 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SHAMSUL: Simultaneous Heatmap-Analysis to investigate Medical Significance Utilizing Local interpretability methods
Jul 16, 2023
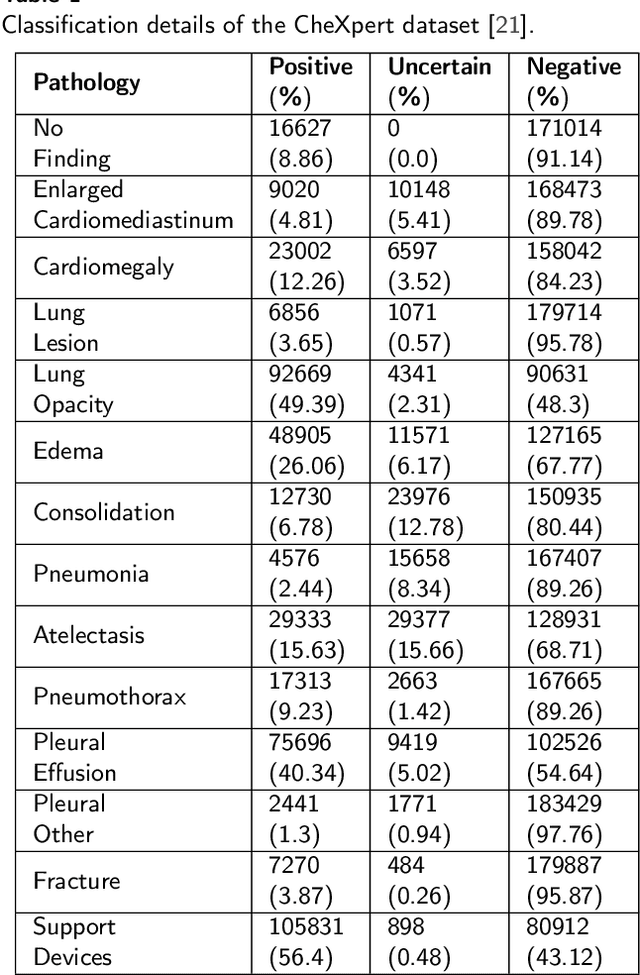
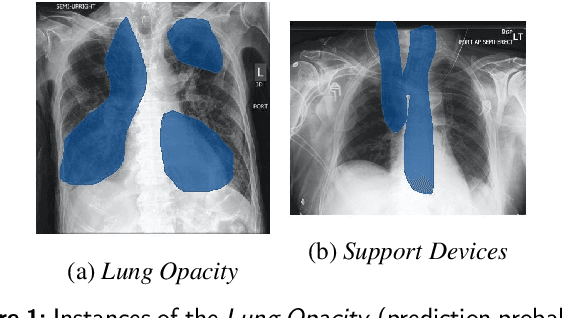
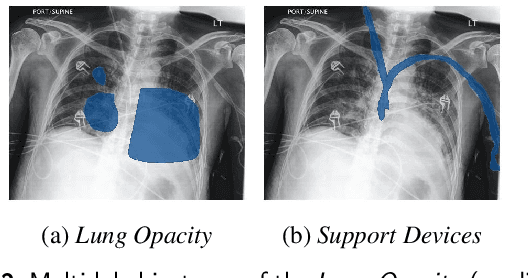
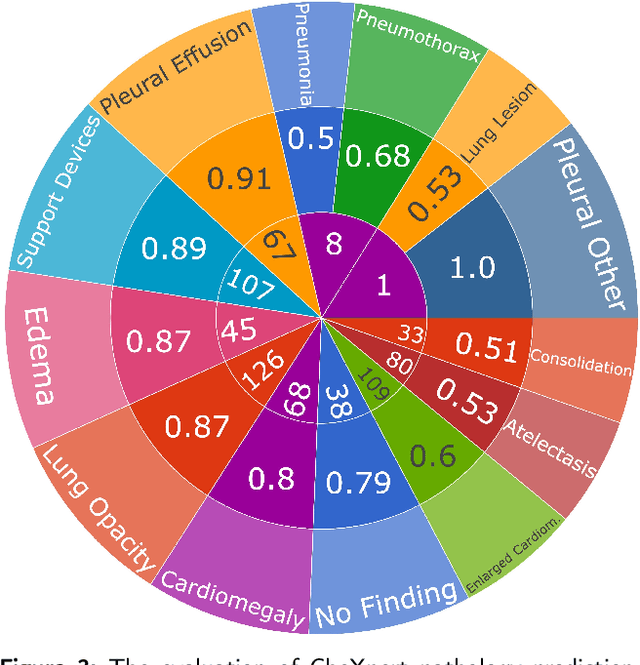
The interpretability of deep neural networks has become a subject of great interest within the medical and healthcare domain. This attention stems from concerns regarding transparency, legal and ethical considerations, and the medical significance of predictions generated by these deep neural networks in clinical decision support systems. To address this matter, our study delves into the application of four well-established interpretability methods: Local Interpretable Model-agnostic Explanations (LIME), Shapley Additive exPlanations (SHAP), Gradient-weighted Class Activation Mapping (Grad-CAM), and Layer-wise Relevance Propagation (LRP). Leveraging the approach of transfer learning with a multi-label-multi-class chest radiography dataset, we aim to interpret predictions pertaining to specific pathology classes. Our analysis encompasses both single-label and multi-label predictions, providing a comprehensive and unbiased assessment through quantitative and qualitative investigations, which are compared against human expert annotation. Notably, Grad-CAM demonstrates the most favorable performance in quantitative evaluation, while the LIME heatmap segmentation visualization exhibits the highest level of medical significance. Our research highlights the strengths and limitations of these interpretability methods and suggests that a multimodal-based approach, incorporating diverse sources of information beyond chest radiography images, could offer additional insights for enhancing interpretability in the medical domain.
Untrained neural network embedded Fourier phase retrieval from few measurements
Jul 16, 2023Fourier phase retrieval (FPR) is a challenging task widely used in various applications. It involves recovering an unknown signal from its Fourier phaseless measurements. FPR with few measurements is important for reducing time and hardware costs, but it suffers from serious ill-posedness. Recently, untrained neural networks have offered new approaches by introducing learned priors to alleviate the ill-posedness without requiring any external data. However, they may not be ideal for reconstructing fine details in images and can be computationally expensive. This paper proposes an untrained neural network (NN) embedded algorithm based on the alternating direction method of multipliers (ADMM) framework to solve FPR with few measurements. Specifically, we use a generative network to represent the image to be recovered, which confines the image to the space defined by the network structure. To improve the ability to represent high-frequency information, total variation (TV) regularization is imposed to facilitate the recovery of local structures in the image. Furthermore, to reduce the computational cost mainly caused by the parameter updates of the untrained NN, we develop an accelerated algorithm that adaptively trades off between explicit and implicit regularization. Experimental results indicate that the proposed algorithm outperforms existing untrained NN-based algorithms with fewer computational resources and even performs competitively against trained NN-based algorithms.
Generative Language Models on Nucleotide Sequences of Human Genes
Jul 20, 2023Language models, primarily transformer-based ones, obtained colossal success in NLP. To be more precise, studies like BERT in NLU and works such as GPT-3 for NLG are very crucial. DNA sequences are very close to natural language in terms of structure, so if the DNA-related bioinformatics domain is concerned, discriminative models, like DNABert, exist. Yet, the generative side of the coin is mainly unexplored to the best of our knowledge. Consequently, we focused on developing an autoregressive generative language model like GPT-3 for DNA sequences. Because working with whole DNA sequences is challenging without substantial computational resources, we decided to carry out our study on a smaller scale, focusing on nucleotide sequences of human genes, unique parts in DNA with specific functionalities, instead of the whole DNA. This decision did not change the problem structure a lot due to the fact that both DNA and genes can be seen as 1D sequences consisting of four different nucleotides without losing much information and making too much simplification. First of all, we systematically examined an almost entirely unexplored problem and observed that RNNs performed the best while simple techniques like N-grams were also promising. Another beneficial point was learning how to work with generative models on languages we do not understand, unlike natural language. How essential using real-life tasks beyond the classical metrics such as perplexity is observed. Furthermore, checking whether the data-hungry nature of these models can be changed through selecting a language with minimal vocabulary size, four owing to four different types of nucleotides, is examined. The reason for reviewing this was that choosing such a language might make the problem easier. However, what we observed in this study was it did not provide that much of a change in the amount of data needed.
Modeling Entities as Semantic Points for Visual Information Extraction in the Wild
Mar 23, 2023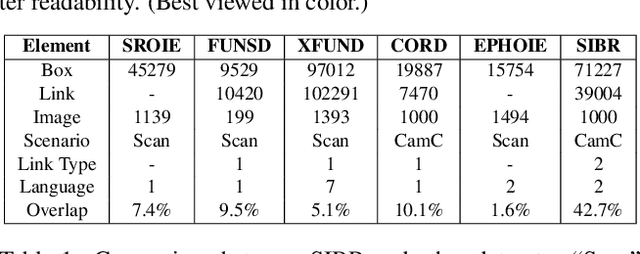
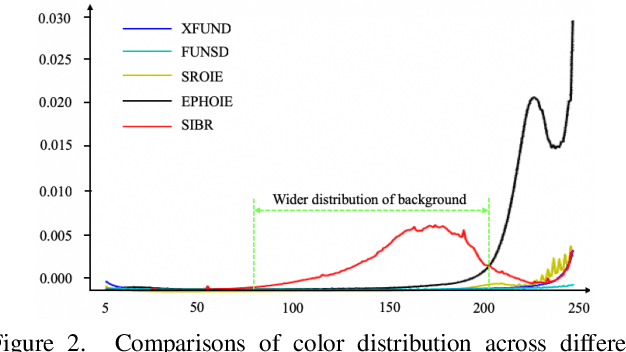
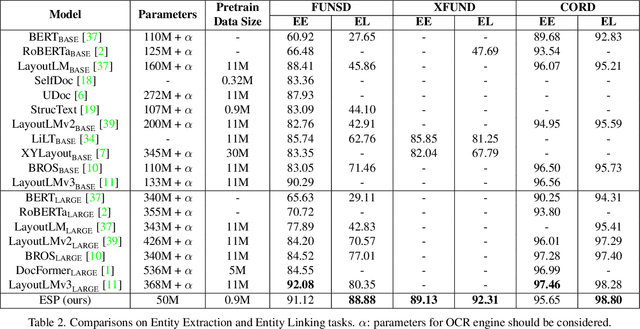
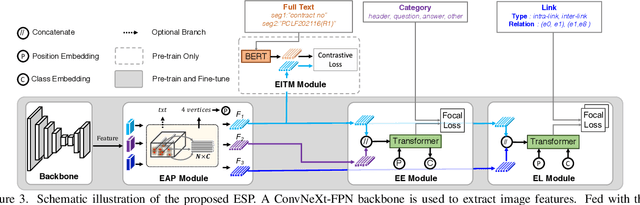
Recently, Visual Information Extraction (VIE) has been becoming increasingly important in both the academia and industry, due to the wide range of real-world applications. Previously, numerous works have been proposed to tackle this problem. However, the benchmarks used to assess these methods are relatively plain, i.e., scenarios with real-world complexity are not fully represented in these benchmarks. As the first contribution of this work, we curate and release a new dataset for VIE, in which the document images are much more challenging in that they are taken from real applications, and difficulties such as blur, partial occlusion, and printing shift are quite common. All these factors may lead to failures in information extraction. Therefore, as the second contribution, we explore an alternative approach to precisely and robustly extract key information from document images under such tough conditions. Specifically, in contrast to previous methods, which usually either incorporate visual information into a multi-modal architecture or train text spotting and information extraction in an end-to-end fashion, we explicitly model entities as semantic points, i.e., center points of entities are enriched with semantic information describing the attributes and relationships of different entities, which could largely benefit entity labeling and linking. Extensive experiments on standard benchmarks in this field as well as the proposed dataset demonstrate that the proposed method can achieve significantly enhanced performance on entity labeling and linking, compared with previous state-of-the-art models. Dataset is available at https://www.modelscope.cn/datasets/damo/SIBR/summary.
On the tightness of information-theoretic bounds on generalization error of learning algorithms
Mar 26, 2023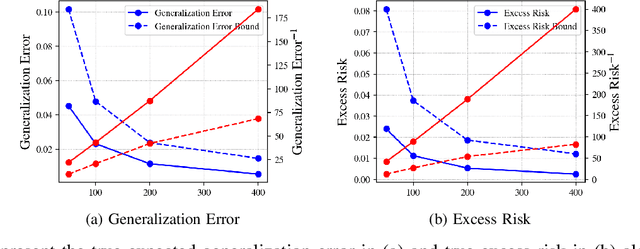

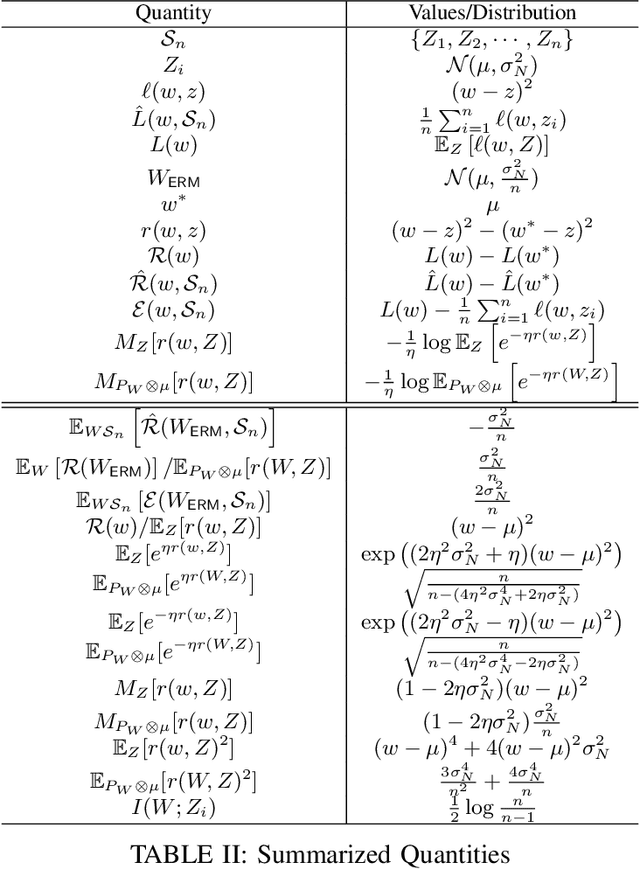
A recent line of works, initiated by Russo and Xu, has shown that the generalization error of a learning algorithm can be upper bounded by information measures. In most of the relevant works, the convergence rate of the expected generalization error is in the form of $O(\sqrt{\lambda/n})$ where $\lambda$ is some information-theoretic quantities such as the mutual information or conditional mutual information between the data and the learned hypothesis. However, such a learning rate is typically considered to be ``slow", compared to a ``fast rate" of $O(\lambda/n)$ in many learning scenarios. In this work, we first show that the square root does not necessarily imply a slow rate, and a fast rate result can still be obtained using this bound under appropriate assumptions. Furthermore, we identify the critical conditions needed for the fast rate generalization error, which we call the $(\eta,c)$-central condition. Under this condition, we give information-theoretic bounds on the generalization error and excess risk, with a fast convergence rate for specific learning algorithms such as empirical risk minimization and its regularized version. Finally, several analytical examples are given to show the effectiveness of the bounds.
Neural Fields for Interactive Visualization of Statistical Dependencies in 3D Simulation Ensembles
Jul 10, 2023
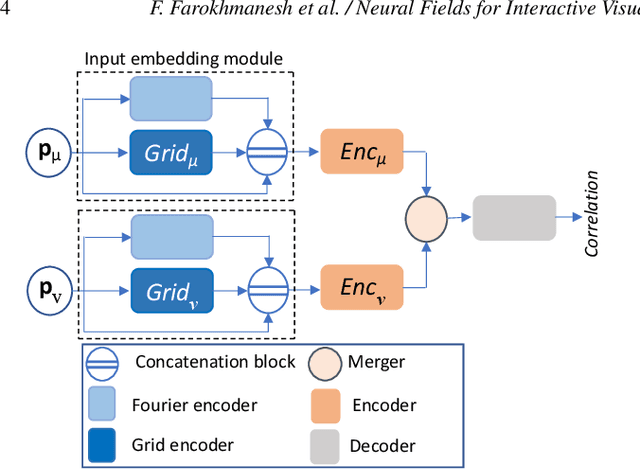
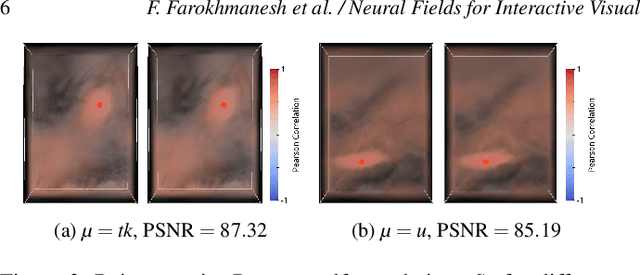
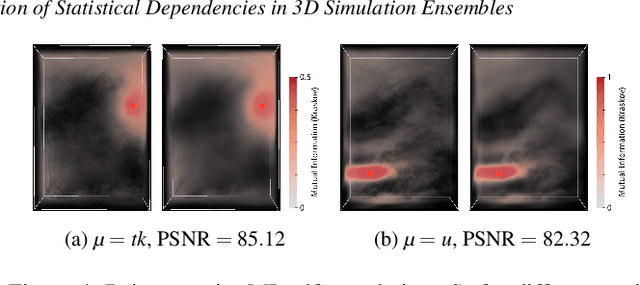
We present the first neural network that has learned to compactly represent and can efficiently reconstruct the statistical dependencies between the values of physical variables at different spatial locations in large 3D simulation ensembles. Going beyond linear dependencies, we consider mutual information as a measure of non-linear dependence. We demonstrate learning and reconstruction with a large weather forecast ensemble comprising 1000 members, each storing multiple physical variables at a 250 x 352 x 20 simulation grid. By circumventing compute-intensive statistical estimators at runtime, we demonstrate significantly reduced memory and computation requirements for reconstructing the major dependence structures. This enables embedding the estimator into a GPU-accelerated direct volume renderer and interactively visualizing all mutual dependencies for a selected domain point.
Reflective Hybrid Intelligence for Meaningful Human Control in Decision-Support Systems
Jul 12, 2023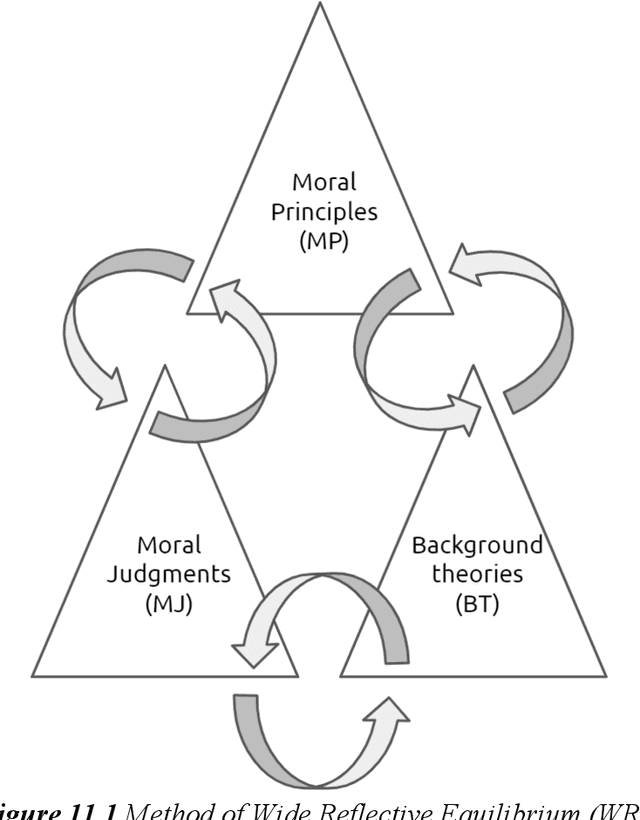
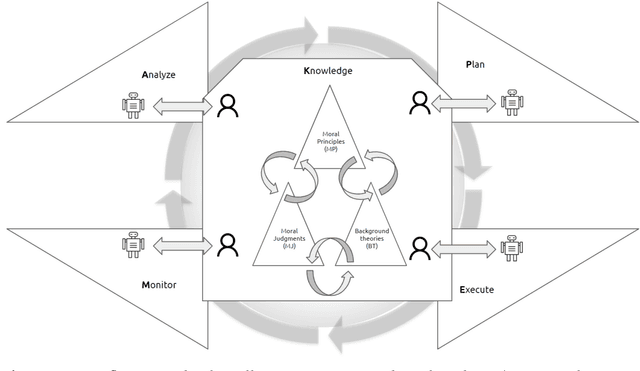
With the growing capabilities and pervasiveness of AI systems, societies must collectively choose between reduced human autonomy, endangered democracies and limited human rights, and AI that is aligned to human and social values, nurturing collaboration, resilience, knowledge and ethical behaviour. In this chapter, we introduce the notion of self-reflective AI systems for meaningful human control over AI systems. Focusing on decision support systems, we propose a framework that integrates knowledge from psychology and philosophy with formal reasoning methods and machine learning approaches to create AI systems responsive to human values and social norms. We also propose a possible research approach to design and develop self-reflective capability in AI systems. Finally, we argue that self-reflective AI systems can lead to self-reflective hybrid systems (human + AI), thus increasing meaningful human control and empowering human moral reasoning by providing comprehensible information and insights on possible human moral blind spots.
Learning with augmented target information: An alternative theory of Feedback Alignment
Apr 03, 2023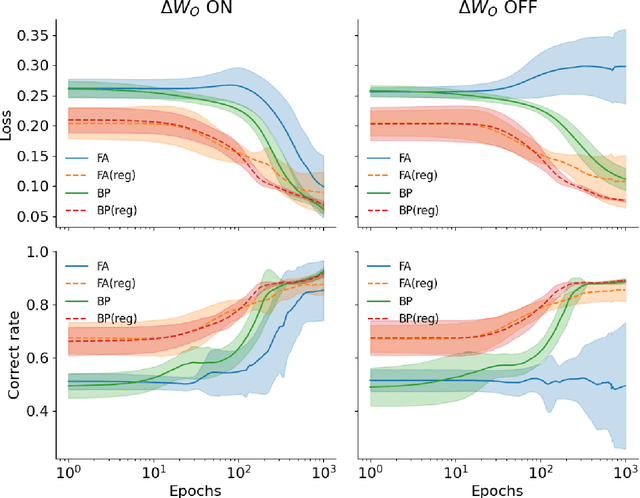
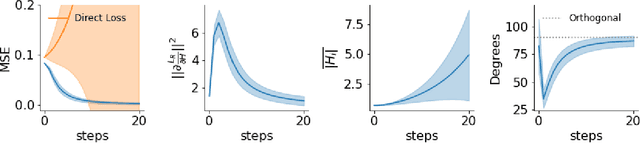
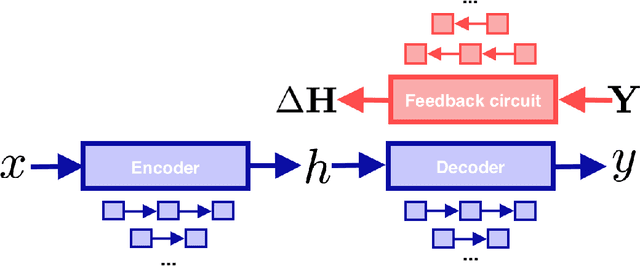
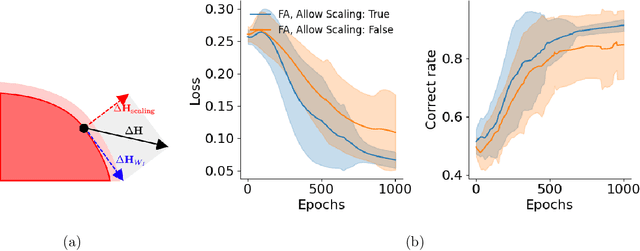
While error backpropagation (BP) has dominated the training of nearly all modern neural networks for a long time, it suffers from several biological plausibility issues such as the symmetric weight requirement and synchronous updates. Feedback Alignment (FA) was proposed as an alternative to BP to address those dilemmas and has been demonstrated to be effective on various tasks and network architectures. Despite its simplicity and effectiveness, a satisfying explanation of how FA works across different architectures is still lacking. Here we propose a novel, architecture-agnostic theory of how FA works through the lens of information theory: Instead of approximating gradients calculated by BP with the same parameter, FA learns effective representations by embedding target information into neural networks to be trained. We show this through the analysis of FA dynamics in idealized settings and then via a series of experiments. Based on the implications of this theory, we designed three variants of FA and show their comparable performance on several tasks. These variants also account for some phenomena and theories in neuroscience such as predictive coding and representational drift.
On the Value of Stochastic Side Information in Online Learning
Mar 09, 2023We study the effectiveness of stochastic side information in deterministic online learning scenarios. We propose a forecaster to predict a deterministic sequence where its performance is evaluated against an expert class. We assume that certain stochastic side information is available to the forecaster but not the experts. We define the minimax expected regret for evaluating the forecasters performance, for which we obtain both upper and lower bounds. Consequently, our results characterize the improvement in the regret due to the stochastic side information. Compared with the classical online learning problem with regret scales with O(\sqrt(n)), the regret can be negative when the stochastic side information is more powerful than the experts. To illustrate, we apply the proposed bounds to two concrete examples of different types of side information.
Removing confounding information from fetal ultrasound images
Mar 24, 2023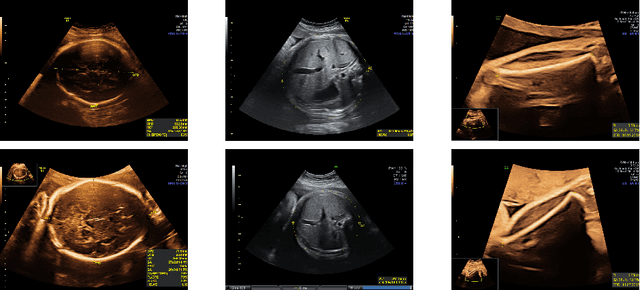
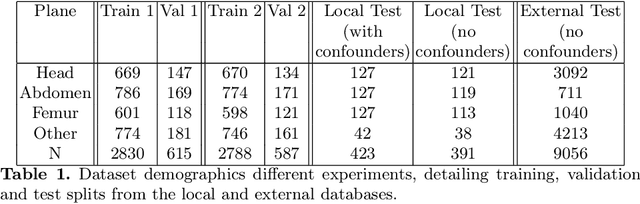

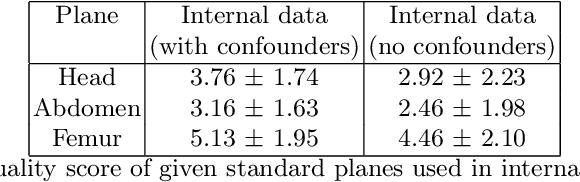
Confounding information in the form of text or markings embedded in medical images can severely affect the training of diagnostic deep learning algorithms. However, data collected for clinical purposes often have such markings embedded in them. In dermatology, known examples include drawings or rulers that are overrepresented in images of malignant lesions. In this paper, we encounter text and calipers placed on the images found in national databases containing fetal screening ultrasound scans, which correlate with standard planes to be predicted. In order to utilize the vast amounts of data available in these databases, we develop and validate a series of methods for minimizing the confounding effects of embedded text and calipers on deep learning algorithms designed for ultrasound, using standard plane classification as a test case.