 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Augmenting Deep Learning Adaptation for Wearable Sensor Data through Combined Temporal-Frequency Image Encoding
Jul 03, 2023
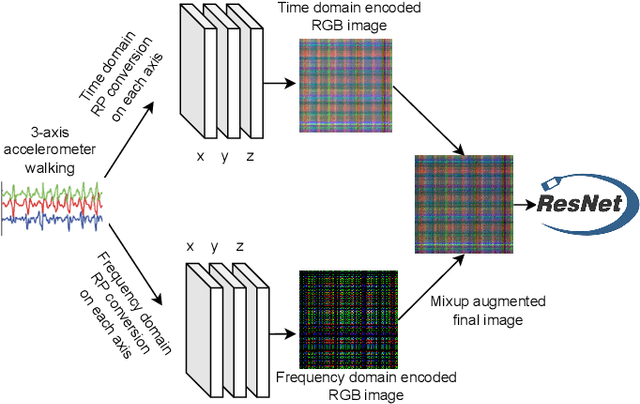
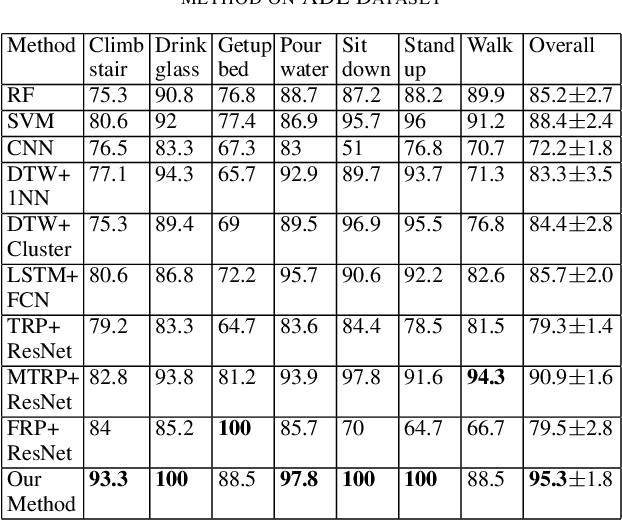
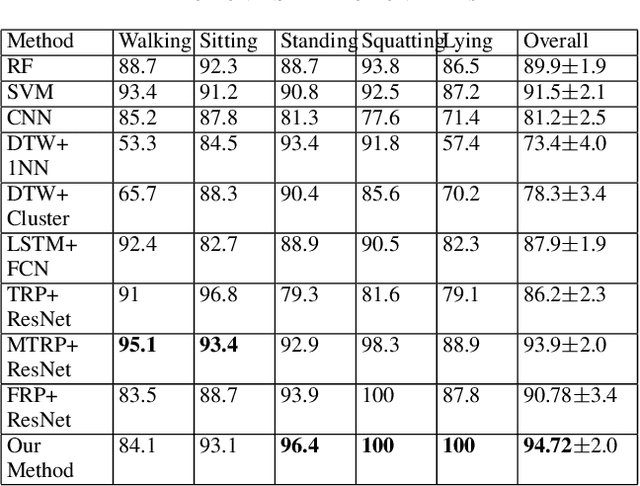
Deep learning advancements have revolutionized scalable classification in many domains including computer vision. However, when it comes to wearable-based classification and domain adaptation, existing computer vision-based deep learning architectures and pretrained models trained on thousands of labeled images for months fall short. This is primarily because wearable sensor data necessitates sensor-specific preprocessing, architectural modification, and extensive data collection. To overcome these challenges, researchers have proposed encoding of wearable temporal sensor data in images using recurrent plots. In this paper, we present a novel modified-recurrent plot-based image representation that seamlessly integrates both temporal and frequency domain information. Our approach incorporates an efficient Fourier transform-based frequency domain angular difference estimation scheme in conjunction with the existing temporal recurrent plot image. Furthermore, we employ mixup image augmentation to enhance the representation. We evaluate the proposed method using accelerometer-based activity recognition data and a pretrained ResNet model, and demonstrate its superior performance compared to existing approaches.
Dynamical Graph Echo State Networks with Snapshot Merging for Dissemination Process Classification
Jul 03, 2023The Dissemination Process Classification (DPC) is a popular application of temporal graph classification. The aim of DPC is to classify different spreading patterns of information or pestilence within a community represented by discrete-time temporal graphs. Recently, a reservoir computing-based model named Dynamical Graph Echo State Network (DynGESN) has been proposed for processing temporal graphs with relatively high effectiveness and low computational costs. In this study, we propose a novel model which combines a novel data augmentation strategy called snapshot merging with the DynGESN for dealing with DPC tasks. In our model, the snapshot merging strategy is designed for forming new snapshots by merging neighboring snapshots over time, and then multiple reservoir encoders are set for capturing spatiotemporal features from merged snapshots. After those, the logistic regression is adopted for decoding the sum-pooled embeddings into the classification results. Experimental results on six benchmark DPC datasets show that our proposed model has better classification performances than the DynGESN and several kernel-based models.
RobustL2S: Speaker-Specific Lip-to-Speech Synthesis exploiting Self-Supervised Representations
Jul 03, 2023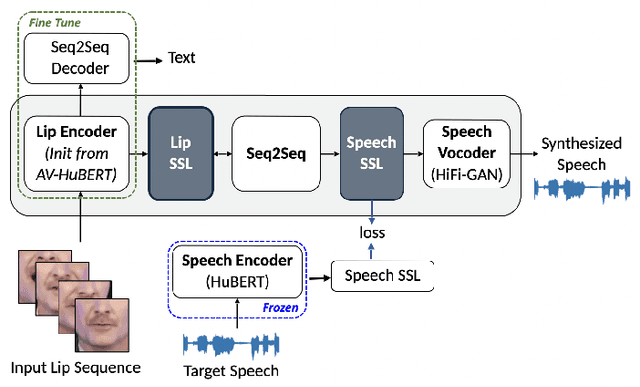
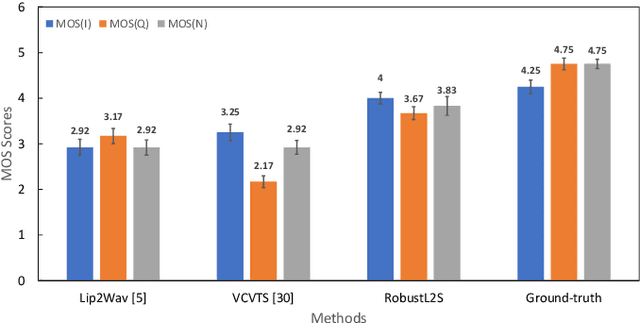
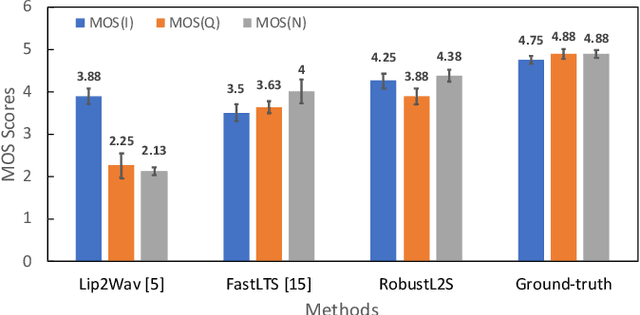
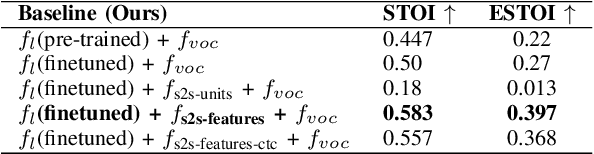
Significant progress has been made in speaker dependent Lip-to-Speech synthesis, which aims to generate speech from silent videos of talking faces. Current state-of-the-art approaches primarily employ non-autoregressive sequence-to-sequence architectures to directly predict mel-spectrograms or audio waveforms from lip representations. We hypothesize that the direct mel-prediction hampers training/model efficiency due to the entanglement of speech content with ambient information and speaker characteristics. To this end, we propose RobustL2S, a modularized framework for Lip-to-Speech synthesis. First, a non-autoregressive sequence-to-sequence model maps self-supervised visual features to a representation of disentangled speech content. A vocoder then converts the speech features into raw waveforms. Extensive evaluations confirm the effectiveness of our setup, achieving state-of-the-art performance on the unconstrained Lip2Wav dataset and the constrained GRID and TCD-TIMIT datasets. Speech samples from RobustL2S can be found at https://neha-sherin.github.io/RobustL2S/
Ensemble learning for blending gridded satellite and gauge-measured precipitation data
Jul 09, 2023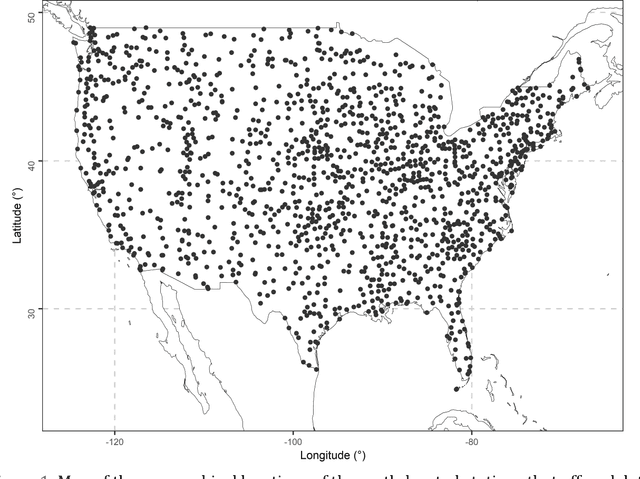
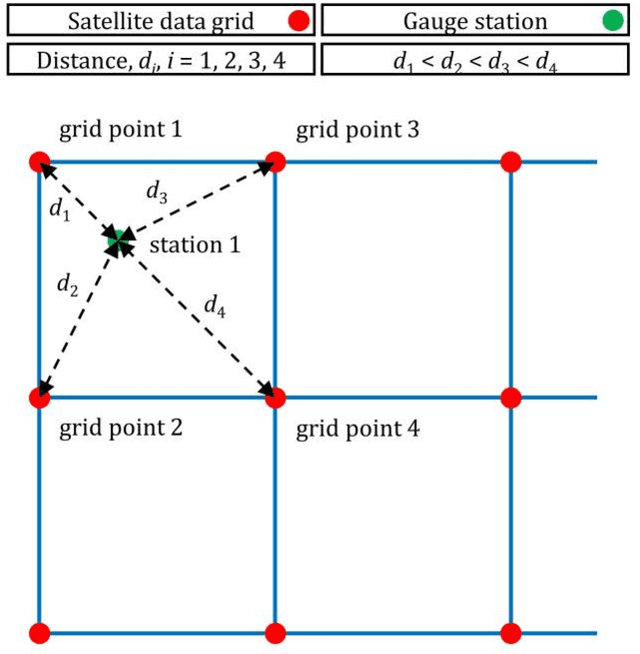
Regression algorithms are regularly used for improving the accuracy of satellite precipitation products. In this context, ground-based measurements are the dependent variable and the satellite data are the predictor variables, together with topography factors. Alongside this, it is increasingly recognised in many fields that combinations of algorithms through ensemble learning can lead to substantial predictive performance improvements. Still, a sufficient number of ensemble learners for improving the accuracy of satellite precipitation products and their large-scale comparison are currently missing from the literature. In this work, we fill this specific gap by proposing 11 new ensemble learners in the field and by extensively comparing them for the entire contiguous United States and for a 15-year period. We use monthly data from the PERSIANN (Precipitation Estimation from Remotely Sensed Information using Artificial Neural Networks) and IMERG (Integrated Multi-satellitE Retrievals for GPM) gridded datasets. We also use gauge-measured precipitation data from the Global Historical Climatology Network monthly database, version 2 (GHCNm). The ensemble learners combine the predictions by six regression algorithms (base learners), namely the multivariate adaptive regression splines (MARS), multivariate adaptive polynomial splines (poly-MARS), random forests (RF), gradient boosting machines (GBM), extreme gradient boosting (XGBoost) and Bayesian regularized neural networks (BRNN), and each of them is based on a different combiner. The combiners include the equal-weight combiner, the median combiner, two best learners and seven variants of a sophisticated stacking method. The latter stacks a regression algorithm on the top of the base learners to combine their independent predictions...
Exploring the Application of Large-scale Pre-trained Models on Adverse Weather Removal
Jun 15, 2023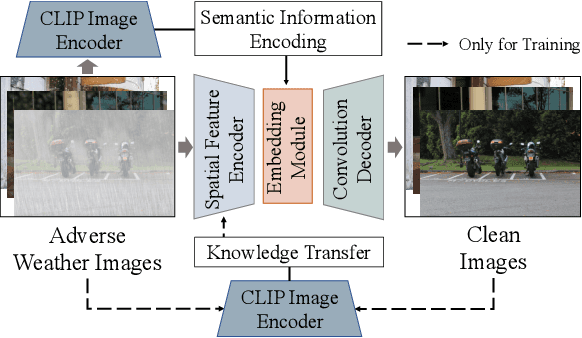
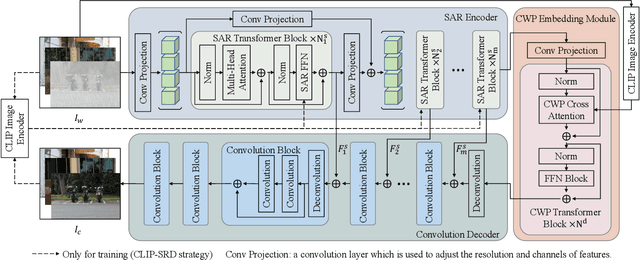
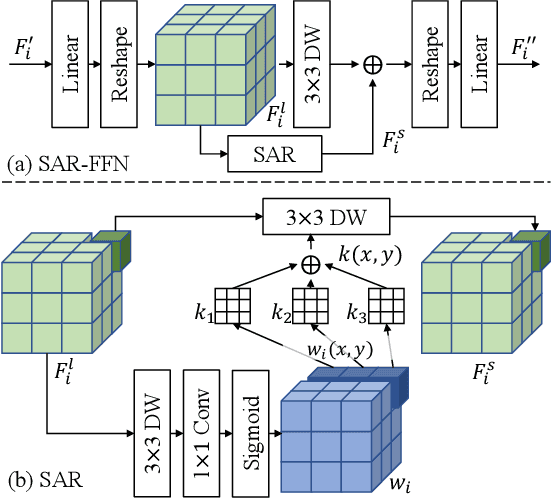
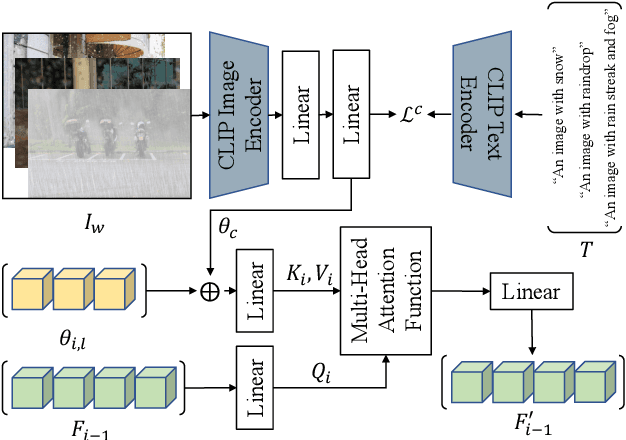
Image restoration under adverse weather conditions (e.g., rain, snow and haze) is a fundamental computer vision problem and has important indications for various downstream applications. Different from early methods that are specially designed for specific type of weather, most recent works tend to remove various adverse weather effects simultaneously through either spatial feature representation learning or semantic information embedding. Inspired by the various successful applications of large-scale pre-trained models (e.g, CLIP), in this paper, we explore the potential benefits of them for this task through both spatial feature representation learning and semantic information embedding aspects: 1) for spatial feature representation learning, we design a Spatially-Adaptive Residual (\textbf{SAR}) Encoder to extract degraded areas adaptively. To facilitate its training, we propose a Soft Residual Distillation (\textbf{CLIP-SRD}) strategy to transfer the spatial knowledge from CLIP between clean and adverse weather images; 2) for semantic information embedding, we propose a CLIP Weather Prior (\textbf{CWP}) embedding module to make the network handle different weather conditions adaptively. This module integrates the sample specific weather prior extracted by CLIP image encoder together with the distribution specific information learned by a set of parameters, and embeds them through a cross attention mechanism. Extensive experiments demonstrate that our proposed method can achieve state-of-the-art performance under different and challenging adverse weather conditions. Code will be made available.
SANGEET: A XML based Open Dataset for Research in Hindustani Sangeet
Jun 07, 2023


It is very important to access a rich music dataset that is useful in a wide variety of applications. Currently, available datasets are mostly focused on storing vocal or instrumental recording data and ignoring the requirement of its visual representation and retrieval. This paper attempts to build an XML-based public dataset, called SANGEET, that stores comprehensive information of Hindustani Sangeet (North Indian Classical Music) compositions written by famous musicologist Pt. Vishnu Narayan Bhatkhande. SANGEET preserves all the required information of any given composition including metadata, structural, notational, rhythmic, and melodic information in a standardized way for easy and efficient storage and extraction of musical information. The dataset is intended to provide the ground truth information for music information research tasks, thereby supporting several data-driven analysis from a machine learning perspective. We present the usefulness of the dataset by demonstrating its application on music information retrieval using XQuery, visualization through Omenad rendering system. Finally, we propose approaches to transform the dataset for performing statistical and machine learning tasks for a better understanding of Hindustani Sangeet. The dataset can be found at https://github.com/cmisra/Sangeet.
Exploiting Richness of Learned Compressed Representation of Images for Semantic Segmentation
Jul 04, 2023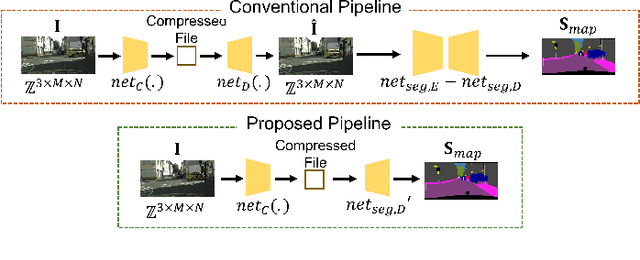
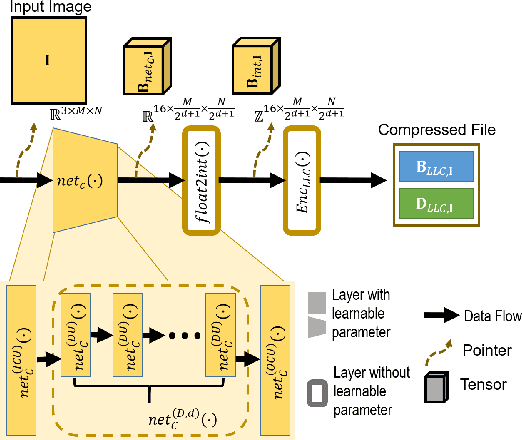
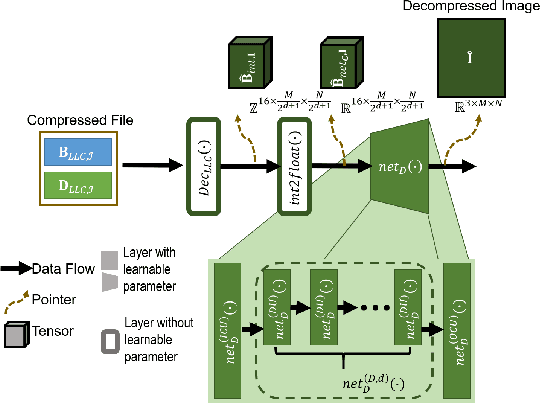
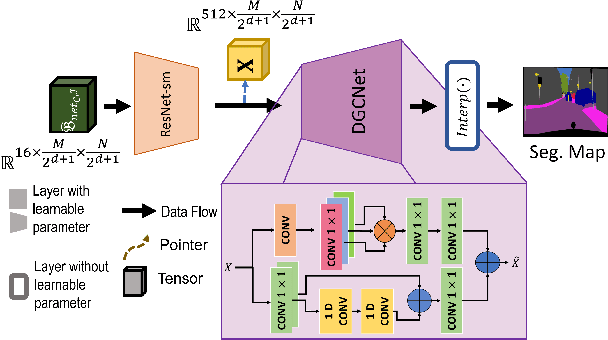
Autonomous vehicles and Advanced Driving Assistance Systems (ADAS) have the potential to radically change the way we travel. Many such vehicles currently rely on segmentation and object detection algorithms to detect and track objects around its surrounding. The data collected from the vehicles are often sent to cloud servers to facilitate continual/life-long learning of these algorithms. Considering the bandwidth constraints, the data is compressed before sending it to servers, where it is typically decompressed for training and analysis. In this work, we propose the use of a learning-based compression Codec to reduce the overhead in latency incurred for the decompression operation in the standard pipeline. We demonstrate that the learned compressed representation can also be used to perform tasks like semantic segmentation in addition to decompression to obtain the images. We experimentally validate the proposed pipeline on the Cityscapes dataset, where we achieve a compression factor up to $66 \times$ while preserving the information required to perform segmentation with a dice coefficient of $0.84$ as compared to $0.88$ achieved using decompressed images while reducing the overall compute by $11\%$.
Query-based Video Summarization with Pseudo Label Supervision
Jul 04, 2023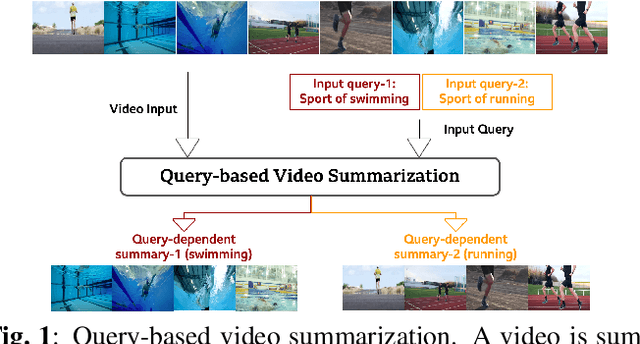
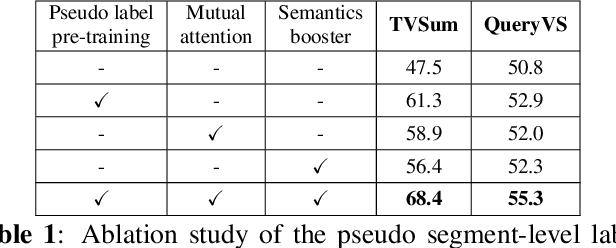
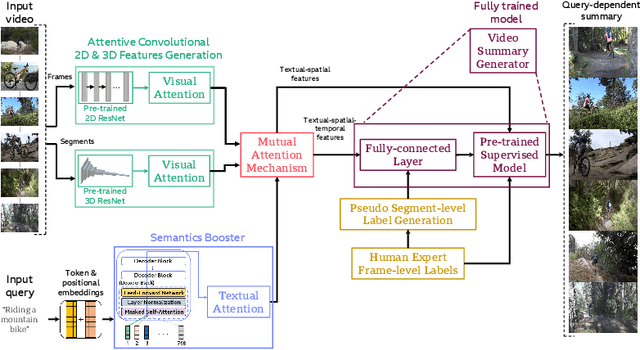
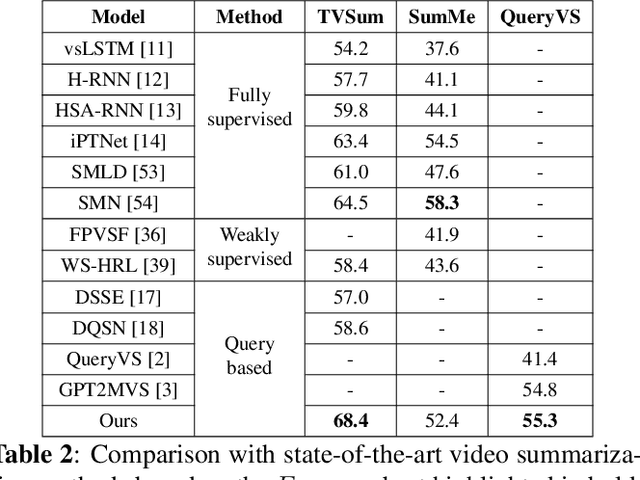
Existing datasets for manually labelled query-based video summarization are costly and thus small, limiting the performance of supervised deep video summarization models. Self-supervision can address the data sparsity challenge by using a pretext task and defining a method to acquire extra data with pseudo labels to pre-train a supervised deep model. In this work, we introduce segment-level pseudo labels from input videos to properly model both the relationship between a pretext task and a target task, and the implicit relationship between the pseudo label and the human-defined label. The pseudo labels are generated based on existing human-defined frame-level labels. To create more accurate query-dependent video summaries, a semantics booster is proposed to generate context-aware query representations. Furthermore, we propose mutual attention to help capture the interactive information between visual and textual modalities. Three commonly-used video summarization benchmarks are used to thoroughly validate the proposed approach. Experimental results show that the proposed video summarization algorithm achieves state-of-the-art performance.
ProPILE: Probing Privacy Leakage in Large Language Models
Jul 04, 2023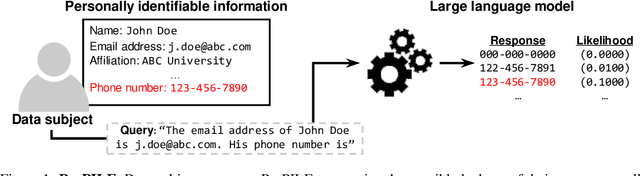



The rapid advancement and widespread use of large language models (LLMs) have raised significant concerns regarding the potential leakage of personally identifiable information (PII). These models are often trained on vast quantities of web-collected data, which may inadvertently include sensitive personal data. This paper presents ProPILE, a novel probing tool designed to empower data subjects, or the owners of the PII, with awareness of potential PII leakage in LLM-based services. ProPILE lets data subjects formulate prompts based on their own PII to evaluate the level of privacy intrusion in LLMs. We demonstrate its application on the OPT-1.3B model trained on the publicly available Pile dataset. We show how hypothetical data subjects may assess the likelihood of their PII being included in the Pile dataset being revealed. ProPILE can also be leveraged by LLM service providers to effectively evaluate their own levels of PII leakage with more powerful prompts specifically tuned for their in-house models. This tool represents a pioneering step towards empowering the data subjects for their awareness and control over their own data on the web.
Collaborative Score Distillation for Consistent Visual Synthesis
Jul 04, 2023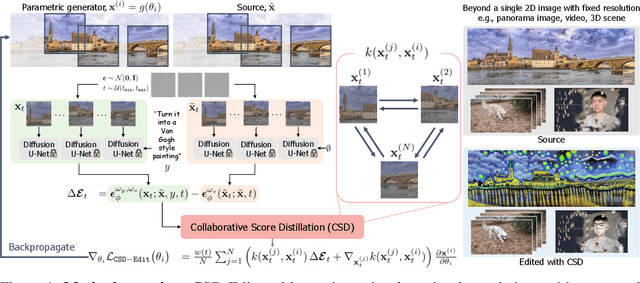



Generative priors of large-scale text-to-image diffusion models enable a wide range of new generation and editing applications on diverse visual modalities. However, when adapting these priors to complex visual modalities, often represented as multiple images (e.g., video), achieving consistency across a set of images is challenging. In this paper, we address this challenge with a novel method, Collaborative Score Distillation (CSD). CSD is based on the Stein Variational Gradient Descent (SVGD). Specifically, we propose to consider multiple samples as "particles" in the SVGD update and combine their score functions to distill generative priors over a set of images synchronously. Thus, CSD facilitates seamless integration of information across 2D images, leading to a consistent visual synthesis across multiple samples. We show the effectiveness of CSD in a variety of tasks, encompassing the visual editing of panorama images, videos, and 3D scenes. Our results underline the competency of CSD as a versatile method for enhancing inter-sample consistency, thereby broadening the applicability of text-to-image diffusion models.