to the development of various types of AI-powered dementia assessments, which can be employed to identify patients at the early stage of dementia. It can revolutionize the dementia care settings. It is essential that the medical community be aware of various AI assessments and choose them considering their degrees of validity, efficiency, practicality, reliability, and accuracy concerning the early identification of patients with dementia (PwD). On the other hand, AI developers should be informed about various non-AI assessments as well as recently developed AI assessments. Thus, this paper, which can be readable by both clinicians and AI engineers, fills the gap in the literature in explaining the existing solutions for the recognition of dementia to clinicians, as well as the techniques used and the most widespread dementia datasets to AI engineers. It follows a review of papers on AI and non-AI assessments for dementia to provide valuable information about various dementia assessments for both the AI and medical communities. The discussion and conclusion highlight the most prominent research directions and the maturity of existing solutions.
Enhancing Feature Extraction for Indoor Fingerprint Localization Using Diversified Data
Jun 30, 2023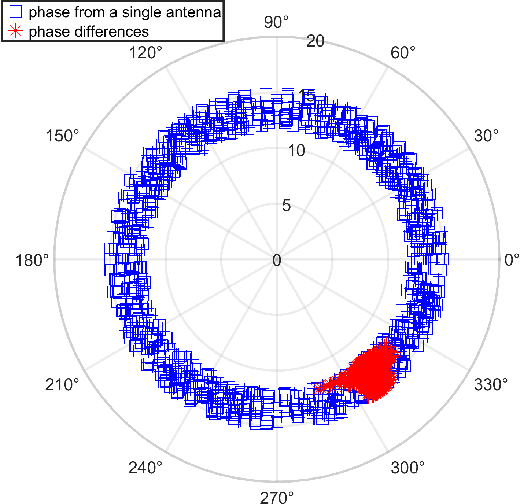
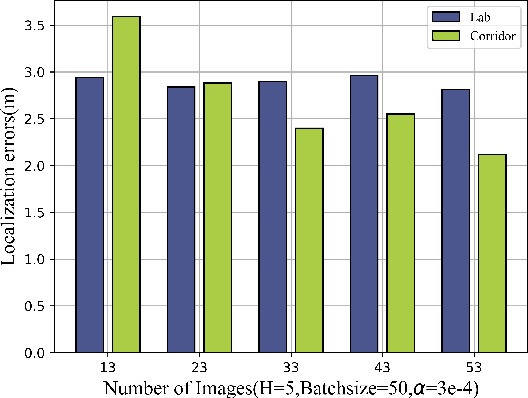
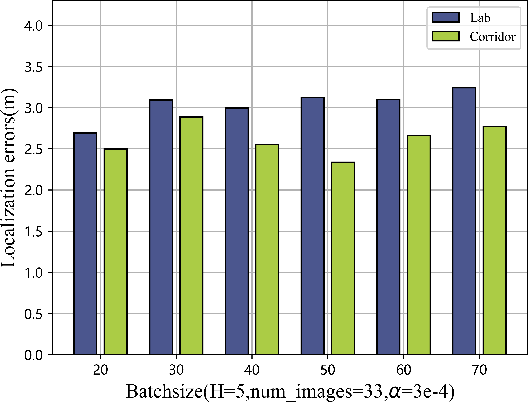
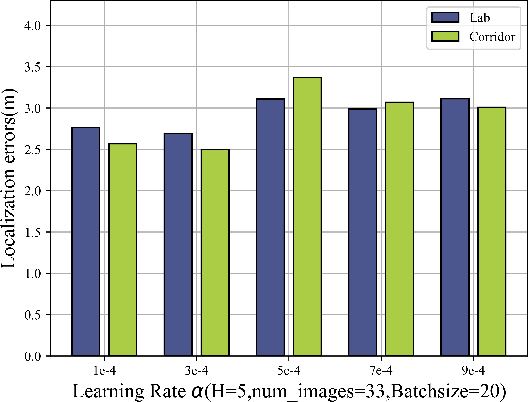
Given the rapid advancements in wireless communication and terminal devices, high-speed and convenient WiFi has permeated various aspects of people's lives, and attention has been drawn to the location services that WiFi can provide. Fingerprint-based methods, as an excellent approach for localization, have gradually become a hot research topic. However, in practical localization, fingerprint features of traditional methods suffer from low reliability and lacking robustness in complex indoor environments. To overcome these limitations, this paper proposes a innovative feature extraction-enhanced intelligent localization scheme named Secci, based on diversified channel state information (CSI). By modifying the device driver, diversified CSI data are extracted and transformed into RGB CSI images, which serve as input to a deep convolutional neural network (DCNN) with SE attention mechanism-assisted training in the offline stage. Employing a greedy probabilistic approach, rapid prediction of the estimated location is performed in the online stage using test RGB CSI images. The Secci system is implemented using off-the-shelf WiFi devices, and comprehensive experiments are carried out in two representative indoor environments to showcase the superior performance of Secci compared to four existing algorithms.
The Effect of Balancing Methods on Model Behavior in Imbalanced Classification Problems
Jun 30, 2023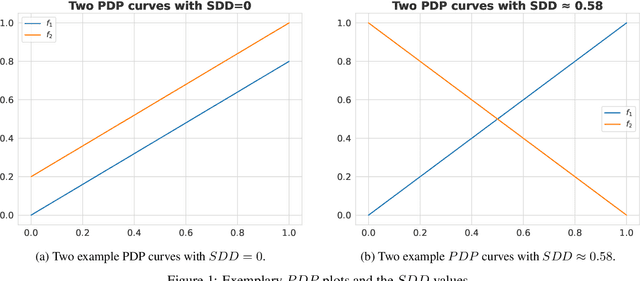
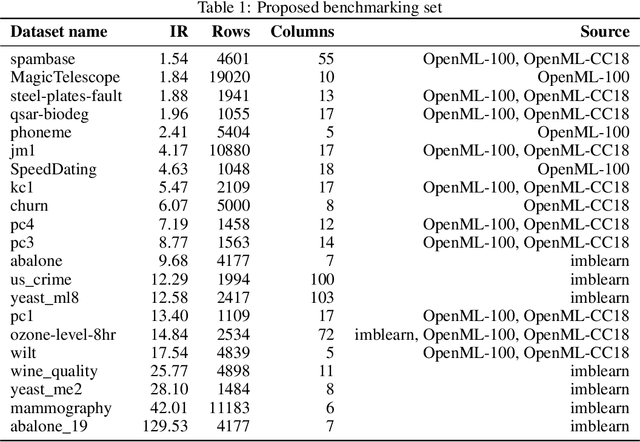

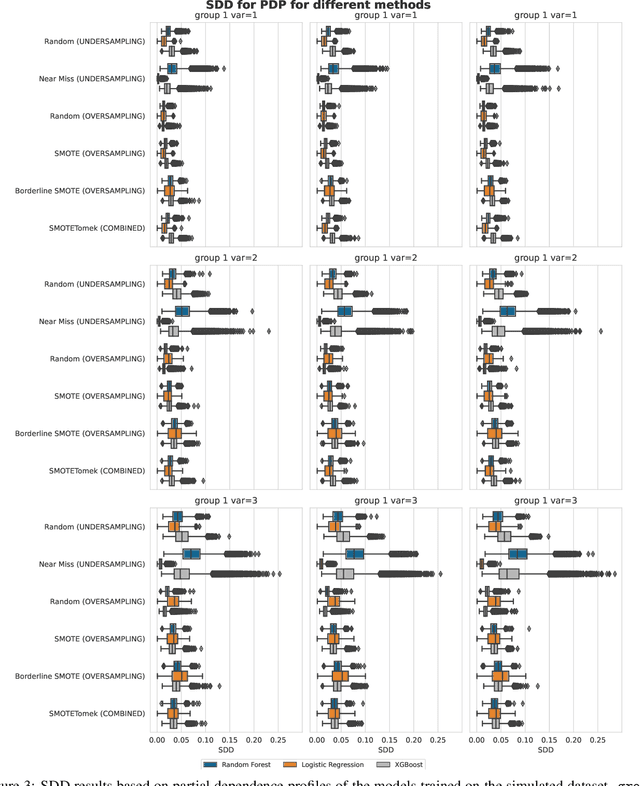
Imbalanced data poses a significant challenge in classification as model performance is affected by insufficient learning from minority classes. Balancing methods are often used to address this problem. However, such techniques can lead to problems such as overfitting or loss of information. This study addresses a more challenging aspect of balancing methods - their impact on model behavior. To capture these changes, Explainable Artificial Intelligence tools are used to compare models trained on datasets before and after balancing. In addition to the variable importance method, this study uses the partial dependence profile and accumulated local effects techniques. Real and simulated datasets are tested, and an open-source Python package edgaro is developed to facilitate this analysis. The results obtained show significant changes in model behavior due to balancing methods, which can lead to biased models toward a balanced distribution. These findings confirm that balancing analysis should go beyond model performance comparisons to achieve higher reliability of machine learning models. Therefore, we propose a new method performance gain plot for informed data balancing strategy to make an optimal selection of balancing method by analyzing the measure of change in model behavior versus performance gain.
RECAP-KG: Mining Knowledge Graphs from Raw GP Notes for Remote COVID-19 Assessment in Primary Care
Jun 17, 2023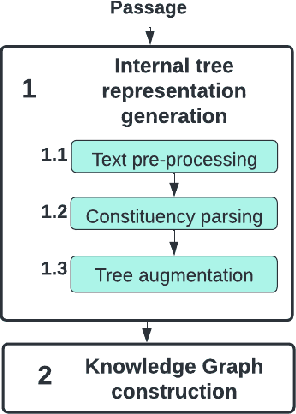

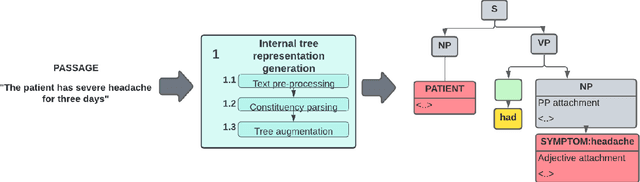
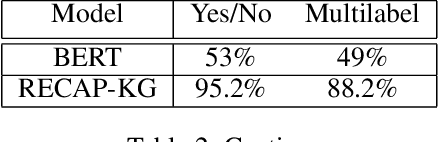
Clinical decision-making is a fundamental stage in delivering appropriate care to patients. In recent years several decision-making systems designed to aid the clinician in this process have been developed. However, technical solutions currently in use are based on simple regression models and are only able to take into account simple pre-defined multiple-choice features, such as patient age, pre-existing conditions, smoker status, etc. One particular source of patient data, that available decision-making systems are incapable of processing is the collection of patient consultation GP notes. These contain crucial signs and symptoms - the information used by clinicians in order to make a final decision and direct the patient to the appropriate care. Extracting information from GP notes is a technically challenging problem, as they tend to include abbreviations, typos, and incomplete sentences. This paper addresses this open challenge. We present a framework that performs knowledge graph construction from raw GP medical notes written during or after patient consultations. By relying on support phrases mined from the SNOMED ontology, as well as predefined supported facts from values used in the RECAP (REmote COVID-19 Assessment in Primary Care) patient risk prediction tool, our graph generative framework is able to extract structured knowledge graphs from the highly unstructured and inconsistent format that consultation notes are written in. Our knowledge graphs include information about existing patient symptoms, their duration, and their severity. We apply our framework to consultation notes of COVID-19 patients in the UK COVID-19 Clinical Assesment Servcie (CCAS) patient dataset. We provide a quantitative evaluation of the performance of our framework, demonstrating that our approach has better accuracy than traditional NLP methods when answering questions about patients.